Detecting Multiple Code Smells and Refactoring Solutions for the Code
Info: 11279 words (45 pages) Dissertation
Published: 30th Dec 2021
Tagged: Computer Science
CHAPTER 1 - INTRODUCTION
Motivation
The methodology of software development has evolved over years. Software products encounter different changes during its software development life-cycle (SDLC). The fundamental idea of the SDLC has been to seek the improvement of software frameworks in an extremely premeditated, organized and systematic way, requiring each phase of the life cycle – from beginning of the plan to delivery of the final product – to be done strictly and consecutively inside the context of the structure being connected [1]. The major phases of software development life-cycle are designing, development and maintenance. A software system becomes noticeably harder to maintain as it develops over time. Its design becomes more complicated and difficult to understand. These changes incite steady degradation of the software product. Due to inevitable time constraints, developers don’t have adequate time to plan and create proficient solutions. The software development process is then performed in a surge, prompting undisciplined execution decisions which causes the introduction of technical debt. Technical debt is the extra maintenance work that develops when code that is easy to implement in the limited time is used instead of the effective solution [7].
Software maintenance is expensive. The aggregate maintenance expense of a software product is 40%-70% of the aggregate cost of the lifecycle of the product [2]. Subsequently, decreasing the exertion spent on maintenance can be viewed as a method for lessening the general expenses of a software product. Due to these reasons, code smell detection and refactoring has been an area of interest for many researchers. According to Martin Fowler, “Refactoring is the process of changing a software system in such a way that it does not alter the external behavior of the code yet improves its internal structure. It is a disciplined way to clean up code that minimizes the chances of introducing bugs”[3]. Code smells are not bugs and they do not prevent the software code from functioning properly but they indicate the weaknesses of the software design which may slow down the process of development and elevate the risk of bugs and failures in the future [4]. According to Fowler, “a code smell is a surface indication that usually corresponds to a deeper problem in the system” [3]. Code smells are specific patterns in object-oriented software systems that prompt troubles in the maintenance of such systems [5]. According to Fowler, there are 22 code smells. These code smells can be divided into 7 different categories: Bloaters, Object-oriented Abusers, Change Preventers, Dispensable, Encapsulators, Couplers and Others [6].
Refactoring is an answer for the issue demonstrated by the code smell. Code refactoring is the way toward rebuilding existing code without changing its external conduct. Refactoring incorporates enhanced code clarity which in turn helps in easy maintenance of the code. Refactoring is carried out in three phases – locating the bad smells, selecting the appropriate refactoring for the bad smell, and finally implementing the selected refactoring. Accurate identification of code smells is the fundamental requirement for refactoring. The refactoring techniques rely upon the code smells found in the code. Presently, there are implementations which distinguish code smells, but all the tools provide detection facilities to only few code smells [29]. The tool proposed in this thesis helps to detect larger set of code smells and suggest ways to refactor the code by using design patterns.
Problem Statement
Recurrent refactoring is a technique to preserve and improve the design quality of a software product. Errorless refactoring can be achieved by proficient code smell detection. Such code smell detection techniques need to coordinate well with refactoring techniques in order to provide ample ideas to enable the client to comprehend the design flaws. Moreover, the procedure of code smell detection and removal by refactoring is complex. Without the understanding of the outline of the specific software product, the chances of breaking the code and degradation of the design are greater. Refactoring the code incorrectly can change the behavior of the code. Numerous refactoring tools have been produced [44, 2, 86, 43, 24] and there are many code smell detection tools proposed by researchers in past [49, 81, 19]. In most of the cases, these tools work independently. There are very few attempts in the areas of combining the tools for code smell detection and refactoring.
The major purpose of this thesis is to focus on developing a tool which detects multiple code smells and provide refactoring solutions to the code using design patterns. The tool automatically detects nine different bad smells and provides refactoring solutions to the code. The target language for this code is Java but the underlying algorithms can be used for the detection of code smells in other object-oriented languages. In order for the tool to detect code smells, the path of the source folder of project is given as an input to the tool. All the Java files in the source folder are parsed with the help of Abstract Syntax Tree (AST) [8] and the bad smells are detected with various algorithm implementations. Apart from this, other contributions of this thesis are:
- Analysis of correlation between code smells and refactoring techniques.
- Algorithms to detect specific code smells.
- Major reasons for code smell introduction in the code
- Computer-aided refactoring of the bad smells
Thesis Outline
The remaining part of the report is outlined as follows:
Chapter 2 discusses the previous work and related research in the field of code smells and refactoring. It also discusses in depth about various code smell detection techniques used in past.
Chapter 3 consists of the analysis of different code smells and discusses the classification of code smells into various categories. It also discusses an empirical study which analyzes when and why code smells are introduced in the code.
In Chapter 4, analysis is carried out for various refactoring techniques, their complications and the conditions that maintain the underlying semantics. It clarifies the significance of semantic checks and demonstrates cases of how refactoring could influence the conduct of the code.
Chapter 5 discusses the architecture of Abstract Syntax Tree alongwith demonstration of ASTVisitor and how it is used in this work
Chapter 6 presents the framework of the Code Smell Detection tool which detects 9 different code smells in the Java source code and provides refactoring suggestions for the code which contains the smells. This chapter also discusses the results obtained by verifying the tool against different test cases.
Chapter 7 draws the conclusion of this thesis and suggests the work that can be accomplished in future.
CHAPTER 2 - RELATED WORK
This section discusses the previous work in the field of code smell detection. It also reviews different refactoring techniques used for code smell removal and improving code quality. In this chapter, an extensive review is conducted for the analysis of different methods used for detecting code smells and anti-patterns and its influence on the non-functional attributes of the source code management and maintenance. Code smell is an indication that there is something wrong in the code. It is not a bug but may result in a bug if not taken care of. While anti-pattern is pre-defined template of solution to a commonly occurring problem, which is ineffective and increases the risk even more [30].
According to Martin Fowler, “a code smell is a surface indication that usually corresponds to a deeper problem in the system” [9]. In his book, Refactoring: Improving the Design of Existing Code, he introduced 22 different code smells which are discussed in depth in the later sections. Code smell can also be defined in terms of design principles and quality as “smells are certain structures in the code that indicate violation of fundamental design principles and negatively impact design quality” [10]. Code smells are not bugs in the system and they do not affect the functional behavior of the code, they are design deficiencies in the code which slows down the maintenance process and injects the risk of errors in future. In 2002, Van Emden and Moonen provided the initial formal elucidation of the code smell detection techniques [11]. They approached the problem by dividing the code smells into two groups – primitive smell aspects and derived smell aspects. They constructed the source model of the system by inspecting the primitive smell aspects and derived smell aspects which was later used for code smell detection. In 2006, Mantyla investigated about the approaches used by developers to distinguish the code smells compared to the detection process carried out by automatic detection tools [13]. A recent study revealed that code smells accumulate in the source-code over time. They are first introduced when the code snippet containing that smell is initially written. These code smells are not removed due to the additional refactoring work [14].
The presence of code smells makes the code prone to error. Such type of code is complex to manage. In the past, there are several researches done in the efforts of code smell detections. According to Satwinder and Sharanpreet, the techniques used for detection can be classified into various classes such as manual detection techniques, visualization-based detection technique, semi-automatic techniques, automatic techniques, empirical based techniques and metric based techniques [17].
The initial approach used by researchers and developers for code smell detection was manual detection. Manual detection technique required human interaction and it was very time-consuming, but it formed the base for different techniques such as semi-automatic and automatic techniques. James Noble presented the relationship between design patterns by classifying the design patterns into two groups, primary relationships and secondary relationships [15]. Relationships such as ‘pattern uses another pattern’, ‘pattern refines another pattern’ and ‘pattern conflicts another pattern’ are primary relationships. Relationships such as ‘pattern similar to another pattern’ and ‘pattern combining with another pattern’ are secondary relationships. Other secondary relationship between the design patterns defined by him are ‘variant’, ‘requires’, ‘tiling’ and ‘sequence of elaboration’. GH Travassos detected bad smells in object-oriented design by providing a set of reading techniques [16]. Software reading techniques endeavor to improve the viability of analysts by providing a set of rules that can be utilized to analyze (or “read”) a given piece of code. The reading techniques used by Travassos for bad smell detection are Defect-Based Reading (DBR), Perspective-Based Reading (PBR) and Use-Based Reading (UBR). DBR detected smells in the requirements which are presented using a state machine notation called SBR. Similarly, PBR detected smells in the requirements but the requirements are represented using natural language. UBR detected anomalies in user interfaces.
In past, many researchers used visualization-based techniques to detect the smells in the source code. These techniques use methods which are visualization oriented such as graphs and UML diagrams to detect the design defects. Langlier et al. provided a visualization-based approach for the quality assurance of complex systems. They described four features in their visualization framework – class representation, program representation, navigation and data filtering [18]. They used a geometrical 3D box for class representation. Geometrical 3D boxes can be used very efficiently as multiple entities can be represented by it. The qualities measured by them in the class representation using geometrical 3D box are cohesion, coupling, inheritance and size complexity. Umut et al. suggested an approach for mining object-oriented design structure [19]. They used sub-graphs to detect similar design structure in the source code. In visualization-based approach, using geometrical structures lead to clear understanding of frequently used designs for software development, more frequently occurring bad smells and model-specific patterns which help engineers to improve the product quality. Moreover, identification of similar design patterns and anti-patterns lead to easier refactoring solutions. Umut et al. experimented with this framework on many open-source projects and effectively found identical design patterns and anti-patterns in the code.
Recently, developers and researchers have turned towards semi-automatic and automatic detection techniques for bad smell detection. These detection techniques use automatized models with minimal human interactions. M. Lakshmanan and S. Mankandan proposed an approach for automatic code smell detection and refactoring [20]. They made the resolution sequence of code smells based on a priority which is calculated by applying topological sorting to the code smells. In order to remove these code smells, they performed multi-step refactoring whose steps include model evaluation, extract design, preferred design and refactoring. Results of this experiment using prioritized sequence of code smells and multi-step refactoring proved to work better than other semi-automatic approaches. Another automatic refactoring work was proposed by Marios et al [21]. They presented a tool developed as an Eclipse plug-in which recognizes Extract Class refactoring by using the clustering algorithm which identifies closely coupled classes within the system. Apart from this, their tool provided rankings to the refactoring techniques based on the amount of refinement it brings to the system. Ranking procedure for the refactoring techniques is carried out by using the Entity Placement metric which measures the overall design quality of the system. Orchard and Rice developed a tool named CamFort which is a refactoring tool for source code written in Fortran. This open-source automatic refactoring tool focuses on domain-related features and design models related to memory and data management. CamFort provides three types of refactoring solutions – equivalence statement elimination, common block elimination and derived data type introduction [22].
Apart from manual and automatic code smell detection, there is metric based code smell detection in which different types of metrics are used to measure different characteristics of refactoring techniques and code smells. Also, many researchers use the metric-based system to measure the quality of code. Remco et al. built a metric-based system that can be utilized to correct the anti-patterns and additionally the degree to which the processes overlap [23]. They assessed it by applying it to two vast process architectures. The assessment demonstrates that the procedure can be utilized to pinpoint the exact area of three refactoring techniques with high accuracy. Elish and Alshayeb categorized the refactoring techniques based on metrics such as internal quality measurements and code testing exertion. It demonstrated an accurate suggestion of the refactoring techniques to be used to optimize the software architecture [24]. Huston Brian suggested an approach for determining the compatibility between the design patterns and the design metric [25]. Huston analyzes the situations where the design pattern and metrics are in contradiction. He analyzed three design patterns against the anti-patterns – Mediator, Bridge and Visitor. The results of his experiments show that pattern-metric incongruity can be reduced if the reduced high metric score is used for determining the pattern usage.
A software system can be made more maintainable by applying various refactoring techniques to the code. Various code modifications are conducted by applying multiple refactoring techniques to various segments of code. Normally, various code smells are recognized in programming; henceforth engineers consider numerous refactoring to improve the quality of software. This leads to a refactoring chain will decrease the time complexity and cost of system maintenance. The code smells can be withdrawn, and time required for making changes in the code can be lessened by applying suitable refactoring techniques. Harman and Tratt presented an approach for search-based refactoring using Pareto optimality [26]. Executing the search based refactoring framework for several number of times led to the generation of a Pareto front, the estimations of which leads to Pareto ideal chain of refactoring techniques. Pareto front expand different metrics used to decide the refactoring techniques to be used. They also demonstrate how the generation of a Pareto front reduces the requirement for complex blends of metrics.
CHAPTER 3 - CODE SMELLS
The term ‘code smell’ was first coined by Kent Beck [3]. A code smell is a signal in the source code that demonstrate potential issues. Code smells are design limitations that indicates the necessity for refactoring. Code smells can be considered as signs to the engineer that some of the sections of the code might be prone to future errors and that it should be improved to increase its understandability and maintainability.
In order to carry out detection and refactoring of code smells effectively, this chapter discusses briefly when and why code smells are introduced. Additionally, code smells are classified into different categories for better understandability.
When and Why Code Smells Are Introduced?
Code smells are the manifestations of faulty and improper design and implementation practices. Code smell is one of the important factors resulting in technical debt and it also influences the maintainability of the software [28]. Some research proposes that critical maintenance actions and the requirements to deliver the product in a situation where time-to-market is preferred over code quality are few of the reasons for code smells. Therefore, software evolution can be considered as one of the reasons for introduction of code smells in the code.
According to the study conducted by Tufano et al., most of the code smells are introduced just before the release of the product. The amount of smells introduced in the initial stages is very low [23]. This backs the fact that the pressure to deliver the product on time can be one of the causes for code smells. Their study also suggests that smells introduced during the enhancement of the features in a software product is 60-66% more compared to the smells introduced during the initial development of the code. Enhancement of a feature is the change applied to the existing code in attempts to improve the product. In addition, the cost of refactoring the code is more when the possibility of side-effects is more compared to the benefits. Also, the tools available in market for code smell detection and refactoring are not very efficient or useful for the developers of software products. As a result, there is a high increment in the number of code smells in the code.
Classification of Code Smells
Based on Properties
In 2000, Martin Fowler and Kent Beck introduced 22 different code smells [3]. According to Mantyla, the flat list of code smells makes it complex to understand and determine the relationship between code smells [6]. Therefore, he divided the code smells into 7 categories depending upon the properties and nature of code smells. Table 3.1 shows the classification of code smells based on properties.
| Categories | Code smells |
| Bloaters |
|
| Change Preventers |
|
| Couplers |
|
| Dispensables |
|
| Object-Oriented Abusers |
|
| Others |
|
Table 3.1 Classification of code smells based on properties
Bloaters. Bloaters are the set of code smells that has increase the code size so much that it is difficult to cope up with. Bloaters include following code smells –
Long Method
A method, procedure or function which contains too many lines of code is considered to be ‘Long Method’. When a method is too long, it uses large number of variables and performs multiple operations and it is more plausible that the method does more than what its name suggests. When a method is small in size, understandability and maintainability of the code increases.
Large Class
Similar to long method code smell, large class code smell occurs when the class is very large in size and contains too many methods, instances and variables. It is very difficult to understand such classes and in case of errors in the class, it is complex to find and resolve the errors. Large class code smell can be cured by Extract Class refactoring technique. The code clumps that are the part of same function and which goes together can be moved to a new class.
Primitive Obsession
Primitive obsession occurs when the primitive data types are used excessively to render the domain ideas. Primitive data types are the building blocks of a language. When the data structure becomes complex, using primitive data types is much easier compared to creating a new class which leads to the abuse. As a result of primitive obsession code smell, code becomes inflexible and harder to control. Also, the ease of the object-oriented design is lost and it tends to lead to a procedural code.
Long Parameter List
When more than three or four parameters are passed as an argument to a method, long parameter list bad smell occurs. When there is a need for additional data in the method, object can be used instead of passing that data as an argument. A long list of parameters is hard to understand and it becomes harder to maintain as it increases in size.
Data Clumps
Data clumps bad smells is the result of similar data types at multiple parts of the code. When a chunk of data appears multiple times in a code, it should be extracted into a class. It results in the reduction of code size and better understanding and organization of code.
Change preventers. Code smells classified in this category makes software modification difficult. When these code smells are present, to make a single code modification, many other parts of code also require modifications.
Divergent Change
When a single class is changed in multiple ways due to different reasons, divergent change bad smell occurs. When a single class is modified for different reasons, it can be assumed that the class has too many responsibilities. In many instances, divergent change is the result of poor programming practices.
Shotgun Surgery
Shotgun surgery is similar to divergent change code smell. When divergent change code smell is present, multiple changes are made to a single class. But when shotgun surgery code smell is present, when a single change is made to multiple classes when there is excessive coupling between the classes and a single responsibility is shared among multiple classes.
Couplers. As the name suggests, this group of code smells occur as a result of excessive coupling between classes.
Feature Envy
Feature envy results when a method uses more objects of another class compared to its own class. This situation may occur when variables and methods are moved to a data class.
Inappropriate Intimacy
Inappropriate intimacy occurs when two classes are highly coupled and methods of these classes use the private variables of each other.
Message Chain
When a class has very high coupling with other classes in the form of chain, message chain bad smell occurs. A message chain occurs when an object of one class calls object of another class which in turn calls object of another class and so on. Due to high coupling, main class require changes when the intermediate classes are changed.
Middle Man
Middle man bad smell occurs when a method or a class passes most of its request to another class or method. A middle man is a class or a method which is not effectively contributing in the system. Removing middle man results in a cleaner and more understandable code.
Dispensables. Code smells classified in this category contributes to trivial and inessential code whose absence will make the code more efficient and understandable.
Lazy class
A class is considered to be a lazy class when it does not perform enough functions. Such situation arises after the class has been refactored and downsized or if the class has been developed in order to support future needs which never came.
Data class
A class which contain only data fields and methods like getters and setters for accessing them is called data class. Data class is generally a repository for data which is utilized by another class. These classes do not have any auxiliary usefulness and they cannot act on their own. It increases the coupling between the classes.
Duplicate Code
Duplicate code bad smell occurs when there are multiple code fragments performing same function in the source code. Code duplication may occur when different programmers are unaware of each other’s work. Duplicate code can be removed by extracting a method or a class.
Speculative Generality
Speculative generality occurs when there is unused code written to support the future needs which never got implemented. It makes code harder to understand and maintain.
Object-oriented abusers. All the smells classified in object-oriented abusers result when the concepts of object-oriented paradigm are applied incorrectly.
Switch Statements
A good case of object-oriented programming indicates less usage of switch cases. Generally, there are many switch cases across the code when a single case is added to satisfy all conditions. When a new condition is added, all the switch cases across the code needs modification.
Temporary Field
Temporary field bad smell occurs when certain variables get their value only in particular circumstances. This happens when these variables are used only in a method. So, variables get their values only when a method is called. In all the other cases, these variables remain empty.
Refused Bequest
When a subclass uses only few methods of its parent class, refused bequest smell occurs. The main objective behind inheritance is code reuse. But when subclass does not use much of its parent class code and has its own method, then there is very less code reuse which contradicts with inheritance paradigm.
Alternative Classes with Different Interfaces
When there are multiple methods which perform similar functions but have different names, alternative classes with different interface smell occurs. It increases code duplication and understandability of such code is very poor.
Others.
Incomplete Library Class
When the functionalities of built-in library classes stop meeting the needs of the developer, incomplete library class code smell results because the library class are only readable. They cannot be modified as per developer’s needs.
Comments
Including comments in the code is a sign of good documentation. But excessive usage of comments result in comments code smell.
Based on Coverage
Another classification of code smells is based on the coverage of code smells. Based on this, code smells are divided into two categories:
- Code smell between classes
- Code smell within class.
In a large-scale software application with multiple classes, there might be object references and method calls between the classes. Code smells like message chain, middle man, etc. generated in such situations are the result of multiple classes. Such code smells are categorized into the first category. On the other hand, code smells within the class affects only one class which contains it. Table 3.2 shows the classification of code smells based on the coverage.
| Code smells between classes | Code smells within classes |
|
|
Table 3.2 Classification of code smells based on coverage
CHAPTER 4 - REFACTORING TECHNIQUES
Due to a variety of rationales, there are multiple smells in the code, and engineers are expected to clean the code. Code refactoring is the systematic procedure of taking code that misses the mark of an ideal design and progressively improving it to a better design. This is achieved by changing the internal structure of code while keeping the external behavior of code intact. It reduces the chances of bugs in the code and increases the maintainability and understandability of code [3]. Martin Fowler cataloged 72 refactoring techniques and classified them seven categories.
| Categories | Refactoring techniques |
| Composing Methods | Extract Method
Replace Method with method Object Inline Method Replace Temp with Query Inline Temp Split Temporary Variables Introduce Explaining Variables Substitute Algorithms Remove Assignments to Parameters |
| Big Refactoring | Convert Procedural Design to Object
Tease Apart Inheritance Extract Hierarchy The Nature of the Game Separate Domain from Presentation |
| Organizing Data | Change Bidirectional Association to Unidirectional
Replace Data Value with Object Change Reference to Value Duplicate Observed Data Encapsulate Collection Encapsulate Field Replace Array with Object Replace Data Value with Object Replace Magic Number with Symbolic Constants Replace Record with Data Class Replace Subclass with Fields Replace Type Code with Class Replace Type Code with State/Strategy Replace Type Code with Subclasses Self Encapsulate Field |
| Moving Features between Objects | Extract Class
Introduce Local Extension Hide Delegate Move Field Inline class Move Method Introduce Foreign Method Remove Middle Man |
| Making Method Calls Simpler | Add Parameter
Rename Method Encapsulate Downcast Replace Constructor with Factory Method Hide Method Replace Error Code with Exception Introduce Parameter Object Replace Exception with Test Parameterize Method Replace Parameter with Explicit Methods Preserve Whole Object Replace Parameter with Method Remove Parameter Separate Query from Modifier Remove String Method |
| Dealing with Generalization | Collapse Hierarchy
Pull Up Field Extract Interface Pull up Method Extract Subclass Push Down Field Extract Superclass Push Down Method Form Template Method Replace Delegation with Inheritance Pull Up Constructor Body Replace Inheritance with Delegation |
| Simplifying Conditional Expressions | Consolidate Conditional Expression 18
Consolidate Duplicate Conditional Fragments Decompose Conditional Introduce Assertion Introduce Null Object Remove Control Flag Replace Conditional with Polymorphism Replace Nested Conditional with Guard Clauses |
Table 4.1 Classification of Refactoring techniques (Martin Fowler)
Out of these refactoring techniques, we will discuss 12 refactoring techniques in this chapter. These refactoring techniques can be utilized to remove the bad smells discussed in this thesis.
Rename Method
When the name of the method does not signify the intention completely, rename method can be applied. Poor naming convention can lead to confusion and increase in time required for understanding and maintainability. Inefficient method names can result when programming is carried out in rush or when the functionalities of the method evolved, the method name stopped providing enough insight.
Refactoring procedure
- If the method is defined in superclass or subclass, repeat all the steps.
- Declare a new method with a meaningful name and copy all the steps from the old method and replace the body of the old method with a call to the new method.
- Obtain all the references to the old method and replace them with the references of new method.
- Delete old method.
- Compile
Example

Figure 4.1 Bad code – Rename Method

Figure 4.2 Refactored Code – Rename Method
Move Method
Move method refactoring can be applied to reduce the coupling between the classes. If a method uses object of another class more than the object of the class in which it is defined, move method should be applied. When method calls are made more frequently from another class, moving method to that class decreases the dependency between the classes.
Refactoring procedure
- Check all the attributes used by the method. If there are few attributes used by the method or the attributes are used only by that method, then those attributes should be moved along with the method
- Declare a method in the new class and provide a self-explanatory name.
- Replicate all the code from the original method to the new method.
- Replace the code of the source method with the call to the new method.
- Change all the old method references to new method references.
- Remove the old method.
- Compile
Example
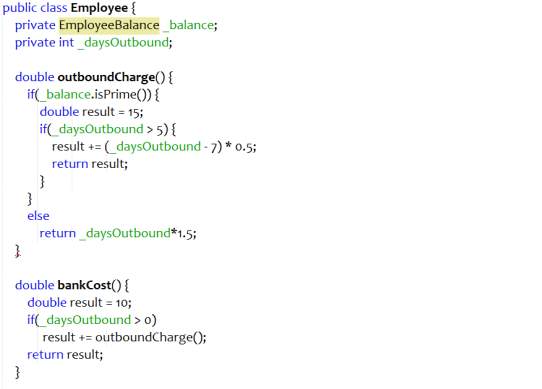
Figure 4.3 Bad code – Move method

Figure 4.4 Refactored Code – Move Method
Add Parameter
When a method does not have enough data and requires more data from the caller, add parameter can be applied. This refactoring technique should be used carefully because excessive usage can result into long parameter list bad smell.
Refactoring procedure
- If the method is defined in superclass or subclass, repeat all the steps.
- Declare a new method with a meaningful name and copy all the steps from the old method and add the required parameter. Replace the body of the old method with a call to the new method.
- Obtain all the references to the old method and replace them with the references of new method.
- Delete old method.
- Compile
Example
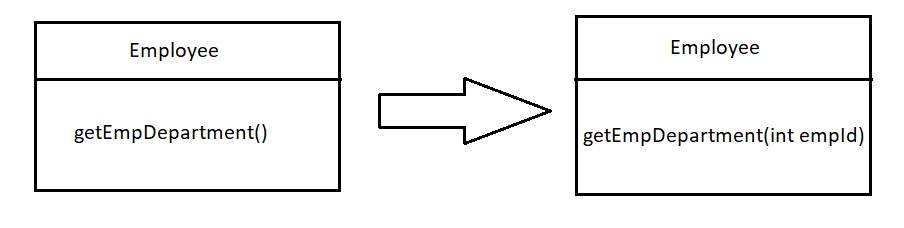
Figure 4.5 Add Parameter smell and refactoring
Parameterize Method
In many cases, multiple methods perform identical tasks with different values. Such code constitutes to duplicity and inflexibility. It can be cured by using parameterize method refactoring. New method is created with additional parameters to address different values and the logic of the old methods is added to it.
Refactoring procedure
- Create a new method with additional parameters to replace the old methods.
- Replace the code of one of the old methods with the call to the new method.
- Repeat the step for all the old methods.
- Compile and test.
Example

Figure 4.6 Bad code – Parameterize Method
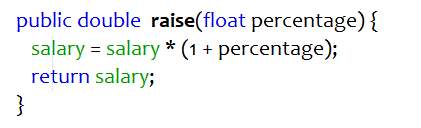
Figure 4.7 Refactored code – Parameterize Method
Extract Super Class
Another example of duplicate code is two or more classes containing similar functionalities. Code duplication is one of the major problems in programming. It can be solved by creating a super class which contains the common functionalities of these classes.
Refactoring procedure
- Create a new super class and make the old classes sub-classes of this super class.
- Use Pull up methods, Pull up constructor-body and Pull up fields refactoring techniques to move the common functionalities of old classes to the super class.
- Compile.
Encapsulate Field
One of the four pillars of object-oriented programming is encapsulation. Encapsulation hides data from outside environment. When the inner data of the class can be accessed directly by other classes, risks of discrepancies in the values and behavior of the data increases. This decreases the flexibility of the code. Encapsulate field makes the data of the class private and adds getter and setter to access the data.
Refactoring procedure
- Create getters and setters for the fields in the class.
- Replace all the references to these fields with the call to getters and setters.
- Change the access modifiers of the fields to private.
- Compile.
Example
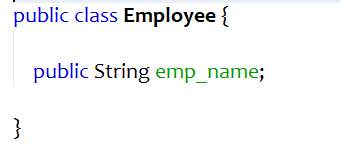
Figure 4.8 Bad code – Encapsulate Field
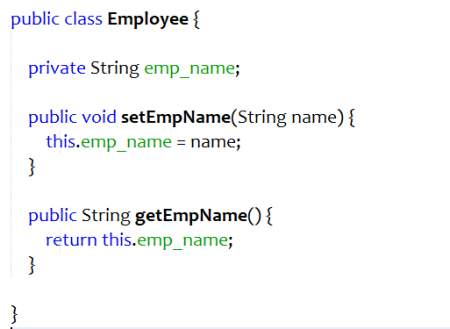
Figure 4.9 Refactored code – Encapsulate Field
Extract Method
When a block of code performs a single function and can be placed together, then it can be converted to a method. This increase the modularity and reusability of the code and decrease code duplication. When there are too many lines of code in the method, then extract methods refactoring can be applied to the chunk of code that can be grouped together.
Refactoring procedure
- Create a new method and give it a self-explanatory name. Replicate the extracted code to the new method.
- Replace the extracted code with the call to the new method.
- Examine the extracted code. If it contains any temporary variable that is used inside the method only, then declare those fields in the new method.
- If the variables are used outside the extracted code, then pass those fields in the return statement.
- Compile and test.
Example

Figure 4.10 Bad code – Extract Method

Figure 4.11 Refactored code – Extract Method
Remove Middle Man
If a class has too many methods that doesn’t do anything except assigning the task to other objects, then such methods should be removed and the methods that perform the tasks should be called directly.
Refactoring procedure
- Replace all the calls to the intermediate method with the calls to the method that performs all the tasks.
- Delete the intermediate method.
- Compile.
Example

Figure 4.12 Bad code – Remove Middle Man

Figure 4.13 Refactored code – Remove Middle Man
Replace Temp with Query
Temporary variables are created to store the results of the expression or some other values which are used later in the code. Such temporary variables increase lines of code. Those expressions can be extracted into a method and replace all the references to the temporary variables with the method call. This method can also be reused by other classes and methods.
Refactoring procedure
- Examine the code and verify that the temporary variable is assigned the value only once.
- Create a new method and the right-hand side of the temporary variable to the body of the method.
- Replace all the references of the temporary variable with the call to the new method.
- Compile and test.
Example
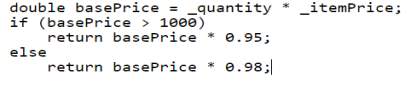
Figure 4.14 Bad code – Replace Temp with Query

Figure 4.15 Refactored code – Replace Temp with Query
Introduce Parameter Object
If there are multiple parameters in the code that can be grouped together, replace those parameters with an object. As a result, all the similar data is clumped together. It reduces code duplication and increases code readability.
Refactoring procedure
- Create a new class to store the group of parameters.
- Add all the parameters to the class.
- Create an object of the new class and replace all the references to the parameters in the data clump with the object.
- Remove the old parameters.
- Compile and test.
Decompose Conditional
Complex conditional logic in the code is very hard to understand. Writing code to fulfill different conditions increases the lines of code and may result in a long method or long class bad smell. Code can be made more readable by extracting the conditions and the logic inside the conditions into a new method. Replacing the conditional logic in the code with the method call makes the code cleaner.
Refactoring procedure
- Copy the conditional logic of code into the new method with the help of extract method refactoring technique.
- Repeat the above step for then and else block.
- Replace the conditional logic of the code with the call to the new methods.
- Compile.
Example
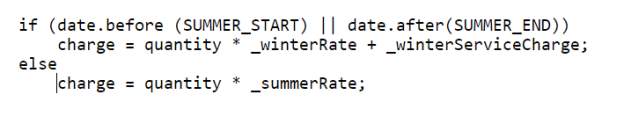
Figure 4.16 Bad Code – Decompose Conditional
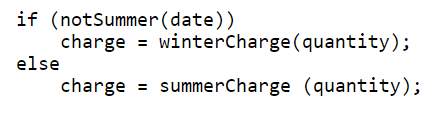
Figure 4.17 – Refactored code – Decompose Conditional
Extract Class
When a class is too long, it is very difficult to know the intention of the class. Initially, the classes are created with a clear motivation and they contain very specific and less amount of data. With the increase in requirements, more methods and parameters are added which results in a very long class. Such classes are bad sign of programming. To solve this issue, determine blocks of code that can be extracted to a new class. Move the code to a new class and the replace that code in old class with the object reference.
Refactoring procedure
- Create a new class.
- Create a link from old class to the new class.
- Determine the blocks of code that can be extracted from the old class.
- With the help of move method and move parameters refactoring techniques, move the pre-decided parameters and methods to the new class.
- Compile and test after each step.
CHAPTER 5 - ABSTRACT SYNTAX TREE
Abstract syntax tree (AST) is the abstract representation of the source code in the form of a tree. The tree representation of source code is more suitable to examine and alter the code programmatically. Every node of the tree represents a single statement in the source code. The structure of the tree, being abstract, does not represent all the details of the source code. For example, start and end parenthesis are not represented in the tree structure and a statement like an if-else condition is represented in the abstract syntax tree with three nodes. As a result, the abstract syntax tree is different from other parse trees, which are generally built by the parser during compilation of code.
Due to the following properties of the abstract syntax tree, it is very useful for the analysis of source code and its modification.
- An abstract syntax tree can be altered and upgraded with data, for example, modification can be carried out for the properties and information of each component it contains. Such altering is difficult with the source code directly, due to various dependencies.
- Contrasted with the source code, an AST does not contain unnecessary braces, semicolons etc.
- An abstract syntax tree contains additional data about the program, because of the continuous phases of compiler analysis. For instance, it might store the situation of every component in the source code, enabling the compiler to print helpful error and warning messages.
- Abstract syntax tree is less complex and contains fewer element compared to the parse tree.
The tool discussed in this thesis uses abstract syntax tree to analyze the source code for bad smell detection. In the initial phase of code smell detection, all the statistical data of the source code like the list of classes, methods, variables, etc. is collected and used in the later phase to detect bad smells.
AST Design
The design of abstract syntax tree is closely related to the design of a compiler [31]. Major requirements to design abstract syntax tree are: [31]
- The type of variables should be correctly represented, and the position of every variable declaration should be preserved in abstract syntax tree.
- The order of the statements to be executed should be well-preserved and defined correctly in the abstract syntax tree.
- Left and right components of binary or ternary operations must be saved and recognized correctly.
- Variables and their values must be saved for assignment statements.
- Unparsing of abstract syntax tree should result in the original code in terms of appearance and execution. Unparsing is term in compiler theory. Parsing is the process of converting the source code into abstract syntax tree and unparsing is the process of converting the abstract syntax tree to source code.
Figure 5.1 shows the general flow of abstract syntax tree. The source code is provided as an input in the form of java file. A character array containing code can also be passed as an input. In the next step, source code is parsed by ASTParser. ASTParser takes java source code as an input and parses it into abstract syntax tree. In the last step, the abstract syntax tree is modified, and the changes are written back with the help of IDocument, which is a java model element that can be used as a wrapper for the source code.
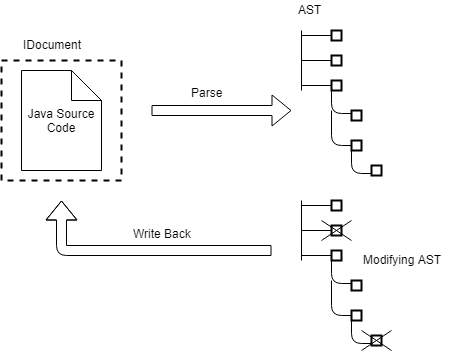
Figure 5.1 Flow of abstract syntax tree
Figure 5.2 shows a simple java code of a method which takes two parameters as an argument and returns an integer value which is the addition of the two parameters.

Figure 5.2 Code Snippet Example
Figure 5.3 depicts the abstract syntax tree representation of the code shown in figure 5.2. Figure 5.4 contains the Eclipse AST view of the same code. This hierarchy can be easily viewed in Eclipse IDE.
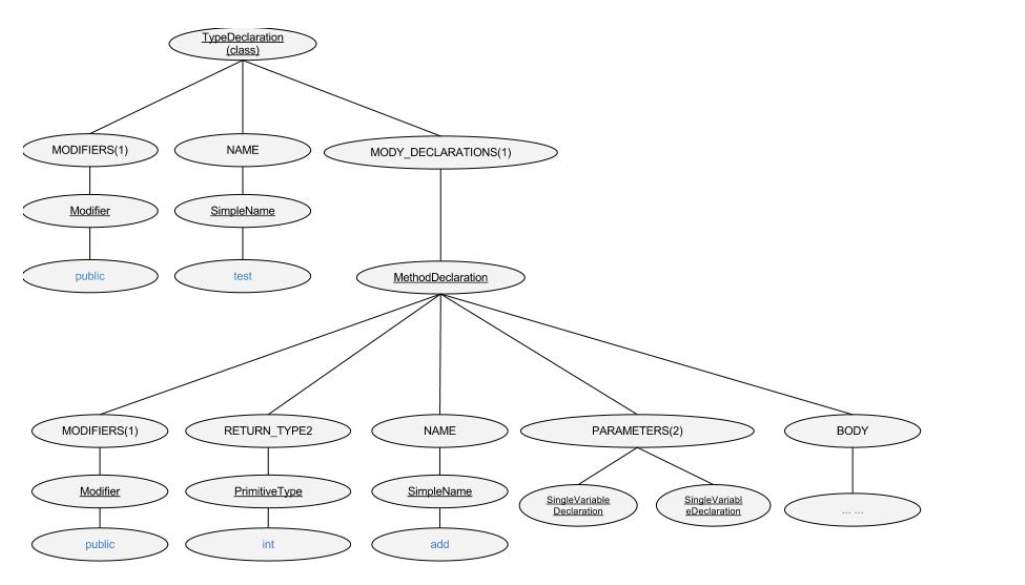
Figure 5.3 Abstract syntax tree
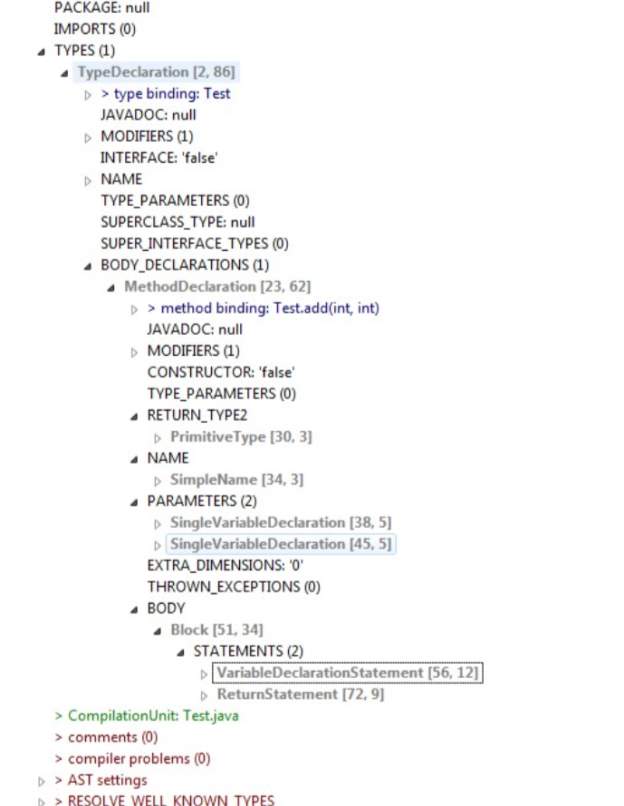
Figure 5.4 Eclipse ASTView
Generally, abstract syntax tree is created by parsing java source code instead of generating it from square one. ASTParser processes java files and created an abstract syntax tree. As shown in Figure 5.5, parse() method parses the source code stored in a file with filePath mentioned in fileName variable.
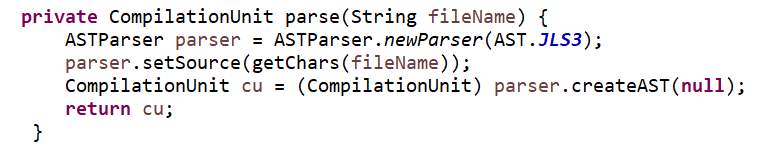
Figure 5.5 Parse() – method to convert source code into AST
In figure 5.5, ASTParser.newParser(AST.JSL3) instructs the parse to process the code which follows Java Language Specification, third edition (JSL3). All the new language specification launched in Java 5 are included in JSL3. The next step is to let the parser know that it should expect the input in the form of character array. It is done by parser.setSource(getChars(fileName) which converts the file stored at the location fileName into a character array and sets the source of the parser. In the last step, abstract syntax tree is generated and it is returned in the form of compilation unit. A compilation unit consists of a single java class definition.
In this thesis, the source code, which contains bad smells, is passed as an input and abstract syntax tree is generated. This tree is analyzed for bad smell detection. The analysis of AST and bad smell detection is discussed in next chapter.
CHAPTER 6 - CODE SMELL DETECTION
The process of code smell detection is very intricate. A detailed and vigilant analysis of the system is needed for effective detection of bad smells. It is relatively easier to detect smells in a small system. But as the system grows, the risks of making the design worse and breaking the code increase if an engineer is not careful. As a result, the necessity for the automatic detection of code smells increases. Code smells are identifiable in source code when one or more smell features are satisfied [3]. When all the features of a specific smell are found using static analysis of the code, that code smell can be identified. However, with the help of statistical data, detection of all the code smells is impractical [32].
In this thesis, source code in Java language is provided as input and the tool analyzes the source to detect the smells. There are seven smells detected in this approach. Those code smells are – Middle Man, Data Class, Temporary Field, Long Method, Switch Case, Message Chains and Long Parameter List. Detection and refactoring of all these smells is discussed in detail in the later section of this chapter.
Architecture
A general workflow of the approach used in this thesis for detection and refactoring of the smell is shown in figure 6.1.
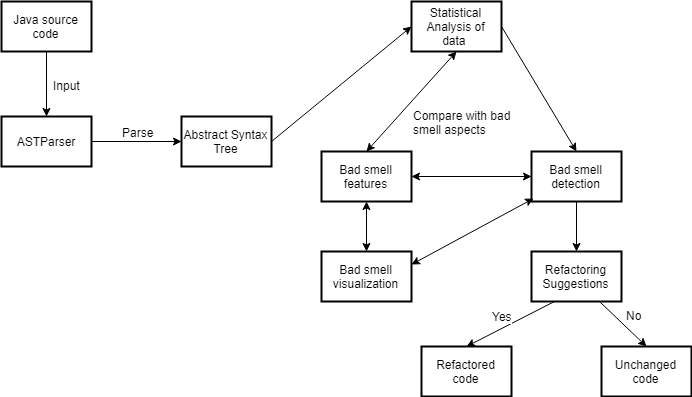
Figure 6.1 Architecture
Java source code is provided as an input which is parsed by ASTParser to the generate the abstract syntax tree. The process of code smell detection is carried out in three phases. In first phase,the ASTParser analyzes the source code and converts it into abstract syntax tree. In the second phase, the analyzer traverses the abstract syntax tree and gathers the statistical data. This statistical data is compared with the existing aspects of bad smells to check if that smell has occurred or not. In the last phase, bad smell is detected and visualized in the user interface (UI) and refactoring suggestions are provided for the detected smells.
The primary UI of the tool is shown in figure 6.2.
Figure 6.2 Main user interface
Middle Man
Problem
Middle man bad smell occurs when a method or a class passes most of its request to another class or method. A middle man is a class or a method which is not effectively contributing in the system.
Objective
Identify methods which contains middle man smell and suggest refactoring techniques.
Solution
- Traverse all the method declaration nodes in abstract syntax tree generated for the source code. Method declaration nodes in abstract syntax tree contains the method definition.
- Visit block node to get the method body.
- Verify if the statement in the method body is a return statement by traversing through the return statement node.
- If it is a return statement node, then check if the body of the return statement contains a method call or not by traversing through the method invocation node.
- Check if the node name of the method invocation node is present in the initially compiled list of methods.
- If the control returns true, then middle man smell is present in the code.
Refactoring
Apply ‘Remove middle man’ refactoring technique to remove middle man bad smell. This refactoring technique is discussed in detail in chapter 4.
Figure 6.3 shows the user interface for middle man code smell.

Figure 6.3 Middle man smell
Data Class
A class which contain only data fields and methods like getters and setters for accessing those data fields is called data class. Data class is generally a repository for data which is utilized by another class. These classes do not have any auxiliary usefulness and they cannot act on their own. It increases the coupling between the classes.
Objective
Check if the class contains data class bad smell. If it contains the smell, then suggest refactoring solutions.
Solution
- Traverse through the method declaration node in abstract syntax tree.
- Block node in the tree contains the method body. Visit the block node. Calculate the number of lines of the method.
- Traverse through the return statement node to verify if it is present of not. If it is present, subtract one from the previously calculated number of lines.
- To count the number of variables declared, visit variable declaration node. Subtract the number of variable declarations from the number of lines.
- Traverse through the expression node. Visit assignment node. Calculate the total number of visited assignment nodes and subtract it from number of lines.
- If the number of lines is greater than zero, then the data class smell exists.
Refactoring
Use move method refactoring technique to move the getter and setter methods to the class which uses these methods. If the whole method cannot be moved to another class, then use extract method to extract the getter and setter part of the method and then move the extracted method to another class which uses it.
Figure 6.4 shows the user interface for Data class bad smell.
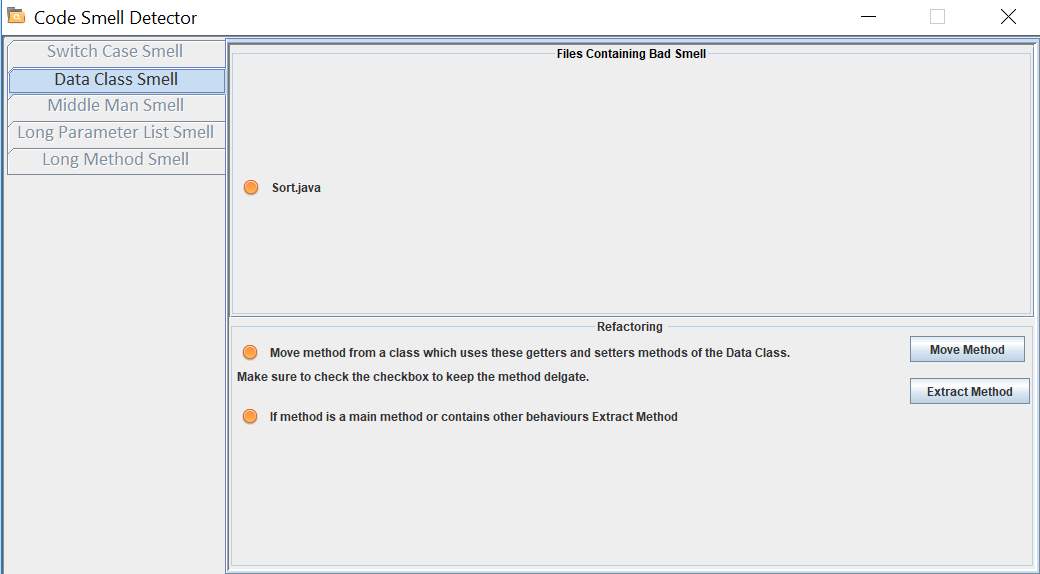
Figure 6.4 Data Class smell
Temporary Field
Temporary field bad smell occurs when certain variables get their value only in particular circumstances. This happens when these variables are used only in a method. So, variables get their values only when a method is called. In all the other cases, these variables remain empty.
Objective
Detect if the class contains temporary field bad smell. Suggest refactoring solutions for it.
Solution
- Traverse through the method declaration node in the abstract syntax tree.
- Access the body of the method by visiting the block node.
- Visit the assignment node by traversing through expression node.
- Check if the right hand of the assignment contains a method call by visiting the method invocation node. Increase the counter by one.
- Perform above step for every assignment node visited.
- If the counter is greater than two, then there is temporary field bad smell present.
Refactoring
Use extract method refactoring to extract the part of the code which contains temporary fields smell. If the temporary fields are used in conditions, then use introduce null object refactoring to remove the temporary fields and directly call the method in conditions.
Long Method
A method, procedure or function which contains too many lines of code is considered to be ‘Long Method’. When a method is too long, it uses large number of variables and performs multiple operations and it is more plausible that the method does more than what its name suggests. When a method is small in size, understandability and maintainability of the code increases.
Objective
Check if the method is too long and contains long method bad smell. Suggest refactoring techniques to remove the smell.
Refactoring
- Traverse through the method declaration node in abstract syntax tree.
- In order to access the body of the method, visit block node. Count the number of lines in the method.
- If the method contains while loop or for loop, repeat step above step.
- If the number of lines is more than fourteen, then long method bad smell is present.
Figure 6.5 shows the user interface for long method bad smell.
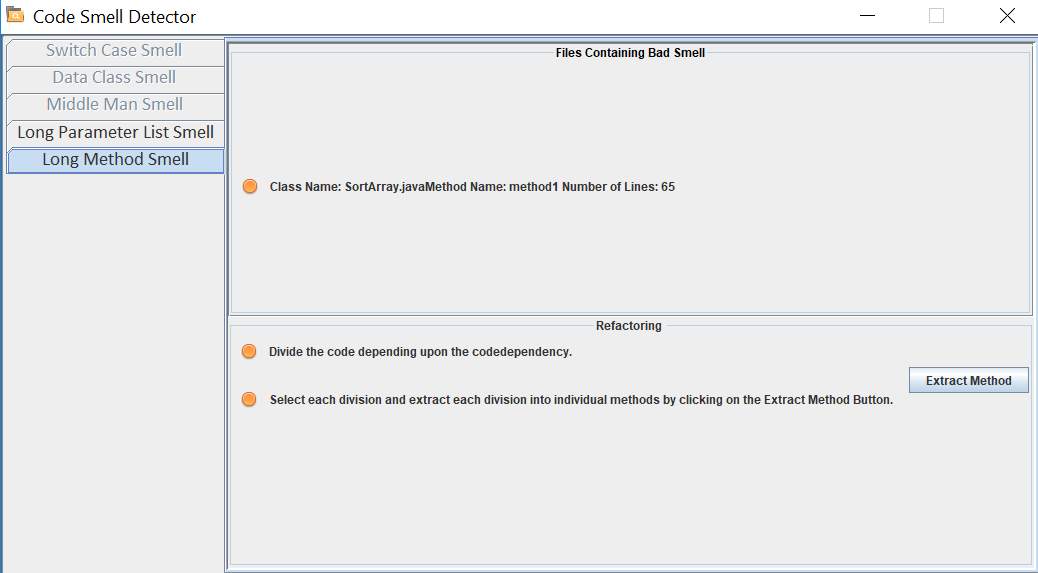
Figure 6.5 Long Method smell
Switch Case
A good case of object-oriented programming indicates less usage of switch cases. Generally, there are many switch cases across the code when a single case is added to satisfy all conditions. When a new condition is added, all the switch cases across the code needs modification.
Objective
Check if there are any switch statements in the method. Suggest refactoring techniques of switch case smell is detected.
Solution
- Traverse through the switch statement node in the method in abstract syntax tree. Calculate the number of times switch statement node is visited.
- For every switch statement node visited, traverse through the simple name node to access the name of the switch statement. Store the name.
- If switch statement node is visited more than three times, switch case smell is present in the code.
Figure 6.6 represents the user interface for switch case bad smell.

Figure 6.6 Switch Case smell
Message Chains
When a class has very high coupling with other classes in the form of chain, message chain bad smell occurs. A message chain occurs when an object of one class calls object of another class which in turn calls object of another class and so on. Due to high coupling, main class require changes when the intermediate classes are changed.
Objective
Detect message chain in the methods of the source code. If the smell is present, provide refactoring suggestions.
Solution
- Traverse all the method declaration nodes in abstract syntax tree generated for the source code. Method declaration nodes in abstract syntax tree contains the method definition.
- Visit block node to get the method body.
- Verify if the statement in the method body is a return statement by traversing through the return statement node.
- If it is a return statement node, then check if the body of the return statement contains a method call or not by traversing through the method invocation node.
- Check if the node name of the method invocation node is present in the initially compiled list of methods.
- If the control returns true, then message chain smell is present in the code.
Refactoring
Use hide delegates refactoring technique to delete the delegating part of code and directly call the end method. Other option is to use the extract method refactoring to extract the end method in the chain and put the extracted code in the main method to remove the chain.
Long Parameter List
When more than three or four parameters are passed as an argument to a method, long parameter list bad smell occurs. When there is a need for additional data in the method, object can be used instead of passing that data as an argument. A long list of parameters is hard to understand and it becomes harder to maintain as it increases in size.
Objective
Detect long parameter list smell in a method and suggest refactoring techniques.
Solution
- Traverse through the method declaration block of the abstract syntax tree.
- Traverse through the single variable declaration node from method declaration node. Single variable declaration node points to the parameters in the method definition.
- Count the number of times single variable declaration node is visited.
- If the number of parameters is greater than four, the method has long parameter list bad smell.
Refactoring
If the parameters can be substituted by a method call, use replace parameter with method refactoring technique.
Figure 6.7 shows the user interface for long parameter list bad smell.
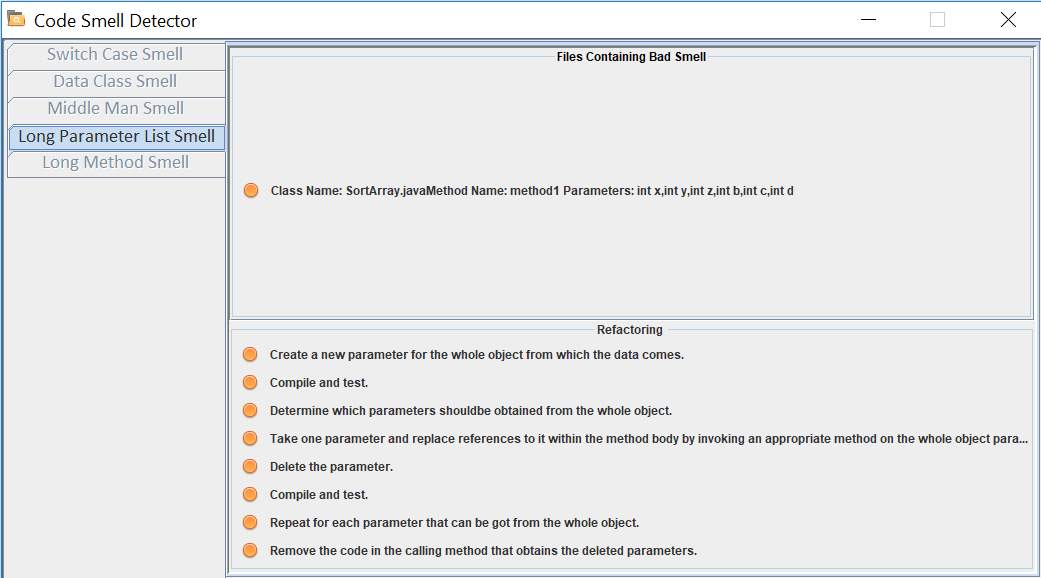
Figure 6.7 Long Parameter List bad smell
CHAPTER 7 - CONCLUSION AND FUTURE WORK
Past work has presented numerous methodologies to refactor the code to make it more readable. Few pieces of research specified the contemplations of consolidating code smells detection with refactoring but none of them has a ready-to-use implementation. Many engineers depend on the metric only to recognize code smells.
In this thesis, it is demonstrated that statistical analysis of the data along with metrics help to detect the code smells with more accuracy. We proposed and built a framework that identifies seven different code smells and suggests refactoring solutions for those bad smells. At last, this thesis has contributed:
- a methodology to gather data, by utilizing abstract syntax tree, for statistical analysis.
- algorithms to recognize each code smell discussed in this thesis.
- connections between code smells and refactoring techniques.
Issues that are still open for future research includes:
- Analysis can be carried out for the bad smells that are not discussed in this thesis.
- Currently, the refactoring solutions provided in this approach are semi-manual. Refactoring can be automatized for all the identified smells.
- Also, the graphical user interface can be made more interactive and user-friendly.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Computer Science"
Computer science is the study of computer systems, computing technologies, data, data structures and algorithms. Computer science provides essential skills and knowledge for a wide range of computing and computer-related professions.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: