Storage Services Security in Cloud Computing using Soft and Hard Decoding
Info: 12129 words (49 pages) Dissertation
Published: 17th Feb 2022
Tagged: Cyber Security
Abstract
Cloud Computing is an archetype of net based computing that allocates shared computer processing resources and data to various users. It offers services such as storage, processing, managing of data along with delivery of other services such networking, analytics etc. The domain and realm of Cloud Computing is an expansive domain furnishing new developments steadily. One of the most indispensable domain of Cloud Computing called Cloud Storage, is a framework of data storage which stores the data in logical pools allowing multiple servers and access at once. They are accessed through a web service Application Programming Interface (API) or by applications that deploy API, for instance Cloud Desktop Storage or Cloud Storage Gateway. Consequently it is imperative for host companies to ensure that Cloud Storage security is not jeopardized. Many research scholars have already given hefty contributions in this domain employing Genetic Algorithm and Round Robin Algorithm. In this thesis I emphasize my research work on Storage Services Security in Cloud Computing using Soft and Hard Decoding for erasure code using Genetic Optimization. Soft and Hard Decoding is employed to check for the parity (timestamp).
TABLE OF CONTENTS
Click to expand Table of Contents
1. INTRODUCTION
1.1 What is Cloud Computing
1.1.2 History of Cloud Computing
1.1.3 Essential Properties of Cloud Computing
1.1.4 Deployment Models
1.1.5 Service Models
1.1.6 Cloud Risks Evaluated
1.2 Research Objective
1.3 Scope of Research
1.4 Research Gap
1.5 Research Methodology
1.6 Work done in six months
1.7Organization of Thesis
1.8 Summary
2. LITERATURE SURVEY AND REVIEW
2.1 Introduction
2.2 Review of Related Literature
2.3 Problem Identification
2.4 Summary
3. DESIGN AND DEVELOPMENT OF PROPOSED APPROACH
3.1 Introduction
3.2 Tradition Method
3.2.2 Algorithm Used
3.2.3 Flowchart for algorithm
3.3 Proposed Method
3.3.1 Proposed Algorithm
3.3.2 Proposed Flowchart
3.4 Platform Used
3.5 Summary
4. RESULT AND ANALYSIS
4.1 Introduction
4.2 Base paper End Results
4.3 Proposed Approach Results
4.3.1 Simulation Graphs
4.3.2 Calculation table
4.3.3 End Result Graphs
4.4 Comparison table of Base Result and Proposed work result
4.5 Summary
5. FUTURE SCOPE AND CONCLUSION
5.1 Introduction
5.2 Future work and Scope of Research
5.3 Conclusion
5.4 Summary
6. REFERENCES
LIST OF FIGURES
1. Evolution of cloud computing
2. Deployment Models in Cloud
3. Service Models
4. Microsoft Office 365 (SaaS)
5. Microsoft Windows Azure (PaaS)
6. Windows Azure (IaaS)
7. Flowchart for Research Methodology
8. Optimization using Genetic Algorithm (GA)
9. GA and it’s Composition
10. Encoding and Decoding In Genetic Algorithm GA
11. Flowchart for Algorithm used
12. Proposed Flowchart
LIST OF TABLES
1. Calculation Table
2. Comparison Table
CHAPTER 1: INTRODUCTION
1.1 INTRODUCTION
1.1.1 WHAT IS CLOUD COMPUTING?
Cloud Computing finds multitude definitions and uses which varies with its diverse applications in the Industry; local as well as offshore influence. It is rapidly growing technology which plays a pivotal role in storage, shared resources and network services of individuals and enterprises alike. Some say it’s a remote virtual pool of on-demand shared resources which is scalable in aspect. I would like to add that, in essence Cloud Computing is caching data in warehouses and accessing it’s programs by the means of Internet and shared network rather than personal computers (PCs). Cloud Computing is revamping the face of numerous organisations and incorporations creating and boasting global impact. With the facility of cloud computing comes the ease of storage, access, compute, network services etc.
To understand Cloud Computing it is imperative to also hold an understanding of VIRTUALISATION. Virtualisation refines and increases the potency of Cloud Computing. Virtualisation is defined as the modelling of various virtual (not real) machines each running a separate operating system or server in order to procreate a storage device or network resource. Like Cloud, virtualisation has also metamorphosed into a buzzword and is analogous with different computing technologies; serving different purposes.
1.1.2 HISTORY OF CLOUD COMPUTING
Origin of the term Cloud Computing is ambiguous and cannot be clearly traced to a particular episode. However the word cloud has been mentioned in many places and is hinted to be first used as early as 1950s. Also the term Cloud has been used as metaphor for Internet and a cloud like shape was popular for depicting network in telephony semantics. Later this symbol become widely popular for representing computing equipment networks in APARNET(1977) and CISNET(1981) both were also known as predecessors of Internet. Throwback to the time of 1960s cloud has become a buzz word, an umbrella term for different computing techniques such as network services, distributed computing, shared pool of resources. Over the decades Cloud Computing has witnessed evolution on different levels as explained below:
1960s – 1970s
In this time period the primary concepts of time-sharing became popular via RJE (Remote Job Entry); associated with IBM and DEC. Full time-sharing solutions were made available from early 1970s on platforms such as Cambridge CTSS , Multics (on GE hardware), and the earliest UNIX ports (on DEC hardware).
1990s
In 1990s telecommunications companies began offering virtual private network (VPN) services with competitive and enhanced quality of service, that too at a lower cost. Overall network bandwidth was utilised more effectively by bypassing traffic. Cloud computing stretched this borderline to cover all servers as well as the network infrastructures. Moreover cloud symbol was used to illustrate the distinction point between the roles and responsibilities of provider as well as users. Time-sharing was explored beyond the realm of normal personal computing, also discovering ways to enhance the impact of large-scale computing. Experiments were conducted employing algorithms to effectively make the best of productivity of the infrastructure, platform, and applications to prioritize CPUs and enlarge efficiency for end users.
2000s
From 2000 onwards, hybrid clouds were first used. In early 2008, NASA’s OpenNebula, enriched in the RESERVOIR European Commission-funded mission, became the first open-source software for set up of hybrid and private clouds, and for the federation of clouds. In the same year, efforts were made on providing quality of service guarantees to cloud-based infrastructures, in the framework of the IRMOS European Commission-funded project, resultant of which was in a real-time cloud environment. By mid-2008, Gartner an American incorporation and research and advisory firm saw a chance for cloud computing “to shape the relationship among consumers of IT services, those who use IT services and those who sell them” and noted that “organizations are switching from company-owned hardware and software assets to per-use service-based models”
1. Evolution of cloud computing
1.1.3 ESSENTIAL PROPERTIES OF CLOUD COMPUTING
The 5 standard characteristics of Cloud Computing are named below:
- On demand self service
- Rapid Elasticity
- Broad Network access
- Measured Service
- Resource Pooling
On-demand self-service: Consumers are able to utilise network storage, as per requirements with no assistance and human interaction from service providers.
Broad Network Access: Capabilities are accessible over the network and accessed through standard mechanisms that encourage use by mixed thin or thick client platforms (e.g., mobile phones, tablets, laptops and workstations).
Resource pooling: The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence as in the customer possess no control or knowledge over the exact location of the provided resources. Examples of resources include storage, memory, processing and network bandwidth.
Rapid elasticity: Capabilities can be flexibly supplied and released, in some cases, for scalability of outward and inward corresponding with demand. Capabilities for consumers are limitless and can be accessed at any particular time with no time-bound restriction.
Measured service: Cloud systems inadvertently controls and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service Resource usage can be monitored, controlled and reported, providing transparency for the provider and consumer.
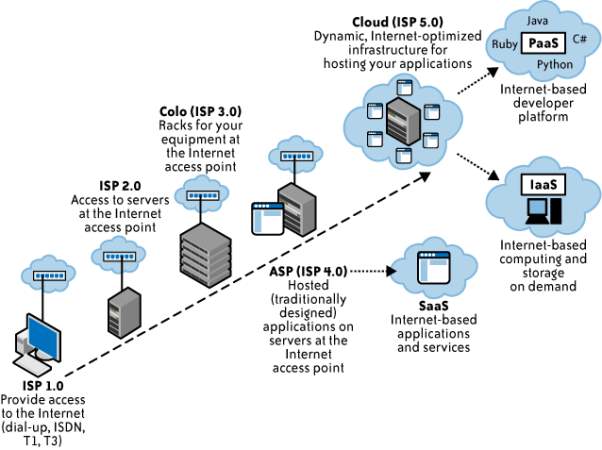
1.1.4 DEPLOYMENT MODELS
Deployment is the process of making the software accessible and ready for use by the users. Deployment models represent cloud environment and are differentiated on the basis of ownership, availablity and capacity. It illuminates about the core essence of cloud. There are 4 kind of deployment models in cloud namely Public Cloud, Private Cloud, Community Cloud and Hybrid Cloud. They are explained below.
2. Deployment Models in Cloud
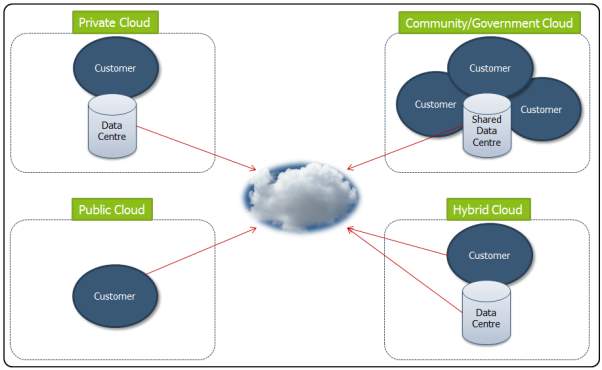
Private cloud. It is the cloud infrastructure which is provisioned for exclusive use by a single organization consisting of multitude consumers (users). The platform on which cloud implementation and execution takes place is highly secure and safeguarded against external attacks and threats and the access over data control lies only with authorised users. There is also a division of access rights on different levels. It may be owned, managed, and operated by the organization, a third party, or a combination of both. It is also called as Internal Cloud.
Community cloud. This archetype of cloud infrastructure is provided for exclusive use by a specific community of consumers from organizations that have shared interests (e.g., mission, security requirements and traders). The setup is shared on a communal basis such as banks, audit firms It can be owned, managed, and operated by one or more of the organizations in the community, a third party, or some arrangement of them, and it can exist on or off premises. It is highly cost-friendly. The major agenda of users is to drive and achieve their business objectives. It is suitable for enterprises and organisations that are working together on a joint venture.
Public cloud. This Deployment model is an acute representation of Cloud. The cloud infrastructure is provisioned for open use by the general public. It can be owned, managed, and operated by a business, academic, or government organization, or some arrangement of them. It exists on premises of the cloud provider, rendering services and infrastructure to several clients. It is similar in structural design to the Private Cloud Model, notwithstanding is has a lower security level. Yet the location of cloud services and infrastructure is concealed from the users and isn’t made public.
Hybrid cloud. This kind of cloud infrastructure is an alignment of two or more disparate cloud infrastructures such as private, community, or public that continue as unique entities, but are bound together by standard or proprietary technology that allows data and application portability and however managing to retain their individual characteristics and features. Also called as integrated Cloud computing, it increases the cloud capacity and the outcome of infrastructural services also reduces the overhead cost of resources in general by adapting and pooling two distinctive resources as per requirements. Hybrid model is typically used to manage Big Data. Using Hybrid model has both its advantages as well as disadvantages. Flexibility, scalability and security being the pro and interface incompatibility being the con.
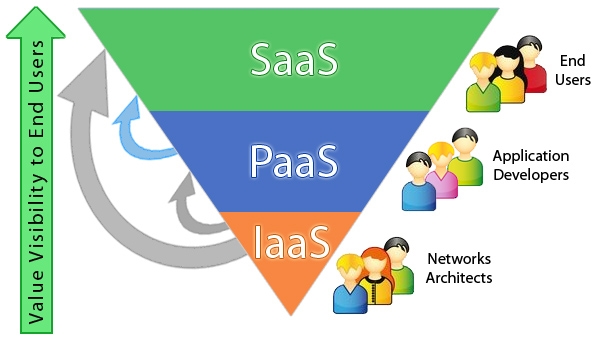
1.1.5 SERVICE MODELS
Cloud provides numerous services such as storage, network topology, collaboration, CRM, Content Management, Identity Management, data warehousing and many more such facilities. The categorisation of cloud services is done by the following methodology depicted in the picture below. The three types of cloud services are namely
- Software as a Service (SaaS)
- Platform as a Service (PaaS)
- Infrastructure as a Service (IaaS)
3. Service Models
Software as a Service(SaaS): The capability provided to the consumer is to use the provider’s applications running on a cloud infrastructure. Only those applications are utilized that are needed for the business. The applications run on provider’s cloud infrastructure and are obtainable from various client devices on the client’s like through either a thin client interface, such as a web browser (e.g., web-based email), or a program interface, or from mobile as well. The consumer does not manage or control the underlying cloud infrastructure including network, servers, operating systems, storage, or even individual application capabilities, with the possible exception of limited user-specific application configuration settings. The inventory of things managed by SaaS are infrastructure, firewalls, operating systems, Load Balancers, runtime environments(.Net and Java), services (CRM), emails and business applications. SaaS comes alongside entirely allocated services with a well-defined feature set. SaaS providers usually offer browser-based interfaces so users can easily attain and customize these services to a certain extent. APIs (Application Programming Interface) are made available for developers as well. Organisations and users that operate on SaaS are labelled “Tenant”, also it does not require beforehand payment and investments in its liaising and set-up. One example of SaaS is Microsoft Office 365 which provides typical Saas services like email, collaboration, online document edit and instant messaging.

4. Microsoft Office 365 (SaaS)
Platform as a Service (PaaS). The capability provisions to the consumer is to deploy onto the cloud infrastructure consumer-created or acquired applications and core hosting operating system that permits the feasibility of running our own applications or third arty-applications.. The consumer albeit does not manage or control the underlying cloud infrastructure (network topology, servers, operating systems, load balancers or storage) but has control over the deployed applications or third party applications. Another advantage to users is that hardware upgradation and running Operating System updates are taken care of. Microsoft Windows Azure and SQL Azure is an example of Platform as a service.
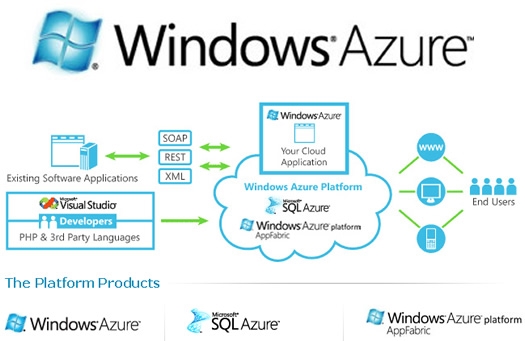
5. Microsoft Windows Azure (PaaS)
Infrastructure as a Service (IaaS). The capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. To deploy applications to the Cloud, user requires to install OS images and related application software on the cloud infrastructure. It’s the responsibility of user to maintain and upgrade the OS. The Cloud provider will typically bill you on computing power by the hour and the amount of resources allocated and consumed (as per its service level agreement (SLA). IaaS outsources the elements of infrastructure like Virtualization, Storage, Networking, Load Balancers and so on, to a Cloud Provider like Microsoft. Amongst the benefit of IaaS is that it allows used to engineer their infrastructure according to organisational requirements. Microsoft Windows Azure also serves as Infrastructure as a Service with Linux Virtual Machines.

6. Windows Azure (IaaS)
1.1.6 CLOUD RISKS EVALUATED
Albeit Cloud infrastructure and environment is secure and stable yet it is prone to the following risks. A prior knowledge and study of risks reduces the risk factor and abet to combat the risk involved.
Environmental security — The cluster of computing resources and users in a cloud computing environment also transcends into a cluster of security threats and hazards. Massive size and significance expose cloud adobe subject it to target by malware, brute force attacks, and other security-endangering attacks. Verify with your cloud provider about access controls, vulnerability calculation practices, and patch and configuration management controls to see that they are effectively protecting your data.
Data privacy and security — Hosting confidential data with cloud service providers includes the transference of a considerable amount of an organization’s control on data security to the provider. Ensure your vendor comprehends your organization’s data privacy and security needs. Also, make sure your cloud provider is conscious of particular data security and privacy rules and regulations that apply to your entity, such as HIPAA, the Payment Card Industry Data Security Standard (DCI DSS), the Federal Information Security Management Act of 2002 (FISMA), or the privacy considerations of Gramm-Leach-Bliley Act.
Data availability and business continuity — A major threat to business continuity in the cloud computing environment is loss of internet connection. Question your cloud provider what controls are in place to confirm internet connectivity. In case of vulnerability, access to the cloud provider must be terminated vulnerability is corrected. Finally, the seizure of a data-hosting server by law enforcement agencies may result in the interruption of unrelated services stored on the same machine.
Disaster recovery — Hosting your computing resources and data at a cloud provider makes the cloud provider’s disaster recovery capabilities vitally important to your company’s disaster recovery plans. Know your cloud provider’s disaster recovery capabilities and ask your provider if they been tested.
1.2 RESEARCH OBJECTIVE
- To optimize the data storage, availability and access in cloud networks by giving a distance based matrix using Soft and Hard decision decoding.
- To enhance the flexibility of data storage utilizing Homomorphic function and counter position of erasure code.
- To enhance dynamic cloud storage avoiding Byzantine failures and generate a simulation data fitting part which checks for parity within time-stamps.
- Genetic algorithm, Homomorphic function, erasure code and soft and hard decision decoding are employed for the fulfilment of these objectives.
- To evaluate fitness and check for parity of bits stored in data blocks.
- To minimize the overhead cost of data storage by reducing fragmentation and minimising garbage values with SHGA. ( Soft hard decoding Genetic Algorithm)
1.3 SCOPE OF RESEARCH
Data encryption and security will continue to improve. One of the biggest criticisms of cloud storage is the potential for hackers to access significant amounts of information that can be used for illegitimate purposes. While there is always some risk of a hacker being able to get around security measures, programs have continued to reduce this risk. Better encryption methods and security features based on custom software designs mean data is more secure than it is on your home PC. Cloud storage companies keep experts on staff that are always monitoring networks and servers to ensure the safety and privacy of your files.
Customized Cloud Storage is on the cards for future development. In the future, there will be a lot of companies that choose to have cloud storage and virtual office systems that are designed precisely for them. The advantages of scheme are multi-fold. When one works with a firm, they can make sure that systems are fine tuned for optimum production and workload.
1.4 RESEARCH GAP
The papers studied and reviewed traces its way to the cutting edge advancements in Cloud Storage Security by proposing and executing novel and avant-grade developments. Notwithstanding the accolades, researchers are still lagging behind in certain areas. Following points attempt to sum up the gaps in Research in Cloud Storage Technology that should be worked upon and require careful analysis and attention.
1. In initial evolution of cloud dynamic data was a fairly new concept does not provide robust data dynamics along with security mechanisms. The proposed system takes care of data dynamics too along with auditing services. This design does not support block insertion.
2. This paper does not give discretion so as to how to handle the misbehaviour of Cloud Service Providers (CSPs) who maliciously discard rarely accessed data and sometimes manipulate data loss incidents to maintain reputation and profit margin.
3. There is a wide gap between technology development and business uptake. Most of the papers published in this field deals with architecture setup and implementation of Cloud Computing. The papers published are still revolving around the technological aspect of cloud computing. The research conducted on Cloud in business front is still very much on Ground Level and the contribution of such research is scanty and limited.
4. There exists a massive gap between academic research and industrial practice i.e. there is a broad gap between theoretical background of cloud and methodological implementation. Most of the papers published and publications give details about theoretical aspects and already existing methods and procedures. The market is lacking in new innovations and practical side of the Cloud. Even many Researchers probe further the academic scholarly papers that give a theoretical view about cloud computing. Only a handful of researchers pick papers for experimental results. This is the widest research gap encountered so far.
5. Also there is an monumental gap between theoretical research and solution proposals. Already existing ideas are doing the rounds in the market of cloud computing. Inspite of being a deeply dug topic there are lesser new proposed solutions. Plentiful of ideas are invested in academic and scholar research but very few solutions are pushed forward amongst them
1.5 RESEARCH METHODOLOGY
I have taken the liberty to broadly categorise my Research approach under four categories.
Category 1: Titled Literature Review and Survey. It encompasses the meticulous and detailed study and review of existing and related Literature. It provides the quintessence of existing and corresponding handiwork tendered and landmarks accomplished in the field of Cloud Storage and Security.
Category 2: Titled Problem Identification. Describes in length about the various roadblocks and hindrance encountered by fellow researchers in the past. It communicates about what are the major challenges in the Security domain of Cloud Computing and suggests prospective resolutions.
Category 3: Titled Design and Development of Proposed Approach. It includes in detailed steps the inception and conclusion of entire proposed approach designed with algorithm, matrices, graphs and readings and explains the with text the ideology and methodology behind proposed work.
Category 4: Titled Implementation Result and Analysis of Proposed Model. It illustrates the final result obtained and compares the results in its analysis with contemporary models.
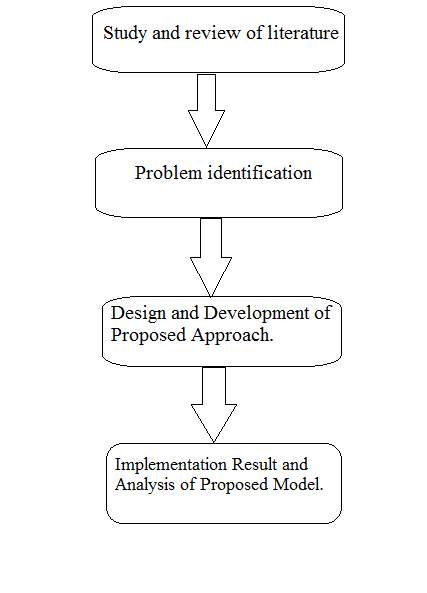
7. Flowchart for Research Methodology
1.6 ORGANIZATION OF THESIS
This thesis has been organized into a total of 5 chapters namely Introduction, Literature Survey and Review, Design and Development of Proposed approach, Implementation Result and Analysis and Future Scope and Conclusion being the final chapter.
Chapter 1: Introduction informs about the acute meaning of the term Cloud, History of Cloud, Essential Properties of Cloud Computing Deployment and service models in Cloud Computing, Cloud Computing Risks and Advantages and Disadvantages of Cloud Computing.
Chapter 2: Literature Survey and Review explains the findings and research of various researchers of the Cloud encompassing Literature Review, Research Gap, Research Methodology, Problem Identification and Research objective.
Chapter 3: Deals with Design and Development Of Proposed approach introducing Proposed algorithm
Chapter 4: It provides the implementation result and the analysis of the result.
Chapter 5: Future Scope and Conclusion. It provides an insight into upcoming trends and innovations of Cloud Computing and concludes the thesis.
1.7 WORK DONE IN SIX MONTHS
From the inception of this term significant energies and efforts were contributed into generating an enhancement model of Secure Cloud Storage which would effectively store the legitimate data as well as prove to be cost effective and minimise overhead cost of Secure Cloud Storage. First and foremost I conducted an in-depth study of Genetic Algorithm, Compact Genetic Algorithm, Soft-Hard Decoder and K-means. I attempted to select out the common features from all to give rise to the hybridisation of an approach that was more potent and effective than it’s contemporaries. In my efforts I had to rule out K-means due to it’s lack of alignment with other mentioned methods and I went on to combine other 3 methods and procedures till I fixated satisfactory results.
In six months a furnishing of a new approach took place with the help of Genetic Algorithm and Soft-Hard decoder. This combination has not been exploited before and it’s an entirely novel concept. Using soft hard decoder I checked for the fitness of the block of codes and data that were ready for storage. I first checked for the fitness using a generic pre-computation token and then I applied soft decoding for the fitness evaluation and lastly I applied soft- hard decoding alongside GA for the fitness check. The block bits were least scattered and wasted in the soft-hard decoding method. The maximum successful transfer and storage was utilised in soft-hard decoding method. Results are demonstrated in the fourth chapter. Soft-hard decoder is more efficient than existing methods. I also generated dynamic simulation for the outcomes alongside proposed algorithm and determined results.
1.8 SUMMARY
This chapter given an opening introduction to cloud and its core. It gives the outline of cloud computing, it’s origin and evolution over the years and the deployment and service model furnished along with essential Properties of Cloud Research gap, Research Methodology, Research objective and Scope of research have been highlighted and explained in this chapter.
CHAPTER 2: LITERATURE SURVEY AND REVIEW
2.1 INTRODUCTION
Cloud storage is a model of data storage in which the digital data is stored in logical pools, the physical storage durations multiple servers (and often locations), and the physical environment is typically owned and managed by a hosting company. These cloud storage providers are accountable for keeping the data available and accessible, and the physical environment secure and running. Individuals and organizations buy or lease storage capacity from the providers to store user, organization, or application data. Companies need to pay for the storage they actually use, typically an average of consumption during a month. This does not mean that cloud storage is less costly, only that it incurs operating expenses rather than capital expenses. Companies using cloud storage can cut their energy consumption by up to 70% creating them a more green and eco-friendly business.
2.2 REVIEW OF RELATED LITERATURE
2.2.1 Toward Secure and Dependable Storage Services in Cloud Computing by Cong Wang, Qian Wang, Kui Ren, Ning Cao and Wenjing Lou.
The objective is to address the problem of reliable and flexible storage services in cloud environment utilizing Homomorphic distributed token and erasure coded data. The work proposed is designing of efficient mechanisms for dynamic data verification and operation and achieve the multifarious goals such as quick localization of data error, dynamic data storage facility, Dependability to enhance data availability against Byzantine failures, malicious data modification and server colluding attacks, i.e., minimizing the effect brought by data errors or server failures and lastly enable storage correctness with minimal overhead.
2.2.2 The paper Ensuring Data Storage Security in Cloud Computing by authors Rampal Singh, Sawan Kumar and Shani Kumar Agrahari.
The authors cited their objective is to deploy the protection of sensitive information by enabling computations with encrypted data, and also protect users from malicious behavior by enabling the validation of the computation result with a data scheme called layered interleaving. The main contributions of this paper are The challenge-response protocol further providing the localization of data error. An efficient method for encoding the data to be transferred and stored in the Cloud. Lastly, an efficient data recovery method and performance analysis for the retrieval of lost data in Cloud. In this paper, it is assumed that the scheme supports secure and efficient dynamic operations on data blocks, including: update, delete and append.
2.2.3 In Secure and Data Dynamics Storage Services on Cloud by authors Manasi Doshi, Swapnaja Hiray
The objective of the paper is to achieve highly scalable, on demand and only pay per use services to be easily consumed over the Internet with security from unauthorized use perform flexible distributed storage, utilizing the homomorphism token and distributed erasure-coded data.
2.2.4 Security of Data Dynamics in Cloud Computing by authors M.Yugandhar, D. Subhramanya Sharma
This paper proposes approach is to design an effective and flexible distributed scheme with explicit dynamic data support to ensure the correctness of users’ data in the cloud. Erasure correcting code is utilized in the file distribution preparation to provide redundancies and guarantee the data dependability reduceing the communication and storage overhead by a noteworthy margin. By making use of the homomorphic token with distributed verification of erasure-coded data, this ploy achieves the storage correctness insurance as well as data error localization adept in correcting corrupted data and in detecting data errors and identification and localisation.
2.2.5 In Outsourcing and Discovering Storage Inconsistencies in Cloud through TPA by the authors Sumathi Karanam , GL Varaprasad
The objective is to makes use of bilinear aggregate signature for simultaneous auditing and Merkle Hash Tree for authenticating the third party auditor and to verify the integrity of data on behalf of cloud data owners. The proposed work is that the setup phase is used to generate security keys like private key and public key which is accomplished by invoking KeyGen(), also making use of homomorphic authenticators and Meta data. This method inspects and scrutinize data generated for verification of integrity and uses two arguments file and key. The proposed system is an underpin pillar of data dynamics with the main ingredients Data modification and data insertion being a vital part of the system demanding the simultaneous operation of the auditing channel. For this reason the proposed scheme supports concurrently using a concept named Bilinear aggregate signature scheme.
2.2.6 In Enabling Public Verifiability and Data Dynamics for Storage Security in Cloud Computing by authors Qian Wang, Cong Wang, Jin Li, Kui Ren, and Wenjing Lou
A general formal PoR (Proof of Retrievability) model is proposed with public verifiability for cloud data storage, in which both blockless and stateless verification are achieved synchronously. The performance of this scheme is justified through concrete implementation and comparisons with the state-of-the-art technology and engineering. The proposed PoR infrastructure is equipped with the function of supporting for fully dynamic data operations such as delete, modify, update and append especially to support block insertion, which is non-existent in most of the models. The proposed scheme makes use of Bilinear Map and Merkel Hash Tree.
A bilinear map is a map e : G × G → GT , where G is a Gap Diffie-Hellman (GDH) group and GT is another multiplicative cyclic group of prime order p with the following properties (i) Computable: there exists an efficiently computable algorithm for computing e; (ii) Bilinear: for all h1, h2 ∈ G and a, b ∈ Zp, e(h a 1 , hb 2 ) = e(h1, h2) ab; (iii) Non-degenerate: e(g, g) 6= 1, where g is a generator of G.
A Merkle Hash Tree (MHT) is a well-studied authentication structure, which is intended to efficiently and securely prove that a set of elements are undamaged and unaltered. It is constructed as a binary tree where the leaves in the MHT are the hashes of authentic data values. While MHT is commonly used to authenticate the values of data blocks. Albeit in this paper Merkle Hash Tree is used specifically to authenticate the values and positions of data blocks
2.2.7 Data Storage in Cloud Server by Token Pre-Computation by authors Bhupesh Kumar Dewangan and Sanjay Kumar Baghel
This paper guarantees the security and fidelity for cloud data storage under the above-mentioned antagonist model. Their aim is to design efficient mechanisms for dynamic data verification and operation and accomplish the following goals: Storage correctness to ensure users that their data are indeed stored appropriately and kept unharmed all the time in the cloud. Fast localization of data error: to effectively trace the faulty server when data corruption has been erected. Dynamic data support: to sustain the same level of storage correctness guarantee even if users modify, delete or append their data files in the cloud. Dependability: to enhance data availability against Intricate failures, malevolent data adjustment and server colluding attacks, i.e. diminishing the effect brought by data errors or server failures. Lightweight: to enable users to perform storage correctness checks with least overhead.
2.2.8 Ensuring Availability and Integrity of Data Storage in Cloud Computing by authors K. Sunitha V. Tejaswini S.K. Prashanth
In this paper the authors advocate to propose an effective and efficient distributed storage verification scheme with explicit dynamic data support to ensure the integrity and availability of users outsourced data in the cloud server. We rely on Fermat Number Transform (FNT) based Reed-Solomon erasure code in the file distribution preparation instead of Vandermonde ReedSolomon code to provide redundancies and guarantee the data availability against Byzantine servers. This construction significantly reduces the computation time and storage over head as compared to the traditional distribution techniques. 2.2 Design Goals The main goals for integrity and of this paper are; 1. The challenge-response protocol will provide the localization of data error. 2. We propose an efficient method for encoding the data file to be transferred and stored in the Cloud. 3. Finally, we propose an efficient data recovery method in order to retrieval the of lost data in Cloud. 4. Dynamic data support which is to maintain the same level of storage correctness assurance even if users modify, insert, delete or append their data files in the cloud.
2.2.9 Data Storage Security in Cloud Computing by authors Manoj Kokane , Premkumar Jain , Poonam Sarangdhar
In this paper the concept of homomorphic functions and tokens using erasure code is exploited again. A lot of contribution has been conjured to reduce the data redundancies. Data dependability is guaranteed alongwith detection of error localization.
2.2.10 A Survey on Data Storage and Security in Cloud Computing by authors V. Spoorthy , M. Mamatha, B. Santhosh Kumar
It cites that so far Data storage in cloud is more lucrative and profitable than other standard storages. In the wake of data availability, scalability, performance, portability and its functional requirements the desirability of cloud storage has paved new methods. A special focus of this paper was cloud storage services and the facilities they provide over traditional storage services. A close look on Amazon s3 and third party auditing (TPA) mechanisms concludes that a lot has occured in terms of cloud storage that has revamped the entire idea od storage service and facility.
2.2.11 In the paper Cloud Computing: Security Issues and Research Challenges Rabi by authors Prasad Padhy Manas Ranjan Patra and Suresh Chandra Satapathy
This paper explains the challenges related to cloud computing have been identified and their consequences have been conveyed. The major segment of challenges in cloud computing comes from Data Transmission, Virtual Machine Security, Network Security, Data Security, Data Privacy, Data Integrity, Data Location, Data Availability, Data Segregation, Security Policy and Patch management.
2.3 PROBLEM IDENTIFICATION
The problem in the domain of cloud storage services have been multi-fold declaring a real time challenge to tackle such complications. To resolve such archetypes of Gordian knot a problem must be understood and addressed foremost and a solution should be proposed thereafter. This thesis attempts to sum up the problems identified in the points given below:
1. Sharing storage hardware and placing data in the hands of a vendor or third part auditor is high risk. The industry is somewhat lacking in the potency and leverage of privacy laws. Data leakages are unavoidable in some situations either wherein a government agency or a private body attempts to access the data making it prone to a malicious hacker attack or an accident such as data spill up.
2. Credentials are an important aspect of profession and business. Access to a given pool of
data warehouse is based on credentials, and users are lumped together backed by common credentials, highlighting the danger that obtaining those credentials makes way for easy illegitimate access of data. Detection of the discrepancy becomes dicey in such a case since the credential is mutual, it is assumed to be encrypted.
3. Service quality is often one of the most under-rated factor in Cloud Storage. Businesses often cite the reason poor ‘Service Quality’ for not migrating their business portals to the cloud. It’s proven that Service Quality provided by the cloud providers today are not adequate to assure the requirements for running a production application on the cloud, especially those related to availability, performance and scalability.
4. Security is a great concern when moving their data to the cloud. Although security in the cloud is generally reliable and proficient, consumers need to know that the cloud provider they chose to work with has a fully secure cloud environment.
5. The migration of data from static and archived form to dynamic mechanism also poses a huge challenge for Cloud Service Providers (CSPs).
6. There are lesser options to encrypt data files prior storage. The encryption techniques used are of two kinds – Data at rest and Data in motion. We use encryption techniques to make our data more secure and elusive. Employing higher levels of security and encryption in data still poses a major challenge for researchers and Cloud Service Providers.
7. The term Interoperability is defined as the ability of two or more systems to function together in order to mutually access and share information and utilize that information for productivity and exponential growth. The current cloud system scenario is designed and functions as a closed system and does not facilitate scope for Interoperability. Due to this reasons many researchers have cited the lack of inter-communication as a challenge for Cloud Computing. The research work on interoperable Virtual Machines (VMs) is ongoing.
10. Energy Resource Management: Energy efficient data warehouses are the need of hour. Estimates say that the cost incurred in terms of power consumption make up for more than half of the entire operational expenditure of data warehouses in organizations. Notwithstanding, many argue that curtails in energy consumption will affect performance of cloud services in it’s wake. The high end application performance can go downhill with the introduction of energy-efficient programmes as it can slow down the machinery embedded in the infrastructure of cloud. It’s again a major problem to be addressed.
11. Multi-tenancy: Multiple users share the common pool of data resources that is available to the users on the grounds of sharing the same organization or same credential. These often leads to slow and down servers, denial of service (DoS) and delayed response timings overall affecting the execution performance of cloud architecture and design.
12. Platform Management: This is one of the most cumbersome and dicey challenge encountered by people dealing in cloud services. The main agenda of cloud computing is to provide existing and upcoming users alike the feasibility to utilise services, access services, write program applications on cloud for implementation. This area is being worked upon and innovators are trying to introduce more to cloud architecture than just system hardware and operating system for the organization.
2.4 SUMMARY
After surveying and reviewing eleven different Research Papers on Cloud Storage Security I sum up that most of the researchers have encountered similar problems and challenges in Cloud storage security. For Example Byzantine Failure a kind of system failure that occurs because of a bug, hardware malfunction or attacks by external agents. The techniques used to solve the problem of Cloud Storage Security have been multitude in number and the approaches have been improvised to add up to the efficiency and optimization of algorithm.
CHAPTER 3: RESEARCH METHODOLOGY
3.1 INTRODUCTION
In my works I dare to propose a new approach named as “Minimization of computational cost for Secure Cloud Storage Services using Soft Hard Genetic Algorithm(SHGA).” This new decoder can be applied to any binary linear block code, particularly for codes without algebraic decoder, unlike Chase algorithm which needs an algebraic hard-decision decoder and uses the dual code and work with the parity-check matrix. The latter makes them less complicated for codes of high rates. The encoded data are modulated and written to the storage media devices. In the storage media, it is where data can be distorted or corrupted thus making us fail to retrieve the stored data. To be able to retrieve the corrupted data you have to use powerful algorithm which will be able to recover the corrupted data. And The values of these signatures should match the corresponding tokens precomputed by the user. Meanwhile, as all servers operate over the same subset of the indices, the requested response values for integrity check must also be a valid codeword determined by the secret matrix P. finally we enhance a soft hard based genetic algorithms- (GAs-) based approach which is effective in addressing genetic optimization problems. We have performed some preliminary evaluations of the proposed approach which shows quite promising results, using one of the classical genetic algorithms. The conclusion is that GAs can be used for decision making in task migrations in pervasive clouds.
3.2 TRADITIONAL METHOD
Genetic Algorithm: To understand Genetic Algorithm we must first be familiar with the process of natural selection and genetics. What comes to your mind after hearing the word natural selection? As cited famously be Darwin in Theory of Evolution, natural selection can be loosely traced to the concept “survival of the fittest”, or only the fittest shall survive. This is a broad definition but can be metamorphosed into Computer Sciences.
Genetic algorithm is a derivative of Evolutionary Computation and was first introduced by John Holland. It.s an optimization technique applied to determine near-optimal solutions for complicated and tricky problems. GA gives the best possible solution to any problem in line with eperimentation with different combination of inputs and processing them to determine the output that is most optimal in nature or close enough.
8. Optimization using GA
Basic Terminology associated with Genetic Algorithm
- Population − It is a subset of all the possible (encoded) solutions to the given problem.
- Chromosomes − A chromosome is one such solution to the given problem.
- Gene − A gene is one element position of a chromosome.
- Genotype − Genotype is the population in the computation space.
- Phenotype − Phenotype is the population in the actual real world. solution space in which solutions are represented in a way they are represented in real world situations.
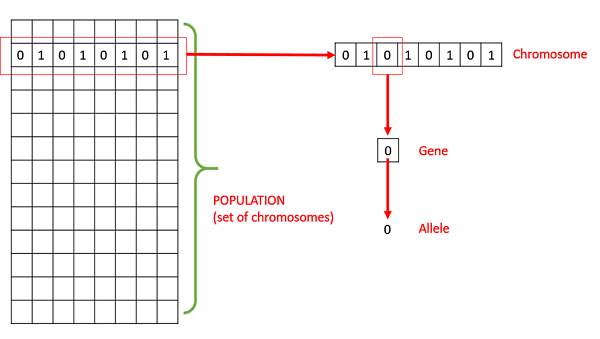
9. GA and it’s composition
- Genetic Operators − These alter the genetic composition of the offspring. These include crossover, mutation, selection, etc.
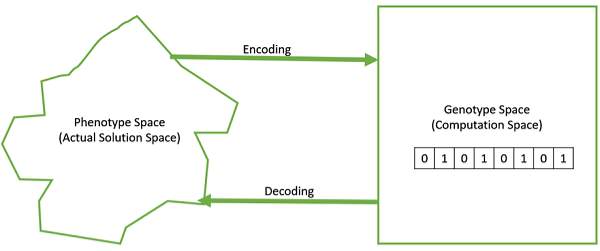
10. Encoding and Decoding in GA
3.2.2 ALGORITHM USED
The steps to compute and determine Genetic Algorithm are given below.
Step 1: Select input parameters l, n, pop, gen, nitea, where pop is population, gen is generation, and nitea is number of iteration.
Step 2: Select the number of tokens ‘t’ from total population.
Step 3: Select the number of rows r from total number of soft parity checks.
Step 4: Generate master key and challenge key from lower and upper bound.
Step 5: for vector G for vector G(j) , j ← 1, n do
Step 6: for round i← 1, t do
Step 7: Derive αi = fkchal (i) and k (i) prp from KPRP.
Step 8: Compute v (j) i = Pr q=1 α q i ∗ G(j) [φk (i) prp (q)]
Step 9: end for
Step 10: end for
Step 11: Find mutated data after storing selective chromosomes.
These steps are performed for computing tricky or difficult operations. GA helps in checking the fitness of bits and values. The methodology involves various representations like Binary representation and real-valued representation of any data. Binary Representation contains data in binary integer bits like 0 and 1. Real Valued representation makes use of other numbers as well as the decimals to depict the realness of function and data operations. Real valued can be further classified
- Integer Representation – for broader range of encoding apart from plain binary ‘0’ and ‘1’.
- Permutation Representation – for encoding in problems where many scenarios can be generated for 1 solution and many permutations can be formed out of the problem statement.
This data is further used for computation using different types of Population Initialization. Initialization is followed by checking the fitness and mutation of data. Travelling Salesman Problem, Knapsack Problem, Roulette Wheel Selection, Tournament Selection all have derived from Genetic Algorithm
3.2.3 FLOWCHART FOR ALGORITHM:
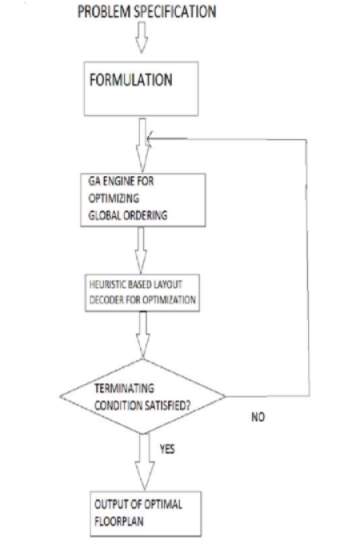
11. Flowchart for algorithm
The algorithm given above demonstrates the steps involved in the working of Genetic Algorithm to achieve near-optimal solutions.
Firstly the problem identification takes place on the part of algorithm designed. the problem at hand and it’s severity is examined. After the initial stage is sorted then formulation of the proposed solution occurs. Formulation is the stage where solution for the given problem is prepared. When the solution is determined at this stage then GA comes to play for advocating optimal or near-optimal solutions. A heuristic based layout is made use of to order optimal solution. If at this stage the problem condition is fulfilled and is about to conclude then an optimal output is generated in return. If on the other hand the termination condition is rendered unsatisfied then the re-formulation of the problem statement takes place and problem is formulated all over with a different stance.
3.3 PROPOSED METHOD
The Compact Genetic Algorithm Decoder (CGAD) is a significant contribution to soft-decision decoding. In effect a comparison with other decoders, that are currently the most successful algorithms for soft decision decoding, shows its efficiency. This new decoder can be applied to any binary linear block code, particularly for codes without algebraic decoder. Unlike Chase algorithm which needs an algebraic hard-decision decoder.
The Compact Genetic Algorithm (cGA), proposed by Harik and al., is a special class of genetic algorithms. It represents the population as a probability distribution over the set of solutions; thus, the whole population do not need to be stored. At each generation, cGA samples individuals according to the probabilities specified in the probability vector. The individuals are evaluated and the probability vector is updated towards the better individual. Hence, its limitation hinges on the assumption of the independency between each individual bit. The cGA has an advantage of using a small amount of memory. The parameters are the step size (1/ λ ) and the chromosome length (l).
First, the probability vector p is initialized to 0.5. Next, the individuals a and b are generated from p . The fitness values are then assigned to a and b . The probability vector is updated towards the better individual. In the population of size λ , the updating step size is 1/ λ ; The probability vector is increased or decreased by this size. The loop is repeated until the vector convergence.
3.3.1 ALGORITHM PROPOSED
Step 1: Initialize the parity, take p1 and p2 as parity and pop as population;
for i = 1 to pop do p[i] = 0.5;
Step 2: Generate two cases from probability parity
p1 = generate(p);
p2 = generate(p);
Step 3: Compete p1 and p2 from the total population
winner, loser = compete(p1, p2);
Step 4: Update the probability vector which is considered in same chromosome
for i=1 to pop do
if winner[i] ≠ loser[i] then
execute pop ++;
if winner[i] = 1 then p[i] = p[i] + 1/ λ
else p[i] = p[i] –1/ λ
Step 5: Check all parity as considered in total number of Generation
Step 6: for i = 1 to pop
if p[i] fit > avg pop
return “decoded data”;
repeat step 2 until all parity is checked;
3.3.2 PROPOSED FLOWCHART
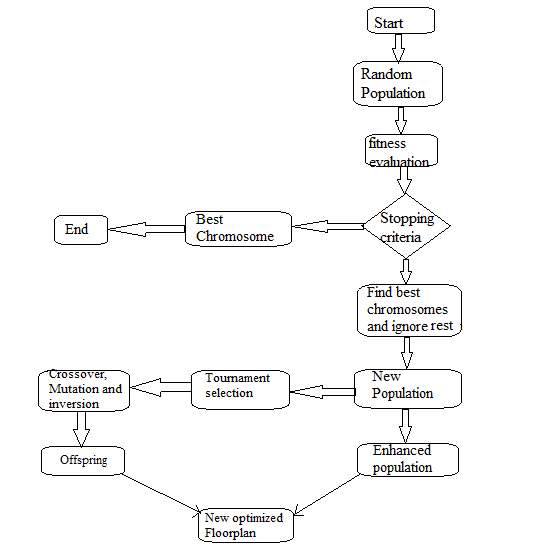
12. Proposed Flowchart
When we encounter any parity or any vector to be examined we make use of this algorithm to check for fitness and evaluate the fittest chromosomes.
At the advent of the algorithm, given population’s fitness level is evaluated and if the best chromosome is detected at this step then we stop the algorithm post obtaining our requirement. If the best chromosome isn’t revealed in this initial step then we select better chromosomes amongst the population discarding the rest of the chromosomes. The chosen better-performing chromosomes are rallied in tournament selection competition against each other. They compete with each other undergoing cross-over, Mutation and inversion and produce off-springs in the process. The off-spring are checked for fitness. Parent of the fittest off-spring is declared as the most optimized solution and becomes a part of all new refined population.
In this proposed flowchart we give an enhancement of Genetic Algorithm applying it with Soft Hard Decoder to check the fitness and parity of the bit or block of data that is to be stored in the cloud security warehouse. This hybridisation serves as an enhancement for the traditional cloud storage security model. It enhances the parity and fitness of the data bits, minimizes the overhead cost by reducing the garbage values that emerge in data pools because of fragmentation. It stores data dynamically without wasting space and memory and also facilitates append, modify, delete and insert operations on bits stored in data blocks.
3.4 PLATFORM USED
To design simulations and algorithms and to achieve end results, MATLAB R2014a simulator was utlized. The main motivation behind using MATLAB R2014a was to achieve a dynamic simulated graph and it is perfect for Numerical Analysis and Symbolic Computation. The end results associated with my research had to be empirically demonstrated in a dynamic simultion format and MATLAB easily made the first choice for my executions. Not only this tool facilitates the ease for graphical optimal output but also generates and Mathworks simply our problems providing better insights for solving and computation. The beauty of MATLAB lies within its powerful simplicity which provides advanced outcomes against simple parametrs. The only ordeal was that it occupied a lot of space but given the quality of graphs furnished the matter is entirely justified.
Dynamic graph generated by MATLAB R2014a
3.5 SUMMARY
In this chapter our research methods and methodology have been discussed. The study can be further extended by considering low and high machine heterogeneity and task heterogeneity. Also, applying the proposed algorithm for erasure code on actual grid environment and considering the cost factor for further soft computing technique can be other open problem in this area. Combination of Soft hard decoding and Genetic Algorithm has been our targetted approach to reduce Byzantine failures, minimize overhead cost and reduce wastage of memory and space. The mutual benefits from Genetic Algorithm and Compact Genetic Algorithm have been extracted to propose a better and novel method. Proposed Implementation has been performed on MATLAB to obtain the final results.
CHAPTER 4: RESULT AND ANALYSIS
4.1 INTRODUCTION
This chapter showcases the base paper implementation resuls and the proposed algorithm and code results and draws comparision between both in terms of finesse and fineness. The comparision is calculated to check which is more efficient, methodical, labour-saving and productive. The reults of the proposed methods are determined in graphs and screenshots of dynamic simulation are also attatched.
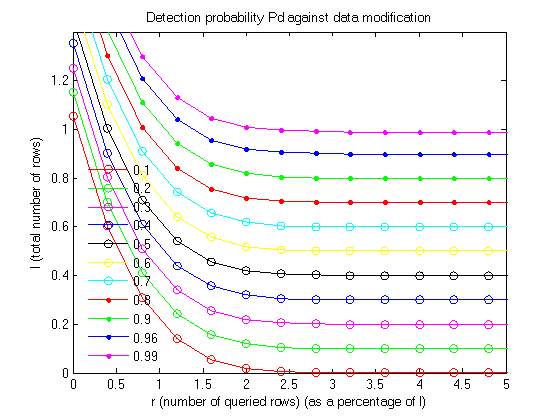
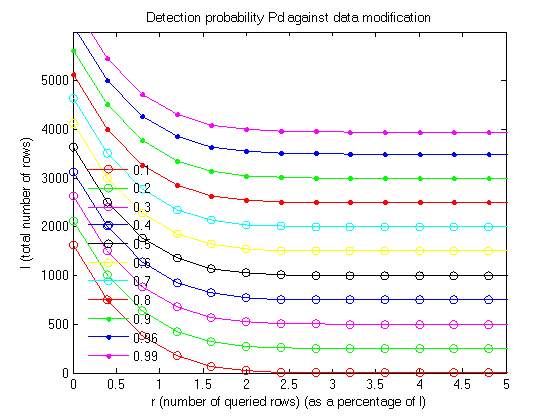
4.2 BASE PAPER END RESULTS
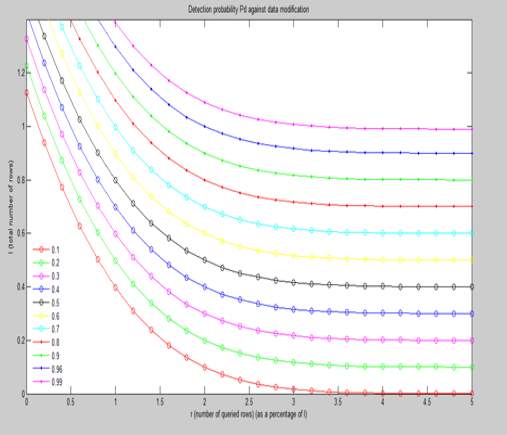
Graph 1
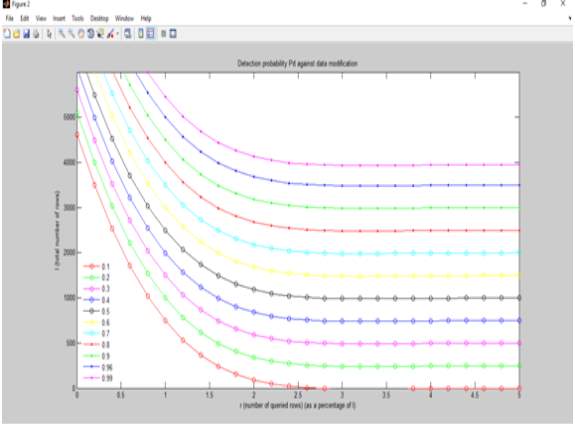
Graph 2
The above two graphs are plotted on the parameters of No. of queried rows vs total no. of rows pn different scales. The first graph uses a scale of 1% of the total no. of rows and the second graph uses a scale of 10% of the total no. of rows. In both the graphs a detection probability is determined from the given data.
4.3 PROPOSED APPROACH RESULTS
Results are categorised into two parts – Simulation results and end results.
4.3.1 SIMULATION GRAPH
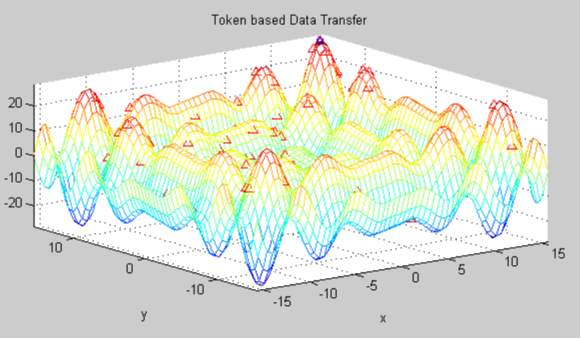
Graph 1
The above picturous illustration is the screenshot of dynamic simulated result using token based Data transfer methods. The Triangular peaks represented in crest of the waves are data bits that are left scattered and unable to achive required transmission or storgage as they transcend into garbage values or waste values even much before the process commences.
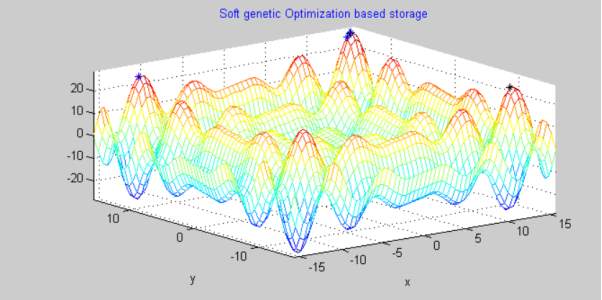
Graph 2
This result is generated by applying soft genetic optimization and code is genertaed using a hybrid of soft decoding and Genetic Algorithm. We can clearly see that the amount of data bits scattered and wasted have reduced considerably with only few bits lying on the peak pof waves. This method is more refined than token based computation and gives well-organised results minimizing redundancy wastage of parity and data bits.
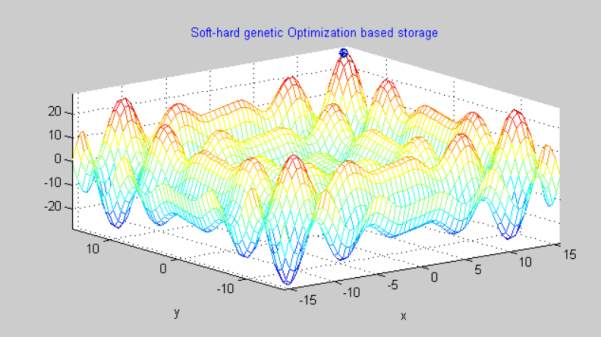
Graph 3
In the above given figure labelled as Graph 3, we have utilized Soft-Hard Genetic Optimization for Secure Data Cloud Storage. This network has so far generated the most productive result. As we can clearly see there are least triangular bits of scattered jittered data in this network in comparision with the networks discussed above. This method not only wastes lesser amount of data in jitters and garbage values but it also minmizes unnecessary overhead costs for data storage and maintenance. Out of all three networks the above network that uses soft-hard genetic optimization is the fittest of all.
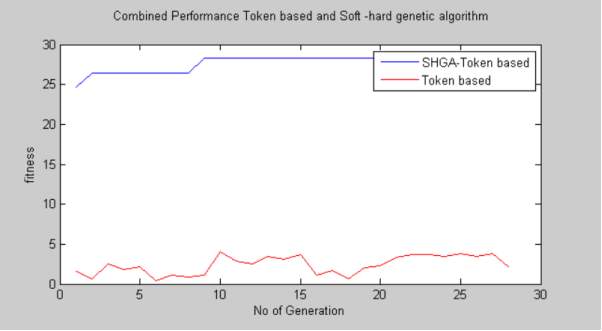
Graph 4
This graph compares the fitness of SHGA(soft-hard genetic algorithm) with the token based computation method used in existing and prior works of Cloud Storage. The blue line is used to depict SHGA and the red line is used for depicting Token Based. We have used No. of generation and fitness as parameters and we observe that for count of no. of generation vs fitness the fitness count of SHGA is higher against the count of token based technique. In first generation the token based method given a fitness of 2 and SHGA gives a fitness of 25.
4.3.2 Calculation table
| SHGA | Token Based | ||
| No. of Generation | Fitness | No. of Generation | Fitness |
| 1 | 25 | 1 | 2 |
| 5 | 27 | 5 | 2 |
| 10 | 29 | 10 | 4 |
| 15 | 29 | 15 | 4 |
| 20 | 29 | 20 | 3 |
| 25 | 29 | 25 | 4 |
4.3.3 END RESULT GRAPH

Graph 1
Graph 2
Graph 3
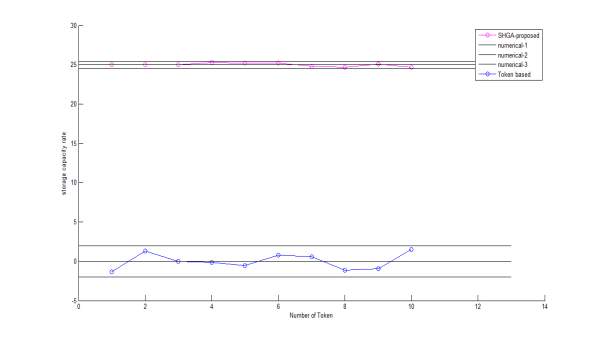
Graph 4
4.4 Calculation Table
| Base Paper Results | Proposed Method Results | ||
| No. of queried rows | Total no. of rows(1% of total rows) | No. of queried rows | Total no. of rows |
| 0.5
1 1.5
|
0.1
0.2 0.3
|
700
750 1100
|
500
1000 1500 |
Above table is the computation of Graph 3, with respect to base graph result 1. In base paper results only 1% of total no. of rows. Disparity in both results are observed in terms of queried rows, with proposed method giving better count of queried rows and performance.
4.5 SUMMARY
Results given above are the handiwork of proposed algorithm and demonstrate the effectiveness of proposed results. Tables have been formulated to showcase a statistical display of data to give a better understanding and clarity of the refined proposed mechanism. Careful analysis of the result is also carried out for the same.
CHAPTER 5: FUTURE SCOPE AND CONCLUSION
5.1 INTRODUCTION
This chapter discusses the future work and scope of research of secure cloud storage summarizing entire thesis with a brief conclusion.
5.2 FUTURE WORK AND SCOPE OF RESEARCH
1. With nearly half the world already online and more users being added every day as communication networks improve, it stands to reason that the demand for cloud storage is going to keep rising. There will be more companies offering on-demand cloud storage services to its patrons.
2. With more demand and more cloud storage servers the competition for business is going to be booming and will escalate and expand rapidly. With more competition there will be a drop in prices and arrival of competitive services. An increasing number of vendors are moving towards cloud computing. From the existing amazon services, google there would be increase in number of stakeholders in cloud in future henceforth broadening the domain of research.
3. Cloud storage will help businesses achieve more. In the modern business age, there is a demand to increase productivity while reducing personnel costs. Cloud storage is a . critical part of the virtual office system. With the cloud employees and clients can access information no matter where they are at.
6. The news of arrival of upcoming 5G technology is doing the rounds in marketplace. 5G boasts of a technology, speed, clarity, coverage far beyond the existing standards of 4G. More enhancement in data mobility technology means more generated data and more generated data implies increased amount of traffic and increased storage. With the launch of 5G the demand for cloud storage will multiply and it will impact the manner of storage security is cloud computing. It will give rise to more scholarly research and innovative ideas.
5.3 CONCLUSION
The problem we are facing at hand is that of data security in cloud data storage, which is essentially a distributed storage system. To achieve the guarantees of cloud data integrity and accessibility and enforce the quality of responsible cloud storage service for users, an effective and flexible distributed scheme is explicit dynamic data support, including block update, delete, and append. By using the homomorphic token with distributed verification of erasure-coded data, this scheme accomplishes the integration of storage correctness insurance and data error localization, i.e., every time data corruption has been detected during the storage correctness verification across the distributed servers, we can almost guarantee the simultaneous identification of the misbehaving server(s).
Bearing in mind the time, computation resources, and even the related online burden of users, we also provide the extension of the suggested main scheme to support third party auditing (TPAs), where users can safely delegate the integrity examination tasks to third party auditors and rest easy to use the cloud storage services. Through detailed security and extensive experiment results, its shown that scheme is highly efficient and resilient to Byzantine failure, malicious data modification attack, and even server colluding attacks. It is essential to maintain parity in data storage security within the provided time-stamp. The sharper the tip of the peak in the graph, higher is the estimated parity.
To sum up, to achieve data storage and security we can attempt a hybridisation of different methods such as Genetic Algorithm, k-means clustering, Soft Hard decision decoding or we can also shape the refinement of existing products. Cloud computing will make history and bear legendary derivatives of its counterpart technology. It has already revamped the modern business conduction and will change the face of industry utilization in years to come opening new gateways and breaking new grounds to higher and evolved modes of technology.
5.4 SUMMARY
The final chapter in this thesis concludes our entire efforts for research and formulation of a better algorithm. Inception of 5G will bring upon Ground-breaking and trail-blazing adaptations and innovations in Cloud Computing, Secure Cloud storage, Traffic Management and other branches of Cloud.
REFERENCES
[1] G. C. Clarck, J.B. Cain, “Error-Correction Coding for Digital Communications”, New York Plenum, 1981.
[2] Y. S. Han, C. R. P. Hartmann, and C.-C. Chen, “Efficient maximum-likelihood soft-decision decoding of linear block codes using algorithm A*”, Technical Report SUCIS-91-42, Syracuse University, Syracuse, NY 13244, December 1991.
[3] A. C. M. Cardoso, D. S. Arantes, “Genetic Decoding of Linear Block Codes”, Congress on Evolutionary Computation, Washington, DC, USA,1999.
[4] I. Shakeel, “GA-based Soft-decision Decoding of Block Codes”, IEEE 17th International Conference on Telecommunications, pp.13-17, Doha, Qatar, 4-7 April 2010.
[5] H.S. Maini, K. G. Mehrotra,C. Mohan, S. Ranka, “Genetic Algorithms for Soft Decision Decoding of Linear Block Codes”, Journal of Evolutionary Computation,Vol.2, No.2, pp.145-164, Nov.1994.
[6] L. Hebbes, R. Malyan, A. Lenaghan, “Genetic Algorithms for Turbo Codes,” IEEE EUROCON 2005, November,Belgrade, 2005.
[7] N. Durand, J.-M Alliot, B. Bartolomé, ” Turbo Codes Optimization Using Genetic Algorithms”, Evolutionary Computation, 1999. CEC 99. in Proc, IEEE Congress on Evolutionary Computation, Vol. 2, pp. 119-125, 1999.
[8] Padmapriya Praveenkumar, Rengarajan Amirtharajan, K. Thenmozhi and John Bosco Balaguru Rayappan, 2012. “Regulated OFDM-Role of ECC and ANN: A Review”, Journal of Applied Sciences, 12: 301-314.
[9] Rajbhandari, Sujan, Ghassemlooy, Zabih and Angelova, “Adaptive ‘soft’ sliding block decoding of convolutional code using the artificial neural network”, Transactions on Emerging Telecommunications Technologies. ISSN 21613915, Maia, 2012.
[10] Johnny W. H. Kao, Stevan M. Berber, and Abbas Bigdeli, “A General Rate K/N Convolutional Decoder Based on Neural Networks with Stopping Criterion”, Advances in Artificial Intelligence, vol. 2009, Article ID 356120, 11 pages, 2009.
[11] J.Orth and S.Houghten, “Optimizing the Salmon Algorithm for the Construction of DNA Error-Correcting Codes”, 2011 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, April 2011.
[12] A. Azouaoui, M. askali, M. Belkasmi, “A genetic algorithm to search of good double-circulant codes”, IEEE Multimedia Computing and Systems (ICMCS), 2011 International Conference, Ouarzazate, Morocco, April 2011.
[13] A. Azouaoui, M. Belkasmi and A. Farchane, “Efficient Dual Domain Decoding of Linear Block Codes Using Genetic Algorithms”,Journal of Electrical and Computer Engineering, vol. 2012, Article ID 503834, 12 pages.
[14] A. Azouaoui and Dr. M. Belkasmi, “A Soft Decoding of Linear Block Codes by Genetic Algorithms”, International Conference on Intelligent Computational Systems (ICICS’2012) Jan. 7-8, 2012, Dubai, UAE.
[15] M. Belkasmi, H. Berbia, F. Elbouanani, “Iterative decoding of product block codes based on the genetic algorithms”, proceedings of 7th International ITG Conference on Source and Channel Coding, 14-16 Janvier,2008.
[16] D. E. Goldberg,”Genetic Algorithms in Search, Optimization, and machine Learning”, New York: AddisonWiesle, London, 1989.
[17] D. Chase, “A Class of Algorithms for Decoding Block Codes with Channel Measurement”, 1972.Information, IEEE Trans. Inform. Theory, vol, 18, pp. 170–181, January.
[18] H. Morelos-Zaragoza, “The Art of Error Correcting Coding”, Second Edition Robert, John Wiley & Sons, Ltd. ISBN : 0470-01558-6, 2006. [19] G. R. Harik, F. G. Lobo and D. E. Goldberg, “The compact genetic algorithm”, in IEEE Transactions on Evolutionary Computation, 1999, Vol. 3, No. 4, 287-2
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: