Data Mining Techniques and Analysis for Privacy Awareness on Social Networks
Info: 10974 words (44 pages) Dissertation
Published: 25th Nov 2021
Tagged: Social Media
Abstract
Data mining techniques have been generally utilised as a part of many research disciplines, for example medicine, sports, social network to extract useful knowledge. Research data regularly should be distributed alongside the data mining model for check or re-analysis. In any case, the security of the distributed information should be ensured that it is protected because the distributed information is liable to abuse, for example, linking attacks.
This project presents a qualitative study to demonstrates data mining technique that will be applied and then present the findings and analysis to the users, a general questionnaire for the interviews are carried out and analysed, the purpose of the questionnaire is to gather a better understanding of social networks and what factors that might cause privacy issues in user’s point of view.
“Twitter” social network has been selected as the case study to reveal connection between social network, data mining and the issues related to privacy.
Furthermore, a review of Big Data and security issues on the social network was demonstrated as a background study. The “Communication privacy theory” will be modified to a framework for additional analysis how people deal with their protection on informal organizations. We concentrate informal communities as a sum in this project. Twitter was chosen as the case study to display the association between Big data, security issues and social network.
The values of privacy should be respected and protected so that the data being collected and mined doesn’t break the trust of users’ providing sensitive data to social platforms. Nevertheless, the issues related to privacy increased because users avoided to understand the data mining on social network. The analyses and evaluation carried out, will be based on the results of the data mining and the interviews. Discovering any issues would benefit users of social network by becoming more aware of the risks related to data mining.
Keywords: Big data Analysis, Data mining, Social network, Data visualisation, Privacy, Twitter
Contents
Click to expand Contents
1 - Introduction
1.1 - Background
1.1.1 - What is big data?
1.1.2 - What is data mining?
1.2 - Aims and Objectives
1.3 - Research Methodology
1.4 - Thesis Structure
2 - Literature review
2.1 - Big data privacy
2.2 - Data mining miss-interpretation and accuracy
2.3 - Big data anonymous information
2.4 - Big Data Legal consequences
2.5 - Summary
3 - Implementation
3.1 - Qualitative Study (Data visualisation)
3.1.1 - Data gathering
3.1.2 - Big data work
3.1.2 - Force atlas 2
3.1.3 - Fruchterman reingold
3.1.5 - Analysing the data with data visualisation
3.1.6 - Modularity visualisation analysis
3.1.7 - Average degree
3.1.8 - Most relationship
3.1.9 - Conclusion
3.2 - Qualitative Study (Interviews)
3.2.1 - Participants
3.2.2 - Data collection
3.3 - Weka model
3.3.1 - Attributes tested
3.3.2 - Confusion matrix
4 - Evaluation
4.1 - Identification of “Gephi”
4.1.2 - Advantages of applying “Gephi”
4.1.3 - Disadvantages of applying “Gephi”
4.1.4 - Implementation of “gephi’s” process
4.2 - Identification of the semi-structured interview
4.2.1 - Advantages of Semi-Structure Interviews
4.2.2 - Disadvantages of Semi-Structure Interviews
4.2.3 - Implementation of semi-structed interview process
4.4 - Conclusion
5 - Future Work
6 - Conclusion and Discussion
7 - Project Management
6.1 - Gantt chart
6.2 - Meeting logs
6.3 - Issues
6.4 - Reflection on the presentation feedback
7 - Appendices
7.1- Appendix A – Statement of Originality
7.2 - Appendix B – Certificate of Ethical Approval
7.3 - Appendix C – PowerPoint slides (Project presentation)
7.4 - Appendix D – Presentation Feedback
7.5 - Appendix E – Detailed project proposal
7.5 - Appendix F – Project Management (Gantt chart)
7.6 - Appendix G – Project Management (Meeting logs)
7.7 - Appendix H – Interview questions
Bibliography
1 - Introduction
This chapter will provide an overview of the project. The following sections will define the structure of the project, theories and common information as the background of the study for the project and describe the main research question.
The purpose to carry out this work was to deliver a different solution with which social network users become more aware of the dangers related to data mining. Data mining techniques to Big data can uncover hidden patterns, which lead to new understandings and findings. This data is regularly delicate, for example, profile data, live location status or even your gadget particular data. Personal information can also be used by associations or individuals. Data mining has turned out to be progressively risky including numerous ethical issues, for example, privacy, misinterpretation, the problem of accuracy, anonymous information, Stereotyping, and Legal consequences.
The inaccurate use of data mining, put individuals that make use of social network applications in questions of how secure their data stored online is.
The intention is to carry out a visual data mining and analyse the visualisation of data mined from twitter using “Gephi” (software tool for data mining visualisation) for a better understanding of the connections and information between users across the dataset, which lets me identify the amount of followers, to have an idea of how big the connection is between users and identify the sensitive data being mined for example user’s current location, this will allow future forecasting for example predicting how a social network can still grow in the coming years.
The interview exercise carried out in this project provided with a questionnaire will allow a better comprehension in relation to user’s experiences of social network, also the factors that may possibly contribute to the privacy issues or the users.
A predictive data model will be demonstrated and analysed using “Weka” (software tool for data mining and predictive model) applying sentiment analysis, which is the process of determining whether a piece of writing is positive, negative or neutral, to determine how users manage their privacy on social networks by defining what users share online, for example: status or opinions posted so if users share their location on social network or not, if users keep their profile private or public.
The outcomes of the project are related to trust between social networks and users. The group of people who would be interested in knowing these findings would be social network users and they would benefit by having a better understanding of the security risks involved in data mining of social network.
1.1 Background
1.1.1 What is big data?
There are different assumptions what Big data is. Big data is produced from an expanding majority of sources, including web clicks, portable exchanges, client created substance and web-based social networking and in addition deliberately created content through sensor systems or business exchanges, for example, deals inquiries and buy exchanges (George et al. 2014). Briefly Big data is a massive data set that is analysed by organisations to find out hidden patterns, trends and associations related to human behaviour and interactions for example.
In this model, volume of information is the most natural measurement. This measurement implies that Big Data acknowledged diverse types of information in the meantime. The quick development of information volume is reflected into two focuses. One is influenced by the effect of the prevalence of cell phones and interpersonal organisations. Another point is that there are various duplicates of similar information. Network Users are increasingly used to back-up their documentation, both on their mobile device and computers.
In the meantime, information is developing at a remarkable speed for era and scattering. This leads an inexorably requesting for handling, constant information. Both transmission and handling of information are confronted with the test of speed overhaul (information speed of the 4-v show).
This is especially obvious when it comes to social networks. Imagine that more than one million clients present another post on Twitter at the same time, if the constant information preparing is moderate and can’t deal with such a considerable measure information in a brief time-frame, and afterwards you are probably going to need to hold up quite a while to see other individuals’ post. Along these lines, in this measurement, the innovation improvement of gushing information examination turns into the key.
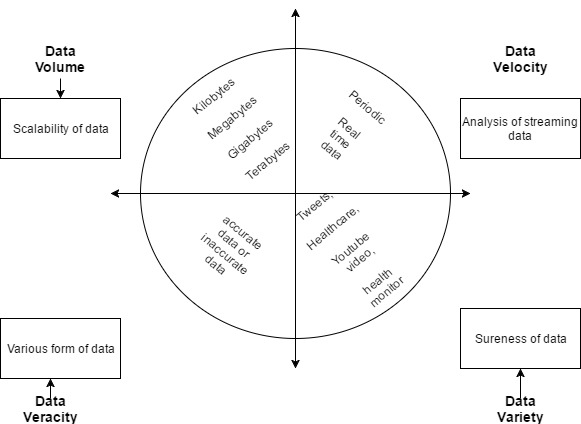
Figure 1.1 The 4-V (Volume, Velocity, Veracity, Variety) Model of Big data (IBM, n.d)
In any case, the most essential reason that makes information turn out to be “enormous” (Sagiroglu and Sinanc, 2013) is the assortment of information. Hypothetically, in a stockroom, organised data not just spares space saving, it also makes it easy to examine and preparing. Without a doubt, now an expansive number of data (specifically the data put away on the system) are such not structured. That leads information seem more unplanned. In this manner, the examination and handling of this sort of data incredibly increase the difficulty.
Semi-Structured information are an exceptional sort of organised data; it utilizes labels or markers to separate information as opposed to placing it into a table or a genuine database (Sagiroglu and Sinanc, 2013). Contrasted and putting individual information into a table, composition a short individual presentation sentence can be considered as semi-organised information. Data will be divided by processing.
1.1.2 What is data mining?
Beal Vangie (n.d) says that “Data mining requires a class of database applications that look for hidden patterns in a group of data that can be used to predict future behaviour. For example, data mining software can help retail companies find customers with common interests”.
“Data mining (sometimes called data or knowledge discovery) is the process of analysing data from different perspectives and summarizing it into useful information “(Anderon.ucla.edu, 2015).
Simplifying, data mining is the preparation of analysing a great number of previous databases to produce different information, which can be analysed again in the future.
1.2 Aims and Objectives
- Collect twitter dataset related to followers (EXCEL extension “NodeXL template”)
- Select a data visualisation tool (“Gephi v8.2”), to provide the users data visualisation, for a better understanding of the connections and information between users across the dataset
- Analyse the findings to identify the number of followers, to have an idea of how big the connection is between users
- Identify possible general questionnaire (20 questions), to gather opinions and analyse them,
- Select a group of people to interview (10 max), users of social network in Coventry University,
- Analyse the results found from the interview to answer my research question
- Covert the “twitter” dataset extracted from “NodeXL” to an “arff” file to use it in “WEKA”
- Build a predictive model based on the users’ tweets on twitter
- Carry out analyses.
1.3 Research Methodology
Planning a research methodology is attempting to change the exploration inquiries into an attainable review. The research in this dissertation is a social science study, given that the purpose of this research is going to study the ethical issues and users’ awareness related to data mining across social network nowadays. As per this, a qualitative methodology is implemented to carry out this research. Based on the research process of Oates (2006) it has for main phases; I have transformed a SLDC analogy (research process) of this research to a framework which is presented in figure 1.2.
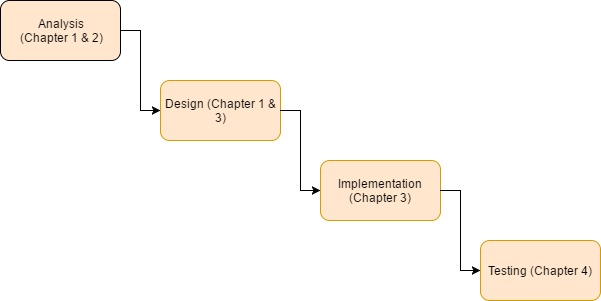
Figure 1.2: SLDC (system development life cycle) analogy research process (Oates, 2006)
Oates (2006) says that the analysis stage is to Break down the flow condition of information (literature review), choose what still should be done and build up an examination proposition, which may regularly incorporate at least one research question and destinations. So, my literature review has two points, to settle down an examination theme and mentions confirmation to reinforce the point of views of the author. As the research topic of this dissertation will have analyses based on diverse data, the problem statement will be covered through the chapter 2 (Literature review).
Design will be supported by chapter 1 and 3, which is based on the arguments and information present from the prior chapters, the prerequisite of the interview and the technique for the information gathering and investigation are arranged and discussed here.
Implementation is suggested by Oates (2006) that the design stage should be followed to carry out the research in the implementation stage. So, in this case, a visual data mining using will be provided and analysed, after that an interview is adopted and the responses are also analysed and finally a predictive data model will be built using “Weka”. Subsequently we can show signs of improvement comprehension about client’s encounters of social network and what factors that may bring about security issues for them and to test how accurate it will be to predict users’ sentiment based on tweets from the twitter dataset.
In this phase, the data collected for this interview research will be based in a semi-structed interview, some of the advantages of that is participants don’t need to follow the original order of the questionnaire. Questions can be adapted or changed for a significant issue during the interview. That supports stimulate the interviewee to demonstrate their sentiment under an appropriate discussion control by analyst. The downside is that the researcher needs to clarify their part of the meeting, and attempt to get a handle on the subject firm as opposed to drifting away, so being clear as possible on questions that the participants might not understand or might not be so clear. As the information being collected from the interview, being gathered by providing a questionnaire, the qualitative analysis is fit for this kind of information.
Testing stage will provide an evaluation of research process applied to see if it answers my original question.
1.4 Thesis Structure
Chapter 1. Introduction
This chapter is a summary of the entire project. This project focus on ethical issues of big data as the significant problem overview, who may benefit from this research and research question will be described in this section, theories and broad knowledge as the background research to support this project’s claim. The first section of this chapter is going to introduce the definition of Big Data and data mining
Chapter 2. Literature review
This chapter describes the history of big data and ethical issues. It contains 3 sections; data mining privacy, datamining miss-interpretation and accuracy and followed with a summary. After a brief history, I can easily understand the detailed ethical issues of privacy related to data mining. The following section will be describing the data mining privacy as an ethical issue. The thirst section will discuss the issues of how accurate data mining can be and the miss-interpretation of the results of data mining. The last section describe graph theoretic as one of the main methods for data mining on social network.
Chapter 3. Implementation
In this chapter I will practically implemented the visual data and analyse the output using “Gephi” as my data visualisation tool, followed with an interview which will describe the data analysis result from the interview, findings such as factor that might have an influence on privacy issues on social network, how participants manage their privacy on social network and general opinion on data mining and ethical privacy issues on social network. Finally, a predictive model will be built here and test using data from twitter based on tweets and will also be analysed to find out how accurate it is to apply data mining techniques.
Chapter 4. Evaluation (Testing)
In this chapter I will evaluate my achievements and reflect on the question that is to be answered.
Chapter 5. Future work
This chapter recommends a selection of the future work that can be done with this hypothesis which could be useful for further research in this field.
Chapter 6. Conclusion and Discussion
In this chapter I will give a brief statement highlighting how the method I used addresses the problem specified in chapter 1 (Introduction), also briefly discuss m results.
Chapter 7. Project Management
In this chapter I will describe the steps I took for the organisation of the project, problems encountered during the completion of the project, how I overcame these problems, how I searched for advice and response to the feedback from the meetings and presentation.
2 Literature review
The usage of big data is the way toward getting and examining information in alternate points of view to determine some new conclusions. People utilise big data of various associations to hunt down new examples to (or “proposing to”) finding new and effective results. The standard meaning of data mining is that it is, “the nontrivial extraction of understood, already obscure, and conceivably valuable data from information”. It is otherwise called, the exploration of separating helpful data from substantial databases. Independent of the way that data mining benefits people, association, and even states in certain ways, it additionally conveys some genuine ethical consequences (Moftakhari and Dogan, 2015).
The most widely recognised issues are the informed assent of those included in research through data mining is the security of individual information and replication of research information from the existing big data. The moral issues involved in the mining of big data can be countered through educated assent, which implies that those included in research tasks ought to be taught of the examination goals, potential unfriendly impacts, the capacity to deny support or withdrawal whenever, with no outcome, keep up their information after the end of the overview, and so on. It will give some accreditation to the first maker of the information.
Some of the ethical issues involved in the usage and exploitation of big data are privacy, Misinterpretation and the problem of accuracy, Anonymous information, and Legal consequences.
2.1 Big data privacy
The most vital and principal moral issue with data mining is the problem of security. Gavison (1984) contended that protection is not an acquired a portion of society because the general investment in the general public requires transactions and interchanges with each other. This implies nobody can live in supreme confinement, and thus total protection is unrealistic. In the circumstances, when there is no complete security, distinctive people and associations have created diverse measures and discernments for protection. People can point of confinement individuals’ entrance to their information by surrendering their availability. Also, they can settle some cost for those, who need to get to their data. Theft rights have a critical part in such manner. Throughout the world, it is broadly conceded that the loss of security is the fundamental underlying result of data mining. Security can be revealed either purposefully or accidentally. However, it can prompt one’s discouragement. So, to address this fundamental issue of data mining, it is required to characterise norms leads through which the assent of the first creator is taken before mining his/her data. The same is valid for associations.
2.2 Data mining miss-interpretation and accuracy
Another imperative moral issue with data mining is the confusion of the outcomes that are being gotten from the data mining. For instance, if the measurements demonstrate that the offer of cool beverages expands so do the frozen yogurts; nonetheless, it does not imply that there is any connection or causation with the dessert increment in the deal with that of cool beverages. So, the ineffectively mined information or unintelligent elucidation of the information can likely prompt the distortion of results (Van and Royakkers, 2004). The confusion of results will offer ascent to the misinterpretations, and henceforth the moral grounds of data mining lose its footings. Another issue with data mining is that information is taken from different sources without recognising the distinction between unique sources. The various outer wellsprings of proof raise issues of the exactness of the new conclusions. Now and then mining is done over terminated information that was exact at some specific time and space yet now, does not clarify the contemporary circumstances. At the point when results are drawn from such terminated information, the odds of incorrectness of those outcomes are regularly.
2.3 Big data anonymous information
In the year of 2006, a research group form Harvard began gathering the social network profiles of around 1,700 college based Facebook users to carry out a study on their interests and friendships changed after some time (Lewis et al. 2008). This evidently anonymous information was made public everywhere in the world, permitting different analysts to investigate and examine it. What different researchers immediately found was that it was achievable to return the process of anonymous parts of the dataset, so find out who the information belongs too: giving in the protection of many students, none of whom knew their information was being gathered (Zimmer, 2017). This is a massive issue because making data available does not mean it is ethical and by being able to make it not anonymous as well, individual’s data is exposed and at risk.
2.4 Big Data Legal consequences
Enterprises that incorporate any delicate information in Big Data operations must guarantee that the information itself is secure, and that similar information security strategies that apply to the information when it exists in databases or records are additionally authorised in the Big Data setting (Villars, Olofson, and Eastwood, 2011). By not ensuring the security can lead to security breach and can have severe harmful consequences to the customer, users and even the organisations employees. The enormous responsibility involved in handling employee’s personal data, business partners, clients and other common customers, is a matter which majority of the and governments as well as companies have taken very non-seriously for a longer period. However, when the risks of poor management proved as huge security threats, the attitudes changed towards it.
2.5 Summary
The data mining technique of Graph theoretic is one of the main methods in social network analysis over the other techniques. The graph theoretic methods are applied to determine important features of the network such as the nodes and links (example influencers and the followers). Despite all these benefits, all data mining techniques share serious ethical, social and privacy implications. It was mentioned by various researchers that there is concerns about data mining and privacy. Big data is an important and very complex topic, it is almost natural that immense security and privacy changes will arise (Michael & Miller, 2013; Tankard, 2012). These studies investigate data mining issues related to social network, highlighting significant points for users’ awareness.
3 Implementation
3.1 Qualitative Study (Data visualisation)
In this chapter I carry out a visual data mining using “gephi” based on twitter users’ account. The aim and goal to carry out the visual data mining is to better understanding the connections and information between users across the dataset friendship.
3.1.1 Data gathering
To gather the data from twitter NodeXL Excel template has been used, which is an add-on for “Microsoft Excel” with additional functions and columns. NodeXL comes with a built-in function that permits the extraction of data from various sources for example Facebook, Twitter and Flirck. I chose twitter as my main social network because it contains a huge amount of information about the connections of various users. I have collected more than 10 thousand of various users’ connections which provided more than 5 thousand of nodes and 7 thousand of edges when using Gephi for data visualisation.
The following screenshot, it’s a spreadsheet of the data gathered as mentioned above. There is a focus on the edges but it also comes with sets of data such as vertices groups, groups and vertices.
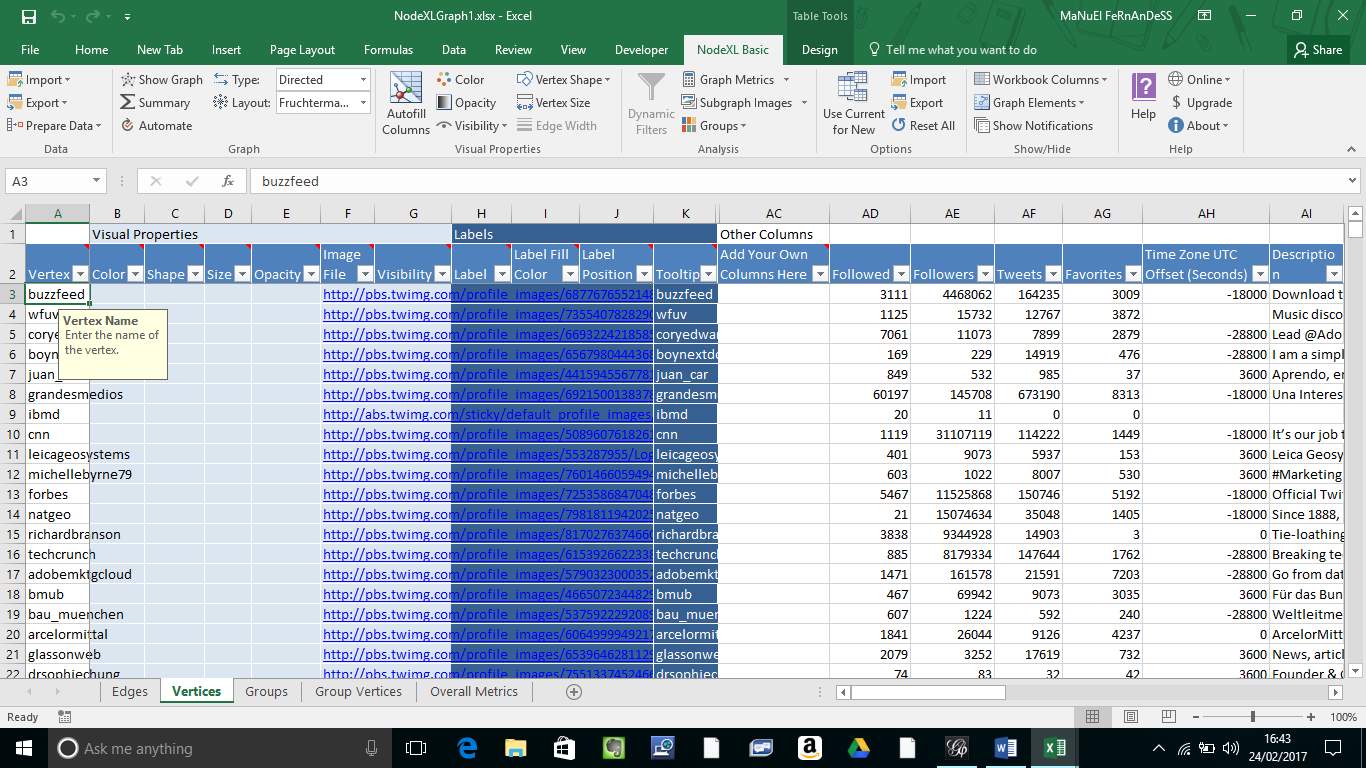
Figure 3.1.1 NodeXL template – Dataset
3.1.2 Big data work
To show how bid data works in various and efficient ways, the twitter dataset set of followers provided above.
The total of nodes shown in the screenshot bellow is of 5890, which are characterised by the dots, which they all contain some type of information that will be displayed in the following images. In these case the dots represent connections and relationships between various users on twitter.

Figure 3.1.2 Gephi – dataset displayed in nodes and edges
To have a clear view of the node and edges I used two different types of layout algorithms provided by “gephi” which are Force-Atlas 2 and Fruchterman Reingold. Those algorithms are very useful as they provided a clearly the connections between nodes and edges as show in the screen shots bellow, also the nodes and edges that are far apart are communities that have no relationships with the main community.
3.1.2 Force atlas 2
This is a layout algorithm provided by “gephi”. “Force Atlas 2” endeavours to determine the inadequacies of the Force Atlas calculation by making a harmony between the nature of the last design and the speed of the calculation. Its execution for huge systems is vastly improved when contrasted with the Force Atlas format algorithm (Packtpub, n.d)

Figure 3.1.3 Gephi – Force atlas 2 layout
3.1.3 Fruchterman reingold
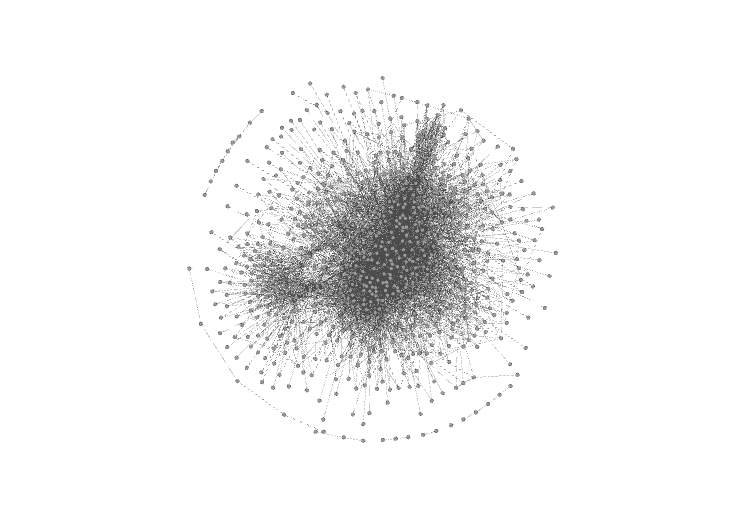
Figure 3.1.4 Gephi – Fruchterman reingold layout
The screenshot bellow is an additional step to clearly view the information contained in each node meantioned previously, in this case will be the users names.

Figure 3.1.5 Gephi – Node’s contained information
3.1.5 Analysing the data with data visualisation
The aim was to analyse connections and relationships between users on the social platform twitter, to focus on the popularity of users’ connections. The outcome from these analyses would be significant to predict how users choose to manage their privacy and group of people they prefer to relate to.
To get a better understand of what is going on in the dataset previously mentioned, an in-depth analysis was required to discover more. Which will help on the focus of important nodes for a better understanding of the most popular nodes and that will allow identify users with most followers.
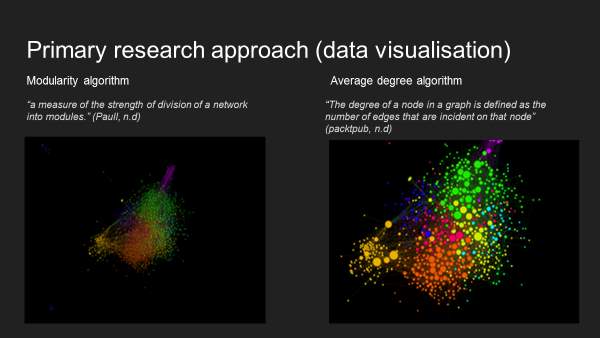
3.1.6 Modularity visualisation analysis
According to Brainasoft (2012) modularity refers to “the degree to which a system’s components are made up of relatively independent components or parts which can be combined”.
Running “modularity” analyses, gave me a better understanding about which data are connected, so the communities that exist in the dataset and how they interact in terms of various communities. Therefore, this brings me to the idea to determine which areas are the most common and the real meaning of the edges and links.
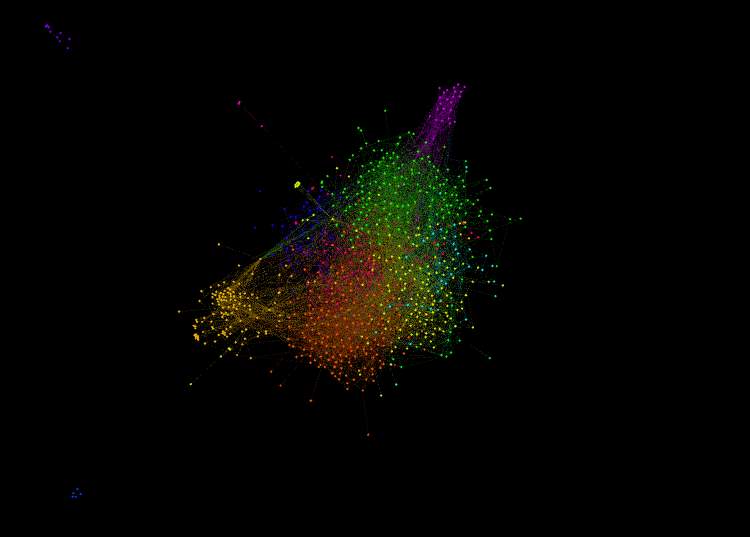
Figure 3.1.6 Gephi – Modularity layout algorithm
3.1.7 Average degree
Hoppe (n.d) says that average degree “is a measure of how many edges compared to a number of vertices”.
Running the “average degree” analyses along with the “modularity degree”, provided a clear view of the relations (edges). So, the dots (nodes) represent each user in the dataset where the lines (edges) represent the relations between different users. The bigger and the brighter dot (nodes), in this case means that a specific user has a lot of followers.

Figure 3.1.7 Gephi – Average degree layout algorithm
3.1.8 Most relationship
As displayed bellow, you can see the user’s information and the most connections/relations compared to other users.
Gephi software doesn’t just let individuals visualise the dataset in dots(nodes) and lines(edges), it also provides great information based on the modification made.
So here different colours are shown which represent different communities in the social network “Twitter”, different node sizes are also displayed they represent the most and least connection/relations between nodes, in different words who is followed the most.
The most followed user is highlighted in pink as shown below.
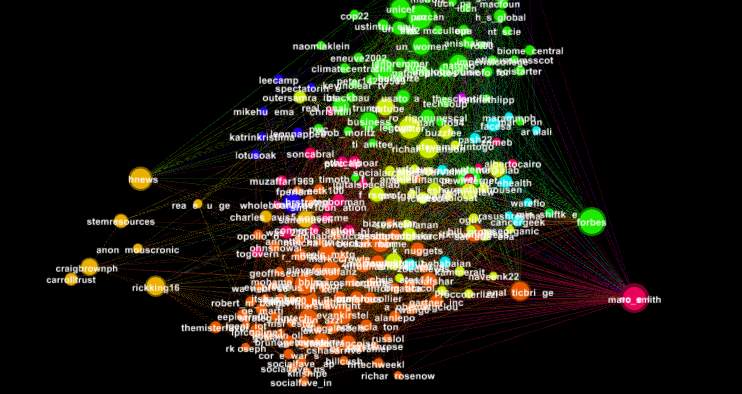
Figure 3.1.8 Gephi – Nodes with most followers

3.1.9 Conclusion
Alterman (2003) suggests that there are three kinds of concern associated with the storage of data. First is that someone “will legitimately gain access to information about you and utilize it to locate and harass or harm you in some manner” (Alterman, 2003, p. 140). The second kind of privacy concern is that information you gave up for one reason or purpose will be accessed or used for purposes that you could not have thought about or did not approve, by mining and analysing the results of the dataset, the initial two security concerns, which Alterman proposes emerge from the big data, are very related to Twitter, in that followers on Twitter could believably utilise tweets to hurt or disturb individuals. Given that many Tweets are public, also in some cases you don’t need to be follower to view or have access to an individual’s tweets. So being so popular or having a lot of followers on twitter may cause a threat to your privacy.
3.2 Qualitative Study (Interviews)
In this chapter I will introduce the interview strategy, which was done face-to-face. According to the research question of this project, the aim and goal to carry out the interview is hoping gather a probable answer from the view of the interviewees. Please see appendix H for interview questions.
3.2.1 Participants
I managed to gather 1 participants in total to take part in the interview, all the participants were a Coventry University student and are users group of social networks. The participants’ age is between 18 to 25 years old, their experience on social network is above 4 year. Participants have more than two social network accounts.
As the aim of this project is to find out the issues of data mining related to social network, within this interview, it also expected that most the participants are studying or working in Computing or IT area and the other participants are specialised in a different filed. Participants’ background might have an impact on their views related to privacy on social networks.
3.2.2 Data collection
10 of 15 aimed interviewees took part in the one to one interview, unfortunately 5 of the agreed participants couldn’t take part due to absents. All the interviews were provided with a questionnaire and kept as evidence for the interview transcription. Participants details such as age, gender education were provided. This one-to-one interview questions concentrated on the interviewees’ point of view and how well they comprehend the privacy issues on social networks nowadays. Questions related to how participants manage their privacy in various social networks were also asked and because most all the participants use more than a single account a brief description of how they are managed individually was necessary through a discussion.
3.3 Weka model
This is twitter sentiment analysis, I am testing for users’ sentiments based on their tweets on twitter, this dataset created for testing only includes 100 positives tweets and 100 negative tweets. There are two different attributes, one of the attributes being the class, so as show below “sentiment”, which is nominal and is either positive or negative and the other attribute named as “tweet_body” serve as “string” which will hold all the tweets as text.
3.3.1 Attributes tested
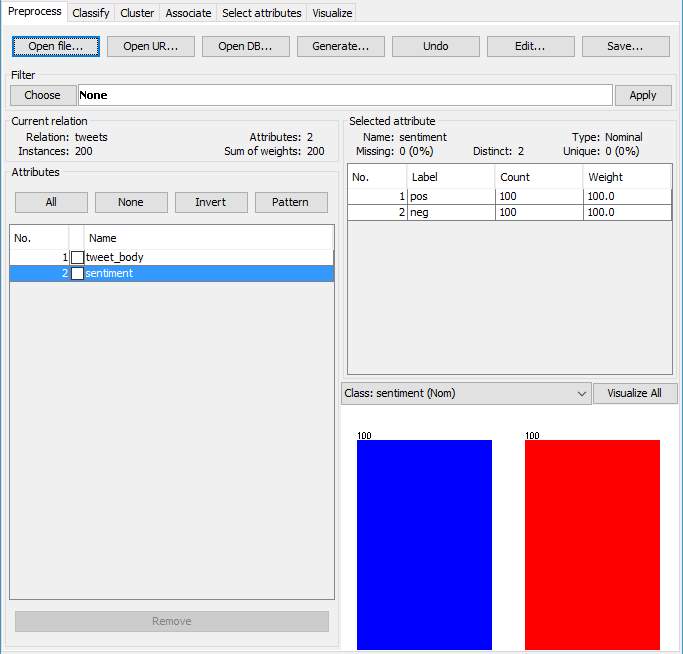
Figure 3.3.1 Weka – Pre-process (Attributes tested)
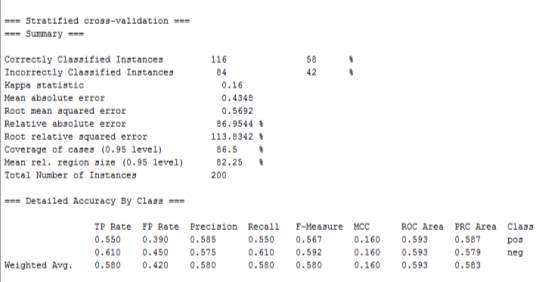
Figure 3.3.2 Weka – Classifier
The image above uses the classifier->filteredclassifier, this is a text classification, I will run on 10 folds split because it splits the data into 10 pieces and uses 9 pieces to train the network and the 10th piece to test against it, this process will repeat 10 times with an altered piece for testing.
The results appear in the table and shows that it gets 58% of the data right and 42% is incorrect from the attributes tested which is a bad accuracy rate, but because the dataset used here is small the I would say that the percentage achieved is just right.
3.3.2 Confusion matrix

Figure 3.3.3 Weka – Confusion Matrix
Matrix confusion is utilised to show the measure of right and off base forecasts.
The way it works and would be interpreted is ; we have two classes “positive” and “negative” (tweets with positive text and negative text) represented by “a = positive” and “b = negative”, “55” now is the number of instances, which were actually “positive” and they were predicted to be “positive”, so “55” were predicted as “good”, “45” is the value of instances which were “negative” but they were predicted to be “positive” by the classifier, “39” is the number of instances, which were actually “positive” classes and they were predicted to be negative classes and finally “61 ” is the number of “negative” classes which were predicted to be “negative” by the model.
Unfortunately, I could not get the clustering layout working in “WEKA” but the aim was to display the accuracy by having a clear view of how the process is done.
4 Evaluation
In this section a comparison of the techniques used in this project will be carried out with 4 criteria. The identification of the technique used, the advantages each technique provides, the disadvantages and the implementation of the techniques’ process.
4.1 Identification of “Gephi”
Gephi “is an open source software for graph and network analysis” (Bastian, Heymann, Jacomy, 2009)
4.1.1 Advantages of applying “Gephi”
Using “gephi” as a network analysts is just part of its job in fact this open source software can do more than just giving you the answer to a specific question related to the data such as:
- Summarises the dataset
- Provides a built-in statistical analysis
- Real-time layout algorithms such as average degree and modularity.
- Set of nodes and edges for clear understanding of the connection and information
- Creates high quality data visualisations
- Doesn’t require programming knowledge to use it as a software
The advantage of applying this data mining techniques is that it gives some helpful data without requiring each record to be comprehended in detail. So “gephi” does the employment and can be depicted as an adaptable and multi-errand design that conveys new conceivable outcomes to work with complex informational collections and deliver significant visual outcomes.
4.1.2 Disadvantages of applying “Gephi”
Some of the advantage I encountered using this network analysis tool are:
- Can get slow and crash at times when it comes to a very large network
- Various algorithms and concepts of analysis are still required for maximum analysis experience
- Related to software if demands high laptop/PC quality at times to run
4.2 Implementation of “gephi’s” process
Network analysis can be implemented in two ways: to detect the behaviour of the network communities and to understand them.
4.2.1 Identification of the semi-structured interview
The technique “semi-structured interview” used in the project “is a qualitative method of inquiry that combines a pre-determined set of open questions (questions that prompt discussion) with the opportunity for the interviewer to explore particular themes or responses further” (Pritchard, n.d)
4.2.2 Advantages of Semi-Structure Interviews
Applying this technique was not easy but did help me find out factor that contributed to the issues of related to social network some benefits are:
- Answers collected could be answered in as much detail as possible
- More substantial data about participants’ attitudes and point of views can be gathered, especially how individuals clarify these issues
- Participants can have an open minded and be honest
- Question can always be adjusted while the interview is going.
This technique also helps collected valuable information from participants in a more realistic way as you will have a face-to-face talk with users’.
4.2.3 Disadvantages of Semi-Structure Interviews
The advantages I encountered applying this technique are:
- Very time consuming – collecting data and analysing
- Not many people agree n taking part
- Challenge to compare the results because they are all unique
4.2.4 Implementation of semi-structed interview process
This technique is implemented by finding suitable questions, selecting a group of audience, carry out the interview, collect the result and then analyse them.
4.3 Conclusion
In this chapter, I portrayed the procedures of chosen strategies from the data mining perspective. It has been understood that all data mining strategies fulfil their objectives splendidly the same applies for the interview technique, however, every method has its own particular qualities and determinations that exhibit their exactness, capability, and inclination.
Data mining has demonstrated itself as an important instrument in numerous ranges, nonetheless, current data mining strategies are frequently far superior suited to some issue regions than to others, thusly it is prescribed to utilise data mining in many organisations for at any rate to help supervisors to settle on right choices as indicated by the data gave by information mining. There is not one method that can be totally successful related to data mining in thought to prediction, forecast, accuracy, limitations and location. It is in this way prescribed these methods ought to be utilised as a part of collaboration with each other for better results and management of users’ privacy
5 Future Work
So far I found that the advancement of Big Data and data mining can influence in the changes of users managing their privacy on social networks. In this project, twitter organisation and dataset extracted from the same social network was mostly examined. It is intriguing to keep on exploring what the other social network such as Snap-Chat or Instagram, that have diverse security techniques compared with Twitter based if privacy management has any differences when it comes to management between various social networks.
It likewise would be curious to study the covered-up dangers and inspiration for why individuals used the decentralised administration of informal organisations. Also, regardless of whether the decentralised administration brings changes to individuals’ security concern. Additionally, would be motivating to research what the social networks can do to diminish the danger of their users’ security and in the meantime, and still contribute to Big data and Data mining.
6 Project Management
In this final chapter I will describe and discuss how I managed the project, issues throughout the project, what I did to overcome these issues, methods or tools used to turn the management stress-free but efficient.
Being the scrum master of the project was challenging, I was in charge of annotating key points from the meetings, so setting tasks to carry out and complete every two weeks.
At the same time as confirming and recording individual contribution using a Gantt chart. All notes allowed the project managing workload to be divided somewhat. Also, relaying information back to my supervisor regarding my opinion on the project’s direction and individual concerns regarding work distribution.
6.1 Gantt chart
The Gantt Chart conducted by me, is because it’s a great technique to apply in the project managements, I used Tom planner’s Website for this project. I used this technique to keep track and record of various tasks, the days/weeks I had to complete each task, also gave me an overview of the start and end date of the whole project. (See Appendix F for a breakdown of Group Gantt chart weekly)
6.2 Meeting logs
To complete the project management, stage a meeting log for every meeting with my supervisor was essential to keep track of individual action or contribution completed and actions to take, to discuss key topics of the project from previous meetings, issues encountered during each task, if any more time was needed.
Below you will find the original meeting log (See Appendix G for all the meeting log)
6.3 Issues
During the flow of the project, Challenges and problems were encountered. As the weeks progress I started investing more time and resources into the project, the project required time and effort that I couldn’t always give because of the workload brought from another module. This was one of my main problems which took a lot of effort and detailed planning to overcome it. Getting participants for the interview was also a very difficult, most of the time individuals just would decline my request to take part, I tried to overcome this problem by requesting student that took part in previous projects with me. The lack of expertise knowledge using WEKA led to a lot of misconceptions of the goals and the outcomes I needed to achieve. To overcome that I went to see of the Lecturer who is an expertise in WEKA and data mining, to gather some guidance.
Despite the fact that, those issues were heaping up, I managed to complete the tasks that I set each week, I overviewed the issues, carried out some research for help and guidance on how to deal with type of issues until I solved each one.
6.4 Reflection on the presentation feedback
I think overall my presentation went great, however, I can recognise features which could have been enhanced for future presentation. Given the feedback from my supervisor one primary thing that emerges is that “no discussion on the methodology”. At the time i thought that this presentation was only to discuss how far I was with the project and show what I have achieved so far, but reflecting on the feedback, it would be great to have discussed that section as it would make my supervisor have a clear idea of how I approached my question and how my project is being constructed.
There are a few other points mentioned by my supervisor such as “no title”, “modularity and average degree missing description” and “to clarify my deliverables”. Regards the description for the type of analyses missing I’m sure it was included in the presentation but then again reflecting on it, I will include this section in the project to clear this issue. Other than that, I realise that a title would be helpful to identify what my project is about and for the deliverables I was still confused as I wasn’t sure if it was meant deliverables as in the primary research (interviews, data visualisation and predictive WEKA model) I carried out or just a briefly discussion of the report structure.
Overall I am satisfied with the way the undertaking went and very delighted in inquiring about the subject and although assembling the information was challenging but it was interesting. Carrying out a presentation made me nervous, yet that gave me great practice at thinking about my sentences on the spot and sorting out my thoughts. I feel that get ready and delivering the presentation has built up my confidence and I will think back on it as an extremely positive experience.
Appendices
Appendix C – PowerPoint slides (Project presentation)








Appendix E – Detailed project proposal
300/303COM Detailed Project Proposal
| First Name: | |
| Last Name: | |
| Student Number: | |
| Supervisor: |
Section one: Defining your research Project
1.1 Detailed research question
Can data mining technique (Graph theoretic) be used to demonstrate privacy issues relating to Twitter?
1.2 Keywords
Big data Analysis, Data mining, Social network, Data visualisation, Privacy, Twitter
1.3 Project title
A linkage-based and structural analysis for privacy awareness on social network
1.4 Client, Audience and Motivation:
Data mining techniques to big data can reveal hidden patterns, which lead to new insights. In the context of social network, large amounts of information are stored daily online. This information is often sensitive, such as profile information, current location or even your device-specific information. This sensitive data can be exploited by organisations or individuals.
I chose this topic because data mining has become increasingly problematic involving many ethical issues such as privacy, misinterpretation, the problem of accuracy, anonymous information, Stereotyping, and Legal consequences.
The incorrect use of the data mined, put users of social network in doubts of how secure their sensitive data is. The outcomes of the project are related to trust between social networks and users. The group of people who would be interested in knowing these findings would be social network users and they would benefit by having a better understanding of the security risks involved in data mining of social network.
1.5 Primary Research Plan
1) Collecting and analysing twitter data (using gephi), to provide the users data visualisation,
2) Highlight main points from analysis to present in the interview, to make participants more aware of the findings before answering the questionnaire,
3) Identify possible general questionnaire (6-8 questions), to gather opinions and analyse them,
4) Select a group of people to interview (10 max), users of social networks in Coventry University,
5) Comparison of data and summary of results, 5 of the participants will have access to the findings of data mining and the others won’t. To identify the differences between the two groups’ opinions,
6) Analyse the results found from the interview to answer my research question.
Section Two: abstract and Literature review (1500 words suggested)
2.1 Abstract
Data mining methods have been generally utilised as a part of many research disciplines, for example medicine, sports, social network to extract useful knowledge. Research data regularly should be distributed alongside the data mining model for check or re-analysis. In any case, the security of the distributed information should be ensured that it is protected because the distributed information is liable to abuse, for example, linking attacks.
This project presents a qualitative study to demonstrates data mining technique that will be applied and then present the findings and analysis to the users, a general questionnaire for the interviews are carried out, analysed and evaluated to find out of how effective it is to apply data mining to see how aware users are of the issues related to data mining. “Twitter” social network has been selected as the case study to reveal connection between social network, data mining and the issues related to privacy.
The values of privacy should be respected and protected so that the data being collected and mined doesn’t break the trust of users’ providing sensitive data to social platforms. Nevertheless, the issues related to privacy increased because users avoided to understand the process of data mining on social network. The analyses and evaluation carried out, will be based on the results of the data mining and the interviews by analysing the findings and comparing users answers of two different groups. Raising these issues would benefit users of social network by becoming more aware of the risks related to data mining.
2.2 Initial/Mini Literature Review (500 words – 750 words)
The usage of big data is the way toward getting and examining information in alternate points of view to determine some new conclusions. People utilise big data of various associations to hunt down new examples to (or “proposing to”) finding new and effective results. The standard meaning of data mining is that it is, “the nontrivial extraction of understood, already obscure, and conceivably valuable data from information”. It is otherwise called, the exploration of separating helpful data from substantial databases. Independent of the way that data mining benefits people, association, and even states in certain ways, it additionally conveys some genuine ethical consequences (Moftakhari and Dogan, 2015).
The most widely recognised issues are the informed assent of those included in research through data mining is the security of individual information and replication of research information from the existing big data. The moral issues involved in the mining of big data can be countered through educated assent, which implies that those included in research tasks ought to be taught of the examination goals, potential unfriendly impacts, the capacity to deny support or withdrawal whenever, with no outcome, keep up their information after the end of the overview, and so on. It will give some accreditation to the first maker of the information.
Some of the ethical issues involved in the usage and exploitation of big data are privacy, Misinterpretation and the problem of accuracy, Anonymous information, Stereotyping, and Legal consequences.
Data mining privacy
The most vital and principal moral issue with data mining is the problem of security. Gavison (1984) contended that protection is not an acquired a portion of society because the general investment in the general public requires transactions and interchanges with each other. This implies nobody can live in supreme confinement, and thus total protection is unrealistic. In the circumstances, when there is no complete security, distinctive people and associations have created diverse measures and discernments for protection. People can point of confinement individuals’ entrance to their information by surrendering their availability. Also, they can settle some cost for those, who need to get to their data. Theft rights have a critical part in such manner. Throughout the world, it is broadly conceded that the loss of security is the fundamental underlying result of data mining. Security can be revealed either purposefully or accidentally. However, it can prompt one’s discouragement. So, to address this fundamental issue of data mining, it is required to characterise norms leads through which the assent of the first creator is taken before mining his/her data. The same is valid for associations.
Data mining miss-interpretation and accuracy
Another imperative moral issue with data mining is the confusion of the outcomes that are being gotten from the data mining. For instance, if the measurements demonstrate that the offer of cool beverages expands so do the frozen yogurts; nonetheless, it does not imply that there is any connection or causation with the dessert increment in the deal with that of cool beverages. So, the ineffectively mined information or unintelligent elucidation of the information can likely prompt the distortion of results (Van and Royakkers, 2004). The confusion of results will offer ascent to the misinterpretations, and henceforth the moral grounds of data mining lose its footings. Another issue with data mining is that information is taken from different sources without recognising the distinction between unique sources. The various outer wellsprings of proof raise issues of the exactness of the new conclusions. Now and then mining is done over terminated information that was exact at some specific time and space yet now, does not clarify the contemporary circumstances. At the point when results are drawn from such terminated information, the odds of incorrectness of those outcomes are regularly.
Summary
The data mining technique of Graph theoretic is one of the main methods in social network analysis over the other techniques. The graph theoretic methods are applied to determine important features of the network such as the nodes and links (example influencers and the followers). Despite all these benefits, all data mining techniques share serious ethical, social and privacy implications. It was mentioned by various researchers that there is concerns about data mining and privacy. Big data is an important and very complex topic, it is almost natural that immense security and privacy changes will arise (Michael & Miller, 2013; Tankard, 2012). These studies investigate data mining issues related to social network, highlighting significant points for users’ awareness.
Bibliography
Tucker, P. (2013) Is privacy Algorithmically impossible? [online] available from
Press, G. (2013) ‘A very short history of big data’. Forbes [online] 9 May. available from
Laney, D. (2001) Application delivery strategies [online] available from
Chen, M.-S., Han, J., and Yu, P. S. (1996) ‘Data mining: An overview from a database perspective’. IEEE Transactions on Knowledge and Data Engineering 8 (6), 866–883
Fang, L. and LeFevre, K. (2010) ‘Privacy wizards for social networking sites’. Proceedings of the 19th international conference on World wide web – WWW ’10 [online] 351–360. available from
Iles, H. (2013) Ethics of Data Mining: a New Zealand Survey. 1st ed. [online] Howard Robert Iles, pp.4. available from: https://www.researchgate.net/publication/264673019_Ethics_of_Data_Mining_a_New_Zealand_Survey#pf4 > [3 January 2017]
Moftakhari, M.M., and Doğan, G., Ethical Issues in Data Mining. [online] available from:
Van Wel, L., and Royakkers, L., (2004) Ethical issues in the web data mining. Ethics and Information Technology, [online] 6(2), pp.129-140. available from http://link.springer.com/article/10.1023/B:ETIN.0000047476.05912.3d > [3 January 2017]
Martin, K. E. (2015). Ethical issues in the Big Data industry. MIS Quarterly Executive, [online] 14, 2. available from http://misqe.org/ojs2/index.php/misqe/article/viewFile/588/394 > [3 January 2017]
Saunders, M., Lewis, P., and Thornhill, A (2011) Research methods for business students. [online] available from https://is.vsfs.cz/el/6410/leto2014/BA_BSeBM/um/Research_Methods_for_Business_Students__5th_Edition.pdf> [2 February 2017]
Michael, K., Miller, K, W (2013) Big data: New opportunities and New Challenges [Guest editors’ introduction]. Computer, [online] 46(6), pp.22-24 available from http://ieeexplore.ieee.org/document/6527259> [2 February 2017]
Tankard, C (2012) Big data security. Network security, [online] 7(2), pp.5-8 available from https://www.researchgate.net/publication/257523496_Big_data_security> [2 February 2017]
George, G., Haas, M. R., Pentland, A., Imperial, 1, and London (2014) ‘Big data and management’.Academy of Management Journal [online] 57 (2), 321–326. available from
IBM (n.d.) Extracting business value from the 4 V’s of big datano[online] available from
Sagiroglu, S. and Sinanc, D. (2013) ‘Big data: A review’. 2013 International Conference on Collaboration Technologies and Systems (CTS) [online] 42–47. available from
Beal, Vangie data mining [online] available from http://www.webopedia.com/TERM/D/data_mining.html> [19 March 2017]
Anderon.ucla.edu (2015) Data mining: what is data mining? [online] available from http://www.anderson.ucla.edu/faculty/jason.frand/teacher/technologies/palace/datamining.htm> [19 November 2017]
Alterman, A. (2003) “A piece of yourself”: Ethical issues in biometric identification. Ethics and Information Technology [online] 5(3), 139-150. Available from [19 March 2017]
Villars, R. L., Olofson, C. W., and Eastwod, M. (2011) Big data: What it is and Why you should care [online] available from
Lewis, K., Kaufman, J., Gonzalez, M., Wimmer, A. and Christakis, N. (2008) “Tastes, Ties, And Time: A New Social Network Dataset Using Facebook.Com”. Social Networks 30 (4), 330-342
Zimmer, M. (2017) On The “Anonymity” Of The Facebook Dataset (Updated) | Michaelzimmer.Org [online] available from
Oates, B. J. (2006a) Research Information systems and computing [online] SAGE Publications. Available from https://books.google.co.uk/books?id=ztrj8aph-4sC&pg=PA33&lpg=PA33&dq=oates+research+process+framework&source=bl&ots=BehKwVslfg&sig=lg7B-SB7q4xWBiDS4g6J0BB4DxA&hl=en&sa=X&ved=0ahUKEwj9kqnWjPzSAhXIL8AKHZzICAgQ6AEIKTAB#v=onepage&q=oates%20research%20process%20framework&f=false> [31 March 2017]
Hoppe, (n.d) Density and average degree [online] available from [12 April 2017]
Brainasoft, I. D (2012) Modularity definition and information [online] available from
Packtpub (n.d) Using the Force Atlas 2 layout algorithm [online] available from [12 April 2017]
Bastian M., Heymann S., Jacomy M. (2009). Gephi: an open source software for exploring and manipulating networks.International AAAI Conference on Weblogs and Social Media.
Pritchard, M (n.d) semi-structed interview [online] available from http://evaluationtoolbox.net.au/index.php?option=com_content&view=article&id=31&itemid=137> [16 April 2017]
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Social Media"
Social Media is technology that enables people from around the world to connect with each other online. Social Media encourages discussion, the sharing of information, and the uploading of content.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: