Clustering Algorithms for Big Data
Info: 9297 words (37 pages) Dissertation
Published: 26th Nov 2021
Tagged: Computer ScienceInternet
CHAPTER 1 - INTRODUCTION
This chapter gives an overview about data clustering, Big Data and cloud computing. It describes about the aim of the thesis and the motivation behind it. Various challenges about clustering, Big Data and cloud computing have also been discussed.
1.1 OVERVIEW
Clustering is an unsupervised learning technique for discovering the groups or identifying the structure of the dataset. Survey papers [1,2,3] provide a good reference on clustering methods. Graph based method is one of the best used traditional clustering techniques. The advantage of graph based method to that of other methods is that the users need not know the number of clusters in advance. It is simple and the clusters are created by assigning the thresholds. Spectral Clustering [4] is a graph based method that constructs the graph with each point as vertex and the similarity between the points as the weights connecting the vertices. The disadvantage of spectral clustering is that it consumes much time and space.
Clustering using power method overcomes this issue by replacing the matrix decomposition by matrix vector multiplication. It is a very powerful and a simple method. Google’s page rank algorithm [5] uses the power method to compute its web pages. Power Iteration Clustering (PIC) [6] is an algorithm that clusters data, using the power method. This algorithm performs matrix vector multiplication where the matrix W is combined with the vector v0 to obtain Wv0. It is an iterative process in which the vector gets updated and normalized to avoid it becoming too large. The major drawback of the power method lies in its convergence factor. Though, it converges quickly at local minima, it has very slow convergence at global minima. The faster the algorithm converges higher is its efficiency. Hence, the convergence of the power method in PIC is accelerated using extrapolation techniques like fixed point iteration, Aitken method and Steffensen method [7,8].
Moreover, several terabytes of data are being generated every second. Handling this data, processing and extracting useful information from these is itself a big challenge. Existing sequential algorithms and tools have to be parallelized or refined to manage this growth. Also, new tools are needed to analyze them. It needs large computing power and distributed storage. Existing parallel processing architecture have several shortcomings like node failure, fault tolerance, network congestion, and data loss. Hence, Google introduced the MapReduce [9] framework that is flexible and supports distributed processing. Moreover, Cloud computing expands dynamically to handle Big Data. Public cloud like Amazon Elastic cloud can be used for computation and Amazon S3 for storage [10]. Using these tools and technologies, computation on storage and processing of huge datasets can be handled easily.
1.2 MOTIVATION
Clustering is an efficient tool to handle Big Data. Existing traditional algorithms becomes inefficient when it comes to larger datasets. The major reason is that most of the algorithms do not support huge size and dimensionality. Moreover, they are designed to handle only structured data. Graph data has become pervasive. Mostly, data comes from graph based network where nodes represent the data points and relation between the data points are its edges [11]. Data from various streams like log files, social network, you tube etc. are flowing in every second.Hence, existing algorithms should be refined to have good clusters regardless of its data size. This growing size and variety of data on the web, motivates us to refine some clustering algorithm that are scalable and effective for Big Data.
The drawbacks of the parallel computing architecture like fault tolerance, node failure and network congestion also have to be addressed. These issues of parallel architectures insist us to implement the existing algorithms in a distributed processing framework like MapReduce. The need for large storage and computation power prompts to choose the computing and storage resources like Amazon EC2 and Amazon S3.
1.3 AIM OF THE THESIS
The main aim of this thesis is to reduce the research gap by developing fast, scalable iterative clustering algorithms that converges faster having higher performance with better accuracy and reduced error rate. Another idea is to address the issues of parallel architecture using MapReduce framework. The implementation of the developed algorithms on a distributed framework on the cloud server makes them effective for storing and processing larger datasets.
1.4 MACHINE LEARNING
Machine learning is the method of analyzing data that uses algorithm that learns continuously from the data without being programmed explicitly. They learn themselves when they are exposed to new data. Machine learning is similar to that of data mining to search for the patterns in the data [12]. Machine learning uses these data to detect patterns and adjust program actions accordingly. Facebook, web search engine, smart phones, page ranking etc. uses machine learning algorithms for its processing. It constructs program with the characteristics that automatically adjusts itself to increase the performance using the existing data. The motivation of machine learning is to learn automatically and to identify the patterns to take decisions based on them. Machine learning has three methods namely [13],
- Supervised learning or Predictive learning
- Unsupervised learning or Descriptive learning
- Semi supervised learning.
1.4.1 Supervised Learning
Supervised learning which is also called as the predictive learning, is a method of mapping the inputs and the outputs, given a set of training set
D=xiyi1n, where, D is the training set and N is the number of training examples [12]. It is the method to discover the relation between the input and output represented in a structure called model. These models are used for predicting the output knowing the inputs. Here, the system uses a set of trained data to learn correctly to identify the patterns. They are trained using labeled data, where the output is known. The learning algorithm gets the output along with the output datasets to find the errors. Classification, regression, prediction are some of the methods of supervised learning. Supervised learning is grouped into [13]
- Classification model
- Regression model
In the regression model the input is mapped to the real value e.g. disease/ color, whereas in the classification model, the classifier maps the output to the predefined classes. e.g. dollars/ weights. Supervised learning is based on the training set from which the input features and the structure of the algorithm is determined. The steps involved in a supervised learning technique are as follows [13]
- Determine the type of training example
- Collect the training set
- Determine the input features
- Determine the structure and its algorithm
- Implement the algorithm
- Perform validation
- Evaluate the results.
Working of supervised technique – Given a set of training set {( x1,y1)……(xn,yn)}, a function
g:X→Ywhere
Xis the input and Y is the output and g is the element of some function G namely the hypothesis space [14]. Here g is defined using the scoring function
f=X×Y→R
such that g is defined as returning to Y with the highest score.
gx=argmax f(x,y)
Here f and g are chosen by empirical risk minimization that best fits in the training data or structure risks which controls the risk using penalty function. Some popular supervised learning algorithm include discriminant analysis and K-nearest neighbors for classification Linear regression for regression problems, Random forest for classification and regression problems, SVM for classification problems [15].
1.4.2 Unsupervised Learning
The unsupervised learning technique is a descriptive approach which finds the interesting patterns in the data
D=xii=1N where D is the training set and N is the number of training examples.This learning method represents the input x based on some features and searches for them. It labels the data automatically. It has input but no corresponding output. The data has no labels and the similarities between the objects are found i.e. a method for discovering labels from data itself [16]. It comprises of task like dimension reduction, clustering, density estimation etc. Their goal is to explore the data and find some structure within it. The steps involved in unsupervised learning includes [12]
- Discovering clusters – It can be done using model selection or by identifying the variables.
- Discover latent factors- It is used to reduce the dimensionality of the data based on the latent factor.
- Discover graph structure- It discovers the calculation between the variables where the nodes are the variables and the edges represents the relation between them.
- Matrix completion- It fills the missing data whose variables are unknown.
- Image inpainting – It fills the holes in the image with some realistic textures.
- Collaborative filtering- It is a method of prediction based on the rating of matrix rather the features.
Popular technique includes SOM, nearest neighbour, K-means etc. Unsupervised leaning is further grouped into
- Clustering- Here inherit groups in data’s are being learned.
- Association- Here the rules that describes larger portions of data are being discovered e.g. K- means for clustering and the Apriori algorithm for association.
1.4.3 Semi Supervised Learning
Semi-supervised learning is a technique where the samples are not labeled in the training data. These algorithms can perform well when there is a small amount of labeled points and a huge amount of unlabeled points [12]. Given a labeled training set, X
=xii∈n, it is partitioned into two sets,
xi={x1x2,….,xn}with labels
yl={y1y2,….,yl}and points
xu=xl+1,xl+2,….,xl+nfor which labels are not provided. The prediction is performed only on the test points with many inputs and a little output. It uses both the labeled and unlabeled data for training with small amount of labeled data and huge amount of unlabeled data. This learning can be used with classification, regression and prediction. It is used when the cost for training data is high.
1.5 DATA CLUSTERING
Data clustering is a method of grouping of dataset where each member in the dataset belongs to a particular group. Clustering is a type of unsupervised learning. It finds the structure in a group of unlabeled data. The unlabeled patterns are grouped into some meaningful cluster [11].
1.5.1 Cluster Analysis
Cluster is a collection of objects that have the same properties which is collectively known as a group. Cluster analysis is a method of finding the group of objects that are similar to each other within a group and are dissimilar between two different groups [17]. It groups the data, based only on the information about the object and the way it is being related. A cluster is said to be of good quality if the distance between the objects within the cluster is minimum and the distance between the objects of different clusters is maximum. The distance between the objects is shown in Figure 1.1
Figure 1.1 Cluster Analysis
Clusters can be well separated if the objects are close to other objects within the cluster than any of the objects outside the cluster. If the object is closer based on the prototype of the cluster then it is considered prototype based cluster. In a graph based cluster the data is represented as a graph with nodes representing objects and links representing their connections. Clusters can also be group based on the density. It is used when the clusters are irregular and have more outliers.
1.5.2 Data Types in Cluster Analysis
Data types have great impact on the choosing the clustering algorithm. Data can be of any type either categorical, structural, unstructured or temporal [18]. Some of the data types used in cluster analysis are
- Categorical data- These data types are used in real datasets, as many of the attributes like age, pin codes etc. are discrete.
- Text data- These are the most common types of data that are found on the web. They are sparse and also have great dimensionality. Their attribute value depends on the frequency of occurrence of the words.
- Discrete data- Most of the data are discrete e.g. web logs, biological data etc. They represent placement rather than time.
- Time series data- These are data from sensors, stock markets etc. these types of data are always dependent on each other. Many data’s are produced over time.
- Multimedia data- These are unstructured data obtained from social networks, mails, and videos. e.g. Facebook, Twitter etc. These data’s are of mixed type.
- Internal Scaled variables- It is a continuous measurement of a rough linear scale. It generally uses the Minkowski distance, Manhattan distance, and the Euclidean distance for its calculation.
- Binary variables- The binary variable has two states either it can be 0 or 1. Simple matching coefficient and Jaccard coefficient are used to measure the distance.
- Nominal variable- It uses the simple matching method which takes more than two states.
- Ordinal variable- They can either be discrete or continuous. It is measured as an interval scaled. Hence it uses the interval scaled variable for calculating dissimilarities.
- Mixed type variables- It can be binary, nominal, interval based or ordinal type of data.
1.5.3 Procedure for Cluster Analysis
Cluster analysis identifies the structure within the data. Xu et al.[19] have described the procedure for cluster analysis in various steps namely [20]
- Feature selection
- Choosing of efficient algorithm
- Cluster validation and
- Interpretation of the results
The first step of cluster analysis is feature selection. Feature selection is a very effective method for dimensionality reduction which selects the useful features. If the information provided is too large then the redundant data are identified and converted to a set of reduced features. Feature selection is not the same as feature extraction and it can be used if the features are more and the samples are less. It is used for the following reason
- Shorter training time.
- Simplification.
- Dimensionality reduction.
- Generalization.
Feature selection is classified into four models namely Filter model, Wrapper model, Embedded model and Hybrid model [21]. The steps involved in feature selection are subset generation, subset evaluation, stopping criterion, and result validation. As far as clustering is considered removing irrelevant features does not affect the accuracy but reduces the storage and computational time. Moreover, different classes of same features result in different clustering that helps to discover hidden patterns.
The second step is selection of an effective clustering algorithm. Choosing the algorithm depends on the cluster models. Some of the cluster models include graph based model, density based model, centroid based model, and connectivity based models [22]. It involves choosing the appropriate metric for validation. The metric is based on the similarity measure. The constraints are identified and the objective is defined. It depends on the effectiveness and the performance of the algorithm. The procedure for clustering is shown in Figure 1.2
Figure 1.2 Clustering Procedure
The third step is the implementation of the clustering algorithm to form clusters. Cluster validation is carried out here. Validation is used to measure the quality of the clusters generated by the algorithm [23]. Validation should be done to avoid noise, to compare the objects within the cluster, to compare two different set of clusters and also to compare the clustering algorithm. The measure of cluster validity includes external indices, internal indices or relative indices. The external criterion measures the performance and the internal criterion measures the cluster quality. A comparative analysis of the obtained structure and the existing structure is carried out in external and relative validation. It finds out the difference between the variables.
Result interpretation is the next step after cluster validation. The validated clusters obtained are to be examined and produced for analysis. The method of finally examining the cluster centroid and cluster variables is called result interpretation. Finally, the results are examined using different tools to obtain meaningful information.
1.5.4 Clustering Algorithm Design
Clustering is used in various fields of science like speech character recognitions, image processing, vector quantization etc. Distance and similarity measures play an important role in design of an algorithm. Some of the distance measures include the Euclidean distance, Manhattan distance and the Squared Euclidean distance. Cosine similarity and Jaccard similarity are some of the similarity measures [24]. Choosing distance and similarity measure depends on the objects and the way it is represented. After selecting the distance and similarity measures the clustering algorithm is designed. The design of clustering algorithm includes methods which can be hierarchical, nonhierarchical or it can be a combination of both [12].
The hierarchical methods are divided into agglomerative or divisive technique which identifies the cluster based on the selected features and forms a tree structure or hierarchy. The agglomerative method starts with its own cluster and two nearest clusters are combined to form a single cluster and the procedure follows. Some of the popular agglomerative technique includes single linkage, complete linkage, average linkage or centroid based [11,19]. The divisive approach begins with a single cluster and divides itself based on the similarity and it combines further containing dissimilar objects [22].
The non-hierarchical clustering methods include the partitional methods. It clusters the data based on the objects. It is generally used for larger datasets. It involves two steps namely identification of the clusters and the assignment of the clusters. The main advantage of non-hierarchical clustering technique is that it is simple and can be used for larger datasets. A combination of both the methods can also be used where the number of clusters is selected using hierarchical method and the clusters are formed using non-hierarchical method. Requirements of clustering algorithms are [25]
- Scalability – They deal with high dimensional datasets.
- Attributes –They handle different types of attributes like numerical data, categorical data, binary data etc.
- Handling outliers – They deal with noisy data, they identify and also remove them.
- Shapes–They detect clusters of any arbitrary shapes.
1.5.5 Challenges in Data Clustering
Data clustering has various challenges. Based on the data distribution the challenges identified include sparsity, outlier detection, high dimensionality and identification of large number of clusters. Based on application content the challenges lie on legacy clustering and distributed data. There are no definite solutions for the normalisation of the data. Moreover, choosing the similarity measure is itself a great task. There may be some redundant data available and analysing these data effectively is also an issue. As far as cluster analysis is considered there is no specific method for feature selection or extraction. There are no universal validation techniques for finding best solutions and to measure the quality of the results. Some common challenges faced are [26, 27]
- Identifying the number of cluster is difficult
- Identifying the distance measure for categorical attributes is difficult
- It lacks class labels
- Database contains unstructured data
- Database contains various attributes
- Choosing of initial cluster is difficult
- It cannot deal with high dimensionality
- It is sparse with less features
1.6 BIG DATA
Data becomes big when the size, speed and complexities increase to an extent that finds it difficult to be handled using existing algorithms and tools. Its challenges include storage, processing, sharing and visualization. Data can be of any types structured, semi structured or unstructured. The structured datasets X consists of some items {X1,X2,X3,….,Xm} with features x1,x2,x3,…..,xn. Therefore, {X1,X2,X3,…,Xm}={xij} where I =1,2,…,m and j=1,2,…,n. Here xijis the jth value of the element i. If the values m and n increases then the data is considered as Big Data [28]. On the other hand if its features increase then it can be considered as high dimensional data. Hence, the definition of Big Data is given as, “A Data is considered Big if it has high volume, high velocity and data high variety and its scale, diversity and complexity requires new tools, techniques and algorithms for processing and handling them”. Big Data classification [29] is shown in Figure 1.3.
Figure 1.3 Big Data Classification
There are huge numbers of data flowing in and out every second. They can be from shopping centers, ATM, social network, e-commerce, telecommunication, health care etc. Big Data can be defined as datasets whose size is above the capability of which any database can store and process. The understanding varies from person to person as described in HACE Theorem [30]. Every day at least 2.5 quintillion bytes are being generated. From the time of recording since the year 2003 the data was five billion GB. This was noticed to be produced in just two years in 2011 and every 10 min in 2013 [31].
These data may be relational like tables, transactional etc. or text data from the web or semi structured data as in XML, graph data as in social network or streaming data. The main aim of Big Data is to support the enterprise to take better decision and to analyse and process these huge data efficiently. Since, Big Data collected from these unstructured data cannot fit into the traditional database, new technologies have risen. Hence, these large datasets can be clustered and processed using these technologies.
The main seven pillars of Big Data that rules the data world today are Volume, Velocity, Variety, Variability, Value, Veracity and Visualization. These pillars are the characteristics of Big Data [32] and are shown in Figure1.4.
- Volume – It is the amount of data that is generated every second. The size of the data decides the value and its potential of it when considered. Data size is generally in terabyte, petabytes, sometimes even beyond them. The huge data can come form of log files, transactions etc.
- Velocity – It refers to the rate at which data is created and processed. The data that was processed for many years in 1990’s is being handled for every second nowadays. Every minute hundreds of data are being uploaded in YouTube, social network and hundreds of transactions takes place every second. The speed at which data is created should be directly proportional to rate at which data is processed for effective results.
- Variety – Data can be structured, semi structured and mostly unstructured. Data from social network, web, YouTube, are mostly unstructured. Managing, merging and governing these data are very challenging.
- Variability – The continuous change in data is its variability. This member of data from various resources led to inconsistencies in data flow. Some data keep on changing e.g. stock exchange, language processing etc. As a single word can have more meanings interpretation can also vary. Hence, a unique decoding is a challenge to be faced in Big Data [33].
Figure 1.4 Big Data Characteristics
- Value – It is the most important aspect of Big Data. It has low value density i.e. even the meaning is stored. Earlier the customer information was stored as a whole but now information about each customer itself has more value.
- Veracity – It is the provenance of the data origin. The level of accuracy, completeness and extendedness is its veracity. Noisy data should not be accumulated in the system.
- Visualization – Usage of charts & graph to view large amount of data may be more effective in displaying its meaning.
1.6.1 Big Data Clustering
Clustering in Big Data is classified into single machine clustering techniques and multiple clustering techniques. The single machine techniques include clustering and classification [34]. The multi machine clustering draws more attention that becomes more efficient for Big Data. Single machine clustering includes the sampling based technique like CLACARS, BIRCH, and CURE. Big Data Clustering Techniques are shown in Figure 1.5
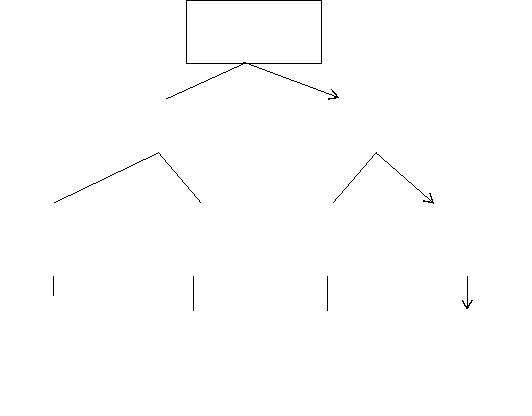
Figure 1.5 Big Data Clustering Techniques
Dimensional reduction technique, random projection and global project are the techniques to overcome the drawbacks of sampling. Although single machine clustering techniques improves scalability and the speed of the algorithm, they could not handle the growth of the data. But, multiple machine techniques easily handle these issues using parallel and distributed architecture. They can deal with terabytes and petabytes of data. Multi machine Clustering algorithms are divided into two types
- Unautomated distributions
- Automated distribution.
Unautomated or parallel algorithm has many issues like fault tolerance, node failure, uneven distribution of data etc. These issues are all overcome by the algorithm of automated distribution done using the MapReduce framework.
1.6.2 Big Data Storage Mechanism
Existing storage mechanisms of Big Data may be classified into three bottom-up levels namely file systems, databases, programming models [35].
- File Systems: File systems are the basis for the applications at the higher levels. GFS designed by Google is a distributed file system that supports large, distributed, parallel applications.
- Databases: Numerous database systems have been developed to handle datasets of increasing sizes. They support several applications and MySQL technology for Big Data. The three main MySQL database are key-value databases, column-oriented databases, and document-oriented databases.
- Programming Models- The programming model is difficult for implementing the application for data analysis. Further, it is difficult for traditional parallel architectures to implement huge data.
Big Data Storage – It is a storage method designed to store, manage and to process large amount of data. This data is stored such that it can be accessed easily and processed by applications to work on Big Data. The collected information is arranged in a convenient format for extracting and analyzing. Storage technologies are classified as
- Direct Attached Storage (DAS)
- Network storage
Direct Attached Storage (DAS):In DAS, numerous hard disks are connected directly with servers, and data management is held on the server rather than on individual machines. The data is stored on peripheral devices that take a certain amount of I/O resource to be managed by the individual application software. It connects only limited size. The DAS storage is shown in Figure 1.6
|
 Server Ports
Server PortsFigure 1.6 DAS storage
It has limited service for upgradation and expansion. When the size increases the efficiency decreases. The disadvantages of DAS include undelivered storage, socialisation of data, and dependency on server for replication.
Network Storage: It is to make use of the network to provide users with an interface for data access and sharing. It can be easily expandable. It is classified into two types.
- Network Attached Storage (NAS)
- Storage Area Network (SAN).
Network Attached Storage (NAS): NAS is actually an auxiliary storage equipment of a network and is directly connected to a network through a hub or switch using TCP/IP protocols. It provides a network for data access and sharing. Devices like disk, tapes, and other storage devices are present here. It is expandable and directly connected to the network and data transmission takes place as files. The performance and reliability can be predicted.The advantages of NAS are that it is flexible, scalable, efficient, predictable, highly available reduced cost and easily manageable.The NAS storage is shown in Figure 1.7
|
Figure 1.7 NAS storage
Storage Area Network (SAN): In SAN, is special designed for storage. Data storage management is independent on a storage local area network. Here the data switching among the internal nodes are used for data sharing and data management. It supports efficient bandwidth intensive network,
Distributed Storage System - It uses normal servers which are very powerful. They allow storage similar to databases, operating systems and all other applications [36]. Special devices are not necessary to store these information. Finding an efficient way to develop a large scale distributed storage system for efficient data processing and analysis is a great challenge [37]. To store enormous data, the following features should be taken into consideration
- Consistency (C)
- Availability (A)
- Partition Tolerance (P)
Since consistency, availability, and partition tolerance could not be achieved simultaneously, we can have
- CA system – This is achieved by ignoring partition tolerance.
- CP system – This is achieved by ignoring availability.
- AP system -This is achieved by ignoring consistency.
Distribute File System - It stores large unstructured data. Its main purpose is permanent storage and sharing of information. It performs functions like storing, retrieval, naming and sharing etc. It also supports remote information sharing, user mobility, availability [38]. The feature of DFS includes 1) Transparency,
2) Performance, 3) Scalability, 4) Availability. 5) Reliability, 6) Security and
7) Simplicity.
NoSQL- It stands for not only SQL. It is an efficient approach for database management and database design. The types of NoSQL database include Key Value storage, Document storage, Column storage and Graph storage. It’s a schemaless database. It provides write-ahead logging to avoid data loss. They are generally fast. Its advantages include flexibility and easy maintenance. It has a huge write performance.
NewSQL- it is a relational form of database for providing high per node performance and scalability. It maintains transactional guarantees. It supports ACID properties. Non locking concurrency control mechanism. It is almost 50 times faster than traditional database [38].
Cloud storage – It is a storage mechanism used for enterprises and other end users. It provides flexible access, easy storage service like Amazon S3, Microsoft Azure. Cloud storage is made of distributed resources. It is highly fault tolerant and durable. The cloud can be private, public or hybrid. Its benefits are that they can be accessed any time from any place. It has a remote backup, reduce cost and pay as you go characters. Its main drawback is limited bandwidth which causes a problem of accessing or sharing at low internet speed. It is also less secure in open cloud.
1.6.3 Tools for Big Data
Many tools for Big Data mining and analysis are available, including professional and amateur software, expensive commercial software, and open source software. The most widely used software’s are as follows [39,40, 41]
- R – It is an open source programming language designed to compute intensive tasks using C, C++ and FORTRAN. This software environment is specially designed for data analysis and visualization.
- Excel –It is an essential component of Microsoft Office. Itprovides effective data processing and statistical analyzing capabilities. It is the usually used commercial software.
- Rapid-I Rapid Miner– It is also an open source software. It is used in data mining, machine learning and predictive analysis. Data mining and machine learning programs provided Rapid Miner include Extract, Transform and Load (ETL), data pre-processing, visualization, modeling, evaluation, and deployment.
- KNIME (Konstanz Information Miner) – It is an easy open-source, data integration, data processing, data analysis, and data mining platform which allows users to create data flows in a visualized manner. It is possible to selectively run some or all analytical procedures, and run analytical results, models, and interactive views.
- Weka/Pentaho stands forWaikato Environment for Knowledge Analysis. It is free and open-source machine learning and data mining software written in Java. It supports features like data processing, feature selection, classification, regression, clustering, association rule and visualization.
- Apache Spark- It is a distributed framework to run very large data based applications across clustered computer. Its data repositories include HDFS, NoSQL, and HIVE. It’s based on Hadoop/ MapReduce. MapReduce can be used efficiently to query and process data. It has high processing speed.
- Tableau- It is a data visualization tool that creates and distributes data in the form of charts and graphs. It connects the files and Big Data sources to process data. It is highly scalable, easy and also fast. The data is connected and displayed as multiple graphic representations.
Applications Of Big Data
- Commercial application: These applications include storing the data in using current techniques like RDBMS. Some of the examples of this include forms of various reports, dashboard, queries, business intelligence, online transaction, interactive visualization and data mining [42].
- Scientific Application: Scientific research in many fields is gaining large data using massive output sensors and instruments, such as astrophysics, genomics, oceanology and environmental research.
- Multimedia Application: Multimedia data is the collection of different forms of data that contains valuable information by extracting useful information from them. Some recent research significances include multimedia summarization, annotation, index and retrieval, suggestion, and event detection.
- Mobile Data Analysis– Sensors play a major role for the source of Big Data by displaying its location and it also involves the delivery of the alert messages of patient who are connected to them.
- Big Data in Enterprises– In finance, this application has been greatly developed, while processing enterprises can improve its efficiency, contentment, labor force and cost, precisely forecasting the requirements, and avoiding excess production capacity [43].
- Online Social-Network Oriented Big Data: The application includes network public opinion analysis, collection of network intelligence and analysis, online shopping; government based decision-making support, and other online educational analysis.
- Medical Field Related Applications: It is very useful for the process of storing, retrieving, updating, deleting the medical records of the patients in the health care industries.
1.6.5 Relationship between Clustering and Big Data
Big Data is a broad and a large term that is used for a massive volume of structured and unstructured data. It is very complex to solve and process using usual databases and software. Clustering is an efficient tool of Big Data that helps in storing and processing large amount of data.
Big Data and Power Iteration Clustering: Power iteration clustering [6] is one of the simple and scalable techniques, when compared to other spectral methods. Steps involved in PIC includes,
- Input datasets and similarity function
- Calculate the Similarity matrix
- Perform Normalization.
- Perform Iterative matrix vector multiplication.
- Cluster using K-means and output results
The main advantage of Power Iteration Clustering is that it is of low cost when compared to other spectral clustering methods and also the number of clusters is not predefined. This algorithm is fast and scalable. It can easily handle larger datasets and it’s suitable for Big Data.
Big Data and K-means Clustering Algorithm: K-means is one of the most popular clustering algorithms, which are used in metric spaces. At first, K cluster centroids are selected randomly. Then, the algorithm reassigns all the points to their nearest centroids and recomputed centroids of the newly assembled groups. The iterative relocation continues until the criterion function converges. It is very sensitive to noise and outliers. Even a small number of such data has significant effect on the centroids. It has poor cluster descriptors and cannot deal with clusters of arbitrary shape, size and density [44].The steps involved in K- means are
- Choose the number of clusters, k.
- Randomly generate k clusters and determine the cluster centers
- Assign each point to the nearest cluster center.
- Recompute the new cluster centers.
- Repeat the above previous steps until some convergence criterion is met.
K-means is simple and easier. It’s fast on known inputs. The vectors obtained by the power method are clustered using any efficient clustering algorithm. Here, PIC uses K-means to cluster their vectors.
Big Data and K-medoids Clustering Algorithm - Partitioning Around Medoids (PAM) or K-medoids is represented by its medoids that is the most centrally situated object in the cluster. Medoids are more resilient to outliers and noise compared to centroids. PAM begins by selecting an object randomly as medoids for each of the k clusters. Then, each of the non-selected objects is grouped with the most similar medoids. PAM then iteratively replaces one of the medoids by one of the non-medoids objects yielding the greatest improvement in the cost function [45]. The advantages of K- medoids make it suitable for handling larger datasets on combination with an algorithm like PIC.
1.6.6 Relationship between Big Data and Hadoop
Hadoop is a tool to process huge and complex datasets that are difficult to be processed using existing tools. It is an open source distributed framework to deal with Big Data. Hadoop works to interpret or parse the results of Big Data through certain algorithm. It has two main components such as the MapReduce and the Hadoop Distributed File System [33].
Hadoop maps a large data set into
Hadoop is generally used as a part of Big Data applications in the industry, e.g., spam sifting, weather forecasting and social networks. Yahoo runs Hadoop in 42,000 servers at four data centers to strengthen its data and administrations, e.g. searching and spam sifting. The biggest Hadoop bunch was 4,000 nodes, expanded to 10,000 in Hadoop 2.0. In June 2012, Facebook reported that their Hadoop group can prepare 100 PB data, which became by 0.5 PB per day as in November 2012 [46]. Similarly, many organizations support using Hadoop for their effective utilization. Bahga et al. [47] proposed a system for data association and cloud assuming foundation the Cloud view. Cloud view uses blended architectures, nearby nodes, and remote clusters taking into account Hadoop to break down machine-generated data. Nearby nodes are utilized for the Figure of constant failures, clusters in view of Hadoop are utilized for complex tasks disconnected from the net investigation. Gunarathne et al. [48] utilized distributed computing foundations, AWS, and data handling system based on MapReduce and Hadoop to run two parallel bio-medication applications. The authors inferred that the free coupling will be increasingly connected to look into on electron cloud, and MapReduce frame work may give the client an interface with more convenient services and reduce excessive costs.
1.6.7 Relationship between Big Data and Cloud
Big Data needs large storage and computing power for processing and extracting useful information. Servers have resources for processing and storage of data. Storage saves the data and processor performs computation. To handle Big Data the processing and storage resources of cloud providers can be utilized. Cloud computing focuses on anywhere access and it can be dynamically expanded to handle Big Data. Cloud computing can expand and shrink and hence it is scalable. Cloud computing is cheaper because it’s enough to pay for what is being used. Big Data needs large on demand scale computing power and distribute storage which is provided by Cloud computing. Hence, cloud computing is used to process Big Data. It uses the scalable public cloud computer network to perform computing tasks e.g. Amazon Web Service. Cloud computing is a solution for processing data, storage and data distribution. Moving large datasets to and from the cloud is itself a great challenge [28,49, 50]. The advantages of cloud computing includes availability, scalability, reduced cost, easy computing and high storage capacity.
1.6.8 Challenges of Big Data Clustering
- Though there are billions and trillions of data, all of them are not of much benefit. A big challenge here is analyzing and extracting of useful information from them without discarding any essential information.
- Next big challenge is automatic generation of metadata that describes data about the data and its storage.
- Handling enormous amount of mixed data (structured, semi structured and unstructured) is difficult.
- Management of data between the database and the providers is also a difficult task to be noted.
- As data volume is increasing faster than computing resources and hence scalability becomes a concern.
- The system has to efficiently deal with the rapidity of the data since bigger the data, longer the time for processing.
- Privacy is also a concern since most of the data becomes public.
- The main challenge lies in the analysis, usage, and effective storage of data. The data should be understood correctly and managed. Quality should be taken care of and also useful information should not be discarded [29,34,46]. Moreover, they should also deal with outliers as most data are sensitive.
1.7 CLOUD COMPUTING
Cloud computing plays a major role in Big Data to store large amount of data. Storing and processing becomes easier because of cloud server like Amazon S3. Amazon EC2.
Basic Concepts
Cloud computing is a technology in which there are a large number of systems connected to configure, manipulate and process the applications online [51]. It provides dynamic and a scalable infrastructure for application, data and file storage. There are two working models for cloud computing 1) Deployment Models and 2) Service Models. Deployment models define the method of the location of the cloud. Cloud access is generally of four types Public, Private, Hybrid and Community cloud [51,52]. The different cloud computing service models is shown in Figure 1.8

Figure 1.8 Cloud Computing Service Models
The Public Cloud allows systems and services to be easily accessible to everyone in the public. It is open and hence it becomes less secure. They are owned by third parties. All customers share the same infrastructure with limited configurations, security and services. It provides low cost for the users since it is a pay as you go model.
The Private Cloud permits systems and services to be available for a particular group of people within an organization. Since, it is not open it is secure than public cloud. It addresses the problem of security and openness in public cloud. The internal private cloud has its own data center. Its drawback lies in its size and scalability. The external private cloud is more secure.
The Hybrid Cloud is a combination of both the public and private cloud. It brings the advantages and disadvantages of both the clouds. Main events can be carried out in private cloud whereas others can be done in a public cloud. Hybrid cloud improves the elasticity of computing as it can utilize the advantages of the third party cloud providers. It provides on demand services.
The Community Cloud permits systems and services to be available by group of organizations from a particular community which is managed by third party or hosted internally and externally. It has some security concerns.
1.7.2 Cloud Computing Models
Service models are of three types namely 1) Infrastructure as a Service (IaaS) 2) Platform as a Service (PaaS) and 3) Software as a Service (SaaS) [51]
- IaaS- It is a pay per use model which provides services like storage, database management and computation. Servers, storage system and network equipments are available to the users. Some of the examples include Amazon web services, GoGrid
- PaaS- It provides run time environments for applications, development and deployment tools. Here the platforms needed for designing and development are provided by the infrastructure. It provides a platform upon which other higher level services can be built.
- SaaS- The entire application is given to the customer. A single instance of server run and the users can make use of them. It serves highly scalable, internet based applications.
1.7.3 Benefits of Cloud Computing
- Reduced Cost – The cloud provides a pay as you go service and hence the cost for computing is reduced for the users.
- Increased Storage – The cloud providers offers large storage capability and easy maintenance to the users. Dynamic scaling is also provided by the clouds[53]
- Flexibility- Cloud provides speed delivery of the applications and the needs of the users. Hence, they are flexible by getting the resources needed for deployment. Public cloud can be integrated with private cloud easily.
- Reliability– Different resources and services are assigned from different region. If any one of the service fails in public cloud they can be acquired from another easily.
- Easy implementation- Implementation of cloud is much easier when compared to other technologies.
1.7.4 Challenges of Cloud Computing
- Data Protection- Security is an important concern associated to cloud computing. Since, the data is being open users have the disbelief that if they will be lost or unsafe. The fear of losing the data confidentiality is a major drawback [54].
- Limited control- There is only limited control of data to the users. Limited data access is provided based on user context. Customers are also limited to the control and manage their applications, data, and services, but not the backend infrastructure
- Possible downtime without internet connection- Cloud computing is dependent on internet connection. When the network is down, the services provided by the cloud providers may not be consumed. If the network connection is slow it affects its performance.
1.8 RESEARCH OBJECTIVES
Clustering is an efficient tool to analyse and extract Big Data. Existing clustering algorithms cannot be applied as such to handle Big Data as most of them are slow and are only efficient for smaller datasets. Some acceleration techniques can be induced to make them effective. They have to be parallelised using some distributed architecture that has the capability to support larger datasets. Hence, the main objectives of this research are as follows
- To design fast, scalable iterative clustering algorithms using convergence acceleration techniques that reduces the number of iterations, thereby decreasing the execution time.
- To minimise the error between the iterations leading to faster convergence.
- To improve the performance of the clustering algorithms by inducing Lagrangian constraints
- To improve the accuracy of the clustering algorithms using deflation techniques.
- To store and process larger datasets by implementing the developed algorithms using distributed framework Hadoop on the Cloud Server.
1.9 ORGANIZATION OF THE THESIS
The main objective of this thesis is to develop fast iterative clustering algorithms with faster convergence and greater accuracy to handle larger datasets by implementing them on a distributed framework Hadoop, thereby addressing the issues of parallel architectures. This thesis comprises of seven chapters.
Chapter 1 introduces the research problem and presents the general overview along with the challenges of the problem domain. It explains the fundamental concepts of clustering and Big Data and gives the relation between them. The motivation and the objectives of the thesis are also formulated and explained in this chapter.
Chapter 2 gives an overview of the Big Data clustering techniques and a detailed survey of ongoing research in this area. Based on the comparative study of the existing work, the research challenges have been identified.
Chapter 3 explains the new proposed algorithm for convergence using Aitken and Steffensen methods. The disadvantages of this proposed algorithm is identified and is being overcome using Banach fixed point theorem. Experimental results have also been discussed.
Chapter 4 describes about the Hyperflated Power Iteration Clustering algorithm using Lagrangian constraint and Schurs complement deflation techniques. The advantages and disadvantages are highlighted. The experimental results are shown to prove the efficiency of the proposed algorithms. They have less computational complexity and improve accuracy.
Chapter 5 describes about the performance evaluation of PIC, IPIC and HPIC using Hadoop and Amazon EC2. The cluster is being set and the developed algorithms are implemented using the distributed framework Hadoop on the cloud server. Comparative analysis is carried out and its characteristics are highlighted.
Chapter 6 discusses about two case studies where one is related to medical data mining for prediction of disease and the other is to analyze of the performance of the students. Experiments have been conducted to evaluate the algorithms based on the real datasets obtained from the patients datasets and the students dataset.
Chapter 7 concludes the research by highlighting the findings that facilitated to accomplish the objectives. The limitations of the thesis have been stated and insights into the possible future research directions are also given.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Internet"
The Internet is a worldwide network that connects computers from around the world. Anybody with an Internet connection can interact and communicate with others from across the globe.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: