Dissertation on Was/Were Language Variation in Lancashire
Info: 16577 words (66 pages) Dissertation
Published: 15th Nov 2021
Tagged: LanguagesLinguistics
Abstract
This study examines was/were variation in Lancashire. A variationist approach is taken to investigate how the nonstandard variants are conditioned and whether this has changed over time. The primary purpose of this is to investigate whether Lancashire data uses nonstandard was more than nonstandard were and therefore supports Chambers (2004) posit of was-levelling becoming a vernacular of English. Data from two time settings roughly two generations apart have been used to gain a diachronic view of these variables. This allowed examination into whether Lancashire speakers are moving away from the traditionally Northern nonstandard were and using the nonstandard was at a higher rate instead. Overall, results questioned whether English is moving towards a ‘default singular’ vernacular as Lancashire are found to still favour the nonstandard were. However, some important changes in the conditioning of nonstandard variants are found to have taken place over time, suggesting the way these variants are used has undergone significant change.
Click to expand Table of Contents
Contents
1. Introduction………………………………………………………………………………..1
2. Literature Review…………………………………………………………………..……..4
3. Methods…………………………………………………………………………….……14
3.1 The Data……………………………………………………………………….…….14
3.1.1 British National Corpus (BNC)………………………………………….……15
3.1.2 Freiburg English Dialect Corpus (FRED)…………………………………….15
3.2 The Variables………………………………………………………………………..16
3.3 The Speech Community…………………………………………………………..…19
4. Results……………………………………………………………………………………20
4.1 Distributional Analysis……………………………………………………………….20
4.2 Multivariate Analysis…………………………………………………………………27
4.2.1 Were used in standard contexts of was……………………………………….28
4.2.2 Was used in standard context of were…………………………………………31
5. Discussion…………………………………………………………………………….…35
6. Conclusion…………………………………………………………………………….…46
References……………………………………………………………………………….…48
List of Figures
Figure 1: Dialect map of past tense BE across the UK by Ellis (1889)
Figure 2: Map to show the county of Lancashire (taken from google maps)
Figure 3: Graph to show the rates of both nonstandard was and were across corpora
Figure 4: Graphic representation of cross-tabulation between gender and corpus
Figure 5: Graphic representation of cross-tabulation between polarity and gender
Figure 6: Graphic representation of cross-tabulation between noun phrase head and gender
Figure 7:Graphic representation of cross tabulation of pronoun and corporawith nonstandard were
Figure 8: Graphic representation of cross-tabulation between pronoun type and corpora with nonstandard was
List of Tables
Table 1: Standard paradigm of past tense verb BE
Table 2: A table to show distribution of informants across social factors
Table 3: Table to show factor by factor results of both nonstandard was and were by corpora
Table 4: Multivariate analysis results for nonstandard were
Table 5: Multivariate analysis for nonstandard was
1. Introduction
You was with me (BNC 2007) is not an uncommon expression to hear in dialects within the English Language. Hearing this utterance may not sound unusual to many English speakers, however, grammatically, it is nonstandard. This is due to the subject, you, not agreeing with the verb, past tense be. The term for this is was-levelling. However, within the dialects in the Northern regions of the UK, nonstandard phrases like it were early in the year (BNC 2007) may also be commonly heard. This example illustrates were-levelling, where were is used in a standard was position. The presence of both these generalisations has led to past tense to be being labelled as a ‘badly mixed up verb’ (Pyles and Algeo 1993:127). Therefore, research has been extensively undertaken to examine what conditions these nonstandard occurrences.
Historically, were-levelling has been found to be more common than was-levelling, particularly in the North (Ellis 1889). More recent research, however, suggests that rates of was-levelling are surpassing were-levelling. A Survey of British English Grammar, in 1989, (Cheshire, Edwards and Whittles) revealed that rates of nonstandard was had increased dramatically since Ellis’s findings one century earlier. This rise in was-levelling has led Chambers (2004) to claim levelling to was is becoming a universal vernacular of English. However, this creates some tension: was-levelling is a vernacular universal, in the North were-levelling is common. Does this mean was and were levelling coexist at high levels in the North? If so, what conditions was-levelling and what conditions were-levelling? Britain (2002) identifies a pattern which perhaps begins to explain this. He found that, in The Fens, was-levelling is present but in positive polarity and were-levelling occurs with negative polarity. Chambers (2004) explains this by suggesting that it is from the ‘default singular’ that this pattern arises. Thus, suggesting as levels of was-levelling increase, were-levelling is restricted to negative polarity.
Therefore, this paper aims to investigate was/were variation within the county of Lancashire to further research into the patterning of the nonstandard variants. This will be done with a slightly different approach to previous studies in this field. It will be a diachronic study, focusing on how the patterning of was/were variation has changed over time in this area. The purpose of this is to put particular emphasis on Chambers (2004) posit of the ‘default singular’ becoming a vernacular universal and thus examining if Lancashire are indeed progressing towards categorical use of generalised was. To do so in a Northern region is particularly interesting due to past research that shows nonstandard were is overtly common here (Ellis 1889). Furthermore, it has already been recognised that Lancashire, in particular, favours generalised were forms (Pietsch 2005). Therefore, if this is no longer the case, this provides stronger evidence for Chambers theory than research in a Southern area, which has always been less likely to use nonstandard were.
If Chambers (2004) is correct, I should find a significant rise in the use of was-levelling in Lancashire and thus a decrease in the use of were-levelling over time. Consequently, I hypothesise that there will be a higher rate of generalised was in the more recent data than the old. I will also find, as Chamber’s predicts, expect to find some evidence of Britain’s (2002) pattern emerging out of the increased use of the ‘default singular’. Thus, I will find generalised were being restricted to negative polarity. This will further research into which nonstandard pattern, if any, is becoming a vernacular universal of English. Furthermore, this could give us some level of insight into the direction in which this variable is headed as the most recent data will no means show the end points of this linguistic change.
I aim to achieve this through conducting variation analysis on two Lancashire corpora, roughly two generations apart. By comparing older data with more modern data, I will gain a diachronic picture of was/were variation and how the conditioning of the nonstandard has changed. By looking at the overall rates of use of nonstandard were and use of nonstandard was, I will see which is favoured in Lancashire and therefore be able to support or disprove my hypothesis and therefore, Chambers (2004) ideas of vernacular English. I will pay particular attention to polarity as an independent variable here in order to examine whether Britain’s (2002) pattern is evident in the data. I will then be able to make evaluations on whether the default singular is vernacular in Lancashire or if there is a different patterning emerging. Furthermore, this will develop previous research surrounding what conditions the nonstandard past tense BE forms as this research has never been conducted in this area.
2. Literature Review
This chapter will provide an overview on the existing body of literature surrounding the past tense BE paradigm. It will begin by outlining the standard and nonstandard forms before progressing onto providing a comprehensive insight into previous studies conducted on how these variants are used in areas across the UK. I will draw out the main results from previous works in order to give an overview on what has been found most important in conditioning the nonstandard form. Furthermore, I will link these studies to the existing theories surrounding the ‘vernacular universal’ titles given to was-generalisation.
To understand variation, the standard form must first be addressed. The standard paradigm is presented below.
| Singular | Plural | |
| First person | Was | Were |
| Second person | Were | Were |
| Third person | Was | Were |
Table 1: Standard paradigm of past tense verb BE
Following this creates constructions such as:
1. a) I was going to the park
b) He was going to the park
Thus, in Standard English, was is only used with the past tense form of BE when occurring with singular forms (he/she/it), excluding the second person you (even when referring to a singular person). Were is then used for all plural forms and second person singular you.
2. a) You were going to the park
b) We were going to the park
c) They were going to the park
Thus, was/were highlights a plural/singular distinction with the noun phrase head. Therefore, if the noun phrase head were to be a noun, instead of a pronoun, examples such as found in (3) will be derived.
3. a) The book was on the shelf
b) The books were on the shelf
However, an increasing number of studies are finding high levels of was/were generalisation in vernacular speech. This means was has been found to occur with plural noun phrase heads and were with singular noun phrase heads e.g.
4. a) He were a bit unhappy
b) You was there the other day
This process can be termed as levelling, defined by Britain (2002) as ‘where the number of variants in the output is dramatically reduced from the number in the input’. Thus, if a speaker uses was for both singular and plural noun phrase heads, the standard two variants, was and were, converge to just one, was. Chambers (2004) has coined this example as the ‘default singular’.
Evidence of generalisation to were has also been found. Ellis’ (1889) map in Figure 1 shows that patterns of nonstandard were are more prominent in the North as depicted by the cluster of stars in the North/North West regions. In fact, all over the UK, this pattern is much more prominent than the nonstandard was. It is also notable that there are no findings of was in contexts of standard were in these Northern regions but these patterns are found sparsely in the South. Instances of weren’t in contexts of standard wasn’t are also not found in a great number of areas across the UK. Furthermore, where they are found are all more Southern regions rather than Northern. Thus, interestingly, Ellis’ (1889) findings suggest a general convergence towards were was taking place in 1889. It also shows that this is primarily a feature of Northern speech.
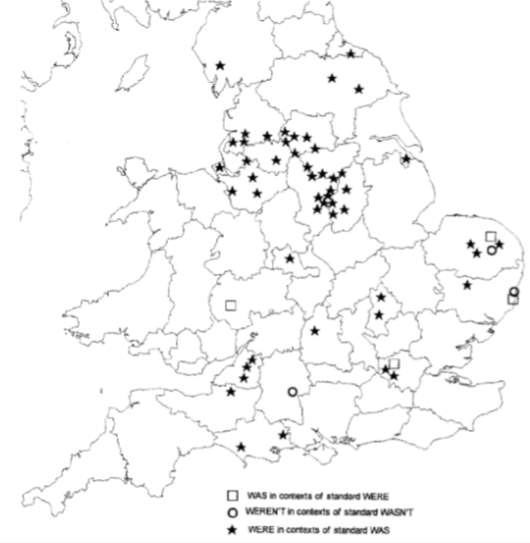
Figure 1: Dialect map of past tense BE across the UK by Ellis (1889)
Cheshire, Edwards and Whittles (1989) Survey of British Dialect Grammar, reported that 80% of the responses from their questionnaire presented nonstandard was. This was found across the country, unlike, 100 years previously, in Ellis’ (1889) findings where it was found predominantly in the South. This shows a rise in nonstandard was over this time period. However, nonstandard were was still found at a higher rate in Northern areas confirming Ellis’s findings and showing it still remained a feature of Northern speech. Comparison of these two studies shows us that the nonstandard was has increased over time, spreading geographically. Whereas, nonstandard were remains to be predominant in the North although still existing at a lower rate in the South. Nonstandard were with negative polarity, or nonstandard weren’t, was found in the later study to be frequent in the North and Glasgow. This shows a development from Figure 1 which showed this pattern to be infrequent in the North. The Survey of British Dialect Grammar also revealed that, in some areas, nonstandard weren’t was reported but not nonstandard were. Thus, showing that in some areas nonstandard were is strictly conditioned to negative polarity.
The more modern findings of Chambers (2004) suggest a general levelling towards was. Chambers posits this as the ‘default singular’, which he argues is a vernacular universal of English. The ‘default singular’ has been identified as was occurring variably for the standard were in both negative (5a) and affirmative (5b) contexts. This shall be referred to as pattern one.
(5) a. They wasn’t allowed to come
b. You was there last week
Adgar and Smith (2005:155) concur with Chambers, stating that ‘one of the most common features of vernacular dialects’ is the nonstandard was. This literature suggests that English, even in the North of the UK, are moving away from the generalised were and using higher rates of the generalised was.
Findings in Shetland English (Durham 2013) support Chambers (2004) ‘default singular’ being labelled a vernacular universal. In this study, the factor of age was found to be particularly important in conditioning the variants. Use of the nonstandard was increases considerably in younger generations in the study and nonstandard were is found to decrease. This is particular prominent when focusing on the context of existentials. Nonstandard were in the context of singular existentials was found to be never used by young speakers whereas older speakers were found to use it at a rate of 53% (Durham 2013). On the other hand, nonstandard was in contexts of plural existentials was found to be used at a near categorical rate of 93% by young speakers and only 24% in old speakers. These results show that the use of nonstandard was has increased considerably in younger speakers. This age effect suggests that the rates of nonstandard was will continue to increase in later generations and thus was and were will converge into one form.
In Buckie English, a dialect spoken in the north-east of Scotland, Smith & Tagliamonte (1998) also found an overall tendency for levelling towards was rather than were. They observed the overall frequency of was in contexts of standard were to be 58%. These studies suggest, as Chambers (2004) posits, that the default singular is moving towards becoming a vernacular of English as it is clear that, in Shetland English, there is a convergence to the one was form with regards to past tense BE. Furthermore, this evidence suggests a divergence from the nonstandard were which was heavily present in Ellis’ (1889) findings.
However, Britain (2002) describes a second pattern, in which was levelling occurs with positive polarity (6a) and were levelling with negative polarity (6b). This develops the results from the Survey of British Dialect Grammar (1989) as described above which suggested the emergence of this pattern. This is ‘pattern two’.
(6) a. The kids was going to the shop
b. He weren’t alright that night
(6a) exemplifies was levelling with positive polarity: the subject is a plural noun phrase and therefore does not agree with the singular verb form. On the other hand, in (6b) nonstandard were is demonstrated: the subject is singular but the verb form is plural. Here, the verb form is negated: contracted with the negative particle ‘not’. Thus, in other words, this pattern proposed by Britain (2002) suggests that nonstandard was is used in affirmative contexts, or positive polarity, and nonstandard were is used with negative polarity. Britain (2002) formed pattern two from his findings in The Fens. Here, he found use of nonstandard was in affirmative contexts was increasing amongst young speakers and weren’t in negative contexts was found to be used ‘almost exclusively’ (Britain 2002: 2). Chambers (2004) explicitly rejects this pattern when referring to the ‘default singular’ and focuses primarily on nonstandard was. He does, however, predict that we will find evidence of this pattern emerging out of the ‘default singular’. This suggest that vernacular dialects will show a tendency to the generalised was and then emerge to use the generalised were in the restricted context of negative polarity. Despite evidence of this pattern in many dialects (Tagliamonte 1998; Cheshire & Fox 2008; Durham 2003), Chambers still prioritises nonstandard was as a vernacular over this other possibility.
For example, in York, Tagliamonte (1998) found an overall tendency for non-standard levelling towards was rather than were in affirmative contexts. Her data set conspiciously displayed pattern two (6), with her results concluding a high rate in use of non-standard was and an increase in the non-standard weren’t. Particularly, rates of nonstandard were was highest in negative tag questions with it, such as ‘weren’t it?’ Interestingly, Tagliamonte (1998) notes the increase in use of this construction is particularly prominent among women. It is generally understood that women deviate more from linguistic norms when the deviations carry covert prestige (Labov 2001), thus suggesting that this may be the case in York. Women leading the change suggests that there is no social stigma attached to the nonstandard here in York. Furthermore, this gender effect shows us that this variable is not yet in stable sociolinguistic stratification as, in these cases, it would be the men using the nonstandard form at higher rate than women (Labov 2001). Thus, the nonstandard were in negative constructions carrying no social stigma lends evidence to suggestions that’s its use will continue to rise as it will not be inhibited by a stigma leading certain speakers to diverge from its use. The females high rate of use suggests that, in fact, the variant may carry some covert prestige (Labov 2001) and thus, this will facilitate its rise in use. Therefore, this study suggests that pattern two’s presence in dialects will continue to rise with help from carrying a covert prestige and therefore may be the predominant patterning in vernacular dialects.
In London (Cheshire & Fox 2008), nonstandard were was never found in positive contexts whereas the rate of non-standard was in inner London adolescents was 58% and 42% in outer London adolescents. This supports Chambers (2004) suggestion of the ‘default singular’ becoming a vernacular of English as the two forms of past tense to be are converging to one.However, this is complicated by their other findings that show an increase in non-standard were with a negative particle as this exemplifies pattern two and shows that total convergence to was is not occurring as non-standard were is on the rise in this negative context. A 69% rate of non-standard weren’t found in outer London adolescents. But also, similar to in York, tag questions is a favouring environment for the non-standard weren’t as older speakers in this study were found to only use it in this context. Negative tag questions represent 11% of all instances of nonstandard weren’t in inner city speakers and 30% in outer city speakers. Across all older speakers in the study, negated tag questions was the only context that nonstandard weren’t was found in. Younger speakers using the nonstandard were in more contexts than the older speakers suggests it is a growing variant and, thus, Chambers is not accurate in suggesting convergence to just the was variant as another non-standard variant is on the rise. Furthermore, women were found to be leading the levelling in London too, much like York. Thus, we can again presume that there is no social stigma to the nonstandard variants in this region. This supports the idea of the nonstandard becoming a vernacular of English as without stigmatization, it is more likely to become the norm. Thus, these studies show Chambers (2004) was correct in predicting the emergence of Britain’s (2002) pattern from the ‘default singular’.
However, even acknowledgement of this alternative regularisation possibility, Chambers (2004) still fails to acknowledge the third possibility: favouring towards the generalised were despite evidence of it still being widely used. Furthermore, these studies raise the question as to why it is just the nonstandard was being deemed a vernacular universal when nonstandard were is clearly still widely used, even if so in a restricted context. Chambers (2001) outlined ‘vernacular universals’ to denote nonstandard features that are recurrently used across English. Therefore, if there is evidence for were generalisation still being widely used across English, should this not be deemed a ‘vernacular universal’ also?
Moore (2010) has found evidence in Bolton, to support that nonstandard were in contexts of positive polarity is still a predominant variant. She found it occurring in Bolton at a rate of 17%, compared to the just 3% found in Tagliamonte’s (1998) study of York. In fact, Moore (2010) found no real evidence for levelled was in the Bolton dialect. She found that the nonstandard was does occur but only in the restricted context of existential clauses: a context in which variation occurs even in standardised varieties of English and thus not providing strong evidence of the existence of an overall was-levelling occurring in Bolton. Due to, as Shnukal (1978) states, nonstandard was in this context not being as stigmatised as it is when occurring in other contexts. Furthermore, Moore (2010) argues that the stability of nonstandard were in Bolton may be due to its use of a symbol of localness. Thus, as Bolton was considered a Lancashire town until 1974, it will be interesting to see if I find similar results in my study of the wider area of Lancashire. Her findings suggest that the non-standard were is used as a reflection of social group as the ‘townies’, the girls who spent the most time in the local area, have the highest rate of the variant. Thus, overall, Moore’s (2010) finding in Bolton contradicts Chambers (2004) suggestion of a general levelling towards was as the nonstandard were variant is still very much in use. This contributes to my argument that it is both generalisation to was and were that should be deemed a vernacular universal. It also presents my study with the question of whether this nonstandard were variant is also present in other areas of the North West, such as Lancashire, or whether this is an isolated feature of the Bolton community.
I will therefore use my study of Lancashire, to not only examine what conditions the nonstandard variants here, but to further research that questions Chamber’s (2004) posit of the default singular becoming a vernacular of English. If Chambers suggestion is correct then, in my study, I can expect to find a higher rate of the non-standard was in the more recent data and less in the older data as this would show Lancashire speakers moving away from nonstandard were and towards the nonstandard was. Furthermore, I may expect to find a higher rate of non-standard were in my older speakers as this is the typically Northern variant and, historically, more common than the nonstandard was (Ellis 1889). This would be much like the findings in Shetland English (Durham 2013). Therefore, it would agree with Chambers posit of the ‘default singular’ and his general understanding that was being used in contexts of standard were is becoming increasingly popular and even now a vernacular universal. However, research into various specific areas of the UK, such as York and London, suggest that the undergoing levelling process is more complex than simply the two forms converging into one. Existing research shows that polarity plays a really important role in this process, thus meaning was-levelling occurs in affirmative contexts but it is were-levelling which occurs in negative polarity. Therefore, I will examine what conditions the nonstandard was and nonstandard were in Lancashire. This will involve investigating whether polarity, as in other dialects, is the most important factor or if other variables are more important. Thus, this paper will present a study of Lancashire in order to contribute to the existing body of literature on this variable in order to find what conditions was and were-levelling in Lancashire dialect and question Chambers (2004) ‘default singular’ vernacular universal. To be clear, the research questions for this paper are the following:
- What conditions the nonstandard was and nonstandard were in Lancashire speech? How has this changed over time?
- Is there evidence that rates of was-levelling are surpassing were-levelling in Lancashire therefore supporting Chambers (2004) default singular?
3. Methods
This section will outline the data and methodology used in to conduct my research. I will begin by describing my dataset and how it was collected. I will then describe the dependent and independent variables in the study and give examples of each. Finally, I will give a bit of information on the area covered, Lancashire, in order to clear up where, and who, this area covers.
3.1 The data
The data for this study has come from two corpora from different time periods: the British National Corpus (BNC) and the Freiburg English Dialect Corpus (FRED). There is roughly a 40 years gap between the oldest speakers in BNC and the oldest speakers in FRED. Therefore, the use of these corpora combined allows for a diachronic view of was/were levelling in Lancashire and how the conditioning of the nonstandard variants has changed over nearly two generation. Furthermore, another benefit of using two corpora is simply access to more data and therefore a wider view of the variable. The broader implications of using both corpora is that it aids predictions into the direction in which the variable is heading. Thus, aiding in either supporting Chambers (2004) posit of the default singular as being a vernacular of English or suggesting the variants behave differently to how he suggests.
Therefore, the dataset used in this study is a subsample from both corpora combined. Overall, this subsample consists of 36 speakers: 12 from FRED and 24 from BNC. The speakers range from 14-93 and all of them are speakers of the Lancashire dialect. The oldest speaker in my dataset was born in 1877. Table 1 shows the distribution of participants amongst these age groupings and gender. One male speaker from the BNC corpus is listed as ‘unknown’ and therefore he is unaccounted for in this table leaving the total 35 rather than 36.
| Male | Female | Total | |
| Young | 15 | 20 | 25 |
| Old | 9 | 11 | 20 |
| Total | 24 | 31 | 35 |
Table 2: A table of distribution of informants across social factors
3.1.1 British National Corpus (BNC)
The BNC is made up of 124 informants in total. These informants were chosen to ensure equal distribution across age, gender and social grouping. Informants used a personal stereo to record all their conversations over the time period of two or three days and were asked to log details of each conversation e.g. age, gender, accent and occupation. This data was collected in the 1990’s. Roughly, informants were born between 1930 and 1980. 1588 tokens of was and were are used in this study from the BNC.
3.1.2 Freiburg Corpus of English Dialects (FRED)
FRED consists of 370 texts, which total 2.5 million words or 300 hours of speech. Lancashire dialect speakers contribute to 7.8% of the overall spoken corpora. The average age of participants from the FRED data is 63. The data was collected through transcribed interviews during the 1970s and 1980s. Most participants in this corpus were born between 1890 and 1920. There are 12 participants used from the FRED corpus in this study. 3038 tokens of was and were were returned from these informants.
3.2 The variables
The dependant variable in this study is whether the token was or were is standard or nonstandard. This is a binary variable with two levels. A nonstandard was is where was is used in the context of a standard were. A nonstandard were is where were is used in the context of a standard was. To be clear, throughout this paper the terms ‘nonstandard were’ and ‘nonstandard was’ will be used to refer to these instances. Once all the tokens of both was and were from both BNC and FRED were compiled, they were coded for the independent variables. This section will explain each variable and give an example of each from the data used.
The external factors are age and gender. For gender, this is a binary factor: male or female. As the age data provided by each corpus was different: FRED given in specific age and BNC given in age groups, a new age grouping needed to be made. Thus, another binary factor was created: ‘old’ and ‘young’. The ‘old’ group consists of speakers 60 years of age and over and the ‘young’ group consisted of those under 60 years. This grouping was decided to allow fair distribution of participants amongst groups. However, the corpus variable itself will be a better indicator of age in this study. Corpus creates another binary independent variable: either BNC or FRED.
The internal factors in this study were decided on based on findings from the previous studies discussed in Section 2. All these variables are binary with two levels. Tag questions, as illustrated in (7), were found a significant predictor of the nonstandard were in both York (Tagliamonte 1998) and London (Cheshire and Fox 2008). Therefore, I felt this a valuable variable to be coded for in this study.
(7) a. They were in that top cupboard, weren’t they? (BNC KSS)
b. That was a silly question, wasn’t it? (BNC KBP)
Thus, it was felt necessary to investigate whether other question types had an effect on the conditioning of the nonstandard. Therefore, WH-questions (8) were also coded for as an independent variable. Some previous studies (Cheshire and Fox 2008) did not separate this question type in clausal analysis. However, I chose to investigate these as Moore (2010) did find an effect of this question type on were-levelling in Bolton. As Bolton is close geographically, I felt like this could mean it has an impact in Lancashire too.
(8) a. What was the other thing? (BNC KDW)
b. What werethey singing? (BNC KDW)
The last question type explored in this study is regular, yes/no questions (9). I chose to include this predictor as it has been found to have high rates of the nonstandard in Moore’s (2010) study of Bolton, a study close to Lancashire.
(9) a. Was she on her own? (BNC KB9)
b. Weren’t it a good cake? (BNC KBC)
As explored in section 2, in some studies (Tagliamonte 1998; Cheshire and Fox 2008), polarity has been found the most significant predictor of the nonstandard, particularly in conditioning the nonstandard were. Thus, it was pivotal that coding for affirmative and negative contexts was done. The two levels to this binary variable are negative and affirmative. This was also an essential variable in exploring whether Britain’s (2002) pattern is present in Lancashire speech. Example (10) illustrates the standard was and were in contexts of negative polarity. Example (11) illustrates the standard forms in positive polarity.
(10) a. They weren’t there yesterday (BNC KB9)
b. She wasn’t involving me at all (BNC KBC)
(11) a. It was on good authority (BNC KB0)
b. We were just pulling away (BNC KB9)
Lastly, noun phrase head type was coded for. Pronoun or noun are the two levels for this factor. This corresponds to whether the head of the utterance in which was/were is used is a pronoun or a noun. Example (12) demonstrates both was and were occurring in utterances with a pronoun noun phrase head and example (13) demonstrates was/were with nouns in the head of the utterance. As Lancashire is a Northern county, we may expect the Northern Subject Rule to be followed here, and thus was will appear with nouns in the head more than pronouns.
(12) a. I was born in Lancashire (BNC KB0)
b. I thought you were going in Friday (BNC KB9)
(13) a. Carolyn was working at Witham (BNC KBP)
b. Joan and Clive were saying they did them (BNC KBP)
In the distributional analysis, the rate of the nonstandard in each of the conditions will be explored in order to see which are the best predictors of the nonstandard forms. In multivariate analysis, all will be entered into a regression in order to predict, controlling for all variables, which corpus has the higher probability of the nonstandard.
3.3 Lancashire
As this study pays particular interest to Lancashire being in the Northern region, it is useful to outline what areas the county covers. Lancashire is a county in the North-west of England. Figure 2 shows which cities are covered by the county of Lancashire. Its population is 1,191,700 and the area covers 2,903 km2 (Lancashire County Council 2017). It neighbours Yorkshire and Manchester. Therefore, my study will have particular interest in Tagliamonte’s (1998) study of York to see if the patterning of the variable are similar in the two geographically close locations. Also, this means Moore’s (2010) study of Bolton will be of particular interest as Bolton once was a Lancashire town.
Figure 2: Map to show the county of Lancashire (sourced from Google Maps)
4. Results
This chapter will report the results from analysis undertaken on the dataset. Distributional analysis (4.1) will be key in answering my first research question: what conditions the nonstandard and how this has changed over time. Thus, analysis in this section will be done with the data divided by corpora and by variant. Multivariate analysis (4.2) will be important in confirming what conditions the nonstandard but most importantly, it will answer my second research question: is it were-levelling or was-levelling that is favoured in this Lancashire dataset and which corpus the nonstandard is favoured by. Thus, this section will be done with the data divided only by variant (was vs were).
4.1 Distributional analysis
In this section, distributional analysis of both nonstandard was and were will be reported. Primarily, cross tabulations will be applied to the data. The aim of this analysis is to examine the differences between corpora in the conditioning of the nonstandard was and were. Between-corpus analysis allows for an insight into how behaviour of these variants has changed over time.
Preliminary results show that predictions made relating to the nonstandard were have been supported: there is significantly more use of nonstandard were in the FRED corpus than in the BNC corpus. This shows that the use of were-levelling has decreased over time in Lancashire. There is a significant difference of 13% (X²(1, N=1653) = 26, p was is also used more in the FRED corpus than the BNC. Therefore, use of was-levelling has also decreased over time. However, this difference is smaller at just 6%. Thus, the rates of were-levelling have decreased more rapidly than was-levelling.
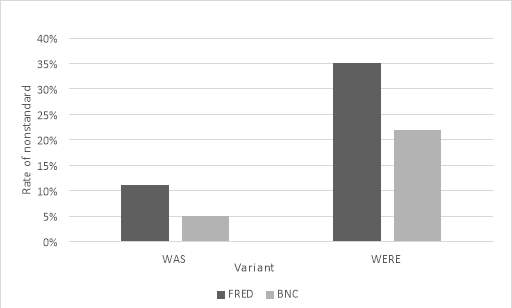
Figure 3: Graph to show the rates of both nonstandard was and were across corpora
Overall, Figure 3 shows that rates of both nonstandard variants are reasonably low in Lancashire, revealing that the standard forms are still very much favoured. It also shows that the rates of nonstandard were are higher than nonstandard was in both corpora,showing that were-levelling is more prominent than was-levelling in Lancashire. However, between corpora results show that this has decreased over time. In sum, over the generations, Lancashire speakers have grown to favour standard forms more than nonstandard. However, with regards to nonstandard, it is were-levelling which is favoured over was-levelling.
When looking at the nonstandard tokens alone, results showed that the BNC accounted for just 22% of the nonstandard was tokens and 19% of the nonstandard were. In FRED, 78% of the nonstandard was tokens were found and 81% of the nonstandard were. Thus, showing higher rates of both nonstandard forms.
Next, cross tabulations with corpora and the other independent variables were conducted to examine how the nonstandard forms are conditioned. This allowed insight into how the conditioning of the nonstandard has changed over time in Lancashire speech. A table of percentage rates of the nonstandard form are reported below.
| WAS | WERE | |||||||
| BNC | FRED | BNC | FRED | |||||
| % | N | % | N | % | N | % | N | |
| Gender | ||||||||
| Male | 4 | 299 | 13 | 661 | 32 | 129 | 36 | 407 |
| Female | 5 | 830 | 9 | 1183 | 18 | 330 | 35 | 787 |
| Question Types | ||||||||
| Tag question | 8 | 49 | 20 | 5 | 57 | 37 | 33 | 3 |
| WH-question | 0 | 27 | 0 | 4 | 0 | 6 | 0 | 1 |
| Yes/no question | 0 | 59 | 0 | 17 | 14 | 22 | 100 | 3 |
| NP type | ||||||||
| Pronoun | 3 | 859 | 7 | 1303 | 24 | 370 | 35 | 898 |
| Noun | 9 | 270 | 19 | 541 | 12 | 89 | 34 | 296 |
| Polarity | ||||||||
| Negative | 6 | 93 | 16 | 119 | 49 | 70 | 20 | 74 |
| Affirmative | 5 | 1036 | 10 | 1725 | 17 | 386 | 36 | 1120 |
| Age | ||||||||
| Young | 5 | 641 | 5 | 236 | 19 | 176 | 0 | 183 |
| Old | 5 | 462 | 11 | 1608 | 25 | 271 | 41 | 1011 |
Table 3: Table to show factor by factor results in each corpus of both nonstandard was and were
Gender
Table 3 shows that males are using nonstandard were at a higher rate than females in both FRED and BNC. Without grouping by corpora, males use the nonstandard 5% more than females. When examining just the nonstandard were tokens, the gender effects vary between corpora. The gender gap is much bigger (14%) in the more recent corpus, the BNC. Thus, in the BNC corpus, gender is a significant predictor of the nonstandard were (X2(1, N=459) = 9.99, p were show that a gender gap has formed over time: males are now using the nonstandard form at a higher rate than females.
Nonstandard was in the FRED corpus shows the same patterning: males are using the nonstandard variant at a higher rate than females. This is a small difference of 4% but nevertheless significant (X2 (1, N= 1844) = 8.53, p was in the BNC. Therefore, the gender effect on nonstandard was has changed over time: the gender gap has reduced between generations.
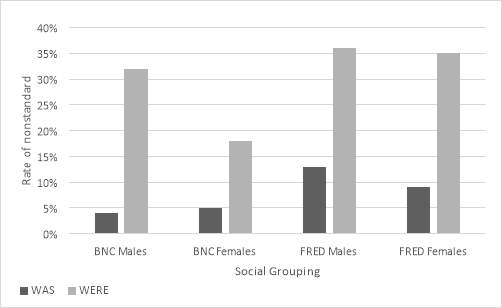
Figure 4: Graphic representation of cross-tabulation between gender and corpus
Age
Age results show that, in FRED, it was older speakers using the nonstandard was at the highest rate and old speakers using the nonstandard were. Young speakers in FRED never exhibit use of the nonstandard were. In BNC, it is also old speakers using the nonstandard were at the highest rate. However, speakers across both groups use the nonstandard was at the same rate. However, this rate is low at just 5%.
Polarity
The resulting effect of polarity differs interestingly across corpora and variant. As table 3 shows, in the FRED corpus, the rate of the nonstandard were in affirmative contexts is significantly higher than in negative contexts by 16% (X²(1, N=1194) = 7.6, p was within FRED is the opposite: there is a higher rate of nonstandard was in negatives contexts than affirmative contexts by 6%.
The BNC exhibits a different polarity effect. The rate of the nonstandard were is significantly higher in negative contexts than affirmative by 32% (X²(1, N=456) = 35, p was rate is also higher in negative contexts but only by 1%, therefore proving insignificant.
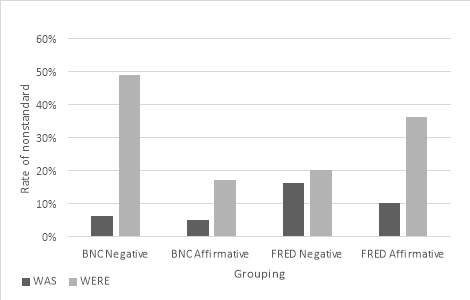
Figure 5: Graphic representation of cross-tabulation between polarity and gender
The polarity and gender cross-tabulations show how polarity conditions the nonstandard forms in Lancashire has changed dramatically over time. Furthermore, it is clear from Figure 5 that the context in which nonstandard were is used most is with negative polarity in BNC. It is used least with positive polarity in BNC. The context in which nonstandard was is used most is in FRED negative polarity and it is used least in BNC affirmative polarity, but only slightly.
Noun phrase head type
The direction of effect of noun phrase head type on the rate of nonstandard were has remained constant over the corpora. There is more nonstandard were in utterances with a pronoun in the noun phrase head than those with a noun. However, this effect is much greater in the BNC (12%) than FRED (1%). In the FRED corpus, there is a marginal difference which shows that noun phrase type does not strongly condition the nonstandard.
This variable has the opposite effect on the rates of nonstandard was: there is more nonstandard was in utterances where a noun is the noun phrase head rather than a pronoun. This result stands in both corpora. In the FRED corpus, this effect is greater by 12% but only greater by 6% in the BNC. This is visualised in Figure 6.
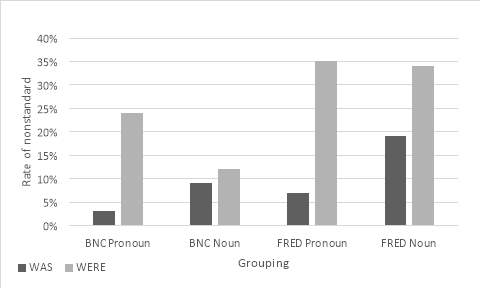
Figure 6: Graphic representation of cross-tabulation between noun phrase head and gender
Question types
Questions were found to be the least favouring linguistic environment for nonstandard forms. Table 3 shows the effects of varying question types on the rates of nonstandard was and were. Both corpora never use the nonstandard were in WH-questions. In terms of tag questions, the rate of were in contexts of standard was is considerably higher in the BNC corpus than FRED. Yes/no questionshave the opposite effect: the rate of nonstandard were hereis highest in the FRED corpus. In fact, 100% of yes/no questions in the FRED corpora use were in a nonstandard context. Thus, there has been a shift in how question types condition were levelling over time in the Lancashire dialect. Despite WH-questions still categorically using the standard past tense be verb, the effect of tag questions and regular questions has changed over time.
Table 3 also reports that WH-questions categorically use the standard forms in the was variable too: there is a 0% rate of the nonstandard variant in both corpora. Thus, WH-questions always use the standard forms within the past tense be paradigm. Furthermore, yes/no questions also never use nonstandard was in both corpora. Nonstandard was in tag questions is found at a low rate in the BNC and a 12% higher rate in FRED corpus.
Summary
In sum, Table 3 shows that conditioning of the nonstandard forms has changed over time in Lancashire. The most noteworthy changes here are gender and polarity. The generational change in nonstandard was patterning shows that it was males using the nonstandard at a greater weight than females but the rates have since levelled out. The opposite effect is exhibited for nonstandard were where the nonstandard used to be used at a similar rate but now it is males using it more. Polarity also shows an important change over time. Negative polarity used to favour the nonstandard was but now favours nonstandard were. Affirmative polarity used to favour nonstandard were but now favours nonstandard was. The next section will use multivariate analysis to examine how these factors affect the nonstandard when considered simulataneously.
4.2 Multivariate analysis
This section will focus on the second research question laid out in section 2 as it will report which nonstandard variant is favoured overall. Using logistic regression models, I will report not only which conditions favour the nonstandard, confirming or disagreeing with results in 4.1, but also use the corpus predictor to reveal whether the preference of were or was-levelling has changed over time. This predictor will play the most important role in testing my hypothesis. I will analyse was and were separately with the corpora combined, producing two separate models. To test the second part of my hypothesis, centring around Britain’s (2002) polarity patterning, I included an interaction between polarity and corpus in the models. This will reveal how polarity patterning have changed over time and reveal if pattern two is present in the data.
Yes/no questions and WH-questions factors was not selected for this analysis due to a 0% rate of use of nonstandard was in both these contexts and 0% rate of nonstandard were in WH-questions and a low rate of nonstandard were in yes/ no questions. Due to this, the regression models could not run with nonstandard was and these factors as the data was invariant. As I wanted the models to be fair, it felt best fit to remove these factors from both models despite nonstandard were having some rate of appearing in regular questions.
4.2.1 Were used in standard contexts of was
In this subsection, I will introduce the multivariate regression model for instances of were used in a standard was context. This will reveal the conditions that favour use of the nonstandard were. Most importantly, it will reveal which time context (BNC or FRED) favours were-levelling.
With regards to research question two, the most important result here is the corpus predictor. Multivariate analysis results suggest that BNC favours the nonstandard were over FRED. This does not support my hypothesis nor agree with results in 4.1 which show higher rates of nonstandard were in FRED. Corpus, however, does not prove a significant predictor of the nonstandard and therefore, this effect is fairly weak. Furthermore, results do reveal that the old age group favour the nonstandard. This concurs with my predictions as, if Chambers (2004) is correct, we should expect to see less young people using nonstandard were than old people.
| Factor | N | % | Factor Weight |
P-value |
| Noun phrase head | ||||
| Pronoun | 1260 | 0.323 | 0.546 | |
| Noun | 381 | 0.297 | 0.454 | |
| Polarity | ||||
| Negative | 146 | 0.349 | 0.528 | |
| Affirmative | 1495 | 0.314 | 0.472 | |
| Tag Question | 0.186 | |||
| 1 | 40 | 0.550 | 0.581 | |
| 0 | 1601 | 0.311 | 0.419 | |
| Age | 0.501 | |||
| Old | 1282 | 0.379 | 0.566 | |
| Young | 359 | 0.095 | 0.412 | |
| Gender | 0.287 | |||
| Male | 524 | 0.357 | 0.588 | |
| Female | 1117 | 0.298 | 0.412 | |
| Corpus | ||||
| BNC | 447 | 0.226 | 0.584 | |
| FRED | 1194 | 0.351 | 0.416 | |
| Polarity:Corpus | ||||
| Affirmative : FRED | 1120 | 0.361 | 0.617 | |
| Negative : BNC | 72 | 0.500 | 0.617 | |
| Affirmative : BNC | 375 | 0.173 | 0.383 | |
| Negative : FRED | 74 | 0.203 | 0.383 |
Table 4: Multivariate analysis results for nonstandard were
Evaluating the results in light of Britain’s (2002) pattern, Lancashire data patterns as expected as negative polarity favours the nonstandard were. Furthermore, the interaction effect between polarity and gender supports the cross-tabulations conducted in 4.2. Within the FRED corpora, affirmative contexts favour the nonstandard were but, contrastingly, within the BNC, negative contexts favour the nonstandard were. Furthermore, this interaction proves a significant factor in predicting nonstandard were with a p-value smaller than 0.001. This interaction result follows predictions and shows some evidence of the nonstandard were being heavily conditioned by polarity in BNC. As the opposite pattern is exhibited in FRED, it is suggested that this pattern has emerged significantly in the gap between corpora. Thus, following Chambers (2004) predictions surrounding the emergence of pattern two.
The other factors in Table 4 shed light on research question 1 and the conditioning of the nonstandard. Also, they can be used to confirm and further results from 4.1, therefore strengthening results. Gender results exhibited in Table 4 show it is the males who favour the nonstandard were over females. This confirms findings in 4.1. Although, the difference between these groups proves insignificant when all factors are considered. Furthermore, the p-values in Table 4 show that a significant predictor of were being produced in a standard was context is noun phrase head type. More specifically, it is pronoun phrase heads which favour the nonstandard were over nouns. Thus, the probability of a nonstandard were being produced with a preceding pronoun is more likely than with a preceding noun. After confirming the analysis undertaken in section 4.1 (Table 3), I chose to look examine this predictor in more depth to reveal which exact pronoun favoured the nonstandard.
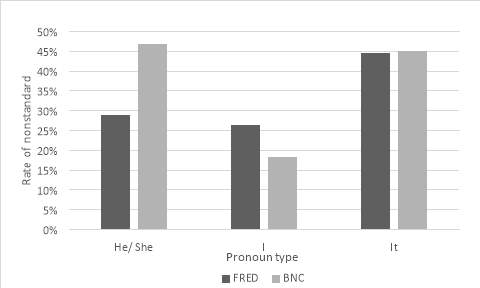
Figure 7: Graphic representation of cross tabulation of pronoun type and corpora with nonstandard were
Figure 7 shows, the rates of nonstandard were with the third person singular pronouns (he/ she) have increased over time. This pronoun type in the BNC corpus has the highest overall rate of the nonstandard were. In the FRED corpus, on the other hand, it favours the nonstandard. However, rates of nonstandard here have remained fairly constant over time. Contrastingly, use of first person singular with the nonstandard were has decreased over time. Thus, patterning of nonstandard were with pronouns has changed dramatically over time in Lancashire.
Following the literature explored in Section 2, table 4 shows the expected result that tag questions favour the nonstandard form. However, this does not prove a significant predictor of nonstandard were. It does, however, confirm findings in4.1 which show high rates of the nonstandard were in tag questions.
4.2.2 Was used in standard contexts of were
In this subsection, I will present the regression model for nonstandard was. The same factors were considered as in the model for nonstandard were.
Most unexpectedly, Table 5 shows that FRED favours nonstandard was over BNC. This is not expected in my hypothesis as it suggests the use of nonstandard was has decreased over time in Lancashire. Furthermore, the age results support this as they reveal that old speakers favour the nonstandard whereas following Chambers (2004), I would have predicted young people to favour the nonstandard as this would suggest its vernacular state. However, again, the corpus predictor shows a small effect and age proves insignificant.
Table 5: Results from multivariate analysis of nonstandard was
| Factor | Tokens | % | Factor Weight | P-value |
| Noun phrase head | 5.95e-18 | |||
| Noun | 792 | 0.158 | 0.651 | |
| Pronoun | 2155 | 0.054 | 0.349 | |
| Polarity | ||||
| Negative | 212 | 0.118 | 0.575 | |
| Affirmative | 2735 | 0.079 | 0.425 | |
| Tag Question | 0.173 | |||
| 1 | 54 | 0.093 | 0.599 | |
| 0 | 2893 | 0.082 | 0.401 | |
| Age | 0.549 | |||
| Old | 2249 | 0.092 | 0.529 | |
| Young | 698 | 0.049 | 0.471 | |
| Gender | 0.705 | |||
| Male | 934 | 0.103 | 0.515 | |
| Female | 2013 | 0.073 | 0.485 | |
| Corpus | ||||
| FRED | 1844 | 0.102 | 0.597 | |
| BNC | 1103 | 0.048 | 0.403 | |
| Polarity:Corpus | 0.718 | |||
| Affirmative: BNC | 1010 | 0.047 | 0.513 | |
| Negative: FRED | 119 | 0.160 | 0.513 | |
| Affirmative: FRED | 1725 | 0.099 | 0.487 | |
| Negative: BNC | 93 | 0.065 | 0.487 |
Polarity displays the same effect upon nonstandard was as were: negative contexts favour the nonstandard. This, is not expected as per my hypothesis or Chambers (2004) prediction of the emergence of pattern two as, in this pattern, affirmative polarity favours the nonstandard. However, the interaction between corpus and polarity shows, in the BNC corpus, affirmative contexts favour the nonstandard form. Whereas, in FRED, it is negative contexts favouring the nonstandard. The probability of a nonstandard was being used is least likely in a negative context in the BNC and an affirmative context in FRED. Thus, the corpora display opposite patterning. This interaction does support my predictions as it shows the recent data does favour the nonstandard in affirmative and disfavour in negative. This follows Britain’s (2002) pattern. This interaction, however, does not prove significant for nonstandard was and thus the effect is not as strong as on nonstandard were.
Other factors in the model can be examined to answer research question 1. With regards to gender, the regression model for nonstandard was exhibits the same effect as with nonstandard were: males favour the nonstandard. This, again, agrees with the within corpora analysis undertaken in 4.1. However, with the corpora combined and all factors considered simultaneously, gender is not a significant predictor for nonstandard was. Furthermore, it shows that nonstandard was exhibits the opposite effect to nonstandard were in terms of noun phrase head type: here, nouns favour the nonstandard. In the case of nonstandard was, this would refer to plural noun phrases such as the houses. Again, after confirming the results from 4.1, further pronoun analysis was undertaken despite pronouns not being the favoured noun phrase head type. This allowed for more detailed results on the conditioning of nonstandard and comparison with nonstandard were. This analysis was undertaken by corpora to examine how this may have changed over time.
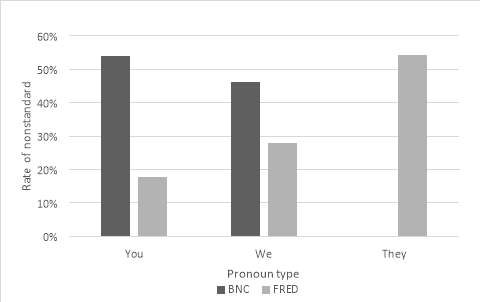
Figure 8: Graphic representation of cross-tabulation between pronoun type and corpora with nonstandard was
These more detailed pronoun results reveal nonstandard was is never used with they in BNC despite this being he favouring pronoun for it in FRED. It shows the distribution of the nonstandard was tokens are distributed fairly evenly over the rest of the pronouns in BNC. In FRED, you is found to be least favouring for the nonstandard form.
4. Discussion
Regarding the patterning on nonstandard was and nonstandard were in Lancashire, results show there have been some interesting shifts in patterning. Noun phrase head type proved to be an important factor in predicting both nonstandard was and were. The two variants showed the opposite effect: pronouns favour nonstandard were and nouns favour nonstandard was. This has remained constant over time. When analysing pronoun types further for nonstandard were, the following hierarchy was found to be present (in order from most favouring to least): it > he/she > I. The finding that the pronoun to favour nonstandard were most strongly is it agrees with findings in York. Tagliamonte (1998) found that across all ages, it favoured nonstandard were over other pronoun types. However, she found the first person singular to favour the nonstandard over he/ she. Therefore, following these results, a speaker from Lancashire is more likely to produce a nonstandard were with he/ she than a speaker from York. Comparing the grammatical subject results to the close findings of Bolton (Moore 2010) shows Lancashire has different patterning again. The hierarchy of the three subjects in question in Bolton is: he/she > it > I. However, the Lancashire and Bolton data agree that, out of these pronouns, I is the least favouring to nonstandard were.
Nonstandard was results show that this variant is strongly conditioned by a plural noun being the head type of the utterance. This follows the Northern Subject rule where the verb takes the -s form in the plural where the subject is a noun (Beal 2004). Thus, over time, Lancashire has remained constrained by this rule. This, again, perhaps demonstrates the desire to show off one’s self-identity as ‘northern’ and align oneself to traditionally Northern speech.
Contrastingly, Anderwald (2004) found in the Southeast of England that pronouns we, they and you presented near categorical use with nonstandard was. Thus, the opposite effect is exhibited in the South as it is pronouns that favour nonstandard was. This, again, coincides with the Northern Subject Rule as the rule is exhibited in Lancashire, a Northern region, but not in the Southeast of England (Anderwald 2004). This furthers the idea that, in Lancashire, speakers may have upheld the Northern Subject Rule over time in my data due to their Northern social identity as it disassociates themselves with Southern speakers, who do not adhere to this rule. As Chambers said, we mark ourselves to territory and ‘one of the most convincing markers is by speaking like the people who live there’ (Chambers 2009:266). Thus, Lancashire speakers mark themselves to Northern territory by speaking as a Northerner does. Results from rates of nonstandard was with pronouns in the recent BNC data are found to be in accordance with the previous body of literature. They show that they was never appears in the BNC dataset. Chambers (2004) has previously identified they as the most inhibiting pronoun to nonstandard was and this is upheld in this most recent Lancashire dataset. This has also been upheld in other studies, such as of Buckie English (Smith and Tagliamonte 1998) where they was is also not found at all. Therefore, this is per expected previous research. Furthermore, Pietsch (2005) found that in all areas that allowed the nonstandard was with pronouns, you was seemed to be favoured over we was. Therefore, again, my findings in Lancashire agree with existing lite6rature concerning nonstandard was with pronouns. The hierarchy I found to be used in the recent data in this study of Lancashire is exactly as expected according to previous studies: you > we > they. However, the older, FRED, data show very different results, showing that Lancashire pronoun and nonstandard was usage has only, in the gap between corpora, converged to other parts of the country. In FRED, I found they to be the favouring pronoun for nonstandard was. In fact, the hierarchy here is they > we > you, the opposite to the recent data. This is surprising following previous research but not unheard of as in York, Tagliamonte (1998) also found instances of they was. However, in York, this was at a lower rate than both we and you. These results show that over time, the way in which pronouns are produced with nonstandard was has dramatically changed. This suggests that as generalising to was has become more popular in Lancashire speech, its usage has levelled out with other speech communities nonstandard was usage.
Also in this study, it was found that WH-questions categorically use the standard forms. Despite finding some instances of its usage, Moore (2010) found this clause type to be disfavouring of nonstandard were. Thus, agreeing with the Lancashire results. This has not changed over time in Lancashire: in both data sets the nonstandard forms never appear in this question type. In terms of regular, yes/no questions, I found a categorical use of the standard was, but there was evidence of nonstandard were in these question types. In the older data, all regular questions using were were nonstandard. In the more recent data, there was a 14% rate of nonstandard were in regular questions. Therefore, it can be speculated that the rate of nonstandard were in this question type has decreased over time and therefore, this is no longer a predictor of nonstandard were showing a recently developed restriction on where the nonstandard were is used. However, due to the lack of tokens in the FRED data of regular questions, it is difficult to draw a concrete conclusion on how this patterning has changed over time. This question type was found to have a fairly high rate of nonstandard were at 39% in Bolton (Moore 2010) and therefore, the recent data results from Lancashire different significantly from this. Neither of these question types were ran in the regression model, but distributional results do summarise that there is a low rate of nonstandard in both and therefore neither are a significant predictor of the nonstandard in Lancashire. However, there are differences in the patterning of the nonstandard of WH-questions and regular questions as WH-questions never use the nonstandard were or was whereas regular questions use the nonstandard were but not was. A possible explanation for this difference could be formality. This has been previously speculated by Moore (2010) who pointed out that WH-questions are typically more formal than regular questions and therefore less likely to favour the nonstandard.
Tag questions have previously been found to be an important predictor in nonstandard were, particularly in a negative context (Tagliamonte 1998; Cheshire and Fox 2008). In Lancashire, results show that tag questions do indeed favour nonstandard were over grammatical structures that aren’t tag questions. However, this is not a significant predictor as it is in other dialects. Results, however, do agree with prior research in that nonstandard were favours negative tags over affirmative tags. Tagliamonte (1998) found, in York, 91/95 tag questions were negative tags and 81% of these occurred with nonstandard weren’t. In Lancashire, I also found negative tag questions to favour nonstandard were over affirmative tags. However, surprisingly, the nonstandard was also favours tag questions over non-tag questions in these results. This shows that, in Lancashire, the nonstandard generally favours tag questions, this is not specific to were-levelling. However, tag questions are not a significant predictor of nonstandard was either.
In terms of the key variable of polarity, Lancashire data shows a somewhat unexpected result with regards to Britain’s (2002) pattern. Britain, amongst other studies (Tagliamonte 1998; Trudgill 2004) identifies that nonstandard were is favoured in negative polarity and nonstandard was is favoured in positive polarity. However, results from this Lancashire data show that both nonstandard was and were favour the negative context. The nonstandard was results, thus, somewhat support Chamber’s (2004) ‘default singular’ as becoming universal as it seems was is used across all contexts and therefore, it can be argued that the past tense to be paradigm is reducing to just was, or the ‘default singular’. Furthermore, these results suggest that Britain’s (2002) pattern is not evident in Lancashire speech as nonstandard was is not constrained to occur with only positive polarity. Tagliamonte (1998) found in York that was never occurred in negative contexts of standard were. However, the results from this study conflict with those from York as not only does was occur in negative contexts of were in Lancashire but the negative contexts favour nonstandard was over positive contexts. However, results from nonstandard were analysis do conform to predictions based on previous research: negative polarity favours were-levelling.
However, the results of the interaction between polarity and corpus add a more in depth look into the polarity patterning. It shows that in the more recent data, the affirmative contexts favour nonstandard was the most and negative contexts disfavour nonstandard. Furthermore, in regards to nonstandard were, it shows negative polarity in the BNC favours nonstandard over affirmative polarity in the BNC. As the older data shows the opposite patterning to this, it shows that Britain’s (2002) pattern has emerged during the gap between corpora. Chambers (2004) does predict that pattern two will emerge out of pattern one. However, it seems that in this data, pattern two has begun to emerge out of a different pattern: were-levelling, not the ‘default singular’ (pattern one). Chambers did not account for this possibility as he overlooks the nonstandard were in his predictions. I suggest that the data shows a historic favouring of were-levelling and, although in the recent data, overall, were-levelling is still favoured, we begin to see the emergence of Britain’s (2002) pattern (pattern two) whereby negative polarity particularly favours levelling to were and positive polarity favours levelling to was. Therefore, it would have been more appropriate to predict that pattern two could emerge out of either was-levelling or were-levelling, whichever one that particular speech community has historically favoured rather than it emerging from the ‘default singular’.
Once the general patterning of the nonstandard forms had been established in Lancashire, evaluations of Chambers (2004) posit of the vernacular ‘default singular’ could be evaluated. Overall, results show that there is still were-levelling happening in Lancashire and, therefore, was-levelling has not completely over taken. In fact, comparing overall rates, there is a higher rate of nonstandard were than nonstandard was. This upholds previous conceptions that in areas the North strongly favour generalised were (Pietsch 2005). Thus, these traditional ideas are found to be still present in Lancashire, challenging Chambers (2004) ‘default singular’. This suggests that the ‘default singular’ is not becoming a vernacular of English as, in Lancashire, nonstandard were is the dominant nonstandard form. Thus, the ‘vernacular’ in Lancashire for past tense to be seems to be the generalised were, not generalised was due to nonstandard were being used at a higher rate. This has remained consistent over time in Lancashire. Furthermore, this is strengthened when evaluating these results in the light of previous findings (Petyt 1985; Ellis 1889; Shorrocks 1999; Beal 2004; Moore 2010) which also find a generalisation towards were over was. It is then evident that there are areas in the Northwest that are not progressing towards the ‘default singular’ becoming vernacular and, instead, they uphold the traditionally Northern nonstandard were. Evidence for this is particularly strong in Lancashire due to this pattern being evident in the most recent data as well as the older data. This is not expected as per Chamber’s (2004) predictions not my hypothesis
Thus, Chambers (2004) is overlooking a significant nonstandard feature when positing the ‘default singular’ as universal. My results, along with previous studies with similar results, suggest that it should be generalisation to both was and were that should be posited as becoming a vernacular universal of English instead of just was. This is also acknowledged also by Trudgill (2009: 306) who believes ‘simply regularisation’ should alternatively be posited the as the vernacular. Furthermore, he justifies this as were-levelling is present, in some areas, in both positive and negative contexts which is displayed in my results. Therefore, my data supports and provides evidence for Trudgill’s suggestion here.
Offering some explanation to this, Moore (2010) argued that the strong presence of were-levelling in Bolton may be due to its use of a symbol of localness. Thus, this could be applied to the wider area: were-levelling throughout Lancashire could be used as a symbol of their Northern localness. As previously shown in Figure 1, was in contexts of standard were was only present in the South. Whereas, were in contexts of standard was was heavily conditioned to the Northern regions. Furthermore, in the Southeast of England, it was found that singular subjects occurring with were was ‘exceedingly rare’ (Anderwald 2004: 183). Therefore, nonstandard were became seen as a Northern feature. It is then possible that, at this time, nonstandard was was considered a Southern feature as it is only there where it appears. Thus, Lancashire possibly diverge and resist was-levelling as it is not considered ‘Northern’. This suggests the nonstandard were variant may carry some covert prestige and, therefore, this could explain the presence of it still in the recent data and the unexpected lack of was-levelling. Covert prestige defines nonstandard features that are favoured due to associations with ‘the local, the informal, and the vernacular’ (Chambers 1995: 235). A good example of this from my data could be the persistent use of it were because it is so outwardly nonstandard, and therefore informal, yet Lancashire speakers consistently use it at a fairly high rate. Furthermore, the explanation for the covert prestige, and therefore continued use of the nonstandard were, could be ‘solidarity-stressing’ (Chambers 2000a). This defines the high evaluation of a nonstandard feature due to associations with ‘kindness, likeability, friendliness, goodness and trust’ (Chambers 2000a:238) in regional speakers. Therefore, speakers may continue use of the nonstandard were to show solidarity with their region and associate themselves with these positive features. As Wales (1999) states, dialect differences will remain if there is still a desire to show allegiance to a region (Wales 1999:12). Therefore, this could explain why the favouring of were-levelling over was-levelling has remained constant over time: there is still a speaker desire to show allegiance to their region.
However, although it does have higher rates then was-levelling, were-levelling has significantly decreased over time in the century between corpora: rates of nonstandard were are significantly higher in FRED than BNC. Contrastingly, this suggests that Lancashire speakers are using the nonstandard were less than they once did. Thus, it has perhaps lost some of its covert prestige. Or, solidarity with the region is not valued as much as it once was. In Shetland English (Durham 2013) it was found that the change from were to was occurred in the middle generation and in the youngest generation, it had gone to completion. However, in Lancashire, the change has not gone to completion in the younger data. Instead, rates of were-levelling remain higher than was-levelling. This shows that Lancashire has not undergone the complete transition like Shetland English has despite there being some decrease. But, age analysis shows that it is older speakers that favour the nonstandard were over younger speakers. Thus, rates of the nonstandard have dropped in the younger generation. This could suggest that the most recent data I have explored could represent the ‘middle’ generation in the Shetland English study in that in this generation, levels are decreasing and in later generations, levels of nonstandard were could drop even further. Thus, my research could be furthered by investigating Lancashire dialect today and seeing if this has occurred yet.
Was-levelling has also decreased over time, rather than increased like one may expect according to Chamber’s predictions. Thus, overall, rates of nonstandard have decreased, meaning rates of standard forms have increased. This shows that Lancashire favour the standard forms and are perhaps diverging away from both nonstandard forms. Therefore, the standard past tense BE paradigm is very much still favoured in Lancashire. Thus, it seems that Lancashire are pulling away from the local form in favour of standardised English. Instead of moving towards Chambers (2004) ‘default singular’, Lancashire are simply favouring the standard forms. This is confirmed in age analysis which shows that old speakers favour the nonstandard was over young speakers here too. This, again, suggests that rates will continue to decrease in future generations and therefore nonstandard was will not be a vernacular in Lancashire speakers.
Corpus results from multivariate analysis show surprising results. These results do not support my hypothesis. In fact, the results exhibit the exact opposite. If Chamber’s was correct in suggesting that the English language is moving towards a default singular, then we would expect to find a higher probability of nonstandard was in the more recent data. As this is not what the results show, it further suggests that Chambers isn’t accurate in this assumption. The results show that, instead, in the most recent data, nonstandard were is foremost. This, again, shows that were-levelling is being used more than was-levelling. The nonstandard was model shows the unexpected result that it is most likely in the FRED corpora. Despite single factor analysis showing that there is a higher rate of nonstandard were than nonstandard was in the older dataset, with all factors considered simultaneously, the probability of nonstandard was is higher in the older data. This does not agree with Ellis’ (1889) map. This is particularly surprising as the FRED sources data from around a similar time context.
The gender effects in Lancashire are important in evaluating Chambers (2004) posit of the ‘default singular’ being a vernacular as gender patterning can reveal how variables are viewed by speakers. Results show it is the males leading the nonstandard. Previous studies exhibit very different gender effects. In York (Tagliamonte 1998) and outer London (Cheshire and Fox 2009) it was found that females were using nonstandard forms at a higher rate than males. Therefore, it was concluded that change from below was taking place in these cases and thus women were leading in the use of the incoming nonstandard variants. However, Following the principles as per Labov (1990) this suggests that these variables, in Lancashire, are in stable sociolinguistic stratification. As it is here than men use the nonstandard as a higher rate than women. As he suggests that men are less influenced by social stigmas, this shows that the nonstandard forms in this study have a social stigma attached to them. Therefore, this could be why women avoid using them more than men. This is most evident in the were data. Thus, it seems that nonstandard were has a greater social stigma surrounding it than nonstandard was. This perhaps provides evidence for the ‘default singular’ being vernacular as nonstandard was is less stigmatised than nonstandard were and it is less likely for a stigmatised variant to become a universal vernacular of English than a non-stigmatised variant because no social groups are deviating from it which would inhibit the spread of its use.
When examining the individual corpus results, it is evident that this stigma surrounding nonstandard were developed during the years between the corpora. In the older data, there was no significant gender differences: males and females were using nonstandard were at a similar rate. Thus, suggesting that, in this time context, nonstandard were was not associated with any social stigma. However, in the most recent data, males are using the nonstandard at a significantly higher rate than females. And so, it appears that in this time setting females are avoiding its use but males continue using it because, as Labov states, men are ‘less influenced by the social stigma’ (Labov 1990: 210). This also suggests that the feature has developed some covert prestige. Trudgill’s (1972) study of Norwich illustrates the notion of covert prestige well. Most importantly, the study showed that men are more influenced than women by the covert prestige of nonstandard forms (Trudgill and Chambers 1998). This is what is what is being suggested in the gender results of this study: men are using a higher rate of the nonstandard because they are greater influenced by its covert prestige. However, with nonstandard was, the opposite patterning has developed over time. In the older data, there was a significant gender gap in rates of nonstandard was, suggesting it then had a social stigma. This was perhaps due to its association with Southern speakers. However, it has seemingly lost its stigma as, in the recent data, there is no significant gender gap. This, again, supports Chambers (2004) posit of the ‘default singular’ becoming a vernacular of English as males and females are using it at a similar rate, showing the stigma surrounding the nonstandard has been lost.
6. Conclusion
In this paper, I have explored variation in subject agreement with BE in the Lancashire speech community. Drawing on datasets from two time points, roughly two generations apart, I have analysed how patterning within this variable has changed over time. In this chapter I will summarise the findings and implications of the research carried out in this paper.
I have found that, overall, were-levelling is more prominent than was-levelling in Lancashire. Not only are these results present in the dataset overall but also in the individual corpora results. This shows that the older data supports the traditional idea of Northern speakers favouring the generalised were (Ellis 1889) and shows that this has not changed in the next generation of speakers: were-levelling is still favoured over was-levelling. This disproves my hypothesis as, based on Chamber’s (2004) ‘default singular’, I expected to see an increase in the use of generalised was and even to see this overtake rates of generalised were. However, this is not the case. In fact, rates of nonstandard was have decreased within the next generation of Lancashire speakers. The fact that a large area of the North, Lancashire, still level in favour of were and not was, shows that Chambers (2004) overlooks a significant feature when positing the ‘default singular’ as universal. Alternatively, it should perhaps be generalisation to both was and were in the past tense to be paradigm that should be posited as becoming a universal vernacular of English.
A possible reason for Lancashire speakers upholding use of generalised were could be as a marker of their social identity as belonging to the region of Lancashire, or perhaps even the wider region of ‘The North’. As Chambers (2009:266) states, ‘the underlying cause of sociolinguistic differences… is the human instinct to establish and maintain social identity’. Thus, I suggest the underlying reason for the continued use of were-levelling in this study is for speakers here to maintain their social identity as belonging to Lancashire. Moore (2010) also found high rates of were-levelling to still be used in Bolton for similar reasons of expressing social identity. Therefore, these results in conjunction with the results from my Lancashire study show a desire in the North west to uphold a Northern identity.
With regards to Britain’s (2002) pattern of were-levelling being restricted to negative polarity and was-levelling occurring predominantly in affirmative polarity, my results show that this pattern has begun to emerge in Lancashire. In the older data, polarity did not have the expected effect on generalisations. It displayed a patterning in which the affirmative favoured nonstandard were and the negative favoured nonstandard was. This is the opposite of expected as per Britain’s pattern. However, in the more recent data, affirmative polarity favours the nonstandard was and negative polarity disfavours the nonstandard. Furthermore, in this data, negative polarity favours the nonstandard were and the affirmative disfavours its use. These results show that Britain’s pattern has emerged within a generation of Lancashire speakers. Thus, the second part of the research hypothesis was supported. However, as pattern one is not present, pattern two cannot have emerged from this. Therefore, we see the presence of pattern two emerge from a were-generalisation and not was-generalisation and it is were-generalisation that is favoured significantly in the older data. This does not support Chamber’s prediction that pattern two will emerge from patterns of favoured was-generalisation.
References
Adger, D. & J. Smith (2005) Variation and the minimalist program. In Leonie Cornips & Karen Corrigan (eds.), Syntax and variation: Reconciling the biological and the social, 149-178. Amsterdam: Benjamins
Anderwald, L. (2004) The varieties of English spoken in the Southeast of England: morphology and syntax. In: B. Kortmann, K. Burridge, R. Mesthrie, E. Schneider and C. Upton, ed., A Handbook of Varieties of English, 1st ed. Berlin: Mouton de Gruyter, pp.175-195
Beal, J. (2004) English dialects in the North of England: morphology and syntax. In: B. Kortmann, K. Burridge, R. Mesthrie, E. Schneider and C. Upton, ed., A Handbook of Varieties of English, 1st ed. Berlin: Mouton de Gruyter, pp.114-141
Britain, D. (2002) Diffusion, levelling, simplification and reallocation in the past tense of BE in the English Fens. In: Lesley Milroy (ed.), Investigating Change and Variation Through Dialect Contact. Special issue of Journal of Sociolinguistics 6: 16–43
Chambers, J. K. (2000a) Sociolinguistic uses of subjective evaluation tests Einstellungsforschung in der Soziolinguistik and Nachbardisziplien, ed. Szilvia Deminger, Thorsten Fogen, Joachim Scharloth, and Simone Zwickl. Frankfurt: Peter Lang, pp. 52-60
Chambers, J. K. (2001) Vernacular universals In. ICLaVE 1: Proceedings of the First International Conference on Language Variation in Europe ed. J.M. Fontana, L. McNally, M.T. Turell and E. Vallduvi. Barcelona: Universitat Pompeu Fabra
Chambers, J. K. (2004) Dynamic typology and vernacular universals. In B. Kortmann (ed.), Dialectology meets typology: Dialect grammar from a cross-linguistic perspective. Berlin: Mouton de Gruyter. 127–145
Chambers, J. K. (2009). Sociolinguistic Theory. Rev. edn. Chichester: John Wiley & Sons Ltd
Chambers, J. K. and P. Trudgill (1998) Dialectology. 2nd edn. Cambridge: Cambridge University Press
Cheshire, J. & S. Fox (2008) Was/were variation: a perspective from London. University of London
Cheshire, J., V. Edwards & P. Whittle (1989) Urban British Dialect Grammar: The Question of Dialect Levelling English World Wide 10: 185-225
Durham, M. (2013) ‘Was/were alternation in Shetland English’ World Englishes, 32: 108–128
Ellis, A. (1889) On Early English Pronunciation (Part 5) London: Truebner and Co.
Google Maps (2017) Map of Lancashire [online]. Google. Available from: https://www.google.co.uk/maps/place/Lancashire/@53.8611615,-2.5511274,9z/data=!4m5!3m4!1s0x487a4d4c5226f5db:0xb5497dd10c461b65!8m2!3d53.7632254!4d-2.7044052 [Accessed 24January 2017]
Labov, W. (1990) ‘The intersection of sex and social class in the course of linguistic change’ Language, Variation and Change, 2, 205- 254, Cambridge University Press
Labov, W. (2001) Chapter 11: ‘Resolving the Gender Paradox’ Principles of linguistic change: social factors, 2
Lancashire County Council (2017). Home. [online] http://Lancashire.gov.uk. Available at: http://www.lancashire.gov.uk/ [Accessed 25 Feb. 2017]
Moore, E. (2010) Interaction between social category and social practice: explaining was/were variation, Language Variation and Change, 22(3), pp. 347–37
Petyt, K. M. (1985) Dialect and Accent in Industrial West Yorkshire In Varieties of English Around the World. General Series. 1st edn. Amsterdam: John Benjamin’s Publishing Company
Pietsch, L. (2005) Some do and some doesn’t’: Verbal concord variation in the north of the British Isles In. B. Kortmann, T. Herrmann, L. Pietsch and S. Wagner A Comparative Grammar of British English Dialects. Agreement, Gender, Relative Clauses, 1st ed. Berlin: Mouton de Gruyter pp. 125-210
Pyles, T. and J. Algeo (1993) The Origins and Development of the English-Language. Orlando: Harcourt Brace and Company
Shorrocks, G. (1999) A Grammar of the Dialect of the Bolton Area. Frankfurt: Lang
Shnukal, A. (1978) A Sociolinguistic Study of Australian English: Phonological and Syntactic Variation in Cessnock, NSW. Georgetown
Tagliamonte, S. (1998) Was/were variation across the generations: View from the city of York. Language Variation and Change 10: 153–191
Tagliamonte, S. & Smith (1998) ‘We were all thegither…I think we was all thegither’: regularization in Buckie English World Englishes, Vol 17, No. 2, pp. 105-126
The British National Corpus, Version 3 (2007) Distributed by Oxford University Computing Services on behalf of the BNC Consortium. URL: http://www.natcorp.ox.ac.uk/
Trudgill, P. (1972) Sex, covert prestige and linguistic change in the urban British English of Norwich. Language in society, 1(02), 179-195
Trudgill, P. (1999) Standard English: What it isn’t. In: T. Bex and R. Watts, ed., Standard English, 1st ed. London: Routledge, pp.117-128
Trudgill, P. (2004) The dialect of East Anglia: morphology and syntax. In A Handbook of Varieties of English Vol.2: Morphology and Syntax, ed. B. Kortmann, K. Burridge, R. Mesthrie, E. Schneider and C. Upton. Berlin: Mouton de Gruyter, pp.142-153
Trudgill, P. (2008) 13 Vernacular Universals and the sociolinguistic Typology of english dialects. Vernacular universals and language contacts: Evidence from varieties of English and beyond, 304
Wales, K. (1999) ‘North and South: A Linguistic divide?’ Inaugural professorial lecture, University of Leeds, 10th June 1999. URL: https://www.cambridge.org/core/services/aop-cambridge-core/content/view/S0266078400011378> Accessed 18/4/2017
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Linguistics"
Linguistics is a field of study that explores the science of languages and their structures. Linguistics covers how factors such as history, culture, society, and politics, amongst other elements, can have an impact on language.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: