Information Retrieval Model System Design
Info: 7525 words (30 pages) Dissertation
Published: 23rd Dec 2021
Tagged: Information Systems
CHAPTER 1: INTRODUCTION
1.1 INFORMATION RETRIEVAL
The advent of Internet has created an information space that is so vast and of unpredictable size. Though it offers many benefits with respect to information seeking, it also leaves many challenges to be addressed by the research community. Information Retrieval is an area in computer science that deals with the search of information in a given domain or information repository. The classic Information Retrieval model is represented in the Figure 1.1. Though the usage of retrieval systems date back to 1960’s, the increase of the processing power and the storage systems resulted in the development of new retrieval systems[1] which has now become widely visible across all the domains. In particular, after the success of search-based applications, there has been a vibrant growth in Information Retrieval. The conventional approaches have been replaced by fully automated approaches of managing and retrieving information.
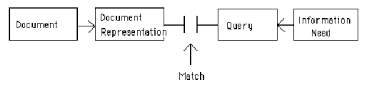
Figure 1.1 The Classic Information Retrieval Model
The need of an Informational Retrieval system arises when the collection of data reaches a state where the conventional cataloguing system will never be able to cope with the huge amount of data to be managed. Information Retrieval system locates the information that is relevant to the user’s information need specified as a query. Since the digital data has been scaling up in a way which is beyond comprehension or understanding, the retrieval becomes a tedious task and alsoposes many challenges with respect to the varieties of datato be handled and managed.
The effective retrieval of information is based upon the tasks performed by the user and the logical view of the system [2]. The interaction of the user with the retrieval system happens either through browsing or retrieval. The Information retrieval system user has to transform the information need into a query in a language specified by the system. Normally this is done by specifying few keywords that convey the information need which is referred to as executing a retrieval task. The Information Retrieval system consists of basic activities normally referred to as Information Retrieval process.
1.2 INFORMATION RETRIEVAL PROCESS
An Information Retrieval system is supported by basic processes such as i) Query Handling ii) Indexing and iii) Matching which together constitutes the Information Retrieval process[3]. The following diagram FIGURE 1.2 illustrates the Information Retrieval process.
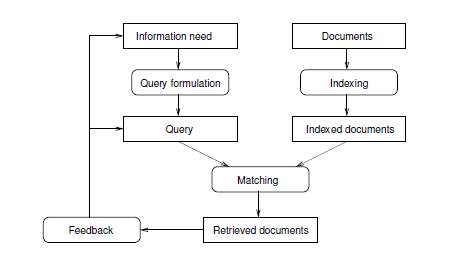
Figure 1. 2 : INFORMATION RETRIEVAL PROCESS
The rectangular boxes represent the information that is supplied as input to the process, and the rounded rectangles represent the processes. Any improvement in any of the above components will result in the improvement of the overall Information Retrieval system.
Indexing happens in the back end without the direct involvement of the user and is responsible for the representation of the documents. The indexing process includes storing the document either partly or in some case the whole document. The index is always built before the searching begins and is a constant dynamic process. There are many indexing techniques such as signature files, suffix arrays and inverted files.
The user’s information need is normally referred to as a query. The process of translating the information need into a query is called as query formulation. In its original form, a query consists of keywords, and the documents containing those keywords are searched for. A query may consist of a single word or a combination of words with multiple operations.
The query representation is further matched with the document representation that is stored in the index file and is referred to as the matching process. It results in a set of ordered documents based on the relevance and is referred to as the ranked list. There are various ranking algorithms that have evolved over a period of time such as PageRank , HITS (Hypertext Induced Topic Search), Boolean spread; Vector spread and most-cited. However, the focus of this work has been around Query Handling.
1.3 INFORMATION RETRIEVAL MODEL
An Information Retrieval model is defined as a quadruple [D, Q, F, Rel(qi,dj) ] where
- D represents a group of documents found in a collection.
- Q represents a group of information needs which is referred to as queries.
- F represents a Framework that consists of documents, queries with their relationships with those documents.
- Rel (qi,dj) represents the score which is associated with the query qi and the document dj. It is used to arrange the documents in order to be displayed to the user.
To construct a model, it is important to understand how the document and the query are represented. Based on this representation, the framework is developed. It also provides a way in which the documents can be ordered, based on the score generated which in turn represents the level of relevance between the query and document. In the traditional Boolean model, the documents and the basic set operations are available in the framework, whereas in the vector model the algebra operations on vectors are available on the framework and for the probabilistic model the Bayes theorem and probability operations are part of the framework.
As years passed by, various other alternative models have been put forward for each type of classic models. Extended Boolean model and fuzzy model have been put forward an alternative set-theoretic models, The Neural network model, latent semantic indexing and generalized vector models have been put forward as alternative algebraic models, and the inference network and the belief network have been proposed as alternative probabilistic models [4]. Beyond referring the textual content in the documents, the structure present in the written text is also referred using structural models like proximal nodes model and Non-overlapping lists model. The following figure (Figure 1.3) depicts the classical information retrieval models. The classic models are elaborated in the following (section 1.3.1), (section1.3.2) and (section 1.3.3).
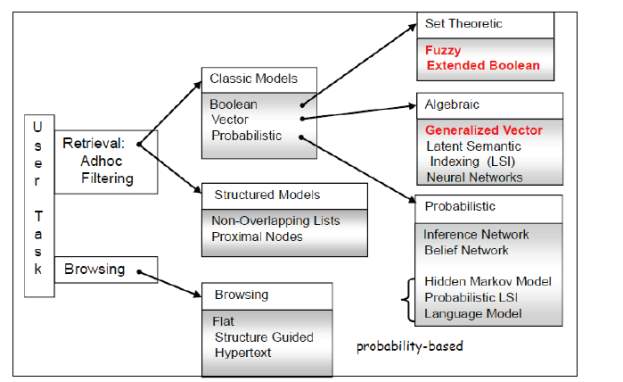
Figure 1.3 : INFORMATION RETRIEVAL MODELS
1.3.1 THE BOOLEAN MODEL
This model is considered to be one of the oldest and the traditional Information Retrieval model known. This model can be explained well by mapping the terms in the query with a set of documents. For example, the term “Botany” defines all the documents with the term “Botany” and indexes them. Using the Boolean operators, the terms in the query and the concerned documents can be combined to form a whole new set of documents. Using AND operator between two terms will be giving a set of documents that will smaller or equal to the document set otherwise, whereas using OR operator will fetch a set of documents that will be greater or equal to the document set otherwise. For,e.g. the information need “Botany AND Zoology” will be giving a set of documents that contain both the words and so the query with the keywords “Botany AND Zoology” will be giving a set of documents that are either having the word “Botany” or “Zoology”. The representation is clearly explained in the following Venn diagrams (Figure 1.4, Figure 1.5 and Figure 1.6). The set of documents that can be retrieved are well represented as grey areas.
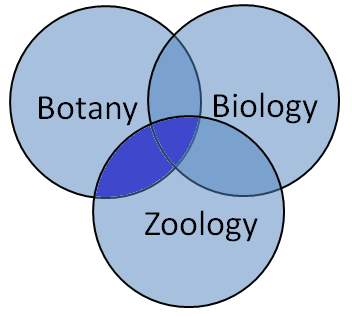
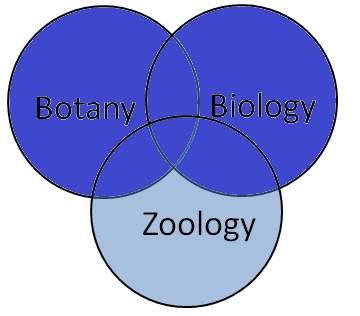
Figure 1.4 Botany AND Zoology Figure 1.5 Botany OR Zoology
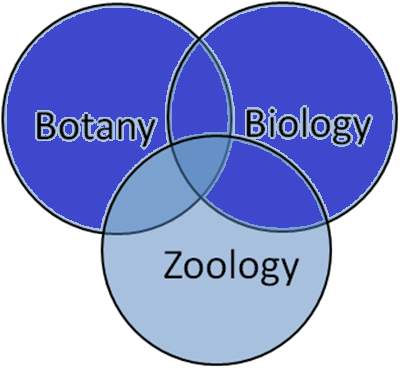
Figure 1.6 (Botany OR Biology) AND NOT (Botany AND Zoology)
This model provides the end user with a sense of system control. It is because of the fact that the end user immediately understands why the document is retrieved or not. It is also easy to understand why the document is retrieved or not retrieved. In case of a query “Botany AND Zoology AND Biology” will not retrieve a document that contains the terms “Family” or “Friends” or the “Parents”, but will also fail to retrieve a document which may contain “Botany” and “Zoology” but not “Biology”. But however, there are serious limitations in this model, such as a failure to provide aranking based on the relevance incase of retrieving multiple documents.
1.3.2 VECTOR SPACE MODEL
This model is a widely adopted model that was proposed by Gerard Salton and his team of researchers which is based on a similarity condition explained by the vector representation. Every document in the document space and the information need put forward as a query are expressed using a vector in the term space. The similarity score between both the vectors is computed. This model takes into consideration of a notion that, the document is expressed using a set of words and hence the words represented in a vector can be considered as the document representation. The query which is a set of keywords can also be represented as a vector. The similarity score can be computed by measuring the distance between the document vector and the query vector, which represents how close or far the document is related to the query. The following diagram (figure 1.7) illustrates the query representation and document representation in vector space model. The example of the vector representation of a document and query that is spanned by the following terms Botany, Zoology and Biology are as follows.
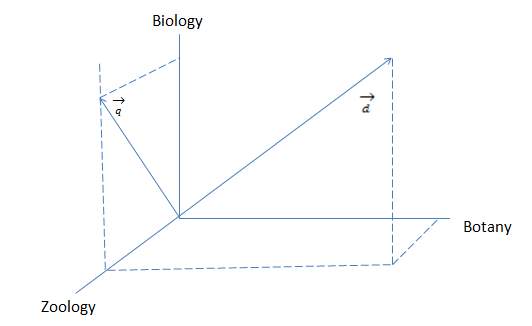
Figure 1.7: A query and documents representation in the vector space model.
The similarity score is normally the cosine of the angle that separates the two vectors
→qand
→d. The cosine of the angle is 0 if the vectors are orthogonal in the space and is 1 if the angle is 0 degrees. The formula is given as follows.
Score (
→d,
→q) =
∑k=1mn(dk). n(qk) ———————— (1)
Where n(vk) =
vk∑k=1mvK2 ————————- (2)
The representation of angles between the vectors in the dimensional space makes it easy to explain. This geometric interpretation adapted in the vector space approach makes it easy to use in challenges related to Information Retrieval. It is also widely used in the field of clustering of documents and in the Automatic categorization of Textual data.
1.3.3 PROBABILISTIC MODEL
This model as the name suggests is based on the Theory of Probability. Hence the similarity score is computed between the query and the document with the probability that the document is relevant to the query. Many approaches were proposed based on the underlying model. Consider the probability of the relevance which is represented as P(R), and the set of all the different possible outputs in the experiment referred to as sample space. With respect of P(R), the outcome will be either relevant or irrelevant where “1” denotes relevant and “0” denotes irrelevant.
Suppose there are 2 million documents in a collection, and consider that there are 200 documents which are relevant to the collection, then the probability of relevance is calculated as follows P (R =1) = 200/2,000,000 = 0.0001. Suppose P(Dt ) is the probability that a document consists of the term “t” and the sample space represented as {0,1}, where “0” is the value if the term “t” is not present in the document, and “1” if the term “t” is present in the document. The probability P(R, Dt) represents the combined probability with several outcomes that is represented as {(0,0),(0,1),(1,0),(1,1)}. P(R=1|Dt =1) is the relevance probability if the document containing the terms “t” is considered.
Different models such as Probabilistic Indexing model and Probabilistic Retrieval model that uses Probability theory have been proposed over the period of time and have found its usage in addressing different challenges related to IR. An example illustrating the Probabilistic Retrieval model is elaborated below in Figure 1.8.
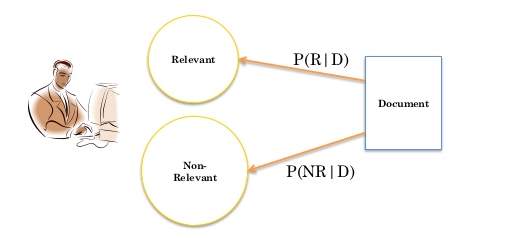
Figure 1.8: The Probabilistic Retrieval model.
Suppose ‘R’ represents the total no of Relevant documents, ‘NR’ represents the total no of Non Relevant documents and ‘D’ represents the document space then, P(R|D) represents the probability of relevant documents among the total documents available in the Document and P(NR|D) represents the probability of non relevant documents among the total documents available. The Bayes Rule is also used in the Probability model, and is defined as follows
P (R|D) =
P DRP(R)P(D) ————————————————— (3)
In the probability retrieval model P(R|D) can be interpreted as follows. If there are 20 documents that are represented by ‘D’ and out of that 18 are relevant, then P(R|D) = 0.9. Few more models that are used in many other areas of Information Retrieval are also briefly explained below in section 1.3.4.
1.3.4. ADDITIONAL MODELS
Various other models have also been specified over the period of time, and they deal with different features. Few of them are briefly elaborated below:
a) Language Models:
This model is based on the notion that every document is represented as a language model and the likelihood of the document generating the information need is calculated.
b) Model-based on Inference Network:
This model incorporates Bayesian Network to find out the relevance of the document to the query that is imposed. The “evidence” that is incorporated in the document about its relevancy allows the inference to be made. The inference is used to compute the similarity score.
c) Model-based on Latent Semantic Indexing:
The Term-document matrix representation is used to represent the term occurrence in the document. The single value decomposition (SVD) is used to remove the noise that is found in the document so that many documents that will be having the similar semantics can be located in the time-space close to close.
d) Model-based on Neural Network:
This model is based upon Neural Network, where the similarity is computed based on the links that are available between the query and the documents. When the query is given, it results in a series of links to be activated which is represented as a Neurons or Nodes that connects a document with the query. The similarity score is computed based on that value of nodes available for the document and the query. The network is further trained by adjusting the weights in the links that connect the document with the query.
e) Model-based on Genetic Algorithm:
This model focuses on the concept of evolution which points to the fact that the optimized query aimed at finding the documents that are relevant has to be evolved. The seed query which is the first query generated is further developed into a newer one with individual term weights estimates or random values. As the process continues, the newly formed query survives by being close to the set of relevant documents and the other related queries which are not fit are later removed from the further processing.
f) Model-based on Fuzzy Set Retrieval:
This model is based on the concept of theFuzzy set where the documents in the document set are mapped to a Fuzzy set which not only consists of the elements but also a number that indicates the strength of the membership. AND, OR and NOT operators are used to formulating Boolean queries that result in the strength of membership which is associated with every document that is related to the query. These values are used to compute the similarity score.
This research work revolves around the area of formulating a user Query. The following section 1.4 elaborates the process of Query Formulation in detail.
1.4. QUERY FORMULATION
Query handling is a vibrant area in the field of Information Retrieval. Experiments reveal that formulating a query plays a vital role in generating relevant results. Since most of the users of web environment are naïve, query formulation cannot be expected to be effective always.A user information need is put forward in the form of query. To make things worse, the Web queries formulated are very short, and studies reveal that they range from two to five words[5] normally. Though there are many ways to address the concept of thequery, one assumption is that a thought pattern generated by the user is being put forward as a query. There is, therefore, no standard defined way to explain how a query has to be written. But it is understood that the user is looking for some information.Failing to understand the need behind the query, results in documents fetched from the web which will not be of any use for the user.Hence different search engines engage in different ways by which they try to understand the user means.
1.5 QUERY REFORMULATION
Query Reformulation has been a vibrant field of research [6][7] with the continued growth of online information. The main aim of query reformulation is to find out new meaningful terms that can be added to the initial query. Many researchers use different techniques to reformulate queries. Query Reformulation is considered as an effective technique to improve the performance of the Information Retrieval systems. It adds more terms to the original query, which provides more information about the user need. With Query Reformulation, the user is guided to reformulate queries which enable more relevant results to be generated. The process can either be i) Automatic ii) Manual or iii) Interactive [8].
The new terms should provide contextual information for the initial query to improve the retrieval results. Query Reformulation techniques are further classified into two major classes: Global methods and Local methods. Global methods use individual query terms for expansion whereas Local methods use documents that are retrieved using unmodified query [9]. Though Query Reformulation is seen as an effective technique to improve the performance of the Information Retrieval systems; it may also cause overhead if not handled effectively.
Query Classification addresses this issue by helping to identify the queries, for which Reformulation may be beneficial. Query Classification techniques classify the queries into two categories based on user intention: Informational queries and Non-informational queries. Informational queries are further subjected to Query Reformulation, where relevant terms are added to the original query, to provide more information about the user need. The term similarity coefficients are further used to determine the relevant related terms.
1.5.1 NEED FOR QUERY REFORMULATION
There are many reasons why the commercial search applications fail to deliver the desired result expected by the end user. Few problems are listed below.
- The end user queries are processed by the indexes which normally works based on matching the exact query terms with the terms in documents [10].
- The user’s incapability [11] of framing the right query is overlooked by the search applications.
- Many times the size of the user information needs to be expressed as a query is so short [5] to explain what user wants.
- The users of the search applications are naïve hence the formulated user query is so vague and is not clear about the intended results.
- The query submitted consists of keywords which are related to different domains [12] and have multiple meanings.
- Many issues related to mismatch of terms arise, since the terms used by the indexes [10] and the query differs.
- Keyword queries do face issues related to vocabulary problem [13] that arises because of Polysemy and Synonymy.
The above problems lie with respect to the formulation of query. A way to reformulate the query will help to overcome the drawbacks associated with the search applications. One of the ways to move forward is the Query Reformulation.
1.5.2 COST OF QUERY REFORMULATION
Though the Query Reformulation approaches help to retrieve more accurate and better relevant results than the other traditional ones, it also has few overheads such as the following:
- Rapid response time for every search.
- Cost of computation involved with it.
- It may fail to understand the relationship of a single term with similar other terms and also their usage in different environments.
- Few query reformulation approaches leave the initial query, thus resulting in topic drift.
- Sometimes the results of queries may decrease the effectiveness of retrieval.
The following section (1.5.3) illustrates the different types of Query Reformulation approaches that have been proposed by the researchers.
1.5.3 TYPES OF QUERY REFORMULATION
The Query Reformulation approaches are classified based on different factors. One of the widely used metric for the classification is the user involvement in the reformulation process. Based on the involvement of the end user, the query reformulation approaches [8] are classified as:
Manual Query Reformulation:
In this approach, the end user takes care of the reformulation process and transforms the initial query to a query which is considered to be a more responsive one for retrieval.
Automatic Query Reformulation:
In this approach, the end user doesn’t have any role in the reformulation process. However the corpus for the relevant terms to be looked for is already set, and the retrieval system automatically finds the similar terms to be added and reformulates the query. Though this approach has benefits to its claim, it also suffers one of the limitations, as the reformulated query being totally different from the initial query, thus causing a problem called as query drift.
Interactive Query Reformulation :
This reformulation process follows a hybrid approach where both the system and the end user are involved. The system is responsible for returning the relevant terms for the initial keywords in the seed query; however, the end user selects the terms to be added to the seed query. Thereby the preference of the user in selecting the terms to be added gets priority in this interactive approach. This hybrid approach can also help to overcome the problem of query drift.
1.5.4 APPLICATIONS OF QUERY REFORMULATION
Query Reformulation has been a vibrant field of research in Information Retrieval, primarily because of its usage in different fields of search-based applications. Few of the most common areas where Query Reformulation is being used are as follows:
Multilingual Information Retrieval
Multilingual information retrieval deals with the retrieval of information that is available in different languages. It is also referred to as cross-language information retrieval. This allows the user to pose the query in one language and retrieve the results in another language. Suppose the query of the user is in Kannada or Tamil, the retrieved result set may have documents in not only in Tamil but can also in English. This area of Multilingual Information Retrieval has gained more momentum in recent years because of the popular forums like TREC that focuses on promoting research in this field.
There are three classic approaches that are being adopted in MLIR. I) Using Translators to translate the query 2) Approaches based on Corpus and 3) Usage of Dictionaries that are readable by the machine. But the main issue that most of the approaches suffer is the problems related to the translation of terms that are inflected, uncertainty issues between the primary source and the primary target language and certain non translatable words depending upon the language that is used. One of the ways to overcome this problem is to reformulate the query. Query reformulation can be applied either during the translation process or before or after the translation process. There have been few attempts by the researchers to use query reformulation in the MLIR such as [14] where the previous history of the user is used for the personalized retrieval of documents. The evaluation also suggests that the approaches that are adopting the personalized retrieval outperform the approaches that use the non personalized way of retrieval. Another work in this area which was published very recently [15] reveals an approach using the translator to transform a query using the embedding of words from Hindi to English.
Question Answering
It is yet another field of Information Retrieval that is build of the conceptual understanding of answering questions with direct answers. The focus of this approach has been to keep the answer very short and precise and not retrieving the documents and listing it to the end user. For example, the system expects and accepts questions like “Where are the 2020 Olympic games going to be?” and not an initial query with few keywords in it. However, this field also suffers a serious problem that occurs because of mismatch of terms in the questions as well as in the answers.
Today most of the commercial search applications utilize this capability of Question answering for specific types of queries which start with “How? What? When? Why?” Together with the answer being displayed, the list of documents is also retrieved and displayed in the answer interface. Many works have been undertaken to overcome the mismatch issues. Few of them depend on the FAQ information for the reformulation of query which is considered as the most generic way, whereas very recently the researchers have explored the use of terms from the social networking [16, 17, 18] towards the query reformulation.
Multimedia Information Retrieval
It is yet another vibrant field of Information Retrieval that deals with the semantic information available with the multimedia such as audio, video and image. Though most of these systems depend on the textual information such as the metadata, title, caption and the text available in the anchor, these techniques fail when the above information is not available. That’s where reformulating the query plays a vital role. The works that have been done in the area of audio retrieval report an increase in the retrieval of relevant results. Recent work on audio retrieval [19] elaborates on a query reformulation method which is based on the contents picked from the social network, and the authors use a reformulation on different segments of speech.
Few works that have been done in the area of video retrieval also illustrates the usage of query reformulation. The query reformulation is being done by expanding the textual query based on the statistical and the lexical approaches. Recent works in this field [20] uses a Meta synopsis for the indexing of the video files. Important information that is needed for the retrieval of the relevant videos is present in the Meta synopsis.
Even in the field of image retrieval, the general approach is to retrieve images based on the description of the images such as colour, texture and the other visual aspects. A recent study conducted [21] lists out the various contributions are done in this area. Few approaches suggest the usage of the query log and few others tend to reformulate the query based on the features of the original query.
Collaborative filtering and content-basedfiltering
Filtering of information is yet another prime area in the field of Information Retrieval which focuses on removing the unnecessary data from the result set. Though the discussion is on to figure out the differences between Information Retrieval and Information Filtering, Information Filtering (IF) can be considered as another type of IR which also focuses on retrieving relevant information. Few works have also been done to illustrate the advantage of Query Reformulation in it. Recent work in this area proceeds as follows. The interactions of the web users are being watched, and their behaviour is used to construct a pattern [22] which is later used for reformulation. Another work in this area is based on the clustering method [23] which was used to reformulation. Using the data sources in World Wide Web is gathering momentum in the field of Query Reformulation as well; one of the very recent works uses DBpedia [24] for reformulating the initial query.
Personalization
As we witness the social revolution on a large scale, sharing the information, commenting on different online contents, arating of the services and so on, and personalization has taken an important place in the field of information retrieval as well. Recording and analyzing the user’s preferences helps to retrieve documents which could satisfy the user’s interest. Various Query Reformulation approaches have also been suggested in this regard. Similarity measures and the proximity measures also play an important role in Personalization. Query Reformulation with respect to personalization is elaborated in work [25]. Another work on personalized query reformulation was proposed [26]. The reformulation is based on social annotation, and a tagging system was used for indexing. However, a very recent work that was done in the area of personalization uses the embedding of words for the query reformulation [27]. The analysis of this work was done on a CLEF Social Book search 2016 collection.
Other Areas of applications
Query Reformulation has also found its impact in many more areas such as searching for social media applications such as Twitter[28], searching the source code as explained in [29], used in the E-commerce related application as explained in [30], detecting the ambiguity of data by using it in plagiarism detection[31], helping the query based application in the field of Biomedical[32], searching application used for enterprises[33] , Internet of Things based applications [34,35], searching for events [36,37] and grouping of textual data [38].
Other than Query Reformulation, an Automatic Query Classifier has been proposed in this work. The following section (1.6) explores the background of the Query Classification process and its importance to understand user information need.
1.6 QUERY CLASSIFICATION
To better understand and process the information need posed by the end user, the queries are classified. There are different metrics used to classify them. Based on the intention behind the queries, they are classified into the following: i) Informational ii) Navigational and iii) Transactional[39,40]. The queries that are aimed at finding the meaning of the terms are called as Informational queries. The queries that are using the search applications to find a particular website or a homepage is normally termed as Navigational queries and the queries whose intention are used to determine the service is termed as Transactional queries. In this proposed work the queries are classified based on the end user beneficial to use reformulation. They are classified into Informational queries and Non Informational queries. The set of queries that benefit from query reformulation are termed as Informational whereas the set of queries that do not benefit from query reformulation are termed as Non-Informational.
Another part of this proposed research work deals with the similarity computation for the terms extracted from the lexical resources. The following section explains the importanct of similarity measures in the field of Information Retrieval.
1.7 SIMILARITY MEASURE COMPUTATION
Another widely used concept in the field of Information Retrieval is Similarity. It is a measure that denotes the relationship between the terms in the seed query and the terms derived from the Lexical resources. The similarity is normally used to measure the distance between any two objects [41], where the object can either be a term (word), set of terms (sentences) or documents. The semantic similarity is a measure that is used to find the similarity between any two terms that are similar. There are multiple ways to measure the similarity [42]. In this proposed work, a hybrid similarity score is computed to assign weight to each term that can be added to the seed query. The hybrid similarity score computation is based on the widely adopted similarity computation measures such as Jaccard similarity coefficient [43], Dice similarity coefficient [44] and the Cosine similarity coefficient [45].
1.8 LIMITATIONS IN THE EXISTING APPROACH
To overcome the issues faced by the search based applications, different Query Reformulation techniques have been proposed by different researchers. However there are certain grey areas that has been not looked into. They are described below :
- Query classification[39] has been studied separately so far, No work has been done to show the advantage and impact of Query classification in the reformulation process.
- Reformulation approaches using Thesaurus and Domain Independent ontology such as WordNet[46] are available separately, however a hybrid attempt to use both the capabilities have not been attempted.
- Many reformulation approaches[47] suffer from Topic drift, the ability to use boolean operators to overcome this problem has not been studied extensively.
- Semantic similarity is computed using the Query reformulation methodologies incoporating lexical resources, however the usage of the term similarity in that context has not been studied.
The above issues has been addressed in this proposed research work. An automatic web classifier acts as a bridge between the Query Classification and the Query Reformulation. Topic drift have been covercome using the boolean operators and merging the original query with the expansion terms generated for the reformulated query. Term similarity is applied using a hybrid approach incorporating Jaccard, Dice and Cosine similarity measure.
1.9 MOTIVATIONS BEHIND THE PROPOSED APPROACH
The focus of this work revolves around Query Reformulation, and the motivation behind the present work are as follows. The quantity of information available in the repositories such as World Wide Web are increasing in a way beyond measure. Apart from this repository, collections like digital libraries are fast growing. Since every content is available online does not mean it is going to be useful. The present search applications has grown tremendously with many capabilities in the past decade.
However, this proposed research work provides few more capabilities to the current searching scenario by:
- Improving the retrieval effectiveness of search based applications by providing more relevant results for the user queries.
- Adding semantic capabilities to the searching process by providing more semantic relevant results that increase the precision of the Informtion Retrieval process .
- Adding more relevant terms to the query, but not comporimising on the original query posed by the user, thus maintaining search fairness.
- Optimal usage of the boolean operators, resulting in the formulation of the boolean queries, which helps to overcome Query Drift
- Personalized query reformulation by storing the earlier data in a web log, thus analyzing the user intention behind the web search
One of the areas by which they process the user information need is by adding new related terms to the query hence making the user query much more responsive to the information retrieval system. In this work, measures have been proposed to understand the query in its actual form, and transforming it into another responsive format, so that more relevant results are generated.
1.10 AIM AND OBJECTIVES
The main objective of this research work is to design an effective Information Retrieval system based on Query Classification and Reformulation using lexical resources. An Automatic web query classifier is proposed as part of this Information Retrieval system, and a new Query Reformulation algorithm is designed for generating relevant, reliable candidate terms and its effectiveness in the real web environment is evaluated. The candidate terms are assigned weight by computing term similarity using different similarity measures.
1.11 CONTRIBUTION OF THIS THESIS
The proposed methodology involves an automatic Query Classification algorithm which is used to classify the query into informational queries and non informational queries. The informational queries are further reformulated by adding reliable and relevant candidate terms from Lexical sources like Ontology and Thesaurus. In the process of improving the query, there is also a chance of adding unnecessary words that may cause the query to lose its original meaning. Hence in this work, the problem is overcome by Query Classification where the user logs are used to do the classification. The query classifier is used to classify the user queries based on user intention into two categories i) Informational queries (which may benefit from Query expansion) and ii) Non-informational queries (Used for Navigational and Transactional purposes).
The main contribution of this work is the process of finding out the candidate terms. The candidate terms are generated from two sources, a Domain independent ontology word net and Thesaurus. All the possible candidate terms will be listed from both the resources. Different similarity measures like Cosine, Dice and Jaccard similarity are used to calculate the similarity measure between the first candidate term and the other candidate terms that are generated. The similarity measures range from zero to one. The proposed similarity measure lists out the collection of terms that were assigned the higher weight by the above methods.
1.12 OUTLINE OF THE THESIS
Chapter two comprises of the previous research initiatives that are done in the area on Information Retrieval, with specific reference to the area of Query Handling. It helps in establishing the background for the rest of the chapters. The first part of the chapter two lists out the various works that were done in the area of Query Classification. The study of queries and the need to understand the queries has always been done to understand the user’s perspective behind placing the information need as a query. Various attempts have been made in the past to understand the queries by studying them. A brief survey of the various types of Query classification schemes that have been proposed over the period of time and the details about the intention behind those classification mechanisms that have been proposed have been elaborated.
The second part of the chapter two lists out the various works that were done in the area of Query Reformulation. Query Reformulation has been an important area of study since the advent of the World Wide Web. The study of web queries has led to a lot of improvement in generating more relevant search results. The detailed investigation related to the different Query Reformulation approaches that have been proposed and the problems they overcome has been done. This part discusses the research findings in the area of Query Reformulation.
The third part of chapter two discusses the Text Similarity approaches that have been used to measure the Similarity between any two given words or strings. The research findings related to term similarities such as lexical similarity and semantic similarity are being elaborated. The different measures that are used to compute asimilarity score between any two words are being explained in this part.
The purpose of this study was to come up with an effective information retrieval system based on Query Classification and Query Reformulation. Chapter three discusses the motivation behind this model and the features of the proposed approach in the first two parts. The different sub-processes before the Query Reformulation have been explained in detail. An Automatic Query Classifier that is proposed as part of this research study has been presented in the third part of the third chapter. The Automatic Query classifier classifies the web queries into two types such as i) Informational queries and ii) Non-Informational Queries . The intent behind this classification is to determine for which type of queries the reformulation will be beneficial, and for which queries it may not be effective.
The fourth part of the third chapter describes the Query Reformulation technique that is being proposed. The process of reformulation is aimed at identifying the right words to be added to the actual query, which will increase the precision of the search. Though lexical sources have been one of the repositories of these words, identifying them and adding them to the actual query is the process Query Reformulation. We use the lexical resources such as Thesaurus, Domain independent ontology like wordnet to generate those words. Selecting the right candidate terms from the available terms can be attributed to the semantic scores that are generated. Few of the similarity measures are being used in the hybrid method that is being proposed. Dice coefficient, Cosine coefficient and Jaccard coefficient are part of the hybrid methodology that is formulated. The fourth part of the third chapter explains the similarity score computation. These scores form the basis of adding the candidate terms to the actual seed query.Finally, the overall performance analysis and discussion are given.
The different components of the Effective information retrieval system are being explained in separate chapters elaborately. Automatic Query Classifier in chapter 4, Query Reformulation in chapter 5 and Similarity measure computation in chapter 6. All the proposed algorithms and their analysis have been explained.
The proposed algorithms were analyzed in the Real-time environments, and are discussed in the seventh Chapter which focuses on Results and Discussions.The Experimental environment, the performance metrics, the evaluation was done using the Log based Dataset and the Evaluation is done using the TREC Queries, and the experimental results are explained in detail.
The eighth chapter discusses the brief summary of the Research work that has been done. The research has helped to design a new Query Classification algorithm which classifies the web queries into informational and non informational queries whereas the Query Reformulation algorithm designed is used for generating relevant, reliable candidate terms, and its effectiveness has been evaluated in the real web environment. This algorithm also assigns weight to each candidate term by computing term similarity considering the similarity scores generated by different similarity measures. The results in real time web environment have clearly shown that the proposed algorithm based on ontology and Thesaurus using term similarity coefficients is very effective and efficient and increases the relevance of search results.
The future scope of research in this area is also presented in the final part of the eighth chapter, which suggests new directions in this research work to be continued further on.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: