Sentiment Analysis in the Medical Field
Info: 8814 words (35 pages) Dissertation
Published: 10th Dec 2019
2.1 Introduction
This chapter discusses current literature and work in sentiment analysis along with the analysis process and classification methods used. Section 2.2 will discuss sentiment analysis followed by a section which discusses the areas of application of sentiment analysis. Classification of existing sentiment analysis method is discussed in the fourth section. The next section shows us the process of sentiment analysis and then we look at different sentiment analysis methods, after which we look at sentiment analysis in the medical field. WSD and N-grams are some of the most widely used techniques for information retrieval and it was essential to review the literature and understand n-grams before the framework for this thesis could be finalized. Finally, we look at the current gaps and challenges in the application of natural language processing to analyzing and classifying text and documents. Finally, a summary concludes the chapter.
2.2 Sentiment Analysis Review
Sentiment analysis is the computational study of human opinions, emotions, attitudes and thoughts towards an event or topic or individual. Opinion or sentiment mining, sentiment extraction and subjectivity analysis are other terms used for sentiment analysis (Chandni, March – 2015). Sentiment analysis uses natural language processing, computation techniques and text analysis to automate the entire process of extracting and classifying sentiment reviews. Sentiment analysis has spread across many fields such as marketing, consumer information, books, websites, application and social media. The main aim of analyzing sentiments in a variety of areas is to analyze and examine the reviews and score of sentiments (Hussein, 2016).
Opinions usually comprise of polarity which can positive or negative, the target or the aspects about which the sentiment was expressed, and the time at which the opinion was expressed.
Typically, we can perform sentiment analysis by using lexicon-based method or machine learning or a combination of the two methods also known as hybrid methods. Machine learning uses algorithm that needs to be trained with labelled data and then the model is used for classifying new documents. The labelled data is created by human annotator and is a labor-intensive process. Distant supervision is an alternative method which relies on usage of certain emoticons which signify sentiments. Although distant supervision has been proved to do well in classification, it is very difficult to integrate it with machine learning algorithm. Lexicon based methods make use of sentiment lexicons which associate terms with sentiment polarity (negative, positive or neutral) usually by using a numerical score that is an indicator of sentiment strength and dimension. But sentiment lexicons do not contain sentiment bearing and domain specific terms and this makes it difficult to classify high sentiment bearing words properly (Muhammad, Wiratunga, Lothian, & Glassey, 2013).
The goal of sentiment analysis is to analyze and examine the sentiments shown in the sentence and determine the polarity of the sentence. Sentiment analysis can be examined as a process of three systemization levels which are document level, aspect level and sentence level. Document level sentiment analysis sets to organize thoughts in a document as carrying a positive or negative or neutral sentiment. An aspect is a part of the product/movie that has been commented on in a review. For example, ‘battery life’ in the opinion phrase ‘The battery life of this camera is too short’. Sentence level opinion mining first tries to recognize the sentence as subjective or objective and then if a sentence is subjective it tries to examine whether it displays positive or negative sentiment. There is no real distinction between document- and sentence-level analysis because sentences are considered small records from a document (Chandni, March – 2015).
2.2.1 Areas of Application of Sentiment Analysis
Consumers make a choice or decision regarding a product from the information about the reputation of the product derived from the opinions of other users. When users choose a product, they are interested or attracted to certain aspects of the product and may comment on specific aspects in their review. A review is an assessment of the quality of a product, for example, that is posted online. An aspect is a part of the product that has been commented on in a review. For example, ‘battery life’ in the opinion phrase ‘The battery life of this camera is too short’. A rating is an intended interpretation of user satisfaction in terms of numerical values. Most review websites use ratings (number of stars) in the range from 1 to 5. Sentiment analysis can help collect the opinions of the reviewers and help estimate ratings on a specific aspect of the product, as a single global rating can be deceiving. Thus, sentiment analysis or mining can be used to give an indication or recommendation in choosing products. Another usage of sentiment analysis is for the organizations or companies to know the opinion consumers have of their products, which then can be used to improve on the aspects consumers did not like or found unsatisfactory. Sentiment analysis can also help companies understand which aspects consumers liked, and automatically suggest advertisement for other products that suit a viewer’s opinion and this provides numerous opportunities in the human–machine interface domain.
2.2.2 Process of Sentiment Analysis
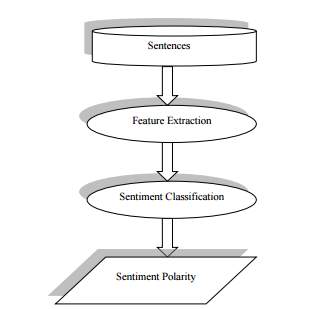
Figure 2 Sentiment Analysis Process (Source: Chandni, March – 2015)
The process of sentiment analysis, as shown in Figure 2, may be simplistically viewed as a series of actions that begin with a sentence to be analysed and ends with the determination of the polarity of the sentence. The feature extraction phase deals with features which may be of the following types in sentiment classification:
1. Part of speech (POS): It includes adjectives which are important for opinion or thought.
2. Presence of Terms and their Frequencies: These features are type of word i.e. individual word or N-gram words and their relative count of frequencies. Frequency count is used to show the relative value of features.
3. Words and Phrases for opinion: words and phrases that are commonly used to the opinions like love or hate, high or low.
4. Negation: as a negative word before any word may change the meaning of that word or opinion e.g. not love is similar to hate. (Chandni, March – 2015).
(Asghar, Khan, Ahmad, Qasim, & Khan, 2017) detail many of the functions performed during lexicon-based sentiment analysis, presented here in Figure 3. Their method is based on the three steps: 1. Acquisition of data from different online resources; 2. Noise reduction, performed by applying different preprocessing techniques to refine the text that can be used for later processing, and 3. Classification techniques applied to classify the reviews into positive, negative or neutral.
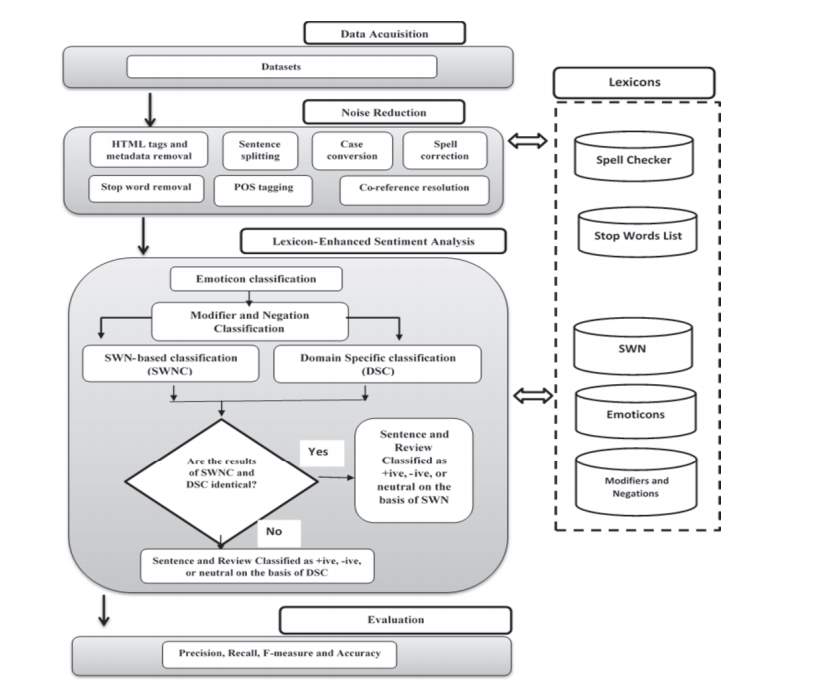
Figure 3 Sentiment Analysis Components (Source: Asghar, Khan, Ahmad, Qasim, & Khan, 2017)
In the following section, we look at the different ways existing solutions have been classified.
2.2.3 Classification of existing solutions
Existing solutions on sentiment analysis can be classified on different points such as technique used, view of text, level of detail of text analysis, rating level, etc. From a technical standpoint, we can classify based on the approaches.
Table 1 Approaches and Techniques from Existing Solutions
| Method/Approach | Measure/Technique Used |
| Machine Learning | Learning algorithms |
| Lexicon-based | Semantic orientation |
| Rule-based | Classification |
| Statistical | Multinomial distribution, Clustering |
As shown in Table 1, the machine learning method uses several learning algorithms to determine the sentiment by training on a known dataset. The lexicon-based approach involves calculating sentiment polarity for a review using the semantic orientation of words or sentences in the review; “semantic orientation” is a measure of subjectivity and opinion in text. The rule-based approach looks for opinion words in a text and then classifies it based on the number of positive and negative words. It considers different rules for classification such as dictionary polarity, negation words, booster words, idioms, emoticons, mixed opinions, to mention a few. Statistical models represent each review as a mixture of latent aspects and ratings. It is assumed that aspects and their ratings can be represented by multinomial distributions and try to cluster head terms into aspects and sentiments into ratings.
Most of the solutions for review classification rely on polarity of the review and machine learning techniques. Solutions which aim for more detailed classification of user reviews use a great deal of linguistic features including negation, modality, intensification and discourse structure. Figure 4 gives further detail on the classification of existing methods.
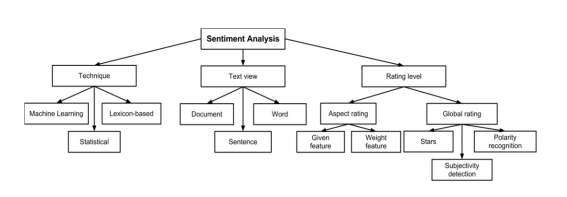
Figure 4 Sentiment Analysis Classification (Source: Collomb et al., 2014)
Another classification of sentiment analysis is oriented more on the structure of the text: document level, sentence level or word/feature level classification. Document-level classification aims to find a sentiment polarity for the whole review, whereas sentence level or word-level classification can express a sentiment polarity for each sentence of a review and even for each word. (Collomb, Costea, Joyeux, Hasan, & Brunie, 2014) state that most of the methods tend to focus on document-level classification. They also distinguish methods which measure sentiment strength for different aspects of a product and methods which attempt to rate a review on a global level.
In the next section, we look at some of the sentiment analysis methods from literature.
2.3 Sentiment Analysis Methods and Tools
In this section, we discuss various sentiment analysis methods and tools created by researchers in performing sentiment analysis.
2.3.1. Sentiment Classification of Online Customer Reviews
(Khan, Baharudin, & Khan, 2011) presented a domain-independent rule-based method for classifying sentiments from customer reviews that works in three parts. First, the reviews are split into sentences, corrected and POS tagged, and the base word of each word in the sentence is stored. Next, opinion word extraction is used to find out the polarity of the sentence based on the contextual information and structure of the sentence. The noun phrases are the aspects of the product. The third part consists of classifying the sentence as subjective or objective—using rule based methods. Each word conveys opinion and has a semantic score which is calculated from SentiWordNet dictionary, and a weight is assigned to a sentence, by rating each term, to decide if it conveys positive or negative sentiment.
For evaluation, (Khan et al., 2011) collected three types of customer reviews (movie, hotel and airline reviews) which had an average of 1,000 movie and airlines reviews and 2,600 hotel reviews. The performance was assessed with an accuracy of 91% at the review level and 86% at the sentence level; moreover, the sentence level sentiment classification performed better than the word level. The accuracy of 70-75% seems better than the average results of other methods but there is no comparison provided with other lexicon-based methods, nor with learning-based methods.
2.3.2. Concept-Level Sentiment Analysis
pSenti is a concept level sentiment analysis system which combines lexicon based and learning-based approaches. It measures and reports the overall sentiment of a review through a score that can be positive, negative or neutral or 1–5 stars classification. The main advantages and main interests of this article are the lexicon/learning symbiosis, the detection and measurement of sentiments at the concept level and the lesser sensitivity to changes in topic domain.
It works in four parts:
- Pre-processing of the review where the noise (idioms and emoticons) is removed and each word is tagged and stored by the method Part of Speech (POS).
- Aspects and views are extracted to generate a list of top 100 aspect groups and top 100 views. The aspects are identified as nouns and noun phrases, and the views as sentiment words, adjectives and known sentiment words which occur near an aspect.
- Then the lexicon-based approach is used to give a “sentiment value” to any sentiment word and generates features for the supervised machine learning algorithm.
- Algorithm generates a “feature vector” for each aspect which is either the sum of the sentiment value for a sentiment word or the number of occurrences of this word in relation with other adjectives.
To evaluate this method, experiments were conducted on software reviews (more than 10,000) and movie reviews (7,000) datasets. Software reviews were separated into software editor reviews and customer software reviews categories. In their experiments, pSenti’s accuracy was proved close to the pure learning-based system and higher than the pure lexicon-based method. It was also shown that the performance was not as good on customer software reviews as on software editor reviews because customer software reviews are usually much “noisier” (with comments that are irrelevant to the subject) than professional software editor reviews. Its accuracy was also affected by many reviews for which it did not detect any sentiment or assigned neutral score. However, the sentiment separability in movie reviews was much lower than in software reviews. One of the reasons is that many movie reviews have plot descriptions and quotes from the movie where words are identified as sentiments by the system (Collomb et al., 2014; Mudinas, Zhang, & Levene, 2012).
2.3.3. Interdependent Latent Dirichlet Allocation
(Moghaddam & Ester, 2011), introduced Interdependent Latent Dirichlet Allocation (ILDA) in 2011. They introduced the probabilistic assumption that there is interdependency between an aspect and its corresponding rating. ILDA is a probabilistic graphical model which shows each review as a mixture of latent aspects and ratings. It assumes that aspects and their ratings can be represented by multinomial distributions and tries to cluster head terms into aspects and sentiments into ratings. ILDA relies on a concept introduced in 2003 by (Blei, Ng, & Jordan, 2003). Latent Dirichlet Allocation (LDA). It is a generative probabilistic model for collections of discrete data such as text corpora. The basic idea is that each item of a collection is modeled as a finite mixture over an underlying set of latent variables.
Their experiments showed notable improved results for ILDA compared to the other two graphical models described in the paper (PLSI and LDA), gaining in average almost 20% for the accuracy of rating prediction. They obtain in average 83% accuracy in aspect identification and 73% accuracy in aspect rating.
2.3.4. A Joint Model of Feature Mining and Sentiment Analysis
This solution was introduced in 2011 by (de Albornoz, Plaza, Gervás, & Díaz, 2011). The authors propose a method that globally rates a product review into three categories by measuring the polarity and strength of the expressed opinion. This solution was chosen as a representative of the global rating solutions, as it goes further than other solutions; It tries to find the strength of the opinion as well as the relevance of the feature the opinion is about.
The mechanism of this method is straightforward:
- Important features are found
- Sentences having opinions on those features are found in the body of the review and polarity and strength are computed
- Next, a global score is computed. The method does not rely on any earlier knowledge about the importance of the features to the customer, contrary to Hu and Liu, but learn it from a set of reviews using an unsupervised model. Another contribution is that each feature is automatically weighted. Feature importance and opinion extraction, as well as opinion rating rely on the WordNet lexical database for English. This can be an important disadvantage of the method, as it cannot be applied on reviews written in other languages.
- The fourth step – rating reviews are predicted and these reviews are structured using Vector Feature Intensity (VFI) graph. It is constructed using the strength of the opinion and the relevance of the feature. This graph is fed as input to any machine learning algorithm that will classify the review into different rating categories.
This solution offers flexibility when it comes to choosing the best machine learning method for classifying reviews.
2.3.5. Opinion Digger
The solution Opinion Digger was introduced in 2010 by (Moghaddam & Ester, 2010) and is a good and exact example of a completely unsupervised machine learning method. The particularity of this solution is to use as input a set of known aspects of a product and a ratings guideline (5 means “excellent” 4 means “good”). With these elements, Opinion Digger finds and outputs a set of other aspects and ratings in each aspect according to the guideline. The impetus for this research was based on the fact that many reviewing websites like amazon.com provide these input elements but there was no method that used them.
Opinion digger works in two steps:
- In the first phase, Opinion Digger decides the set of aspects. After the pre-processing, each sentence is tagged with POS. It assumes that aspects are nouns so it first isolates the frequent nouns as potential aspects. With the sentences matching the known aspects, they determine opinion patterns as sequence of POS-tags that expressed opinion on an aspect. The frequent patterns used with known aspects are considered opinion patterns. If reviews with a “potential aspect” noun match at least two different opinion aspects, Opinion digger considers the noun as an aspect.
- The second phase is rating the aspects. For each sentence having an aspect, Opinion Digger associates the closest adjective to the opinion. It searches two synonyms from the guideline in the WordNet synonymy graph. The estimated rating of the aspect is the weighted average of the corresponding rating in the guideline. Weight is calculated by the inverse of the smallest path distance between the opinion adjective and the guideline’s adjective in the WordNet hierarchy.
The experiments show good performance in aspect determination and an excellent accuracy in ratings. The evaluation of aspect ratings was made using only the known set of aspects and compared to 3 other unsupervised methods. Opinion Digger performs with an average ranking loss of only 0.49 which is the difference between estimated and actual ratings. By incorporating new current information in the machine learning process, Opinion Digger increases the accuracy of the unsupervised machine-learning method.
2.3.6. Latent Aspect Rating Analysis
This solution treats a special problem called Latent Aspect Rating Analysis with a model-based method. The model is called the Latent Rating Regression (LRR) model and was created by (Wang, Lu, & Zhai, 2010). It estimates ratings on different aspects in a review but also decides the emphasis of the author on each aspect. It uses a given set of aspects and the overall ratings of the review. It starts with an aspect-segmentation step. By recursively associating words with aspects, it builds an aspect dictionary and links each phrase of a review to the corresponding aspect, then it applies the model. The assumption of reviewer’s rating behavior is as follows: to generate an opinionated review the reviewer first decides the aspects for reputation evaluation that she/he wants to comment on; and then for each aspect, the reviewer carefully chooses the words to express her/his opinions. The reviewer then forms a rating on each aspect based on the sentiments of words she/he used to discuss that aspect. Finally, the reviewer assigns an overall rating depending on a weighted sum of all the aspect ratings, where the weights reflect the relative emphasis she/he placed on each aspect. So, the overall rating is not directly decided by the words used in the review but rather by latent ratings on different aspects which are decided by the words.
With a probabilistic regression approach, Latent Aspect Rating Analysis converts the model into a Bayesian regression problem, and then decides the aspect ratings and weight with consideration to the author’s intent. The overall rating r is assumed to be a sample drawn from a Gaussian distribution with variance delta square and mean the weighted sum of the aspect ratings S. S is the result of the weighted sum of the words W in the reviews. A multivariate Gaussian distribution is employed as the prior for aspect weight’s alpha.
The experimentation shows an average performance compared to other unsupervised methods in aspect ratings. However, it achieves what it set out to achieve—to estimate an aspect’s weight (Collomb et al., 2014; Wang et al., 2010).
2.3.7. More approaches and tools
In this section, we go on to introduce some more research and tools in the area of sentiment analysis.
(Asghar, Khan, Ahmad, Qasim, & Khan, 2017) looked at enhancing the performance of sentiment analysis and resolving the issues of data sparseness and incorrect classification caused by the presence of noisy text, emoticons, modifiers and domain specific words (See Figure 3). The basic theme was to reduce noise from the review text by applying different pre-processing steps and processes through a variety of classifiers. The proposed method was used to test the text from different online forums; the reviews compiled from these sources were used as input items.
One simple way proposed to detect the polarity of a message is based on the emoticons it contains. Emoticons have become popular in recent years, to the extent that some (e.g. <3) are now included in English Oxford Dictionary. Emoticons are primarily face-based and represent happy or sad feelings, although a wide range of non-facial variations exist: for instance, <3 represents a heart and expresses love or affection. To extract polarity from emoticons, a set of common emoticons, which also includes popular variations that expresses positive, negative and neutral sentiments, are utilized (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
Linguistic Inquiry and Word Count (LIWC)is a text analysis tool that evaluates emotional, cognitive, and structural components of a given text based on the use of a dictionary containing words and their classified categories. In addition to detecting positive and negative effects in each text, LIWC provides other sets of sentiment categories. For example, the word “agree” belongs to the following word categories: assent, affective, positive emotion, positive feeling, and cognitive process (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
Machine-learning-based methods are suitable for applications that need content-driven or adaptive polarity identification models. Several key classifiers for identifying polarity in online social network data have been proposed in the literature. A very comprehensive work developed SentiStrength which compared a wide range of supervised and unsupervised classification methods, including simple logistic regression, SVM, J48 classification tree, JRip rule-based classifier, SVM regression, AdaBoost, Decision Table, Multilayer Perception, and Naive Bayes. It was shown that, SentiStrength implements the state-of-the-art machine learning method in the context of online social networks. SentiStrength version 2.0, is available at http://sentistrength.wlv.ac.uk/Download (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
SentiWordNet is a tool that is widely used in opinion mining, and is based on an English lexical dictionary called WordNet. Wordnet groups adjectives, nouns, verbs and other grammatical classes of a word into synonym sets called synsets. SentiWordNet associates three scores—positive, negative, and objective (neutral)—with synsets from the WordNet dictionary to indicate the sentiment of the text. The scores, which are in the values of [0, 1] and add up to 1, are obtained using a semi-supervised machine learning method SentiWordNet was evaluated with a labeled lexicon dictionary. To assign polarity based on this method, the average scores of all associated synsets of a given text are considered, and the text is considered to be positive if the average score of the positive affect is greater than that of the negative affect. Scores from objective sentiment were not used in determining polarity. SentiWordNet version 3.0, which is available at http://sentiwordnet.isti.cnr.it/. WordNet is discussed in Chapter 3 and SentiWordNet in Chapter 4 (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
SenticNet is a method of opinion mining and sentiment analysis that explores artificial intelligence and semantic Web techniques. SenticNet infers polarity of common sense concepts from natural language text at a semantic level (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
The method uses NLP techniques to create a polarity for nearly 14,000 concepts. For example, to interpret a message “Boring, it’s Monday morning”, SenticNet first tries to identify concepts, which are “boring” and “Monday morning”. Then it assigns a polarity score to each concept, in this case, -0.383 for “boring”, and +0.228 for “Monday morning” (Gonçalves, Araújo, Benevenuto, & Cha, 2013). The resulting sentiment score of SenticNet is an average of the polarity scores which is -0.077. The National Health Service in England used SenticNet to test and evaluate the polarity in opinions of patients about the health service. We use SenticNet version 2.0, which is available at http://sentic.net/ (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
SASA is a method based on machine learning techniques such as SentiStrengh and was evaluated with 17,000 labeled tweets on the 2012 U.S. Elections. The open source tool was evaluated by the Amazon Mechanical Turk (AMT), where “turkers” were invited to label tweets as positive, negative, neutral, or undefined. The SASA python package version 0.1.3 is available at https://pypi.python.org/pypi/sasa/0.1.3 (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
Happiness Index is a sentiment scale that uses the popular Affective Norms for English Words (ANEW). ANEW is a collection of 1,034 words commonly used associated with their affective dimensions of valence, arousal, and dominance. Happiness Index was constructed based on the ANEW terms and has scores for a given text between 1 and 9, indicating the amount of happiness existing in the text. The authors calculated the frequency that each word from the ANEW appears in the text and then computed a weighted average of the valence of the ANEW study words. The validation of the Happiness Index score is based on examples. ANEW was applied to a dataset of song lyrics, song titles, and blog sentences. It was found that the happiness score for song lyrics had declined from 1961 to 2007, while the same score for blog posts in the same period had increased (Gonçalves, Araújo, Benevenuto, & Cha, 2013). To adapt Happiness Index for detecting polarity, any text that is classified with this method in the range of [1..5] is considered to be negative and in the range of [5..9] to be positive.
PANAS-t is a psychometric scale proposed for detecting mood fluctuations of users on Twitter. The method consists of an adapted version of the Positive Affect Negative Affect Scale (PANAS), which is a method in psychology. PANAS-t is based on a large set of words associated with eleven moods: joviality, assurance, serenity, surprise, fear, sadness, guilt, hostility, shyness, fatigue, and attentiveness (Gonçalves, Araújo, Benevenuto, & Cha, 2013). This method is used to track any increase or decrease in sentiments over time and to associate text to a sentiment, PANAS-t first utilizes a baseline or the normative values of each sentiment based on the entire data. Then the method computes the P(s) score for each sentiment s for a given time as values between [−1.0, 1.0] to indicate the change. For example, if a given set of tweets contain P(“surprise”) as 0.250, then sentiments related to “surprise” increased by 25% compared to a typical day. Similarly, P(s) = −0.015 means that the sentiment s decreased by 1.5% compared to a typical day (Gonçalves, Araújo, Benevenuto, & Cha, 2013).
There are various other solutions in the market which offer a variety of opinion mining tools; most of them are custom made to analyze the sentiments from customer reviews about products and services by interpreting natural language. An example of a freely available application that simply analyzes terms can be found at http://twitrratr.com/ (Cieliebak, Dürr, & Uzdilli, 2013).
Wordclouds are also becoming more and more used in making sense of large quantities of information in a snapshot and is a popular solution for word visualization. Such tools are also extremely simplified and only offer a visualization of the most commonly used terms, which gives an idea of what the document is about. Tools such as those available at www.wordle.com offer an appealing design solution that can serve as an entry level in the opinion mining market (Cieliebak, Dürr, & Uzdilli, 2013).
Another way of classifying or making sense of large amount of information is to rely on human effort using collective intelligence and or crowdsourcing, where people will not only filter but also signal the most important ones. The website www.uservoice.com provides such a tool which allows users to send feedback and rate other users’ ideas, and this helps in creating new ideas (Cieliebak, Dürr, & Uzdilli, 2013).
There is a flourishing market of enterprise-level software for opinion mining with much more advanced features. These tools are largely in use by companies to monitor their reputation and the feedback about products on social media. In the government context, opinion mining has long been in used as an intelligence tool to detect hostile or negative communications. These tools rely on machine learning for finding and classifying relevant comments, using a combination of latent semantic analysis, support vector machines, “bag of words” and semantic orientation. These processes need significant human effort aided by machines; tools in the market rely on a combination of machine and human analysis, typically using machines to augment human capacity to classify, code and label comments. Automated analysis is based on a combination of semantic and statistical analysis. Recently, because of the sheer increase in the quantity of datasets available, statistical analysis is becoming more important (Cieliebak, Dürr, & Uzdilli, 2013).
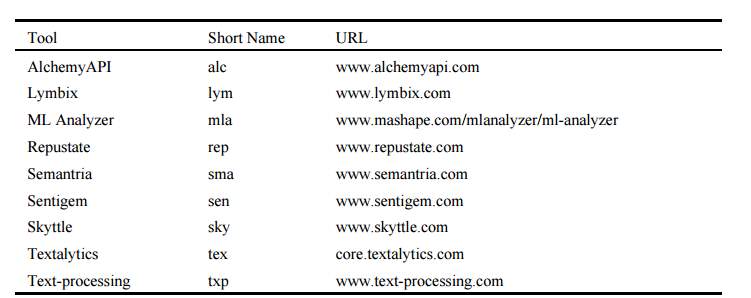
Table 2 lists some of the commercially available sentiment analysis tools which can analyze arbitrary texts, with free API access and are available free of charge (Cieliebak, Dürr, & Uzdilli, 2013).
Table 2 Commercial Tools. (Source: Cieliebak et al., 2013)
2.4 Sentiment analysis in the medical field
As the goal of this thesis is to analyze sentiments expressed by patients of a medical centre, a review of existing research on sentiment analysis in the medical field was undertaken. Such literature can be grouped based on textual source (e.g. medical web content, biomedical literature and clinical notes), task (e.g. polarity analysis, outcome classification), method (e.g. rule-based, machine-learning based) and level (e.g. word level, sentence level).
2.4.1 Sentiment analysis from the medical web
Most research on sentiment analysis in the domain of medicine considers web data such as medical blogs or forums for mining or studying patient opinions or measuring quality. For example, a method was introduced that separates factual texts from experiential texts to measure content quality and credibility in patient-generated content. As factual content is better than affective content since more information is given (in contrast to moods and feelings), a system has been developed using subjectivity words and a medical ontology to evaluate the factual content of medical social media.
As in general sentiment analysis, existing approaches to sentiment analysis from medical web data are either machine-learning based or rule-based. Most of the work focuses on polarity classification.
(Xia, Gentile, Munro, & Iria, 2009) introduced a multi-step approach to patient opinion classification. Their approach decides the topic and the polarity expressed towards it. An F-measure of around 0.67 was reported.
(Sokolova, Matwin, Jafer, & Schramm, 2013) tested several classifiers including naive Bayes, decision trees and support vector machines for the sentiment classification of tweets. Texts were represented as bags of words. Two classification tasks were considered: three-class (positive, negative and neutral) and two-class (positive, negative). The best F-measure of 0.69 was achieved with an SVM classifier.
The work by (Biyani et al., 2013) focused on determining the polarity of sentiments expressed by users in online health communities. More specifically, they performed sentiment classification of user posts in an online cancer support community (cancer survivors network) by exploiting domain-dependent and domain-independent sentiment features as the two complementary views of a post and exploiting them for post-classification in a semi-supervised setting employing a co-training algorithm. This work was later extended with features derived from a dynamic sentiment lexicon, while the previous work used a general sentiment lexicon to extract features.
(Smith & Lee, 2012) studied another aspect of sentiment in patient feedback, namely discourse functions such as expressiveness and persuasiveness. A classifier was evaluated based on a patient feedback corpus from NHS Choices. The results illustrate that the multinomial naive Bayes classifier with frequency-based features can achieve the best accuracy (83.53%). Further, the results showed that a classification model trained solely on an expressive corpus can be directly applied to the persuasive corpus and achieve a performance comparable to the training based on the corpus with the same discourse function.
(Sharif, Zaffar, Abbasi, & Zimbra, 2014) presented an interesting application of sentiment analysis with their extracts of semantic, sentiment and affect cues for detecting adverse drug events reported by patients in medical blogs. This approach can reflect the experiences of people when they discuss adverse drug reactions as well as the severity and emotional impact of their experiences.
(Na et al., 2012) presented a rule-based linguistic approach for the sentiment classification of drug reviews. They used existing resources for sentiment analysis, namely SentiWordNet and the Subjectivity Lexicon, and came up with linguistic rules for classification. Their approach achieved an F-measure of 0.79. Additional work has tackled the detection and analysis of emotion in medical web documents.
(Sokolova & Bobicev, 2013) considered the categories encouragement (e.g. hope, happiness), gratitude (e.g. thankfulness), confusion (e.g. worry, concern, doubt), facts, and facts + encouragement. They used the affective lexicon WordNetAffect for emotion analysis of forum entries. However the f-score achieved, with a naive Bayes classifier, was 0.518.
Also, it is interesting to note the work of (Melzi et al., 2014) who applied an SVM classifier on a feature set comprising unigrams, bigrams and specific attributes to classify sentences into one of six emotion categories.
2.4.2 Sentiment analysis from biomedical literature
In addition to medical social media data, biomedical literature has been analyzed with respect to the outcome of a medical treatment. In this context, sentiment refers to the outcome of a treatment or intervention. Four classes were considered in existing work: positive, negative, neutral outcome and no outcome. (Niu, Zhu, Li, & Hirst, 2005) used a supervised method to classify the (outcome) polarity at sentence level. Unigrams, bigrams, change phrases, negations and categories were employed as features. As per the results, the algorithm’s accuracy was improved by the usage of category information and context information derived from a medical terminology ontology—the unified medical language system.
(Sarker, Mollá-Aliod, & Paris, 2011) developed a new feature called the relative average negation count (RANC) to calculate polarity with respect to the number and position of the negations. This count suggests that a larger total number of negations reflects a negative outcome. The experimental corpus was collected from medical research papers, which are related to the practice of evidence-based medicine. An NGram feature set with RANC exploited by an SVM classifier achieved an accuracy of 74.9%.
2.4.3 Sentiment analysis from other medical texts
Researchers have focused medical texts to apply sentiment analysis methods to suicide notes which was a shared task in an i2b2 challenge. (Cambria, Benson, Eckl, & Hussain, 2012) introduced Sentic PROMs, where emotion analysis methods were integrated into a framework to measure healthcare quality. In a questionnaire, patients answered questions regarding their health status. From the free text entered, emotion terms such as “happy” and “sad” were detected using the semantic resources WordNet-Affect and ConceptNet. The extractions were assigned to one of 24 affective clusters following the concept of hourglass of emotions. Performance was promising with an F-score of 0.61 being achieved with an SVM classifier. This concept presents the affective common-sense knowledge in terms of a vector, which shows the location in the affective space.
2.4.4 Summary of medical opinion mining approaches
In summary, existing methods for sentiment analysis in the medical domain so far have focused on processing web content or biomedical literature. The clinical narratives which are used to record the activities and observations of physicians as well as patient records have not yet been analyzed in this context. In terms of methods, rule-based approaches are presented, but most papers report on machine-learning methods (SVM, naive Bayes, and regression tree) using features such as parts of speech and uni-band trigrams. Although general sentiment lexicons are exploited, experiments showed that they are not well suited for capturing the meanings in medical texts. In contrast to “normal” sentiment analysis, additional domain-specific features have been explored in some approaches, mainly UMLS concepts reflecting medical conditions and treatments. The main tasks considered have been polarity classification, but new tasks are emerging including outcome classification, information content classification or emotion analysis. However, the existing work on medical sentiment analysis does not cover all facets of sentiment analysis described in Section 2. In summary, there is still a huge potential for future research.
2.5 N-Grams
N-grams is one of the most used techniques for solving the problem of language recognition that is used in information retrieval (Jacob and Gokhale, 2007). N-gram based techniques are used in NLP and its applications where they are used as features to create vector space and then classification algorithms are applied to this model. The values of these features are n-grams frequencies. Traditional N-grams can be a sequence of words in a text, POS tags, or any other elements as they appear one after the other. N-grams correspond to the number of elements in a sequence (Sidorov, Velasquez, Stamatatos, Gelbukh, & Chanona-Hernández, 2014). N-grams are substrings of a large string of length n which is split in to strings of fixed length. For example, the string “MALWARE”, can be segmented into several 4-grams: “MALW”, “ALWA”, “LWAR”, “WARE” and so on (Santos, Penya, Devesa, & Bringas, 2009).
N-gram technique has been used for analysis for quite a long time in the field of NLP for tasks such as language modelling and speech recognition. In 1994, character n-gram was used mainly for text categorization, but currently, common n-gram (CNG) analysis has been successfully applied to authorship attribution, detection of dementia and text clustering.
2.5.1 How N-grams Work
Text n-grams are used widely in NLP for text mining tasks.
N-grams are co-occurring words in each window selected from a sentence and while computing n-gram we move forward on words.
Consider the following sentence “The cow jumps over the moon”. To calculate bigram where N=2, N-gram for the sentence would be:
- the cow
- cow jumps
- jumps over
- over the
- the moon
For N=3, the n-grams would be:
- the cow jumps
- cow jumps over
- jumps over the
- over the moon
So, bigram generated 5 n-grams whereas trigram generated 4 n-grams. For unigram, N=1 and this is essentially the individual words in a sentence. When N>3 this is usually referred to as four grams or five grams and so on.
If X = Number of words in each sentence K, the number of n-grams for sentence K would be:
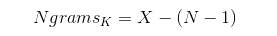
Equation 1 Calculating N-Gram (Source: Banerjee & Pedersen, 2003)
It is essential to identify tokens in a sentence as N-grams are formed by connecting tokens (Banerjee & Pedersen, 2003).
2.5.2 Use and application of N-grams
N-grams are used for a variety of tasks such as developing a language model which can be unigram or bigram or trigram model. Microsoft and Google have developed web scale n-gram models which are used for a variety of tasks such as spelling correction, text summarization and word breaking.
N-grams are also used in developing features for supervised machine learning classification algorithms such as SVMs, MaxEnt models, Naive Bayes, etc. The idea is to use tokens such as bigrams in the feature space instead of just unigrams. But the use of bigrams and trigrams in feature space may not necessarily yield any significant improvement.
N-gram methodologies are used a great deal in statistical modeling which is used for predicting the next word in any sentence. The language model predicts that the probability of the next word depends on last n-1 words.
Shannon game is an application which tries to guess the next letter (Shannon, 1951). (Damashek, 1995) measured topical similarity in unrestricted text using n-grams while (Huang, Peng, Schuurmans, Cercone, & Robertson, 2003) identified boundaries of sessions using n-grams in a large collection of Livelink log data. (Cavnar & Trenkle, 1994) researched electronic documents, and they calculated the frequency of n-grams in terms of textual errors, such as spelling and grammatical errors. (Roark, Saraclar, & Collins, 2007) used a discriminative n-gram approach for speech recognition. N-gram language modeling can be used for optical or speech character recognition, handwriting recognition, spelling correction and statistical machine translation. Spelling errors can be detected using character n-grams and is used in predicting topic continuations in search engine queries, more than word n-grams.
(Mcnamee & Mayfield, 2004) used the character n-gram method for multilingual text retrieval. They aimed to show that the character n-gram tokenization can provide retrieval accuracy better than the other language specific approaches. (Liu & Kešelj, 2007) studied automatic classification of web user navigation patterns, and they implemented the character n-gram method for capturing textual content of web pages. (Kanaris & Stamatatos, 2007) studied about webpage genre identification for improving the quality of search engines, and they applied the character n-gram method to identify of webpage genres. (Chau, Lu, Fang, & Yang, 2009) researched the character usage of Chinese search logs from Chinese search engines; since the character n-gram method is independent from language, they implemented this method to their study without any difficulty. (Vilares, Vilares, & Otero, 2011) used the classic stemming based methods and the character n-gram method for identifying spelling mistakes and make corrections in Spanish. They compared these methods and showed performance results in their study. In addition to these studies, (El-Nasan A. & M., 2002; Senda & Yamada, 2001) used the character n-gram method in handwriting recognition (Gencosman, Ozmutlu, & Ozmutlu, 2014).
Next, we look at code which can be used to generate N-grams.
2.5.3 Pseudo-code to generate N-grams
The following code may be used to generate N-gram(s); given length of n-gram to be generated and a sentence, a list is returned which will hold the list of n-grams generated.
void GenerateNGrams(int N, String sent) {
String [] tokens = sent.split(“\s+”); //split sentence into tokens
List<string> ngramList = new List<string>();
//GENERATE THE N-GRAMS
for (int k=0; k < (tokens.length – N+1); k++) {
String s=””;
int start=k;
int end=k+N;
for (int j=start; j<end; j++) {
s=s+””+tokens[j];
}
//Add n-gram to a list
ngramList.add(s);
}
}
2.6 Gaps and Key Challenges
Solutions for sentiment analysis are being developed, typically by reducing the amount of human effort needed to classify text. But there are challenges that have been identified and are applicable to this thesis.
1. Detecting fake reviews and spam, which is done by identifying duplicates and outliers and the reputation of reviewers.
Fake reviews refer to fake or bogus reviews which misguide the users or customers by providing them ‘false’ positive or negative opinion about any object. Spam makes opinion or sentiment analysis useless in many areas and is a challenge faced by sentiment analysis and researchers (Chandni, 2015).
2. The integration of opinion with behavior and implicit data, to validate and provide further analysis into the data beyond opinion expressed.
3. Availability of opinion mining software, currently can only be afforded by organizations and governments, but not by citizens. In other words, governments have the means today to monitor public opinion in ways that are not available to the average citizen. Citizens produce and publish content but are unable to analyze it.
4. The usability and user-friendliness of tools need to be improved so as to be usable by citizens and not just by data analysts (Osimo & Mureddu, 2012).
5. Language Problem: Researchers always face a challenge for building lexicons, corpora and dictionaries for any language although there are a number of resources available for English language.
6. NLP processing needs more enhancement with respect to domain-dependent sentiment analysis and or context-based mining, which will give good results compared to domain independent corpus. But domain-dependent corpora are more difficult to build (Chandni, 2015).
2.7 Summary
This chapter presented a literature review of areas closely aligned with the topic of this thesis. It was found that current research focusses on: Reduction of human effort needed to analyze content; Semantic analysis through lexicon/corpus of words with known sentiment for sentiment classification; Identification of opinionated material to be analyzed; and Computer-generated reference corpuses in the healthcare field. We then looked at N-Grams, which is a technique widely used for text mining, the algorithm used to calculate n-grams and the pseudo code which can be written in any programming language to generate n-grams.
Current gaps in research and key challenges in the field were also presented.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Medicine"
The area of Medicine focuses on the healing of patients, including diagnosing and treating them, as well as the prevention of disease. Medicine is an essential science, looking to combat health issues and improve overall well-being.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: