Improvement of Open-Source Digital Forensics Toolkit
Info: 18836 words (75 pages) Dissertation
Published: 20th Dec 2021
Tagged: TechnologyForensic Science
Abstract
Digital forensics has seen an uprising due to the omnipresence of technology in the modern world. It is the way through which crimes are demystified, the innocent is condoned and the guilty is uncovered. It also goes beyond cybercrime cases to solve even murder cases based on the little piece of technology involved. The tools available though, cost a lot – while freely available tools lack features which would greatly help investigators. In this project, we assess the state of popular tools presently available and find a way to improve one of them, the Autopsy software, more commonly known as The Sleuth Kit. Since a picture is worth a thousand words, the improvement here is to bring the power of rich visuals to an otherwise, mostly text-based boring interface. The said visuals are delivered by web-based components, which means they can be more responsive and dynamic as compared to what is available in the traditional programming languages in which Autopsy is developed. In addition, the purpose of this project is also to create a baseline of powerful visuals which can be improved upon by the active community of Autopsy users and developers.
Table of Contents
Click to expand Table of Contents
1 Introduction
1.1 Forensics
1.2 Digital Forensics
1.3 Forensics Tools
1.4 Problem Statement
1.5 Aims & Objectives
1.6 Research Questions
2 Literature Review
2.1 Themes
2.2 Purpose & Usage
2.3 Types of Forensics
2.3.1 Computer Forensics
2.3.2 Mobile Device Forensics
2.3.3 Network Forensics
2.3.4 Forensic Data Analysis
2.3.5 Database Forensics
2.4 Risks Involved
2.5 Benefits & Drawbacks
2.6 Common Usage Cases Examples
2.7 Existing Forensics Tools
2.7.1 Autopsy
2.7.2 Digital Forensics Framework (DFF)
2.7.3 EnCase Forensic
2.7.4 AccessData Forensic Toolkit (FTK)
2.8 Possibilities of Improvement
2.8.1 Visual Representation of Data in Forensic Tools
2.8.2 Cached Images
2.8.3 Language Translation
2.9 Chapter Summary
3 Methodology
3.1 Method of Research
3.2 Requirements Gathering
3.3 Project Plan
3.4 Estimated timeline of deliverables
3.5 Hardware Recommendation
3.6 Potential Tools & Technologies
3.7 Chapter Summary
4 Analysis
4.1 Functional Requirements
4.2 Non-Functional Requirements
4.3 Alternative Solutions
4.3.1 Porting Thumbcache Viewer
4.3.2 Adding translation capabilities
4.3.3 Correcting bugs in the toolkit
4.4 Proposed Solution
4.5 Chapter Summary
5 Design
5.1 Software Design Approach
5.2 Interface Design
5.3 System Modelling
5.3.1 Use-case Diagram
5.3.2 Class Diagram
5.3.3 Sequence Diagram
5.3.4 Web Components Model
5.4 Chapter Summary
6 Implementation
6.1 Implementation Issues
6.1.1 Size of input
6.2 Standards and Conventions
6.2.1 Java Coding Standard
6.2.2 Code & Naming Conventions
6.3 Development Tools & Environment Used
6.3.1 Hardware
6.3.2 Software
6.4 Implementation of Different Units
6.4.1 Java Autopsy Extension
6.4.2 Node.js / Express.js Server
6.4.3 Client-side JavaScript
6.5 Difficulties Encountered
6.6 Chapter Summary
7 Testing
7.1 Static Testing
7.1.1 Automatic Static Analysis Tool: PMD
7.1.2 White-box Testing: Inspection Process
7.2 Dynamic Testing
7.2.1 Black-box Testing
7.2.2 Unit Testing
7.3 Chapter Summary
8 Results & Conclusion
8.1 Results
8.2 Achievements
8.3 Difficulties
8.4 Future Works
References
List of Figures
Figure 1: Literature review themes
Figure 2: Autopsy logo from website
Figure 3: DFF logo from website
Figure 4: EnCase logo from website
Figure 5: AccessData FTK capabilities (AccessData, 2016)
Figure 6: The incremental model
Figure 7: Autopsy add-on placement
Figure 8: Wireframe – File types (count)
Figure 9: Wireframe – File types (size)
Figure 10: Wireframe – long paths
Figure 11: Wireframe – suspicious files
Figure 12: Wireframe – timeline of files
Figure 13: Wireframe – timeline of directories
Figure 14: Use-case diagram
Figure 15: Class diagram
Figure 16: Sequence diagram
Figure 17: Web components model
Figure 18: PMD results
Figure 19: Index of data received after two runs
Figure 20: Node’s console logs after two runs and index listing
Figure 21: Screenshot – success
Figure 22: Sample of more information displayed
Figure 23: Drilldown on Suspicious Files chart
Figure 24: Only description required is shown
Figure 25: Timeline of Files is zoomable
Figure 26: Unit test #1
Figure 27: Unit test #2
Figure 28: Unit test #3
Figure 29: Unit test #4
Figure 30: Unit test #5
Figure 31: Unit test #6
Figure 32: Major steps of usage
Figure 33: Autopsy screenshot
List of Tables
Table 1: Acronyms
Table 2: Benefits & drawbacks of digital forensics
Table 3: Strengths and weaknesses of Autopsy
Table 4: Strengths and weaknesses of Digital Forensics Framework (DFF)
Table 5: Timeline of deliverables
Table 6: Functional requirements
Table 7: Non-functional requirements
Table 8: Difficulties encountered during implementation
Table 9: Michael Fagan-inspired inspection checklist
Table 10: Tests
Table 11: Unit Tests
Table 12: Achievements
Table 13: Difficulties
List of Acronyms & Abbreviations
Table 1: Acronyms
| AJAX | Asynchronous JavaScript and XML |
| API | Application Program Interface |
| DOCX | Microsoft Word Open XML Format Document |
| DOM | Document Object Model |
| DFF | Digital Forensics Framework |
| FAT | File Allocation Table |
| GUI | Graphical User Interface |
| HTML | Hypertext Mark-up Language |
| ISO | International Organisation for Standardization |
| JNI | Java Native Interface |
| JS | JavaScript |
| JVM | Java Virtual Machine |
| LAN | Local Area Network |
| LNK | Link |
| NTFS | New Technology Files System |
| Portable Document Format | |
| RAM | Random Access Memory |
| RPM | Revolutions Per Minute |
| TSK | The Sleuth Kit |
| OS | Operating System |
| UDF | Universal Disk Format |
| UFS | Unix File System |
| UI | User Interface |
| USD | United States Dollars |
| WAN | Wide Area Network |
| XML | eXtensible Mark-up Language |
1 Introduction
1.1 Forensics
Forensics, or forensic science, relates to the application of science and its methods to find actionable proofs to be presented in a court or a judicial system in the context of a criminal investigation. It may prove the existence of a crime and disclose the perpetrator or someone’s connection to the crime. The forensic scientists, if properly qualified and recognised by a country’s judicial system, can stand in court as expert witnesses and testify against criminals or in favour of the innocent, on the basis of sheer proof through extensive examination of physical evidence and then examination, administration and reporting of data and tests. The truthful testimony of the expert witness can condemn the guilty or condone the innocent.
1.2 Digital Forensics
Digital forensics, or digital forensic science, is the branch of forensics concerned with the acquisition, analysis and manipulation of digital data mostly in relation to cybercrime. It involves computer forensics, including phone forensics, network forensics and forensic data analysis. A report from the First Digital Forensic Research Workshop (DFRWS) defined digital forensics as:
“The use of scientifically derived and proven methods toward the preservation, collection, validation, identification, analysis, interpretation, documentation and presentation of digital evidence derived from digital sources for the purpose of facilitating or furthering the reconstruction of events found to be criminal, or helping to anticipate unauthorized actions shown to be disruptive to planned operations.” (Palmer, 2001)
Digital forensics has found its use in multiple domains across the world, even in a country like Mauritius which has experienced a recent boom in technology. Everywhere and every time technology flourishes, it brings along the need for digital forensics as people will undoubtedly exploit this technology to satisfy their malicious intents. Digital forensics can direct investigators to the perpetrator; it can confirm or refute alibis and statements; it can help determine intent of a crime; it can be used to determine source of evidence and attest to its truthfulness (Casey, 2009).
1.3 Forensics Tools
Forensics tools are software applications used for the purpose of capturing data, analysing and making sense of captured by decoding it; these are the tools used in digital forensics. The results may be used to prove innocence or guilt or simply recover a deleted file. A simple use case of a forensic tool in a professional environment would be to scrutinise a suspected paedophile’s computer for any text (cookies, emails, documents, etc.) pertaining to child abuse or pornography. As such, a wide array of applications is readily available to be used by forensics investigators, the police, hackers, corporation employees as well as any computer user. A possible classification of such tools is given below (InfoSec Institute, 2014).
- Disk and data capture tools
- File viewing and analysis tools
- Registry analysis tools
- Internet analysis tools
- Email analysis tools
- Mobile devices analysis tools
- Mac OS analysis tools
- Network forensics tools
- Database forensics tools
1.4 Problem Statement
Over the recent years, a spiral in cybercrimes can be noticed, even in Mauritius (ICTA, 2010; Bignoux, 2012). Thus, as technology becomes omnipresent, our dependence on it increases. We all use machines to assist us in our tasks and information that is used by and transferred between them can be helpful to us or others. When required, forensics tools allow us to dig into these pieces of information and find the necessary proofs needed in investigation cases, even if they have been masked or hidden with anti-forensics tools (GCN, 2014). For example, a data recovery software can bring back deleted child pornography content from a suspect USB drive; more advanced software can match keywords related to such content from deleted documents and web history. As such attacks and exploits become more common, tools against these also need to improve. Tools having an abundance of features packed together cost a lot and freely available tools are not perfect – they contain bugs, have incomplete functionality or simply lack some desired features, such as rich report generators, cached image thumbnails parsers and on-the-fly document translators.
Autopsy has just a simple report generator able to process HTML and Excel sheet files. Paid tools can generate modern report formats such as PDFs and DOCX reports, along with visual descriptions like charts to better explain results of processing (AccessData, 2016; Mizota, 2013). This provides better insight on the result as better visualisation techniques to display information to digital forensic officers will help them direct their searches to suspicious files and not waste any more of their precious time. Teerlink & Erbacher, Jankun-Kelly et al. and Fowle & Schofeld have all demonstrated that visual representations indeed reduce the time taken to find evidences from loads of evidence data (Teerlink & Erbacher, 2006; Jankun-Kelly, et al., 2011; Fowle & Schofeld, 2011). And sadly, Autopsy still provides mostly textual representation of data processed from images. This is the main problem to be addressed in this thesis.
1.5 Aims & Objectives
The aim of this project is to find an area in which an existing freely available open-source forensics toolkit lacks functionality and develop an improvement to add to its value. The software in question is Autopsy for Windows OSes, a multipurpose forensics tool for forensics investigators as provided mainly by Brian Carrier (Carrier, 2016). Autopsy provides the interface to The Sleuth Kit (TSK) which is the core tool to perform digital forensics. The objectives are as follows:
- Study the Autopsy environment
- Find area which requires improvement or feature present in paid tools absent from Autopsy
- Implement said functionality
- Document development and tests performed along with usage cases
1.6 Research Questions
What does Autopsy lack that commercially available forensics tools have?
How can the existing digital forensics tools and features available in Autopsy be enhanced?
How has newly added features improved Autopsy’s usefulness to investigators?
2 Literature Review
This chapter builds on the Introduction chapter on digital forensics and concerns itself with an overview, the branches and some usage cases of digital forensics. A comparison of different digital forensic tools also entails, along with benefits and drawbacks of related tools. In addition, the visual representation of data and how they can be helpful in the digital forensics field is discussed.
2.1 Themes
Figure 1 below, shows main themes touched upon in this section.
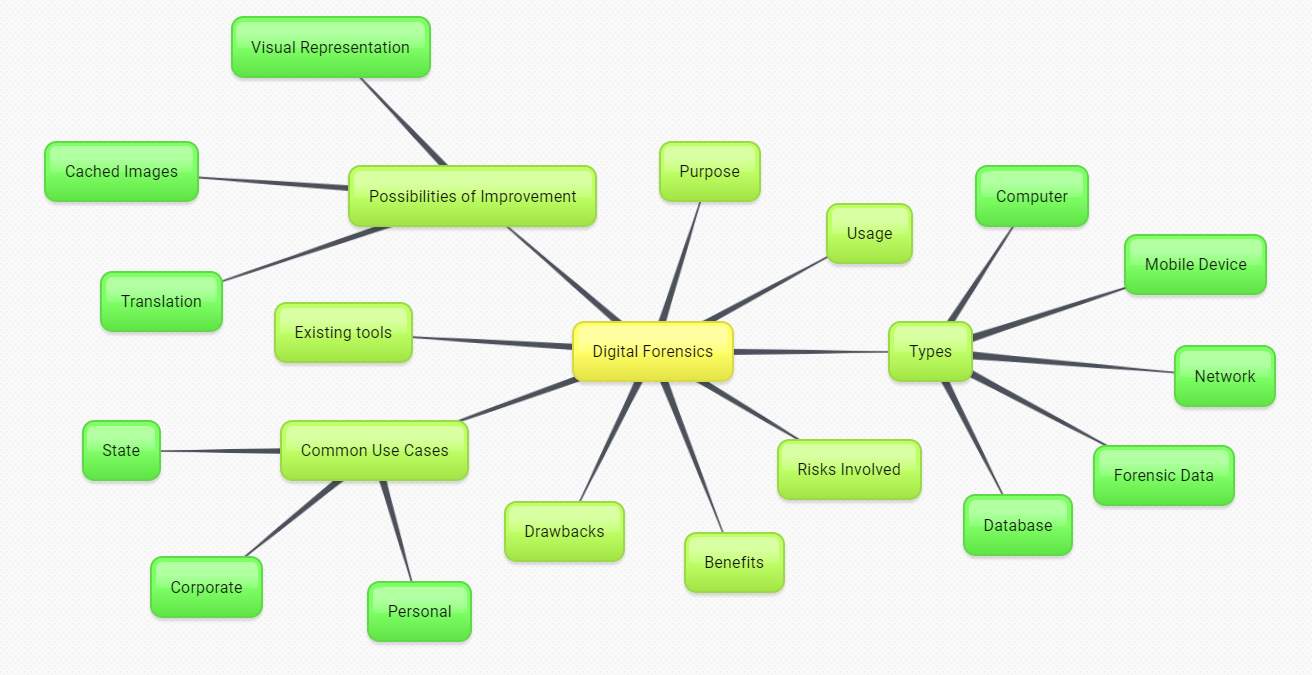
Figure 1: Literature review themes
2.2 Purpose & Usage
As mentioned in Chapter 1, digital forensics has proved to be quintessential in demystifying modern crimes. It now only concerns crimes committed in cyberspace, though. The purpose of digital forensics lie way beyond only technology. Digital forensics have helped solve crimes like murder, kidnapping and abuse, among others. A popular example is the case of Dennis Rader, the “Bind-Torture-Kill” serial killer who evaded the police for more than 30 years and was finally traced from a deleted word document contained in a floppy he himself sent to the police (Rosen, 2014). Digital forensics has repurposed traditional methods of investigation and shown promise in multiple fields of investigative work. Digital forensics uncover acts motivated by personal gain and targeted undercover activities.
2.3 Types of Forensics
Potentially, digital forensics can be divided into five branches, namely computer forensics, mobile device forensics, network forensics, forensic data analysis and database forensics (Srivastava & Vatsal, 2016).
2.3.1 Computer Forensics
The main aim of this sub-branch is to describe the present state of a digital artefact, the artefact being either a computer system unit, an electronic file or a storage medium (Yasinsac, et al., 2003). The usual target devices included are computers, embedded systems and static memory (Ngiannini, 2013), for e.g. desktop computers, MP3 players or pen drives. Computer forensics is applied to information ranging from routine logs and history in a web browser to physical files on an application server.
2.3.2 Mobile Device Forensics
Mobile device forensics pertains to forensics of mobile devices, with the major difference from computers being the integrated communication capability of the phones and its ability to be locate itself using either inbuilt GPS or with the base station’s location; this communication capacity adds SMS, emails and calls to the list of digital evidences (Srivastava & Vatsal, 2016). As both computers and smartphones evolve, the line of difference between computer forensics and mobile device forensics gets blurry.
2.3.3 Network Forensics
This relates to the capturing, recording and breakdown of events obtained from network traffic on any type of network (LAN or WAN), to ultimately collect evidence, detect intrusion, gather information (Palmer, 2001) or uncover the perpetrator of security attacks. Network forensics is complex owing to the bulky volume of data and their respective internet protocols that passes through a network (EC-Council, 2010).
2.3.4 Forensic Data Analysis
Forensic data analysis is used on structured data – obtained from software applications or their underlying databases, in contrast to files from mobile phones, for instance – which relates to occurrences of financial crime, for e.g. attacks on a bank’s system. The goal here is to find and examine patterns of duplicitous happenings, in order to spot and stop fraud, waste and abuse (Ernst & Young LLP, 2013).
2.3.5 Database Forensics
This is forensics on databases and their metadata, including the related contents, logs and data from volatile memory such as cache and RAM. Information in volatile memory may require live capture and analysis. It is similar to computer forensics. The information obtained is used to build a timeline of events and thus recover needed information (Srivastava & Vatsal, 2016).
2.4 Risks Involved
While performing digital forensics, there are inherent risks involved. Those risks need to be recognised so that an investigation can complete successfully. One of the major risks is the risk of losing integrity of evidence (Thakore, 2008); it is concerned with the preservation of the evidence as it was collected. To address this risk, the following may be done:
- Perform bit-stream imaging of disks before using them for anything else,
- Filter out inserted data by acquisition tools while performing live data capture and
- Perform regular copies of data or have multiple hard disks while performing live data capture to prevent overload of storage capacity.
Legal risks are also a worry in digital forensics. Before intercepting or analysing any type of data, it is necessary to be sure that one has the necessary permissions to do it. Mining personal information of employees may result in an abuse to their privacy and law enforcement will charge whoever is doing this once caught; abuse to privacy is, however, not well-defined (Austin, 2015). Similarly, law enforcement agencies cannot simply decide whether to intercept a tourist’s call without any warrant or good reason to do so. Thus, one should verify if any kind of digital forensics is legal or not.
Modifying a framework’s code or extending it requires strict adherence to conserving the integrity of the information. While Autopsy protects the data source by abstracting it (Carrier, 2017), any code should not be written that tries to manipulate the data source. Also, the information should not leave the system by any means. It should be well-confined since it may well be confidential information an investigator is dealing with. Moreover, everything that is processed by Autopsy should be included in our representation, unless it is completely irrelevant. Omitting applicable data will defeat the purpose of the new tool.
2.5 Benefits & Drawbacks
Table 2 lists some of the benefits of digital forensics and related tools, along with the drawbacks and challenges faced.
Table 2: Benefits & drawbacks of digital forensics
| Benefits | Drawbacks & Challenges |
| Faster than any human could sift through mountains of information | As storage capacities increase, difficult to find processing power to process digital information |
| More accurate than humans | Data can be easily modified or fabricated |
| Lots of heuristics available to better examine pieces of evidence | Experts are expensive to hire |
| Readily available software now available on the market | Can only pinpoint a device sometimes, and not the culprit who operated it |
| Can be applied to other types of investigations like rape and murder | Professional software cost a lot to use |
| Popularity and salaries has attracted many students; thus, more experts in the field | Resources required for optimal use of software is expensive to buy |
| Can be used to emulate a crime as it happened, providing insight to investigators |
2.6 Common Usage Cases Examples
Some common use cases of digital forensics as they occur in the modern world are outlined below.
- Law enforcement agencies and government
- Divorce cases (messages transmitted and web sites visited)
- Illegal activities (cyberstalking, hacking, keylogging, phishing)
- Corporate negligence investigation
- E-Discovery (recovery of digital evidence)
- Find deleted or hidden data in media
- Corporate
- Breach of contract (selling company information online)
- Intellectual property dispute (distributing music illegally)
- Employee investigation (Facebook at work)
- Personal
- Recover accidentally data from hard drives
- Find files lost in file system
2.7 Existing Forensics Tools
This section provides a description and appraisal of existing forensics tools, both freely available and commercially sold.
2.7.1 Autopsy
Features and objectives
Autopsy (Carrier, 2016) is a GUI version of The Sleuth Kit (TSK) command line tool. Its objective is to analyse disk images, drives or files and apply a multitude of features to generate a report of findings. It is used by home users, corporate examiners, the military and law enforcement to investigate events and analyse or recover data from a computer. The interface is built to be approachable to non-technical examiners and a wizard-style design has been adopted so as to guide the users through their tasks. Autopsy/TSK is among the top 22 popular tools in use as identified by the InfoSec Institute (InfoSec Institute, 2014) and was once found to be the most common open-source forensics tool in use (Hibshi, et al., 2011).

Figure 2: Autopsy logo from website
Functional requirements
The section below summarises the functional requirements addressed by the Autopsy tool (Carrier, 2016).
- Take inputs in raw, dd or E01 file formats
- Data recovery from unallocated space
- Has write blocker to protect integrity of disk or image
- Facilitates team collaboration by allowing multiple users on a case
- Analyse timeline of system events to identify activities
- Search and extract keywords through explicit terms or regular expressions
- Extract common web activity from browsers
- Identify recently accessed documents and USB drives
- Identify shortcuts through LNK files
- Parse and analyse emails of the MBOX format (used by Thunderbird)
- Extract EXIF information from JPEGs
- File type grouping and sorting
- Built-in image viewer and video playback
- Support analysis of multiple file systems (NTFS, FAT12/FAT16/FAT32/ExFAT, HFS+, ISO9660 (CD-ROM), Ext2/Ext3/Ext4, Yaffs2, UFS)
- Good and bad file filtering using known hash sets
- Tag and annotate files
- Extract strings from unallocated space or unknown file types
- Detect files by signature or extension mismatch
- Flag files based on name and path
- Extract Android data such as call logs and SMS
- Provide findings in HTML or Excel format
- Allow extensions via an add-ons API
Non-functional requirements
Autopsy/TSK was designed to consider the following non-functional requirements (Carrier, 2016).
- Be intuitive and easy to use by non-technical users
- Be extensible to accommodate third party plug-ins
- Be fast by making use of parallel cores in background
- Be quick to display results, that is, display as soon as one result obtained
- Be cost-effective to provide the same functionality as paid tools for free
Reviews
Table 3: Strengths and weaknesses of Autopsy
| Strengths | Weaknesses |
| Has very good documentation available online | User interface has lags on old machines |
| Has support of a whole community due to its common use | No native support for Outlook mail messages which is the most common email message formats |
| Is free | Latest version of Autopsy only available for Windows; Linux have to use TSK command line, older versions or build Autopsy themselves |
| Is extensible via plugins/scripts | |
| Easy to setup | |
| Still under active development; latest code commit made on 2016/10/28 on 2016/10/29 | |
| Has rich community of developers (12437 commits and 32 contributors (Autopsy Contributors, 2016)) |
2.7.2 Digital Forensics Framework (DFF)
Features and Objectives
DFF is an open source computer forensics platform designed to be simple and to allow automation of computer forensic investigation. It is provided for free and a professional extended version can also be purchased.

Figure 3: DFF logo from website
Functional Requirements
A summary of the functional requirements provided by the DFF software is provided below (ArxSys, n.d.).
- Consists of a write blocker to prevent integrity corruption
- Is compatible with raw, EnCase EWF and AFF file formats
- Does hash calculation
- Does file signature detection
- Has advanced filtering and search engine
- Can detect and mount partitions
- Compatible with VMDK, FAT12/16/32, NTFS. HFS/+/x, Ext2/3/4 file system formats
- Has inbuilt multimedia viewer and EXIF extractor
- Can parse shortcut files (LNK)
- Can analyse registry entries
- Can view and extract metadata from office documents
Non-functional Requirements
A summary of the non-functional requirements provided by the DFF software is provided below (ArxSys, 2015). The DFF team aims to be:
- Modular – this architecture allows to rapid improvement of the software and eases splitting of tasks among developers
- Extensible through scripts to provide more flexibility
- Genericity so as not to be OS specific and thus focus on larger audiences
Reviews
Table 4: Strengths and weaknesses of Digital Forensics Framework (DFF)
| Strengths | Weaknesses |
| Available for both Windows and Linux | Lack of proper documentation for use |
| Is extensible with scripts | Latest DFF code commit made on 2015/12/09 on 2016/10/29 |
| Has free version | Need to pay for more features |
| Has dying community of developers (183 commits and 3 contributors (ArxSys, 2015)) |
2.7.3 EnCase Forensic
Features and Objectives
EnCase forensic is a paid bundle of hardware and software which aims to quickly help you solve cases by giving actionable evidence acceptable to most courts (EnCase, 2016). It costs over USD 3500 and is provided by Guidance Software, Inc. Information provided is scarce due to lack of technical information on the proprietary software. At the time of writing, EnCase Forensic is at version 8.

Figure 4: EnCase logo from website
Functional Requirements
EnCase Forensic has all the features of the open-source software Autopsy and DFF and more. Some of the main requirement it aims to meet are:
- Run over multiple nodes to provide parallel processing
- Extract information from Active Directory
- Analyse hardware from registry and configuration files
- Native viewing for over 400 file formats
- Advanced file and keyword searching functionalities
- Advanced reporting capabilities
- Investigation from data of most email clients and instant messengers
- Support for most file systems including Palm and TiVo devices
More features can be found at (EnCase, 2008).
Non-functional Requirements
- Easy to use interface
- Provide flexible reporting solutions
Reviews
EnCase being a paid software could not be evaluated. Reviews are obtained from technology editor for SC Magazine, Dr P. Stephenson, a cyber criminologist, digital investigator, digital forensic scientist, researcher and lecturer on cyber threat analysis, cyber criminology and cyber jurisprudence (Stephenson, 2014).
“Strengths: Solid product in the EnCase tradition. While the new UI is challenging at first, there are lots of capabilities and new features, including decryption, mobile device analysis and prioritized processing.
Weaknesses: A bit rough over the network when evidence is not at the processing computer.
Verdict: Pretty much what one would expect from Guidance – solid performance, excepting the network issue – and loads of features to make the forensic analyst’s job easier and faster.”
2.7.4 AccessData Forensic Toolkit (FTK)
Features and Objectives
FTK is a forensic software built for speed, stability and ease of use. Its initial license costs nearly USD 4000 and support costs over USD 1000. It is developed by AccessData and boasts of a 5-star review from SC Magazine for 3 years in a row (AccessData, 2016).
Functional Requirements
The functional requirements as met by AccessData FTK can be summarised in Figure 5 below. This is the only official source of features provided by the software.
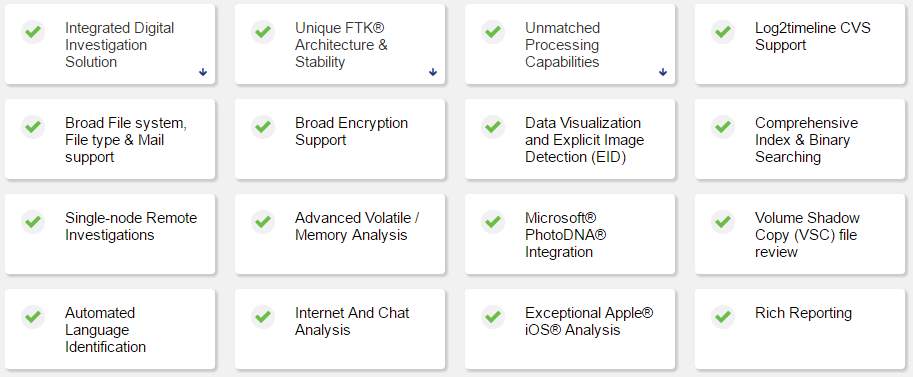
Figure 5: AccessData FTK capabilities (AccessData, 2016)
Non-functional Requirements
AccessData FTK aims to:
- Be able to handle massive data sets
- Provide stability and processing speeds that outdo competitors
- Do quick and accurate reporting on relevant investigation material
- Provide a centralised location for reviewing data and identity relevant evidence
Reviews
As for EnCase, FTK also could not be evaluated. The information comes from Dr Stephenson (Stephenson, 2016).
“Strengths: Reliability, performance, logical, procedure-focused user interface and improved analytics.
Weaknesses: None that we found.
Verdict: This is a heavyweight general-purpose cyber forensic tool with a lot of features, add-ons and built-in power. It has been SC Lab Approved for the past two years and we continue that for another year. Next year, at the end of its current tenure in the lab, we will present a special production-oriented review.”
2.8 Possibilities of Improvement
This section tries to compare different ways an open-source forensics toolkit can be improved upon, along with providing reasons as to why such improvements would be useful to the user community.
2.8.1 Visual Representation of Data in Forensic Tools
The human brain processes visual information faster than it processes textual information (Thermopylae Sciences + Technology, 2014). This allows for faster transmission of messages and thus faster comprehension, along with the benefit of the information being retained for a longer period of time in any individual’s memory (Burmark, 2002). Investigators are human beings, and human beings make mistakes. It is very likely that a person focuses on unimportant clues for a long time and gets tired. In that situation, he may disregard a similar but decisive clue moments later. A visual representation of data minimises the probability of this happening since it is less cluttered and easier on the eyes.
Textual data results in waste of time for forensic specialists as they sift through massive amounts of uncorrelated, unrelated and meaningless data to reach the particular information that really is of interest. A picture is indeed worth a thousand words and its meaning is transmitted faster and better than words. The brain has the innate ability to process graphics such as images, charts and video in parallel while text can only be processed serially (Kelsey, 1997).
Teerlink and Erbacher demonstrated that forensics analysts indeed performed better when paired with visual aids (Teerlink & Erbacher, 2006). They compared performances between manually searching through a Linux file system using commands and then providing visual aid to the researchers to help them. Using the visual aids, the first suspicious file was found 57% faster and the total overall reduction in time was of 35%. The mean time to locate the next file of interest was 8.8 minutes using their forensics software as compared to 13.7 minutes with the execution and results of Linux commands only.
The contemporary world and its dependence on digital forensics requires investigators to make use of innovative technologies to collect, study and present evidence to necessary parties such as courts. The primitive requisite of a digital forensic tool is to view specific files in a human-friendly format for scrutiny. This process of analysis is slow and tedious. Good visual interfaces and visualisations can immensely reduce the time it takes to investigate data, as well as help users gain an overview of the said data without causing information overload and loss, spot patterns and incongruities in it and so lessen inaccuracies and tediousness (Lowman & Ferguson, 2010).
2.8.2 Cached Images
In computer and mobile forensics, sometimes culprits make sure that they annihilate everything that they use. For example, someone dealing with media containing child pornography may delete everything he had kept stored when suspicions of police investigation arise. He could even replace the files with decent files so as to mask what had been stored. This way, during police investigation, no evidence would be would be found on his computer. However, operating systems like Windows and Android keep records of thumbnails of images. This is done to speed up the preview of images while someone is on a particular folder. This cache is hidden from users, but not from the system. The cache can be retrieved and examined, leading to the discovery of what media were being kept in that space.
This cache space, commonly known as “thumbcache” under Windows, is unknown to many users; if the thumbnail cache files do exist, this means that the operating system had to preview those images to the user (Parsonage, 2012), making the user guilty.
An example of thumbnail cache helping in a case is a case in the UK whereby original images were deleted and only cached thumbnail images were able to be retrieved (Quick, et al., 2014). Commercial tools like AccessData FTK and EnCase already provide thumbnail parsing (Quick, et al., 2014). There are standalone tools available to examine the cache files, namely the open-source “Thumbcache Viewer” (thumbcacheviewer, 2016) and the older “Vinetto.” (Roukine, 2008)
2.8.3 Language Translation
In a connected world, an investigator is sure to find documents and media from storage medium that are in a foreign language. Bringing in translators of each of the found languages is a costly and time-consuming activity. Adding translators to forensics toolkits would help investigators elucidate crimes in a timely manner, without incurring any additional expense. Several translation APIs are available online for common languages. Machine translation is also a reality; that is, translating media such as audio, video and movies. One example of such a software is SDL BeGlobal (Bara, 2014) which is aimed at machine translation for digital forensics practitioners.
2.9 Chapter Summary
This chapter has explored digital forensics, its purpose and usage and the different types we have. The risks involved in digital forensics are also mentioned, along with some possible benefits and drawbacks, or rather challenges that this field faces. Additionally, examples of usage case are provided. Next, an analysis of existing forensics tools, both commercial and freely available, is provided. Finally, possible enhancements to the Autopsy forensics toolkit are discussed.
3 Methodology
This chapter deals with defining the methods and techniques to be used for the software development life cycle and how the goals of the project and the resources available are to be aligned to fit together.
3.1 Method of Research
The qualitative methodology is chosen for this project since firstly, it is based off opinions of and comments from a community of users spread across the globe. The current state of the problem is to be assessed and a possible solution will be provided. Related forums, discussions and articles will be read and analysed before concluding how to answer this project’s questions. Existing paid tools will be investigated and possible improvements will be identified. Finally, a solution will be proposed, implemented and tested.
3.2 Requirements Gathering
As the goal of this project is to improve an open-source digital forensics toolkit, in all fairness, the requirements are best taken from the community of users supporting the software. Thus, the main source of requirements will be the git repository of the application and the related issues, along with suggestions and gaps denoted by research papers on the software and related topics; most of which have been discussed in the second chapter.
3.3 Project Plan
Requirements will be extracted from the project’s aims and online users’ comments and experiences with the software. Upon requirements gathering, the subsequent stages will be analysis and design of the software component. Incremental software development allows implementation, integration and testing of distinct incremental builds. Each increment will be validated and then, the necessary amendments will be made. As testing ensues, omitted or improper functionalities will be adjusted. Breaking software in manageable bits makes it easier to program, test and debug. The incremental model is also flexible to consider any additional feature established after development has initiated. Figure 6, illustrates the incremental model.
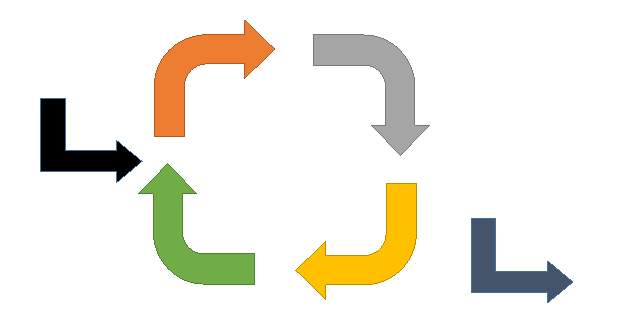
Figure 6: The incremental model
Supervisor meetings should be conducted monthly to validate progress and discuss on issues raised. On-going communication should occur via calls and emails.
3.4 Estimated timeline of deliverables
Table 5 details the timeline of deliverables with their estimated date of completion.
Table 5: Timeline of deliverables
| Task | Estimated Date of Completion |
| Introduction | October 31, 2016 |
| Background study | November 30, 2016 |
| Analysis | November 30, 2016 |
| Design | December 10, 2016 |
| Report writing | March 31, 2017 |
| Autopsy investigation | December 1, 2016 |
| Development | January 31, 2017 |
| Testing and Results | February 28, 2017 |
3.5 Hardware Recommendation
The tentative hardware to be used for this project is as follows:
- Intel Core i5 processor
- 8 GB of RAM
- 512 GB hard drive
The hardware setup is average enough to ensure maximum compatibility with other current systems. The threading capabilities is capitalised upon by the Autopsy software (Autopsy, 2016), thus multiple threads are spawned for mutually-exclusive processing jobs.
3.6 Potential Tools & Technologies
The Autopsy platform is developed in Java. Add-ons however can be developed in either the Java language itself or Python.
Java
The Java programming language is an option to extend the Autopsy platform. Java is a compiled language which runs in its own environment called the Java Virtual Machine.
Python
The Python programming language is also an option to extend Autopsy’s functionality with add-ons. Python is an interpreted language and is usually simpler to program than Java.
In order to develop the software, an IDE will be required. The possibilities are:
NetBeans Java IDE
This is the recommended IDE since proper documentation is provided in the Autopsy technical documentation.
Eclipse IDE
Eclipse is also an IDE to program in Java. Eclipse IDE is open-source and extensible by free plugins.
Sublime Text 3
Alternatively, a text editor can be used to write programs in both Java and Python.
To represent data visually, a library will need to be used. The possibilities are:
DynamicReports
DynamicReports (Mariaca, 2017) is a free and open-source Java reporting tool which may aid in building charts for Autopsy.
JFreeChart
JFreeChart (JFreeChart, 2014) is an alternative to DynamicReports capable of also generating charts in Java.
Instead of generating charts in Java, JavaScript can be given the job. JavaScript, being a web technology, can provide better, more responsive ways to represent data. There is also more support for JavaScript in the world of visual information than in Java, since JavaScript is more widely used on the web. A framework will need to be added to tunnel information from Java to JavaScript smoothly.
Express.js
A node server can be used to handle information to be transferred between Java and JavaScript. Express.js is a simple, light-weight web server that can deploy a node application in seconds.
Highcharts JS
Highcharts JS is a popular charting library used to make stunning visuals of data. It is free for personal use but costly for enterprise use.
Vinetto
Vinetto is a forensics tool to identify Thumbs.db files from the Windows file systems. The last update was in 2008.
ThumbCache Viewer
Thumbcache Viewer allows extraction of thumbnail images from the thumbcache_*.db and iconcache_*.db database files which are created by Windows systems.
Google Translate API
The Google Translate API is a translation provider but is no longer free.
Bing Translator API
The Bing Translator is an alternative translator which is currently free.
3.7 Chapter Summary
The methodology chapter has started with defining the method of research to be used in this project. Next, the requirements gathering process and project plan has been presented, followed by a timeline of deliverables. Finally, the possible hardware and software are mentioned.
4 Analysis
This chapter contains the functional and non-functional requirements of the system along with alternative possible solutions and the proposed solution.
4.1 Functional Requirements
The requirements detailing the technical functionality of the system (what it should do) is presented in Table 6 below.
Table 6: Functional requirements
| ID | Description |
| FR1 | The system shall parse image files uploaded into Autopsy. |
| FR2 | The system shall calculate types of files present in a data source. |
| FR3 | The system shall calculate sizes of different file types present in a data source. |
| FR4 | The system shall watch for suspicious folder paths. |
| FR5 | The system shall maintain a library of known suspicious files. |
| FR6 | The system shall compare found files with the library of known suspicious files. |
| FR7 | The system shall build a timeline of files’ creation, access and modification dates. |
| FR8 | The system shall build a timeline of directories’ creation, access and modification dates. |
| FR9 | The system shall generate interactive charts to represent all mined information. |
| FR10 | The system shall provide additional information to user about suspicious files found. |
4.2 Non-Functional Requirements
The requirements detailing under which constraints the system (how it should do) will run is presented in Table 7.
Table 7: Non-functional requirements
| ID | Description |
| NFR1: Usability | The system shall not add any complexity for the user of the Autopsy platform. |
| NFR2: Robustness | The system shall handle all kinds of possible errors and react accordingly. |
| NFR3: Scalability | The system shall adapt to changes in operating system, processor and/or memory architecture and number of cores and/or processors. |
| NFR4: Platform independence | The system shall be easily executable on any operating system Autopsy can be installed on. |
| NFR5: Maintainability | The system’s code shall be comprehensible and extensible easily. |
| NFR6: Data integrity | The system shall not, in any way, affect the integrity of the data it handles. |
| NFR7: Security | The system shall protect data and not let it leak outside the system. |
| NFR8: Performance | The system shall not cripple a system so as to make it unusable. |
4.3 Alternative Solutions
This section details some possible solutions thought of that will improve an open-source forensics toolkit. The proposed solution comes afterward.
4.3.1 Porting Thumbcache Viewer
One solution to build on is to enhance Autopsy with a port of Thumbcache Viewer. Thumbcache Viewer was originally developed in the C and C++ programming languages. The program’s source code could be re-written from scratch in either Java or Python to be a compatible Autopsy add-on. Alternatively, Java Native Interface (JNI) could also be used to call the C/C++ program. The latter option requires the original program to be compiled as a DLL file, which is to be called from Java. Such a feature has been requested by the Autopsy community and has been acknowledged by the program’s main developer (Carrier, 2016). This option was not chosen because it focuses only on one set of operating systems, namely the Windows operating systems.
4.3.2 Adding translation capabilities
A much-needed functionality when dealing with criminal investigation of a global scale is the possibility to quickly understand multiple languages. Thus, the use of Google translate APIs or Bing translate APIs could be made to help investigators. The translation capability would have to be provided for any text from any file, detected to be in a language other than the native language. Coincidentally, this feature has already been requested by the community; the issue number is 137 (Adam, 2013). This solution was not chosen because of the lack of free, decent and open-source APIs to perform translation. Google Translate, arguably the best translation service available today, has scrapped its API due to abuse from developers (Google Cloud Platform, 2017).
4.3.3 Correcting bugs in the toolkit
At the time of writing, the Autopsy community shows nine open issues ranging from the 2012 and 2014 timeframe (Autopsy Issues, 2017). Most of the issues have already been fixed in newer versions of the program and the rest are trivial or specific to certain use cases, and thus do not affect the general community of users and developers. If the issues were blocking or fixing them would greatly help the Autopsy community, a solution would be to fix those issues. Any software program needs to be maintained to be usable. New user cases always arise and bugs will inevitably be found. This solution was not chosen since there exists no major bugs at the time.
4.4 Proposed Solution
The proposed solution, that is, the improvement suggested is to make Autopsy’s results more visual. Paid forensics software greatly aid users with the use of charts and diagrams to represent otherwise monotonous and easily omitted information. As discussed in chapter 2’s Visual Representation of Data’s section, the advantages brought by graphics is undeniable.
To begin with, a parser will be developed to read and analyse the data input into Autopsy. The parsing will be initiated by Autopsy itself since it is an add-on. This process will have to be able to run on a multi-threaded architecture; therefore, care should be taken to keep all variables and methods thread-safe, as well as taking maximum advantage of concurrency without sacrificing CPU time waiting for blocking operations. Next, the parsed data will be expressed in a universal format called JSON and then passed to a middleware application responsible for serving the data to demanding parties. The demanding party is the client or consumer application which will take the JSON string and convert it from textual to a visual representation. The client-side JavaScript is responsible for making sense of all the data received.
4.5 Chapter Summary
The analysis chapter has started with defining the functional and non-functional requirements of the project. Then, alternative solutions to the problem of improvement were discussed. Finally, the proposed solution has been explained.
5 Design
The design chapter presents the approach to be used for building the system. It also provides the tentative models that the system will adhere to.
5.1 Software Design Approach
The sensible choice for this project was the top-down design methodology. Top-down design, or stepwise refinement, is the breaking down of an intricate and large problem into numerous units, where each unit is additionally broken down until the sub-units realise only one precise job. Hence, these sub-units are easily understood and implemented as well as simpler to debug.
Benefits of stepwise refinement:
- Stepwise refinement improves code readability because fewer lines of codes are easily read and processed.
- Fragmenting a problem into components makes coding more effective since a developer can work on one specific module at a time and perfect it
- Understanding a complicated problem by breaking it into many condensed sub-problems is easier.
- It is much easier to add and edit functions which add new functionalities in the project.
- Fragmenting the code simplifies testing since smaller and autonomous components are easier to debug as compared to a huge code base.
5.2 Interface Design
The screen where Autopsy will display the add-on is the File Ingest module window used to configure a data source. This is the case for all ingest modules that extend Autopsy. Figure 7 depicts this screen.
Module will appear in this list.
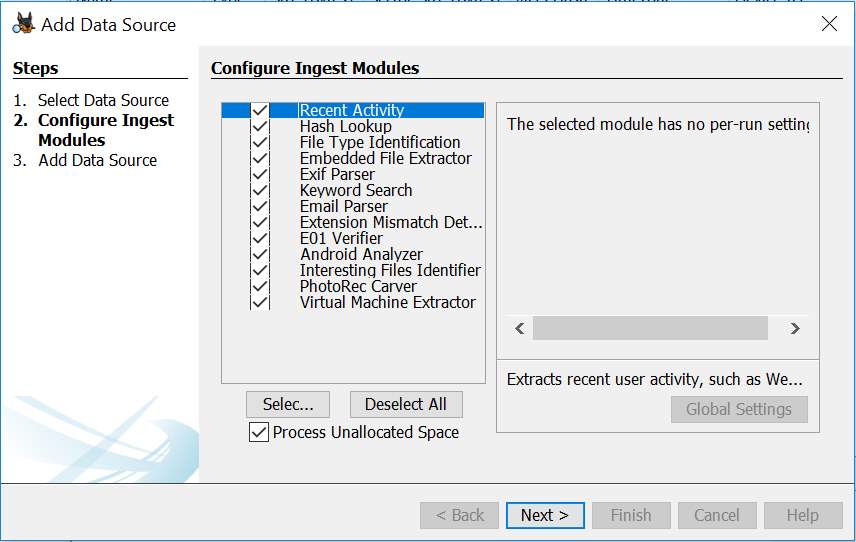
Figure 7: Autopsy add-on placement
The visual representation will follow the below wireframes or mock-ups.
Figure 8: Wireframe – File types (count)
Figure 9: Wireframe – File types (size)
Figure 10: Wireframe – long paths

Figure 11: Wireframe – suspicious files
Figure 12: Wireframe – timeline of files
Figure 13: Wireframe – timeline of directories
5.3 System Modelling
This section models the system to be developed. It does so by depicting use cases, class diagrams and sequence diagrams. A model of the web components used also follows.
5.3.1 Use-case Diagram
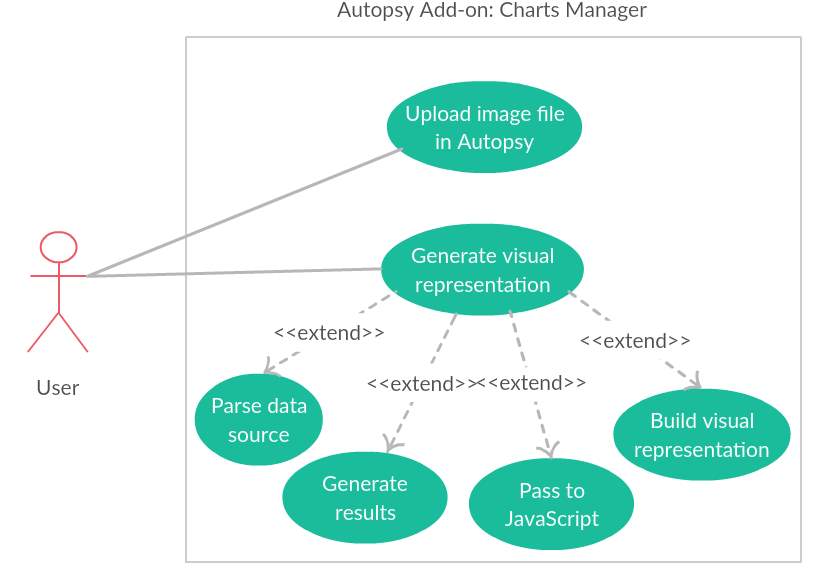
Figure 14: Use-case diagram
5.3.2 Class Diagram
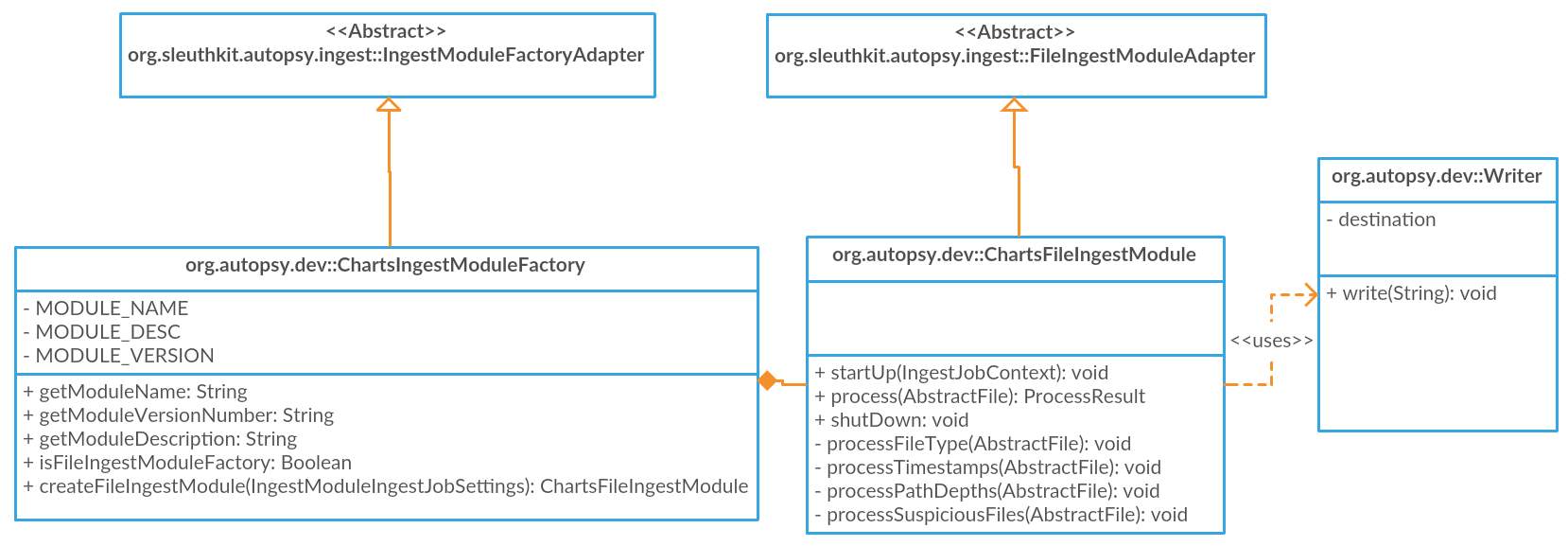
Figure 15: Class diagram
5.3.3 Sequence Diagram
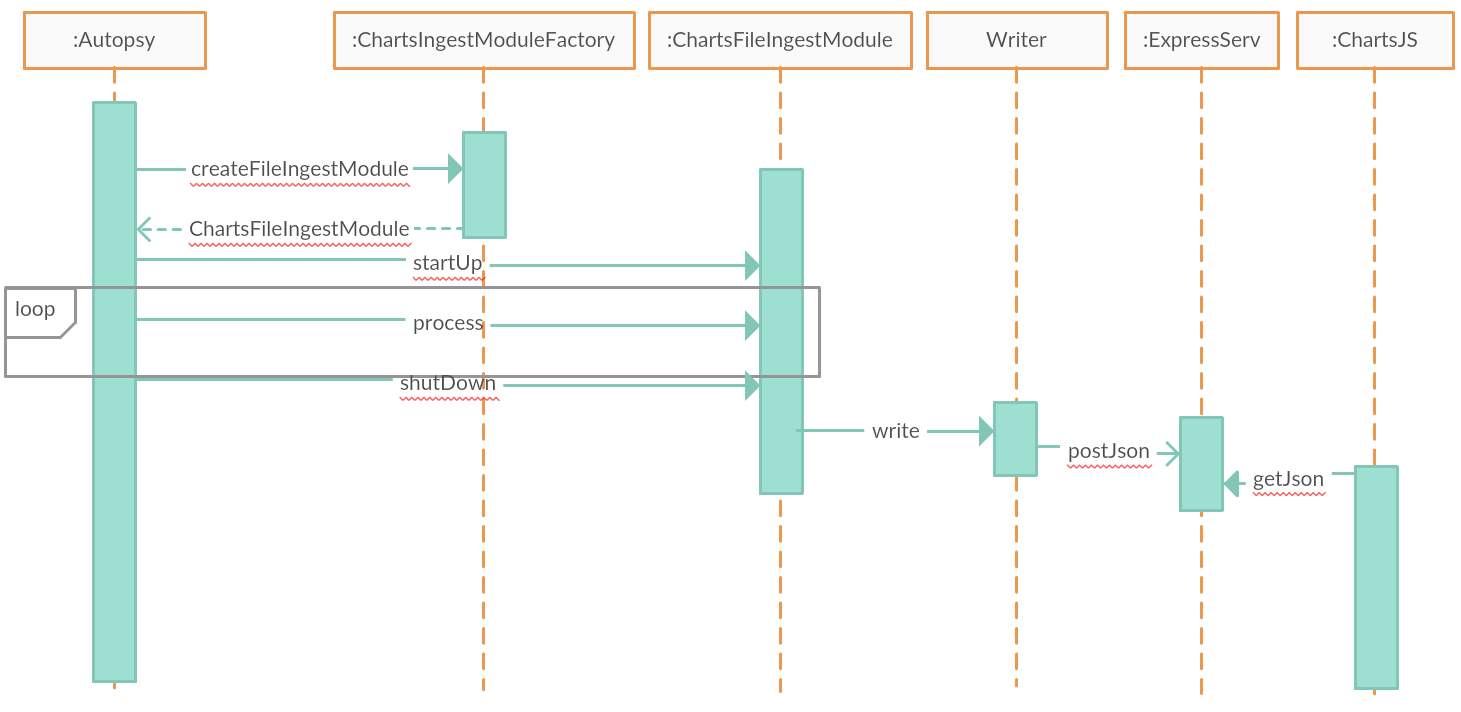
Figure 16: Sequence diagram
5.3.4 Web Components Model
This model details how the components generally link to each other.
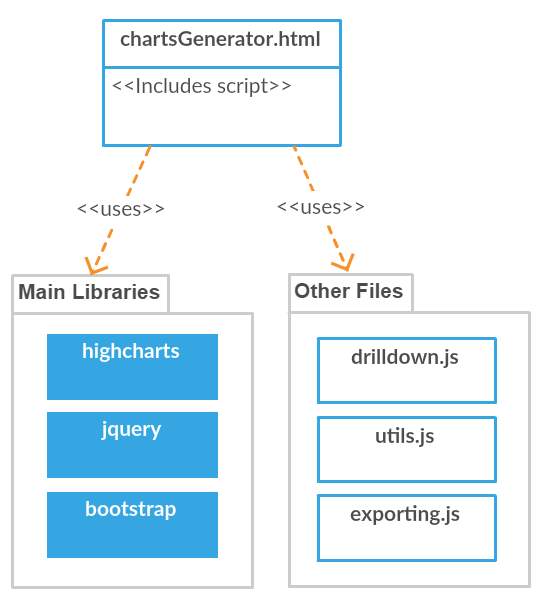
Figure 17: Web components model
5.4 Chapter Summary
This chapter has defined the software design approach to be used in the project. Next, an interface design was provided, along with models of how the system will be implemented.
6 Implementation
This chapter contains the details of implementation issues, standards, conventions and development tools used. The implementation of different components has also been conversed. Example codes have likewise been provided for the components discussed. Lastly, the technical difficulties during implementation are described.
6.1 Implementation Issues
6.1.1 Size of input
Processing and parsing information from virtual images is a compute-intensive process which requires much CPU time along with generous RAM capacity. Even a 512-gigabyte disk image with only 2 gigabytes used will have to be processed for 512 gigabytes since not all OSes store data serially and there is always the possibility of hidden and overwritten data elsewhere on the disk. Due to the aforesaid problem and resource limitations, small image sizes of less than 1024 megabytes will have be used so implementation is efficient and not too time-consuming. However, to ensure scalability with respect to images sizes, care will be taken not to write any code which has exponential time complexity.
6.2 Standards and Conventions
6.2.1 Java Coding Standard
SEI CERT Oracle Coding Standard for Java was used to broadly define the rules to respect while developing the system, to limit developer assumptions and bugs. This coding standard specifies rules such as those mentioned below. (McManus, 2017):
- Declarations and Initializers
- “Do not reuse public identifiers from the Java Standard Library”
- “Do not modify the collection’s elements during an enhanced for statement”
- Expressions
- “Do not ignore values returned by methods”
- “Do not use a null in a case where an object is required”
- Object Orientation
- “Limit accessibility of fields”
- “Do not return references to private mutable class members”
- Methods
- “Do not use deprecated or obsolete classes or methods”
- “Do not increase the accessibility of overridden or hidden methods”
- Thread APIs
- “Do not invoke Thread.run()”
- “Do not use Thread.stop() to terminate threads”
6.2.2 Code & Naming Conventions
Best-practice naming conventions are to be respected to distinguish between class names, function names and attribute identifiers among others. Some naming conventions are:
- Class names will be in title case, that is, the first letter of every word will be uppercase and it will contain no spaces. For e.g. FileIngestModule
- Methods and attributes will be written as camel case, that is, all first letters of words will be in uppercase except for the starting word. For e.g. fileType.
- Attributes declared as static will be written in uppercase and will contain underscores instead of spaces.
To facilitate reading, declarations are to be done centrally at the top. Modifiers will be explicitly written ant not left to conjecture. Indentations will be respected and large blocks of code will be annotated, unless the logic is made explicit through naming and function calls.
6.3 Development Tools & Environment Used
The machine configuration used for the implementation of the software is offered below.
6.3.1 Hardware
The hardware configuration used for development are:
- Processor: Core i5 clocked at 2.40 GHz
- RAM: 8 GB
- Hard disk: 512 GB at 5400 RPM
6.3.2 Software
The software used during the development are:
- Windows 10 Professional 64-bit
- Java as the programming language to extend Autopsy
- NetBeans Java IDE to develop in Java
- Autopsy Platform
- Sublime Text 3 to develop JavaScript programs
- Gson to convert serialise Java objects into JSON
- Node.js to build Express.js application
- Express.js to handle communication between Java and JavaScript
- JQuery to facilitate DOM manipulation
- Bootstrap for styling and UI logic
- Highcharts JS to create dynamic and responsive charts
6.4 Implementation of Different Units
6.4.1 Java Autopsy Extension
This part of the software is the one which required the most knowledge about Autopsy. Autopsy’s framework, its APIs, how it handles files along with everything it provides to be extended had to be learned and tested. A class named ChartsIngestModuleFactory.java was created to advertise the methods that Autopsy needs to know about in order to call the custom methods correctly. This class inherits from IngestModuleFactoryAdapter from the org.sleuthkit.autopsy.ingest package namespace. It contains attributes and provides methods to describe the add-on and how it should appear in the Autopsy File Ingest Modules menu. Below are some parts of the code from the class.
package org.autopsy.dev;
import org.openide.util.lookup.ServiceProvider;
import org.sleuthkit.autopsy.ingest.DataSourceIngestModule;
import org.sleuthkit.autopsy.ingest.FileIngestModule;
import org.sleuthkit.autopsy.ingest.IngestModuleFactory;
import org.sleuthkit.autopsy.ingest.IngestModuleFactoryAdapter;
import org.sleuthkit.autopsy.ingest.IngestModuleIngestJobSettings;
@ServiceProvider(service = IngestModuleFactory.class)
public class ChartsIngestModuleFactory extends IngestModuleFactoryAdapter {
private static final String MODULE_NAME = “Charts Manager”;
private static final String MODULE_DESC = “Helps forensic officers by providing easier and ….”;
private static final String MODULE_VERSION = “0.1.0”;
@Override
public String getModuleDisplayName() {
return MODULE_NAME;
}
@Override
public String getModuleDescription() {
return MODULE_DESC;
}
@Override
public String getModuleVersionNumber() {
return MODULE_VERSION;
}
/* Overridden DataSource Ingest Module options go here */
@Override
public boolean isFileIngestModuleFactory(){
return true;
}
@Override
public FileIngestModule createFileIngestModule(IngestModuleIngestJobSettings ingestOptions) {
return new ChartsFileIngestModule();
}
}
The actual class responsible for parsing the files’ information is named ChartsFileIngestModule.java and it extends from ChartsFileIngestModule, which is also from the org.sleuthkit.autopsy.ingest namespace. Codes from the class are presented below.
package org.autopsy.dev;
import com.google.gson.Gson;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import org.openide.util.Exceptions;
import org.sleuthkit.autopsy.ingest.FileIngestModuleAdapter;
import org.sleuthkit.autopsy.ingest.IngestJobContext;
import org.sleuthkit.datamodel.AbstractFile;
import org.sleuthkit.datamodel.Content;
import org.sleuthkit.datamodel.TskCoreException;
/**
*
* @author Azhar
*/
public class ChartsFileIngestModule extends FileIngestModuleAdapter {
public static ConcurrentHashMap
public static ConcurrentHashMap
public static ArrayList
private static String suspectExtDict = “SuspiciousFileExts.csv”;
HashMap
public static ConcurrentHashMap
@Override
public void startUp(IngestJobContext context) {
fileTypes = new ConcurrentHashMap();
timestamps = new ConcurrentHashMap();
timestamps.put(“directories”, new HashMap
timestamps.put(“files”, new HashMap
pathDepths = new ArrayList();
try {
suspectMap = getSuspectMap();
} catch (IOException ex) {
throw new Error(ex.getCause());
}
suspiciousFiles = new ConcurrentHashMap();
}
private HashMap
FileInputStream fstream = null;
BufferedReader br = null;
fstream = new FileInputStream(suspectExtDict);
br = new BufferedReader(new InputStreamReader(fstream));
String strLine;
HashMap
HashMap
String ext, type, description;
String lineParts[];
while ((strLine = br.readLine()) != null) {
lineParts = strLine.split(“\|”);
ext = lineParts[0]; type = lineParts[1]; description = lineParts[2];
details = new HashMap();
details.put(“type”, type);
details.put(“description”, description);
extToDetails.put(ext, details);
}
br.close();
return extToDetails;
}
@Override
public ProcessResult process(AbstractFile af) {
processFileType(af);
processTimestamps(af);
processPathDepths(af);
processSuspiciousFiles(af);
return ProcessResult.OK;
}
private void processFileType(AbstractFile af) {
try {
if (af.isFile()) {
HashMap
fileTypes.put(af.getNameExtension(), map);
}
} catch (TskCoreException ex) {
Exceptions.printStackTrace(ex);
}
}
private HashMap
if (currentMap == null) {
currentMap = new HashMap();
currentMap.put(“count”, 1);
currentMap.put(“size”, fileSize);
HashMap
fileMap.put(“name”, fileName);
fileMap.put(“size”, fileSize);
fileMap.put(“path”, filePath);
ArrayList
files.add(fileMap);
currentMap.put(“files”, files);
return currentMap;
} else {
currentMap.put(“count”, (int)currentMap.get(“count”) + 1);
currentMap.put(“size”, (long)currentMap.get(“size”) + fileSize);
ArrayList
HashMap
fileMap.put(“name”, fileName);
fileMap.put(“size”, fileSize);
fileMap.put(“path”, filePath);
files.add(fileMap);
return currentMap;
}
}
private void processTimestamps(AbstractFile af) {
if (af.isDir()) {
try {
HashMap
HashMap
dirDetails.put(“children_count”, af.getChildrenCount());
List
List
HashMap
for (Content c : lstChildren) {
child = new HashMap();
child.put(“name”, c.getName());
child.put(“size”, c.getSize());
child.put(“path”, c.getUniquePath());
children.add(child);
}
dirDetails.put(“children”, children);
directories.put(af.getName(), dirDetails);
timestamps.put(“directories”, directories);
} catch (TskCoreException ex) {
Exceptions.printStackTrace(ex);
}
}
if (af.isFile()) {
HashMap
HashMap
fileDetails.put(“size”, af.getSize());
files.put(af.getName(), fileDetails);
timestamps.put(“files”, files);
}
}
private HashMap
try {
HashMap
details.put(“path”, af.getUniquePath());
details.put(“created_date”, af.getCrtimeAsDate());
details.put(“modified_date”, af.getMtimeAsDate());
details.put(“accessed_date”, af.getAtimeAsDate());
return details;
} catch (TskCoreException ex) {
Exceptions.printStackTrace(ex);
}
}
private void processPathDepths(AbstractFile af) {
try {
if (af.isDir()) {
HashMap
pathDetails.put(“name”, af.getName());
String path = af.getUniquePath();
pathDetails.put(“path”, path);
int depth = 0;
for(int i=0; i
if(path.charAt(i) == ‘/’) {
depth++;
}
}
pathDetails.put(“depth”, depth);
pathDetails.put(“children_count”, af.getChildrenCount());
List
List
HashMap
for (Content c : lstChildren) {
child = new HashMap();
child.put(“name”, c.getName());
child.put(“size”, c.getSize());
child.put(“path”, c.getUniquePath());
children.add(child);
}
pathDetails.put(“children”, children);
pathDepths.add(pathDetails);
}
} catch (TskCoreException ex) {
Exceptions.printStackTrace(ex);
}
}
private void processSuspiciousFiles(AbstractFile af) {
try {
if (!af.isFile()) return;
String nameExt = af.getNameExtension();
if (nameExt == null) return;
if (nameExt.equals(“”)) return;
if (!suspectMap.containsKey(nameExt)) return;
HashMap
map.put(“type”, suspectMap.get(nameExt).get(“type”));
map.put(“description”, suspectMap.get(nameExt).get(“description”));
suspiciousFiles.put(nameExt, map);
} catch (TskCoreException ex) {
Exceptions.printStackTrace(ex);
}
}
private HashMap
if (currentMap == null) {
currentMap = new HashMap();
HashMap
fileMap.put(“name”, fileName);
fileMap.put(“size”, fileSize);
fileMap.put(“path”, filePath);
ArrayList
files.add(fileMap);
currentMap.put(“files”, files);
currentMap.put(“count”, 1);
currentMap.put(“size”, fileSize);
} else {
ArrayList
HashMap
fileMap.put(“name”, fileName);
fileMap.put(“size”, fileSize);
fileMap.put(“path”, filePath);
files.add(fileMap);
currentMap.put(“count”, (int)currentMap.get(“count”) + 1);
currentMap.put(“size”, (long)currentMap.get(“size”) + fileSize);
}
return currentMap;
}
@Override
public void shutDown() {
Gson gson = new Gson();
HashMap
motherJson.put(“file_types”, fileTypes);
motherJson.put(“timestamps”, timestamps);
motherJson.put(“path_depths”, pathDepths);
motherJson.put(“suspicious_files”, suspiciousFiles);
String json = gson.toJson(motherJson);
(new Writer()).write(json);
}
}
6.4.2 Node.js / Express.js Server
The middleware used to connect the Java extension to JavaScript was built on JavaScript itself. A Node.js server powered by Express.js is responsible for storing and serving data to client-side JavaScript. The main implementation of the server is shown below.
var express = require(‘express’);
var bodyParser = require(‘body-parser’);
var app = express();
app.use(bodyParser.json());
var id = 1;
var allJsons = {};
var log = function(msg) {
console.log(msg);
}
app.use(function(req, res, next) {
res.setHeader(‘Access-Control-Allow-Origin’, ‘*’);
res.setHeader(‘Access-Control-Allow-Methods’, ‘GET, POST, OPTIONS, PUT, PATCH, DELETE’);
res.setHeader(‘Access-Control-Allow-Headers’, ‘X-Requested-With,content-type’);
res.setHeader(‘Access-Control-Allow-Credentials’, true);
next();
});
app.get(‘/’, function(req, res) {
var br = ‘
’, h2Start = ‘
’, h2End = ‘
’, preStart = ‘
’, preEnd = ‘
’;
var help = h2Start + ‘Routes:’ + h2End;
help += preStart + ‘get /index’ + preEnd + ‘ to list JSONs’ + br + br;
help += preStart + ‘get /latest’ + preEnd + ‘ to get last JSON’ + br + br;
help += preStart + ‘get /id’ + preEnd + ‘ to get JSON’ + br + br;
help += preStart + ‘post /new’ + preEnd + ‘ to insert JSON’ + br + br;
res.send(help);
})
app.get(‘/index’, function(req, res) {
log(‘GET /index’);
res.json(allJsons);
})
app.get(‘/latest’, function(req, res) {
log(‘GET /latest’);
res.json(allJsons[id-1]);
})
app.get(‘/:id’, function(req, res) {
log(‘GET /:id’);
res.json(allJsons[req.params.id]);
})
app.post(‘/new’, function(req, res) {
log(‘POST /new’);
var json = req.body;
allJsons[id++] = json;
res.send(‘new = ‘ + json);
})
app.listen(3000, function() {
log(‘chartsmw (Charts Middleware) is running on port 3000’);
})
6.4.3 Client-side JavaScript
The third major component is the JavaScript client code. This unit comprises of web technologies, that is, HTML, CSS and JavaScript. The JavaScript code here is responsible to parse the data received from the server. The main start-up file named charts.html, along with utils.js and chartsGenerator.js are the main drivers of the render. Other files are also included such as the Bootstrap, JQuery and Highcharts JS libraries. The script in charts.html performs an AJAX request to retrieve the data and then initialises the methods to generate the charts. Due to the lengthiness of the files, only the broad logic of the main file is shown hereunder.
function generateFileTypeCharts(fileTypes) {
/* Logic here */
var fileTypeClickHandler = function(e, title) {
/* Click action on chart */
}
var fileTypeCountParams = {
/* Parameters for chart */
};
generatePieChart(fileTypeCountParams);
var fileTypeSizeParams = {
/* Parameters for chart */
};
generatePieChart(fileTypeSizeParams);
};
function generatePathDepthChart(pathDepths) {
var pathClickHandler = function(e) {
/* Click action on chart */
}
/* Logic here */
var pathDepthBarParams = {
/* Parameters for chart */
};
generateBarChart(pathDepthBarParams);
};
function generateSuspiciousFileChart(suspiciousFiles) {
/* Logic here */
var suspiciousFilesParams = {
/* Parameters for chart */
};
generateDrilldownPieChart(suspiciousFilesParams);
};
function generateFileTimeline(fileTimestamps) {
var pointClickHandler = function(point) {
/* Click action on chart */
}
/* Logic here */
params = {
/* Parameters for chart */
};
generateScatterChart(params);
};
function generateDirTimeline(dirTimestamps) {
var pointClickHandler = function(point) {
/* Click action on chart */
}
/* Logic here */
params = {
/* Parameters for chart */
};
generateScatterChart(params);
};
function load(url) {
if (url == null) url = ‘http://localhost:3000/latest’;
$.get(url).done(function(json) {
generateFileTypeCharts(json.file_types);
generatePathDepthChart(json.path_depths);
generateSuspiciousFileChart(json.suspicious_files);
generateFileTimeline(json.timestamps.files);
generateDirTimeline(json.timestamps.directories);
});
}
load();
6.5 Difficulties Encountered
The Table 8 below presents a list of the difficulties encountered during the course of project implementation.
Table 8: Difficulties encountered during implementation
| Difficulty | Description | Solution |
| Learning Java again | The good practices and syntax of Java had to be learned again. | Read documentation. |
| Understanding Autopsy’s platform | The platform’s codes needed to be understood in order to extend them with an add-on. | Reading developer documentation and performing trail and errors with codes. |
| Lack of memory | The development machine was running out of memory while test-processing large images. | Reduce image size and increase JVM’s priority in task manager. |
| Execution time | Program running time was delaying development. | Reduce image size and increase JVM’s priority in task manager. |
| “Thread-safe”-ing methods | Autopsy takes advantage of concurrency so the add-on also need to be thread-safe. | More digging into the Java language to handle concurrency. |
6.6 Chapter Summary
The implementation chapter has dealt with the actual implementation of the project. The issues are first discussed, followed by the standards and conventions adopted and specifications of the development environment. Then, the different units implemented are explained with sample codes. Finally, the difficulties encountered with the implementation are outlined.
7 Testing
This chapter demonstrates the diverse types of testing done on the software and infers their equivalent outcomes. Both static and dynamic testing has been performed.
7.1 Static Testing
This section depicts the testing done on the code, without executing it. This has been done both by using a tool and manually.
7.1.1 Automatic Static Analysis Tool: PMD
The project was scanned by PMD, a software which reports any violations to code standards. The only violation found was a method used for testing purposes during development. The results of PMD’s scan is show in the Figure 18. This violation was ignored since it does not affect code quality in this case, and will be removed once it is not needed. If it is found to be useful, the method will be used; if the method is used, the violation will no longer apply.
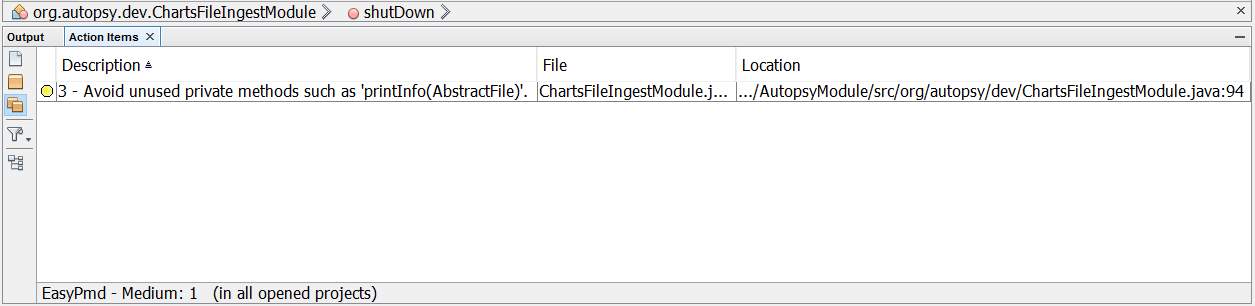
Figure 18: PMD results
7.1.2 White-box Testing: Inspection Process
Since only one developer was working on this project, a simplified variation of the Michael Fagan inspection process (Fagan, 2011) was selected for testing the source code using the white-box technique. The phases catered for are:
- Planning: The inspection is planned.
- Preparation: The code to be inspected is reviewed.
- Inspection: Prepared checklist is read aloud and answers (true or false) are given for each of the items. This is where the problems are found.
- Rework: Necessary modifications are made to the code.
- Follow-up: Modifications made are reviewed.
This inspection process has been reported to reduce defects in code by up to 90% by IBM (Fagan, 1986). The checklist for the inspection was prepared and filled as follows in Table 9.
Table 9: Michael Fagan-inspired inspection checklist
| # | Description | Yes | No |
| 1 | Is every variable properly declared? | ✔ | |
| 2 | Is every variable suitably typed? | ✔ | |
| 3 | Is every variable rightly initialised? | ✔ | |
| 4 | Do all attributes have correct access modifiers? | ✔ | |
| 5 | Are all static variables required to be static and vice versa? | ✔ | |
| 6 | Are variable names descriptive of their contents? | ✔ | |
| 7 | Do identifiers follow naming conventions? | ✔ | |
| 8 | Are there identifiers with similar names? | ✔ | |
| 9 | Do class names follow naming conventions? | ✔ | |
| 10 | Do all classes have appropriate constructors? | ✔ | |
| 11 | Does one class call multiple constructors of another class? | ✔ | |
| 12 | Do method names follow naming conventions? | ✔ | |
| 13 | Are exceptions clearly reported? | ✔ | |
| 14 | Do all methods have an appropriate return type? | ✔ | |
| 15 | Do loops iterate as less as is needed? | ✔ | |
| 16 | Are data structures large and scalable? | ✔ | |
| 17 | Are codes well indented? | ✔ | |
| 18 | Has each Boolean expression been simplified using De Morgan’s law? | ✔ | |
| 19 | Are all conditions catered for in conditional statements? | ✔ | |
| 20 | Are there too many nested if conditions? | ✔ | |
| 21 | For each method, is it no more than 50 lines? | ✔ | |
| 22 | Have files been checked for existence before opening? | ✔ | |
| 23 | Have files been closed after use? | ✔ | |
| 24 | Are there spelling or grammatical errors in displayed messages? | ✔ | |
| 25 | Are parentheses used to avoid ambiguity? | ✔ | |
| 26 | Are null pointers checked where applicable? | ✔ | |
| 27 | Are method arguments correctly altered, if altered within methods? | ✔ | |
| 28 | Are data structures fast enough? | ✔ | |
| 29 | Are data structures used suitable for concurrency? | ✔ |
Issue #13
All exceptions cannot be clearly reported since they are masked by Autopsy. As much as possible, exceptions are handled internally. If an exception occurs in the code, Autopsy will continue with its operations and ignore the crashed extension.
Issue #22
Files were not checked for existence. This was corrected in the next rework of the code.
7.2 Dynamic Testing
This section details the testing done by operating the code. In other words, the program is run and then these tests are performed.
7.2.1 Black-box Testing
Table 10: Tests
| # | Test data | Data type | Expected outcome | Actual outcome |
| 1 | Image file is selected by Autopsy and extension is run | Valid | Express.js server should receive a set of data | Express.js server receives set of data |
| 2 | Second image file is added to Autopsy and extension is run | Valid | Express.js server should receive another set of data | Express.js server receives another set of data |
| 3 | Web page is opened while server contains data | Valid | Charts should be rendered | Charts are rendered |
| 4 | Web page is opened while server has no data | Invalid | Charts should be blank | Charts are blank |
| 5 | File Types Count can be clicked for more information | Valid | More information about data should be shown | More information about data is shown |
| 6 | File Types Sizes can be clicked for more information | Valid | More information about data should be shown | More information about data is shown |
| 7 | Path Depths can be clicked for more information | Valid | More information about data should be shown | More information about data is shown |
| 8 | Suspicious Files can be drilled down to reveal more information | Valid | More information about data should be shown | More information about data is shown |
| 9 | Only present suspicious files have descriptions | Valid | Descriptions should be shown | Descriptions are shown |
| 10 | Suspicious files not present are not described | Invalid | Redundant descriptions should not be shown | Redundant descriptions are not shown |
| 11 | Timeline of Files can be clicked for more information | Valid | More information about data should be shown | More information about data is shown |
| 12 | Timeline of Files can be zoomed in | Valid | Results should filter based on user selection | Results are filtered based on user selection |
| 13 | Timeline of Directories can be clicked for more information | Valid | More information about data should be shown | More information about data is shown |
| 14 | Timeline of Directories can be zoomed in | Valid | Results should filter based on user selection | Results are filtered based on user selection |
Some screenshots from the above tests are shown below.
Figure 19: Index of data received after two runs
Figure 20: Node’s console logs after two runs and index listing
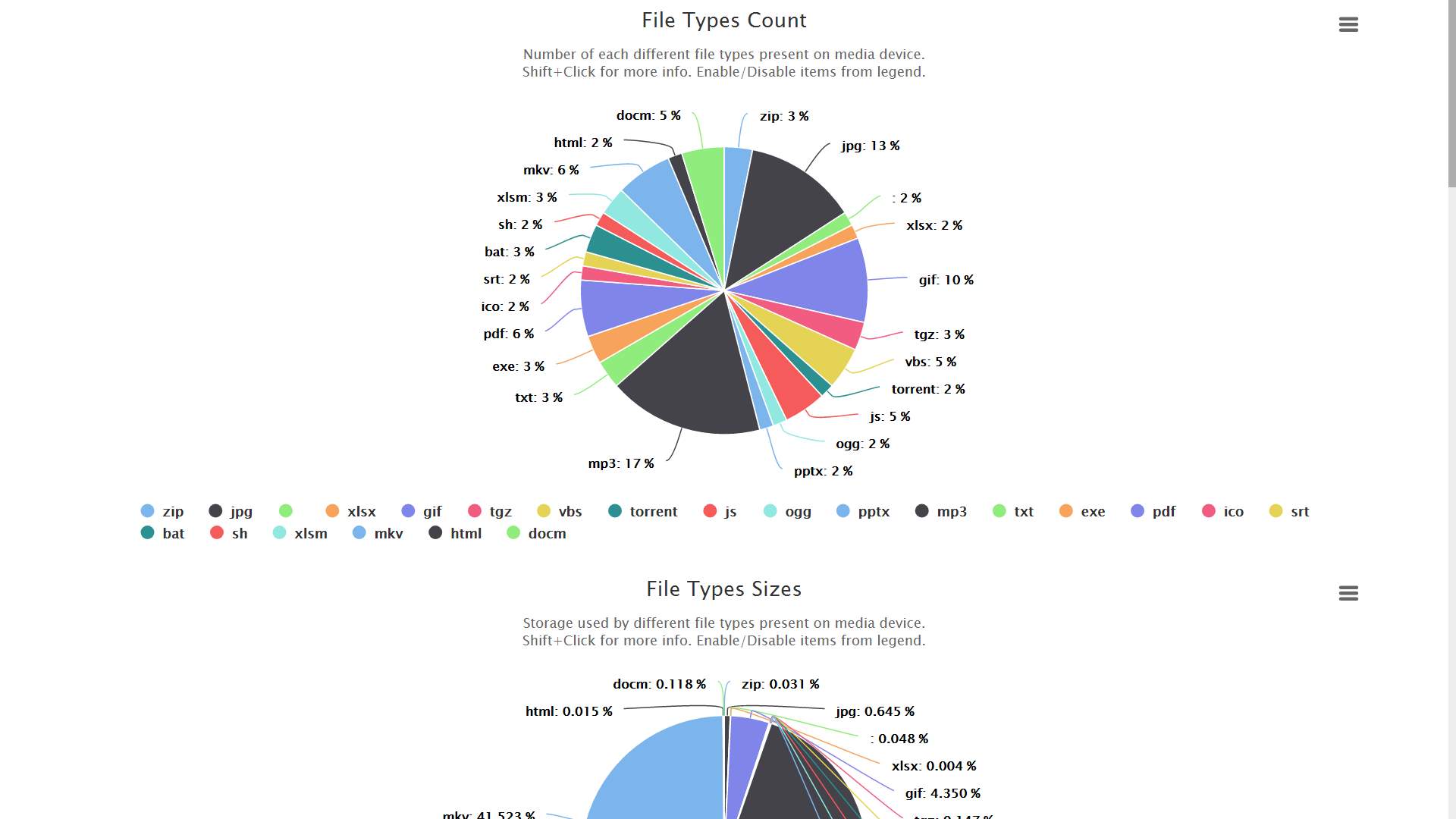
Figure 21: Screenshot – success
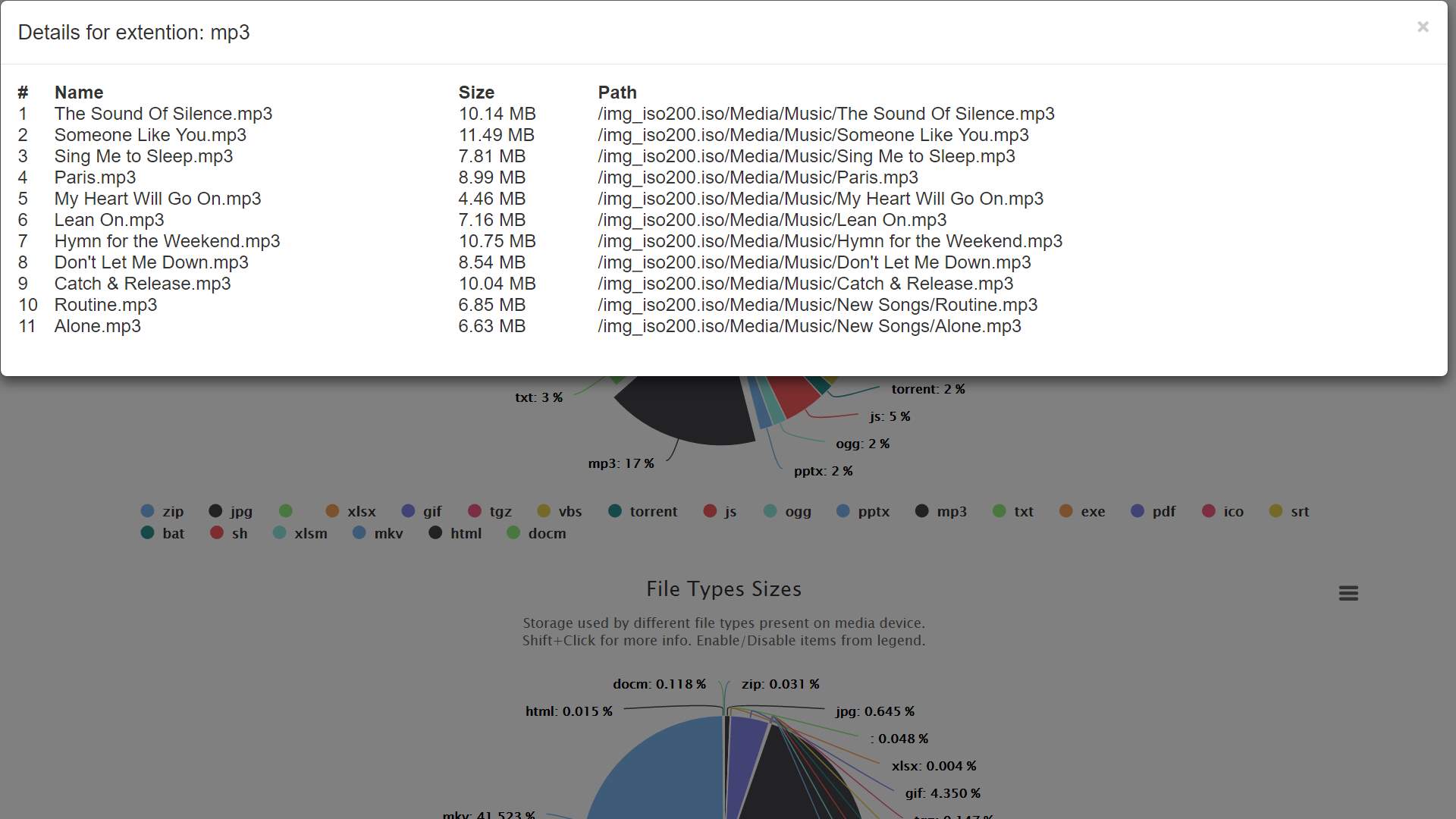
Figure 22: Sample of more information displayed
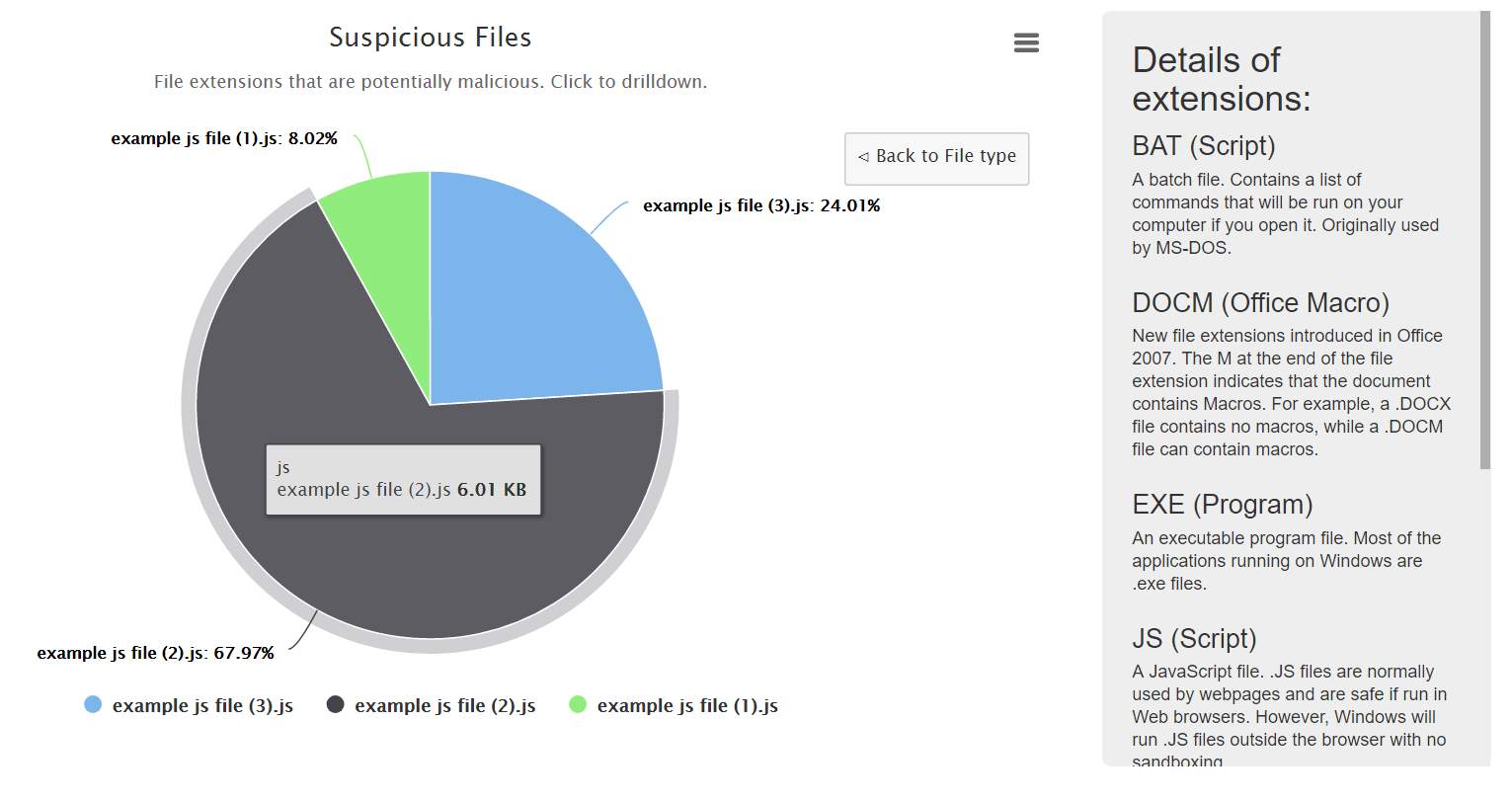
Figure 23: Drilldown on Suspicious Files chart
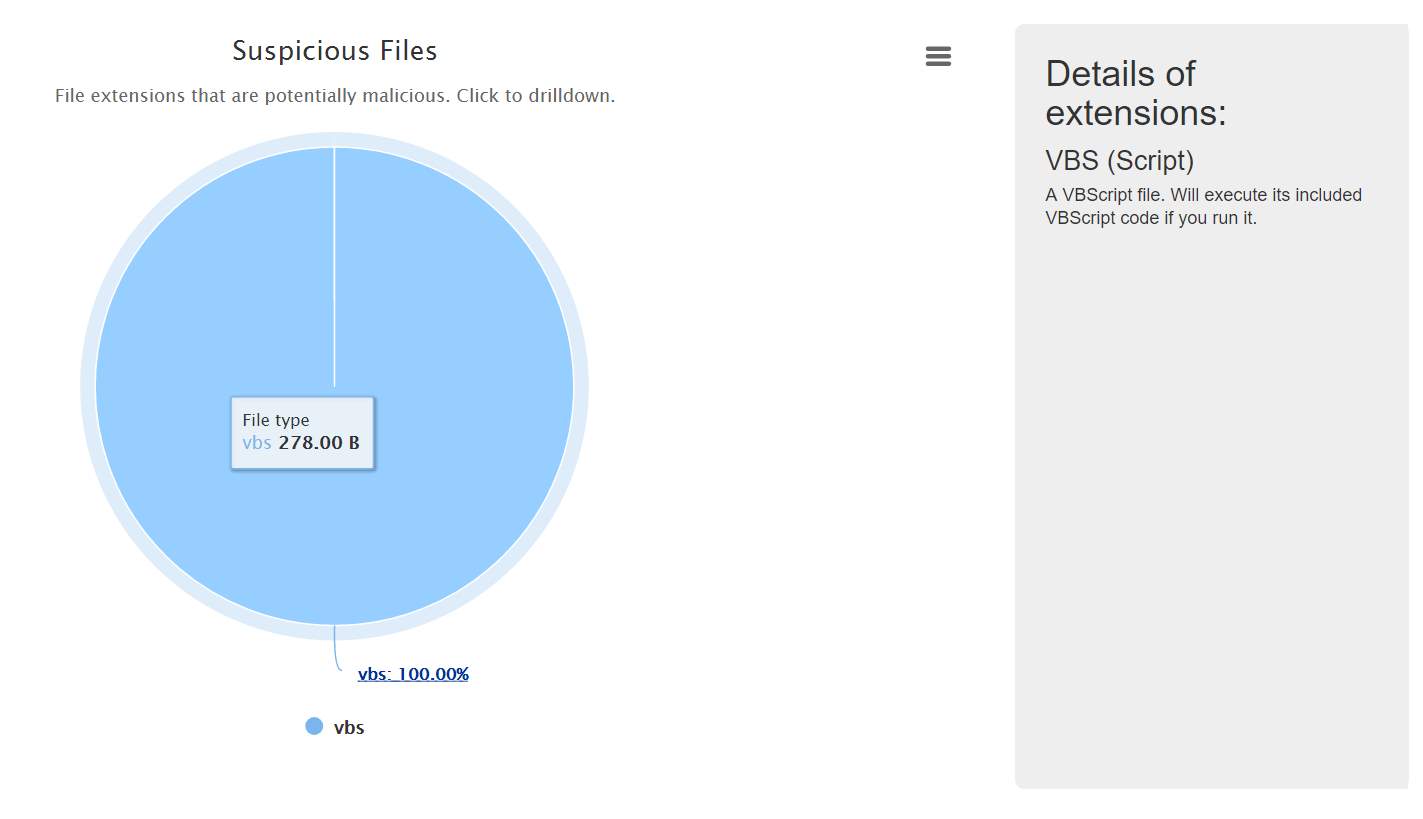
Figure 24: Only description required is shown
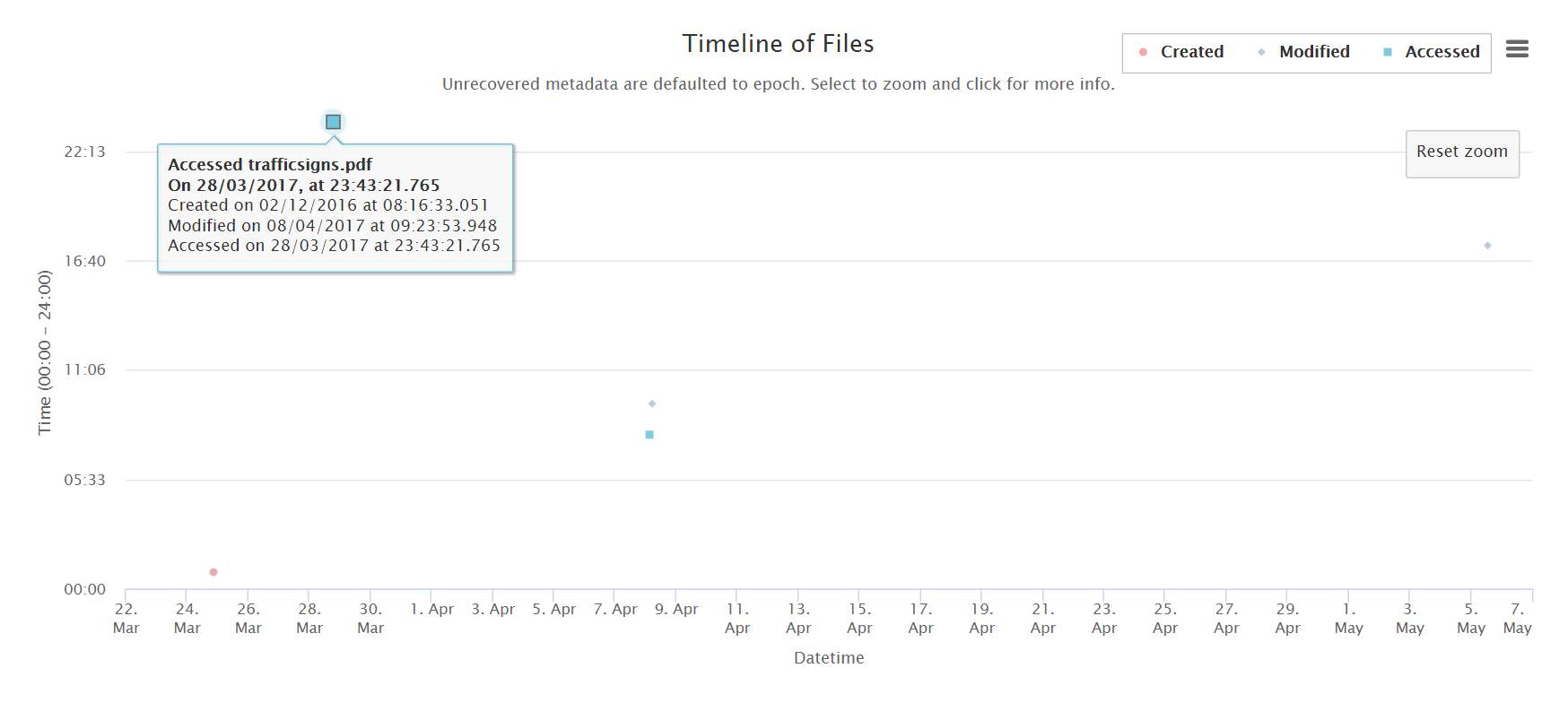
Figure 25: Timeline of Files is zoomable
7.2.2 Unit Testing
This part deals with performing unit tests of the middleware used to serve data to JavaScript.
Table 11: Unit Tests
| # | Description | Expected outcome | Actual outcome |
| 1 | Posting new JSON data | New data should be saved | New data is saved |
| 2 | Getting all data on server | List of all data should be returned | List of all data is returned |
| 3 | Getting data with a specific valid ID | Data with specified ID should be returned | Data with specified ID is returned |
| 4 | Getting data with a specific invalid ID | No data should be returned | No data is returned |
| 5 | Getting latest data added | Latest data on server should be returned | Latest data on server is returned |
| 6 | Getting latest data added, while server has no data. | No data should be returned | No data is returned |
The screenshots from the above tests are displayed below.
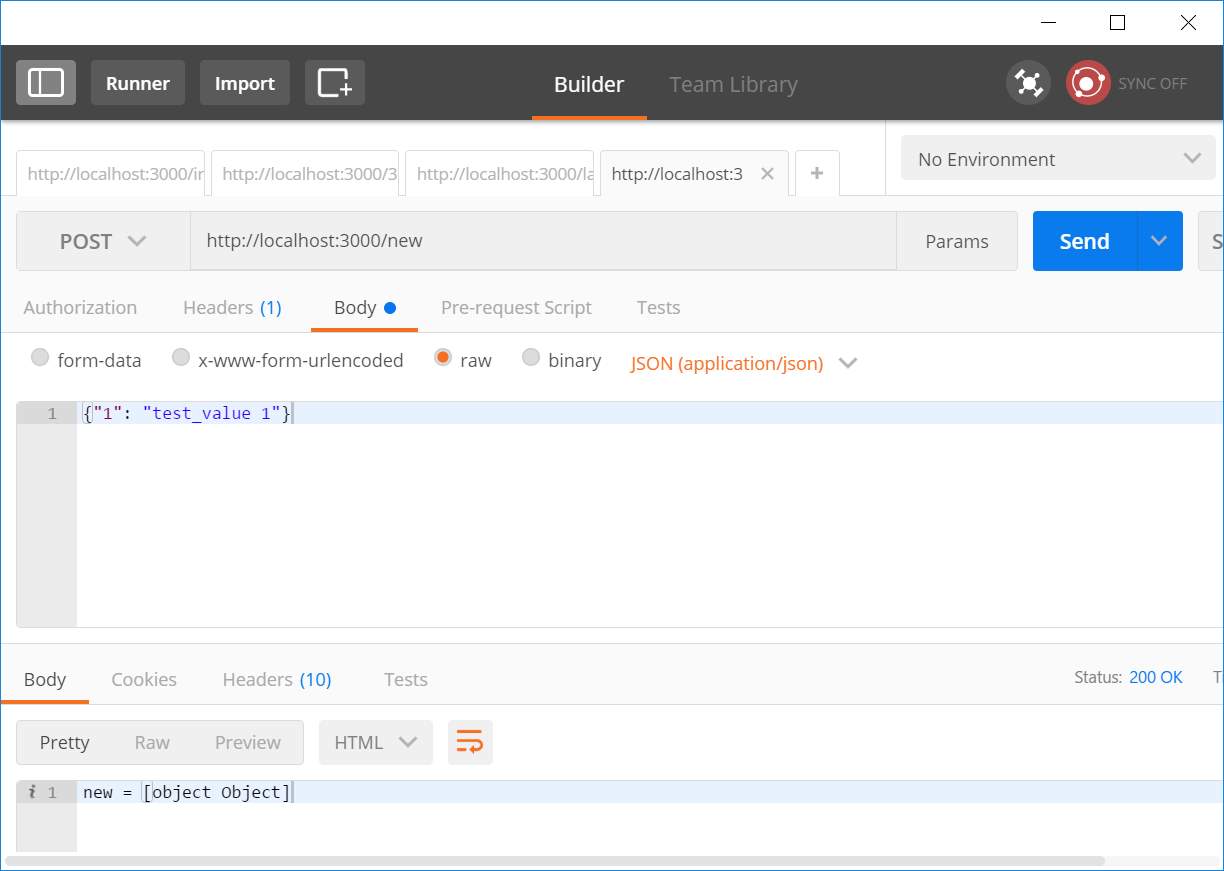
Figure 26: Unit test #1
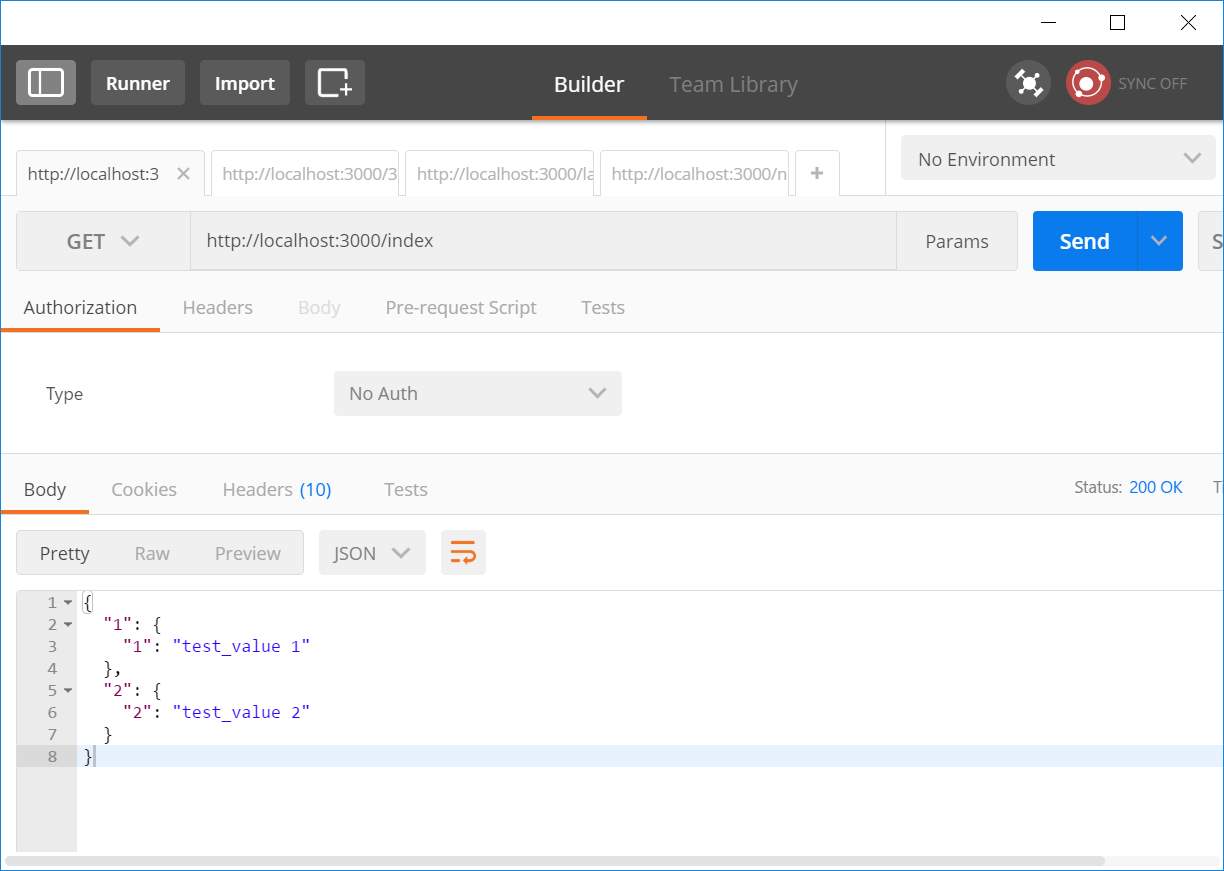
Figure 27: Unit test #2
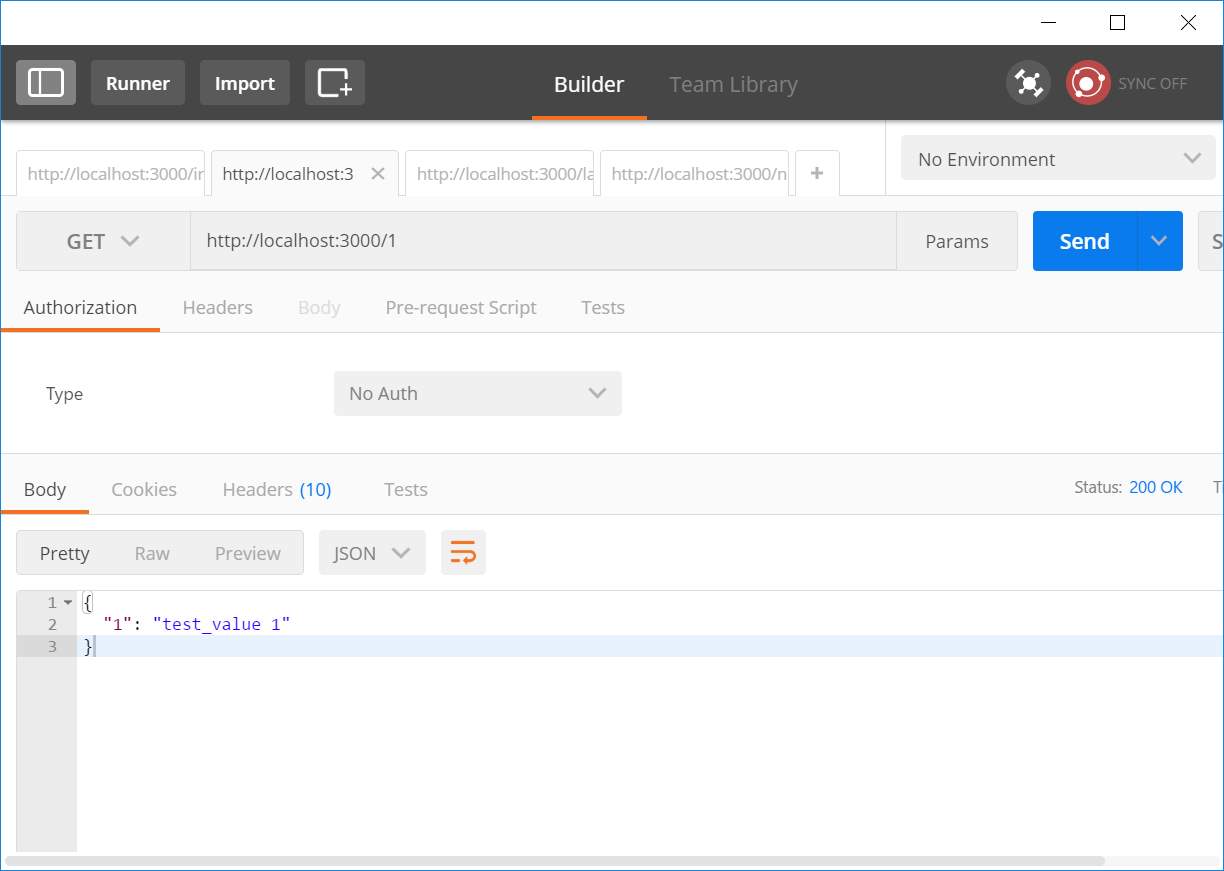
Figure 28: Unit test #3
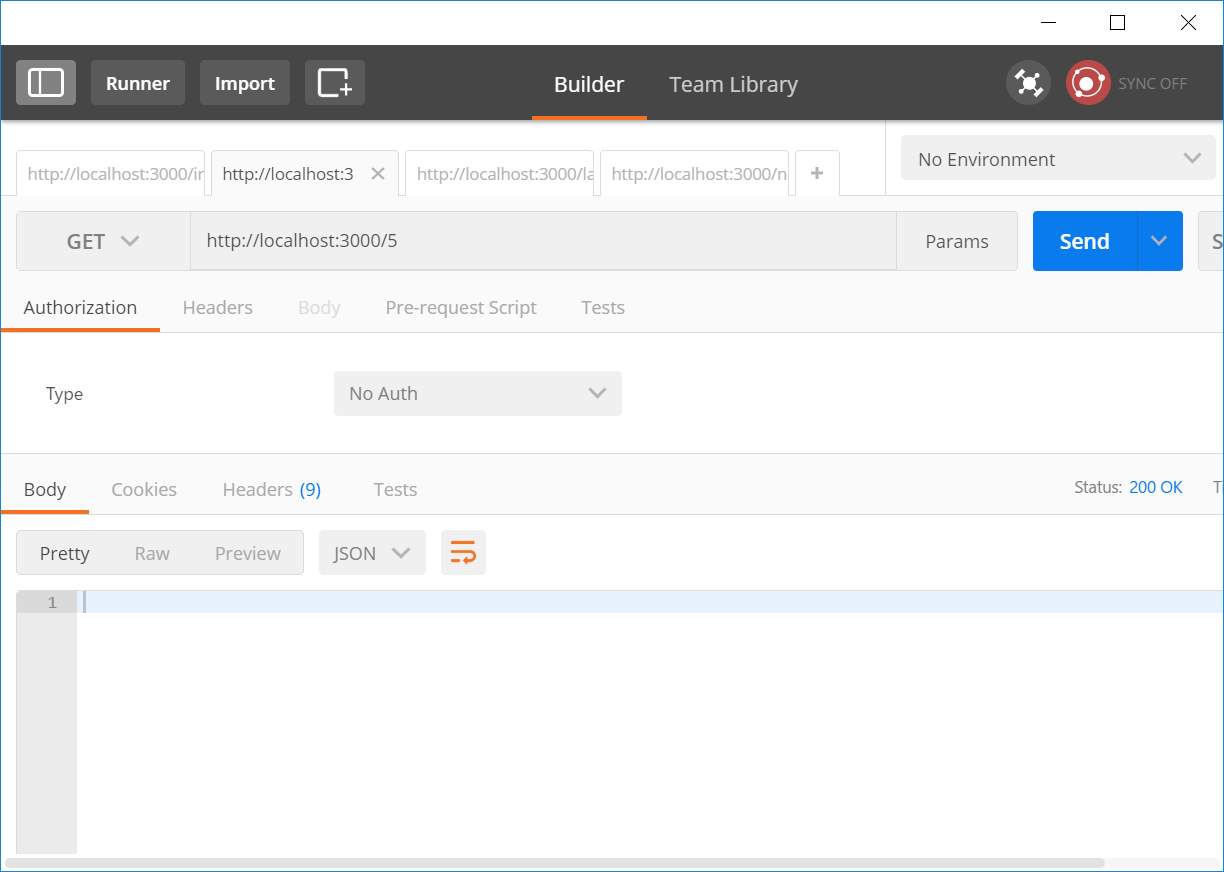
Figure 29: Unit test #4
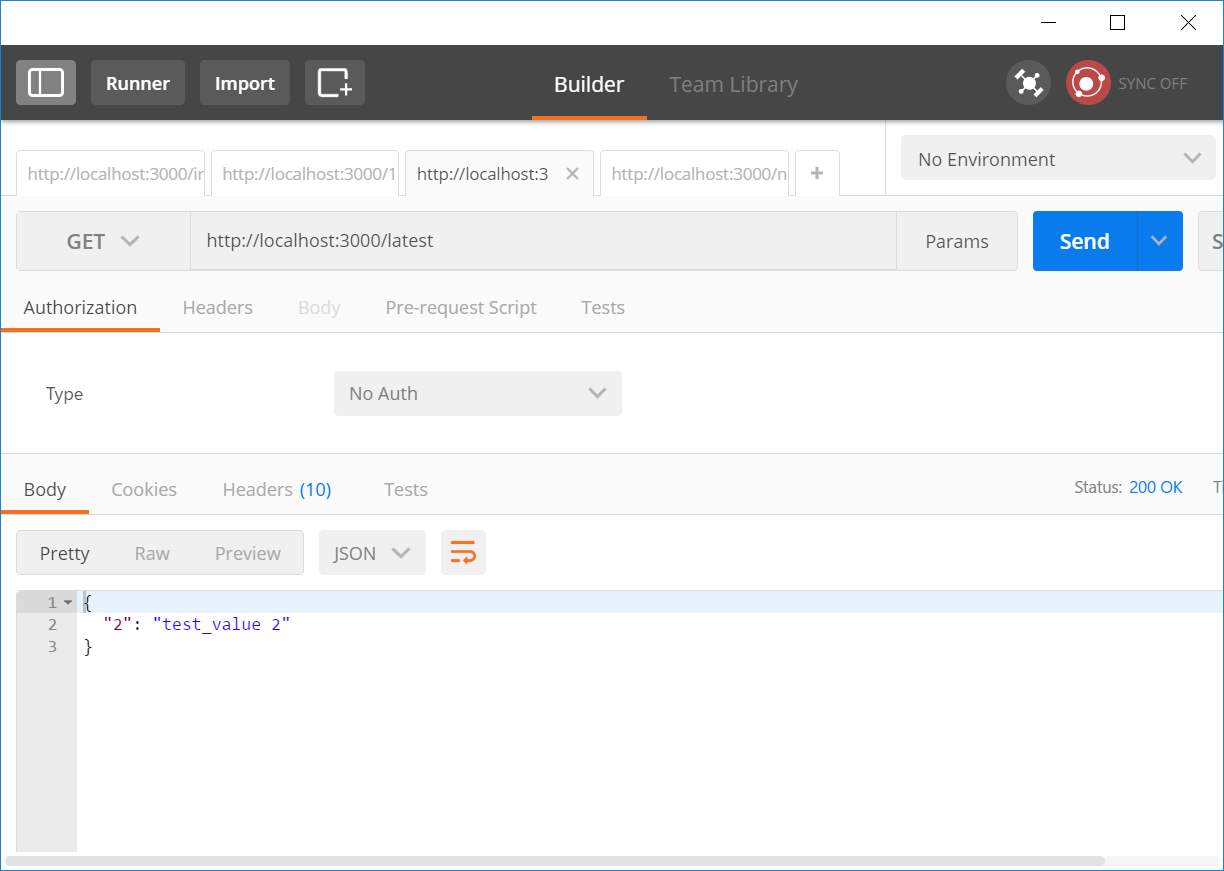
Figure 30: Unit test #5
Figure 31: Unit test #6
7.3 Chapter Summary
The testing chapter was concerned with performing tests on the software. It contained static and dynamic testing methods along with screenshot of steps or results.
8 Results & Conclusion
The final chapter discusses the results of the project, and then moves on to the achievements and the difficulties faced during the project. It finishes by providing a basis for future works with the system.
8.1 Results
As planned, a visual representation of an image file’s contents can be obtained from Autopsy. The user does not need to rely on textual information anymore. Figure 32 below presents the major steps from a user’s perspective.
Figure 32: Major steps of usage
Figure 33 demonstrates an example of how the results would have had to be viewed in classic Autopsy only.
Figure 33: Autopsy screenshot
8.2 Achievements
This section comprises the accomplishments in the project. Based on the preliminary aims and objectives, a fully-functional add-on software has been developed which fulfils all the requirements as stated in the analysis chapter. A list of all the original functional and non-functional requirements is offered in Table 12 along with their status.
Table 12: Achievements
| ID | Description | Complete |
| FR1 | The system shall parse image files uploaded into Autopsy. | ✔ |
| FR2 | The system shall calculate types of files present in a data source. | ✔ |
| FR3 | The system shall calculate sizes of different file types present in a data source. | ✔ |
| FR4 | The system shall watch for suspicious folder paths. | ✔ |
| FR5 | The system shall maintain a library of known suspicious files. | ✔ |
| FR6 | The system shall compare found files with the library of known suspicious files. | ✔ |
| FR7 | The system shall build a timeline of files’ creation, access and modification dates. | ✔ |
| FR8 | The system shall build a timeline of directories’ creation, access and modification dates. | ✔ |
| FR9 | The system shall generate interactive charts to represent all mined information. | ✔ |
| FR10 | The system shall provide additional information to user about suspicious files found. | ✔ |
| NFR1: Usability | The system shall not add any complexity for the user of the Autopsy platform. | ✔ |
| NFR2: Robustness | The system shall handle all kinds of possible errors and react accordingly. | ✔ |
| NFR3: Scalability | The system shall adapt to changes in operating system, processor and/or memory architecture and number of cores and/or processors. | ✔ |
| NFR4: Platform independence | The system shall be easily executable on any operating system Autopsy can be installed on. | ✔ |
| NFR5: Maintainability | The system’s code shall be comprehensible and extensible easily. | ✔ |
| NFR6: Data integrity | The system shall not, in any way, affect the integrity of the data it handles. | ✔ |
| NFR7: Security | The system shall protect data and not let it leak outside the system. | ✔ |
| NFR8: Performance | The system shall not cripple a system so as to make it unusable. | ✔ |
8.3 Difficulties
This section specifies the complications that were encountered during the course of the thesis. It does not include technical difficulties as this was already discussed in the Implementation chapter under Difficulties Encountered.
Table 13: Difficulties
| Difficulty | Description |
| Lack of time | Focusing on the thesis was hard since work life became really hectic due to new projects and new clients. |
| Lack of research on the platform | The few number of research papers on open-source forensics toolkits and what are their shortcomings decelerated the progress. |
| Lack of student licenses for paid software | No student licenses are available for the paid digital forensics software. These licenses would be helpful to determine what features they really excel at and how they can be brought to the open-source community. |
| Release from work | Due to a full pipeline, it was difficult to take time for regular supervisor meetings or even classes. |
8.4 Future Works
There remains a lot of potential in the Autopsy platform in the field of visual representation. Much work is needed to make Autopsy as good as its expensive commercial counterpart. The possible future works are detailed below.
- Display more information visually, such as hash mismatches and wrong file extension/magic number pair.
- Implement add-on directly in Autopsy for content viewers. An example could be a tag cloud for documents.
- Find a way to integrate the JavaScript component directly into the Java component, to eliminate the need for a separate browser.
References
AccessData, 2016. Forensic Toolkit (FTK) | AccessData. [Online] Available at: http://accessdata.com/solutions/digital-forensics/forensic-toolkit-ftk/capabilities [Accessed 29 October 2016].
AccessData, 2016. Forensic Toolkit (FTK) | AccessData. [Online] Available at: http://accessdata.com/solutions/digital-forensics/forensic-toolkit-ftk [Accessed 13 November 2016].
AccessData, 2016. SC Magazine gives AccessData FTK five-star seal of approval for third year in a row | AccessData. [Online] Available at: http://accessdata.com/news/sc-magazines-lab-review-has-given-accessdata-ftk-its-five-star-seal-of-appr [Accessed 29 October 2016].
Adam, 2013. Multilanguage support · Issue #137 · sleuthkit/autopsy · GitHub. [Online] Available at: https://github.com/sleuthkit/autopsy/issues/137 [Accessed 13 November 2016].
ArxSys, 2015. GitHub – arxsys/dff. [Online] Available at: https://github.com/arxsys/dff [Accessed 29 October 2016].
ArxSys, n.d. Features – ArxSys. [Online] Available at: http://www.arxsys.fr/features/ [Accessed 28 October 2016].
Austin, E., 2015. Privacy, Attribution and Liability Law for the Digital Investigator. [Online] Available at: http://www.forensicmag.com/article/2015/08/privacy-attribution-and-liability-law-digital-investigator [Accessed 19 4 2017].
Autopsy Contributors, 2016. GitHub – sleuthkit/autopsy. [Online] Available at: https://github.com/sleuthkit/autopsy [Accessed 29 October 2016].
Autopsy Issues, 2017. Issues · sleuthkit/autopsy · GitHub. [Online] Available at: https://github.com/sleuthkit/autopsy/issues [Accessed 30 April 2017].
Autopsy, 2016. Autopsy User Documentation: Optimizing Performance. [Online] Available at: https://www.sleuthkit.org/autopsy/docs/user-docs/4.0/performance_page.html [Accessed 30 April 2017].
Bara, G., 2014. Machine Translation: the Digital Forensics investigator’s best new friend | SDL Language Translation & Content Management Blog. [Online] Available at: http://blog.sdl.com/company/machine-translation-the-digital-forensics-investigators-best-new-friend/ [Accessed 17 March 2017].
Bignoux, L., 2012. Mauritius steps up battle against rising cyber crime – Africa Review. [Online] Available at: http://www.africareview.com/News/Mauritius-steps-up-battle-against-rising-cyber-crime/-/979180/1895366/-/h6ela3z/-/index.html [Accessed 13 November 2016].
Burmark, L., 2002. Visual Literacy: Learn to See, See to Learn. 1st ed. California: Association for Supervision and Curriculum Development.
Carrier, B., 2016. Autopsy. [Online] Available at: http://www.sleuthkit.org/autopsy/ [Accessed 28 October 2016].
Carrier, B., 2016. Autopsy: Features. [Online] Available at: http://www.sleuthkit.org/autopsy/features.php [Accessed 28 October 2016].
Carrier, B., 2016. make thumbs.db parser · Issue #2224 · sleuthkit/autopsy · GitHub. [Online] Available at: https://github.com/sleuthkit/autopsy/issues/2224 [Accessed 13 November 2016].
Carrier, B., 2017. Autopsy: Description. [Online] Available at: https://www.sleuthkit.org/autopsy/v2/ [Accessed 4 March 2017].
Casey, E., 2009. The Handbook of Digital Forensics and Investigation. 1st ed. s.l.:Academic Press.
EC-Council, 2010. Computer Forensics: Investigating Network Intrusions and Cyber Crime. 4 ed. New York: Cengage Learning.
EnCase, 2008. EnCase Forensic Features and Functionality. [Online] Available at: http://www.moonsoft.fi/materials/guidance_encase_feature.pdf [Accessed 29 October 2016].
EnCase, 2016. EnCase Forensic Software. [Online] Available at: https://www.guidancesoftware.com/encase-forensic?cmpid=nav_r [Accessed 29 October 2016].
Ernst & Young LLP, 2013. Forensic Data Analytics, Kolkata: Ernst & Young LLP.
Fagan, M., 1986. Advances in Software Inspections. IEEE Transactions on Software Engineering, SE-12(7), pp. 744-751.
Fagan, M., 2011. Michael Fagan Associates – Our Process. [Online] Available at: http://www.mfagan.com/our_process.html [Accessed 30 April 2017].
Fowle, K. & Schofeld, D., 2011. Visualising forensic data: investigation to court. Perth, Edith Cowan University.
GCN, 2014. Digital forensic tools dig up hidden evidence faster. [Online] Available at: https://gcn.com/Articles/2014/01/15/Forensics-Toolkit.aspx [Accessed 13 November 2016].
Google Cloud Platform, 2017. FAQ | Google Cloud Translation API Documentation | Google Cloud Platform. [Online] Available at: https://cloud.google.com/translate/faq [Accessed 2017 April 30].
Hibshi, H., Vidas, T. & Cranor, L., 2011. Usability of Forensics Tools: A User Study. Washington, IEEE Computer Society, pp. 81-91.
ICTA, 2010. ICT Authority and National Cyber Crime Prevention Committee set up International Cooperation to fighting Cyber Crime. [Online] Available at: https://www.icta.mu/mediaoffice/2010/cyber_crime_prevention_en.htm [Accessed 13 November 2016].
InfoSec Institute, 2014. 22 Popular Computer Forensics Tools. [Online] Available at: http://resources.infosecinstitute.com/computer-forensics-tools/ [Accessed 28 October 2016].
Jankun-Kelly, T. J. et al., 2011. Visual Analysis for Textual Relationships in Digital Forensics. Information Visualization on VizSec 2009, 10(2), pp. 134-144.
JFreeChart, 2014. JFreeChart. [Online] Available at: http://www.jfree.org/jfreechart/ [Accessed 30 April 2017].
Kelsey, C. A., 1997. Detection of Vision Information. 1st ed. New York: Springer New York.
Lowman, S. & Ferguson, I., 2010. Web History Visualisation for Forensic Investigators, Glasgow: University of Strathclyde.
Mariaca, R., 2017. DynamicReports – Free and open source Java reporting tool. [Online] Available at: http://www.dynamicreports.org/ [Accessed 10 May 2017].
McManus, J., 2017. SEI CERT Oracle Coding Standard for Java. [Online] Available at: https://www.securecoding.cert.org/confluence/x/Ux [Accessed 30 April 2017].
Mizota, K., 2013. Digital Forensics Today Blog: New Flexible Reporting Template in EnCase App Central. [Online] Available at: http://encase-forensic-blog.guidancesoftware.com/2013/10/examination-reporting-with-flexible.html [Accessed 13 November 2016].
Ngiannini, 2013. System Fundamentals For Cyber Security/Digital Forensics/Branches. [Online] Available at: http://csf102.dfcsc.uri.edu/wiki/System_Fundamentals_For_Cyber_Security/Digital_Forensics/Branches [Accessed 30 April 2017].
Palmer, G., 2001. A Road Map for Digital Forensic Research, New York: DFRWS.
Parsonage, H., 2012. UnderMyThumbs. [Online] Available at: http://computerforensics.parsonage.co.uk/downloads/UnderMyThumbs.pdf [Accessed 30 April 2017].
Quick, D., Tassone, C. & Choo, K.-K. R., 2014. Forensic Analysis of Windows Thumbcache files. Savannah, Association for Information Systems ( AIS ).
Rosen, R., 2014. ‘The Floppy Did Me In’ – The Atlantic. [Online] Available at: https://www.theatlantic.com/technology/archive/2014/01/the-floppy-did-me-in/283132/ [Accessed 20 April 2016].
Roukine, M., 2008. Vinetto : a forensics tool to examine Thumbs.db files. [Online] Available at: http://vinetto.sourceforge.net/ [Accessed 29 April 2017].
Srivastava, A. & Vatsal, P., 2016. Forensic Importance of SIM Cards as a Digital Evidence. Journal of Forensic Research: Open, 7(322).
Stephenson, P., 2014. EnCase Forensic v7.09.02 product review | SC Magazine. [Online] Available at: http://www.scmagazine.com/encase-forensic-v70902/review/4179/ [Accessed 29 October 2016].
Stephenson, P., 2016. AccessData Forensic Toolkit (FTK) product review | SC Magazine. [Online] Available at: http://www.scmagazine.com/accessdata-forensic-toolkit-ftk/review/4617/ [Accessed 29 October 2016].
Teerlink, S. & Erbacher, R. F., 2006. 7th IEEE Workshop on Information Assurance. New York, IEEE.
Thakore, 2008. Thakore Risk Analysis for Evidence Collection. [Online] Available at: https://www.cs.nmt.edu/~df/StudentPapers/Thakore%20Risk%20Analysis%20for%20Evidence%20Collection.pdf [Accessed 28 April 2017].
Thermopylae Sciences + Technology, 2014. Humans Process Visual Data Better. [Online] Available at: http://www.t-sciences.com/news/humans-process-visual-data-better [Accessed 25 February 2017].
thumbcacheviewer, 2016. Thumbcache Viewer – Extract thumbnail images from the thumbcache_*.db and iconcache_*.db database files.. [Online] Available at: https://thumbcacheviewer.github.io/ [Accessed 13 November 2016].
Yasinsac, A. et al., 2003. Computer forensics education. IEEE Security & Privacy, 99(4), pp. 15-23.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Forensic Science"
Forensic science, or forensics, is the application of science to criminal and civil law, usually during criminal investigation, and involves examining trace material evidence to establish how events occurred. Forensic scientists provide impartial scientific evidence that can be used in court.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: