A Survey of Person Re-identification Using Deep Learning Approach
Info: 11694 words (47 pages) Dissertation
Published: 9th Dec 2019
A survey of person re-identification using deep learning approach
Abstract:
From the past few years’ person re-identification plays an active role in the automated video surveillance and has been an active research area. Various images and videos are captures from one camera and when matched with images and videos taken from different other cameras in order to identify a particular person, this process is known as identification. Other than surveillance, robotics, multimedia and forensics are also applications of person re-identification. This problem becomes more challenging when person’s appearance over different cameras gets affected from the uncertainty in visual ambiguity and spatiotemporal. The problem becomes more massive when the images are of low resolution and videos are of poor quality containing unrelated information more as compare to useful information. Describing a human from their appearance often becomes difficult as human can change their appearance by changing their posture, clothing and lighting conditions. Thus describing human with the help of particular feature is a challenging task. In person re-identification extraction and matching of features plays a vital role. The appropriate way is to automatically learn features from data together with other components. This is hard to achieve without deep learning. In particular, recent advances of deep learning techniques bring encouraging performance in handling challenges obtained from complex variations of lightings viewpoints, blurring effects, image resolutions, camera settings, occlusions and background clutter across camera views. This paper explores five of the deep learning architectures applied in a wide range of scenarios of person re-identification. We have also presented the current challenges that are overcome by the usage of these deep learning architectures.
- Introduction:
In the community of modern computer vision, person re-identification is to find out whether different images capture from multiple cameras are belong to the same subject or not. In video surveillance, person re-identification is to judge whether queried person appear in the view of another camera, placed at different location or at different time. The performance of other applications such as analysis of behavior, retrieval of an object and tracking of cross camera is closely related to the performance of person re-identification. In recent years’ advancement in the representation of samples and in the evaluation metrics, which evaluate similarity between samples, greatly increases the performance of person re-identification but due to degradation and variation in person images make it more challenging. There exist different survey papers [1-4], reviewing about person re-identification. These survey paper does not review about the approaches based on deep learning. Instead some survey papers are based on single feature i.e. appearance feature-based approaches. Also, the presentation of approaches is not in a tabular format. This survey paper represents the deep learning-based approaches for person re-identification by classifying them according to their architecture and also according to the correspondence established between the query set and the input set. In the approaches based on deep learning, feature learning takes place automatically from data together with other components, this greatly improves the performance. In many computer vision problems such as recognition of hand writing [1], face [11,12,13,14] and object [2,3], detection of an object [4,5,6,7], classification of an image [8,9] and understanding a particular scene [10], deep learning has achieved a great success. Being a part of machine learning methods, it deals with algorithms which uses the concept of artificial neural networks and thus may also be named as deep structured learning.
There occur different topologies of deep networks in deep learning. Neural network is one of the deep network consisting of many layers of networks, such that each layer provides some functionality, such as data representations and feature extraction. The development of these networks basically occurs by adding layers. With the addition of each layers comprises adding more weights and interconnections between the layers and also within the layers. In this paper we discuss about the problems of person re-identification with their solutions using any of the five deep learning architectures: convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM) or gated recurrent unit (GRU), deep belief networks (DBN) and deep stacking networks (DSNs). These are the most popular architectures of deep learning.
In the next section2, we will explore the deep learning methods [15-22] to solve the challenges come across in person re-identification problem. The section 3 provides current scenarios of person re-identification problem by classifying methods based on correspondence between query data and output data which helps in better understanding of current approaches. In section 4 we present and compare the results generated from the deep learning approaches and the approaches other than deep learning on the commonly used datasets for the problem of person re-identification. Section 5 concludes the paper.
- Person Re-Identification Using Deep Learning Approach:
The problem of person re-identification comprises of two components feature extraction and representation and metric learning, deep learning-based methods [22-28] have been applied simultaneously to both the components. A typical structure of this approach consists of two parts, shown by figure 3.1
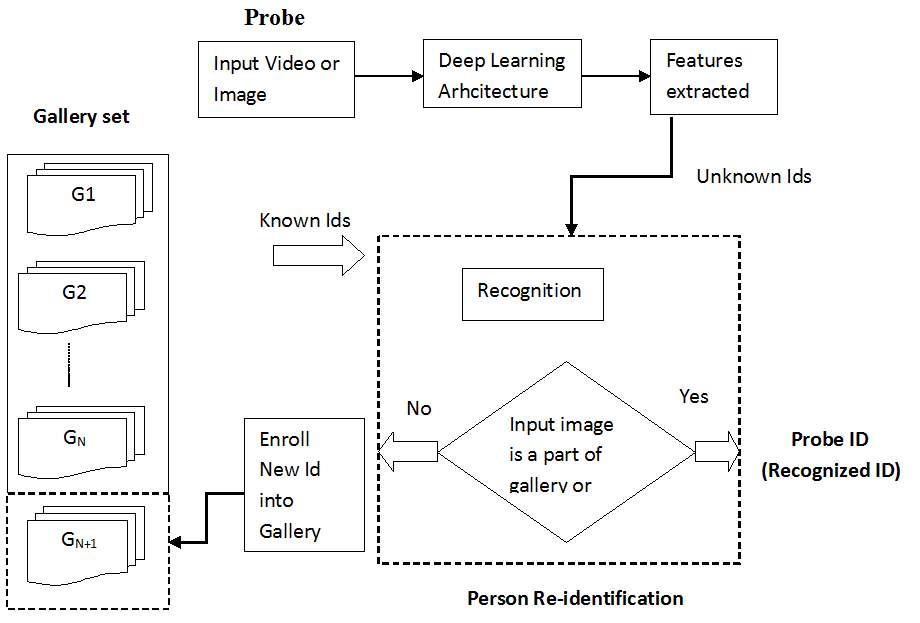
Fig. 3.1 Process of Person Re-identification using deep learning approach
In above figure the first part is a featurelearning network, usually a convolutional neural network or other kinds of networks. The feature pairs extracted from the first step are then fed into severalmetric learning layers to predict whether a pair of image belongs to the same person. The networks used in such approach have simple structure and thus for a particular type of data they can be trained easily. While dealing with person re-identification one essential factor which come upon is space-time information, which usually come across when data is in form of video sequences. In order to represent and extract features such approaches are hence appropriate for single-shot problem. and learn metric, some approaches use a pair of images, for them thus consideration of space-time information is not possible. But deep learning-based methods learn space-time information more efficiently by using simple neural networks [29,30].
Each deep learning architecture is used to solve many problems that come across in person re identification and previous approaches are not efficient enough to solve these problems. Following figure 3.2 shows different networks which follow deep learning architecture. This figure also gives the year in which they developed.
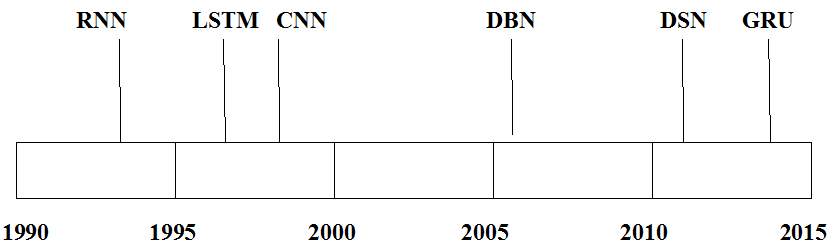
Fig. 3.2 Deep learning networks with year in which they developed
(I) Convolutional neural networks [ ]
A CNN is a type of neural network which has more than one layers biologically motivated by the animal visual cortex. In image processing, such networks play a vital role. It was firstly created by Yann LeCun, for the interpretation of postal code which involve recognition of handwritten character. When used as a multi-layer deep network, former layers are used in recognition of features, thereafter these recognized features are recombined into higher-level attributes of the input by the layers later on. In the first step an input to the CNN is an image which is then gets segmented into different fields. The extraction of features is made from this segmented image by the convolutional layer. The Second step is itself composed of two steps: first is down sampling process under which reduction in the dimension of the extracted features takes place and second step is max-pooling which retain the important information among extracted features. Again, repetition of first two steps i.e. convolution and pooling take place, the output of which is connected to the multilayer perceptron. The output of this network is a layer containing a set of nodes. These set of nodes are used in the identification of features of the image. A process known as back propagation is used to train the network.
Following are the challenges that come across in person re-identification and overcome by using CNN.
(a) Automatically learning of the feature from the cross dataset in person re-identification:
Feature extraction and metric learning are the two basic and essential steps in person re-identification. The majority of existing methods include two separate steps: feature extraction and metric learning. The features usually come from two separate sources: color and texture, some of which are designed by hand, some of which are learned, and then they are finally connected or fused by simple strategies. Another challenge that comes across is that in real time person re-identification generally source and target data sets are different here source data set are those data sets that are used to train model and target dataset are those on which testing of model is to be done. Different between the two datasets could be if they are taken from different cameras and also under different environments. So, the “Deep Metric Learning” (DML)[31] method provides a framework which overcome above challenge and combine two separate modules together, one is learning the color feature, texture feature and another is metric. In this method siamese convolutional neural network (SCNN) is used whose structure is shown in figure 3.3.
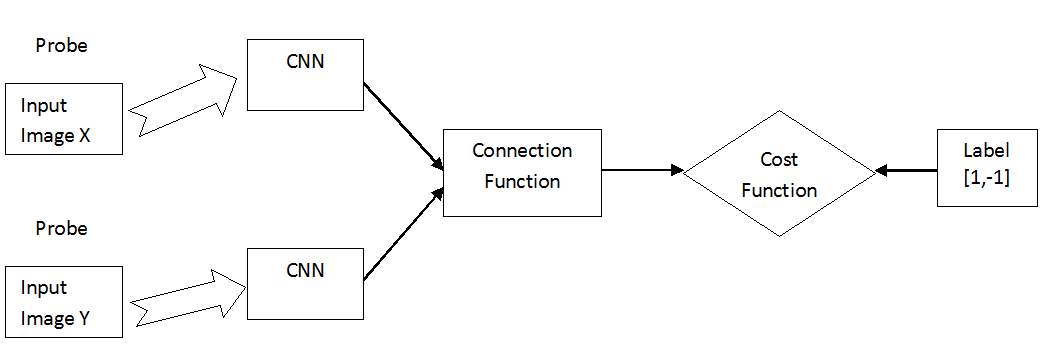
Fig. 3.3. The structure of the siamese convolutional neural network (SCNN), which is composed by three components: CNN, connection function and cost function
In the following figure 3.3 SCNN is composed by three components CNN, connection function and cost function. Based on the parameter sharing, SCNN can be classified into two types: First type is “General” in which two sub-networks share the same parameters i.e. weights and biases and thus can be used for cross dataset person re-identification. The second type is “View-Specific” in which there is no parameter sharing among sub-networks. The CNN used in SCNN is composed of 3 components 2 convolutional layers, 2 max pooling layers and a full connected layer. Every pooling layer also includes a cross-channel normalization unit. The output of the CNN is a vector of 500 dimensions which is same size as the input because initially input data are padded by zero values. In this framework recognition of input probe is made on the basis of similarity with images in gallery set which is provided in two forms i.e. rank and similarity score. By predicting the value of label= [1,-1], this framework determines whether the two input images X and Y belongs to the same subject or not, respectively. The performance of this method based on intra dataset experiments is evaluated using the same dataset for training and test both on VIPeR and PRID and cross dataset experiments is evaluated using the training dataset on i-LIDS and test on VIPeR, training on i-LIDS and test on PRID, training on CUHK Campus and test on VIPeR and training on CUHK Campus and test on PRID.
(b) Complex variations of lightings, poses, viewpoints, blurring effects, image resolutions, camera settings, occlusions and background clutter across camera views:
When computing the similarity between two images, visual features of two corresponding patches are compared. The challenges which are faced while matching patches in two camera views are misalignment problem, variations of lightings, so with such challenges it becomes difficult to design optimal features which are independent of other components. The designing of feature should be optimal otherwise it can degrade the performance. With deep learning it becomes easier to automatically learn features. The features can be assumed and represented using the photometric or geometric transform models which then involve learning the model parameters from training samples. Filter pair neural network (FPNN) [32] approach uses CNN architecture of deep learning, under which photometric transforms are learned with filter pairs and a maxout grouping layer. On the other hand, geometric transforms are learned with a patch matching layer, a convolutional-maxpooling layer and a fully connected layer. In order to handle misalignment, cross-view photometric and geometric transforms occlusions and background clutter in person re-identification the architecture of FPNN consists of six layers which is shown in figure 3.4.
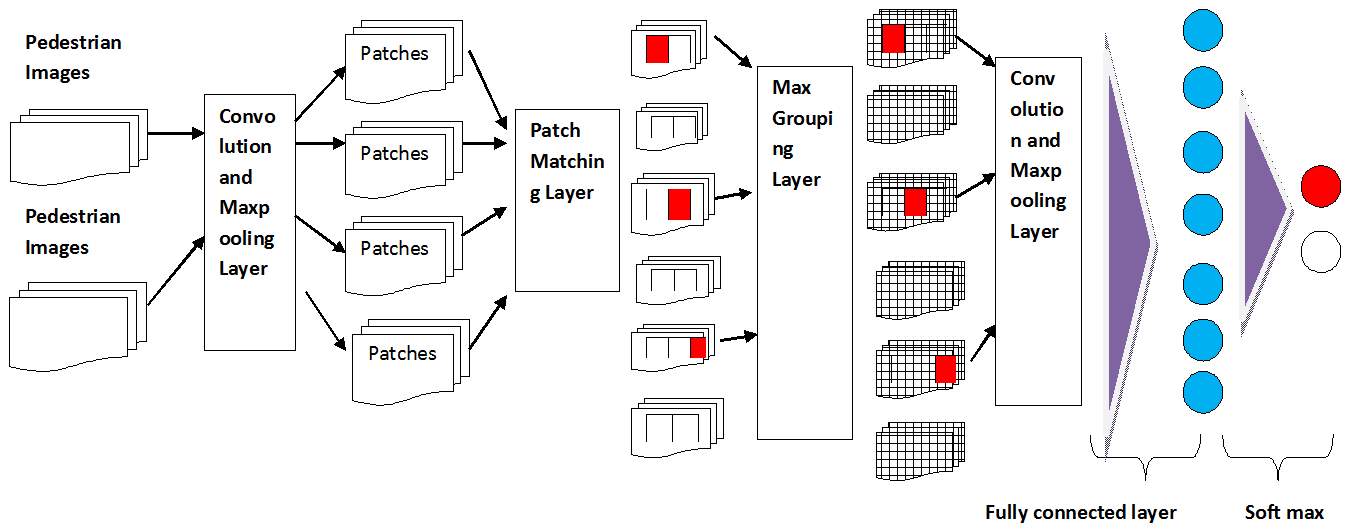
Fig. 3.4 The structure of the Filter Pairing neural network (FPNN), which is composed by three components: CNN, connection function and cost function.
The first layer is a convolutional and max-pooling layer. An input image is divided into horizontal stripes, such that each stripe contains W1 patches. The convolutional layer filters the input images taken from different camera views and extracts the responses from all local patches as the local features. The convolutional layer is followed by max-pooling, which makes the features robust to local misalignment. The output of the max-pooling layer is a feature map. The second layer is the patch matching layer i.e. is used to match the filter responses of local patches across views. Another layer is the maxout-grouping layer, to make features more robust by detecting the photometric transforms in patch matching by generating patch displacement matrices of selected features. In order to obtain the displacement matrices of body parts on a larger scale, the fourth layer i.e. another convolutionand max-pooling layer is added on the top of patch displacement matrices. The output of this layer is the displacement of a particular part w.r.t the visual feature, which then acts as an input to the next fully connected layer. This layer produces part displacements which represents a global geometric transform. Using the global geometric transforms, the last softmax layer uses the softmax function to measure whether two input images belong to the same person or not. This approach is evaluated on CUHK01 and CUHK03 dataset which shows that improved FPNN performs well and produces improved low-level features which can be shared by different camera settings. In contrast to those works that use hand-crafted features, FPNN automatically learns features optimal for the re-identification task from data.
(c) To localize and segment objects when there is a scarcity of labeled data:
Object detection is the process of finding instances of real-world objects such as faces, bicycles, and buildings in images or videos. Object detection algorithms typically use extracted features and learning algorithms to recognize instances of an object category. In person re-identification object detection plays an important role as it requires people to be accurately detected and tracked in order to build a strong visual signature of people appearances. Unlike image classification, object detection requires localizing (likely many) objects within an image. So, in person re-identification it is necessary to determine whether a given person of interest has already been observed over a network of cameras or not which greatly involves the process of localizing the person of interest. In order to build a strong visual signature of people appearances it is necessary to segment the person image and extracts features from each region. The following figure 3.5 shows difference between detection, localization and segmentation.

Fig. 3.5 Images showing difference between object detection, localization and segmentation. Here objects are cat, duck and dog [33].
In image segmentation you will segment regions of the image. Your output will not label segments and region of an image that consistent with each other should be in same segment. Extracting super pixels from an image is an example of this task or foreground-background segmentation. These all process is easily possible when we have labelled data but without labelled data it becomes very difficult. The conventional solution to this problem is R-CNN (Regions CNN) [34] which uses unsupervised pre-training, followed by domain-specific fine-tuning instead of supervised fine-tuning (e.g., [4]). This approach extracts around 2000 bottom-up region proposals from an input image, thereafter computes feature for each proposal using a large convolutional neural network (CNN), and then classifies each region using class-specific linear SVMs. R-CNN achieves a mean average precision (mAP) of 53.7% on PASCAL VOC 2010 dataset, which is more than 30% relative to the previous best result on VOC 2012
(d) Identifying a person of interest from noisy videos, i.e. with arbitrary sequence duration and starting/ending frames, unknown camera viewpoint/lighting variations and also affected with occlusion:
The problem of person re-identification in the video setting, which occurs when a video of a person as observed in one camera, must be matched against a gallery of videos captured by a different non overlapping camera. A significant approach was presented in 2014, which aim to construct a discriminative video matching framework [35] for person re-identification by selecting more reliable space-time features from unregulated videos of a person. This approach is known as Discriminative Video fragments selection and Ranking (DVR) which is based on a robust space-time feature representation given unregulated image sequences of people. The model is formulated using a multi-instance ranking strategy for learning from pairs of image sequences over non-overlapping camera views. We derive a multi-fragments based space-time feature representation of image sequences of people. This representation is based on a combination of HOG3D features and optic flow energy profile over each image sequence, designed to break down automatically unregulated video clips of people into multiple fragments. Then DVR model for cross-view re-identification by simultaneously selecting and matching more reliable space-time features from video fragments. DVR automatically discover and exploit the most reliable video fragments extracted from inherently incomplete and inaccurate person image sequences captured against cluttered background, and without any guarantee on starting/ending frame alignment.
(e) To recognize actions in the videos:
The actions in the videos represents various activities going on in a video e.g. in a video recognizing whether person is smoking or not, or handshaking. The following figure 3.6 shows a input videos in which some action is going on.

Fig. 3.6: Input videos showing some action is occurring [36]
One challenge is that video contains a varying number of frames which is incompatible to the standard input format of model. Thus, in order to recognize it is necessary to design a feature representation which fully exploit the spatial-temporal information in videos. Previous research includes state-of-the-art methods which usually generate video-level representations by adopting hand-crafted features such as spatial-temporal interest points [37] or trajectories [38], [39] and unsupervised feature encoding methods such as Fisher vector encoding [40]. These methods Existing methods handle this issue either by directly sampling a fixed number of frames or bypassing this issue by introducing a 3D convolutional layer which conducts convolution in spatial-temporal domain. Temporal pyramid pooling CNN [41] presents a novel network structure which allows an arbitrary number of frames as the network input. The overall structure of the network is shown in Figure3.7.
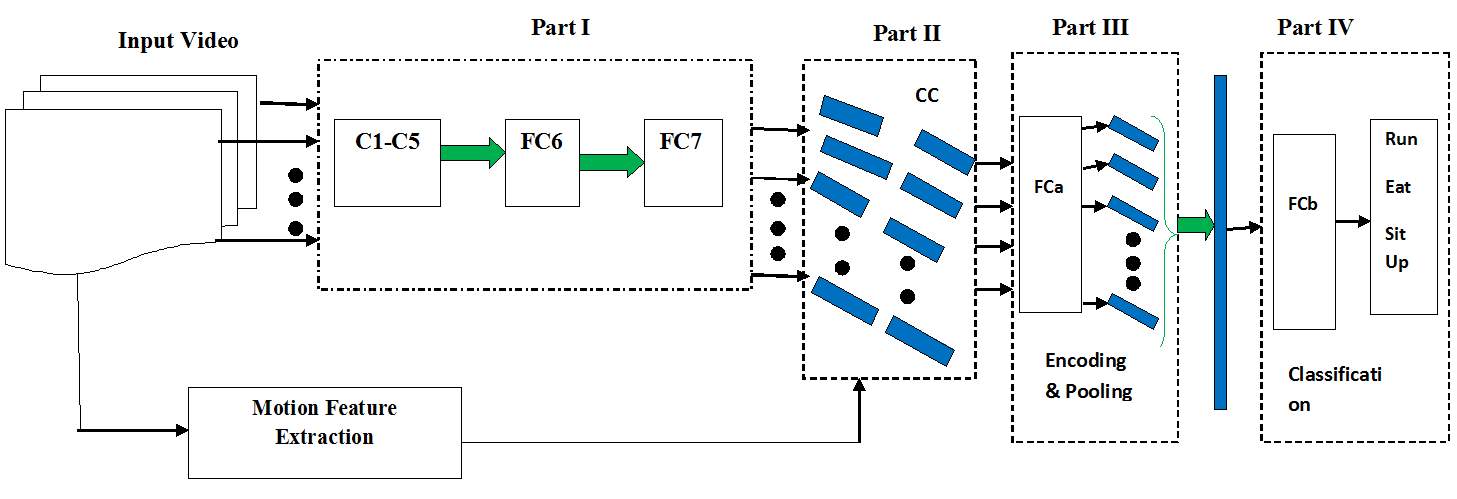
Fig. 3.7. The structure of the Temporal Pyramid Pooling Based Convolutional Neural Network for Action Recognition. We extract appearance and motion representation from a video and concatenate them. After encoding and temporal pooling, we get the final representation of the video for classification.
It can be decomposed into four parts: the first part consists of five convolutional layers C1-C5 and two fully connected layers FC6 and FC7. In the second part, the activation of FC7 is fed into the feature concatenation layer CC, which concatenates the output of FC7 and the frame-level motion feature. The concatenated feature then passes through a fully-connected layer FCa followed by a temporal pyramid pooling layer which converts frame-level features into the video-level feature. FCa together with the temporal pyramid pooling layer constitute the third part of our network, which is also the core part of our network. Finally, the classification layer, which is the fourth part of the network, is applied to the video-level feature to obtain the classification result. This approach is demonstrated on two challenging datasets Hollywood2 and HMDB51 and shows improvement in the classification performance since it can better describe the temporal structure of videos. This method also enables to combine the appearance feature from a CNN and the state-of-the-art motion descriptor.
(f) Event detection from the videos with limited hardware resources:
Event detection is more difficult primarily because an event is more complex and thus has greater intra-class variations. As a result of the unaffordable computation cost, it would be extremely difficult for a relatively smaller research group with limited computational resources to process large scale MED datasets. It becomes important to propose an efficient representation for complex event detection with only affordable computational resources, e.g., a single machine, while at the same time attempting to achieve better performance. It becomes important to propose an efficient representation for complex event detection with only affordable computational resources, e.g., a single machine, while at the same time attempting to achieve better performance. For example, a “marriage proposal” event may take place indoors or outdoors, and may consist of multiple concepts such as ring (object), kneeling down (action) and kissing (action). A discriminative video representation method for event detection over a large scale video dataset was proposed [42] which provides two basic solutions. First this method leverage the encoding techniques to generate video representation based on CNN descriptors. Second, we propose to use a set of latent concept descriptors as frame descriptors. This approach is based on network architecture consisting of 16 weight layers. The first 13 weight layers are convolutional layers, five of which are followed by a max-pooling layer. The last three weight layers are fully connected layers. Video pooling computes video representation over the whole video by pooling all the descriptors from all the frames in a video. We utilize the largest event detection datasets with labels2, namely TRECVID MEDTest 13 [43] and TRECVID MEDTest 14 [44]. For both datasets, there are 20 complex events respectively, but with 10 events overlapping. MEDTest 13 contains events E006-E015 and E021-E030, while MEDTest 14 has events E021-E040. Event names include “Birthday party”, “Bike trick”, etc. we apply linear Support Vector Machine (SVM) with LIBSVM toolkit. TRECVID Multimedia Event Detection (MED) has suffered from huge computation costs in feature extraction and classification processes. Using Convolutional Neural Network (CNN) representation seems to be a good solution, but generating video representation from CNN descriptors has different characteristics from image representation. We are the first to leverage encoding techniques to generate video representation from CNN descriptors. And we propose latent concept descriptors to generate CNN descriptors more properly. For fast event search, we utilize Product Quantization to compress the video representation and predict on the compressed data. Extensive experiments on the two largest event detection collections under different training conditions demonstrate the advantages of our proposed representation. We have achieved promising performance which is superior to the state-of-the-art systems which combine 10 more features.
(g) To handle tracklets in video re-identification datasets:
When both probe and gallery units contain much richer visual information than single images, then image sequences in these video re-id datasets are generated by hand-drawn bounding boxes(bboxes). This process is extremely expensive, requiring intensive human labor. And yet, in terms of bounding box quality, hand-drawn bboxes are biased towards ideal situation, where pedestrians are well-aligned. But in reality, pedestrian detectors will lead to part occlusion or misalignment which may have a non-ignorable effect on re-id accuracy [45]. Another side-effect of hand-drawn box sequences is that each identity has one box sequence under a camera. This happens because there are no natural break points inside each sequence. But in automatically generated data, a number of tracklets are available for each identity due to miss detection or tracking. As a result, in practice one identity will have multiple probes and multiple sequences as ground truths. It remains unsolved how to make use of these visual cues. In person re-identification, current CNN methods [28, 31,32,47] take positive and negative image pairs (or triplets) as input to the network due to the lack of training data per identity. Thus, this approach [46] employ the ID-discriminative Embedding (IDE) [48] using CaffeNet [9] to train the re-id model in classification mode. During training, images are resized to 227_227 pixels, and along with their IDs (label) are fed into CNN in batches. Through five convolutional layers with the same structure as the CaffeNet [9], we define two fully connected layers each with 1,024 blobs. The number of blobs in the 8th layer is equal to the number of training identities which in the case of MARS is 631. The total number of training bboxes on MARS is 518k. In testing, since re-id is different from image classification in that the training and testing identities do not overlap, we extract probe and gallery features using the CNN model before metric learning steps. Specifically, we extract the FC7 features for all bboxes in an input tracklet. Then, max/average pooling is employed to generate a 1,024-dim vector for a tracklet of arbitrary length. Finally, metric learning is leveraged as in image-based re-id. When transferring the CNN model trained on MARS to other video re-id datasets, we fine-tune the MARS-learned CNN model on the target datasets. In this architecture all the 7 CNN layers including the convolutional and fully connected layers are fine tuned. The Last fully connected layer (FC8) is trained from scratch. This approach shows that under realistic settings with complex background, occlusion, and various poses, the learned CNN feature outperforms motion features and a number of state-of-the-art image descriptors to a large margin, and has good generalization ability on other video datasets.
(h) Requirement of manual annotation in order to perform either training from scratch or fine-tuning for the target task:
Initialization by a pre-trained network and re-training for another task, a process called fine tuning, significantly improves the adaptation ability. Fine-tuning by training with classes of particular objects, e.g. building classes in the work of Babenko etal. [49], is known to improve retrieval accuracy. A number of image clustering methods based on local features have been introduced [50,51,52]. Due to the spatial verification, the clusters discovered by these methods are reliable. In fact, these methods provide not only clusters, but also a matching graph or sub-graph on the cluster images. These graphs are further used as an input to a Structure-from-Motion (SfM) pipeline to build a 3D model [53]. The SfM filters out virtually all mismatched images, and also provides camera positions for all matched images in the cluster. The whole process from unordered collection of images to 3D reconstructions is fully automatic. An approach [54]whichexploit SfM information and enforce not only hard non-matching (negative) but also hard matching (positive) examples to be learned by the CNN. This approach enhances the derived image representation. In the architecture used in this approach, fully connected layers are discarded and the pre-trained networks constitute the initialization for our convolutional layers. Now, the last convolutional layer is followed by a MAC layer that performs MAC vector computation (1). The input of a MAC layer is a 3D tensor of activation and the output is a non-negative vector. Then, an `2-normalization block takes care that output vectors are normalized. We adopt a siamese architecture and train a two branch network. Each branch is a clone of the other, meaning that they share the same parameters. Training input consists of image pairs (i; j) and labels Y (i; j) 2 f0; 1g declaring whether a pair is non-matching (label 0) or matching (label 1). The dataset used for experiment purpose are Oxford5k, Oxford10k, Paris6k, Paris10k, Hol, Hol101k. The achieved results are reaching the level of the best systems based on local features with spatial matching and query expansion, while being faster and requiring less memory.
(II) Re-current Neural Networks (RNN):
The RNN is one of the foundational network architectures from which other deep learning architectures are built. The architecture of RNN is shown by figure 3.8. The primary difference between a typical multilayer network and a recurrent network is that rather than completely feed-forward connections, a recurrent network might have connections that feed back into prior layers (or into the same layer). This feedback allows RNNs to maintain memory of past inputs and model problems in time. RNNs consist of a rich set of architectures (we’ll look at one popular topology called LSTM next). The key differentiator is feedback within the network, which could manifest itself from a hidden layer, the output layer, or some combination thereof. RNNs can be unfolded in time and trained with standard back-propagation or by using a variant of back-propagation that is called back-propagation in time (BPTT).
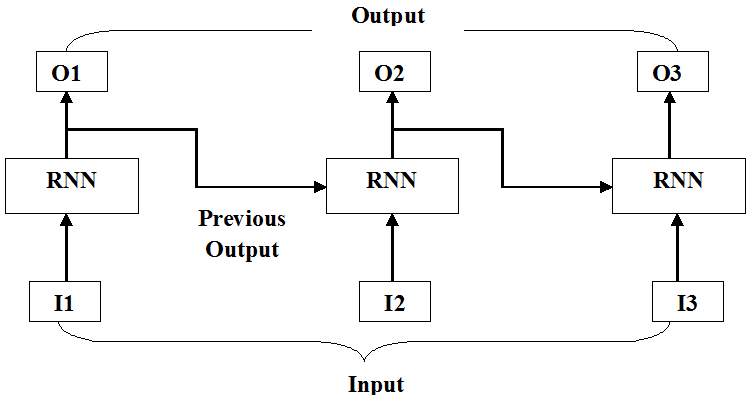
Fig. 3.8 Illustration of RNN in which I1, I2 and I3 are the input and O1, O2 and O3 are output respectively such that output of one stage is input to next layer.
Following are the networks based on the RNN framework
(A) Long short-term memory (LSTM)
Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. They were introduced by Hochreiter & Schmidhuber (1997), and were refined and popularized by many people in following work.They work tremendously well on a large variety of problems, and are now widely used. LSTMs are explicitly designed to avoid the long-term dependency problem. The architecture of LSTM is shown by following figure 3.9.
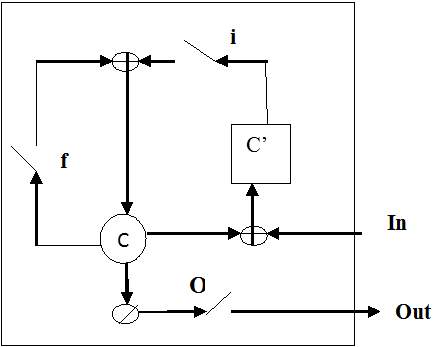
Fig. 3.9. Illustration of LSTM in which i, f and O are the input, forget and output gates respectively. C and C’ denote the memory cell and the new memory cell content.
In the following figure, LSTM memory cell contains three gates that control how information flows into or out of the cell. The input gate controls when new information can flow into the memory. The forget gate controls when an existing piece of information is forgotten, allowing the cell to remember new data. Finally, the output gate controls when the information that is contained in the cell is used in the output from the cell. The cell also contains weights, which control each gate. The training algorithm, commonly BPTT, optimizes these weights based on the resulting network output error.
Remembering information for long periods of time is practically their default behavior, not something they struggle to learn. All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.
LSTM works upon following challenges that come across in person re-identification.
(a) Classifying videos according to content semantics:
Video classification is a process which models static spatial information, short-term motion, as well as long-term temporal clues in the videos. This is not sufficient for video classification, as many complex contents can be better identified by considering the temporal order of short-term actions. Take a “birthday” event as an example, it usually involves several sequential actions, such as “making a wish”, “blowing out candles” and “eating cakes”. Classifying videos according to content semantics is an important problem with a wide range of applications. The following figure 3.10 gives an overview of the framework. Specifically, the spatial and the short-term motion features are extracted separately by two convolutional neural networks (CNN). These two types of CNN-based features are then combined in a regularized feature fusion network for classification, which is able to learn and utilize feature relationships for improved performance.
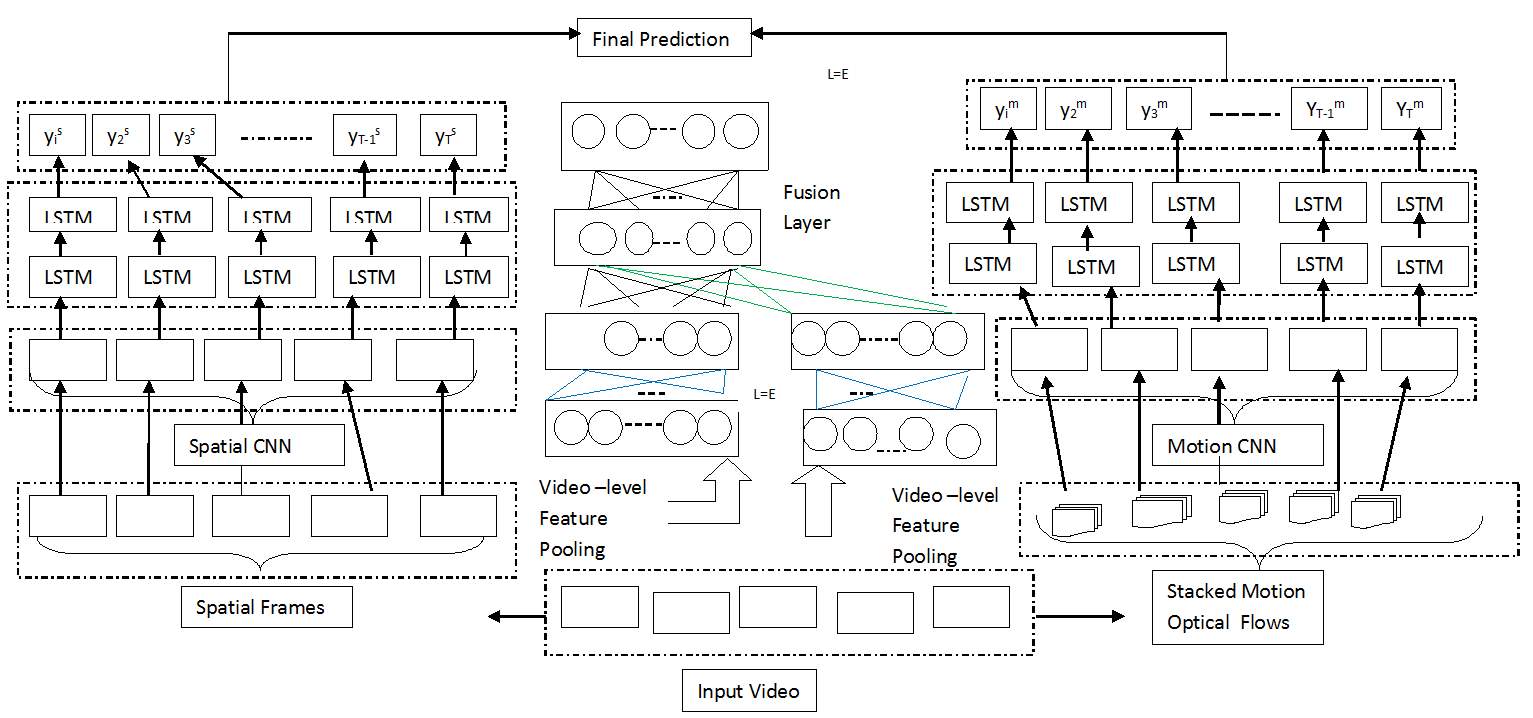
Fig. 3.10 An overview of the proposed hybrid deep learning framework for video classification.
In this figure given an input video, two types of features are extracted using the CNN from spatial frames and short-term stacked motion optical flows respectively. The features are separately fed into two sets of LSTM networks for long- term temporal modeling (Left and Right). In addition, we also employ a regularized feature fusion network to perform video-level feature fusion and classification (Middle). The outputs of the sequence-based LSTM and the video-level feature fusion network are combined to generate the final prediction. In addition, it can be seen in figure 3.10 that Long Short Term Memory (LSTM) networks are applied on top of the two features to further model longer-term temporal clues. This work uses the hybrid learning framework that can model several important aspects of the video data. We also show that (1) combining the spatial and the short-term motion features in the regularized fusion network is better than direct classification and fusion using the CNN with a softmax layer, and (2) the sequence-based LSTM is highly complementary to the traditional classification strategy without considering the temporal frame orders. Extensive experiments are conducted on two popular and challenging benchmarks, the UCF-101 Human Actions and the Columbia Consumer Videos (CCV). On both benchmarks, this approach achieves to-date the best reported performance: 91:3% on the UCF-101 and 83:5% on the CCV.
(b) To systematically aggregate both the frame-wise appearance information as well as temporal dynamics information along the human sequence:
Despite the significant progress in recent years, the performance achieved by these methods does not fulfill the real-application requirement due to the following reasons. First, images captured by different cameras undergo large amount of appearance variations caused by illumination changes, heavy occlusion, background clutter, or human pose changes. More importantly, for real surveillance, persons always appear in a video rather than in a single-shot image. These single-shot based methods fail to make full use of the temporal sequence information in surveillance videos. To exploit the richer sequence information, existing methods mainly resort to: (1) key frame/fragment representation [11]; (2) feature fusion/encoding [12,13,14] and (3) spatio-temporal appearance model [15]. Despite their favorable performance on recent benchmark datasets [11,16], we have the following observations on their limitations.
First, key frame/fragment representation based algorithms [35] often assume the discriminative fragments to be located in the local minima and maxima of Flow Energy Profile [35], which may not be accurate. During the final matching, since only one fragment is selected to represent the whole sequence, richer information contained by the rest of the sequences is not fully utilized. Second, feature fusion/encoding methods [45,55,56] take bag-of-words approach to encode a set of frame-wise features into a global vector, but ignore the informative spatio-temporal information of human sequence. To overcome these shortages, the recently proposed method [57] employs the spatially and temporally aligned appearance of the person in a walking cycle for matching. However, such approach is extremely computationally inefficient and thus inappropriate for real applications. It is therefore of great importance to explore a more effective and efficient scheme to make full use of the richer sequence information for person re-id. The fundamental challenge of multi-shot person re-id is how to systematically aggregate both the frame-wise appearance information as well as temporal dynamics information along the human sequence to generate a more discriminative sequence level human representation.
An approach [46] uses a recurrent feature aggregation network (RFA-Net) that builds a sequence level representation from a temporally ordered sequence of frame-wise features, based on a typical version of recurrent neural network, namely, Long Short-Term Memory network [58]. The proposed feature aggregation framework possesses various advantages. First, it allows discriminative information of frame wise data to propagate along the temporal direction, and discriminative information could be accumulated from the first LSTM node to the deepest one, thus yielding a highly discriminative sequence level human representation. Second, during feature propagation, this framework can prevent non-informative information from reaching the deep nodes, therefore it is robust to noisy features (due to occlusion, tracking/detection failure, or background clutter etc). Third, the fusion network architecture of this approach is simple yet efficient, which is able to deal with sequences with variable length. Experimental evaluations are performed on the two-person re-id benchmarks: iLIDS-VID and PRID 2011 which shows that features learned by this recurrent network not only possess high discriminativeness, and also show great robustness to noise.
(B) Gated recurrent unit (GRU):
In 2014, a simplification of the LSTM was introduced called the gated recurrent unit. This model has two gates, getting rid of the output gate present in the LSTM model. For many applications, the GRU has performance similar to the LSTM, but being simpler means fewer weights and faster execution. The following figure 3.11 shows an architecture of GRU.
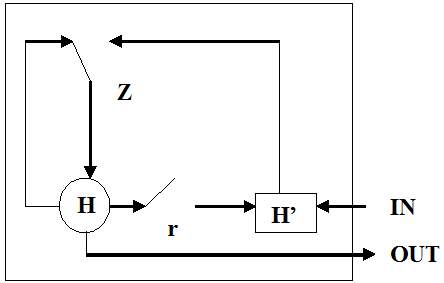
Fig. 3.11. Illustration of Gated Recurrent Units in which r and z are the reset and update gates, respectively and H and H’ are the activation and the candidate activation.
In the following figure it can be seen that GRU includes two gates: an update gate and a reset gate. The update gate indicates how much of the previous cell contents to maintain. The reset gate defines how to incorporate the new input with the previous cell contents. A GRU can model a standard RNN simply by setting the reset gate to 1 and the update gate to 0. The GRU is simpler than the LSTM, can be trained more quickly, and can be more efficient in its execution. However, the LSTM can be more expressive and with more data, can lead to better results.
GRU works upon following challenges that come across in person re-identification.
(a) Identifying a person of interest in videos:
This problem of person re-identification in the video setting occurs when a video of a person as observed in one camera must be matched against a gallery of videos captured by a different non overlapping camera. In practice, video-based person re-identification provides a more natural method for person recognition in a surveillance system. Videos of pedestrians can easily be captured in a surveillance system, and inevitably contain more information about identity than do a subset of the images therein. Person re-identification imposes the challenge of out-of-domain to verify the time series from pedestrians that are not present in the training set. This approach [59] presents a novel deep recurrent convolutional neural network that combines convolution layer at all levels, recurrent layer, and temporal pooling to produce an improved video representation and learn a good similarity measure between time series. This approach makes use of a deep recurrent convolutional neural network in which a GRU is a recurrent unit to adaptively capture dependencies of different time scales. The figure 3.12 gives the overview of architecture of deep recurrent convolutional network
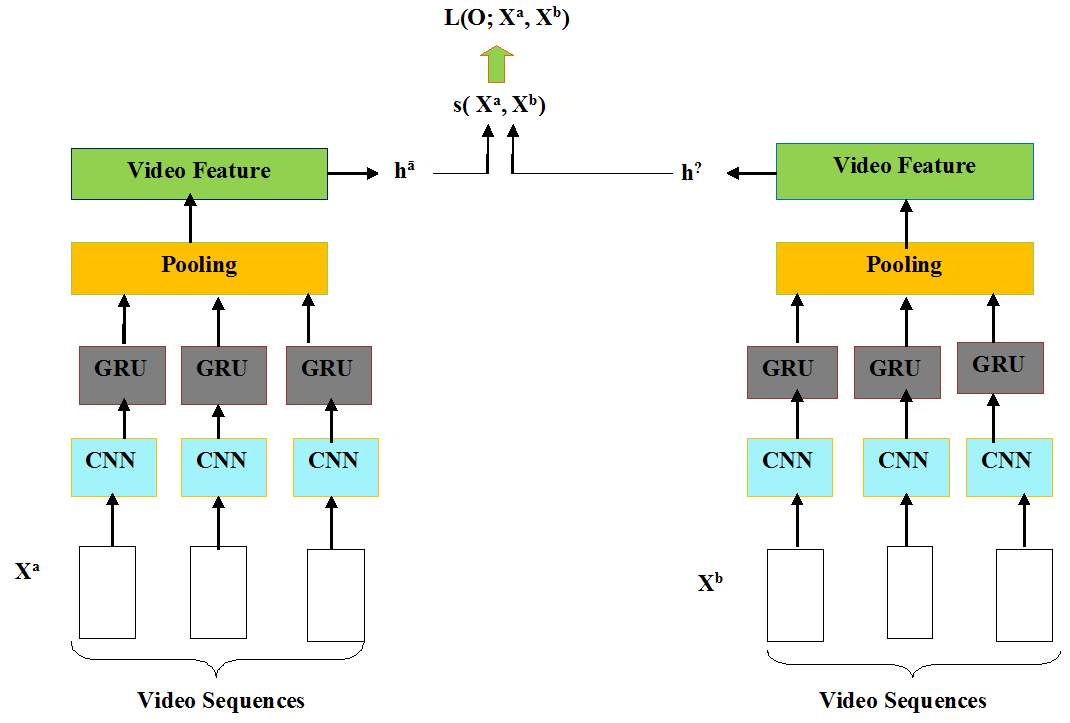
Fig. 3.12. Deep Recurrent Convolutional Network Using GRU
In the following figure given a pair of pedestrian video sequences with variable length (e.g., Xa and Xb), our deep recurrent convolutional network incorporates nonlinear encoder (three-layer CNNs), recurrent layers (Gated recurrent units), and temporal pooling over time steps to learn video-level features and corresponding similarity value (s( Xa, Xb)) in an end-to-end fashion. L(Ɵ; Xa, Xb) is the loss function to be minimized and Ɵ denotes all network parameters to be learnt. Horizontal red arrows indicate that the two subnetworks share parameterization. Experiments are conducted on two benchmark video sequences for person re-identification: the iLIDS-VID dataset [35] and the PRID 2011 dataset [60]. GRUs was found to have superior performance to LSTMs and also with fewer parameters.
The degradation problem causing degradation in accuracy:
Major problem which generated while using deeper networks is the degradation problem. When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [61, 62] and thoroughly verified by our experiments.
- Person Re-ID Scenarios
In person re-identification, one matches a probe (or query) person against a set of gallery persons for generating a ranked list according to their matching similarity, typically assuming the correct match is assigned to one of the top ranks, ideally Rank-1 [15, 16, 17, 18]. As the probe and gallery persons are often captured from a pair of non-overlapping camera views at different time, cross-view visual appearance variation can be significant. If the probe person is not matched that means it is not a part of gallery set, then this probe is added to the gallery set and given a new id. With respect to the probe-to-gallery” pattern, there are four re-id strategies: image-to-image, image-to-video, video-to-image, and video-to-video.
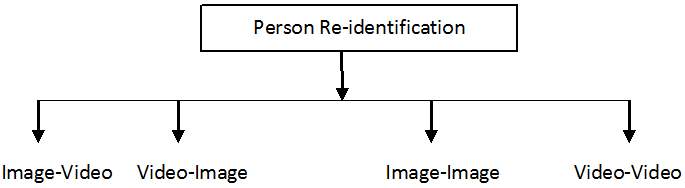
Fig: 3.1 Classification of Person Re-identification based on establishing correspondence (Matching)
In image-to-image strategy, sometimes input is the single shot images, then state of arts method usually for such type of input images match spatial appearance features (e.g. color and intensity gradient histograms). However, single-shot appearance features are intrinsically limited due to the inherent visual ambiguity caused by clothing similarity among people in public spaces, and appearance changes from cross-view illumination variation, viewpoint difference, cluttered background and occlusions. When input is in the form of multishot image, then multishot methods are used, which uses different observations of the same object during the matching process. In this an object of interest can have several observations and typically the appearance of moving objects can change across time from the same point of view. The image-to-video mode can be viewed as a special case of multi-shot, and the video-to-image mode involves multiple queries. In the last, video-to-video mode, image sequences are generated either manually or automatically. In each method features plays a very important role.
The techniques based on deep learning approach also lie in the above categories of person re-identification and thus can be represented in table 3.1
| S No | Year | Approach | Type of Deep Learning N/W | Mode | Evaluation | Dataset | ||||||||||||||||
| VIPer | PRID | MARS | iLIDS | iLIDS-VID | Market-1501 | GRID | CUHK-01 | CUHK-03 | MORPH | CACD | CACD-VS | 3DPeS | TRECVID MEDTest 14 | HMDB51 | Hollywood | ImageNet | ||||||
| 1 | 2017 | Feature aggregation network (RFA-Net) [46] | LSTM | Image-Image | CMC | – | 58.2% | – | – | 49.3% | – | – | – | – | – | – | – | – | – | |||
| 2 | 2017 | Multi-task deep
Network (MTDnet) [63] |
CNN | Image-Image | CMC | 45.89% | 32% | – | 57.80% | – | – | – | 77.50% | 74.68% | – | – | – | – | – | |||
| 3 | 2017 | Distance Metric Optimization [64] | CNN | Image-Image | CMC | – | – | – | – | – | – | – | – | – | 93.6% | 70.79% | 89.3% | – | – | |||
| 4 | 2017 | Identity Irrelevant Pixel Removal Learning (IIPRL) [65] | CNN | Image-Image | CMC | – | – | – | – | – | 86.7% | – | – | 71.03% | – | – | – | – | – | |||
| 5 | 2017 | End-to-End Comparative Attention Network (CAN) [66] | CNN | Image-Image | CMC | 47.2% | – | – | – | – | – | – | 67.2% | 72.3% | – | – | – | – | – | |||
| 6 | 2017 | Jointly Learning Multi-Loss (JLML) [67] | CNN | Image-Image | CMC | 50.2% | – | – | – | – | – | – | 70.48% | 71.10% | – | – | – | – | – | |||
| 7 | 2017 | Progressive Unsupervised Learning (PUL) [68] | CNN | Image-Image | CMC | – | – | – | – | – | 41.9% | – | – | – | – | – | – | – | – | |||
| 8 | 2016 | Convolutional Covariance Features (CCF) [70] | CNN | Image-Image | CMC | 47.18 | – | – | 55.85% | – | – | – | 63.85% | 63.94% | – | – | – | – | – | |||
| 9 | 2016 | Deep Recurrent Convolutional Networks [71] | GRU | Video-Video | CMC | 49.8% | – | – | 42.6% | – | – | – | – | – | – | – | – | – | ||||
| 11 | 2016 | a novel recurrent DNN architecture[72] | RNN | Video-Video | 70% | – | 58% | – | – | – | – | – | – | – | – | – | – | |||||
| 12 | 2016 | PersonNet [73] | CNN | Image-Image | CMC | – | – | – | – | – | 37.21% | – | 71.14% | 64.80% | – | – | – | 45.60% | – | |||
| 6 | 2016 | Tracklets based [74] | CNN | video-video | CMC | – | 77.3 | 68.3 | – | 53.0 | – | – | – | – | – | – | – | – | – | |||
| 7 | 2016 | Gated Siamese CNN [75] | LSTM | Image-Image | CMC | – | 37.80 | – | – | – | 76.04% | – | – | 68.10% | – | – | – | – | – | |||
| 8 | 2016 | Multi-Channel Parts-Based CNN [76] | CNN | Image-Image | CMC | 47.8% | 22.0% | – | 60.4% | – | – | – | 53.7% | – | – | – | – | – | – | |||
| 9 | 2016 | Deep Attributes Driven Multi-Camera [77] | CNN | Image-Image | CMC | 43.5% | 22.6% | – | – | – | – | 22.4% | – | – | – | – | – | – | – | |||
| 10 | 2016 | (JSTL) Domain Guided Dropout [78] | CNN | Image-Image | CMC | 37.70% | 60.00% | – | 59.60% | – | – | – | 63.00% | 72.50% | – | – | – | – | – | |||
| 11 | 2016 | A novel temporal deep neural network architecture [79] | CNN | Image-Image | CMC | 44.11% | – | – | – | – | 48.15 | – | 67.12% | 63.23% | – | – | – | – | – | |||
| 12 | 2015 | a discriminative video representation [42] | CNN | video-video | CMC | – | – | – | – | – | – | – | – | – | – | – | – | – | 36.8% | |||
| 13 | 2015 | Temporal Pyramid Pooling [41] | CNN | video-video | CMC | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 60.8% | 68.4% | |
| 14 | 2014 | Improved Deep Metric Learning [80] | CNN | Image-Image | CMC | 34.49% | 11.61% | 16.27% | – | – | – | – | – | – | – | – | ||||||
| 15 | 2014 | Deep Filter Pairing Neural Network [32] | CNN | Image-Image | CMC | – | – | – | – | – | – | – | 27.87% | – | – | – | – | – | – | – | – | |
| 16 | 2012 | Deep CNN [9] | CNN | Image-Image | CMC | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 40.7% |
- Evaluation:
In this section, we present extensive experimental evaluations and in-depth analysis of the proposed method in terms of effectiveness and robustness. We also quantitatively compare our method with the state of-the-art multi-shot re-id methods. Algorithmic evaluations are performed on the following two-person re-id benchmarks:
- ViPer:
The ViPER dataset [81] consists of images of people from two different camera views, but it has only one image of each person per camera. The dataset was collected in order to test viewpoint invariant pedestrian recognition and hence the aim was to capture as many same viewpoint pairs as possible. The view angles were roughly quantized into 45° angles and hence there are 8 same viewpoint angle pairs or 28 different viewpoint angle pairs. The dataset contains 632 pedestrian image pairs taken by two different cameras. The cameras have different viewpoints and illumination variations exist between them. The images are cropped and scaled to be 128 × 48 pixels. This is one of the most challenging datasets yet for automated person Re-ID.
Following table shows results of using different features with VIPER dataset
| Sno | Technique | Feature | Result |
| 1 | end-to-end CAN(VGG-16) + LOMO | appearance focus on parts of pairs of person images. combining output features of CAN and LOMO | 54.1% |
| 2 | end-to-end CAN(VGG-16) | appearance focus on parts of pairs of person images | 47.2% |
| 3 | end-to-end CAN(AlexNet) [9] Neeta paper | appearance focus on parts of pairs of person images | 41.5% |
| 4 | JSTL + DGD ( Domain Guided Dropout) | CNN features | 37.70% |
| 5 | FT + JSTL + DGD ( Domain Guided Dropout) | CNN features | 38.60% |
| 6 | Improved DML[3] | color feature, texture feature and metric in a unified framework. | 34.40% |
| 7 | Salience [7] | color and texture feature | 30.16% |
| 8 | LAFT [6] | visual features | 29.60% |
| 9 | DML [21] | color and texture feature | 28.23% |
| 10 | RPML [27] | color and texture feature | 27% |
| 11 | PPCA [30] | visual features | 19.27% |
| 12 | RDC [2] | visual features | 15.66% |
| 13 | ELF [16] | color and texture feature | 12% |
- iLIDS-VID dataset
The iLIDS-VID dataset [82] contains of 600 image sequences for 300 people in two non-overlapping camera views. Each image sequence consists of frames of variable length from 23 to 192, with an average length of 73. This dataset was created at an airport arrival hall under a multi-camera CCTV network, and the images were captured with significant background clutter, occlusions, and viewpoint/illumination variations, which makes the dataset very challenging. Following table shows results of using different features with iLIDS-VID dataset.
| Sno | Technique | Feature | Result |
| 1 | Color &LBP+ RFA-Net+ RSVM | Color & LBP | 49.3 |
| 2 | CNN+Kiss | CNN features | 48.8 |
| 3 | STFV3D+KISSME [37] | low-level features | 44.3 |
| 4 | Deep RCN | video level features | 42.6 |
| 5 | 3D Hog & Color +DVR [36] | 3D HoG feature | 39.5 |
| 6 | MS-Colour & LBP[20] + DVR | Colour & Texture Features | 34.5 |
| 7 | Color + DVR | Color | 32.7 |
| 8 | DVDL [14] | space-time and appearance features | 25.9 |
| 9 | FV3D [33] | local HOG features with fischer vector | 25.3 |
| 10 | DVR (ours) | space-time feature | 23.3 |
| 11 | FV2D [34] | Fisher vector | 18.2 |
| 12 | HOG3D+XQDA | 3D HOG features | 16.1 |
| 13 | BoW+XQDA | Hessian affine local features | 14 |
| 14 | GEI+Kiss. | Gait features | 10.3 |
| 15 | HoGHoF[27]+ DTW[26] | spatial & temporal Features | 5.3 |
(c) PRID 2011 dataset.:
The PRID 2011 dataset [83] includes 400 image sequences for 200 people from two cameras. Each image sequence has a variable length consisting of 5 to 675 image frames, with an average number of 100. The images were captured in an uncrowded outdoor environment with relatively simple and clean background and rare occlusion; however, there are significant viewpoint and illumination variations as well as color inconsistency between the two views.
Following table shows results of using different features with PRID 2011dataset
| Sno | Technique | Feature | Result |
| 1 | CNN+XQDA | CNN features | 77.3 |
| 2 | Color&LBP+RFA-Net+ RSVM | Color &LBP | 58.2 |
| 3 | MS-Colour + DVR | Colour & Texture Features | 41.8 |
| 4 | DVDL [14] | space-time and appearance features | 40 |
| 5 | 3D Hog& Color+ DVR [36] | 3D HoG feature | 40 |
| 6 | Salience | spatial feature | 25.8 |
- HMDB51 dataset:
This is a generic action classification dataset composed of roughly 7,000 clips divided into 51 action classes. Videos and actions of this dataset are subject to different camera motions, viewpoints, video quality and occlusions. As done in the literature we use a one-vs-all classification strategy and report the mean classification accuracy over three standard splits provided by the authors in [84]. Following table shows results of using different features with HMDB51 dataset
| Sno. | Technique | Feature | Result |
| 1 | Rank pooling+ CNN | CNN features | 65.8 |
| 2 | Score-Level Fusion | fusion of fisher vector and motion features | 61.80% |
| 3 | Hoai et al [20] | video features | 60.8 |
| 4 | Wang et al [66] | Local space-time features (trajectory shape,HOG, HOF, MBH) | 46.6 |
(e)MARS:
MARS (Motion Analysis and Re-Identification Set) dataset for video-based person re-identification. It is an extension of the Market-1501 dataset [46]. During collection, we placed six near-synchronized cameras in the campus of Tsinghua university. There were five 1,080 ×1920 HD cameras and one 640 × 480 SD camera. MARS consists of 1,261 different pedestrians whom are captured by at least 2 cameras. MARS is the largest video re-id dataset to date. Containing 1,261 IDs and around 20,000 tracklets, it provides rich visual information compared to image-based datasets. The tracklets are automatically generated by the Deformable Part Model (DPM) as pedestrian detector and the GMMCP tracker. Following table shows results of using different features with MARS dataset
| Sno. | Technique | Feature | Result |
| 1 | CNN+ Kiss.+ MQ | CNN features | 68.3 |
| 2 | HistLBP + XQ. | Color & LBP | 18.6 |
| 3 | gBiCov + XQ. | Biologically Inspired Features (BIF) | 9.2 |
| 4 | HOG3D+Kiss. | HOG 3Dfeatures | 2.6 |
- Hollywood2:
The Hollywood2 dataset [37] is composed of video clips from 69 movies and includes 12 classes. It contains a total of 1,707 videos with 823 training videos and 884 testing videos. Training and testing videos belong to different movies. The performance is measured by mean average precision (mAP). Following table shows results of using different features with Hollywood2 dataset
| Sno. | Technique | Feature | Result |
| 1 | Rank pooling+CNN | CNN features | 75.2 |
| 2 | Hoai et al [20] | video features | 73.6 |
| 3 | Jain et al [23] | spatio temporal features | 62.5 |
| 4 | Wang et al [67] | trajectory features | 64.3 |
- Cooking:
Cooking activities dataset [49]. This dataset was created to evaluate fine-grained action classification. It is composed of 65 different actions that take place continuously within 8 hours of recordings. As the kitchen remains the same throughout the recordings, the classification focuses mainly on the content of the actions and cannot benefit from potentially discriminative background information (e.g. driving a car always takes place inside a car). We compute per class average precision using the same procedure as in [49] and report the final mAP. Following table shows results of using different features with Cooking dataset.
| Sno. | Technique | Feature | Result |
| 1 | Rank pooling | CNN features | 72 |
| 2 | Rohrbach et al [49] | video features (HOG, HOF, MBH) | 59.2 |
- MEDTest14:
Following table shows results of using different features with MEDTest14 dataset
| Sno. | Technique | Feature | Result |
| 1 | IDT (Improved Dense Trajectories) | space-time and appearance features | 27.6 |
| 2 | CNN with average pooling | CNN features | 24.8 |
Following table shows results of using different features with UCF-101 dataset
| Sno. | Technique | Feature | Result |
| 1 | Ours | feature fusion of static visual features, short-term motion patterns and long-term temporal clues. | 91.30% |
| 2 | CNN + LSTM (Spatial & Motion) | CNN features + spatial & motion features | 90.17% |
| 3 | Zha et al. [52] | image trained CNN features (visual features) | 89.60% |
| 4 | Lan et al. [22] | visual features | 89.10% |
| 5 | CNN + LSTM (Spatial) | CNN features + spatial features | 84.09% |
| 6 | Spatial LSTM | spatial features | 83.33% |
Following table shows results of using different features with CCV dataset
| Sno. | Technique | Feature | Result |
| 1 | Regularized Fusion Network | feature fusion spatial and motion CNN feature | 76.20% |
| 2 | Spatial CNN | spatial features | 75.00% |
| 3 | Motion SVM | motion features | 57.90% |
Following table shows results of using different features with VOC2007test dataset
| Sno. | Technique | Feature | Result |
| 1 | Region Proposal (R-CNN) | CNN features | 58.5 |
| 2 | DPM HSC [27] | replaces HOG with histograms of sparse codes (HSC). | 34.5 |
| 3 | DPM v5 [17] | HOG features | 33.7 |
| 4 | DPM ST [25] | HOG features with histograms of “sketch token” probabilities. | 29.1 |
Following table shows results of using different features with Dev view of ViPer dataset
| Sno. | Technique | Feature | Result |
| 1 | With Aug. datasets deep metric learning method by using siamese convolutional neural network. | color and texture feature. fuse the features learned from multiple datasets to improve the performance | 34.49% |
| 2 | Without Aug. datasets. deep metric learning method by using siamese convolutional neural network. | using (Dev view) 3D pose of person | 18.40% |
- Conclusion
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: