Malware Detection Method to Detect Unknown Malwares Using Deep Learning
Info: 20518 words (82 pages) Dissertation
Published: 12th Sep 2024
Tagged: Cyber Security
ABSTRACT
The main aim of this paper is to present a robust Malware Detection method to detect unknown malwares using deep learning. With the ascent in the shadow Internet economy, malware has formed into one of the significant dangers to PCs and data frameworks all through the world.
Deep learning works on multiple processing layers which makes it more efficient. While, the existing signature or update based detection is customary technique in existing antivirus products, they can detect malwares only after the damage has been done. Therefore, detection is not that effective. As of now the greater part of such frameworks are signature based, which implies that they attempt to recognize malware in light of a solitary element.
The significant burden of such signature based recognition frameworks is that they can’t identify obscure malware, yet just distinguish variations of malware that have been already recognized. So, this circumstance seriously affects the detection of malwares. We will evaluate the malwares, and to improve the detection accuracy, we have adopted a new classification method. For detecting viruses there are phases, which includes disassembly, pre-processing, Control Flow Graph (CGF) conversion, and classification. In this paper we are using Neural Networks for the purpose of Classification.
Index Terms — Deep Learning, Data Mining, IDA, Neural Networks, CFG, Classification.
1 INTRODUCTION
1.1 Aim & Objectives
1.1.1 Aim
The point of the venture was to build up a dispersed framework fit for utilizing machine learning strategies to identify malicious behavior and keep away the further spread of infections it can do. As indicated by Kaspersky in April 2013 alone, 215190 novel examples of malware where found on their clients PCs. This worryingly high number is just prone to increment, particularly as the malware writer’s motivators for composing such programming is presently for the most part a budgetary one. Customary infection location depends on the utilization of marks, which comprise of groupings of bytes in the machine code of the infection. A decent mark is one that is found in each question contaminated by the infection, however is probably not going to be found if the infection is absent. The issue with the utilization of signature alone is that new sorts of infections, for example, polymorphic ones, can change their code, making mark era troublesome/inconceivable. By using a machine learning approach we expect to prepare our framework to recognize action which seems peculiar, which means the framework will have the capacity to distinguish new infections without waiting be unequivocally prepared of their nearness.
1.1.2 Objectives
The Project was made with the following objectives in the mind:
- Manufacture a system to securely watch virus proliferation.
- Catch or download infections and eliminate it.
- Outline a perception to see the spread of these infections.
- Build up a framework with the objective of enhancing each machine’s capacity to identify an infection.
- Thorough testing of the framework will be important to evaluate its execution.
1.2 Importance
An anti-virus or a digital assault framework is any sort of hostile framework utilized by people or extensive associations that objectives foundations, PC systems and data frameworks, and different gadgets in different vindictive ways. The dangers or assaults normally start from an unknown source that either takes, changes, or totally crushes specific focus by hacking into a powerless piece of the framework. Digital assaults have turned out to be progressively complex and unsafe and a favored strategy for assaults against expansive elements, by aggressors. Digital war or digital fear based oppression is synonymous with digital assaults and endeavors three primary elements for threatening individuals that additionally impedes tourism, improvement and smooth working of governments and other foundation in a nation or a substantial business partnerships. These elements are dread about security of lives, substantial scale financial misfortune that causes negative attention about a company or government also, defenselessness of government frameworks and foundation that brings up issues about the honesty and credibility of information that is distributed in them.
1.2.1 About the Research Problem
Hostile to malware investigation and discovery framework is a noteworthy asset in keeping up an association’s antivirus readiness and responsiveness amid flare-up occasions. This readiness and reaction adds to the prosperity of the associations IT wellbeing, and therefore to the economy all in all. In any case, the utilization of such programming is predicated on an underlying and precise distinguishing proof of malware that is utilized to create strategies to help the computerization of malware ID and grouping. Malware distinguishing proof and examination is an in fact exceptional teach, requiring profound learning of equipment, working frameworks, compilers and programming dialects.
To aggravate the issue, effective recognizable proof and examination by malware investigators has been bewildered by the utilization of jumbled code as of late. Malware scholars have received confusion innovation to mask the malware program so that its noxious plan is hard to distinguish. Confusion strategies can include clouding a program’s behavioral examples or get together code, scrambling a few segments, or compacting a portion of the malware information in this way de-14stroying the discernible code designs. There are unreservedly accessible open-source and business muddling devices which indicate to solidify applications against theft and de-obscurity systems. In the open source extend UPX, for instance, the muddling is intended to be reversible, yet programmers make slight adjustments to the source code to demolish this property. Manual unloading by an accomplished individual should at present be possible in this case, yet a computerized procedure turns out to be to a great degree troublesome.
In the counter infection industry, the lion’s share of against infection recognition frameworks are mark based which was powerful in the early phases of malware. Be that as it may, given the quick improvement of malware innovations and the colossal measure of malware discharged each day, the mark based approach is neither productive nor powerful in vanquishing malware dangers. As of now, we need discovering more powerful and effective approaches. To manage the fast improvement of malware, specialists have moved from a mark based strategy, to new methodologies in light of either a static or element examination to recognize and group malware. In the static investigation, specialists concentrate on dismantling code to obtain valuable data to speak to malware, though in the dynamic examination, they screen the execution of malware in a controlled domain and concentrate data from runtime follow reports to speak to the malware.
In utilizing both static and element strategies, it is pivotal to discover key components that can speak to malware and that are viable in malware discovery and characterization. One of the objections about malware identification and arrangement is that once the strategy is made open, a malware essayist require just jumble the central element utilized as a part of the grouping to maintain a strategic distance from location. In building up this proposition, I planned and actualized a few examinations in light of static and element systems. The aftereffects of these investigations drove me and my exploration partners to trust that an integrated technique could be produced that joins static and element strategies to supplement each other to make the location and arrangement successful and vigorous to changes in malware development. A moment protest about standard techniques for order is that they depend on a given arrangement of malware and may apply to that set, however may not toll too on later or future malware. In building up this proposition, we brought later malware families into our examinations to test the power of our strategy.
1.2.2 Impact of Research Problem
The essentialness of a programmed and powerful malware location and order framework has the accompanying advantages:
- When new malware is found in the wild, it can rapidly be resolved whether it is another example of malware or a variation of known family.
- If it is a variation of known family, the counter infection examiners can foresee the conceivable harm it can bring about, and can dispatch the important method to isolate or expel the malware. Moreover, given arrangements of malware tests that have a place with various malware families, it turns out to be essentially less demanding to infer summed up marks, actualize evacuation techniques, and make new relief systems that work for an entire class of projects.
- Alternatively, on the off chance that it is new malware, the framework can at present recognize the comparability between the new malware and other known malware which gives significant data to further investigation.
- Analysts can be free from the tiring examination of an immense number of variations of known malware families and concentrate on the genuinely new one.
1.3 Types of Attacks
We can list down the numerous types of digital assaults in an expanding request of modernity and multifaceted nature of the assault itself. The request is likewise sequential in some courses since the assaults have turned out to be more advanced with time keeping in mind the end goal to remain in front of the security frameworks that are utilized as a part of the systems and on individual frameworks. The underlying assaults on PCs were more social building assaults that were not exceptionally confused and were gone for individual hosts. The system sniffers, parcel sniffing and session seizing assaults came next, with the approach of internetworking.
Computerized tests and outputs that came next, do surveillance taking after which across the board assaults, for example, the disseminated dissent of administration sort assaults were executed. Infections that exploited on the defenselessness in a product just by taking a gander at gathered code came into picture. The more complex infections that spread through messages and across the board trojans came close by. Hostile to measurable malware and worms that escape the security frameworks by utilizing encryption and code pressing, are extremely widespread as of late. So are the inexorably refined system of traded off hosts, called botnets. Botnets have charge and control ability inside its own system and can do greatly huge spread assaults in the size of internet.
1.3.1 Role of Malware in Cyber Attacks
In all these distinctive methods from the early circumstances to now, one segment of the assault design essentially should be distinguished and relieved from spreading itself. These are the vindictive executable records or the malware, that do the greater part of the meddlesome exercises on a framework and that spreads itself over the hosts in a system. Noxious programming (malware) is characterized as programming performing activities proposed by an aggressor, for the most part with vindictive aims of taking data, personality or different assets in the figuring frameworks. The distinctive sorts of malware incorporate worms, infections, Trojan stallions, bots, spyware and adware. They all display diverse kind of vindictive conduct on the objective frameworks and it is fundamental to keep their action and further expansion in the system utilizing distinctive techniques.
1.3.2 Viruses
A program that duplicates itself and contaminates a host, spreading starting with one record then onto the next, and afterward starting with one host then onto the next, when the documents are replicated or shared. The infections generally join themselves for the most part to executable documents and here and there with ace boot record, auto run scripts, MS Office Macros or even different sorts of files. The hypothetical preparatory work on PC infections backpedals similar to 1949. John von Neumann (1903-1957) built up the hypothesis of self-replicating robots. The capacity of an infection is to basically pulverize or degenerate documents on the contaminated hosts. It was in 1984 that Fred Cohen presented the execution of PC infection and showed its capacities on a UNIX machine. The “Mind” infection that tainted the boot division of the DOS working framework was discharged in 1986.
1.3.3 Worms
PC worms send duplicates of themselves to different has in the system, more often than not through security vulnerabilities in the working frameworks or the product. They spread consequently regularly with no client intervention. The worms spread quickly over the system influencing many has in their way. They include most of the malware and are frequently erroneously called infections. Probably the most renowned worms incorporate the ILOVEYOU worm, transmitted as an email connection that cost organizations upwards of 5.5 billion dollars in harm. The Code Red worm damaged 359,000 web sites. SQL Slammer had backed off the whole web for a short timeframe and the celebrated Blaster worm would compel the host PC to reboot over and over.
1.3.4 Trojans
Trojan are applications that give off an impression of being accomplishing something harmless, however covertly have pernicious code that has meddling conduct. Much of the time, trojans as a rule make an indirect access that permits the host to be controlled remotely either specifically or as a major aspect of a botnet system of PCs likewise tainted with a Trojan or different malevolent programming. The real distinction between an infection and a Trojan is that trojans don’t duplicate themselves. They are typically introduced by a clueless client. PC Writer was the main Trojan steed program that turned out in 1986. It put on a show to resemble a real installable for the shareware PC Writer Word preparing program. In any case, on execution the Trojan steed would begin and erase all information on the hard plate and arrangement the drive.
1.3.5 Spywares
Spyware is any product introduced on a host which gathers your information starved of the assent or learning of the client, and sends that data back to its architect. This could incorporate key logging to catch out passwords, and other delicate data. The spyware begins introducing undesirable programming and toolbars in the programs without the information or assent from the client. Countless individuals have spyware running in their frameworks without recognizing it, however for the most part those that have one spyware application introduced additionally have twelve more. The sign for its nearness is that the PC turns out to be moderate and numerous obscure programming are normally naturally introduced.
1.3.6 Botnets
Botnets are systems of traded off hosts which can be remotely controlled by an assailant who is normally alluded to as the botmaster or the bot-herder. A bot is commonly associated with the Internet, and for the most part influenced by a malware similar to a Trojan stallion. The botmaster can control every bot remotely over the system. It can educate the bots to do malware refresh, send spam messages and take data. The operation of the bots are controlled utilizing a charge and control (C2C) channel, which can be incorporated or companion to-peer. The topology and control channel decides the effectiveness and versatility of the botnet. The botnet discovery is a dynamic zone of research because of the natural many-sided quality and size of the issue.
1.3.7 Malware Hazards Lately
The multiplication of malware lately is evident from the insights accumulated, over the years. From the information assembled from an autonomous IT security organization AV-Test, we see that the aggregate number of malware on the web has come to about 1 billion in the year 2015. More than 30 million new malware occasions have showed up in the year 2012 alone, which is double the quantity of concealed malware that were presented in the earlier year. A scope of noxious programming/frameworks, extending from exemplary PC infections to Internet worms and bot systems, target PC frameworks connected to a private systems or the Internet. Multiplication of this danger is driven by a criminal industry which methodically involves arranged hosts for unlawful purposes, for example, social event of secret information, conveyance of spam messages, and abuse of data for monetary additions and so forth.
As indicated by McAfee, My Doom is an enormous spam-mailing malware that brought on the most monetary harm ever, an expected $38 billion. Conficker was a botnet utilized for secret word taking and it created an expected $9.1 billion harm. Sadly, the rising numbers and high differing qualities of malware render exemplary security systems, for example, against infection scanners, not extremely helpful and have brought about a large number of hosts in the Internet tainted with noxious programming (Microsoft, 2014; Symantec, 2016) From the above examination, it is seen obviously that a tremendous assignment of enhancing the location ability and philosophy on the host lies on the antivirus items. Continually tested by the malware which make utilization of known or obscure vulnerabilities in the product or the system frameworks to concoct new sorts of assaulting and concealing instruments.
The antivirus organizations utilize numerous methods for making the database of known assault vectors to distinguish known assaults. One of them is to gather any suspicious looking documents or doubles (or those that were known to bring about issues) that are distinguished by the end clients or another framework, and afterward dissect them. This procedure, called malware investigation, envelops the means of malware identification and malware grouping. These need not be separate strides in the entire procedure, however in some useful executions they might be.
1.4 Detection Methods
In this segment, we audit the identification and anticipation answers for digital assaults when all is said in done and malware specifically. When we discuss security arrangements it is evident to begin with characterizing an Intrusion Detection System. An Intrusion Detection System can be a gadget or a product that screens a system or a framework, for vindictive exercises and creates a reports for an administration station [47]. They for the most part distinguish the interruption that have as of now happened or that which are in advance. The earliest frameworks in 70s included searching for suspicious or strange occasions in framework review logs. The sum or granularity of review logs that are broke down is a tradeoff amongst overhead and adequacy. The host based IDS alludes to a framework that is conveyed on individual has; this is typically an operator program that does occasion relationship, log examination, honesty checking, and arrangement authorization and so on a framework level.
The Antivirus arrangements are a sort of HIDS that screen the dynamic conduct of the host framework. They screen each client and framework action and raise caution on any security approach infringement at client and framework level. The Anti-infection programming items think about and dissect the malware and concoct extraordinary examples or marks to recognize the diverse sorts of malware. This is vital since the cleanup, isolate and expulsion strategies for every sort of malware is not quite the same as each other. Regular the counter infection organizations get a huge number of cases of conceivable vindictive records that must be broke down, in a speedy and effective way. For this the mark based malware location strategies are generally utilized attributable to their speed and effectiveness. Be that as it may, they may not give an entire scope for every single conceivable assault, since the malware toolboxes create polymorphic and transformative variations of infections and worms that effortlessly beat the mark based frameworks.
After investigation, the pairs are given names and the marks are extricated for recently observed variations and put away in the infection database. Throughout the postulation, we characterize malware examination as ordering or bunching a malware to a specific family or gather and don’t address the issue of malware recognition alone. The issue and the current answers for tackling it are clarified in detail in the coming areas.
We now will take a gander at the part of IDS in identification of already inconspicuous zero-day assaults. Aside from the Host-based IDS talked about before alternate class of IDS that is utilized to screen the exercises and occurrences going in a system shape the class of Network Intrusion Detection Systems. A few govern based and factual techniques have been utilized in the current NIDS. A few IDS utilize profound parcel examination in the system movement information while a few strategies utilize header data in the bundles or do filtering of the activity information at different level of granularity, to search for unusual examples. The movement information can be voluminous and examining the information to search for examples, particularly for uncommon and beforehand concealed occasions, for example, an infection assault can challenge assignment. Likewise the assaults can be made in, for example, route as to fumes the assets that are utilized as a part of the IDS stage.
The other fundamental order of IDS is done in light of the decision of demonstrating the assault and the non-assault or kind data. There are abuse identification frameworks or the mark based location frameworks that model the examples of beforehand known assaults. These could be hand-created marks or even standards learnt by a framework that portrayed a known assault. These frameworks are quick in identifying known assaults however are extremely frail in recognizing zero-day assaults. Likewise the speed of these frameworks have a tendency to be slower as the database of mark develops and frequently than not, the assaults are identified after they happen as it were. Alternate class of IDS is the abnormality identification frameworks that models the typical non-vindictive conduct of the framework and any deviation from that as unusual. They are exceptionally viable in recognizing new concealed assaults, however experience the ill effects of the issue of high false-positive rates.
Likewise the earth is dynamic to the point that the very meaning of what is typical or irregular information itself changes after some time, posturing more difficulties in demonstrating the framework. The Intrusion Detection Systems that make utilization of measurable elements in the movement designs as well as payload information, have the characteristic issue with regards to relearning the model. A proficient technique for relearning turns out to be critical and there are not very many earlier work that address this. Additionally the machine learning framework itself can end up plainly helpless against manipulative preparing information infused by the programmers keeping in mind the end goal to deceive the framework into displaying vindictive code as non-malevolent. In this way the security of a clump prepared model itself turns into a genuine concern.
1.4.1 Malware Analysis
The malware investigation that Anti-infection organizations do, can be ordered extensively into two classes; the static examination systems and the dynamic examination methods. The static systems include investigating the parallels specifically or the figuring out the code for examples in the same. The dynamic examination procedures include catching the conduct of the malware test by executing it in a sandboxed domain or by program investigation techniques and after that utilization that for removing designs for every group of infection. Cases for these are frameworks like Anubis and CW-Sandbox. Recently static twofold examination procedures are winding up noticeably progressively troublesome with the code confusion strategies and code pressing utilized when composing the malware. The conduct based examination procedures are favored in more refined malware investigation frameworks due to this reason.
In past works, various grouping and characterization procedures from machine learning have been utilized to arrange the malware into families and to likewise distinguish new malware families, from the conduct reports. In our investigations, we propose to utilize the Prole Hidden Markov Model to order the malware les into families or gatherings in light of their conduct on the host framework. We have taken a gander at the difficulties including examination of countless tainted les, and demonstrate a broad assessment of our technique in the accompanying section.
1.4.2 Static Examination
Signature based identification is utilized to recognize an infection or group of infections. A mark based locator needs to refresh its rundown of marks all the more frequently. Since the mark of another infection would not be accessible in the database, it is unrealistic to recognize it as another infection. Indicators here and there investigate heuristics as opposed to depending on marks. Be that as it may, marks frame an imposing rate in the identification procedure. Signature recognition is quick and basic. Polymorphic and changeable infections can’t be contained utilizing mark location. Changeable malware utilize a blend of different code obscurity systems. Putting away marks of every variation of a malware is for all intents and purposes not doable since it builds the word reference of the finder with superfluous marks.
1.4.3 Signature Based Strategies
Signature-based identification gives unquestionable focal points to operational utilize. It utilizes upgraded design coordinating calculations with controlled multifaceted nature and low false positive rates. Lamentably, frame based identification demonstrates totally overpowered by the snappy development of the viral assaults. The bottleneck in the recognition procedure lies in the mark era and the dissemination procedure taking after the revelation of new malware. The mark era is regularly a manual procedure requiring a tight code investigation that is to a great degree tedious. Once created, it must be disseminated to the potential targets. In the best cases, this appropriation is programmed however in the event that this refresh is physically activated by the client, it can at present take days. In a setting where worms, for example, Sapphire can taint over 90% of the powerless machines in under 10 min, assaults and assurance don’t follow up on a similar time scale.
1.4.4 Problems in Static Examination
In the previous couple of years the quantity of watched malware tests has expanded significantly. This is because of the way that assailants began to transform malware tests so as to maintain a strategic distance from recognition by syntactic marks. McAfee, a producer of malware location items, detailed that 1.7 million out of 2.8 million malware tests gathered in 2007 are polymorphic variations of different specimens. As an outcome an immense number of marks should be made and appropriated by against malware organizations. These must be prepared by location items at the client’s framework, prompting debasement of the frameworks execution. Malware conduct families can address this issue. In this way, all polymorphic variations of a specific specimen are dealt with as individuals from the same malware conduct family. For this, we require a programmed strategy for suitably gathering tests into separate conduct families.
1.4.4.1 Polymorphic Malwares
The variations delivered by polymorphic malware continually change. This is finished by filename changes, pressure, scrambling with variable keys, and so forth. Polymorphic malware deliver distinctive variations of itself while keeping the natural usefulness as same. This is accomplished through polymorphic code, which is center to a polymorphic malware.
1.4.4.2 Metamorphic Malwares
Changeable malware speak to the following class of infection that can make a completely new variation after propagation. Not at all like, polymorphic malware, changeable malware contain a transforming motor. The transforming motor is in charge of jumbling malware totally. The body of a transformative malware can be comprehensively partitioned into two sections – to be specific Morphing motor and malicious code metamorphic malwares utilize code confusion systems rather than encryption utilized by polymorphic infections.
1.4.4.3 Code Jumbling Strategies
Code jumbling is a strategy of intentionally making code hard to comprehend and read. The subsequent code after jumbling has a similar usefulness. There are an assortment of code jumbling strategies in particular Garbage Code Insertion, Register Renaming, Subroutine Permutation, Code reordering and Equivalent code substitution that are intensely utilized as a part of the transformative infection era toolboxes. A case of proportionate code substitution and refuse code addition. The accompanying figure demonstrates a case of code re-requesting that is done utilizing unqualified bounce directions. Of every one of these strategies the subroutine stage is minimal less demanding to recognize utilizing mark based strategy since there is no genuine adjustment of the guidelines, accordingly.
1.4.5 Dynamic Examination
Robotized, dynamic malware examination frameworks work by observing a projects execution and creating an investigation report condensing the conduct of the program. These examination reports ordinarily cover document exercises (e.g., what records were made), Windows registry exercises (e.g., what registry qualities were set), arrange exercises (e.g., what records were downloaded, what adventure were sent over the wire), prepare exercises, for example, when a procedure was made or ended and Windows benefit exercises, for example, when the administration was introduced or begun in the framework and so on. A few of them are openly accessible on the Internet (Anubis, CW-Sandbox, Joe-box and Norman Sandbox). The primary concern to note about element investigation frameworks is that they execute the parallel for a restricted measure of time. Since vindictive projects don’t uncover their conduct when executed for a few seconds, dynamic frameworks are required to screen the binary’s execution for a more drawn out time. Hence changing examination is asset serious as far as vital equipment and time. There is additionally the issue of numerous ways in the execution arrangement and dissecting every one of them may not be conceivable in a sandbox situation.
1.4.6 Models on Dynamic Methods
Machine learning approaches like arrangement and bunching of malware have been proposed on reports created from element examination. Models are worked for malware families whose marks are accessible and utilized for foreseeing the malware names for recently observed example reports. These models can sum up well, contingent upon the learning calculation and the specimen preparing information from which they were fabricated. The state-of the-workmanship malware investigation frameworks play out a stage of characterization took after by a stage of bunching. In the following segment, a point by point audit of these frameworks and their execution is displayed.
Data mining every so often called information or knowledge discovery is the process of investigating data from different perspectives and summarizing it into valuable information. Graph mining is a special case of structured data mining, Structure mining or organized information mining is the procedure of discovering and removing helpful data from semi organized information sets.
Graph mining is an exceptional instance of organized information mining. The utilization’s development of semi-organized information has made new open doors for information mining, which has customarily been worried with even information sets, mirroring the solid relationship between information mining and social databases. A significant part of the world’s intriguing and mineable information does not effectively overlay into social databases, however an era of programming architects have been prepared to trust this was the best way to handle information, and information mining calculations have for the most part been created just to adapt to even information. XML, being the most regular method for speaking to semi-organized information, has the capacity speak to both even information and self-assertive trees. Any specific representation of information to be traded between two applications in XML is ordinarily portrayed by a pattern regularly written in XSD. Malware or noxious programming, is any product for disturbing PC operation, accumulate delicate data, or obtain entrance to isolated PC frameworks.

1.5 Classifying Malwares
Our point is to beat a portion of the enormous issues that the antivirus innovations confront these days. At last, these issues are communicated as far as bland location of malware, while getting a couple of false positives as could be expected under the circumstances. In this part, we display a structure for malware location expecting to get a couple of false positives as could reasonably be expected. Besides comes about with a profound learning approach, joined with highlight determination in light of the CFG’s, is prepared on a medium-estimate dataset comprising of clean and malware records. Cross validation is then performed keeping in mind the end goal to pick the correct qualities for parameters. At last, tests are performed on another, non-related dataset. The acquired outcomes were exceptionally promising.
1.5.1 Features for Machine Learning
For each two fold record in the preparation datasets, an arrangement of elements/traits was registered, in view of numerous conceivable methods for breaking down a malware, for example:
- Behavior attributes in secured situations. From the Drone-zilla condition, we watched and observed conduct attributes of malware. These qualities were subsequently presented in a restrictive runtime copying motor that can run the malware test inside a secured domain and concentrate the components for each such specimen in a matter of milliseconds.
- File qualities from the PE design perspective. Malevolent double executables are frequently adjusted keeping in mind the end goal to make them littler, pressed and muddled. We screen distinctive methods, for example, unusual sizes of every parallel code segment, which is imperative; the quantity of areas; the compiler that was utilized to produce the paired code; the nearness of TLS data (code that is executed before the primary string is begun); the quantity of DLL’s references for element connecting; the nearness of certain asset data inserted inside the PE executable, and so on.
- File arrange from a geometrical perspective. For a prepared eye, really observing another twofold malware, it is anything but difficult to state if something is suspicious. We noted down every one of the anomalies that we watched when taking a gander at a paired and utilized them as components for the learning structure.
- File packer, obfuscator or defender sort. An imperative down to earth perception was that the greater part of the malware code these days comes pressed, muddled or protected (i.e. shielded from manual well-ordered investigating). We changed a portion of the static marks identifying known packers/obfuscators/defenders into elements contributing in the recognizable proof of malware.
- Package installer sort.
- File content data recovered from imports, trades, asset index or from various strings that dwell in the information segment of the record.
- Compiler particular components. The aggregate number of document traits that we characterized {excluding those identified with imported functions} was around 800, however for the extent of this proposal just 308 Boolean qualities were utilized.
1.5.2 Datasets & Calculations
We utilized a preparation dataset containing more than 10000 virus signatures. The quantity of malware documents and separately clean records in these datasets is appeared in the initial two segments. As expressed over, our fundamental objective is to accomplish malware location with just a couple (if conceivable 0) false positives, in this way the spotless documents in this dataset is substantially bigger than the quantity of malware records. The perfect records in the preparation database are fundamentally framework documents (from various variants of working frameworks) and executable and library records from various prominent applications. We likewise utilize clean documents that are pressed or have a similar shape or the same geometrical similitudes with malware records (e.g. utilize a similar packer) so as to better prepare and test the framework.
1.5.3 Results from Various Calculations
Cross-approval tests for 3, 5, 7, and 10 folds were performed for every calculation on the preparation dataset. For every calculation, we utilized the best outcome from most extreme 200 iterations. The cross-approval comes about to get the best malware identification rate (i.e. affectability) on preparing dataset, the quantity of false cautions created by this calculation is substantially higher than the one14. The outcomes for the comparison demonstrate that both COS-P-Map-F1/F2 calculations create great outcomes, with a decent specificity (83%) and not very many (2) false positives, regardless of the possibility that the malware dispersion in this dataset is different15 from the one in the preparation dataset. From the specialized perspective, the most helpful calculations are the course uneven perceptron and its expressly mapped adaptation.
1.6 Deep Learning
Given the impediments of preparing profound neural systems, this area presents different strategies and calculations that permit to conquer these confinements so as to develop effective profound neural systems. Outlining highlights has been a troublesome theme in flag preparing. For instance, the SIFT locator characterized by Lowe in [9] is an intense component division, however it is hard to adjust to particular issues in PC vision. An alternate approach is to take in components from information. This can be accomplished by outlining highlight indicators in an approach to display the structure of the information well. The initial step of profound learning is generative pre-preparing, which works in an approach to in this manner learn layers of highlight indicators. Beginning with basic components, these fill in as contribution to the following layer so as to take in more mind boggling highlights. Pre-preparing permits to locate a decent introduction of the weights, which is a locale of the cost work that can be advanced rapidly through discriminative adjusting of the system utilizing back propagation.
1.6.1 Restricted Boltzmann Machines
A Boltzmann Machine is a generative repetitive stochastic neural system that permits to take in complex components from information. As intra-layer associations make learning troublesome and wasteful, it is not examined assist.
A Restricted Boltzmann Machine (RBM) characterized by Hinton in [16] and [18] is a Boltzmann Machine, in which the neurons are twofold hubs of a bipartite diagram. (A bipartite chart is a diagram whose hubs can be assembled into two disjoint sets, with the end goal that each edge associate a hub from the principal set to the next.) Both gatherings of neurons/units are called unmistakable and concealed layer as pictured in Figure 1.1. The general idea of RBMs is shown in [13].
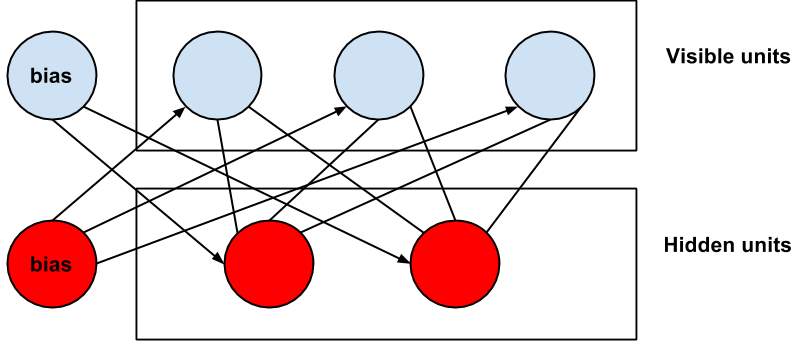
Fig 1.1: Controlled Boltzmann Machine with three visible elements and two concealed units (and biases)
The noticeable units of a RBM speak to states that are watched, i.e. contribution to the system, while the shrouded units speak to the element locators. RBMs are undirected, with a solitary framework W of parameters, which relates the availability of obvious units v and shrouded units h. Besides, there are predisposition units for the noticeable units and h for the shrouded units. The vitality of a joint design (v, h) of the units of both layers has a vitality work.
1.6.1.1 Training
Taking in the network weights is performed in an approach to learn highlights identifiers in the concealed layer of the noticeable layer. All the more absolutely, the enhancement goal of RBMs is to augment the weights and predispositions keeping in mind the end goal to dole out high probabilities to preparing illustrations and to bring down the vitality of these preparation cases. Alternately, some other cases might have a high vitality. The subsidiary of the log likelihood of a preparation case as for a weight.
1.6.1.2 Contrastive Divergence
Contrastive dissimilarity shrouded by Hinton in [16] approximates the inclination doing the accompanying system, expecting that all unmistakable and concealed units are twofold: First, the obvious units are set to a preparation case. Second, the twofold conditions of the shrouded layer are registered. Third, a parallel supposed “reproduction” of the obvious layer is figured. Lastly, it is connected again to figure double estimations of the concealed layer. The weight refresh administer is then:
The purpose behind utilizing double and not probabilistic values in the concealed units originates from data hypothesis. Highlight indicators fill in as data bottlenecks, as each concealed units can transmit no less than one piece. Utilizing probabilities in the concealed units would disregard this bottleneck. For the obvious units, additionally probabilistic qualities could be utilized with little outcomes. When all is said in done, contrastive uniqueness is substantially quicker than the essential preparing calculation introduced already and returns normally very much prepared RBM weights.
1.6.2 Auto Encoders
An auto-encoder or auto-associator is a three-layer neural system with s1 info and yield units and s2 concealed units as envisioned in Figure 1.2.
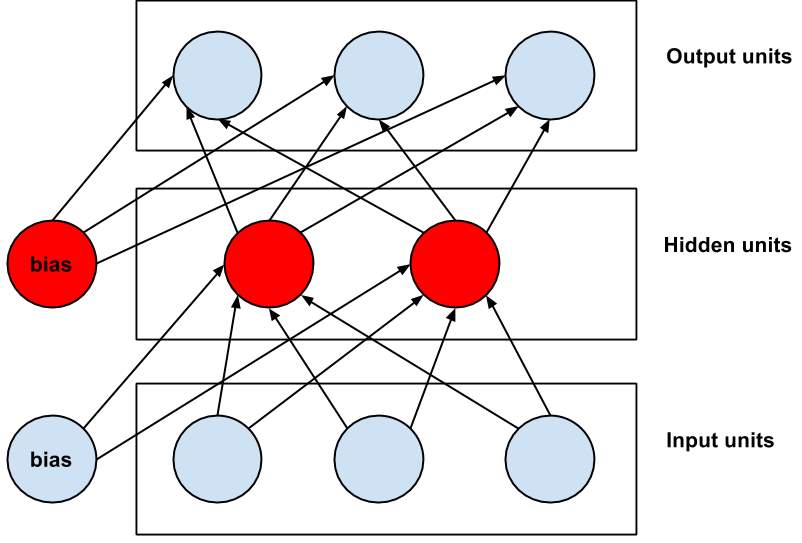
Fig 1.2: Auto-encoder using three input & output components & two concealed units.
It sets its yield qualities to its info values, i.e. y(i) = x(i) and tries to take in the personality work hθ(x) ≈ x. This can be accomplished utilizing back propagation in its fundamental definition. Subsequent to taking in the weights, the shrouded layer units progress toward becoming component identifiers. The quantity of concealed units is variable. On the off chance that s2 s1 maps the contribution to a higher measurement.
1.6.3 Stacked Auto Encoders
Building a DBN from auto-encoders is additionally called a stacked auto-encoder. The learning procedure is identified with developing a DBN from RBMs, specifically the layer-wise pre-preparing, as clarified in [21]. Initial, an auto-encoder is prepared on the info. The prepared concealed layers serves then as the primary shrouded layer of the stacked auto-encoder. Second, the components learned by the concealed layer are utilized as info and yield to prepare another auto-encoder. The educated concealed layer of the second auto-encoder is then utilized as the second shrouded layer of the stacked auto-encoder. This procedure can be proceeded for numerous auto-encoders, comparably to preparing a DBN made out of RBMs. So also, each concealed layer adapts more intricate elements. Last, adjusting of the weights utilizing back propagation is performed on the stacked auto-encoder.
1.6.4 Deep Belief Networks
A Deep Belief Network (DBN) is a stack of simple networks, such as RBMs or auto-encoders that were trained layer-wise in an unsupervised procedure. In the following section, RBMs are used to explain the idea behind DBNs.
Training of a DBN consists of two stages that allows to learn feature hierarchies, as defined in [18], [21] and [22]. In the first stage, generative unsupervised learning is performed layer-wise on RBMs. First, a RBM is trained on the data. Second, its hidden units are used as input to another RBM, which is trained on them. This process can be continued for multiple RBMs, as visualized in Figure 1.3. As a consequence, each RBM learns more complex features.
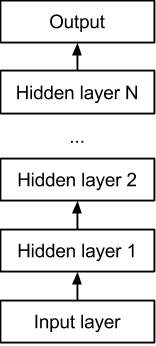
Fig 1.3: Deep belief network structure.
For instance, in a PC vision application, one of the principal RBM layers may learn straightforward elements, for example, to perceive edges. Taking after RBM layers may take in a gathering of edges, for example, shapes, while best layers may figure out how to perceive articles, for example, faces et cetera. This is pictured in Figure 1.4.
In the second stage, discriminative adjusting utilizing back propagation is performed on the whole DBN to change the weights. In light of the pre-preparing, the weights have a decent instatement, which permits back propagation to rapidly enhance the weights, which is clarified in detail in [23], [11] and [12]. Part 4 gives useful proposals on the most proficient method to design DBNs, for example, the quantity of shrouded layers, and the quantity of concealed units in each layer, how much calibrating to perform, and so on.
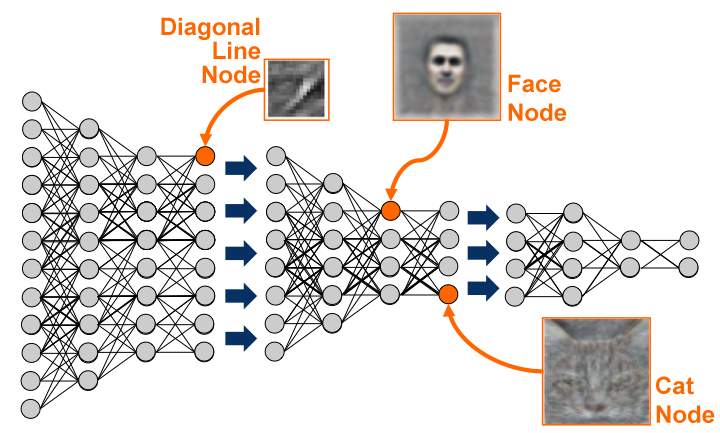
Fig 1.4: Deep belief network strata learning multifaceted feature orders.
1.6.5 Further Approaches
This area quickly covers elective methodologies that are utilized to prepare profound neural systems.
1.6.5.1 Discriminative Pre-Training
Beginning with a solitary shrouded layer, a neural system is prepared discriminatively. Thusly, a moment shrouded layer is embedded between the principal concealed layer and the yield layer. Next, the entire system is prepared discriminately once more. This procedure can be rehashed for more concealed layers. At long last, discriminative adjusting is performed keeping in mind the end goal to change the weights. This technique is called discriminative adjusting and depicted by Hinton in [20].
1.6.5.2 Reducing Internal Covariance Shift
As depicted in [39], amid preparing, a change of the parameters of the past layers makes the dissemination of each layer’s information change. This purported inner covariance move backs off preparing and may bring about a neural system that over fits. Inner covariance move can be repaid by normalizing the contribution of each layer. As a result, preparing can be essentially quickened. The subsequent neural system is additionally more averse to over fit. This approach is drastically extraordinary to regularization shrouded in Chapter 2.4, as it addresses the reason for over fitting, as opposed to attempting to enhance a model that over fits.
2 LITERATURE SURVEY
A From the earliest starting point, heaps of mechanism has been satisfied on malware location utilizing structure succession and control stream examination [1]. Besides, calls (API) have been researched for its helpful data around malware action [2]. Likewise machine learning has been used in different location stages [3]. In the first days of infection appearance, just stagnant and straightforward infections were acquainted with world. In this way, the basic mark based routines had the capacity overcome them [6]. These were great toward the starting however quick development in vindictive exercises of malware influenced scientists to turn on new techniques. A standout amongst the most alluring strategies that conceived at right on time days is smearing information mining on n-grrams approach. Gerald suggested a technique where prolonged the n-grams investigation to distinguish boot area infections utilizing neural systems.
Based upon the occurrences of event in viral and kind projects. Highlight decrease was gotten by creating a four cover such that every infection in the data-set ought to have no less than four of these incessant n-grams present all together for the n-grams to be incorporated into the dataset [8]. Since n-grams neglect to catch the program’s semantics, another element ought to be utilized rather than it. Hofmeyr was profiting from straightforward groupings of framework calls as direction to acknowledge malevolent codes [9]. These API call successions demonstrated the dormant conditions between code arrangements. Bergeron took the conduct and element ascribes into thought to battle the changeability [10]. Gao spoken to another technique to figure out contrasts in twofold projects. Syntactic contrasts without a doubt have the possibility to bring about commotion, so discovering the semantic contrasts would be testing. They used another chart isomorphism method and typical implementation to dissect the switch stream diagram of PE-documents by distinguishing the most extreme regular sub-chart. Their technique discovered the semantic contrast between a PE-document and its fixed rendition; in any case, its false positive does not fulfill zero-day prerequisites [11].
File willIn research of malware discovery and order, the two center issues to be settled are:
- Suitable Representation of Malware.
- Choice of Optimal Classification Decision Making Mechanisms. The portrayal of malware is vigorously reliant on malware investigation and extraction approaches. Distinctive examination and extraction approaches concentrate on various parts of malware and build differing highlight sets. We should choose what sorts of data can be extricated from executable and how this data ought to be removed, composed and used to speak to the executable. Decision of Optimal arrangement basic leadership is identified with the grouping calculations and execution assessment techniques utilized. We have to choose which grouping calculations can be connected in our exploration and what is our summed up characterization handle, and in the meantime choose how to assess the execution of our framework. All malware investigation and extraction methodologies can essentially be arranged into two sorts: (i) in light of components drawn from an unloaded static rendition of the executable document without executing the broke down executable records [Ghe05-09] and (ii) in view of element elements or behavioral elements got amid the execution of the executable records [CJK07, WSD08, AHSF09, KChK+09, ZXZ+10].
2.1 Based on Static Feature Extraction
Since the vast majority of the business programming and malware is disseminated as twofold code, parallel code investigation turns into the premise of static component extraction. Conventional against infection recognition and characterization frameworks depend on static elements separated from executable by figuring out [Eil05, FPM05, Eag08]. Static element extraction in light of parallel code examination is utilized to give data about a program’s substance and structure which are basic, and in this way an establishment of numerous applications, including paired change, double interpretation, twofold coordinating, execution profiling, troubleshooting, extraction of parameters for execution displaying, PC security and crime scene investigation [HM05].
As I said beforehand, static element extraction produces data about the substance of the program, which incorporates code data, for example, directions, essential pieces, capacities, modules, and auxiliary data, similar to control stream and information stream. Much research is centered on this data from alternate points of view. We consider some of these beneath. Gheorghescu [Ghe05] concentrates on fundamental squares of code in malware, which are characterized as “a consistent grouping of guidelines that contains no hops or bounce target”, and by and large contains 12-14 bytes of information. These squares are utilized to frame a control stream chart. The creator utilizes the string alter separation to ascertain the separation between two essential pieces. The string alter remove between two fundamental pieces is characterized as the quantity of bytes in which the squares contrast, which is otherwise called the altered separate. Comparability inquiries can be replied by figuring the hash work for every fundamental piece in the source test and confirming whether the bit at the relating position in the objective channel is set. The creator presents two strategies for inexact coordinating of projects. One is to process the string alter remove, and another strategy is the reversed file which is ordinarily utilized as a part of word web indexes. As the creator specifies, these two strategies have their downsides; alter separation is CPU-escalated and the modified record is I/O bound. The sprout channels [Blo70] strategy was presented centered on fact that Bloom channels are productive in inquiry time as well as away space since they are settled in size.
Essential squares are spoken to in a Bloom channel, and similitude questions can be replied by processing the hash work for every fundamental piece in the source test and confirming if the bit at the relating position in the objective channel is set. Their outcomes were introduced on 4000 examples of Win32 malware. An imperative commitment of this paper is that the creator exhibits that it is conceivable to actualize a computerized ongoing framework to play out this examination on a desktop machine. Kapoor and Spurlock [KS06] contend that a parallel code correlation of the malware itself is not attractive centered on fact that it is blunder inclined, can be effortlessly influenced by the infusion of garbage code and on the grounds that code examination calculations are costly with poor time multifaceted nature. They express that looking at malware on the premise of usefulness is more powerful centered on fact that it is truly the conduct of the code that figures out what it is. Kapoor and Spurlock assume that the more mind boggling the capacity, the more probable it is to characterize the code conduct.
Weightings are doled out to code contingent upon the multifaceted nature of the capacity. A capacity tree is then built in light of the control stream diagram of the framework, and used to take out “uninteresting” code. At that point, they change over the tree depiction of a malware test to a vector and contrast vectors with decide the comparability of malware. The advantages of this are: control tree extraction and examination, however a noteworthy disadvantage of this technique is the concentrated preprocessing which must be done in deciding the weight relegated to each capacity. In [SBN+10], the creators utilized weighted op code succession frequencies to compute the cosine likeness between two PE executable records. These op code arrangements depend on static investigation and have two commitments. One is to dole out a weight to each op code which figures the recurrence with which the op code shows up in an accumulation of malware and amiable programming, then decides a proportion in light of measurements.
Along these lines, they mine the importance of the op code and furthermore get a weight for each op code. The second commitment is [SBN+10] proposes a technique which depends on the op code succession recurrence to process closeness between two executable documents. Their investigation was tried on an accumulation of malware downloaded from Vx-Heavens (http://vx.netlux.org) which originates from 6 malware families. As we would see it, code jumbling is a major test for this strategy. A few creators utilize arrangements of framework calls, API calls and capacity calls of malware to distinguish malevolent practices. Peisert [PBKM07] utilize arrangements of capacity calls to speak to the conduct of a program. Sathyanarayan [SKB08] utilize static examination to concentrate API calls from known malware then develop a mark for a whole class. The API calls of an unclassified specimen of malware can be contrasted and the “signature” API requires a family to decide whether the example has a place with the family or not.
The downside is that muddling of API calls can influence the precision of results. In their paper Sathyanarayan say that they utilized IDA to concentrate API and they tried it on eight families with 126 malware altogether. Programming interface Calls are additionally utilized by [XSCM04, XSML07] to look at polymorphic malware, with their examination did specifically on the PE (compact executable) code. Programming interface calling groupings are developed for both the known infection and the suspicious code. In their technique, they check the entire area of CALL directions for each code segment of a PE record to acquire an arrangement of strings, which stores the names of the called APIs. They then utilized Euclidean separation to play out a similitude estimation between the two groupings after an arrangement realignment operation is performed. Ye [YLJW10] introduce a classifier utilizing post-handling strategies of cooperative grouping in malware location which depends on their past work they called Intelligent Malware Detection System (IMDS). Their technique depends on 26the static examination of API execution calls. Their trial was tried on an expansive accumulation of executable including 35,000 malware and 15,000 clean ware tests, and utilized different information mining strategies which accomplished near 88% accuracy. [WPZL09] presents an infection discovery system in view of distinguishing proof of API call arrangements under the windows condition.
They initially procured API calls from malware records by static examination of the techniques, and afterward set up the arrangement of API calls. The creators pick Bayes calculation as an inexact determinant of an infection centered on fact that the Bayes calculation is a technique used to figure the back likelihood as indicated by earlier likelihood. The machining learning strategy was connected amid that method and the system was a huge endeavor to tackle the win32 infection with low cure rate. A shrewd guideline grouping based malware order framework is introduced in [HYJ09]. It comprises of three incorporated modules: highlight extractor, grouping and mark generator. They utilized the IDA Pro disassembler to extricate the capacity calls from the unloaded malware and a bunching technique was utilized to order. They tried their technique on 2029 malware tests from 408 families and gained near 79% precision over their informational collection.
2.1.1 Goods & Bad of Static Analysis
In this area, I might want to expound on the points of interest and weaknesses of static examination and extraction. Static investigation and extraction of executable documents gives data about the substance and structure of a program, and in this manner are the establishment of malware recognition and arrangement. These have been very much investigated and broadly received because of the accompanying favorable circumstances:
- Low Level Time and Resource Consumption. Amid static investigation, we have no compelling reason to run the malware which is high in both time and asset Consumption. In static examination, the ideal opportunity for dismantling is decidedly proliferated with the size of the code, while the ideal opportunity for element investigation is identified with execution stream, which turns out to be much slower particularly on account of a circle with a great many cycles [Li04].
- Global View. An enormous preferred standpoint of static investigation is that it can break down any conceivable way of execution of an executable. This is as opposed to element investigation, which can just examine a solitary way of execution at any given moment. A static examination has a decent worldwide perspective of the entire executable, covers the entire executable and can make sense of the whole program rationale of the executable without running it [Li04, Oos08].
- Easily Accessible Form. In static examination and extraction, we analyze the dismantling code produced by figuring out programming. The initial step of figuring out programming is as a rule to dismantle the paired code into relating constructing agent directions, and after that gathering these guidelines such that the substance and structure data about the executable, similar to capacities, essential pieces, control stream and information stream, is effectively available [Oos08].
- Stable and Repeatable. Contrasted and dynamic investigation, the dismantling code created amid static examination is moderately steady and consistent, which means is simple for us to apply and test new arrangement calculations or speculations.
- Moreover, the repeatability of the dismantling strategy gives adaptability to static examination and extraction.
- Safety and Data Independent. Once the dismantling data of the first executable records is removed and saved, we don’t have to work the first documents any longer. This implies amid static investigation, the chances of being influenced by malevolent code is lessened to zero. While static examination has its focal points, it likewise has its constraints:
- Limitation of Software Reverse-designing Techniques. Static investigation relies on upon programming figuring out strategies, with the dismantling code of executable followed up on. The creators in [HCS09] say that since generally present day malware projects are composed in abnormal state programming dialects, a minor alteration in source code can prompt a critical change in paired code.
- Susceptible to Inaccuracies Due to Obfuscation and Polymorphic Techniques. Code and information obscurity postures impressive difficulties to static investigation. More robotized muddling apparatuses execute procedures, for example, direction reordering, identical guideline arrangement substitution, and branch reversal. Malware creators can exploit these instruments to effectively produce new malware renditions that are grammatically not the same as, yet semantically proportionate to, the first form.
- Content-based Analysis. Creators in [GAMP+08] contended that in the static investigation strategy, the portrayal of malware concentrates basically on substance based marks, that is to state they speak to the malware in view of the basic data of a document, which is naturally vulnerable to mistakes because of polymorphic and changeable systems. This sort of examination neglects to identify between part/framework associations data which is very essential in malware investigation. In the meantime, it is feasible for malware creators to defeat content-based likeness estimations.
Conservative Approximation. The estimation is a standard static examination strategy, with this system actualized with a couple of approximations which are dependably excessively traditionalist [Sax07]. Moreover, this estimate actually includes a specific loss of exactness [Vig07]. In [MKK07], the creators investigate the impediment of the static examination procedure from the perspective of jumbling innovation. In this paper, they present a code confusion pattern which exhibits that static examination alone is insufficient to either recognize or order malignant code. They recommend that dynamic examination is a 30necessary supplement to static procedures as it is altogether less defenseless against code muddling changes.
In [LLGR10], the creators bring up that dynamic examination of malware is frequently significantly more compelling than static investigation. Observing the conduct of the parallel amid its execution empowers it to gather a profile of the operations performed by the twofold and offers possibly more prominent knowledge into the code itself if jumbling is expelled (e.g., the double is unloaded) over the span of its running. Progressively, more specialists are presently taking a shot at element investigation procedures to enhance the adequacy and exactness of malware recognition and grouping. In the following area, I will present some related element examination and extraction approaches.
2.2 Based on Dynamic Feature Extraction
In [CJK07], Christodorescu contend that it is the conduct of malware that ought to be utilized to order it. Seeing malware as a discovery, they concentrate on its communication with the working framework, along these lines utilizing framework calls as the building squares of their procedure. They contrast these and the framework calls of non-malevolent code with a specific end goal to trim the subsequent chart of conditions between calls. In their technique, behavioral data for each bit of malware must be gathered and a diagram developed for it. Their outcomes depend on an examination of 16 bits of known malware. The creators in [WSD08] utilize dynamic investigation advances to characterize malware by utilizing a controller to oversee execution, with the execution ceased following 10 seconds. At first they figured the similitude between two API call groupings by building a closeness network in light of activity codes (to our understanding activity codes in this paper are really the succession of API calls). The relative recurrence of each capacity call was processed and the Hellinger separation was utilized to show how much data was contained in malware conduct to develop a moment lattice.
At last, two phylogenetic trees were built utilizing the similitude grid and the Hellinger remove lattices independently. They tried this on a little arrangement of 104 malware samples, and as I would see it, their calculation has moderately high time and space complexities. In this paper, the creators don’t say the grouping precision. In [AHSF09], the creators open another plausibility in malware investigation and extraction by proposing a composite technique which removes factual elements from both spatial and fleeting data accessible in run-time API calls. From the perspective of space, spatial elements are by and large measurable properties, for example, means, changes and entropies of address pointers and size parameters.
From the point of view of time, the worldly element is the nth request discrete time Markov chain [CT91] in which each state compares to a specific API call. They utilize 237 center API calls from six distinctive utilitarian classifications and utilize a 10-crease cross approval technique with five standard grouping calculations. The cost of their strategy is awesome as a result of its high computational intricacy, while they chronicled great outcomes with 96.3% order exactness. A novel malware recognition approach is proposed in [KChK+09], with the creators concentrating on host-based malware locators centered on fact that these identifiers have the upside of watching the total arrangement of activities that a malware program performs and it is even conceivable to distinguish vindictive code before it is executed. The creators first investigate a malware program in a controlled situation to manufacture a model that describes its conduct. Such a model depicts the data stream between the framework calls fundamental to the malware’s main goal and afterward separates the program cuts in charge of such data stream. Amid discovery, they execute these cuts to match models against the runtime conduct of an obscure program.
In [ZXZ+10], the creators propose a robotized order technique in view of behavioral examination. They portray malware behavioral profile in a follow report which contains the changed status brought about by the executable and the occasion which is exchanged from comparing Win32 API calls and their parameters. They extricate conduct unit strings as components which reflect behavioral examples of various malware families. At that point, these elements of vector space fill in as contribution to the bolster vector machine (SVM), with and string closeness and data increased used to diminish the measurement of highlight space to enhance framework effectiveness.
2.2.1 Goods & Bad of Dynamic Analysis
Likewise with static investigation, dynamic examination additionally has its focal points and hindrances. Dynamic investigation beats static examination because of the accompanying qualities.
Points of interest:
- Effectiveness and accuracy. Perception of the real execution of a program to decide it is vindictive is a great deal less demanding than inspecting its paired code. Perception can uncover inconspicuous noxious practices which are excessively unpredictable, making it impossible to be recognized utilizing static investigation. Dynamic examination is commonly more exact than static investigation since it works with genuine values in the ideal light of run-time [Net04]. Likewise, dynamic examination is exact centered on fact that no estimation or reflection should be done and the investigation can look at the genuine, correct run-time conduct of the executables [ME03].
- Simplicity. Static investigation is the examination of the source or the accumulated code of an executable without executing it. It comprises of breaking down code and separating structures in the code at various levels of granularity. This is an extremely serious process [Oos08]. As dynamic investigation just considers a solitary execution way, it is frequently substantially easier than static examination [Net04].
- Runtime Behavioral Information. The benefit of element investigation originates from the way that malware executes its own particular planned in usefulness when it is begun and when it is being executed. Amid element investigation, the information gathered, for example, memory assignment, records composed, registry read and composed, and forms made, is more valuable than the information gathered amid static examination. The element runtime data can be straightforwardly utilized as a part of evaluating the potential harm malware can bring about which empowers identification and characterization of new dangers. That is to state dynamic examination can be utilized to test the setting data at run time since most estimations of enlist or memory can as it were be delivered and viewed on the fly [Li04].
- No Unpacking. In element investigation, we execute the malware in a controlled domain. Amid that strategy, malware naturally executes the unloading code then runs its noxious code without fail.
- Robust to Code Obfuscation. Contrasted with static examination, dynamic investigation is more viable in distinguishing jumbled malware essentially centered on fact that the muddled code does not influence the last behavioral data gathered amid the execution. Disregarding the undeniable favorable circumstances of element discovery techniques in distinguishing present day malware, dynamic examination location has its own particular implicit downsides or impediments:
- Limited View of Malware. The time has come expending and unthinkable for us to inspect all the conceivable execution ways and variable qualities amid element investigation, which implies dynamic examination gives a restricted perspective of malware. Static examination gives a review of malware on the grounds that the dismantling code contains all the conceivable execution ways and variable qualities.
- Trace Dependence and Execution Time Period. The fundamental confinement of any element malware examination approach is that it is follow subordinate [BCH+09]. The creator expresses that in element investigation, examination results are just in view of malware conduct amid (at least one) particular execution runs. Sadly, some of malware’s conduct might be activated just under particular conditions. Likewise, the creator gives three cases to outline its confinement. A straightforward illustration is a period bomb, which is trigger-based and just displays its malignant conduct on a particular date. Another illustration is a bot that lone performs noxious activities when it gets particular orders through a charge and control channel. What’s more, the era in which malignant practices are gathered in element investigation is another constraint. It is conceivable that specific practices won’t be seen inside this period because of time-ward or deferred exercises [BOA+07].
- Lack of Interactive Behavior Information. Since we run malware consequently without human collaboration, intelligent practices, for example, giving information or signing into particular sites, is not performed amid element investigation which limits the show of further malignant practices [BCH+09].
- Time and Resource Consumption. Dynamic examination includes running malware in a controlled domain for a particular time or until the execution is done. It is a tedious assignment when we are confronted with the test to break down immense measures of malware documents discharged each day. Also, running malware involves an abnormal state PC framework and system assets [KK10].
Limitation of VM Environment and Detection Inaccuracy. The virtual machine condition in which malware is executed is generally repetitive and enduring contrasted and the genuine runtime condition, which likewise confines the show of further malignant practices. Also, dynamic examination identification about genuine usefulness of the broke down malware record can be off base. [KK10].
2.3 Based on Machine Learning Classification
Another center issue in malware identification and order is the selection of components for arrangement basic leadership. This undertaking includes the accompanying viewpoints:
- Selecting appropriate order calculations.
- Generalizing arrangement forms in light of the capabilities got in malware examination and extraction.
- Evaluating the execution of framework.
As I specified in Section 2.1, the fundamental downside of a mark based discovery framework is that it can’t recognize obscure malware. Machine learning is equipped for summing up on obscure information, and in this way can be a potential and promising approach for recognizing malware. With a specific end goal to identify obscure malware, an ever increasing number of analysts are handing their consideration over acquiring a type of speculation in malware location and order by utilizing machine learning systems. Machine Learning is characterized by Ethem Alpaydin in [Alp04] as: “Machine Learning is modifying PCs to streamline an execution paradigm utilizing illustration information or past experience.”
In [Nil96], the creator brings up that, similar to zoologists and analysts who think about learning in people and creatures, Artificial Intelligence scientists concentrate on learning in machines. The center thought of machine learning is speculation. At the end of the day, machine learning is utilized to sum up past the known information gave amid the preparation expression to new information displayed at the season of testing. Machine learning is an exceptionally open and handy field and it is extensively connected in many fields, including Expert System, Cognition Simulation, Network Information Service, Image Reorganization, Fault Diagnose, apply autonomy, and machine interpretation. [Sti10] calls attention to that from a machine learning point of view, mark construct malware recognition is situated in light of a forecast model where no speculation exists, that is to state that no discovery past the known malware can be performed.
As we said above, machine learning is fit for summing up on obscure information, in this way, can be utilized as a part of a malware discovery framework. In the present writing, numerous distributions apply information mining and machine learning arrangement basic leadership systems [AACKS04, MSF+08, SMEG09, CJK07, SEZS01, SXCM04, WDF+03, HJ06]. Machine learning calculations utilized as a part of this territory incorporate affiliation classifiers, bolster vector machines, choice tree, irregular woodland and Naive Bayes. There have additionally been a few activities in programmed malware order utilizing bunching procedures [KM04].
The creators in [SEZS01] initially present applying machine learning procedures in the location of malware. They remove highlights from various parts of malware, including the program header, string, byte arrangement and four classifiers connected in their work, including the mark based strategy, Ripper which is a rule based learner, Na¨ıve Bayes and Multi-Na¨ıve Bayes. [SEZS01] found that machine learning strategies are more precise and more compelling than mark based techniques. In [AACKS04], the creators connected the Common N-Gram investigation (CNG) strategy which was effectively utilized as a part of test grouping examination in the recognition of malignant code. They received machine learning systems in light of byte n-gram examination in the recognition of vindictive code. 65 particular Windows executable documents (25 noxious code, and 40 considerate code) were tried and their technique accomplished 100% exactness on preparing information, and 98% precision in 3-overlap cross approval.
In [KM04], the creators connected machine learning procedures in view of data recovery and content grouping in identifying obscure malware in nature. Subsequent to assessing an assortment of inductive arrangement techniques, including Naıve Bayes, choice trees, bolster vector machines, and boosting, their outcomes proposed that supported choice trees outflanked different strategies with a territory under the ROC bend of 0.996. The creators in [KM06] developed their past work [KM04] by giving three commitments. In the first place they demonstrate to utilize built up information mining strategies for content arrangement to identify and order malevolent executable.
Also, they exhibit experimental outcomes from a broad investigation of inductive machine learning strategies for identifying and characterizing malevolent executable in nature. At last they demonstrate that their machine learning based techniques accomplished high location rates, even on totally new, beforehand concealed malevolent executable. In [HJ06], the creators express that more broad components ought to be used in malware location since marks are over fitted. They exhibit a n-gram based information mining approach and assess their machine learning technique by utilizing 4 classifiers, including ID3 and J48 choice trees, Na¨ıve Bayes and the SMO. In [MSF+08], they utilized four regularly utilized grouping calculations, including Artificial Neural Networks (ANN), Decision Trees, Na¨ıve Bayes, and Support Vector Machines.
In [Sti10], they researched the pertinence of machine learning strategies for distinguishing infections in genuine tainted DOS executable records when utilizing the n-gram portrayal. Despite the fact that, the creator expresses that identifying infections in genuine contaminated executable records with machine learning strategies is almost incomprehensible in the n-gram portrayal. In any case, the creator sees that learning calculations for successive information could be a compelling methodology, and another promising methodology is take in the practices of malware by machine learning strategies.
In [Kel11], the creator examined the utilization of a determination of machine learning strategies in malware location. In [Kel11], the creator expresses that we require a proactive approach not a responsive approach, which implies malware ought to be recognized before their marks are known and before they have an opportunity to do harm. The preparatory outcomes from their venture underpins the possibility that AI methods can undoubtedly be connected to the recognition of concealed malevolent code with a list of capabilities got from Win32 API calls, and the outcomes additionally give proof to the prevalence of a few strategies over others.
2.4 Proposed Method
As I said in Section 2.2 , the two center issues of malware discovery and grouping is appropriate portrayal of malware and the decision of instrument for ideal order basic leadership. The principal issue of portrayal of malware relies on upon the malware investigation and extraction approaches. The second issue of basic leadership instruments is identified with the decision of order calculations, the speculation of grouping procedures and the assessment of execution. My framework plans to develop a powerful, adaptable and generalizable malware recognition and grouping framework. When all is said in done, this framework ought to have the accompanying qualities:
- Malware examination and extraction ought to be founded on basic and successful capabilities.
- These capabilities ought to be effectively removed, connected and joined.
- These capabilities ought to display malware from various perspectives all together to secure malware in a general path as precisely as could be expected under the circumstances.
- These components ought to be sufficiently strong against the development of malware.
- The malware characterization process ought to be generalizable.
- There ought to be a powerful assessment of execution.
- Given the above elements and the two center issues that I say above, we set up our malware recognition and order framework. I give a concise depiction of it in the accompanying two areas.
2.4.1 Integrated Analysis & Extraction Approach
We begin our framework by utilizing static examination and extraction approaches. In static examination, we break down and remove straightforward and viable components from executable records, including Function Length Frequency (FLF), and Printable String Information (PSI). We can’t exclusively depend on one single approach, so in this manner we present element examination and extraction approaches into our framework. The greater part of the elements from both static and element investigation are basic, can be effortlessly separated and are appropriate to apply to both little and huge informational collections. We can acquire work length data by executing a few database stockpiling systems and capacities, and we can undoubtedly bring printable string data from our table strings window (see Section 3.4 in Chapter 3). These elements can be effectively consolidated and connected to a substantial informational collection and they additionally display malware from a few unique perspectives. Likewise, as we will show from our test brings about Chapters 4, 5, 6, 7, and 8, these components are successful and sufficiently powerful against the development of malware.
As all techniques have their qualities and shortcomings, dynamic examination does not plan to supplant static investigation but rather provides an extra layer of intelligence. Static and element investigation ought to supplement the benefits of each other. The creator in [ME03] notices that scientists need to grow new explanatory techniques that supplement existing ones, and all the more vitally, specialists need to eradicate the limits amongst static and element examination and make bound together investigations that can work in either mode, or in a mode that mixes the qualities of both approaches. Our proposed technique means to assemble a strong framework which coordinates dynamic examination and static investigation approaches. This permits the blend of their points of interest and limits their flaws. In our framework, static examination utilizes double code investigation to analyze the code which the malware is included and extricate static components to catch the capacities of the malware without really executing it.
Dynamic investigation gives a strategy to acquiring abnormal state, ongoing conduct of an executable, which includes running the executable in a virtual machine condition. We then union both static and element highlights into a more extensive element which is connected into our machine learning based grouping basic leadership system. At the season of composing this proposition there was an absence of incorporated malware discovery and grouping stages which incorporate reciprocal static and element examination so as to achieve high and powerful characterization exactness. Such a coordinated stage is an essential commitment of this postulation. Keeping in mind the end goal to assess the heartiness and versatility of our framework, the malware executable documents that we research extend cross an 8-year traverse, from 2003 to 2010.
2.4.2 Classification
As I specified in Section 2.2.5, information mining and machine learning methodologies are connected as an order basic leadership component in malware discovery and grouping so as to sum up the arrangement procedure, and in this manner, to recognize obscure malware. In Section 3.6 of Chapter 3, I will give a nitty gritty depiction of machine learning and information mining procedures connected in our framework. In this area, I will present four grouping calculations connected in our framework: bolster vector machine (SVM), choice tree (DT), arbitrary timberland (RF) and occurrence based (IB1), alongside boosting strategies.
These calculations speak to the range of significant characterization methods accessible, in view of varying ways to deal with the order. Great characterization exactness got over these calculations bolsters our claim of a hearty philosophy. Keeping in mind the end goal to evaluate the summed up precision, K-crease cross approval is connected centered on fact that it is the most prevalent and broadly utilized way to deal with measure how the consequences of a factual investigation will be generalizable to a free informational index.
2.4.3 Summary
This section has introduced a writing audit identified with my exploration. In light of the issue depiction of conventional techniques utilized by the counter infection industry, I proposed the two center issues of malware recognition and grouping. Taking after this, the present static and element strategies were displayed and I investigated and expressed the benefits and constraints of both static and element approaches. I additionally proposed our incorporated strategy and proposed our theories alongside the focused on order exactness of our framework.
3 PROBLEM FORMULATION
Classification is a typical information mining system built on device learning. Fundamentally classification is used to categorize each piece in a set of data into one of previous pre-defined set of modules or groups. Here, we are focusing on Neural Networks Classification Method. Our approach to solve this method is divided in various phases. We will have an input executable file
- First, the file will be disassembled in standard assembly code.
- Using a pre-processor, unnecessary instructions will be removed from the assembly code.
- From this assembly code which is clean, we will extract Control Flow Graph.
- Virus signature will then be searched on that graph.
Finally, in the decision phase Neural Network Classification Algorithm will be applied on the dataset and after matching the file with the dataset it will be determined whether the file has malware or not. The general system of our proposed methodology is sketched out in Fig. 1. This methodology is made out of a few stages.
To begin with, the framework dismantles the file to a typical assembly cryptogram and after that concentrates the CFG from it. A CFG (Control Flow Graph) is a joined and coordinated diagram comprising of an arrangement of vertices that relate to the streaks of assembly code, and an arrangement of coordinated edges that compare to the execution grouping of choice making tasks (e.g., typical succession, restrictive bounce, unlimited hop, capacity call and return direction).
Secondly, framework starts to create the CFG with termed API’s. This basic CFG now will swing out to API approaches CFG which we request API-CFG. Lastly, framework matches file with dataset to settle on a choice, whether the file is malevolent or not.
3.1 Overall Perspective
Our methodology comprises of three main parts, CFG generator, detection module and File disassembler which are represented in Fig. 1. Initially, the assembly code of data file is produced. Then, the additional guidelines are expelled from the muster code by a function of a tool called IDA. In this way, the CFG is prepared by this clean code. The edges are associated with an API that is approached such explanations of assembly code. Since performing an arrangement calculation on these charts is mind boggling and takes critical time, the neural net classification is performed on the dataset. The module utilizes this erudition model to understand the info record is malovalent or favorable. In the accompanying parts of this segment, these stages are depicted by subtle element.
3.2 CFG Construction
A control stream diagram or control flow diagram (CFG) in software engineering is a representation, utilizing graph documentation, of all conducts that may be steered through a structure and its execution. The CFG is because of Frances E. Allen, who noticed that Reese T. Prosser utilized Boolean availability networks for stream examination some time recently. The CFG is vital to numerous compiler advancements and static investigation apparatuses. In CFG every node in the diagram speaks to a fundamental square, i.e. a straight-line bit of code with no bounced or hop targets; hop targets begin a piece, and hops end a square.
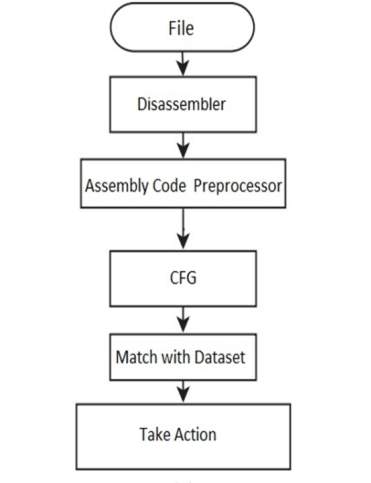
Fig 3.1: Phases during virus detection.
Coordinated edges are utilized to speak to hops in the control stream. There are, in many presentations, two extraordinarily assigned hinders: the passage obstruct, over which mechanism goes into the stream diagram, and the technique ready piece, over which all mechanism stream takes off. The principle some portion of this study is centered on these stages. Files are dis-assembled by a software IDA. The dis-assembler is intended to be anything but difficult to utilize contrasted and different disassemblers. To that end, a percentage of the usefulness found in different items has been forgotten so as to keep the procedure basic and quick. While as intense as the more costly, committed disassemblers. This disintegrator backs most well-known Intel x-86 guideline collections and augmentations, for example, MMX, SSE3. Figure 2 shows types of control graphs, when a record is opened with IDA, the Unpacker module recognizes whether the document is pressed, and after that the information record will be unloaded naturally.
The Unpacker module takes a shot at stuffed malware executable and can deal with a document. This system frequently is utilized by malware creators to make unloading and figuring out harder. This software can’t dismantle an arrangement of some files consequently; thus, in that case client must do files one by one. Subsequently, we can dismantle an arrangement of files naturally. The pre-handling steps the vital directions are endured and the others are expelled from gathering information document is malware or not. The essential directions are as taking after: hop guidelines, technique invokes, API and all streaks which are focused of bounce directions. Afterwards, control stream chart (CFG) is developed with these directions.
As said before, the apexes of CFG are shaped by hop directions, methodology calls and bounce targets. The boundaries of CFG are made by associations between every two gathering articulation. For instance, a contingent bounce has two associations with next articulation and the hop target proclamation.
In this way, in CFG, this hub (vertex) has two edges that indicate next explanation and bounce target proclamation. At the point when the CFG is developed, it is navigated and put the associated API-Id on its boundaries, and after that CFG is achieved.
Fig 3.2: Types of CFG’s
3.3 Selecting Suitable Elements
As we all know that graph isomorphism is a surely understood NP-complete problem, so we have utilized a pleasant file size that can be processed in shorter amount of time. The files for which a CFG is extracted have been searched by mining the CFG. Every CFG is matched with the classified data set that decides whether the file is malware or not. The utilizing so as to learn model is built a classifier applying on dataset. This process leads to mining the graph on which we have focused so far.
3.4 Data Preparation
As we all know that graph isomorphism is a surely understood NP-complete problem, so we have utilized a pleasant file size that can be processed in shorter amount of time. The files for which a CFG is extracted have been searched by mining the CFG. Every CFG is matched with the classified data set that decides whether the file is malware or not. The utilizing so as to learn model is built a classifier applying on dataset. This process leads to mining the graph on which we have focused so far. At the pre-handling stage the vital directions are persisted and the rest are expelled from gathering information document is malware or not. The essential directions are as taking after: hop guidelines, technique invokes, API and all streaks which are focused of bounce directions. After that, control stream chart (CFG) is developed with these directions. As said before, the vertices of CFG are shaped by hop directions, methodology calls and bounce targets. The boundaries of CFG are made by associations between every two gathering articulation.
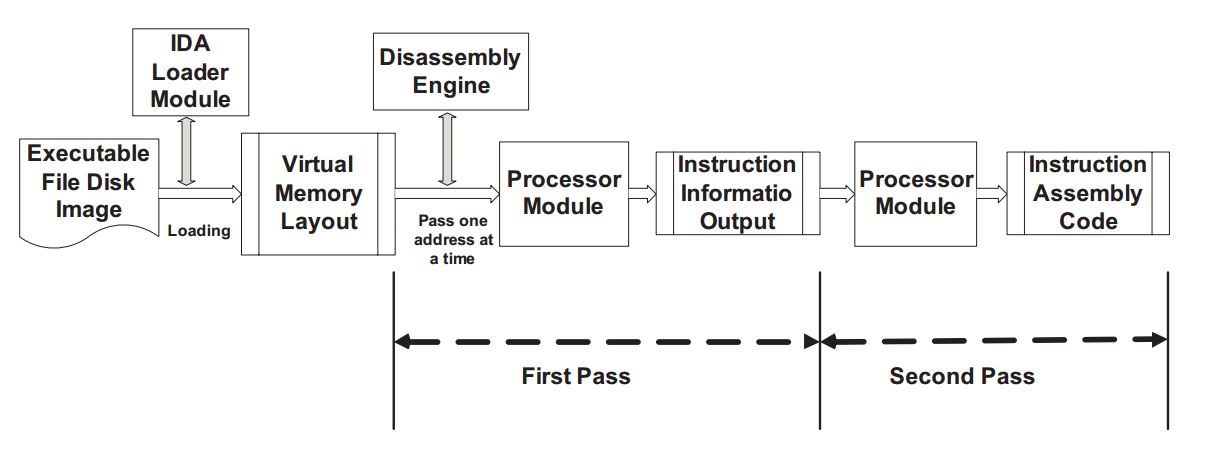
Fig 3.3: IDA Dismantling Process
Three fundamental parts of IDA Pro, including loader module, dismantling motor and processor module, assume the vital part in the dismantling procedure. IDA loader modules act much as working framework loaders carry on. There are three sorts of loader modules in IDA Pro:
- Windows-PE loader. Used to load Window PE records.
- MSD EXE loader. Used to load MSD EXE records.
- Binary File. Default for stacking records that are not perceived by perusing header structure in the plate picture of the dissected document.
When you have picked a record to dissect, the chose loader module begins to stack the document from circle, parse any document header data that it might perceive, make different program segments containing either code or information as determined in the document header, distinguish particular section focuses into the code. Such that the chose loader module decides a virtual memory design for the circle picture of the investigated record and after that the chose loader module returns control to IDA. Once the stacking has completed, the dismantling motor assumes control and starts to pass address from the virtual memory design to the chose processor module one by one.
Much of the time, IDA picks the best possible processor module in view of the data that it peruses from the executable document’s headers or you can relegate an appropriate processor sort before IDA begins to dissect the record. It takes processor module two goes to wrap up the get together code for the investigated document. In the main pass, the procedure module decides the sort and length of direction situated at that address and the areas at which execution can proceed from that address. In such a way, IDA distinguishes every one of the guidelines in the record. In the second pass, processor module creates get together code for every guideline at each address.
3.5 IDA
Capacities are recognized by IDA through the examination of locations that are focuses of call guidelines. IDA plays out a definite investigation of the conduct of the stack pointer enroll to comprehend the development of the capacity’s stack outline. Stack casings are pieces of memory, dispensed inside a program’s runtime stack and committed to a particular summon of a capacity [Eag08]. In light of the examination of the format of capacity’s stack outline, IDA distinguishes each capacity. We realize that in abnormal state programming, software engineers ordinarily amass executables articulations into capacity units, including systems, subroutines or techniques, which play out a specific assignment as characterized by the developers. So work units are dependably the premise when individuals do abnormal state program examination. An IDA capacity is basically an autonomous bit of code distinguished all things considered by IDA and it is not really a capacity unit. However IDA is an all-around characterized system that maps abnormal state programming develops into their untidy, get together code reciprocals. So we expect that IDA capacities have very comparative attributes as utilitarian unit, then we pick IDA works as the premise of our static examination and extraction.
3.5.1 Extract Function Length Information
The initial step that we have to do is to bring information data of each capacity for an executable document from our ida2DBMS schema. Figure 3.4 depicts five tables required in the arrangement of the capacity information data. These five tables are Instructions, Basic Blocks, Functions, Modules and Function Length. From this figure we can see that an IDA capacity is made out of numerous essential pieces; and every fundamental square is made out of guidelines. Every one of the guidelines and all the essential hinders that have a place with a capacity are navigated and assembled them to frame the information of the capacity.
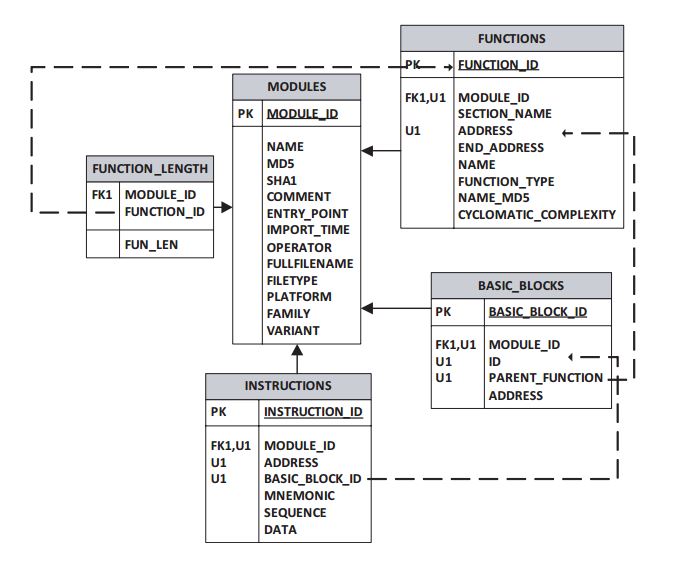
Fig 3.4: IDA Function Data
To get work length data, I program the accompanying four database works or put away techniques to bring capacity length data from the database:
- GetBasicblockData. A database work used to bring all the direction data to shape information data for a particular essential square.
- GetFunData. A database work used to get all the fundamental square information data to frame information data for a particular capacity.
- GetFileData. A database stockpiling strategy used to concentrate work length data for every one of the elements of an executable document and store this data in database.
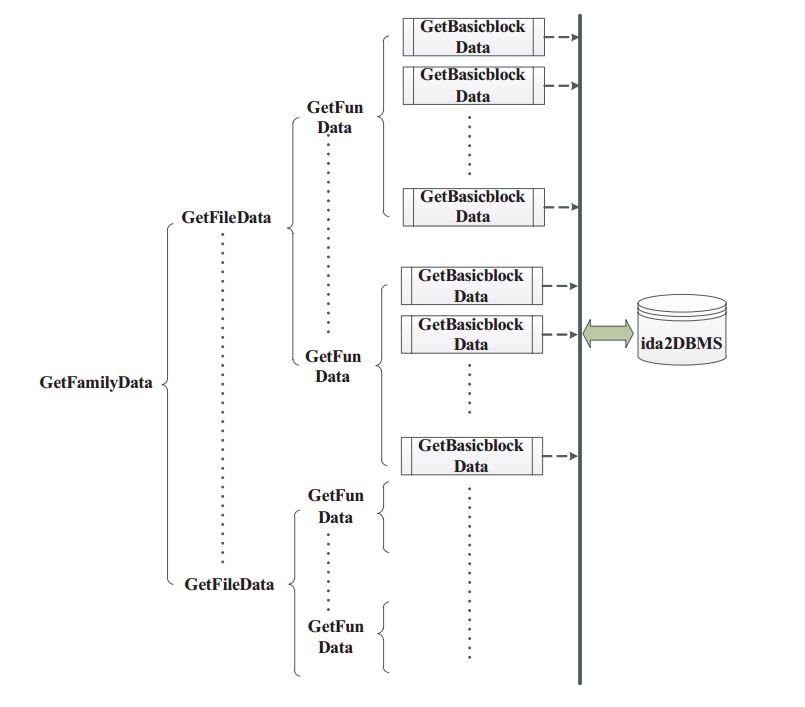
Fig 3.5: Related Database Programs
- GetFamilyData. A database stockpiling system used to concentrate work length data for all the executable records of an allocated family. Figure 3.5 outlines the calling connection between these four database programs.
The center program of these four projects is “GetFunData”. To concentrate work length data, we have to produce information data for each capacity by execute “GetFunData”. Figure 3.6 portrays the way toward creating of information data for each capacity. For each capacity in the dismantling module of a particular executable record, first we have to get all the fundamental pieces having a place with that capacity; and afterward distinguish and Fetch work information.
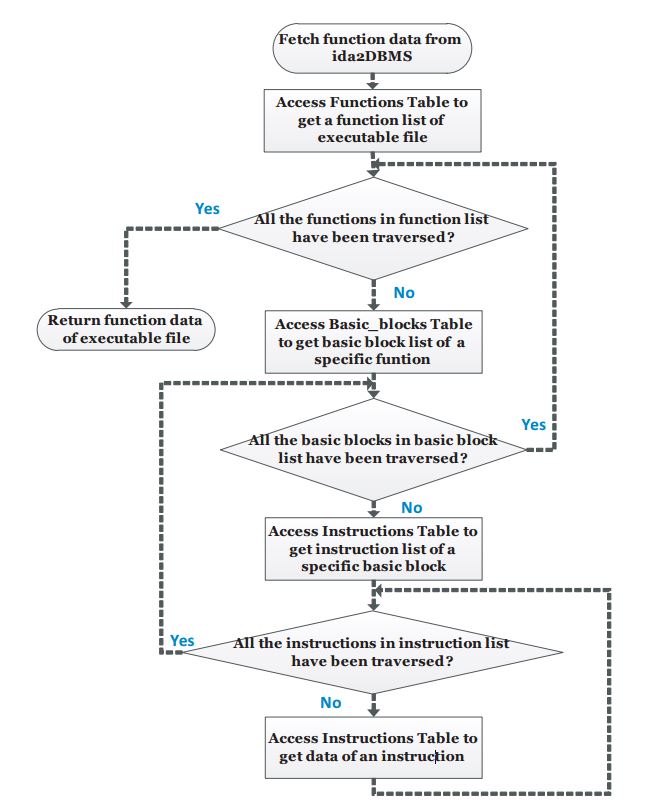
Fig 3.6: Work Fetch
In the underlying stages we extricated work length data from our ida2DBMS catalogue pattern. For each malware executable record we built a rundown containing the length (in bytes) for every one of the capacities. We then sorted the rundown from the most brief length capacity to the longest, and diagramed it. We call this the capacity length design. Figure 3.7 outlines three examples from the Robzips family and Figure 3.8 shows three specimens from the Robknot family.
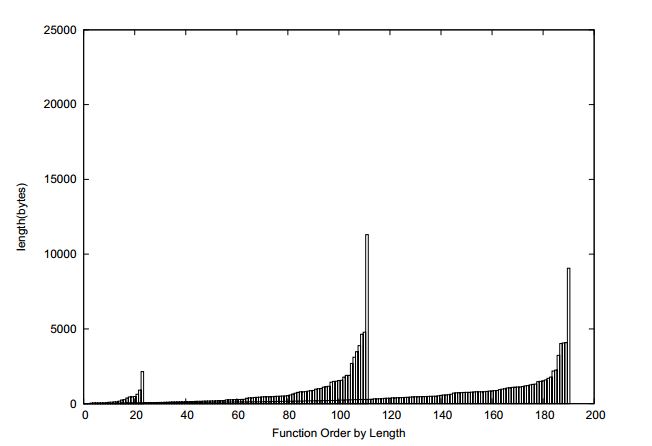
Fig 3.7: Work Length Pattern Samples from Robzips Family
To some extent malware executable from inside the same malware family, we saw that despite the fact that the quantity of capacities and their lengths fluctuated, the state of the capacity length design appeared to be comparable. The executable from various families have distinctive examples. This propelled us to explore whether work length contains factually huge data for arranging malware. The unloading preprocess specified in Section 3.3 of Chapter 3 may not deliver the first paired. Furthermore, when IDA dismantles unloaded malware, it recognizes capacities as indicated by its own particular auto-investigation strategy. The capacities at last separated might be not the same as those returned by the malware programmer.
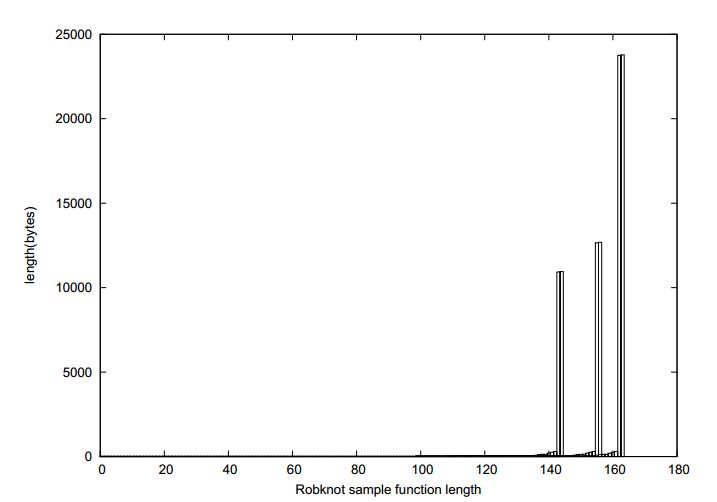
Fig 3.8: Work Length Pattern Samples from Robzips Family
Although it is hard to be exact as to precisely what is implied by a capacity with regards to our analyses, we are by the by utilizing a solid and repeatable process. In our tests, work length is characterized to be the quantity of bytes in the capacity as characterized by IDA. The capacity length design vectors are the crude info given to our tests. A case work length vector, taken from the Be-ovens family (All vectors and sets alluded to in this paper are requested). Each segment in this vector speaks to the length of a capacity in the case. There are 12 works in the specimen the most extreme capacity length is 1380.
3.5.2 Test Dataset
When we first do work length based investigation, we utilize 721 documents from 7 groups of Trojans. Table 3.1 records the families in this analysis. In this trial our point is to explore whether work length contain factually essential data for characterizing malware. So we begin with a generally little test dataset gathered over a 4-year traverse which is from 2003 to 2007. Family Detection Date: No. of Samples
Table 3.1: Test Set of Malware Files
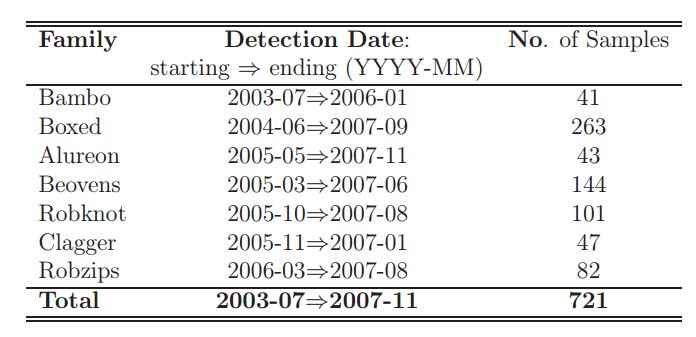
3.5.3 Overview of Experimental Process
Figure 3.9 gives a diagram of our capacity length based tests. The crude capacity length vectors are of various sizes so are not straightforwardly practically identical. We attempt two diverse ways to deal with making vectors of institutionalized size. The first is to number the recurrence of elements of various lengths (depicted in Section 3.5), the other is to institutionalize the capacity length vectors to be of a similar size and scale so that the examples could be analyzed (portrayed in Section 3.4).
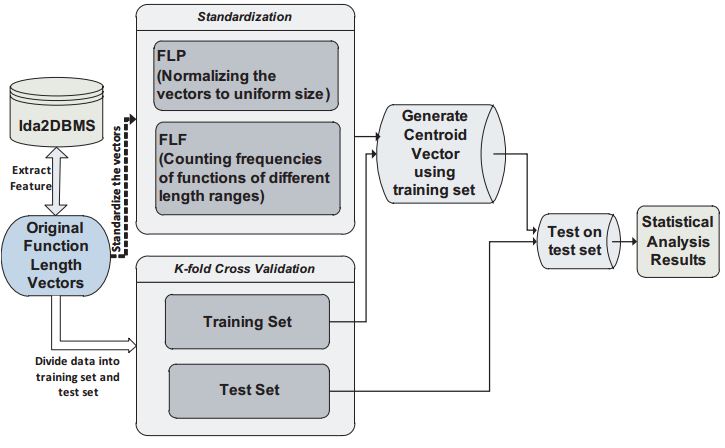
Fig 3.9: Review of Our Investigational Process.
Figure 3.9 is the outline of these two investigations. So as to decide if work length data can be utilized as a part of arrangement, we pick, in each test and for every family, an objective vector, which we call a “centroid” and decide how shut each specimen is to this centroid. For a decent decision of the centroid, we expect tests in the family to be shut in a deliberately characterized factual way, and we expect tests not in the family to be far. We utilize K-crease cross approval in each test. For every family we arbitrarily segment the vectors into 5 subsets of roughly equivalent size.
We utilize one subset as the test set, and join the other 4 subsets as the preparation set. We utilize the preparation set to align the test and approve the adequacy of the centroids against the test set. This is rehashed 5 times, so that every vector is utilized as a test. Our grouping utilizes an adjustment of the system depicted by [SKB08]. For each preparation set we compute a centroid vector. We utilize factual techniques to decide if a test vector is adequately near the centroid vector to be arranged as having a place with that family.
3.6 Overview of Classification Process
We have used the Rapid Miner tool for the purpose of classification, the figure 3.10 below shows the Neural Network generated by the Deep Learning technique. The major dissimilarity between neural net and the deep learning is that the deep learning has more number of hidden layers. We have three hidden layers in our approach.
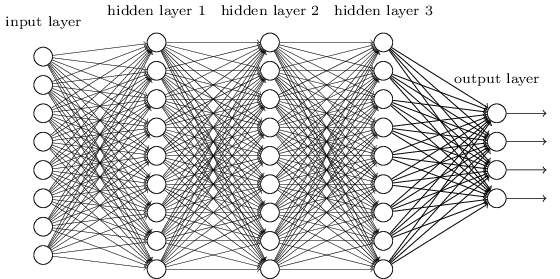
Fig 3.10: Deep Neural Network.
Fig 3.11: Training & Validation.
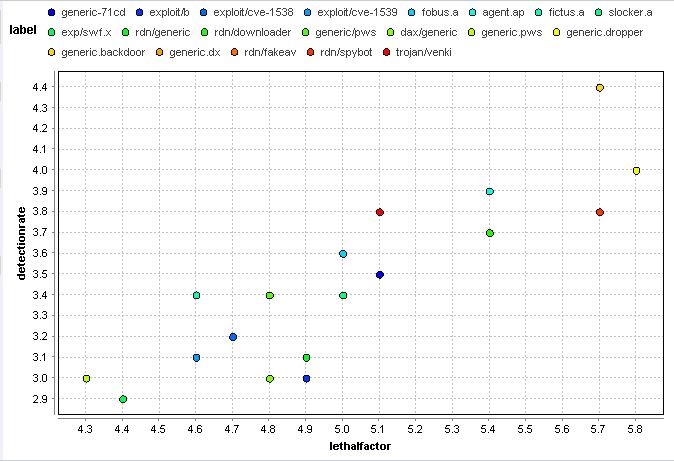
Fig 3.12: Detection Rate & Lethal Factor.
Fig 3.13: Confusion Matrix Graph.
We have used three hidden layers for deep learning. Use of more layers may impact the performance of the model. Figure 3.11 illustrated our training and validation setup in Rapid Miner.
Figure 3.12 shows the detection rate and various lethal factors based on the data set that we have used. A confusion matrix is a table that is frequently used to portray the execution of an arrangement model (or “classifier”) on an arrangement of test information for which the genuine qualities are known. Figure 3.13 shows the confusion matrix graph for our classifier. The confusion matrix itself is moderately easy to see, yet the related phrasing can befuddle.
3.7 UML Diagrams
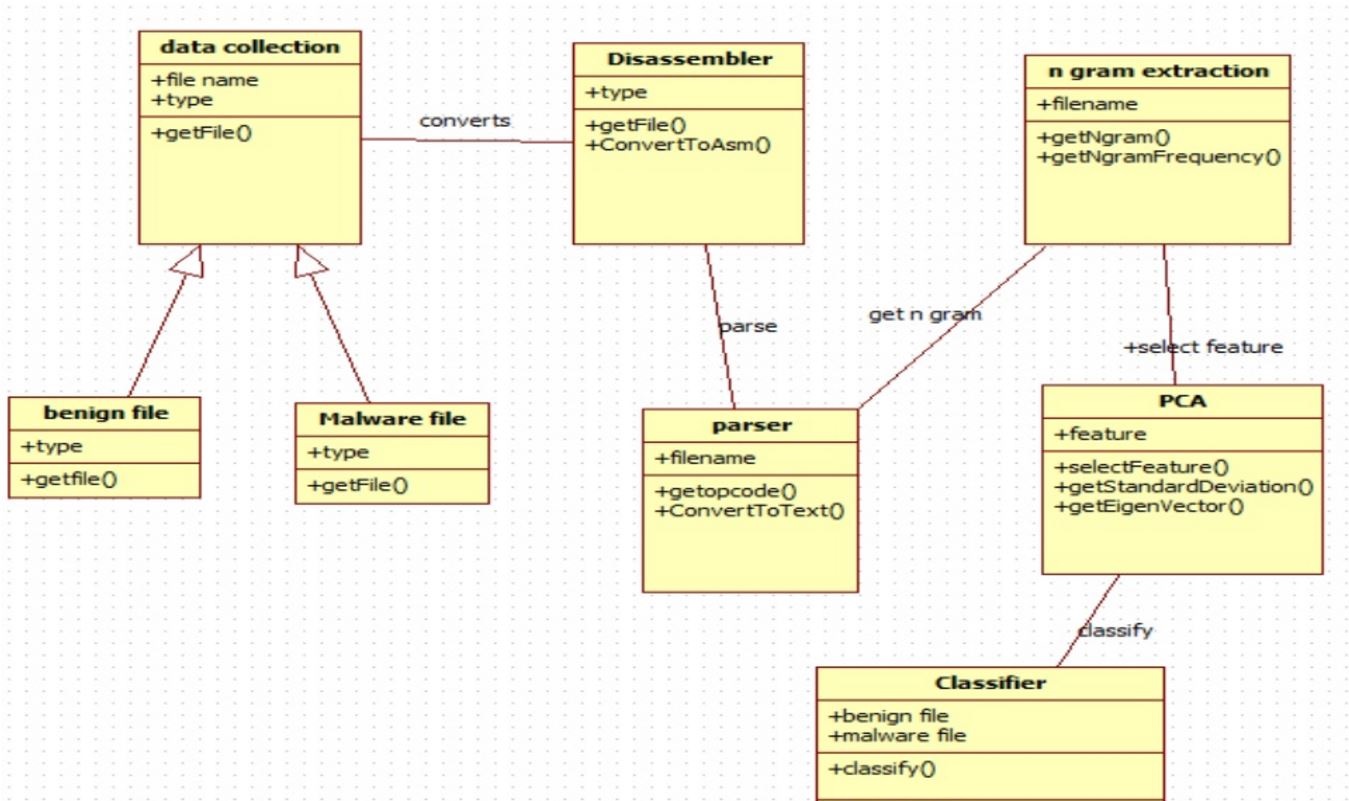
Fig 3.14: Class Diagram.
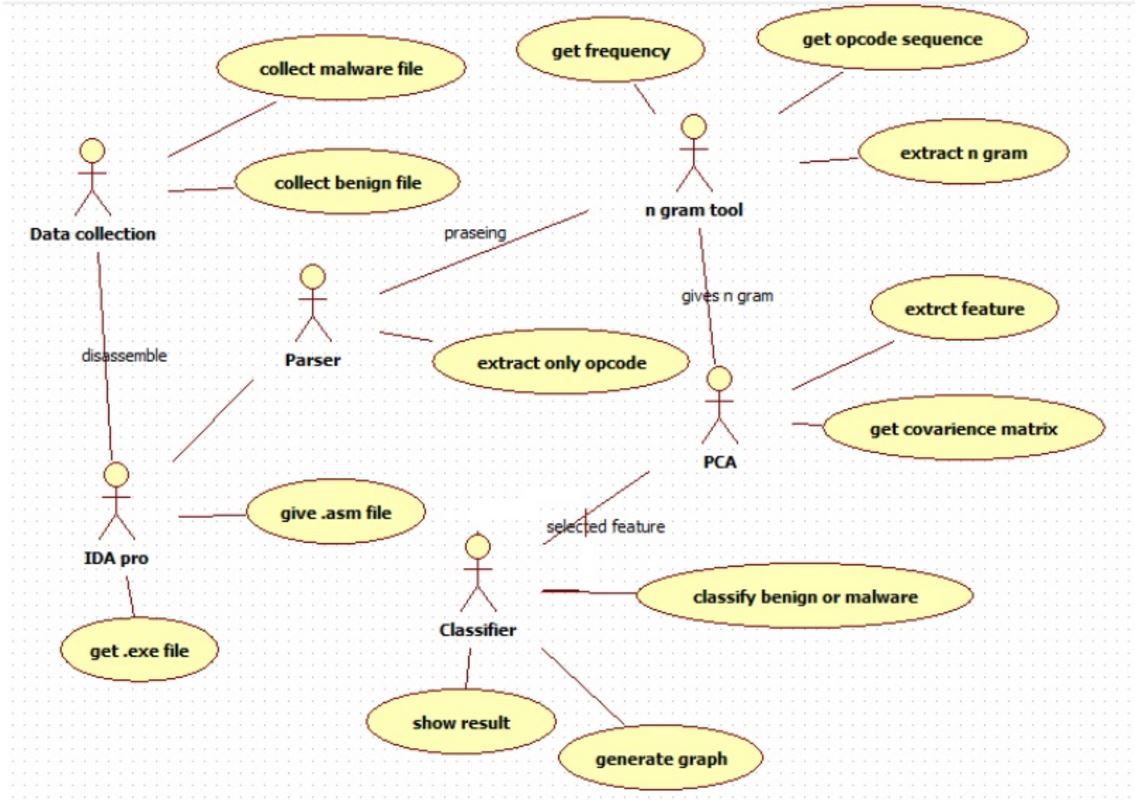
Fig 3.14: Use Case Diagram.
3.8 Sample Code



4 RESULTS & DISCUSSION
We used the malware dataset on which we applied the neural network classification. Figure 3.10 & 3.11 shows the output of the applied deep neural network classification. Figure 3.12 shows the lethal factor. There is no customary and substantial yardstick for system examination in the writing, and each exploratory article reflects the malware exploration, treats with its own datasets attempting to actualize distinctive techniques on their evaluation. Figure 3.13 show the confusion matrix and shows the multinomial model matrix which has highest hit ratio of 95% as shown for top 20 id’s. Since the n-gram techniques need parameter determination, before we contrast this methodology and our methodology, the parameter choice is no more.
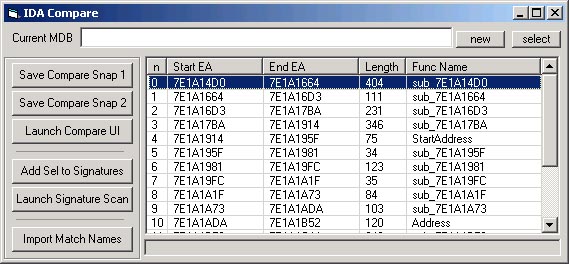
Fig 4.1: Comparison of Instructions.
Then again, in the displayed tactic parameter wants be set. This stricture setting is ended in same part moreover. The vast majority of malwares mean to contaminate file; accordingly, this fixated study concentrates on files and dissecting malware that taint them. Numerous specialists, in this field, utilized an unprovoked dataset as a part of their tests in which the quantity of malwares is substantially more than the quantity of kind records. In any case, this supposition does not remain in this present reality space, for example in figure 4.1 comparison of two files based on their start & end EA’s are shown, where the quantities of malignant parallels are at most as much as that of favorable documents.
Plainly, it can be reason that those strategies, in which we have a lot of malevolent parallels contrasted with the benevolent ones, would give better precision. We characterize “Proportion of Detection” as the rate of entire files named “malware”. CFG search is used by a choice module to decide a file is malevolent or not.
From these outcomes in Table 4.1 and Table 4.2 , we can see that the estimations of order precision are all more than 9% including Naive Bayes which plays out the most exceedingly bad. What’s more, for the weighted normal grouping comes about, every one of the qualities are more than 95% with the exception of Naive Bayes. Our PSI test comes about demonstrate that string data can be utilized to accomplish high order exactness for the scope of techniques we tried. This is proof that strings are an intense element for malware grouping. Accordingly this analysis checks again the proposed in Section 2.4 in Chapter 2: It is conceivable to discover static components which are viable in malware identification and characterization.
Moreover, maybe shockingly, a significant number of the strings utilized for arranging originated from library code (as opposed to the malignant code itself). This recommends string data can be utilized to recognize which libraries the projects utilized. We think the reason of terrible execution of Naive Bayes in our investigations is the impediment of the order calculation.
As I said in Section 3.6 of Chapter 3, Naive Bayesian classifiers depend on the presumption that every one of the traits of the class are restrictively autonomous so the presence (or nonappearance) of a specific property of a class is irrelevant to the nearness (or nonattendance) of some other quality. They consider the greater part of the credits to freely add to the likelihood rundown of characterization which may not be the situation for our information. Brings about Table 4.1 and Table 4.2 check this speculation. In those analyses, Naive Bayes gives the weakest outcomes and Neural Networks proves to be superior.
4.1 Experimental Results
At that point creates the preparation set T and test set Q and believers both sets into Rapid Miner information design. We pass preparing set T to the Rapid Miner library to prepare the classifiers and afterward test the viability with test set Q. Our program is composed such that the framework can choose the families and the relating classifiers as indicated by our necessities as opposed to the default in Rapid Miner. Also, in this experiment we apply 5-layer deep learning neural network in all cases. We then utilize similar Equations to assess the execution of our framework. Table 4.1 and Table 4.2 give the outcomes. Also, Figure 4.2 contrasts the characterization precision and without boosting for these five grouping calculations.
4.2 Analysis
The third expression “Grouping and Performance assessment” is to do order utilizing machine learning machine based strategy and to assess the execution of the framework. We fabricated a program interface to Rapid Miner to do characterization. The program peruses from the idb2CSV database to gather the information for preprocessing, highlight extraction and highlight determination.
Table 4.1: Normal Family Categorization Results
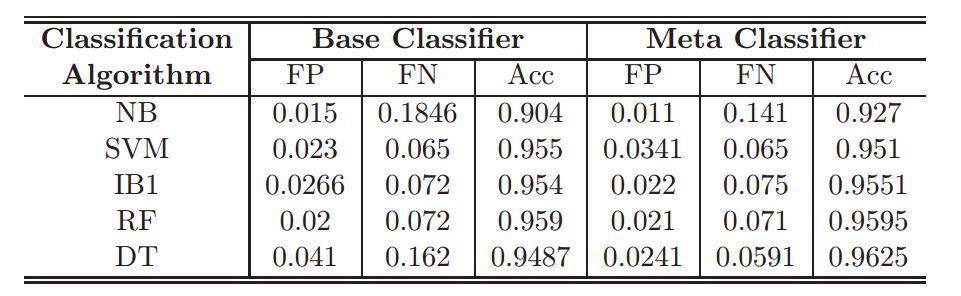
Table 4.1 presents the normal of the trial comes about as indicated by classifier. Na¨ıve Bayes gives the weakest outcomes, while alternate calculations contrast exceptionally well and each other. The meta-classifier AdaBoostM1 enhances all classifiers, except for SVM, yet the distinction is irrelevant. In light of these outcomes, the best exactness rate is over 96% (AdaBoostM1 with DT). Since not all families were of a similar size, we likewise figured a weighted average, where every family was weighted by the quantity of modules in family Fi, and nT is the aggregate number of executable documents (over all families).
Table 4.2: Weighted Regular Family Categorization Results
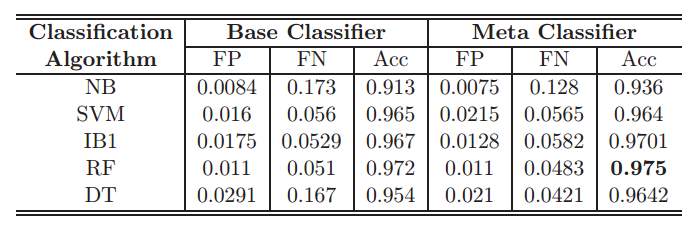
The weighted normal outcomes are appeared in Table 4.2. For all parameters, the weighted outcomes are superior to the non-weighted outcomes. The Random Forest and IB1 classifiers both achiever exactness’s over 97%. Irregular Forest has the best outcomes generally speaking. Once more, AdaBoostM1 enhances all classifiers except for SVM, however the distinction is unimportant. The best exactness rate subsequent to figuring the weighted normal is 96 % (AdaBoostM1) As I said in Section 5.4.2, we present clean ware in this test. Table 4.3 records the order consequences of malware versus clean ware by taking clean ware as a different family.
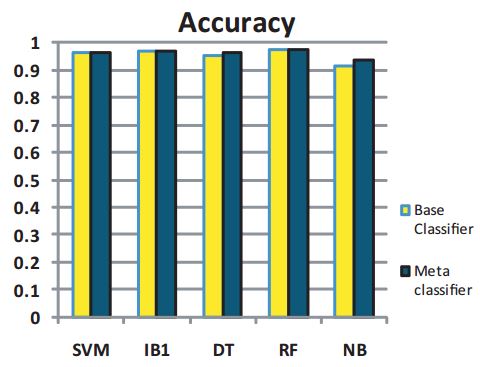
Fig 4.2: Inspection of Classification Precision.
4.3 Execution Times
In the preprocess expression of static investigation, every one of the specimens are traded to ida2CSV pattern. The time spent on sending out executables to the ida2CSV is the Exporting Time. Exporting Times are recorded for the families and these circumstances are in seconds. Exporting Times as of now incorporate the preprocess times. What’s more, the running circumstances for the characterization segment of the tests are 10300 seconds (estimated esteem in view of the grouping segment of the examination for static PSI highlights depicted. The main contrast between that trial and this analysis is the quantity of tests. In that analysis, we test on 9939 specimens and the running time of grouping segment is 368 minutes).
We presented 161 clean executables gathered from win32 stage in this analysis and Table 4.3 records the order consequences of malware versus clean ware by taking clean ware as a different family. In that table, we can see that the best order exactness is 94.8% (RF with boosting). These outcomes demonstrate that our techniques keep comparative execution in separating malware from clean ware. We contrast PSI results and some other late work grouping substantial arrangements of malware and accomplishing no less than 85% precision. Bailey et al. [BOA+07] portray malware conduct as far as framework state changes (taken from occasion logs).
Table 4.3: Malware vs Clean ware Outcomes
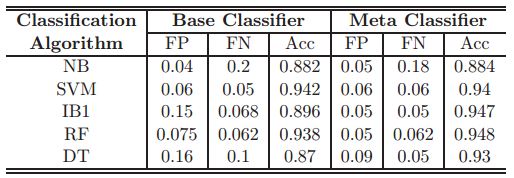
They contrast more than 8000 pre-characterized tests and more than 8000 unclassified specimens utilizing a bunching system to quantify closeness. Examination of Our Method with Existing Work tests. They utilized preparing, test and approval sets and connected Neural Net classifiers picking the best such classifier family by family. General execution is dictated by utilizing a consolidated classifier on the testing allotment. Roughly 88% genuine positive distribution is accomplished. We likewise contrast PSI test and our FLF test.
5 CONCLUSION AND FUTURE WORK
We accomplished a normal discovery and classification exactness of 95%. Consolidating a few static elements can deliver preferable recognition and arrangement execution over any individual component can create. Antivirus research is a generally a vast research field with some work are still performed physically, there is an absence of basic investigation of a malware recognition and order framework. In building up this proposal, some examination addresses and relating arrangements were shaped progressively. In light of these inquiries and arrangements, I have proposed the design for a malware identification and grouping framework what’s more, exhibited its usage.
The first executable records that we gathered were put away in the document framework as twofold code. We expected to preprocess these records to make them reasonable for our exploration. We utilized two strategies for information preprocessing in our framework as examined. These strategies included static and element techniques. In the static technique, we initially unloaded malware then played out a figuring out investigation of the executable documents by IDA Pro and sent out dismantling data into our ida2CSV. In the dynamic strategy, the executable records were executed under a controlled situation.
In the dynamic strategy, we put away element data in the log grinds which recorded the caught windows APIs. With respect to 3 Two sorts of components were separated from the executables, including the static elements and element highlights. Our point was to dissect and extricate straightforward and viable components from executable documents. In the static strategy, we picked FLF in Chapter 4, and PSI in Chapter 5 as our static elements. In the dynamic technique, we picked caught windows APIs as our dynamic elements.
Since our proposed framework meant to fabricate a hearty framework which incorporated the dynamic investigation and static examination approaches. We investigated five sorts of Machine Learning arrangement calculations. There were Deep Neural Nets, IB1 (Instance-Based Learning), DT (Decision Tree), RF (Random Forest), and SVM (Support Vector Machine). In view of the comprehension of their standards, examination of work from different specialists, the benefits of these calculations and their incredible execution in characterization errands, we connected these five calculations alongside Ada-Boost in our analyses.
The work exhibited in this postulation still in its examination stage. My flow examine work concentrate is on enhancing the arrangement exactness. FLF highlights rely on upon capacity length data separated from executables by IDA Pro. What’s more, PSI components are removed from Strings window of IDA Pro. These static methodologies are defenseless against obscurity and polymorphic strategies. In spite of the fact that these two components can supplement each other, if malware essayists jumble them two, the location and characterization precision will be influenced. To manage this, later on work, some other critical static elements would be researched and brought into our framework.
In future work, we will present more sorts of malware and later malware into our framework. Other than capacity length, and printable strings, we additionally store numerous other dismantled data, including essential squares, directions, control stream diagram, call chart and some factual data. In our future work, we can examine this data to unearth more noteworthy static elements. Utilizing the present element strategy, we created the element vectors utilizing recurrence of blocked windows APIs. While we think the groupings or sub successions of captured windows APIs contain planned moves made by malware amid its execution, these booked activities really suggest the huge behavioral data of malware. In future work, these arrangements can be mulled over when we create dynamic components by looking at the log documents.
Wrappers assess every potential subset of components by utilizing the order precision gave by the real target learning calculation. In this proposition, I have not introduced these because of time and space constraints. Arrangement Algorithms and the following point is to improve our framework. The fundamental reason for hereditary calculations is enhancement. So in future work, we will concentrate hereditary calculations and coordinate them into our order framework.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: