Grid Computing Middleware API for Dynamic Configuration
Info: 31374 words (125 pages) Dissertation
Published: 24th Nov 2021
Tagged: Information Systems
CHAPTER 1: INTRODUCTION
In this new developing scientific and technological era, we continuously thrive to solve the complex science and engineering problems. These problems deal with huge amount of data and in order to solve the problems, this huge amount of data has to be analyzed. The analysis of this data can be done by high-performance computing that require availability of enormous computing power. And the branch of high performance computing that can provide the solution is grid computing.
The focus area of the researcher in this thesis is Grid Computing. Grid computing has rapidly emerged as technology and infrastructure for wide area distributed computing. In wide area distributed computing, the resources are distributed globally and are used for computing. So the resources need to be properly shared and used. The security issues should also be taken into consideration when sharing the resources. In Grid computing, resource manager manages the resources needed to an allocated task. But as the number of resources is vast, the probability of failure of a resource is high. If the resources are not dynamically monitored and managed, the computation will fail. So the resources must be used efficiently and effectively. This can be achieved by the middleware.
Motivation and Objective of Research
Motivation
The Grid Computing Environment is evolving at a rapid rate because of the requirement of distributive and collaborative computing. It provides high performance computing to the user who does not have sufficient computing power and the resources. Adding to it, the establishment of virtual organization and rendering services through virtual environment is growing up at a very high rate. To satisfy upcoming requirements GRID networks has become an ultimate solution as on today.
Objective
Looking to the need of the area and the challenges to be taken care, the area of enhancement of GRID architectures, Middleware API’s and Services is taken at the focus of this research. The research work will study at depth the existing Grid Architectures, Middleware API’s supporting various services under each architecture as well as services desired but not available and some challenges are to be identified under this study and analysis. Having done the analysis, the research work will focus on the enhancement of architecture & middleware by way of modeling an improved architecture, enhanced domain of the services and the solution for some of the unattended but needed challenges. For this necessary enhancement of middleware API’s Library is developed. The testing will be carried out at prototype level to justify the targeted achievement.
Scope of Research
In this thesis, problem resulting due to static configuration of middleware are studied and an extension in API is proposed that can help in dynamic configuration of the middleware. In this thesis I have reviewed architectures of various Grid Systems available. I have also reviewed Ganglia Monitoring System and Autopilot Monitoring System. I have found that Ganglia support many features but also have many limitations due to its architecture. I also reviewed and analyzed various grid middleware and frameworks like UNICORE, GLOBUS etc. and found that the need of the hour is a GUI based Grid Framework. Then I analyzed available GUI grid framework – Alchemi .Net and found there is a scope to improve it.
Organization of Thesis
Thesis is organized in chapters as follows –
Chapter 1 is the introduction which contains the Motivation and Objective of Research, Scope of Research and its organization.
Chapter 2 is Literature study and its analysis. The researcher studied various architectures and middleware available. Some of them are state of the art architectures and middleware.
Chapter 3 contains Literature review and findings. Out of more than 300 papers reviewed, 70 papers are selected and reviewed further for problems in architecture and middleware solutions. Drawbacks in existing grid architecture and middleware are identified and presented in the review and findings section.
In Chapter 4, based on findings the problem is formulated and the target of the research is identified.
Chapter 5 contains the proposed work where solution to middleware is proposed. API specification for the proposed solution is given. Further, as an extension to the knowledge, new algorithms are designed and developed for the proposed solution.
Then in Chapter 6, the implementation methodology is given through different experiments, and summary of the results is discussed by comparative analysis.
Finally in Chapter 7 the targets achieved are given as a conclusion.
And last but not the least, in Chapter 8 possible extension of the research work is given.
Chapter 9 contains the References.
Chapter 10 is the Bibliography.
Chapter 11 is the Appendix in which publications of the researcher are given.
CHAPTER 2: LITERATURE STUDY & ANALYSIS
2.1 GRIDCOMPUTING
A Grid environment is a distributed environment comprising of diverse components which are used for various applications. These components are contained with all the software, hardware, services and resources needed to execute the applications. There are three core areas of a Grid environment [1][2] – Architecture, Middleware and Services. In this research, we have focused on the Middleware. Middleware exists on top of the operating system and helps in assisting & connecting software applications and components.
There are many middleware available that can be used for different types of applications. Each middleware has different communication policies & rules, and different modes of operation. These policies, rules and operations classify middleware into procedure oriented, object oriented, message oriented, component based or reflective[1]. Similarly, the functionalities exhibited by the middleware can be classified into – application specific, management specific and information exchange specific categories.
It has been identified that the problem with the GRID environment is that it has diversely distributed components used by large number of users. These can make them vulnerable to faults, failure and excessive loads. Thus, security becomes a very important aspect as most transactions and operations are done online. It is very important to protect the applications and the data involved from malicious, and unauthorized or sometimes unintentional attacks. There should be well defined access policies, cryptography mechanisms and authentication models to solve this issue and provide security.
2.2 GRID ARCHITECTURE APPROACHES
The researcher surveyed different grid architecture and their mechanisms with the objective to find out what is presently available and what can be done to improve it. Some of the architectures studied are discussed as under.
SOGCA – Service-Oriented Grid Computing Architecture
The SOGCA[3] is implemented utilizing Web-service technology shown as Fig. 1.
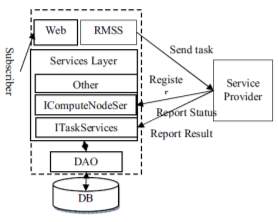
Fig-1: Architecture of SOGCA (Y. Zhu. 2007)
SOGCA inter-operated across heterogeneous platforms by adopting the Web-service architecture. Web services standardize the messages that entities in a distributed system must exchange to perform various operations. At the lowest level, this standardization concerns the protocol used to transport messages (typically HTTP), message encoding (SOAP), and interface description (WSDL). A client interacts with a Web service by sending a SOAP message; the client may subsequently receive response message(s) in reply. The web services implementation of SOGCA refers to Fig.2. There are several interfaces between the Services layer and Services Provider, including one for the Service provider information registering and updating, one for Service Provider state reporting dynamically and one for the task result reporting, etc.
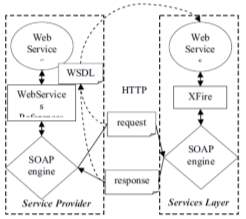
Fig-2: Web Service Implementation (Y. Zhu. 2007)
Services layer utilizes Codehaus XFire which is the next generation framework of SOAP. It makes service oriented development approachable through its easy to use API and support for standards. It also gives high performance. The service provider sends the SOAP messages to service layer by the Web Services References API of .NET platform using WSDL.
AGRADC: Autonomic Grid Application Deployment & Configuration
Architecture
AGRADC (Autonomic Grid Application Deployment & Configuration Architecture)[4], an architecture to instantiate grid applications that allows the necessary infrastructure to be deployed, configured, and managed upon demand. AGRADC is composed of four conceptual elements: management application; component repository; instantiation engine; and instantiation services. Figure 3 gives an overview of the architecture instantiated in a grid infrastructure comprised of three administrative domains, namely A, B, and C. The management application allows the developer to define the application components, specify the steps for deployment and configuration, and request the instantiation of the application. The components and deployment scripts are stored in a repository. The instantiation engine receives invocations from the management application and orchestrates the instantiation of the environment requested. Finally, instantiation services – lodged in all grid stations – supply interfaces enabling them to execute deployment, configuration, and management of components.
The interaction among architecture elements takes place as follows. First of all, using the CDL language, the developer defines the components that participate in the application (e.g., database, http server, and grid service), the deployment sequence to be respected, and the configuration parameters. The result of this phase is the generation of a set of CDL files and components that are stored in the repository. The next phase is the application instantiation request to the instantiation engine (3), which is accompanied by the identifier of the application description file location. Upon receiving the request, the instantiation engine retrieves this file (4), interprets it, and initiates the instantiation process. As the engine identifies each component in the description file, it retrieves the corresponding component from the repository. Based on the information provided by the grid scheduler (5) with relation to the resources available, the engine decides in which stations each component will be instantiated and interacts with the instantiation services of the selected stations (6). The interaction foresees operations for the deployment, configuration, and management of the components. The result of these operations – success or failure – is informed to the engine via notifications generated by the instantiation services (7).
Based on policies expressed at the engine, it automatically reacts advancing the instantiation process or executing a circumventing procedure. Finally, if the instantiation process runs successfully, the execution environment of the grid is ready to execute the application.
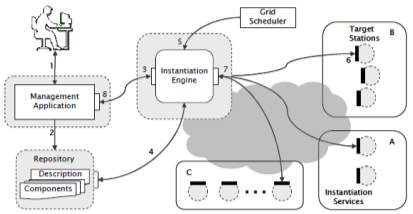
Fig-3: The AGrADC Architecture & Interactions among its components (L. P. Gaspary et al. 2009)
A Security Architecture for Grid-Based Distributed Simulation Platform
A grid-based distributed simulation platform (GDSP)[5] provides the base infrastructure for service oriented simulation platform and environment. It can run simulations efficiently on wide area network; it can reuse simulation resources, and can also improve load balancing capability of the system. GDSP provides assurance of information but the simulation must be guarded from unauthorized access. The overall structure of GDSP is shown in figure 4. Simulation Application Layer includes all kinds of simulations for specific applications. Simulation Grid Portal Layer is the interface for the interaction between simulations and users. Simulation Model Layer provides various models which are necessary to simulations. The model is the abstract of a kind of simulation federates and must be deployed to GDSP. It is grid service of WSRF (Web Services Resource Framework) and every service instance represents a federate. In this way, models need not place on the local. Users can invoke them through remote access over wide area network. And multi-users can access the different instances of the same model service simultaneously. Services can communicate with each other in spite of the diversity of programming languages and platforms.
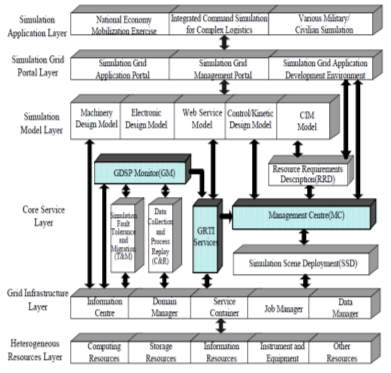
Fig-4: GDSP Architecture (H. He. et al. 2008)
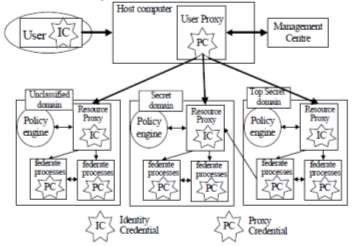
Fig-5: GDSP Security Architecture (H. He. et al. 2008)
To provide an authentication and access control infrastructure, GDSP security architecture uses mechanisms of proxy and multiple certifications. It protects system security and organizational interests, and allows simulations based on GDSP to operate securely in heterogeneous environments. The performance impact of the security architecture on GDSP is little.
Object Based Grid Architecture for Enhancing Security in Grid Computing
Object based Grid Architecture[6] act as a single system; the resources connected with the grid architecture were treated as the single components or peripherals.
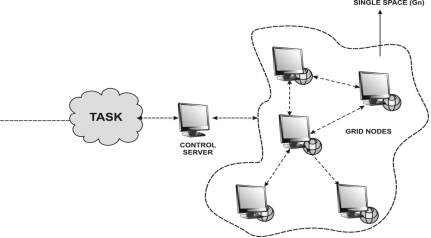
Fig-6: OGA Grid Architecture (M. V. Jose and V. Seenivasagam 2011)
OGA provides a single space grid platform to enhance the security in grid computing and to enhance the privacy in the grid computing. Each node in the grid space was considered as the objects in the MIS and the authentication process will be done in the MIS. During the authentication process the MIS will authenticate the requester with the grid node using the grid node objects. A user entering into the grid space can feel the reality of grid through the MIS virtual interface but this interface is a dynamic object maintained by the MIS and by the corresponding grid node. The node (Gn) connected with the grid environment has a separate partition according to the resource administrator allocated. In that separate partition all the process will be done.
Nimrod/G: Architecture for Resource Management and Scheduling System
The architecture of Nimrod/G[7] is shown in Figure 7 and its key components are: Client or User Station, Parametric Engine, Scheduler, Dispatcher, & Job-Wrapper.
Nimrod/G Client
Nimrod/G Client
Nimrod/G Client
Nimrod/G Client
Nimrod/G Client
Parametric Engine
Schedule Advisor
Resource Discovery
Persistent Info
Dispatcher
Grid Explorer
Grid Middleware Services
Gusto Test Bed
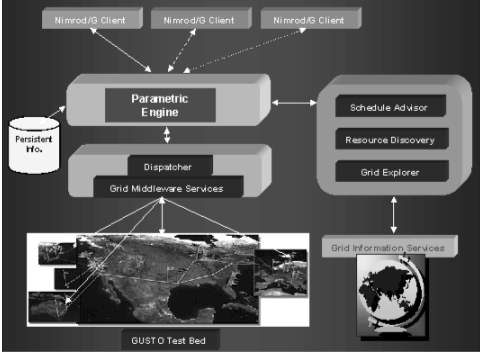
Fig-7: NIMROD/G Architecture (B. Rajkumar et al. 2000)
Client or User Station
This component acts as a user-interface for controlling and supervising an experiment under consideration. The user can vary parameters related to time and cost that influence the direction the scheduler takes while selecting resources. It also serves as a monitoring console and lists status of all jobs, which a user can view and control. Another feature client is that it is possible to run multiple instances of the same client at different locations. That means the experiment can be started on one machine, monitored on another machine by the same or different user, and the experiment can be controlled from yet another location.
Parametric Engine
The parametric engine acts as a persistent job control agent and is the central component from where the whole experiment is managed and maintained. It is responsible for parameterization of the experiment and the actual creation of jobs, maintenance of job status, interacting with clients, schedule advisor, and dispatcher. The parametric engine takes the experiment plan as input described by using our declarative parametric modeling language and manages the experiment under the direction of schedule advisor. It then informs the dispatcher to map an application task to the selected resource. The parametric engine maintains the state of the whole experiment and ensures that the state is recorded in persistent storage. This allows the experiment to be restarted if the node running Nimrod goes down.
Scheduler
The scheduler is responsible for resource discovery, resource selection, and job assignment. The resource discovery algorithm interacts with a grid-information service directory, identifies the list of authorized machines, and keeps track of resource status information. The resource selection algorithm is responsible for selecting those resources that meet the deadline and minimize the cost of computation.
DIRAC: A Scalable Lightweight Architecture for High Throughput Computing
To facilitate large scale simulation and user analysis tasks, DIRAC (Distributed Infrastructure with Remote Agent Control)[8] has been developed. DIRAC can be decomposed into four sections: Services, Agents, Resources, and User Interface, as illustrated in figure 8.
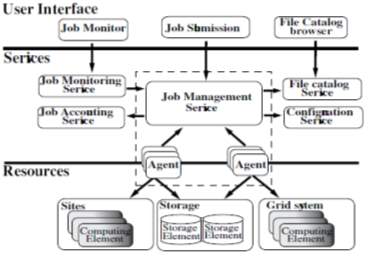
Fig-8: DIRAC Architecture (A. Tsaregorodtsev et al. 2004)
The core of the system is a set of independent, stateless, distributed services. The services are meant to be administered centrally and deployed on a set of high availability machines. Resources refer to the distributed storage and computing resources available at remote sites. Access to these resources is abstracted via a common interface. Each computing resource is managed autonomously by an Agent, which is configured with details of the site and site usage policy by a local administrator. The Agent runs on the remote site, and manages the resources there, monitors and submits job.
Jobs are created by users who interact with the system via the Client components. All jobs are specified using the ClassAd language, as are resource descriptions. These are passed from the Client to the Job Management Services (JMS), allocated to the Agents on-demand, submitted to Computing Elements (CE), executed on a Worker Node (WN), returned back to the JMS and finally retrieved by the user. Jobs are only run when resources are not in use by the local users. It operates only when there are completely free slots, rather than fitting in short jobs ahead of future job reservations. DIRAC has started to explore potentials for distributed computing from instant messaging systems. High public demand for such systems has led to highly optimized packages which utilize well defined standards, and are proven to support thousands of simultaneous users.
Agora Architecture
Agora[9] is an implementation of Virtual Organization. It manages users and resources. It has instances which provide policies to support a MAC hybrid cross-domain access control mechanism. These instances also maintain the context of operations. The architecture is shown in figure 9. It consists of three layers –
- First is the physical layer that contains external resources. It uses an abstraction RController to manipulate external resources.
- Second is the naming layer. All the GNodes are managed by this layer. GNodes include all the entities, users, resources, and agora instances.
- Third is the logic layer that implements all the Agora functionalities.
There are five basic concepts in Agora architecture: resource, user, agora, application, and grip. These five concepts have close relationship. In a word, an application is represented and managed by a grip, runs on behave of a user in a specified agora, and may access the authorized resources in the agora.
Resource: A resource is an entity providing some functions. There are external resources and internal resources. External resources are hosted in the real world, such as CPU, memory, disk, network, server, job queue, software, file, data, etc. Internal resources are managed by Agora in a uniform way. Service is an example of an internal resource.
User: A user is a subject who uses resources. There are three kinds of users in GOS: host users, GOS users and application users. A host user is a user in the local operating system. A GOS user is a global user. An application user is a user who is managed by a GOS application.
Agora: An agora instance, or agora, is a virtual organization for a specific purpose. An agora organizes interested users and needed resources define the access control policies, and forms a resource sharing context.
Application: An application is a software package providing some functions based on resources to end users.
Grip: A grip is a runtime construct to represent a running instance of an application. A grip is used to launch, monitor, and kill an application and to maintain context for the application.
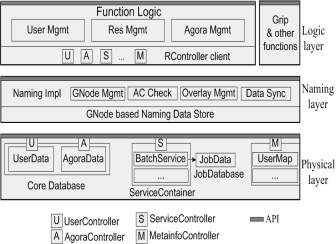
Fig-9: AGORA Architecture (Y. Zou et al. 2010)
PerLa: A Language and Middleware Architecture for Data Management and Integration in Pervasive Information Systems
The development of the PerLa[10] System focused on the design and implementation of the following features:
- data-centric view of the pervasive systems,
- homogeneous high-level interface to heterogeneous devices,
- support for highly dynamic networks (e.g., wireless sensor networks),
- Minimal coding effort for new device addition.
The result of this approach is the possibility of accessing all data generated by the sensing network via an SQL-like query language, called the PerLa Language, that allows end users and high-level applications to gather and process information without any knowledge of the underlying pervasive system. Every detail needed to interact with the network nodes, such as hardware and software idiosyncrasies, communication paradigms and protocols, computational capabilities, etc., is completely masked by the PerLa Middleware.
The PerLa Middleware provides great scalability both in terms of number of nodes and types of nodes. Other middlewares for pervasive systems only support deployment-time network configuration or provide runtime device addition capabilities for a well defined class of sensing nodes at best (e.g., TinyDB). These limitations are no longer acceptable. In modern pervasive systems, specifically wireless sensor networks, nodes can hardly be considered “static” entities. Hardware and software failures, device mobility or communication problems can significantly impact the stability of a sensing network. The ever-increasing presence of transient devices like PDAs, smart-phones, personal biometric sensors, and mobile environmental monitoring appliances makes the resilience to network changes an essential feature for a modern pervasive system middleware. Support for runtime network reconfigurability is therefore a necessity. Moreover, the middleware should also be able to detect device abilities and delegate to them whichever computation they can perform. The tasks that nodes are unable to perform should be executed by the middleware. PerLa fulfills these requirements by means of a Plug & Play device addition mechanism. New types of nodes are registered in the system using an XML Device Descriptor. The PerLa Middleware, upon reception of a device descriptor, autonomously assembles every software component needed to handle the corresponding sensor node. End users and node developers are not required to write any additional line of code.
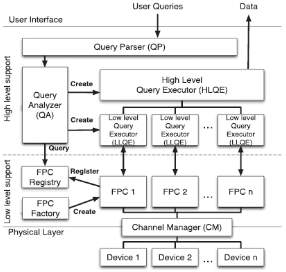
Fig-10: Perla Architecture (F. Schreiber and R. Camplani 2012)
The PerLa architecture[10] is composed of two main elements. A declarative SQL-like language has been designed to provide the final user with an overall homogeneous view on the whole pervasive system. The provided interface is simple and flexible, and it allows users to completely control each physical node, masking the heterogeneity at the data level. A middleware has been implemented in order to support the execution of PerLa queries, and it is mainly charged to manage the heterogeneity at the physical integration level. The key component is the Functionality Proxy Component, which is a Java object able to represent a physical device in the middleware and to take the device’s place whenever unsupported operations are required. In this paper, we have not investigated some optimizations that can improve the performance of the middleware and the expressiveness of the language.
MonALISA – a Distributed Monitoring Service Architecture
MonALISA[11] stands for Monitoring Agents in A Large Integrated Services Architecture. It provides a distributed monitoring service and is based on a scalable Dynamic Distributed Services architecture. This architecture is implemented using JINI/JAVA and WSDL/SOAP technologies. The system provides scalability by using multithreaded Station Servers to host a variety of loosely coupled self-describing dynamic services. Each service has the ability to register itself and then to be discovered and used by any other services or clients. All services and clients have the ability to subscribe to a set of events in the system to be notified automatically. The framework provided by MonALisa integrates many existing monitoring tools and procedures to collect parameters describing application, computational nodes and network performance. It has built-in network protocol support and network-performance monitoring algorithms with which it monitors end-to-end network performance as well as the performance and facilities.
An Architecture for Reliable Mobile Workflow in a Grid Environment[12]
Mobile workflow peers (MWPs) are mobile devices that can connect to grids and participate in workflows. Grid Proxies (GPs) are fixed grid nodes with sufficient resources to allow mobile peers to connect to and participate in workflows on the grid. Because MWPs may be part of different networks they cannot communicate directly with each other, or with other grid nodes; instead they communicate only with the GPs. Each MWP can be in one of the following states: Connected (i.e. on line) or Unavailable (i.e. off line or otherwise busy).
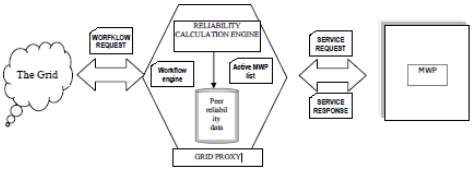
Fig-11: Mobile grid workflow system Architecture[12]
(B. Karakostas and G. Fakas 2009)
A GP keeps track of connected MWPs using a ‘heartbeat’ protocol that involves a periodic sending of a message to a MWP and waiting for a response. If no response is received within a timeout period, the GP considers the MWP unavailable. For each MWP, the GP maintains an index of its reliability, based on the number of disconnections over a certain period. A GP also calculates as the average reliability of the registered MWPs GPs advertise to the grid the services of MWPs that have been registered with them. A GP receives an invitation to participate in a grid workflow by providing a service. The GP can accept the invitation to execute a workflow activity by delegating its execution to a registered MWP. The MWP remains transparent as far as the workflow process and the other grid participants are concerned, as all the interaction of the workflow process is with the GP (Figure 11). However the GP relies on its connected MWPs to actually perform the activity. GP cannot guarantee at the time of the service request, that a suitable, registered MWP will be online. Instead, a GP must perform a reliability calculation to determine the degree of redundancy required to meet the workflow deadlines. This means that the GP will delegate the execution of the activity to multiple MWPs to ensure that one of those will be available to provide the service with an acceptable probability.
MAGDA: A Mobile Agent based Grid Architecture
MAGDA – Mobile Agents based Grid Architecture[13], is conceived in order to provide secure access to a wide class of services in a distributed heterogeneous system, geographically distributed. MAGDA is a layered architecture. Figure 12 shows a listing of MAGDA components and services at each Layer of the Grid model.
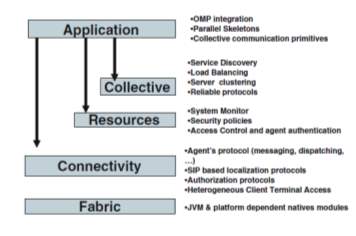
Fig-12: MAGDA Architecture (R. Aversa et al. 2006)
A mobile agent based middleware could be integrated within a Grid platform in order to provide each architecture with the facilities supported in the other one. In general current middleware are not able to migrate an application from one system to another as there are a lot of issues to be addressed. Some examples are the differences across resources in installed software, file system structures, and default environment settings. On the other side reconfiguration is a main issue to implement dynamic load balancing strategies.
BIGS Architecture
BIGS[14], the Big Image Data Analysis Toolkit, a software framework conceived to exploit computing resources of different nature for image processing and analysis tasks. Through its architecture BIGS offers a clear separation of roles for contributing developers and decouples functionality for storage from algorithms implementation, from core development and from deployment packaging.
BIGS architecture is conceived with two goals in mind: (1) to provide an extensible framework where new tasks (algorithms), task patterns, storage interfaces and worker deployment technologies can be integrated; and (2) to encourage a clear separation of roles for contributors to the project through source code decoupling. This is achieved by establishing a set of APIs (Application Programming Interfaces) which decouple BIGS components from each other and against which different BIGS developers implement their code, as shown in Figure 13.
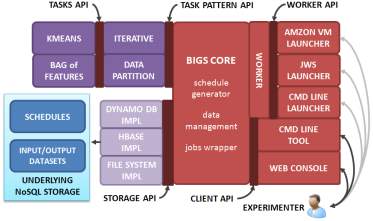
Fig-13: BIGS Architecture (R. Ramos-Pollan et al. 2012)
Each API or component defines the roles of the contributors to BIGS architecture.
Sintok Grid
Sintok-Grid[15] is a Grid used at the University Utara, Malaysia. Its basic architecture is shown in Figure 14 that depicts how the main nodes in the network are connected together and to the public network. This basic architecture consists of two network segments, namely the internal network and the external (public) network. All the servers of the Sintok-Grid are hosted by the internal network and the other grid sites in the Academic Grid Malaysia are hosted by the public network.
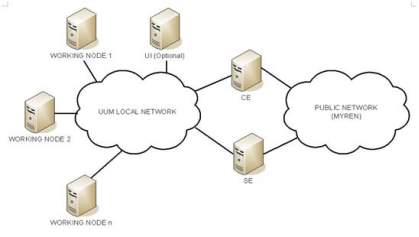
Fig-14: Sintok Grid Architecture (M. S. Sajat et al. 2012)
The Sintok-Grid is a part of the larger A-Grid system, so the server nodes need to be visible and should be accessed from networks outside the Grid. Hence the servers were configured with public IP addresses. To make the grid system accessible from outside, the servers can be enabled to be identified using hostnames rather than IP addresses. For this the Domain Name Server (DNS) should be fully configured so that for each public IP address, forward and reverse lookups are supported. Reverse lookups helps in detecting intrusions and protects the servers from outside attacks. So a DNS system was setup to make the Sintok-Grid seamlessly integrate with the A-Grid. The bandwidth between the WNs and the network, or WAN cloud, plays a major role in the overall performance of the system. The network bandwidth should accommodate all the data and the command requests and responses that are transferred between the public network and the local network. The bandwidth of the internet link is sufficient to handle the expected traffic in Sintok-Grid. The system must be installed with the right software especially the operating system, middleware and virtualization software, once the hardware of the grid system and the network has been installed. In the current implementation of the Sintok-Grid, Scientific Linux 5.x, gLite 3.2 and Proxmox 1.8 have been selected as the operating system, middleware and virtualization platform respectively. Specific elements of the grid system such as CE, SE, UI and IS require specific installation process to be followed.
SUNY (The State University of New York) POC Project [16]
In late 2007 and early 2008, Dell Database and Applications teams partnered with SUNY ITEC and Oracle in a Proof-Of-Concept (POC) project. In this project, the Banner ERP application systems are consolidated through grid computing into a single Grid that is made of Dell servers and storage. The goal of this project was to demonstrate that the Grid running Banner ERP applications can scale to handle 170,000 students in the databases with 11,000 students simultaneous registering for courses and performing others tasks and with around 70,000 courses being selected in one hour, 37 times the actual number seen at a SUNY[16] school of 110,000 students.
Features offered by Oracle 10g and 11g to build the Grid computing model are:-
- A scalable and highly available database clusters is offered by clustering technology.
- As a service directs database connections from an application to one or more database instances, Database services allow applications to become independent from the physical implementation of service. This redirection makes it easy to dynamically connect to other set of database instances with its load-balancing feature.
- Automatic Storage Management is provided.
- Central monitoring, managing and provisioning the entire Grid infrastructure is provided by Oracle Enterprise Manager Grid Control.
- With Load balancing feature, it can be ensured that the workloads of applications can be distributed among the database instances.
Conceptual Framework for Collaborative Business based on Service Oriented
Grid Computing
A conceptual framework for collaborative business of a platform that is based on SOA and Grid computing is shown in Figure 15:
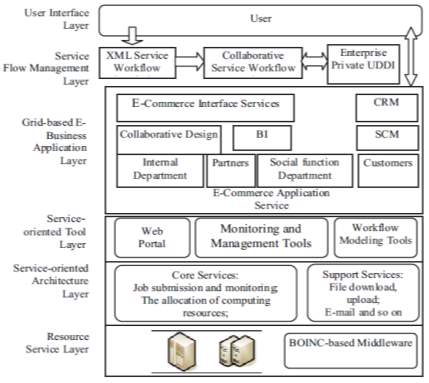
Fig-15: Architecture of Collaborative Business Platforms based on SOA and Grid Service
- Resource Service Layer: This layer represents the computing resources and data resources that are distributed on the Internet. It also provides various resource call services such as the computing power storage capacity and security. This layer is the resource foundation of the collaborative business platform.
- Service-oriented Architecture Layer: This layer is located above the level of resources, providing interface access to the underlying resources layer: In order to support service-based grid application development, operation, deployment and debugging, the service-oriented architecture layer focuses on solving the various types of resource sharing and synergy. Users can submit and monitor jobs, suspend operations, and conduct the remote operation through the Job submission and monitoring service from this layer. Data resource management can process data distribution, replication, resource synchronization and can also manage meta-data.
- Service-oriented Tool Layer: This layer provides users with a consistent user and access interface (such as Web-based service portal). Also, it provides programming modeling tools for debugging and simulation, monitoring and management workflow for the grid application. A variety of tools and API simplify grid application development, deployment, debugging and management.
- Grid-based E-Business Application Layer: This layer contains a Web Service-based Grid application system, which includes all of the collaborative business and enterprise application services. A collaborative business platform integrates a variety of applications and functions which are encapsulated in a grid service. Furthermore, information on external partners, communication, social functions and the interaction among customers and other services are included in this layer.
- Service Flow Management Layer. This layer consists of three parts: XML service workflow description, collaborative workflow engine and business UDDI registration. XML service workflow description, composed in XML markup language, is used for collaborative business process description, and to store the files in order according to the call sequence of their description.
- The User Interface Layer. This layer is used for interactions and operations between end users through a simple and user-friendly interface. The user interface layer also provides visualization tools which enable users to customize the collaborative business workflow which is also called XML workflow description file.
2.3 GRID MIDDLEWARE APPROACHES
We have surveyed different grid middleware and their security solutions with the objective to find out what is presently available, the available security solution and what can be done to improve the available security solution. We also analyzed how efficient is the middleware in terms of its security solution. Some of the middleware we studied are as given below –
- UNICORE [17][18]
- GLOBUS [19]
- GridSim [20][21]
- Sun Grid Engine [22] [23]
- Alchemi [24][25]
- HTCondor [26]
- GARUDA[27]
- Entropia [28], [29]
- Xgrid [30]
- iDataGuard [31]
- Middleware for Mobile Computing[32]
- Selma [33]
- XtremWeb [34]
UNICORE
UNICORE [17] [18] stands for Uniform Interface to Computing Resources. It was developed in Germany to enable their supercomputer centers to provide their users with an intuitive, seamless and secure access to the resources. Its objectives were to hide the seams resulting from different hardware architectures, vendor specific operating systems, incompatible batch systems, different application environments, historically grown computer center practices, naming conventions, file system structures, and security policies. Also security was needed from the start relying on the emerging X.509 standard for certificates authenticating servers, software, and users and encrypting the communication over the internet.
UNICORE provides extensive set of services such as –
- Job creation
- Job management
- Data management
- Application support
- Flow control
- Meta-computing
- Interactive support
- Single sign-on
- Support for legacy jobs
- Resource management
UNICORE assumes that all resources that are consumed are to be accounted for and that the centers are accountable to their governing bodies. UNICORE provides the technical infrastructure which allows the centers to pool and exchange their resources either in total or in part.
The UNICORE Architecture
UNICORE creates a three-tier architecture depicted in Figure 3 at each UNICORE site. The UNICORE client supports the creation, manipulation, and control of complex jobs, which may involve multiple systems at one or more UNICORE sites. The user are represented as Abstract Job Objects, effectively Java classes, which are serialized and signed when transferred between the components of UNICORE.
The server level of UNICORE consists of a Gateway, the secure entry point into a UNICORE site, which authenticates requests from UNICORE clients and forwards them to a Network Job Supervisor (NJS) for further processing. The NJS maps the abstract request, as represented by the AJO, into concrete jobs or actions which are performed by the target system, if it is part of the local UNICORE site. Sub-jobs that have to be run at a different site are transferred to this site’s gateway for subsequent processing by the peer NJS. Functions of NJS are: synchronization of jobs to honor the dependencies specified by the user, automatic transfer of data between UNICORE sites as required for job execution, collection of results from jobs, especially stdout and stderr, import and export of data between the UNICORE space and target system, and client workstation.
The third tier of the architecture is the target host which executes the incarnated user jobs or system functions. A small daemon, called the Target System Interface (TSI) resides on the host to interface with the local batch system on behalf of the user. A stateless protocol is used to communicate between NJS and TSI. Multiple TSIs may be started on a host to increase performance.
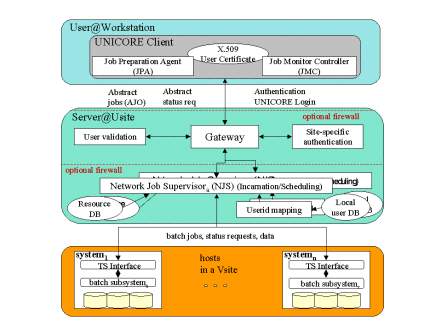
Fig-16: Unicore Architecture (U. T. June 2010)
Grid Services Used
Security: Certificates according to the X.509V3 standards, provide the basis of UNICORE’s security architecture. Certificates serve as grid-wide user identifications which are mapped to existing Unix accounts with the option to follow established conventions. Certificates also mutually authenticate peer systems in a grid. For a smooth procedure all members of a grid should use the same certificate authority (CA) for both user and server certificates. Handling user certificates from different certificate authorities pose no technical problem: If Grid-A requires certificates from CA-A, and Grid-B only accepts those issued by CA-B, a UNICORE client can handle multiple certificates and the user will have to select the correct one when connection to either Grid-A or Grid-B. This is not different from the present situation with users having different accounts on different systems; now they have a different identity for each grid.
Resources: UNICORE relies on descriptions of resources (hardware and software) which are available at run job creation and submission time to the client. Standards defined by the working groups of the Global Grid Forum on Grid Information Services and Scheduling and Resource Management are valuable for future releases of UNICORE, especially for a resource broker. A replacement of the internal representation of resources will be transparent to the user.
Data: The UNICORE data model includes a temporary data space, called Uspace, which functions as a working directory for running UNICORE jobs at a Usite. The placement of the Uspace is fully under the control of the installation. UNICORE implements all functions necessary to move data between the Uspace and the client. This is a synchronous operation controlled by the user. No attempt is presently made top push data to the desktop from the server. Data movement between Uspace and file systems at a Vsite is specified by the user explicitly or by application support in the client exploiting knowledge about data requirements of the application. NJS controls the data movement which may result in Unix copy command or in a symbolic link to the data. Transfer of data between Usites is equally controlled by NJS. Currently, the data is transferred using a byte streaming protocol or within an AJO for small data sets.
Security is maintained in the UNICORE system by single sign-on. For this it uses X.509 version 3 certificates. Prior to use the system, the user must configure their client to use their digital certificate, imported into the Java file called as “keystore”. The user must also import the CA – certificate authority certificates for the resources that they want to access and use. When the client is started, the user has to give their password to unlock the “keystore” file. After this, when the client submits a job to the system, it uses the certificate to digitally sign the AJO (Abstract Job Object), that are the collection of java classes, before it is transmitted to the NJS (Network Job Supervisors) that is the server. After this the signature is verified using a copy of the user’s certificate maintained at the server, If verified, the identity of the user is established.
The X.509 certificate works as follows – Asymmetric key algorithms of cryptography are used in which the encryption and decryption keys are different. Thus it uses public key encryption mechanism. This set up is also called PKI (Public Key Infrastructure).
Two things can be ensured in UNICORE with X.509 certificates:
- Each client or server can prove its identity. It is done by presenting its certificate containing the public key and providing evidence of the private key.
- Encrypted messages can be read by private key only. This way an encrypted communication channel between different users on the Grid is established. The protocol uses the Secure Sockets Layer (SSL) mechanism.
GLOBUS
Globus[19] [32] [33] is:
- A community of users and developers who collaborate on the use and development of open source software, and associated documentation, for distributed computing and resource federation.
- The software itself—the Globus Toolkit: a set of libraries and programs that address common problems that occur when building distributed system services and applications.
- The infrastructure that supports this community — code repositories, email lists, problem tracking system, and so forth.
The software itself provides a variety of components and capabilities, including the following:
- A set of service implementations focused on infrastructure management.
- A powerful standards-based security infrastructure.
- Tools for building new Web services, in Java, C, and Python.
- Both client APIs (in different languages) and command line programs for accessing these various services and capabilities.
Detailed documentation on these various components, their interfaces, and how they can be used to build applications is available. These components in turn enable a rich ecosystem of components and tools that build on, or interoperate with, GT components—and a wide variety of applications in many domains. From our experiences and the experiences of others in developing and using these tools and applications, we identify commonly used design patterns or solutions, knowledge of which can facilitate the construction of new applications.
There are many tools to develop application in grid computing, GT5[37] is the one of the tool using which you can create application in grid computing or middleware of grid computing architecture. The open source Globus Toolkit is a fundamental enabling technology for the “Grid”. It provides facility to share computing power, databases, and other tools securely online across industry, institutional, and geographic boundaries without sacrificing personal freedom. It contains software services and libraries for resource monitoring, discovery, and management, and in addition security and file management.
COMPONENTS OF GT 5.2[38]
- Data Management
- GridFTP
- Jobs Management
- GRAM5
- Security
- GSI C
- MyProxy
- GSI-OpenSSH
- SimpleCA
- Common Runtime
- C Common Libraries
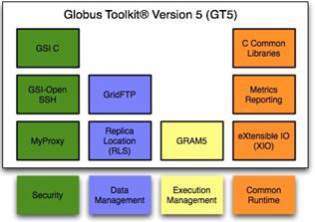
Fig-17: GT5 Components (M. K. Vachhani and K. H. Atkotiya 2012)
(A) GridFTP:
The GridFTP[39] protocol was defined to make the transport of data secure, reliable, and efficient for these distributed science collaborations. The GridFTP protocol extends the standard File Transfer Protocol (FTP) with useful features such as Grid Security Infrastructure (GSI) security, increased reliability via restart markers, high performance data transfer using striping and parallel streams, and support for third-party transfer between GridFTP servers.
One of the foundational issues in HPC computing is the ability to move large (multi Gigabyte, and even Terabyte), file-based data sets between sites. Simple file transfer mechanisms such as FTP and SCP are not sufficient either from a reliability or performance perspective. GridFTP extends the standard FTP protocol to provide a high-performance, secure, reliable protocol for bulk data transfer.
GridFTP is a protocol defined by Global Grid Forum Recommendation GFD.020, RFC 959, RFC 2228, RFC 2389, and a draft before the IETF FTP working group. Key features include:
- Performance – GridFTP protocol supports using parallel TCP streams and multi-node transfers to achieve high performance.
- Checkpointing – GridFTP protocol requires that the server send restart markers (checkpoint) to the client.
- Third-party transfers – The FTP protocol on which GridFTP is based separates control and data channels, enabling third-party transfers, that is, the transfer of data between two end hosts, mediated by a third host.
- Security – Provides strong security on both control and data channels. Control channel is encrypted by default. Data channel is authenticated by default with optional integrity protection and encryption.
Globus Implementation of GridFTP:
The GridFTP protocol provides for the secure, robust, fast and efficient transfer of (especially bulk) data. The Globus Toolkit provides the most commonly used implementation of that protocol, though others do exist (primarily tied to proprietary internal systems).
The Globus Toolkit provides:
- a server implementation called globus-gridftpserver,
- a scriptable command line client called globusurl-copy, and
- a set of development libraries for custom clients.
While the Globus Toolkit does not provide a client with Graphical User Interface (GUI), Globus Online provides a web GUI for GridFTP data movement.
(B) GRAM5:
Globus implements the Grid Resource Allocation and Management (GRAM5)[38] service to provide initiation, monitoring, management, scheduling, and/or coordination of remote computations. In order to address issues such as data staging, delegation of proxy credentials, and job monitoring and management, the GRAM server is deployed along with Delegation and Reliable File Transfer (RFT) servers. GRAM typically depends on a local mechanism for starting and controlling the jobs. To achieve this, GRAM provides various interfaces/adapters to communicate with local resource schedulers (e.g. Condor) in their native messaging formats. The job details to GRAM are specified using an XML-based job description language, known as Resource Specification Language (RSL).
RSL provides syntax consisting of attribute-value pairs for describing resources required for a job, including memory requirements, number of CPU’s needed etc. GSI C, MyProxy and GSI-OpenSSH for Grid Security: These components establish the identity of users or services (authentication), protect communications, and determine who is allowed to perform what actions (authorization), as well as manage user credentials.
(C) Grid Security Infrastructure in C (GSI C):
The Globus Toolkit GSI C component[19] provides APIs and tools for authentication, authorization and certificate management. The authentication API is built using Public Key Infrastructure (PKI) technologies, e.g. X.509 Certificates and TLS. In addition to authentication it features a delegation mechanism based upon X.509 Proxy Certificates. Authorization support takes the form of a couple of APIs. The first provides a generic authorization API that allows callouts to perform access control based on the client’s credentials (i.e. the X.509 certificate chain). The second provides a simple access control list that maps authorized remote entities to local (system) user names. The second mechanism also provides callouts that allow third parties to override the default behavior and is currently used in the Gatekeeper and GridFTP servers. In addition to the above there are various lower level APIs and tools for managing, discovering and querying certificates. GSI uses public key cryptography (also known as asymmetric cryptography) as the basis for its functionality.
D) MyProxy:
MyProxy[19] is open source software for managing X.509 Public Key Infrastructure (PKI) security credentials (certificates and private keys). MyProxy combines an online credential repository with an online certificate authority to allow users to securely obtain credentials when and where needed. Users run myproxy-logon to authenticate and obtain credentials, including trusted CA certificates and Certificate Revocation Lists (CRLs).
(E) GSI-OpenSSH:
GSI-OpenSSH[40] is a modified version of the OpenSSH secure shell server that adds support for X.509 proxy certificate authentication and delegation, providing a single sign-on remote login and file transfer service. GSI-OpenSSH can be used to login to remote systems and transfer files between systems without entering a password, relying instead on a valid proxy credential for authentication. GSI-OpenSSH forwards proxy credentials to the remote system on login, so commands requiring proxy credentials (including GSI-OpenSSH commands) can be used on the remote system without the need to manually create a new proxy credential on that system.
The GSI-OpenSSH distribution provides gsissh, gsiscp, and gsiftp clients that function equivalently to ssh (secure shell), scp (secure copy), and sftp (secure FTP) clients except for the addition of X.509 authentication and delegation.
GridSim [20]
Modeling and simulation of a wide range of heterogeneous resources, single or multiprocessors, shared and distributed memory machines, and clusters are supported by the GridSim[20], [21], [41], [42] toolkit. The GridSim resource entities are being extended to support advanced reservation of resources and user-level setting of background load on simulated resources based on trace data.
The GridSim toolkit supports primitives for application composition and information services for resource discovery. It provides interfaces for assigning application tasks to resources and managing their execution. It also provides visual modeler interface for creating users and resources. These features can be used to simulate parallel and distributed scheduling systems. The GridSim toolkit has been used to create a resource broker that simulates Nimrod/G for the design and evaluation of deadline and budget constrained scheduling algorithms with cost and time optimizations. It is also used to simulate a market-based cluster scheduling system (Libra) in a cooperative economy environment. At the cluster level, the Libra scheduler has been developed to support economy-driven cluster resource management. Libra is used within a single administrative domain for distributing computational tasks among resources that belong to a cluster. At the Grid level, various tools are being developed to support a quality-of-service (QoS) – based management of resources and scheduling of applications. To enable performance evaluation, a Grid simulation toolkit called GridSim has been developed.
The Gridbus Project is engaged in the design and development of grid middleware technologies to support eScience and eBusiness applications. These include visual Grid application development tools for rapid creation of distributed applications, cooperative economy based cluster scheduler, competitive economy based Grid scheduler, Web-services based Grid market directory (GMD), Gridscape for creation of dynamic and interactive testbed portals, Grid accounting services, and G-monitor portal for web-based management of Grid applications execution.
The Gridbus Project has developed Windows .NET based desktop clustering software and Grid job web services to support the integration of both Windows and Unix-class resources for Grid computing. A layered architecture for realisation of low-level and high-level Grid technologies is shown in Figure 18.
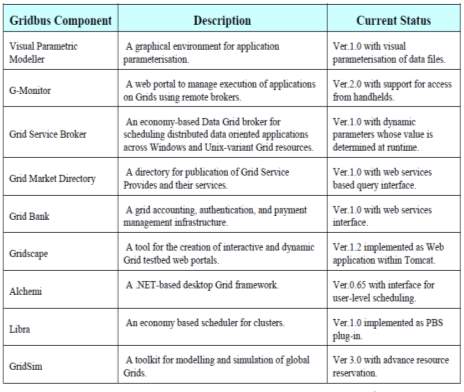
Fig-18: Gridbus technologies and their status (R. Buyya and M. Murshed 2002)
Sun Grid Engine [22], [23]
Sun Grid Engine (SGE) was a grid computing computer cluster software system (otherwise known as a batch-queuing system), then improved and supported by Sun Microsystems. The original Grid Engine open source project website closed in 2010, but versions of the technology are still available under its original Sun Industry Standards Source License. Grid Engine is typically used on a computer farm or high performance computing (HPC) cluster and is responsible for accepting, scheduling, dispatching, and managing the remote and distributed execution of large numbers of standalone, parallel or interactive user jobs. It also manages and schedules the allocation of distributed resources such as processors, memory, disk space, and software licenses.
In 2010, Oracle Corporation acquired Sun and thus renamed Sun Grid Engine to Oracle Grid Engine. The Oracle Grid Engine 6.2u6 source code was not included with the binaries, and changes were not put back to the project’s source repository. In response to this, the Grid Engine community started the Open Grid Scheduler and the Son of Grid Engine projects to continue to develop and maintain a free implementation of Grid Engine. On January 18, 2011, Univa announced that it had hired the principal engineers from the Sun Grid Engine team. On October 22, 2013 Univa announced that it had acquired Oracle Grid Engine assets and intellectual property making it the sole commercial provider of Grid Engine software. Univa Grid Engine 8.0 was the first version, released on April 12, 2011. It was forked from SGE 6.2u5, the last open source release. It adds improved third party application integration, license and policy management, enhanced support for software and hardware platforms, and cloud management tools. Univa Grid Engine 8.3.1 was released on August 28, 2015. This release contained all of the new features in Univa Grid Engine 8.3.0. Univa Grid Engine 8.4.0 was released on May 31, 2016. This release supports Docker containers and will automatically dispatch and run jobs with a user specified Docker Image.
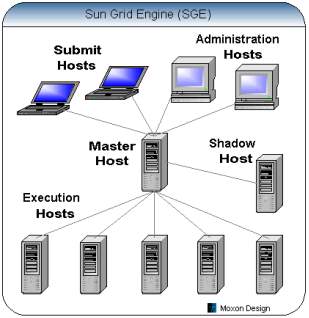
Fig-19: Sun Grid Engine Architecture (Daniel 2014)
As you can see from the above diagram, the SGE is built around a Master Host (qmaster) that accepts requests from the Submit and Administration Hosts and distributes workload across the pool of Execution Hosts. The SGE system uses client-server architecture, and uses NFS file systems and TCP/IP sockets to communicate between the various hosts. The new Sun Grid Engine Enterprise Edition (SGEEE) software manages the delivery of computational resources based on enterprise resource policies set by the organization’s technical and management staff. SGEEE software uses the enterprise resource policies to examine the locally available computational resources, and then allocates and delivers those resources.
In Sun Grid Engine, secret key encryption is used for the messages. The public key algorithm is used to exchange the private key. The user has to present certificate to prove identity, and in response he receives a certificate from the system. This ensures that the communication is correct and valid. This establishes a session for communication. After this, the communication continues in encrypted form only. Being valid only for a limited and certain period, the session ends accordingly. To continue the communication, session has to be reestablished.
Alchemi [25], [43]
Alchemi, a .NET based framework that provides the runtime machinery and programming environment required to construct enterprise/desktop grids and develop grid applications. It allows flexible application composition by supporting an object-oriented application programming model in addition to a file-based job model. Cross-platform support is provided via a web services interface and a flexible execution model supports dedicated and non-dedicated (voluntary) execution by grid nodes. Alchemi was conceived with the aim of making grid construction and development of grid software as easy as possible without sacrificing flexibility, scalability, reliability and extensibility. Alchemi follows the master worker parallel programming paradigm in which a central component dispatches independent units of parallel execution to workers and manages them. In Alchemi, this unit of parallel execution is termed ‘grid thread’ and contains the instructions to be executed on a grid node, while the central component is termed ‘Manager’. A ‘grid application’ consists of a number of related grid threads. Grid applications and grid threads are exposed to the application developer as .NET classes / objects via the Alchemi .NET API.
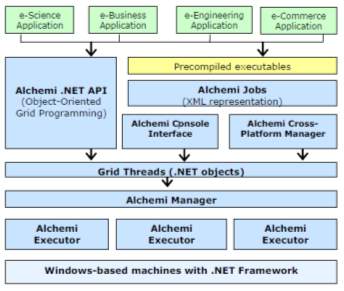
Fig-20: Alchemi .Net Architecture (A. Luther et al. 2005)
When an application written using this API is executed, grid thread objects are submitted to the Alchemi Manager for execution by the grid. Alternatively, file-based jobs (with related jobs comprising a task) can be created using an XML representation to grid-enable legacy applications for which precompiled executables exist. Jobs can be submitted via Alchemi Console Interface or Cross-Platform Manager web service interface, which in turn convert them into the grid threads before submitting then to the Manager for execution by the grid. Alchemi middleware system uses a role-based authentication security model, a thread model to execute and submit jobs and a cross platform web service model for interoperability. Jobs are represented as XML files. Base64 encoding decoding is used. But it does not support single sign-on and delegation mechanism. With the use of X.509 proxy certificates, these mechanisms are implemented on the Alchemi framework. In order to perform this implementation, a trusted communication is set up between two hosts. Then the client host will be authenticated by the server host. After authentication, Client gets access of various applications provided by the framework with full delegation rights.
HTCondor [26]
Condor is a distributed environment designed for high throughput computing (HTC) and CPU harvesting. CPU harvesting is a process of exploiting non-dedicated computers (e.g. desktop computers) when they are not used. Condor-G is a High-throughput scheduler supported by Grid Resource Allocation Management (GRAM) component of Globus. It uses non-dedicated resources to schedule the jobs. Processing huge amounts of data on large and scalable computational infrastructures is gaining increasing importance.
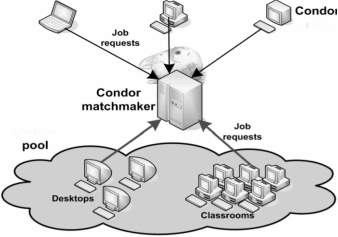
Fig-21: CONDOR Architecture (J. Frey et al. 2001)
Heart of the system is Condor Matchmaker. Users describe their applications with ClassAds language and submit them to Condor. ClassAds allows users to define custom attributes for resources and jobs. On the other side, resources publish information to Matchmaker. Condor then matches job requests with available resources. Condor provides numerous advanced functionalities such as job arrays and workflow support, check pointing, job migration. It enables users to define resource requirements, rank resources and mechanism for transferring files to/from remote machines.
Condor-G is the job management part of Condor. Condor-G allows the users to submit jobs into a job queue having a log maintaining the life eyc1e of the jobs, managing the input and output files. Condor-G uses the Globus Toolkit to start the job on the remote machine instead of using the Condor developed protocols. Condor-G allows users to access both resources and manage jobs running on remote resources. Condor-G manages the job queue and the resources from various sites where the jobs can execute. Using Globus mechanisms Condor-G communicates and transfers the files to and from those resources. Condor-G uses the GRAM for submission of jobs, and it runs a local GASS (Global Access to Secondary Storage) server for file transfers. It allows users to submit many jobs at once and then monitors those jobs with interface and receives notification when job execution completes or job fails to execute.
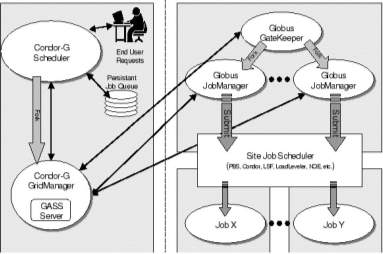
Fig-22: Condor Globus Interaction (J. Frey et al. 2001)
Fig. 22 shows how Condor-G interacts with Globus toolkit. It contains a GASS (Global Access to Secondary Storage) server which is used to transfer the executable, standard input, output and error files to and from the remote job execution site. Condor-G uses the Globus Resource Allocation Manager (GRAM) to contact the remote Globus Gatekeeper to start a new job manager and to monitor the progress of job. Condor-G has the ability to detect and intelligently handle, if the remote resource crashes.
In HTCondor (High throughput computing Condor) the security is applied through authentication mechanism by using authentication methods like GSI authentication, Windows authentication, Kerberos authentication, file system authentication etc. Users use public key certificates in GSI authentication as a result problem of identity spoofing persists. Checkpoint servers are also used but they can be replaced maliciously resulting in poor retrieval of data. In Condor system, the problem of DoS persists that is “Denial of Service” if proper access permissions are not set. Even the configuration files and log files can be changed. The user gets full access of the job once he submits it. This means, he even can change the owner of the job.
Hadoop [44]
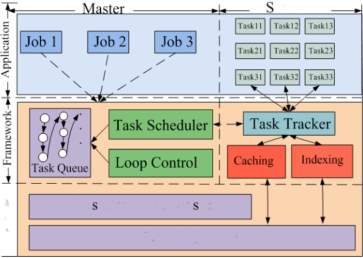
Fig-23: Hadoop Framework Architecture (K. Shvachko et al. 2010)
Fig. 23 shows the Hadoop framework architecture. A Hadoop cluster makes use of the slave nodes to execute map and reduce tasks. Each slave node has a fixed number of map slots and reduces slots that they are executed simultaneously. Slave node sends a heartbeat signal to the master node. Upon receiving the signal from a slave node that has empty map/reduce slots, the master node invokes the Map-Reduce scheduler to assign tasks to the slave node. The slave node then reads the contents of the corresponding input data block, parses input key/value pairs out of the block, and passes each pair to the user defined map function. The output of map function is the intermediate key/value pairs, which then buffered in memory, and written to the local disk and partitioned into R regions by the portioning function. The locations of these intermediate data are passed to the master node. The master node forwards these locations to reduce tasks. A reduce task uses remote procedure calls to read the intermediate data generated by the M map tasks of the job. Each reduce task is responsible for a region of intermediate data and it has to retrieve its partition of data from all slave nodes that have executed the M map tasks. This process of shuffling involves many-to-many communications among slave nodes. The reduce task then reads the intermediate data and invokes the reduce function to produce the final output data (i.e., output key/value pairs) for its reduce partition. The input data is stored in the local disk of the machines that makes up the cluster so that the network bandwidth is conserved. Thus, a Map-Reduce scheduler often takes the input file’s location information and schedules the map task on the slave node that contains the replica of the corresponding input data block. Hadoop is useful for data staging, operational data store architecture and for ETL to ingest massive amount of data so that it eliminates the need to predefine the data schema before loading the data in Hadoop. It provides the parallel nature of execution. Data Transformation and Enrichment process can be done easily using the raw data in Hadoop environment. It provides the flexibility of creating structure for the data. Flat scalability is the main importance of Hadoop instead of using other distributed systems. Hadoop will not results in good performance while executing a limited amount of data on small number of nodes as the indicated overhead in starting Hadoop program is relatively high. MPI (Message Passing Interface), a distributed programming model performs much better on two, three or probably on thousands of machines but it requires high cost to improve the performance and engineering effort by adding more hardware to increase the data volumes. Handling partial failure is very simple as tasks are not dependent and Hadoop is a failure tolerant synchronous distributed system.
GARUDA [27]
The Indian Grid Certification Authority (IGCA), a certification authority for Grid, has received accreditation from Asia Pacific Grid Policy Management Authority (APgridPMA) to provide access of worldwide grids to Indian researchers. Indian researchers can now request user and host certificates to IGCA, part of Centre for Development of Advanced Computing (C-DAC) and get access to worldwide grids. Indian researchers mainly constitute users of GARUDA Grid, Foreign collaborators or institutes related to Grid research and scientific collaborations from India that allows researcher to access the grid.
GARUDA (Global Access to Resource Using Distributed Architecture) is India’s Grid computing initiative connecting 17 cities across the country. The 45 participating institutes in this nationwide project include all the IITs and C-DAC centers and other major institutes in India. GARUDA is a collaboration of science researchers and experimenters on a nationwide grid of computational nodes, mass storage and scientific instruments that aims to provide the technological advances required to enable data and compute intensive science. One of GARUDA’s most important challenges is to strike the right balance between research and the daunting task of deploying that innovation into some of the most complex scientific and engineering endeavors being undertaken today. GARUDA has adopted a pragmatic approach for using existing Grid infrastructure and Web Services technologies. The deployment of grid tools and services for GARUDA will be based on a judicious mix of in-house developed components, the Globus Toolkit (GT), industry grade & open source components. The foundation phase of GARUDA is based on stable version of GT4. The resource management and scheduling in GARUDA is based on a deployment of industry grade schedulers in a hierarchical architecture. At the cluster level, scheduling is achieved through Load Leveler for AIX platforms and Torque for Linux clusters.
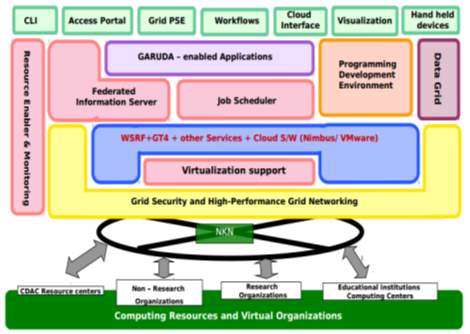
Fig-24: Garuda Architecture (GBC Pune Aug 2012)
Entropia [28], [29]
The Entropia DCGrid aggregates the raw desktop resources into a single logical resource. This logical resource is reliable and predictable despite the fact that the underlying raw resources are unreliable (machines may be turned off or rebooted) and unpredictable (machines may be heavily used by the desktop user at any time). This logical resource provides high performance for applications through parallelism, and the Entropia Virtual Machine provides protection for the desktop PC, unobtrusive behavior for the user of that machine, and protection for the application’s data.
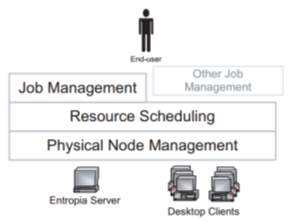
Fig-25: Entropia Desktop Distributed Computing Grid Architecture
(A. Chien et al. 2003)
The Entropia server-side system architecture is composed of three separate layers as shown in Figure. At the bottom is the Physical Node Management layer that provides basic communication to and from the client, the naming (unique identification) of client machines, security, and node resource management. On top of this layer is the Resource Scheduling layer that provides resource matching, scheduling of work to client machines, and fault tolerance. Users can interact directly with the Resource Scheduling layer through the available APIs, or alternatively, users can access the system through the Job Management layer that provides management facilities for handling large numbers of computations and files.
A range of encryption and sandboxing technologies are used in the Entropia security service. Through sandboxing, a single machine virtualization is provided. This helps in enforcement of security policies and management of identity on a single application and the resources. Security is provided by providing cryptography on the applications that communicate and allocating access rights of file system, the interface etc to the jobs. But this increases the cost and reduces the high performance capability of the system.
Legion [45]
Legion has been designed as a virtual operating system for distributed resources with OS-like support for current and expected future interactions between resources. The bottom layer is the local operating system – or execution environment layer. This corresponds to true operating systems such as Linux, AIX, Windows 2000, etc. We depend on process management services, file system support, and inter-process communication services delivered by the bottom layer, e.g., UDP, TCP or shared memory. Above the local operating services layer we build the Legion communications layer. This layer is responsible for object naming and binding as well as delivering sequenced arbitrarily-long messages from one object to another. Delivery is accomplished regardless of the location of the two objects, object migration, or object failure. For example, object A can communicate with object B even while object B is migrating from one place to another place or even if object B fails and subsequently restarts. This is possible because of Legion’s three-level naming and binding scheme, in particular the lower two levels.
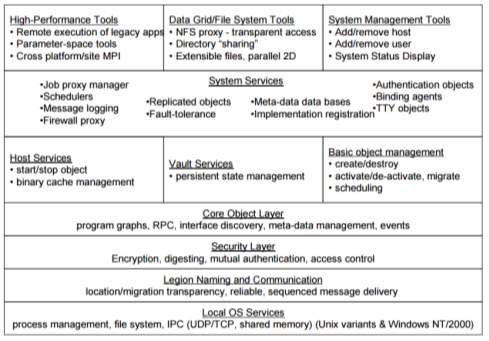
Fig-26: Legion Architecture (A. S. Grimshaw and M. A. Humphrey 2003)
The lower two levels consist of location-independent abstract names called LOIDs (Legion Object IDentifiers) and object addresses specific to communication protocols, e.g., an IP address and a port number. Next is the security layer on the core object layers. The security layer implements the Legion security model for authentication, access control, and data integrity (e.g., mutual authentication and encryption on the wire). The core object layer addresses method invocation, event processing (including exception and error propagation on a per-object basis), interface discovery and the management of meta-data. Above the core object layer are the core services that implement object instance management (class managers) and abstract processing resources (hosts) and storage resources (vaults). These are represented by base classes that can be extended to provide different or enhanced implementations. For example, the host class represents processing resources. It has methods to start an object given a LOID, a persistent storage address, and the LOID of an implementation to use, stop an object given a LOID, kill an object, and so on.
The Legion team presently is focusing on issues of fault-tolerance (autonomic computing) and security policy negotiation across organizations.
Xgrid [30]
Single sign-on is permitted in Xgrid. This is done through Kerberos. For establishing a connection, a password is required to be sent by the client to the server for executing a job. In response, the server again uses a password for authentication. The encryption method used is MD5. For different users, different permissions are set. No certificate authentication or any other mechanism is used. Problem of identity spoofing persists in Xgrid.
iDataGuard [31]
It is an interoperable security grid middleware. Users are allowed to outsource their file system to heterogeneous data storage providers such as Rapidshare and Amazon. It uses cryptographic techniques to maintain data integrity and confidentiality. Normally data at client side is stored in plaintext and the cryptography is applied on the storage provider. Due to this, outside and inside attacks can be possible. iDataguard solves this problem by applying cryptography. It also provides index based search of keyword. But certificate authentication is not supported.
Middleware for Mobile Computing [32]
A survey of middleware paradigms for mobile computing presented several research projects that have been started to address the dynamic and security aspects of mobile distributed systems. It is clear from the paper that traditional middleware approaches based on technologies like CORBA and Java RMI which support object oriented middleware are successful in providing heterogeneity and interoperability but they are not able to provide the appropriate and required support for modern and advanced mobile computing applications.
Selma [33]
One of the mobile agent based middleware is Selma. This middleware provides neighborhood discovery and wireless communication for distributed application in mobile multiple ad-hoc networks. Traditional technologies like CORBA and Java RMI are not suitable for middleware supporting mobile ad-hoc networks. In mobile network based middleware there will be multiple nodes distributed across the network. All of these nodes can be accessed through the above technologies. The paper is concluded by arguing that a complete middleware solution still do not exists that provides and fulfills all the required functionalities for a middleware concerning security aspects and resource management. No certification is used for the authentication.
XtremWeb [34]
It is a open source middleware for peer to peer distributed grid applications and desktop grids. In this, any participant can be a user. The access rights provided are UNIX based and sandboxing technology is also used. It uses public key algorithm for authentication. Problem in this is the grid security policy is breached as the pilot job owner i.e. the one who started the job can be different from the final job owner.
2. 4 Grid Monitoring Systems
A grid environment involves large-scale sharing of resources within various virtual organizations (called VO’s in common grid terminology). There arises a need for mechanisms that enable continuous discovery and monitoring of grid entities (resources, services and activity). This can be quite challenging owing to the dynamic and geographically distributed nature of these entities. Information services thus form a critical part of such an infrastructure, and result in a more planned and regulated utilization of grid resources. Any grid infrastructure should therefore have a monitoring system dedicated to this task, which should provide at a minimum – dynamic resource discovery, information about resources, information about the grid activity, and performance diagnostics.
The goal of grid monitoring[46]–[50] is to measure and publish the state of resources at a particular point in time. Monitoring must be end-to-end which means all components in an environment must be monitored. This means the components which should be monitored are applications, services, processes and operating systems, CPUs, disks, memory and sensors, and routers, switches, bandwidth and latency. Methods like fault detections and recovery mechanisms need the monitoring data to help determine that the parts of an environment are functioning correctly or not. Moreover, a service might use monitoring data as input for a prediction model for forecasting performance which in turn can be used by a scheduler to determine which components to use for prediction [46]–[50].
Monitoring of a grid can be a challenging task given the fact that restricted quality of service, low level of reliability, and network failure are the rule rather than the exception while dealing with globally distributed computing resources. For such a system to be robust there should not be a centralized control of information. The system should exhibit its minimalist behavior for a maximum possible subset of the grid-entities even if certain information access points fail to perform their function. This robustness can only be achieved if:
- The information services are themselves distributed, and geographically reside as close to the individual components of a grid as possible.
- The monitoring is performed in as decentralized a fashion as possible under the constraints of the underlying resources’ architecture.
A grid monitoring system should therefore, make sure that unavailable and/or unreachable services and resources do not interfere with its normal functionality. Also, if there is a provision for the awareness of such defaulting entities, it makes the monitoring more effective in reducing the turnaround time for the grid to recover from failures of its participating entities.
A grid monitoring system that is restricted to command-line interface may fail to provide easy accessibility to the monitoring information. It is beneficial for the front-end of any grid monitoring system to utilize the client-server model of the Internet, and be able to provide up-to-date information transparently and comprehensively to a client while performing all the major tasks at the various layers of the backend.
Conclusively, an effective model for a grid monitoring system should be globally distributed, as much de-centralized as possible, and must be capable of providing access to information in a ubiquitous manner. This work describes design, development and implementation of such a prototype grid monitoring system.
Ganglia Monitoring System
Ganglia – a popular grid monitoring system [50]–[52] currently runs on over 500 clusters around the world. It has been used in nine different operating systems with six different CPU architectures, and is also used in distributed systems. Ganglia[52] is simple and robust because of the use of simple widely used technologies such as XML for data representation and XDR for data transport. With all these advantages, it also has some drawbacks.
Features provided by Ganglia
Following are the features supported in Ganglia –
- Checking of heartbeat – gmond daemons sends a periodic heartbeat (every 20 seconds by default). If the heartbeat is missing it is fair to assume host is down. This alerts to potential down time much quicker.
- Checking single metric across multiple hosts – use a single check to check low disk space on a set of hosts defined by a regular expression.
- Checking of multiple metrics – allows using a single check to multiple metrics on the same host.
- While viewing aggregate graphs with more than 6-7 items, colors will start to blend together and it may be hard to distinguish what on graph is what. This feature allows decomposing a graph by taking every item on the aggregate graph and putting it on a separate graph.
- Provision of utilization heat maps instead of the old style pie charts.
- Adding trend lines to graphs.
- It allows to compare hosts across all the matching metrics (this can mean hundreds of graphs)
- If a regular expression is supplied that matches a set of hosts, it will aggregate all the hosts. This is useful in finding why particular hosts are performing differently.
Following features are now provided in recent versions of Ganglia –
- It can be started in Solaris containers.
- It can be started when Solaris CPU is in FAILED state (segmentation fault).
- It can be started when there is no address on the network interface.
- Prevention of memory leak when receive channel is not configured or not hearing any data.
- Improvements are provided to the Live Dashboard.
- Multiple CD drives are supported for bringing up a frontend.
- Aggregate graphs metric auto complete is provided.
- More reliable notification of changed files.
- After a reboot, all Ganglia history will be restored from the previous boot.
- All the Intel compiler libraries are now copied to the compute nodes.
- XML escape characters (e.g., &, ) are supported in the installation screens (e.g., the Cluster Information screen and the Root Password screen).
Following features are enhanced in Ganglia –
- Ganglia RSS news event service.
- Device driver now builds and loads on compute nodes that have a custom kernel.
- Addition of the Condor Roll. This brings the distributed high-throughput features from the Condor project to clusters.
- Addition of the Area51 Roll. This roll contains security tools and services to check the integrity of the files and operating system on cluster.
- Improved network handling for compute nodes: any interface may be used for the cluster private network.
- Better support for cross-architecture clusters containing x86 and x86_64 machines.
- RAID for custom compute node partitioning is supported.
- Addition of variables for root and swap partition. If the size of root is to be changed and/or swapped, only two XML variables have to be reassigned.
- The default root partition size has been increased to 6 GB from 4 GB.
- Use of ssh instead of telnet for security.
- Latest software updates recompiled for architectures.
- Automatic MySQL Cluster database backup.
- MAC addresses are included for each node in the “Cluster Labels” output.
Autopilot Monitoring System
Autopilot[47], [53], [54] is one grid monitoring system that uses Globus [35], [36], [51] platform and provides graphical features to view and control Autopilot components. Its monitoring components are –
- The Sensor that corresponds to a GMA producer. Sensors are installed on monitored hosts to capture application and system performance information. Sensors can be configured to perform data buffering, local data reduction before transmission, and to change the frequency at which information is communicated to remote clients. Upon start-up, sensors register with the Autopilot Manager (AM).
- The Actuators that corresponds to GMA producers and provides mechanisms for steering remote application behavior and controlling sensor operation. Upon start-up, actuators register with the Autopilot Manager (AM).
- The Autopilot Manager that performs the duties of a GMA registry. It supports registration requests by remote sensors and actuators, and provides a mechanism for clients to locate resource information.
An Autopilot client behaves like it is a GMA consumer. It locates sensors and actuators by searching the AM for registered keywords. For each producer found, a Globus URI is returned so that the consumer can connect to producers directly. Once connected, the client can instruct sensors to extract performance information, or actuators to modify the behavior of remote applications.
The Autopilot Performance Daemon (APD) provides mechanism to retrieve and record system performance information from remote hosts. The APD consists of collectors and recorders. Collectors execute on the machines being monitored and retrieve local resource information. Recorders receive resource information from collectors for output or storage.
Performance Criteria
Following performance parameters and criteria are reviewed:
Scalability and Fault Tolerance
The Autopilot Manager (AM) binds together multiple concurrent clients and producers, and provides seamless mechanism for locating and retrieving resource information from remote sensors. Hence, AM is the key component for ensuring scalability and fault tolerance of the system. However, while multiple AMs can exist within the monitored environment, there is currently no support for communication between multiple AMs. So if an AM fails, the sensor registration that it holds will be unavailable. Sensors can potentially register with multiple AMs and clients can query those AMs. However, mechanisms are not provided to locate available AMs. Due to lack of communication between managers, it is not possible to create hierarchies of managers, wherein each manager contains information from sensors that report directly to it.
Monitoring and Extensibility
The APD periodically captures network and operating system information from the computers on which they execute. Host information includes processor utilization, system interrupts, disk activity, memory utilization, context switches, paging activity and network latencies. Developers could extend the scope of monitoring information by inserting sensors into existing source code that is used to perform local monitoring functions. These sensors can be configured to return specifies resource information. Autopilot does not provide a query interface for sensors.
Data Requests and Presentation
Sensors periodically gather information and cache it locally regardless of client request. Client requests are fulfilled from the sensor’s cache. Historical data is collected by the APM’s collectors and made available to clients. Sensors are capable of filtering and reducing the information returned to clients by using customized functions in the sensors. Mechanisms to support homogeneous view of information from heterogeneous resources are not provided by Autopilot. VIRTUE an immersive environment that accepts real time performance data from Autopilot interacts with sensors and actuators using SDDF (Self Defining Data Format) and provides graphical features to view and control Autopilot components.
Security
Autopilot does not support security support and assumes that applications will use Globus security mechanisms.
GUI Grid System
Alchemi [25][43] is a GUI grid toolkit that is developed in .Net to deal with key issues of security, reliability, scheduling, and resource management. Microsoft .Net platform supports all of these features. It actually provides features such as remote execution and development of web services, multithreading, disconnected data access and managed execution. The key features supported by Alchemi as listed in [43] are:
- Without a shared file system, clustering of desktop computers based on internet;
- Hierarchical and cooperative grids through federation of clusters;
- dedicated or non-dedicated execution by nodes;
- Grid thread programming model is object oriented and
- Cross-platform interoperability
There are four components in Alchemi .NET grid – User or Owner, Executor, Manager and Cross Platform Manager. User (an interface) requests for a task to be done. This task is given to the Manager. Manager is generally installed on the server. However it can also be installed on a client machine. Manager then delegates the task to the executors which are running on different client machines or nodes. Executor executes the task and sends the output to the Manager which then stores it in database and gives it to the User GUI.
CHAPTER 3: LITERATURE REVIEW & FINDINGS
REVIEW OF ARCHITECTURES
- A broader set of experiments are needed in Architecture of AGRADC to measure the times involved when instantiating applications in larger scale scenarios, and explore alternatives concerning the representation of autonomous behavior such as objective policies and utility functions.
- In Nimrod/G, use of economic theories in grid resource management and scheduling should be focused. The components that make up Grid Architecture for Computational Economy (GRACE) include global scheduler (broker), bid-manager, directory server, and bid-server working closely with grid middleware and fabrics. The GRACE infrastructure also offers generic interfaces (APIs) that the grid tools and applications programmers can use to develop software supporting the computational economy.
- The service oriented architecture of DIRAC proved that the flexibility offered by this approach allows faster development of an integrated distributed system. DIRAC should be integrated seamlessly into the third party services, possibly filling functionality gaps, or providing alternative service implementations. DIRAC currently operates in a trusted environment, and therefore had only a minimal emphasis on security issues. A more comprehensive strategy is required for managing authentication and authorization of Agents, Users, Jobs, and Services. A TLS based mechanism can be put in place with encrypted and authenticated XML-RPC calls. A new class of Optimizer can be planned which will allocate time-critical jobs to high priority global queues in order that they be run in a timely fashion. User interactivity, and real-time monitoring and control of Agents and Jobs should be done efficiently. A peer-to-peer network of directly interacting Agents can be envisioned. This would reduce the reliance on the Central Services, as Agents could dynamically load-balance by taking extra jobs from overloaded sites.
- In PerLa architecture, focus is needed on integrating intelligent in-network processing protocols in the middleware and on extending the language semantics with compression and data mining operators. Both the language and the middleware need to be extended to support context-based applications. The basic idea is to change the behavior of the surrounding network depending on the actual context.
- Critical issues that need to be addressed in the architecture for reliable mobile workflow in a Grid Environment include more accurate peer reliability calculation techniques. Development of a process definition tool is needed that will make it easier for workflow managers to create and distribute automatically the workflow definitions to the mobile peers. In addition, since the activity scheduling policy used in this work is rather static, investigation is needed for other scheduling policies based on reliability calculations that employ dynamic information from the peers as well as the environment. The architecture should be used in other environments where reliability is a critical issue and participating mobile peers are mutable; e.g. emergency response systems.
- Globus and other Grid platform do not provide a scheduler, but rather rely on the client operating system scheduler or batch schedulers to handle local scheduling activities. Global scheduling between Grid processes can be provided by meta-schedulers, such as Condor-G.
- Based on a message passing paradigm such as MPICHG Grid environments do not provide high level of abstraction compared to the current practices mostly based on traditional message-passing primitives.
- Current information and monitoring frameworks do not scale to Grid level or are focused on specific aspects. Monitoring and execution support with adequate check pointing and migration support also still lack.
- Currently, there is neither a coherent and generally accepted infrastructure to manage resources nor are there efficient coordination algorithms that suit the complex requirements of a large scale Grid environment with different resource types.
REVIEW OF MIDDLEWARE
- Following lacuna are found in early versions of Unicore –
- In contrast to customary believe, Java applets are not browser independent. Special code was required to support implementations of Netscape on different platforms. The developers had to invest substantial effort in supporting new versions of Netscape on new versions of the operating system.
- Signed applets were either recognized by Netscape or by Internet Explorer but not by both browsers. The project was forced to drop Internet Explorer support for MS Windows.
- Certain advanced programming techniques, like Swing classes were not supported.
- Signed applets could not be cached. This became a performance concern especially for mobile users on slower connections, because the client had to be downloaded from the server each time UNICORE was started.
- In Globus, Grid Portals are increasingly used to provide user interfaces for Computational and Data Grids. However, such Grid Portals do not integrate cleanly with existing Grid security systems such as the Grid Security Infrastructure (GSI), due to lack of delegation capabilities in Web security mechanisms.
- Following challenges are found in Alchemi
- If an Executor i.e. a node fails due to any reason, the task is stopped and the computing remains unfinished.
- If the Manager fails due to any reason, the whole processing is stopped.
- Inter thread communication is not supported.
- There is no peer-to-peer communication between Managers that can solve the problem of node failure.
- There is no policy for allocating resources.
- OGSI standards are not completely followed.
- In the iDataGuard architecture, data storage providers are untrusted. There are no standards on interfaces for IDP (Internet Data Providers) services and therefore every service designs its own interface. For instance, in the Amazon S3 service, data is stored and accessed using the REST based protocol. The application developer has the unenviable task of adapting his/her application to different IDP services or otherwise experience risk significant reduction in clientele. This greatly complicates application development.
- Security and privacy are not implemented in the Selma middleware. And modeling and running multihop ad-hoc networks successfully is still a challenging task.
- In Ganglia Monitoring System, the architecture of the system has had to evolve, features needed to be introduced, and the implementation should be continually refined to keep it fast and robust. Ganglia System does not support following features
- IP SLA (Service Level Agreement) Reports. IP SLAs uses active monitoring to generate traffic in a continuous, reliable, and predictable manner, thus enabling the measurement of network performance and health. No service level agreement reports are provided by Ganglia.
- Monitoring data is published using a flat namespace of monitor metric names. As a result, monitoring of naturally hierarchically data becomes awkward.
- Ganglia lack access control mechanisms on the metric namespace.
- Huge amounts of I/O activity. As a result, nodes running gmetad experience poor performance, especially for interactive jobs.
- Metrics published in Ganglia did not originally have timeouts associated with them. The result was that the size of Ganglia’s monitoring data would simply grow over time.
- Within a single cluster, it is well-known that the quadratic message loads incurred by a multicast-based listen / announce protocol is not going to scale well to thousands of nodes. As a result, supporting emerging clusters of this scale will likely require losing some amount of symmetry at the lowest level.
- For federation of multiple clusters, monitoring through straightforward aggregation of data also presents scaling problems.
- Self-configuration while federating multiple clusters will also require substantial changes to the architecture since manual specification of the federation graph will not scale.
- Autopilot Monitoring system does not support following features
- Monitoring of services and network
- Run time extensibility
- Homogeneous data
- Open standards
- Current Grid middleware still lack mature fault tolerant features. Most of the earlier proposed facilities have been either designed for local area networks or to handle small number of nodes and hence lack in areas such as scalability, efficiency, running times etc.
REVIEW OF PUBLISHED PAPERS
Maghraoui et al. [55] have identified that new applications are being designed as per the requirements and have to be used with the existing deployed applications. This requires constantly changing processing power and communication requirement. And as grids span large geographic locations, number of failures and fluctuations of load become very critical. So authors have proposed a middleware infrastructure based on MPI implementation. This solution enhances the MPI implementations with reconfiguration capability and dynamic load balancing. The challenges still to be worked upon after their work are – mapping between application topologies and environment topologies, evaluation of load balancing procedures, support to non-iterative applications, solving complex applications, and merging the new applications with the existing ones.
Nagaraja and Raju [56] have proposed a new component based lightweight middleware based on Service Component Architecture (SCA). The SCA eases the reconfiguration of the components at runtime to support different communication mechanisms and service discovery protocols. But this architecture is suitable only for mobile devices. The issues still to be worked upon and not fully addressed are the issues of memory and bandwidth for dynamic adaptation.
Mauve et al. [57] have identified that several middleware technologies have been designed and successfully used to support the development of stationary distributed systems built with fixed networks. Their success mainly depends on the ability of making distribution transparentto both users and software engineers, so that systems appear as single integrated computing system. However, completely hiding the implementation details from the application becomes more difficult and makes little sense in a mobile setting. Mobile systems need to quickly detect and adapt to drastic changes happening in the environment.
Sivaharan et al. [58] have identified that presently available middleware does not adequately address the configurability and re-configurability requirements of heterogeneous and changing environments. Current platforms cannot be configured to operate in diverse network types. And so they proposed a new middleware. The challenges ahead of their work are of memory and flexibility.
M. Reddy et al. [59] proposed a two layered P2P middleware “Vishwa” for computing in distributed environment. The two layers leverage the utility of unstructured and structured P2P. The structured layer reconfigures the application to mask failures and unstructured layer reconfigures by adapting to various loads. They identified that though the middleware that they proposed is good enough to build reconfigurable computational grid, there is a need to explore the feasibility of using the middleware Vishwa for building a data grid middleware.
K. J. Naik et al. [60] have identified that a load balancing algorithm which considers the different characteristics of the grid computing environment is needed. For this, they proposed a novel algorithm for fault tolerant job Scheduling and load balancing in grid computing environment named as NovelAlg_FLB, which focuses on grid architecture, computer heterogeneity, communication delay, network bandwidth, resource availability, unpredictability and job characteristics. The main goal was to arrive at job tasks that will deliver in minimal response time and optimal utilization of computing nodes. There is a need of a resource allocation and load balancing algorithm that can perform extremely well in a huge grid environment.
Neha Mishra et al. [61] have identified the various security challenges faced in grid computing such as dynamic creation of services, dynamic establishment of trust domains etc. With the increase in the use of cyber space, they stressed on the need of implementing cyber security measures in grid security mechanisms of modern grids.
Welch et al. [62] identified that some environments require that end entities be able to delegate and create identities quickly. They described Proxy Certificates, a standard mechanism for dynamic delegation and identity creation in public key infrastructures. Proxy certificates are based on X.509 public key certificates in order to allow for significant reuse of protocols. Presently, as there is a move towards a web services dominated world, pure XML-based alternatives to SSL/TLS can be thought for authentication and key exchange based on new and emerging specifications and standards, such as XML-Signature, XML-Encryption, WS-Trust, WS-SecureConversation, etc. These protocols are expected to be able to communicate attribute and authorization assertions transparently without requiring modification of the application protocol.
Sabir Ismail et al. [63] identified that any types of interruption during the run time can cost a great loss to the whole application. There is a need of a failsafe computation strategy for the Grid manager node. They also identified that the distributed memory caching techniques on top of the distributed file system is the trick to implement a complete fail safe solution for the Grid platform. It also opens up the gateway to develop a fault tolerance grid environment.
Hijab and Avula [64] summarized the different resource discovery models, in terms of their strengths and weaknesses. They also described the requirements for wireless, mobile, and adhoc grids. They identified that resource discovery is needed in wireless grids that provide access to different wireless devices of heterogeneous nature, different sizes. New resource discovery approaches are needed to provide effective management of resource information repository, information dissemination and information update with minimum delay and low latency. Existing resource discovery methods need to be analyzed and extended to be able to effectively address resource sharing in the context of this increasing resource potential. Therefore the need for newer resource discovery methods exists.
Montes et al. [65] identified that one of the weakest aspects of Grid systems is that they are difficult to manage due to their complexity and dynamism. A good approach to simplifying grid understanding and management is to have a prediction system that can predict crucial changes. The process of predicting these crucial changes is not an easy task. Given a correct selection of the machine learning algorithm, a multi-stage predictor can be developed that will be capable of predicting a high percentage of transitions, as well as being able to recognize the system stability thereby improving the accuracy.
F. Uzoka [66] examined factors that could likely impact on the adoption of grid technology by universities in a developing economy. Seven distinct factors are found and explored that affect the adoption. Then regression analysis was conducted. The regression statistics indicate that perceived benefits, perceived need, and facilitating conditions exert a significant influence on the adoption of grid computing by Universities. However, it is suggested that newer universities may not have an elaborate structure for staff education and awareness.
N. Mangala et al. [67] [68] gave the integration of Galaxy workflow and GARUDA grid and also the comprehensive testing done on GARUDA Grid. Galaxy is a user friendly workflow which is popular for large bio/chemo informatics applications which require huge compute-data power of grid. The implementation of Galaxy was specifically done for the Gridway metascheduler, but can be extended to support other types of Grid systems. They identified that the currently the Gridway runner only handles the sequential job, it can be extended to support the parallel jobs also. They also made a point that fault tolerance is still to be addressed in the critical systems of Garuda Grid such as the login server, job submission nodes etc.
Karuna Prasad et al. [69] identified that “Paryavekshanam”, a monitoring tool, is been successfully monitoring the GARUDA grid over a periods of years and has been a valuable tool in giving insights about resource and job accounting. It monitors all grid components such as the middleware, operating systems, end-host hardware, submitted jobs, storage, software and networks under one umbrella. Similarly, a monitoring tool with well tailored user interface is needed for other Grid Systems, that can provide detailed information for different levels or domains of users such as the administrators, partners, virtual communities and policy managers according to their needs.
N. A. Azeez and I. M. Venter [70] identified that a secured access control framework is needed. Based on this, they proposed and implemented 3DGBE architecture. They made clear that role based access control can be used to monitor, regulate and authorize users on any high performance computing specifically on the grid. They believe that a full scale implementation of a secure access control framework on a real grid system will ensure a secure, scalable and interoperable grid-based environment.
Vijayalakshmi M. C. [71] stressed that Web Services make it possible for diverse applications to discover each other and exchange data seamlessly via the Internet. The web services architecture provides a new way to think about and implement application – to – application integration and interoperability that makes the development platform irrelevant. For instance, programs written in Java and running on Solaris can find and call code written in C# that run on Windows XP, or programs written in Perl that run on Linux, without any concern about the details of how that service is implemented. Thus, the promise of web services in Grid Computing is to enable a distributed environment in which any number of applications, or application components, can interoperate seamlessly among and between organizations in a platform neutral, language-neutral fashion.
Hema S. et al. [72] pointed that consistent Job Execution Management is extremely important capability of the grid environment. Nowadays systems are not enough for end users to execute heavy jobs. There arise issues in the grid middleware support. So a new toolkit is needed using Hadoop Map-Reduce concept which is an open source implementation of Google Map-Reduce for analyzing huge amounts of data. By integrating big data concept of Hadoop in Globus we can achieve efficient scheduling of grid jobs, management and optimized use of grid resources.
[73][74]–[76][77]–[79][80]–[82][83]–[85][86]–[88][89], [90][91]–[93][94], [95][96], [97][98][99], [100]
FINDINGS
Summing up, after reviewing published papers and most of the existing grid architectures and middleware researcher found out that they provide re-configurability but to a limited extent. Many issues such as memory, bandwidth, processing load are still not solved completely. Hence there is a need of a powerful and flexible dynamic reconfigurable middleware that can serve the purpose. From the survey of all the above middleware systems, it is clear that many security parameters are addressed by them and many are still pending.
Dynamic resource allocation when fault tolerance[41] occurs is not properly done by the existing middleware. Fault tolerance[3], [41], [60] is becoming an important concern for present grid middleware systems. Security[19][34][95][96][97] is also an important concern.
Issues of Security are summarized as follows –
- Authentication management not proper
- Authorization and access control policies not proper
- Violation of Data sharing and Integrity
- Communication protocols are open
- Trust relationship policies are weak
- Inability of working with less resources
- Single sign on mechanism
Due to the dynamic nature of the Internet, node or network failures are the main challenges for grid computing. Moreover, as the nodes have autonomy, they may join or leave the grid system dynamically. We can conclude from this that a middleware is required that can ensure smooth working of applications in spite of node or network failure. Although in inter related applications, dependability and reconfigurable criteria are very significant. Even if a single node fails due to some reason, the entire task and the computation can fail resulting in Grid failure. Failures and dynamic nature of load allocation and de-allocation implies that there is a strong requirement of applications or rather middleware that can dynamically adapt to the situation to improve the overall efficiency and throughput. However, to our best knowledge, existing grid technologies provide only limited reconfigurable criteria and scalability. These systems provide static configuration of middleware or the application.
The researcher studied various security mechanisms of different middleware and found that most projects succeeded in implementing their proposed security middleware but it is not easy to have a fully secured middleware that can handle all the security attacks. There is no single security middleware that could claim full protection against the possible security attacks and the risks. One main reason for this is that depending on the domain and operating environment, application requirements drastically vary.
CHAPTER 4: PROBLEM FORMULATION
PROBLEM STATEMENT
Based on the findings, it can be concluded that failures and dynamic nature of load allocation and de-allocation of resources implies that there is a strong requirement of applications or rather middleware that can dynamically adapt to the situation to improve the overall efficiency and throughput. As the nodes have autonomy, they may join or leave the grid system dynamically. Hence a middleware is required that can ensure smooth working of applications in spite of node or network failure. There is a strong need of analysis and enhancement of Grid architecture or middleware or services provided. With this the problem is formulated as follows –
“Analysis and Enhancement of Grid Architectures, Middleware API’s & Services”
TARGET
A middleware that can provide a dynamically configurable environment that can help in ensuring that the computation does not fail even if any node in the computing fails. This can be done by implementing following things in the middleware.
- The connection to each participating node should be checked regularly and if a node is found to be failed, the task should be allocated to the next available node with less CPU load.
- Moreover, the task should start from the point it was stopped. Task should not be restarted as this would hamper the high performance.
- A Resource Allocation algorithm is needed that can achieve dynamic task allocation.
- Also needed is a caching algorithm through which intermediate results are written into cache using write-through method at the participating node. This method stores the result in cache block as well as the main memory. Contents of cache are transferred to manager nodes at specific intervals. In case of node failure, the last transferred value of cache is taken and the thread with same id is allocated to another node of the network.
CHAPTER 5: PROPOSED WORK
EXTENSION OF KNOWLEDGE
The researcher has developed a dynamically reconfigurable middleware SCADY (Scalable & Dynamic) which provides a dependable execution environment for grid applications. The components of SCADY are User or Executor and Manager. The researcher has used API concepts of Unicore[17], Globus [19] and GridSim [20]. The researcher has tried to extend it in SCADY. The studied environment is utilized for different experiments. Some of the constructs that can help in providing dynamic configuration are given below and some experiments are also conducted that uses these constructs.
The computation in Scady is initiated by the user on the user node, who submits a grid task to one of the available grid nodes along with the task configuration details. The configuration details include, the number of nodes required, type of task and a metafile containing task input descriptions. The middleware determines the leader for the task based on the task id and then sends the task along with the configuration details to the leader, through the reconfigure layer.
SCADY API SPECIFICATION
The API specification for the middleware and its components are discussed as under –
NODE MANAGER
This component acts as a mediator between user program and Scady Grid Middleware. It provides the basic constructs for configuring the grid middleware. The node manager is used by the application to specify the task definition, configuration details, and to get back the results. The main constructs of node manager are as follows –
- Void setScadyNodeIP(String IP): It is used by the application to set IP address of a live grid node. This node is mainly used for constructing the task overlay.
- Void setScadyMetric(Metric m): It is used to specify application metric, i.e. the way of measuring the capability of a node.
- Void setScadyQuery(Query q): It is used to specify the predicate or criteria for selecting the node.
- Void setScadyConditionType(ConditionType type): This construct indicates type of predicate used for selecting the node.
- Void Scadybarrier(): It is a blocking call. It will wait till all previously started remote sub tasks to finish. This method is analogous to the ‘joinAll’ method provided in Java.
- Void setScadySchedulerType(SchedulerType type): It is used to set the type of scheduler used for executing the application. By default it uses the dynamic scheduler.
- Void Scadyinitialize() Throws Exception: This call initiates with the given configuration requirements. It can throw three different types of exceptions. This method should be called before submitting any sub task.
- Void setScadyMinNodes(int min): It is used to set the minimum number of nodes required for execution. If middleware does not find those many capable nodes, it will not start the execution of an application.
- Void setScadyMaxNodes(int max): It is used to specify maximum parallelism, that is maximum number of parallel sub tasks.
- Void setScadyReplicaSize(int rno): It is used to set the middleware replication factor. It will indicate the maximum number of parallel node failures that the middleware can handle.
- Void setScadySurplusValue(int sno): It is used to set the number of surplus nodes. These surplus nodes are used to replace the failed nodes.
- Void Scadyclose(): It closes the node manager of Scady. In other words, it will remove all the temporary files, free all allocated buffers & close all open threads.
- Double getScadyHPF(): This construct is used for getting the HPF of a node.
- Void setScadyCPUFractionValue(double cpuFraction): This construct is used to set the CPU fraction used for calculating the HPF of a node.
- Void setScadyMemoryFractionValue (double memoryFraction): This construct is used to set the memory fraction used for calculating the HPF of a node.
- Void setScadyUpperBound(double value) & void setScadyLowerBound(double value): These two methods are used for setting the upper and lower bounds in query.
CONTEXT CLASS
This class is used for passing parameters to subtask. The subtask could be running on any grid node. The two important methods in this class are ‘get’ and ‘put’. The syntax of these methods is as follows.
- Object Scadyput (String key, Object value): This construct is used for placing the ‘value’ into the table with given ‘key’. It is used for passing inputs to the subtask.
- Object Scadyget (String key): This method used for getting the value. Before starting the execution of a subtask, it will retrieve the input parameters from the Context object.
RESULT CLASS
This class is used for transferring the results from the remote node to client program. Result class is similar to context. But difference is that context is used for passing the inputs while it is used for getting the results back. In addition, result will also support file transfers between remote node and client node.
- Object Scadyput (String key, Object value): This construct is used for placing ‘value’ into the table with given ‘key’. Value could be any predefined or user defined object. At the end of subtask completion, subtask puts its result into this Result object.
- Object Scadyget(String key): This method used for getting the value. Once the client receives subtask results, it will use get method for retrieving the results.
- Void ScadyputFile(ScadyFile): This construct is used for placing file into the result object.
- ScadyFile getFile(): This construct is used for getting file at the client node. If there is no file, it will return null.
PROPOSED MODEL
A Manager is installed on each cluster or the location. One can also install more than one Manager at one location (through inter thread communication model). This will help in removing the problem of failure of any one Manager. This supports the VPN concept. Each Manager can have multiple Executors under it. When any task is to be done, Manager delegates the task to Executors. The result is processed by the executor and sent to the Manager. This working is shown in Fig – 27.
Fig-27: Scady Manager (Connection)
In Manager, IP address and Mac Address will be displayed reading from the system. All the connected nodes in the network will be displayed. Nodes will be selected through check box and connection is established. Managers will take less time to produce result if the numbers of executors are more.
Fig-28: Scady Manager (Application)
If due to any reason an executor goes down in between the task, Manager dynamically reallocates it to another executor and the task is completed. For this the Manager has to dynamically monitor the executors. This is implemented by checking the connection every 10 seconds through the session variable. If a node fails, the task is reallocated to another node by manager based on the CPU load of nodes. After the connection is done, application is selected. These applications can be increased with the use of database. Input values will be provided and then application is started. This application is processed by the executors and the result is sent to the manager. With this model, node failure and unfinished task problem is solved.
DYNAMIC RESOURCE ALLOCATION ALGORITHM
A slight modification is proposed in the design of Scady. Instead of manual selection of node, automatic selection of node is implemented in Scady. This selection is done dynamically. If the user wants, the number of minimum nodes and maximum nodes can be provided as per the requirement. Minimum nodes to perform a task are kept as three. Nodes in the network are found and shown to the user. These nodes are then sorted based on their CPU usage. Nodes with less CPU usage are displayed first. If the user wants, he/she can select the nodes dynamically and then connect to the selected nodes otherwise the first three nodes will be selected. Then the task to be performed is selected from the manage application tab and is delegated to the nodes. An algorithm is developed for the discovery of resources and allocation of resources.
Resource Allocation Algorithm
Input: Application (program) with number of nodes
Steps:
- Begin
- Retrieve the list of nodes with their CPU usage. Call it nodelist.
- If there are no nodes available, show message and exit
- Else
- sort the nodes based on their CPU usage (Less CPU usage first)
- Get the number of minimum and maximum nodes required
- If user has not changed the number of minimum and maximum nodes, select the first three nodes from the nodelist
- Else get the number of minimum and maximum number of nodes
- Select the nodes from the nodelist equal to the number of minimum number of nodes.
- Allocate the tasks to the selected nodes dividing into parallel processes.
- End
Executor is running on each node. Executor computes the tasks and sends back the result to the Manager. If Executor is not running on the nodes, Manager is notified for the same. If due to any reason an Executor goes down in between the task, Manager dynamically reallocates it to another executor and the task is completed. For this the Manager has to dynamically monitor the executors. This is implemented by checking the connection every 10 seconds through the session variable. If a node fails, the task is reallocated to another node by manager based on the CPU usage of nodes. CPU usage is refreshed every 10 seconds.
With this model, node failure and unfinished task problem is solved. Also as the number of managers and executors are more, the time taken to complete the task is less as compared to Alchemi .Net toolkit.
CACHING ALGORITHM FOR FAULT TOLERANCE
If due to any reason an executor goes down in between the task, Manager dynamically reallocates it to another executor and the task is completed. If a node fails, manager node gets the notification and it reallocates the task to another node based on the CPU usage of nodes. To save time and effort, the results are written in cache in the executor node. The cache write-through method is used in which the data is written into the cache block and the corresponding main memory location at the same time. The data written into the cached block can be retrieved very fast ensuring that nothing will get lost in case of a crash or power failure or other system disruption. This is because the same data is in main memory. Write through method is the most preferred method for the applications that stores data which is critical and loss of the data cannot be tolerated. With this model, node failure and unfinished task problem is solved. Also as the number of managers and executors are more, the time taken to complete the task is less as compared to Alchemi .Net toolkit.
Caching Algorithm in Scady Grid Framework
Input: Application (program) with number of nodes
Steps:
- Begin
- Check the existence of executor nodes in the network.
- Retrieve the list of nodes with their CPU usage. Call it nodelist. Sort the nodes based on their CPU usage (Less CPU usage first)
- Allocate the tasks to the nodes dividing into threads. A thread-id is associated with each thread.
- At the executor node – intermediate results are written into cache using write-through method. This method stores the result in cache block as well as the main memory.
- Contents of cache are transferred to manager nodes at specific intervals. Here concept of cache write-back method is used.
- In case of node failure, the last transferred value of cache is taken and the thread with same id is allocated to another node of the network with less CPU usage.
- The node starts the execution with the cache result.
- When the execution gets completed, the results are given to the manager node.
- End
SECURITY MECHANISM
Security in SCADY is provided by using encryption and decryption algorithms and authentication by certification. RSA algorithm is used with SHA as cryptography method using 256 bit key or 512 bit key. For certification, X.509 certificates are used. Security Services offered through the certificate are –
- Digital Signature
- Data Encipherment
- Key Encipherment
- Non-Repudiation
- Certificate Signing
For SCADY User certificate, the services used are: Digital Signature, Non Repudiation, Key Encipherment and Data Encipherment. For the Root Certificate, the service used is Certificate Signing. Summarizing, I found that even though, Scady is working fine in the grid environment, there was a need of security mechanism to secure and authenticate the communication. To remove this limitation, I proposed a security mechanism based on the review findings. The proposed model use X.509 certificate based delegation model and public key cryptography algorithms like RSA with SHA. Root certificate and client certificates are generated and issued. I executed the grid toolkit with this certification model and found that the model is providing the required security to the system.
Enhance key usage extension provided with X.509 certificate generation indicates the use of certificate’s public key. It provides additional information such as whether the certificate is used for client authentication, server authentication, signing the document, IPSec Tunneling, time stamping, Code signing, SSL verification etc.
Additional information used in Scady through Enhanced Key Usage extension are –
- Secure Email – The certificate can be used for securing Emails.
- Client Authentication – The certificate can be used for authenticating the client.
- Server Authentication – The certificate can be used for authenticating the server.
- Document Signing – The certificate can be used to sign various documents.
The researcher created a root certificate as shown in Fig. 29 for the entire organization. Every certificate issued for a client will be signed by this Root Certificate. A Root Certificate (CA certificate) is used to digitally sign other certificates. In order to validate the certificates on other computers, the Root Certificate must be installed on the computers first.
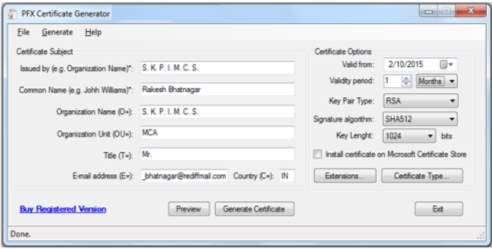
Fig-29: Certificate Generator
Fig. 30 describes the type of certificate. The available types of certificates are – Standard Certificate, Self Signed Certificate and Certificate signed by Root Certificate.
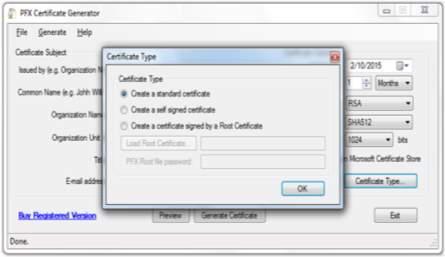
Fig-30: Certificate Type
Next the researcher selected the extensions for the certificate as shown in Fig. 31. These extensions describe the key usage as well as the enhanced key usage of the certificate such as Secure Email, Client Authentication, Server Authentication, IPSEC User, IPSEC Tunnel etc.
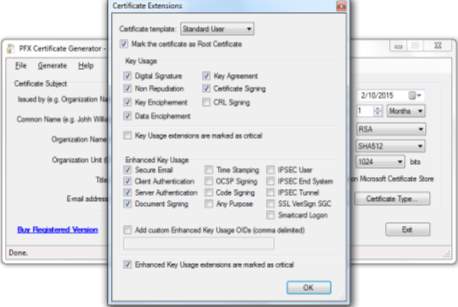
Fig-31: Certificate Extensions
Finally the certificate will be created and will be ready to install for clients as shown in Fig. 32.
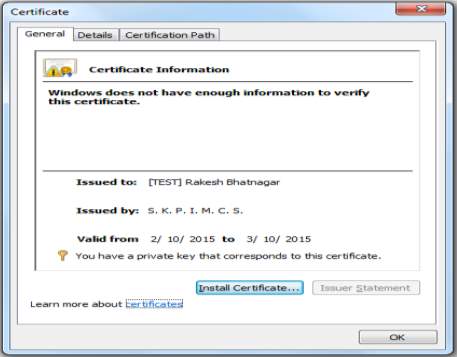
Fig-32: Certificate Information
Issue of the Client Certificate Signed by the Root Certificate
In order to issue certificates signed by this Root Certificate, following steps are taken:
- “Standard User” Certificate is selected.
- Certificate Subject is filled with data like Issued to, Organization, E-mail address, etc.
- Root Certificate is then selected
The present certificate is issued and saved. For Client Certificates, 1024 bit key is used with RSA and for root certificate 2048 bit key is used.
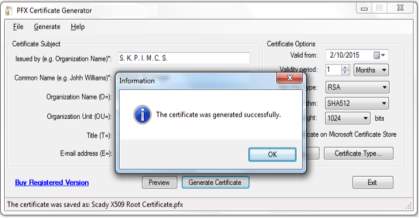
Fig-33: Certificate
After creating the certificates, they are issued as per the communication request. The proposed model given in Fig-34 is implemented and the application is tested. Initially, a root certificate is created with a validity of one month. The duration can be decided by the organization and as per the requirements of the application. The Proposed model using X.509 certificates throws the light on security model of SCADY.
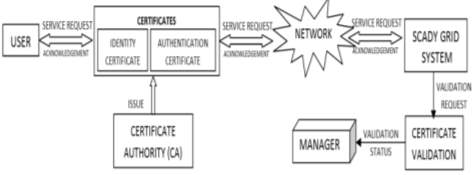
Fig-34: Proposed Model
Use of these certificates and cryptography algorithms are represented through Use case Diagram as in Fig-35.
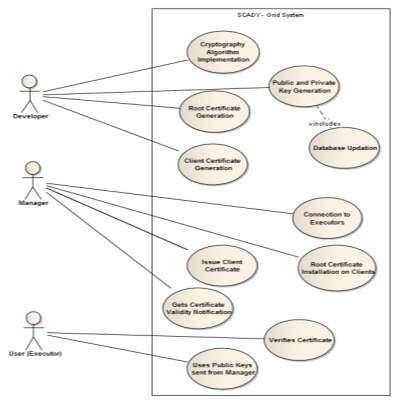
Fig-35: Use Case Diagram
CHAPTER 6: EXPERIMENTAL WORK & COMPARATIVE ANALYSIS
Implementation of Knowledge (Methodology) & Comparative Analysis
The researcher conducted many experiments. Some of them are as follows –
- Calculation of cube of a number
- Calculation of 2n
- Calculation of Sum of n Natural Numbers
- Calculation of Dice Probability using Binomial Distribution
- Calculation of Pi using Monte Carlo Simulation
EXPERIMENT – I
A program is written to calculate cube of a number. The program is tested in 2 phases. First test was done in the institute and the department itself with 3 nodes, then with 10 and then 50 nodes. Nodes were having 2GB of RAM, 2.66GHz speed and Core 2 Duo processor. Second test was done in the campus network of Kadi Sarva Vishwavidyalaya University. It has a wireless network that spans across 55 Kms covering four campuses.
The execution time was measured for all cases and is shown in Table – I and Table – II. Table – I represents the facts gathered from the execution done inside the institution in MCA department i.e. local network with 3, 10 and 50 nodes. Table – II represents the facts gathered from the execution done outside the institution in the university network i.e. network with subnets with 3, 10 and 50 nodes.
TABLE – I: Execution inside the Institute
| Number of Nodes | Time (in Secs) | |
| In other Middleware | In Scady Middleware | |
| 3 | 1.62 | 1.39 |
| 10 | 1.54 | 1.37 |
| 50 | 1.81 | 1.71 |
TABLE-II: Execution in Campus Network
| Number of Nodes | Time (in Secs) | |
| In other Middleware | In Scady Middleware | |
| 3 | 3.25 | 3.07 |
| 10 | 3.48 | 3.28 |
| 50 | 4.77 | 4.52 |
These figures are gathered in the peak working time. Alchemi middleware was used (As other middleware) with SCADY middleware. From the figures, we can rightly identify that as compared to Alchemi, performance of Scady middleware in terms of execution speed is better.
EXPERIMENT – II
Experiment is done to write a program to find factorial of a number. The network taken for the experiment is intranet (campus network) in which there are 4 sub-networks, each sub-network having a minimum of 50 client machines. Total computers in the network are around 300. Hardware and Software configuration used are – nodes with 3 GB RAM and 4 GB RAM, 2.66 GHz, Core-to-Dual Processors, Core-to-Quad Processors and i3 Processors, 24 ports Network Switch, Visual Studio 2012, .Net Framework 4.5 and SQL Server Express Edition. The test was done with 3 nodes (Executors), then with 10 and then 50 nodes. The results are shown in Table – III.
TABLE – III: Execution Time of Factorial Program
| Number of Executors | Time (in Secs) | |
| Alchemi Toolkit | Scady Toolkit | |
| 3 | 0.81 | 0.46 |
| 10 | 0.62 | 0.39 |
| 50 | 0.59 | 0.25 |
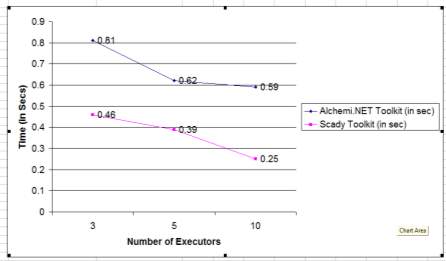
Fig-36: Execution Time of Factorial Program
ANALYSIS
The results of the experiment of calculating factorial of a number by using 3 executors, 10 executors and 50 executors are shown in Fig-III. It can be noted that the time taken to calculate factorial of a number decreases when the number of nodes increases. Also time taken by Scady toolkit is less.
EXPERIMENT – III
Another experiment was done for calculating 2 raise to n where value of n is given as 32 i.e. 232. The test was done with the same hardware & software configuration and selecting 3, 10 and 50 nodes. The working of Scady Manager is shown in following figures.
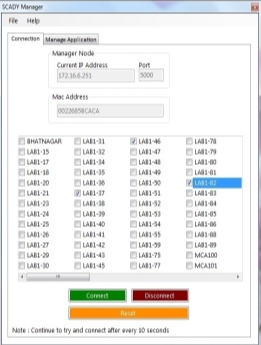
Fig-37: Scady Manager (for 232 Program)
3 nodes are selected from the network namely – Lab-37, Lab-46 and Lab-82. After connection, application is selected and started.
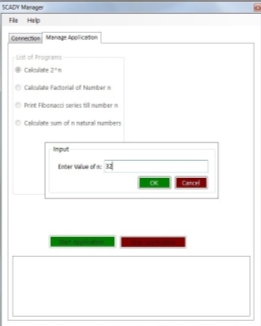
Fig-38: Input Values for 232 Program
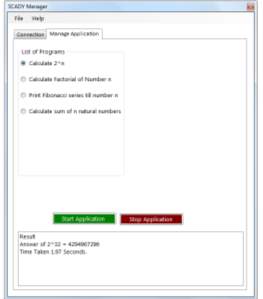
Fig-39: Result of 232 Program
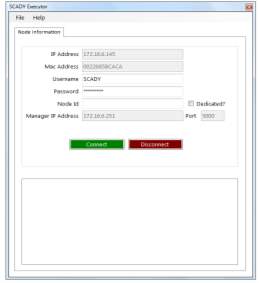
Fig-40: Scady Executor
The result and time taken for calculation is printed in the result window. This experiment is repeated for 10 and 50 nodes also. The results are given in Table-IV.
TABLE-IV: Execution Time of 232 Program
| Number of Executors | Time (in Secs) | |
| Alchemi Toolkit | Scady Toolkit | |
| 3 | 2.62 | 1.97 |
| 10 | 2.34 | 1.65 |
| 50 | 1.81 | 1.23 |
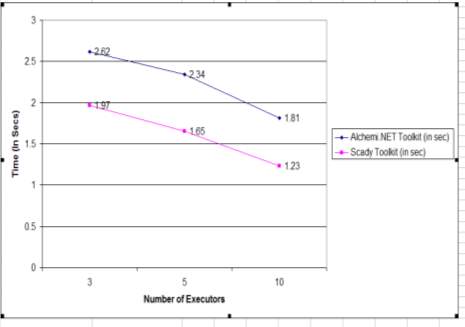
Fig-41: Execution Time of 232 Program
ANALYSIS
The results of the experiment of calculating 232 by using 3 executors, 10 executors and 50 executors are shown in Fig-41. It can be noted that the time taken to calculate 232 decreases when the number of nodes increases. Also time taken by Scady toolkit is less.
EXPERIMENT – IV
Another experiment was done for calculating sum of n natural numbers. The result and time taken for calculation is printed in the result window. This experiment is repeated for 10, 20 and 50 nodes also. The results are given in Table-V.
TABLE-V: Execution Time of Sum Of n Numbers Program
| Number of Executors | Time (in Secs) | |
| Alchemi Toolkit | Scady Toolkit | |
| 3 | 1.21 | 1.18 |
| 10 | 1.19 | 1.12 |
| 20 | 1.14 | 1.09 |
| 50 | 0.91 | 0.82 |
RESULTS
The results of the experiment of calculating sum of n natural numbers (100000 in our experiment) by using 3 nodes, 10 nodes, 20 nodes and 50 nodes are shown in Figure-42.
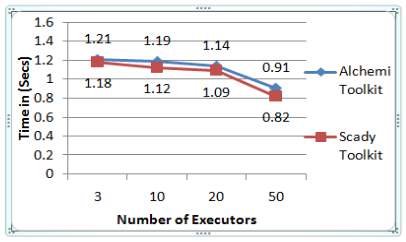
Fig-42: Scady & Alchemi Comparison
It can be noted that the time taken to calculate sum of n natural numbers (100000 in our experiment) decreases when the number of nodes increases. The result and time taken for calculation is printed in the result window. This experiment is repeated for 10, 20 and 50 nodes also.
Then deliberately a node that was executing the task was shutdown and the application was tested. The result and time taken for reallocation of task to another node and its execution is noted. The results are given in Table-VI.
TABLE-VI: Comparison Of Execution Times
With & Without Reallocation
| Number of Executors | Time (in Secs) – Scady Toolkit | |
| Without Reallocation | With Reallocation | |
| 3 | 1.18 | 3.76 |
| 10 | 1.12 | 3.34 |
| 20 | 1.09 | 2.87 |
| 50 | 0.82 | 2.04 |
RESULT ANALYSIS
The results of the experiment of calculating sum of n natural numbers (100000 in our experiment) by using 3 nodes, 10 nodes, 20 nodes and 50 nodes and the reallocation of task to another node in case of node failure are shown in Figure-43.
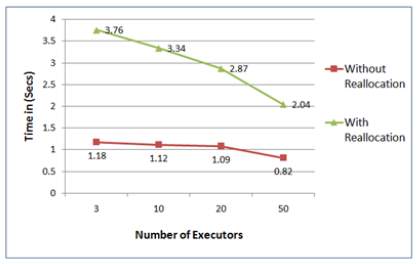
Fig-43: Comparison of Execution Times
It is noted that 100% efficiency is achieved in reallocation of the task to another node in case of node failure. Only exception is if there are no nodes available in the network for reallocation, the tasks are not reallocated. The time taken for the execution with reallocation is slightly more than the normal execution but can be compromised as the objective is fulfilled.
EXPERIMENT – V
Monte Carlo method is implemented. The parameters taken were number of Iterations, Number of nodes (processors/executors) required, Time taken to produce the result in mili seconds, and Dynamic node allocation if a node fails during the execution.
Monte Carlo method is based on random and large number of iterations and trials and takes the average of them. When the application is started, input parameters i.e. number of executors and number of iteration are provided for the calculation as given in Fig-44. These parameters are used for implementing the multithreading concepts and simulation of Monte Carlo method. The researcher used different scenarios by altering these parameters. In the first scenario, the researcher used the number of executors as three and number of iterations as 1000000. Then the value of pi is calculated.
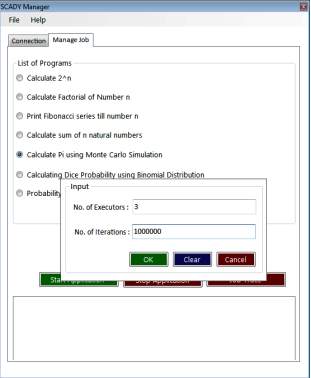
Fig – 44: Input Parameters (Scenario 1)
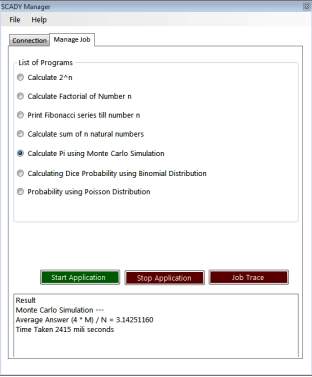
Fig – 45: Result (Scenario 1)
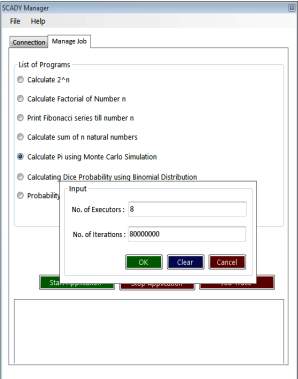
Fig – 46: Input Parameters (Scenario 2)
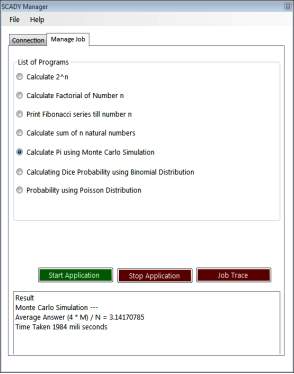
Fig – 47: Result (Scenario 2)
Then the researcher used a different scenario and increased the number of executors with value 8 and number of iterations with value 80000000 and recalculated the value of pi. This is shown in Fig – 46 and Fig – 47. In the similar manner, other scenarios were implemented and tested. Initially, the researcher implemented the scenarios in Scady and Alchemi .Net. The results are given in Table – VII.
TABLE – VII: Execution Time of Pi calculation
| Number of Executors | Number of Iterations | Time (in mili seconds) | |
| Scady Toolkit | Alchemi Toolkit | ||
| 3 | 1000000 | 2551 | 2509 |
| 8 | 80000000 | 1984 | 2016 |
| 8 | 100000000 | 1852 | 1979 |
| 8 | 800000000 | 1619 | 1846 |
| 20 | 800000000 | 1852 | 1979 |
| 50 | 800000000 | 1619 | 1846 |
Then the researcher also implemented the scenarios in Unicore as well as Globus grid environments. The comparative results are given in Table – VIII.
TABLE – VIII: Comparison Of Execution Times using other grid environments
| Number of Executors / Processors | Number of Iterations | Time (in Mili Secs) | |||
| Unicore Toolkit | Globus Toolkit | Alchemi Toolkit | Scady Toolkit | ||
| 3 | 1000000 | 3016 | 2515 | 2509 | 2551 |
| 8 | 80000000 | 2566 | 1998 | 2016 | 1984 |
| 8 | 100000000 | 2025 | 1945 | 1979 | 1852 |
Special scenarios were also tested for dynamic resource allocation. Deliberately a node that was executing the task was shutdown and the application was tested. Manager dynamically reallocates the task to another executor. The cache write-through method is used in which at the same time the data is written into the cache block and the corresponding main memory location. The data cached can be retrieved very fast on demand. And it is ensured that if in case a crash or power failure occurs, nothing will get lost as the same data is in main memory also. Write through method is the most preferred method for storing the data for the applications where data is critical and data loss cannot be tolerated. When the task is allocated to the new node, result from cache is read and the execution starts from the point where it stopped.
TABLE – IX: Execution Time When Node Fails
| Number of Executors | Number of Iterations | Time (in mili seconds) | |
| Scady Toolkit | Alchemi Toolkit | ||
| 3 | 1000000 | 3205 | 4376 |
| 8 | 80000000 | 2882 | 3780 |
| 8 | 800000000 | 2729 | 3225 |
| 20 | 800000000 | 2170 | 2636 |
| 50 | 800000000 | 1724 | 2108 |
Result Analysis
The results of the experiment of calculating value of pi by using different scenarios and the reallocation of task to another node in case of node failure are shown in the comparison chart of Fig – 48 & Fig – 49.
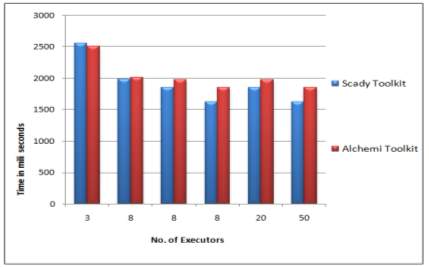
Fig – 48: Comparison Chart of Scady & Alchemi (When Node Fails)
Above comparison chart gives the comparison of Scady with Alchemi .Net toolkit. It indicates that as the numbers of processors/executors are increased, the calculation time decreases. Also the time taken by Scady is less as compared to Alchemi.
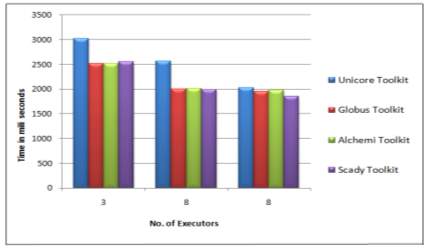
Fig – 49: Comparison Chart of Scady, Alchemi, Unicore & Globus
Above comparison chart gives the comparison of Scady with other Grid environments as well such as Unicore, Globus and Alchemi grids. It indicates that as the numbers of processors/executors are increased, the calculation time decreases. Also the time taken by Scady is less as compared to other grid environments.
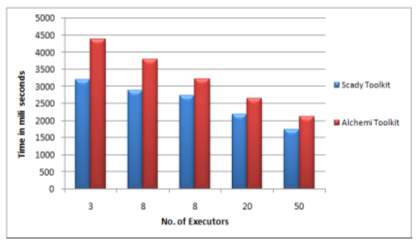
Fig – 50: Comparison Chart of Scady & Alchemi (Reallocation)
This chart indicates the time taken by Scady and Alchemi .Net grids when a node fails and the job is reallocated to a new node. It can be seen that Scady gives better performance as compared to Alchemi .Net as the task reallocated does not start from the beginning but is resumed from where it stopped.
CHAPTER 7: CONCLUSION
Targets Achieved
In this thesis, the researcher studied Alchemi .Net toolkit for Grid Computing & its APIs. The researcher found that even though, Alchemi .Net succeeded in providing sufficient performance in grid computations, it is not easy to provide a dynamically configurable environment that can help in ensuring that the computation does not fail even if any node or executor fails. To solve this problem, the researcher has constructed a small grid toolkit – SCADY and tried to add and extend the existing API of the available middleware. The researcher conducted case studies on both the toolkits and found that Scady toolkit provides the output in less time as compared to Alchemi. Also the time taken is very less when the number of executors increased.
Moreover, there was a need of Resource Allocation algorithm that can help in achieving high performance. To remove this limitation, the researcher made changes in the design of Scady and proposed a Resource Allocation algorithm based on CPU usage. Tasks are allocated according to the CPU usage. This usage for each node is checked every 10 seconds and if a node is found to be failed, the task is allocated to the next available node with less CPU load. The researcher conducted experiment using this Resource Allocation algorithm and found that tasks are now scheduled effectively.
The researcher also proposed a caching algorithm. At the executor node – intermediate results are written into cache using write-through method. This method stores the result in cache block as well as the main memory. Contents of cache are transferred to manager nodes at specific intervals. In case of node failure, the last transferred value of cache is taken and the thread with same id is allocated to another node of the network. The researcher implemented the caching algorithm by taking the problem of Monte Carlo simulation. It was found that the time taken for the execution with reallocation is slightly more than the normal execution but can be compromised as the task got completed and objective is fulfilled.
And the end, there was a need of security mechanism to secure and authenticate the communication. The researcher proposed a security mechanism based on the review findings. The proposed model use X.509 certificate based delegation model and public key cryptography algorithms like RSA with SHA. Root certificate and client certificates are generated and issued. I executed the grid toolkit with this certification model and found that the model is providing the required security to the system.
And to conclude and check the performance of SCADY, it was tested for high performance parallel applications and was compared with results of Alchemi.Net Grid Framework, Unicore and Globus. It was found that even though these frameworks provide good performance, Scady gives better results in node failure as the intermediate results are written into cache and as well as the main memory. And the contents of cache are transferred to manager nodes at specific intervals.
A significant difference of 0.16% to 1.19% is seen in the results of Scady with other middleware when resources are allocated normally and the tasks are started from beginning. And a significant difference of 8.3% to 15.4% is seen in the results of Scady with other middleware when node fails and task is allocated and started from the point of failure.
CHAPTER 8: POSSIBLE EXTENSION OF RESEARCH WORK
The research work undertaken can be extended in future in terms of following aspects:
- There is a need of cross-platform computation for robust and seamless computation not in a smaller domain but in a larger domain say cloud environment. Presently, cross-platform computation is not implemented in Scady – the middleware proposed.
- In cloud environment, the client end need not be restricted to desktop or laptop but the services can be extended through mobile devices also.
- The undertaken work of check pointing mechanism can be enhanced in terms of efficiency level so that it minimizes the time of reallocation of task and its execution.
- The resource allocation algorithm proposed in the undertaken work can be further enhanced to achieve more effective results.
- The caching algorithm proposed in the undertaken work can be also be further enhanced to achieve more effective results.
REFERENCES
[1] “Special Issue: Middleware for Grid Computing,” Concurr. Comput. Pr. Exper, 2007.
[2] P. Asadzadeh, R. Buyya, C. L. Kei, D. Nayar, and S. Venugopal, “Global Grids and Software Toolkits: A Study of Four Grid Middleware Technologies.”
[3] Y. Zhu et al., “Development of scalable service-oriented grid computing architecture,” 2007 Int. Conf. Wirel. Commun. Netw. Mob. Comput. WiCOM 2007, pp. 6001–6004, 2007.
[4] L. P. Gaspary, W. L. Da Costa Cordeiro, S. R. S. Franco, M. P. Barcellos, and G. G. H. Cavalheiro, “AGRADC: An architecture for autonomous deployment and configuration of grid computing applications,” Proc. – IEEE Symp. Comput. Commun., pp. 805–810, 2009.
[5] H. He, L. Chen, P. Yuan, X. Xu, and X. Wang, “A Security Architecture for Grid-Based Distributed Simulation Platform,” Comput. Intell. Ind. Appl. 2008. PACIIA ’08. Pacific-Asia Work., vol. 1, pp. 207–212, 2008.
[6] M. V. Jose and V. Seenivasagam, “Object Based Grid Architecture for enhancing security in grid computing,” 2011 Int. Conf. Signal Process. Commun. Comput. Netw. Technol., no. Icsccn, pp. 414–417, 2011.
[7] B. Rajkumar, D. Abramsont, and J. Giddy, “Nimrod / G : An Architecture for a Resource Management and Scheduling,” pp. 283–289, 2000.
[8] A. Tsaregorodtsev, V. Garonne, and I. Stokes-Rees, “DIRAC: A scalable lightweight architecture for high throughput computing,” Proc. – IEEE/ACM Int. Work. Grid Comput., pp. 19–25, 2004.
[9] Y. Zou, L. Zha, X. Wang, H. Zhou, and P. Li, “A layered Virtual Organization architecture for grid,” J. Supercomput., vol. 51, no. 3, pp. 333–351, 2010.
[10] F. Schreiber and R. Camplani, “Perla: A language and middleware architecture for data management and integration in pervasive information systems,” Softw. …, vol. 38, no. 2, pp. 478–496, 2012.
[11] C. C. H.B. Newman, I.C.Legrand, P. Galvez, R. Voicu, “MonALISA : A Distributed Monitoring Service ArchitectureNo Title,” in Computing in High Energy and Nuclear Physics, p. 1 to 8.
[12] B. Karakostas and G. Fakas, “An architecture for reliable mobile workflow in a grid environment,” Proc. 2009 4th Int. Conf. Internet Web Appl. Serv. ICIW 2009, pp. 499–504, 2009.
[13] R. Aversa, B. Di Martino, N. Mazzocca, and S. Venticinque, “MAGDA: A Mobile Agent based Grid Architecture,” J. Grid Comput., vol. 4, no. 4, pp. 395–412, 2006.
[14] R. Ramos-Pollan et al., “BIGS: A framework for large-scale image processing and analysis over distributed and heterogeneous computing resources,” 2012 IEEE 8th Int. Conf. E-Science, pp. 1–8, 2012.
[15] M. S. Sajat, S. Hassan, A. A. Ahmad, A. Y. Daud, A. Ahmad, and M. Firdhous, “Implementing a secure academic grid system – A malaysian case,” Proc. 10th Aust. Inf. Secur. Manag. Conf. AISM 2012, pp. 59–65, 2012.
[16] K. Yu, S. Engineer, and S. Consultant, “Case Study : Implementing the Oracle Grid Computing on Dell Hardware for Multiple ERP Applications Introduction to SUNY POC Project Grid Design and Implementation of POC project.”
[17] U. T. June, “UNICORE Rich Client user manual,” Workbench, no. June, 2010.
[18] A. Streit et al., “UNICORE 6 – Recent and future advancements,” Ann. des Telecommun. Telecommun., vol. 65, no. 11–12, pp. 757–762, 2010.
[19] N. V. Kanaskar, U. Topaloglu, and C. Bayrak, “Globus security model for grid environment,” ACM SIGSOFT Softw. Eng. Notes, vol. 30, no. 6, p. 1, 2005.
[20] R. Buyya and M. Murshed, “GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for Grid computing,” Concurr. Comput. Exp., vol. 14, no. 13–15, pp. 1175–1220, 2002.
[21] C. Xing, F. Liu, and K. Chen, “A job scheduling simulator in data grid based on GridSim,” in 2009 IEEE International Symposium on IT in Medicine & Education, 2009, pp. 611–616.
[22] S. I. Ahmed, R. Mustafizur, and M. Pathan, “Policy requirements to ensure security in enterprise grid security systems,” Proc. 2009 2nd Int. Conf. Comput. Sci. Its Appl. CSA 2009, 2009.
[23] Daniel, “Programming APIs,” 2014. [Online]. Available: http://gridengine.eu/programming-apis. [Accessed: 31-Dec-2014].
[24] M. Bhardwaj, S. Singh, and M. Singh, “IMPLEMENTATION OF SINGLE SIGN-ON AND DELEGATION MECHANISMS IN ALCHEMI . NET,” vol. 4, no. 1, pp. 289–292, 2011.
[25] A. Luther, R. Buyya, R. Ranjan, and S. Venugopal, “Alchemi: A .NET-based Enterprise Grid Computing System,” Buyya.Com, pp. 403–429, 2005.
[26] J. Frey, T. Tannenbaum, M. Livny, I. Foster, and S. Tuecke, “Condor-G: a computation management agent for multi-institutional grids,” Proc. 10th IEEE Int. Symp. High Perform. Distrib. Comput., pp. 237–246, 2001.
[27] G. Team, “Garuda Grid Architecture.”
[28] A. Chien, B. Calder, S. Elbert, and K. Bhatia, “Entropia: Architecture and performance of an enterprise desktop grid system,” J. Parallel Distrib. Comput., vol. 63, no. 5, pp. 597–610, 2003.
[29] B. Calder, A. A. Chien, J. Wang, and D. Yang, “The entropia virtual machine for desktop grids,” Proc. 1st ACM/USENIX Int. Conf. Virtual Exec. Environ., pp. 186–196, 2005.
[30] B. Hughes, “Building Computational Grids with Apple ’ s Xgrid Middleware,” in Proceeding ACSW Frontiers ’06 Proceedings of the 2006 Australasian workshops on Grid computing and e-research, pp. 47–54.
[31] R. C. Jammalamadaka, R. Gamboni, S. Mehrotra, K. E. Seamons, and N. Venkatasubramanian, “iDataGuard: middleware providing a secure network drive interface to untrusted internet data storage,” Proc. 11th Int. Conf. Extending database Technol. Adv. database Technol., pp. 710–714, 2008.
[32] A. Gaddah and T. Kunz, “A survey of middleware paradigms for mobile computing,” Techical Rep., no. July, 2003.
[33] D. Görgen, J. K. Lehnert, H. Frey, and P. Sturm, “{SELMA}: A Middleware Platform for Self-Organzing Distributed Applications in Mobile Multihop Ad-hoc Networks,” Commun. Networks Distrib. Syst. Model. Simul. {CNDS’04}, pp. 1–16, 2004.
[34] G. Caillat, O. Lodygensky, E. Urbah, G. Fedak, and H. He, “Towards a Security Model to Bridge Internet Desktop Grids and Service Grids,” Springer Berlin Heidelberg, 2009, pp. 247–259.
[35] J. M. Schopf et al., “Monitoring the grid with the Globus Toolkit MDS4,” J. Phys. Conf. Ser., vol. 46, no. 1, pp. 521–525, Sep. 2006.
[36] Xuehai Zhang and J. M. Schopf, “Performance analysis of the Globus Toolkit Monitoring and Discovery Service, MDS2,” in IEEE International Conference on Performance, Computing, and Communications, 2004, pp. 843–849.
[37] M. K. Vachhani and K. H. Atkotiya, “Globus Toolkit 5 (GT5): Introduction of a tool to develop Grid Application and Middleware,” Int. J. Emerg. Technol. Adv. Eng., vol. 2, no. 7, pp. 174–178, 2012.
[38] G. T. Gram, K. Concepts, G. T. Gram, and K. Concepts, “GT 5.2.5 GRAM5 Key Concepts.”
[39] J. Bresnahan, M. Link, R. Kettimuthu, and I. Foster, “Managed GridFTP,” IEEE Int. Symp. Parallel Distrib. Process. Work. Phd Forum, pp. 907–913, 2011.
[40] P. Z. Kolano, “Mesh: Secure, Lightweight, Grid Middleware Using Existing SSH Infrastructure,” Proc. 12th ACM Symp. Access Control Model. Technol. – SACMAT ’07, p. 111, 2007.
[41] D. Nanthiya and P. Keerthika, “Load balancing GridSim architecture with fault tolerance,” in 2013 International Conference on Information Communication and Embedded Systems (ICICES), 2013, pp. 425–428.
[42] A. Caminero, A. Sulistio, B. Caminero, C. Carrion, and R. Buyya, “Extending GridSim with an architecture for failure detection,” in 2007 International Conference on Parallel and Distributed Systems, 2007, pp. 1–8.
[43] A. Luther, R. Buyya, R. Ranjan, and S. Venugopal, “Alchemi: A .NET-based Grid Computing Framework and its Integration into Global Grids,” p. 17, 2004.
[44] K. Shvachko, H. Kuang, S. Radia, and R. Chansler, “The Hadoop distributed file system,” 2010 IEEE 26th Symp. Mass Storage Syst. Technol. MSST2010, pp. 1–10, 2010.
[45] A. S. Grimshaw and M. A. Humphrey, “Legion: An Integrated Architecture for Grid Computing,” pp. 1–33, 2003.
[46] A. W. Cooke et al., “The Relational Grid Monitoring Architecture: Mediating Information about the Grid,” J. Grid Comput., vol. 2, no. 4, pp. 323–339, Dec. 2004.
[47] G. Gombás and Z. Balaton, “A flexible multi-level grid monitoring architecture,” Grid Comput., pp. 214–221, 2004.
[48] Z. Balaton and G. Gombás, “Resource and Job Monitoring in the Grid,” Springer Berlin Heidelberg, 2003, pp. 404–411.
[49] R. Byrom et al., “Relational Grid Monitoring Architecture (R-GMA),” p. 7, 2003.
[50] A. Cooke et al., “R-GMA: An Information Integration System for Grid Monitoring,” Springer Berlin Heidelberg, 2003, pp. 462–481.
[51] E. Imamagic and D. Dobrenic, “Grid infrastructure monitoring system based on Nagios,” in Proceedings of the 2007 workshop on Grid monitoring – GMW ’07, 2007, p. 23.
[52] M. L. Massie, B. N. Chun, and D. E. Culler, “The ganglia distributed monitoring system: design, implementation, and experience,” Parallel Comput., vol. 30, no. 7, pp. 817–840, 2004.
[53] R. L. Ribler, J. S. Vetter, H. Simitci, and D. A. Reed, “Autopilot: adaptive control of distributed applications,” in Proceedings. The Seventh International Symposium on High Performance Distributed Computing (Cat. No.98TB100244), pp. 172–179.
[54] R. L. Ribler, H. Simitci, and D. A. Reed, “The Autopilot performance-directed adaptive control system,” Futur. Gener. Comput. Syst., vol. 18, no. 1, pp. 175–187, 2001.
[55] K. Maghraoui and T. Desell, “Towards a middleware framework for dynamically reconfigurable scientific computing,” Adv. Parallel Comput., vol. 14, pp. 275–301, 2005.
[56] R. Nagaraja and G. Raju, “COMMPC-Component Based Middleware for Pervasive Computing,” Ijcsns, vol. 11, no. 9, p. 124, 2011.
[57] M. Mauve, J. Widmer, and H. Hartenstein, “A survey on position-based routing in mobile ad hoc networks,” IEEE Netw., vol. 15, no. 6, pp. 30–39, 2001.
[58] T. Sivaharan, G. Blair, and G. Coulson, “GREEN: A configurable and re-configurable publish-subscribe middleware for pervasive computing,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 3760 LNCS, pp. 732–749, 2005.
[59] M. V. Reddy, A. V. Srinivas, T. Gopinath, and D. Janakiram, “Vishwa: A reconfigurable P2P middleware for Grid Computations,” in 2006 International Conference on Parallel Processing (ICPP’06), pp. 381–390.
[60] K. J. Naik, A. Jagan, and N. S. Narayana, “A novel algorithm for fault tolerant job Scheduling and load balancing in grid computing environment,” in 2015 International Conference on Green Computing and Internet of Things (ICGCIoT), 2015, pp. 1113–1118.
[61] N. Mishra, R. Yadav, and S. Maheshwari, “Security Issues in Grid Computing,” Int. J. Comput. Sci. Appl., vol. 4, no. 1, pp. 179–187, 2014.
[62] V. Welch et al., “X.509 Proxy Certificates for Dynamic Delegation,” 3rd Annu. PKI RD Work., vol. 14, pp. 31–47, 2004.
[63] Sabir Ismail, Abu Fazal Md Shumon, and Md Ruhul Amin, “Distributed memory caching for the fail safe computation to improve the Grid performance,” in 2010 13th International Conference on Computer and Information Technology (ICCIT), 2010, pp. 198–203.
[64] M. Hijab and D. Avula, “Resource Discovery in Wireless , Mobile and Ad hoc Grids – Issues and Challenges,” Environments, pp. 502–505, 2011.
[65] J. Montes, A. Sánchez, and M. S. Pérez, “Grid global behavior prediction,” Proc. – 11th IEEE/ACM Int. Symp. Clust. Cloud Grid Comput. CCGrid 2011, pp. 124–133, 2011.
[66] F. Uzoka, “A case analysis of factors affecting the adoption of grid technology by universities,” IST-Africa Conf. …, 2011.
[67] N. Karuna Mangala, C. Janaki, S. Shashi, and C. Subrata, “Galaxy workflow integration on GARUDA Grid,” Proc. Work. Enabling Technol. Infrastruct. Collab. Enterp. WETICE, pp. 194–196, 2012.
[68] N. Mangala and A. Jacob, “Comprehensive testing methodology for the operational National Grid Computing infrastructure—GARUDA,” … (EAIT), 2012 Third …, pp. 129–134, 2012.
[69] K. Prasad, H. Gupta, N. Mangala, C. Subrata, H. Deepika, and P. Rao, “Challenges of monitoring tool for operational Indian national grid GARUDA,” 2013 Natl. Conf. Parallel Comput. Technol. PARCOMPTECH 2013, 2013.
[70] N. A. Azeez and I. M. Venter, “Towards achieving scalability and interoperability in a triple-domain grid-based environment (3DGBE),” 2012 Inf. Secur. South Africa – Proc. ISSA 2012 Conf., 2012.
[71] M. C. Vijayalakshmi, “An integrated development environment to establish web services in grid computing Using .NET Framework 4.5 and Visual Basic 2012,” Comput. Inf. Technol., pp. 1–8, 2013.
[72] S. Hema and S. Jaganathan, “Improvisioning hadoop in globus toolkit,” Proc. IEEE Int. Conf. Circuit, Power Comput. Technol. ICCPCT 2013, pp. 1082–1088, 2013.
[73] E. Cody, R. Sharman, R. H. Rao, and S. Upadhyaya, “Security in grid computing: A review and synthesis,” Decis. Support Syst., vol. 44, no. 4, pp. 749–764, 2008.
[74] G. Koole and R. Righter, “Resource allocation in grid computing,” J. Sched., vol. 11, no. 3, pp. 163–173, Jun. 2008.
[75] A. Marosi, G. Gombas, Z. Balaton, P. Kacsuk, and T. Kiss, “Sztaki Desktop Grid: Building a Scalable, Secure Platform for Desktop Grid Computing,” in Making Grids Work, Boston, MA: Springer US, 2008, pp. 365–376.
[76] P. Bastian et al., “A generic grid interface for parallel and adaptive scientific computing. Part I: abstract framework,” Computing, vol. 82, no. 2–3, pp. 103–119, Jul. 2008.
[77] D. Thain, C. Moretti, and J. Hemmes, “Chirp: a practical global filesystem for cluster and Grid computing,” J. Grid Comput., vol. 7, no. 1, pp. 51–72, Mar. 2009.
[78] B. Lang, I. Foster, F. Siebenlist, R. Ananthakrishnan, and T. Freeman, “A Flexible Attribute Based Access Control Method for Grid Computing,” J. Grid Comput., vol. 7, no. 2, pp. 169–180, Jun. 2009.
[79] H. Kurdi, M. Li, and H. Al-Raweshidy, “A Classification of Emerging and Traditional Grid Systems,” IEEE Distrib. Syst. Online, vol. 9, no. 3, pp. 1–1, Mar. 2008.
[80] S. Al-Kiswany, M. Ripeanu, S. S. Vazhkudai, and A. Gharaibeh, “stdchk: A Checkpoint Storage System for Desktop Grid Computing,” in 2008 The 28th International Conference on Distributed Computing Systems, 2008, pp. 613–624.
[81] Q. Liu and Y. Liao, “Grouping-Based Fine-Grained Job Scheduling in Grid Computing,” in 2009 First International Workshop on Education Technology and Computer Science, 2009, pp. 556–559.
[82] T. Kosar and M. Balman, “A new paradigm: Data-aware scheduling in grid computing,” Futur. Gener. Comput. Syst., vol. 25, no. 4, pp. 406–413, 2009.
[83] W. Lee, A. Squicciarini, and E. Bertino, “The Design and Evaluation of Accountable Grid Computing System,” in 2009 29th IEEE International Conference on Distributed Computing Systems, 2009, pp. 145–154.
[84] W.-C. Chung and R.-S. Chang, “A new mechanism for resource monitoring in Grid computing,” Futur. Gener. Comput. Syst., vol. 25, no. 1, pp. 1–7, 2009.
[85] G. C. Silaghi, F. Araujo, L. M. Silva, P. Domingues, and A. E. Arenas, “Defeating Colluding Nodes in Desktop Grid Computing Platforms,” J. Grid Comput., vol. 7, no. 4, pp. 555–573, Dec. 2009.
[86] S. Camarasu-Pop, T. Glatard, J. T. Mościcki, H. Benoit-Cattin, and D. Sarrut, “Dynamic Partitioning of GATE Monte-Carlo Simulations on EGEE,” J. Grid Comput., vol. 8, no. 2, pp. 241–259, Jun. 2010.
[87] L. Wang, G. von Laszewski, D. Chen, J. Tao, and M. Kunze, “Provide Virtual Machine Information for Grid Computing,” IEEE Trans. Syst. Man, Cybern. – Part A Syst. Humans, vol. 40, no. 6, pp. 1362–1374, Nov. 2010.
[88] B. Tang, M. Moca, S. Chevalier, H. He, and G. Fedak, “Towards MapReduce for Desktop Grid Computing,” in 2010 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, 2010, pp. 193–200.
[89] F. G. Khan, K. Qureshi, and B. Nazir, “Performance evaluation of fault tolerance techniques in grid computing system,” Comput. Electr. Eng., vol. 36, no. 6, pp. 1110–1122, 2010.
[90] U. Schwiegelshohn et al., “Perspectives on grid computing,” Futur. Gener. Comput. Syst., vol. 26, no. 8, pp. 1104–1115, 2010.
[91] Y. Wei and M. B. Blake, “Service-Oriented Computing and Cloud Computing: Challenges and Opportunities,” IEEE Internet Comput., vol. 14, no. 6, pp. 72–75, Nov. 2010.
[92] N. Sadashiv and S. M. D. Kumar, “Cluster, grid and cloud computing: A detailed comparison,” in 2011 6th International Conference on Computer Science & Education (ICCSE), 2011, pp. 477–482.
[93] D. Garlasu et al., “A big data implementation based on Grid computing,” in 2013 11th RoEduNet International Conference, 2013, pp. 1–4.
[94] R. Garg and A. Kumar Singh, “Fault Tolerance In Grid Computing: State of the Art and Open Issues,” Int. J. Comput. Sci. Eng. Surv., vol. 2, no. 1, pp. 88–97, 2011.
[95] F. Almenarez, A. Marin, D. Diaz, A. Cortes, C. Campo, and C. Garcia-Rubio, “A Trust-based Middleware for Providing Security to Ad-Hoc Peer-to-Peer Applications,” in 2008 Sixth Annual IEEE International Conference on Pervasive Computing and Communications (PerCom), 2008, pp. 531–536.
[96] P. Ford and C. C. Attribution, “HTCondor Security Mechanisms Overview HTCondor Security › Allows authentication of,” 2005.
[97] L. Ramakrishnan, “Grid computing – Securing next-generation grids,” IT Prof., vol. 6, no. 2, pp. 34–39, Mar. 2004.
[98] S. Wang, Z. Cao, and H. Bao, “Efficient Certificateless Authentication and Key Agreement Protocol for Grid Computing,” Program, vol. 7, no. 3, pp. 342–347, 1954.
[99] A. B. Patel, P. Thanawala, and J. G. Pandya, “Grid Resource Brokering for High Performance Parallel Applications,” Int. J. Comput. Appl. Eng. Technol. Sci. (IJ-CA-ETS), ISSN 0974-3596, vol. 3, no. 4, pp. 1–8, 2013.
[100] M. M. Yassa, H. A. Hassan, and F. A. Omara, “Collaboration Network Organization Grid-Cloud Convergence Architecture (CNOGCA): Based on open grid services architecture,” 2012 22nd Int. Conf. Comput. Theory Appl. ICCTA 2012, no. October, pp. 67–71, 2012.
BIBLIOGRAPHY
[BLUEPRINT] Foster, I., and Kesselman, C. (eds.). The Grid: BluePrint for a new Computing Infrastructure. Morgan Kaufmann, 1999.
[FOSTERARTICLE] Foster, I. What is the Grid?. Grid Today, Vol.1 No. 6, July 22, 2002.
[MDS-2] Czajkowski, K., Fitzgerald, S., Foster, I., Kesselman, C., Grid Information Services for Distributed Resource Sharing. Proceedings of the 10th IEEE International Symposium on High Performance Distributed Computing, 2001.
[GRID FORUM-PAGE] http://www.gridforum.org
[UNICORE-PAGE] https://www.unicore.eu/documentation/architecture/
[GLOBUS-PAGE] http://www.globus.org
[GLOBUS-META] Foster, I., and Kesselman, C. A Metacomputing Infrastructure Toolkit. International Journal of Supercomputing Applications, 11(2):115-128, 1997.
[CONDOR] Litzkow, M., Livny, M., and Mutka, M. Condor – A Hunter of Idle Workstations. Proc. 8th Intl Conf. on Distributed Computing Systems, 1988, pp. 104-111.
[CONDOR-G] Frey, J., Tannenbaum, T., Livny, M., Foster, I., Tuecke, S. Condor-G: A Computation Management Agent for Multi-Institutional Grids. Proceedings of the Tenth International Symposium on High Performance Distributed Computing (HPDC-10), IEEE Press, August 2001
[CONDOR-ADS] Nicholas Coleman, An Implementation of Matchmaking Analysis in Condor, Masters Project report, University of Wisconsin, Madison, May 2001
[GLOBUS TOOLKIT-PAGE] http://www-unix.globus.org/toolkit/
[GLOBUS GRAM-PAGE] http://www-unix.globus.org/api/c-globus-2.2/globus_gram_documentation/html/index.html
[OGSI on .NET-PAGE] http://www.cs.virginia.edu/~humphrey/GCG/ogsi.net.html
[MS .NET GRID PROJECT-PAGE] http://www.epcc.ed.ac.uk/~ogsanet/
APPENDIX – LIST OF PUBLICATION
Journal
- R. Bhatnagar and Dr. J. Patel, “PERFORMANCE ANALYSIS OF A GRID MONITORING SYSTEM – GANGLIA,” International Journal of Emerging Technology and Advanced Engineering, vol. 3, issue 8, pp. 362–365, August 2013.
- R. Bhatnagar and Dr. J. Patel, “PERFORMANCE ANALYSIS OF A GRID MONITORING SYSTEM – AUTOPILOT,” Journal of Sci-Tech Research, pp. 1–6.
- R. Bhatnagar and Dr. J. Patel, “An Empirical Study of Security Issues in Grid Middleware,” International Journal of Emerging Technology and Advanced Engineering, vol. 4, issue 1, pp. 470–474, January 2014.
- R. Bhatnagar and Dr. J. Patel, “API Specification for a Small Grid Middleware – SCADY IEEE Xplore Document”. Ieeexplore.ieee.org. N.p., 2014, DOI: 10.1109/INDICON.2014.7030545
- R. Bhatnagar and Dr. J. Patel, “Scady: A scalable & dynamic toolkit for enhanced performance in grid computing – IEEE Xplore Document”. Ieeexplore.ieee.org. N.p., 2015, DOI: 10.1109/ PERVASIVE.2015.7087085
- R. Bhatnagar, Dr. J. Patel, and N. Vasoya, “Dynamic resource allocation in SCADY grid toolkit – IEEE Xplore Document”. Ieeexplore.ieee.org. N.p., 2015, DOI: 10.1109/CCAA.2015.7148471
- R. Bhatnagar, Dr. J. Patel, S. Rindani, and N. Vasoya, “Implementation of Caching Algorithm in Scady Grid Framework – IEEE Xplore Document”. Ieeexplore.ieee.org. N.p., 2015, DOI: 10.1109/ ICCCNT.2015.7395206
- R. Bhatnagar and Dr. J. Patel “Security Model for Scady Grid Toolkit – Analysis and Implementation”, International Journal of Innovative Research in Computer and Communication Engineering, vol. 3, issue. 12, pp. 12080–12086, Dec 2015.
- R. Bhatnagar and J. Patel, “Performance Analysis of SCADY Grid for High Performance Parallel Applications”, International Journal of Innovative Research in Computer and Communication Engineering, vol. 4, issue. 6, pp. 10975–10983, June 2016.
Conferences
- Annual IEEE India Conference (INDICON), 2014, Pune, India – “API specification for a small Grid Middleware – SCADY”.
- International Conference on Pervasive Computing (ICPC), 2015, IEEE Pune Section, Pune, India – “Scady: A scalable & dynamic toolkit for enhanced performance in grid computing”.
- International Conference on Computing Communication & Automation (ICCCA) 2015, IEEE UP Section, Greater Noida, India – “Dynamic resource allocation in SCADY grid toolkit”.
- International Conference on Computing, Communication & Networking Technologies (ICCCNT) 2015, Texas, USA – “Implementation of Caching Algorithm in Scady Grid Framework”.
Publication Summary
| Sr. No. | Journal | Impact Factor | ISSN No. / DOI / ISBN | Paper Title | Published Date |
| 1 | IJETAE | 4.027 | 2250-2459 | Performance Analysis of Grid Monitoring System – Ganglia | Aug 2013 |
| 2 | KSV-JSTR | – | 0974-9780 | Performance Analysis of Grid Monitoring System – Autopilot | Dec 3013 |
| 3 | IJETAE | 4.027 | 2250-2459 | An Empirical Study of Security Issues in Grid Middleware | Jan 2014 |
| 4 | IEEE Xplore | 5.629 | 10.1109/INDICON.2014.7030545
ISBN – 978-1-4799-5362-2 |
API Specification for a Small Grid Middleware – SCADY | Feb 2015 |
| 5 | IEEE Xplore | 5.629 | 10.1109/PERVASIVE.2015.7087085
ISBN – 978-1-4799-6272-3 |
Scady: A Scalable & Dynamic Toolkit for Enhanced Performance in Grid Computing | April 2015 |
| 6 | IEEE Xplore | 5.629 | 10.1109/CCAA.2015.7148471
ISBN – 978-1-4799-8889-1 |
Dynamic Resource Allocation in SCADY Grid Toolkit | July 2015 |
| 7 | IJIRCCE | 6.577 | 2320-9798 | Security Model for Scady Grid Toolkit – Analysis and Implementation | Dec 2015 |
| 8 | IEEE Xplore | 5.629 | 10.1109/ICCCNT.2015.7395206
ISBN – 978-1-4799-7983-7 |
Implementation of Caching Algorithm in Scady Grid Framework | Feb 2016 |
| 9 | IJIRCCE | 6.577 | 2320-9798 | Performance Analysis of SCADY Grid for High Performance Parallel Applications | June 2016 |
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: