Literature Review on Data Mining
Info: 9906 words (40 pages) Dissertation
Published: 23rd Feb 2022
Contents
Click to expand Contents
1. Introduction
2. Data mining techniques applied in diverse industry
2.1 Machine learning
2.1.1 Classification
2.1.2 Prediction
2.1.3 Association
2.1.4 Others
2.2 Clustering analysis
3 Sentiment analysis
3.1 Semantic orientation approach
3.2 Machine learning approach
3.3 Comparison and Combination of both methods
4 Textual analysis
5 Future research direction
6 Conclusion
Reference
1. Introduction
Big data is emerging as a quite popular theme among practitioners and scholars. For examples, many companies use digital technologies to track social media on a real-time basis, thereby creating longitudinal structures of millions of posts, tweets, or reviews George et al. (2014). Contemporaneously, a large number of research papers are dedicated on the revolutionary of big data in different industry and employ 3Vs to describe big data, the extreme volume of data, the wide variety of data types and the velocity at which the data must be processed(McAfee and Brynjolfsson, 2012). Inevitably, people from very walks of life nowadays are living in the era of big data.
In 2014, Bank of America appointed a new advanced position, the Chief Analytics Officer(CAO), to Douglas Hague who is the former senior vice president of vendor analytics(Ferguson, 2014). He strongly expressed a recognition of the importance of analytics in the use of big data, rather than just reporting on data(Ferguson, 2014). Precisely, companies need to learn taking analytics beyond the data and information which could come into the real insights that impact decision making. Sanders (2016 p.28) exactly gave the difference between big data and analytics,
“Big data without analytics is just a massive amount of data. Analytics without big data are simply mathematical and statistical tools and applications”.
Hence, oriented by big data, we should put more efforts on big data analytics (BDA), which could be defined as
“ a new generation of technologies and architectures, designed to economically extract value from very large volumes of a wide variety of data, by enabling high velocity capture, discovery and /or analysis.”
(Carter, 2011).
Along with the technology of big data analytics being mature gradually, the concept of business intelligence arose through the whole economic globe. Enterprises tend to explore all kinds of deeply hidden features from mass information networks, with prevalent and intelligent analytics skills such as data mining, process mining, web mining or text mining. Business corporations aims to make predictive decision or take action towards a targeted goal with help of these mined valuable information. Social media is one good example of this. Marketing seems the most direct beneficial field of social media analysis. There have been a number of literature involving the role of social media in marketing and the relationship between market variables and online users generated behaviors (Chen et al., 2011). Likewise, Senadheera et al. (2017) affirmed that social media could act as an information system which encourage enterprises to adopt more business applications via social media platforms, for example interact with lower cost with their customer for feedback.
In the accounting and finance field, one emerging research direction is to explore the content, tone or sentiment of social media information. The focuses on the link between these new type financial information and financial markets are becoming the prevalent trends. For example, research work from Yu et al. (2013) suggested that the overall social media had a strong relationship with firm stock performance with stock returns and risks as indicators.
More innovatively, Purda and Skillicorn (2015) employed the latest data mining techniques to detect the fraudulent activity of Management Discussion and Analysis (MD&A) sections of annual report. Different with conventional financial media, such as news or press release, user generated content from social media is unstructured and real-time updated with mass volume. Hence a new kind of methodology combined with big data analytics and statistics need to be concerned in order to help researchers get developing insights about the relationship between social media and financial markets.
According to Miller and Skinner (2015), there is still relatively little research work on how firms use social media for disseminating or disclosing financial information. And little is known about how to use the latest big data analytics to explore the hidden financial information from social media. Thus our research attempt to employ the data mining techniques well-developed in other industry like computer science or marketing to get more insights on financial disclosure on social media.
This literature review will focus on data mining techniques and aim to obtain more understanding on the features, benefits, and context of data mining techniques to be applied on, in order to employ the appropriate and powerful big data analytics for accounting research, especially for financial disclosure, under the circumstance of corporation financial disclosure on social media platform. The paper will be organized as the following structures.
In section 2, details about different data mining techniques will be discussed. The literature which applied specific techniques from diverse industries will be listed and compared.
In section 3&4, more specific data mining application domain will be reviewed, for example, data mining could be used to improve sentiment analysis and text analysis which is our key focus on naturally language analytics, since this is most related to financial disclosure research.
In section 5 we discuss future research direction and in section 6 we conclude the whole paper.
2. Data mining techniques applied in diverse industry
Continuous innovation of computational technology created diverse categories of data mining techniques. This literature review will focus on several popular and widely used data mining techniques in academic papers. To help categorize the literature, Table 1 and Table 2 tabulate most of the papers that I will discuss in this section based on the employed data mining techniques and their explored industry topic. Two main data mining categories will be reviewed as follow as machine learning and clustering analysis.
2.1 Machine learning
Machine learning is probably the better known and most familiar technique in the field of data mining. It originated from computer gaming and artificial intelligence that give the computer the ability to learn without being explicitly programmed(Samuel, 2000). Machine learning tasks are generally classified into two situations, supervised learning and unsupervised learning. Supervised learning involved training computer with presented examples. The goal is to learn the rules from the training set and then apply them into new test task. Unsupervised learning techniques do not require labeled data leaving its own to explore patterns or structures. A very good example to illustrate this is AlphaGo Zero which is an artificial-intelligence chess program from Google DeepMind team. It mastered the chess game without any human data or guidance, which is strongly beating the previous version which did require a large training database to learn(Singh et al., 2017).
Machine learning system could realize different function, such as classification, prediction and explore association. Different data mining techniques or algorithms (i.e support vector machine, decision tree) could be employed in working systems to achieve the expected function with evaluation focusing on accuracy rate(Bandaru et al., 2017).Table 1 lists the sample papers on how to use different tools to build data mining system.
2.1.1 Classification
Classification models could predict categorical class labels. For example, Abdelhamid et al. (2014) dealt with website phishing as a typical classification problem in which the goal is to assign a test data into phishy, legitimate, or suspicious, etc. The working of classification includes two steps, building classifier using classification algorithms based on learning from the training set, then using classifier for classification. This is typically considered as supervised classification methods and Traore et al. (2017) used this method to process a set of satellite images, classifying new areas into epidemic risk or not an epidemic risk in order to find the link between the geographical area of the Niger River and the spread of the cholera epidemic.
Kim and Lee (2014) modelled SQLIA detection as a data-mining based binary classification problem utilizing the support vector machine which is beneficial in detecting unknown attacks with high accuracy. Support vector machines(SVM) emerging in the nineties have become one of the most widespread machine learning techniques(Moro et al., 2016).It transforms the input into a high m-dimensional vector space then utilizes the algorithm to build the classifier finding the best linear separating hyper plane(Moro et al., 2016). Latkowski and Osowski (2015) combined SVM with other algorithms in an ensemble to select the most significant genes in the expression microarray of autism.
| Diverse industry | Machine Learning | |
| Supervised learning | Unsupervised learning | |
| Support Vector Machines
Neural Networks Decision Trees |
Association Rule Mining | |
| Brand building | Moro et al (2016), | |
| Network security | Kim and Lee (2014)
Abdelhamid et al (2014) |
|
| Fraud | Carneiro et al (2017) | |
| Bioengineering | Latkowski and Osowski (2015) | |
| Medical Science | Marciano-Cedeno (2013),
Garcia-Rudolph and Gilbert (2014), Zolbanin et al (2015) |
Yang and Chen (2015) |
| Shale reservoirs | Tahmasebi,et al 2017 | |
| Geography | Traore et al (2017) | Lee et al (2014) |
| Computer&software | Chemchen and Drias (2015)
Ariyajunya et al (2017) |
|
| Financial stock | Liao and Chou (2013) | |
| Education | ||
Table1 – Sample papers on machine learning
2.1.2 Prediction
Similar with classification task, Moro et al. (2016) presented an approach using SVM for predicting the impact of publishing individual posts on a social media network of company’s page. The predictive knowledge could support manager’s decisions on whether to publish each post. By the latest, Carneiroa et al. (2017) addressed the problem of fraud detection in order to build a risk scoring system which will predict a Fraud suspicion score for each order. SVM, logistic regression and random forests are employed and compared in this experiment. The latter two data mining techniques are not discussed in this paper due to its non-universality.
Prediction is fundamentally based on the relationship between a thing that you can know and a thing you need to predict. A classification problem could be seen as a predictor of class as well. Garcia-Rudolph and Gibert (2014) used decision tree algorithm which is a classification algorithm to build data-driven models for NeuroRehabilitation Ranger which could support the therapist for assigning the most appropriate cognitive rehabilitation plan to each patient. In the same field, Zolbanin et al. (2015) applied 4 machine learning techniques including decision tree, logistic regression, random forest and neural network to build predictive models in order to help practitioners make better diagnostic and treatment decision from information about comorbid conditions of patients.
Neural network technique is another supervised machine learning technique which could learn functions between the inputs and the outcome form the training sets. It uses the data to modify the weighted connections between all of its functions until it is able to predict the test data accurately. Marcano-Cedeño et al. (2013) used 3 data mining techniques including decision tree, multilayer perceptron and general regression neural network to construct the prediction models which could predict the outcomes of cognitive rehabilitation in patients with acquired brain injury. Moreover Tahmasebi et al. (2017)used stepwise algorithm and neural network algorithm to propose models which could effectively estimate the probability of targeting the sweet spots in shale reservoirs.
2.1.3 Association
The association rules mining is an important issue in the area of data mining. It is a technique to uncover how items or features are associated to each other. Furthermore, it is mainly used to determine the synchronous relationships and use these as a reference during decision-making (Liao and Chou, 2013).In the field of medical treatment, Yang and Chen (2015) analyzed the correlation between the clinical information and pathology reports based on a data association mining method. Many rules have been generated and evaluated to support the diagnosis of lung cancer pathologic staging (Yang and Chen, 2015).
Associations rules mining is frequently used with the technique of clustering analysis which will be discussed in 2.2, in order to classify the relationship into more detailed cluster groups. Liao and Chou (2013) investigated the co-movement in the Taiwan and Hong Kong stock markets and also explored possible clusters of stock category indexes between the two stock markets using association rules and clustering analysis. Contemporaneously, Lee et al. (2014) proposed a framework to mining geo-tagged images from Flickr with a combination of clustering and association rules mining, in order to detect points-of-interest and their association.
2.1.4 Others
Data mining techniques play an important role in the world of business intelligence. Summarized only in the above three function is far not enough and limited. For example, Nedic et al. (2014) suggested a novel approach based on four optimization techniques for modeling traffic noise which could support control of noise sound level in urban areas. This approach utilizes advanced optimization algorithms which represent another area of data mining. Moreover, Campagni et al. (2015) presented two data mining techniques of clustering and sequential patterns in order to propose strategies for improving performance of students and the scheduling of exams. This is one of the first attempt to use the sequential pattern technique in the area of education and sequential patterns are investigated in the whole student database.
Additionally, there is always no specific research topics in which some specific data mining techniques should fit. The performance of data mining system mostly depends on the goal of design and the way how the systems are built on. Under a lot of situations, some data mining techniques are combined to use or tested together for performance comparisons. For instance, Pachidi et al. (2014) suggested how 3 types of data mining techniques could be integrated to analyze software operation data, including classification, clustering and sequential pattern mining. Furthermore Chemchem and Drias (2015) focused on the two fields of clustering and the supervised classification in order to present a new paradigm of induction rules mining. In the same field, Ariyajunya et al. (2017) employed data mining methods including stepwise regression, classification and multiple testing procedure to propose an approach for handling multicollinearity.
In this paper, we mainly focus more on functional and practical aspects of data mining techniques rather than technical and algorithmic aspects of it (Lee et al., 2014). Likewise, the performance or evaluation of diverse data mining system is not reviewed. However, the comparisons on the feature and the using context of diverse data mining techniques are still future research direction which needs more concerns and efforts.
2.2 Clustering analysis
Many different areas have used clustering analysis such as textual analysis, image processing, statistical analysis, patterns investigation (Moreno Sáez et al., 2013). The clustering algorithms could group the information into a number of clusters that show the characteristics of the data as well as the relationships among the groups (Al-Hassan et al., 2013). In a word, clustering is segmenting a heterogeneous population into a number of more homogeneous subgroups. Table 2 lists the sample papers on clustering analysis.
The two papers at the bottom specifically focused on the application of clustering algorithms. Moreno Sáez et al. (2013) applied cluster analysis to group the number of measured solar spectra from more the 250,000 into only 5 different clusters. This improved advanced analytics on performance ratio value estimated for photovoltaic. More interestingly, Al-Hassan et al. (2013)applied clustering on textual data mining of corporation legal statements, mainly on documents of privacy policy and terms of use. They aimed to detect if the data mining system will cluster similar corporations on legal statements into the same industrial sectors based on North American Industry classification System code (NAICS). Unfortunately, the results are only marginally successful which leads to more concerns on the evaluation on data mining techniques on textual analysis.
| clustering | |
| Divers industry | |
| Brand building | |
| Network security | |
| Fraud | |
| Bioengineering | |
| Medical Science | |
| Shale reservoirs | |
| Geography | Lee et al (2014) |
| Computer&software | Pachidi et al (2014)
Chemchen and Drias (2015) |
| Financial stock | Liao and Chou (2013) |
| education | Campaigning et al (2015) |
| Texual analysis | Hassan et al (2013) |
| Solar photovoltaic | Saez,et al (2013) |
Table 2 Sample papers on clustering analysis
As we also reviewed in last section, clustering analysis has been frequently combined with other data mining techniques. Both of papers from Lee et al. (2014)and Liao and Chou (2013) applied the association rules mining to find the relationship firstly, then grouped these relationships into different interested clusters. While Campagni et al. (2015) utilized clustering to group student database into two classes firstly, then applied sequential patterns mining to find patterns separately in second step. As a data mining function, cluster analysis serves as a tool to gain insight into the distribution of data to observe characteristics of each cluster, with a good advantage of fast processing time.
3. Sentiment analysis
Sentiment analysis techniques have been well-studied in different domain, for example stock prediction in Accounting/Finance, online product sales in marketing, and corporate reputation in corporate governance, etc (Schumaker et al., 2016). As Yu and Wang (2015)stated, sentiment analysis is a task of judging the opinion(positive or negative) which is transforming unstructured qualitative data into quantitative data that can be used for decision making, for example the reviews of customers about products and services(document, sentence, paragraph, etc.)(Choi and Lee, 2017).
Existing sentiment analysis approaches are either based on linguistic resources or on machine learning (Yu and Wang, 2015). Choi and Lee (2017) categorized the sentiment analysis into machine learning approach and semantic orientation approach. Table 3 lists the sample papers reviewed in this literature review, classified on machine learning approach(MLA), semantic orientation approach(SOA) and combination of both methods. Fersini et al. (2014)categorized sentiment analysis into unsupervised, semi-supervised and supervised. Unsupervised methods are typically lexicon-based approach described by Choi and Lee (2017). Semi-supervised methods are based on an expanded sentiment words set through synonyms and antonyms form dictionary(Fersini et al., 2014).Likewise, Giatsoglou et al. (2017)categorized sentiment analysis into the supervised machine learning approach with classification algorithms and unsupervised methods which relied on natural language processes, existing lexicons and also document’s statistical properties such as word co-occurrence.
| Diverse industry/topic | Machine learning | Semantic orientation | combination |
| Sport | Yu and Wang (2015) | ||
| Educaiton | Ortigosa et al (2014) | ||
| E-commerce | Choi and Lee (2015) | ||
| Financial market | Yu et al (2013)
Nguyen et al (2015) |
Daniel et al (2017)
Pröllochs et al (2016) |
|
| Methodology | Fersini et al (2014)
Lau et al (2014) Yang and Chao (2015) Meier et al (2016) Yousefpour et al (2017) Chan and Chong (2017) Chen et al (2017) Tellez et al (2017) |
Qi et al (2015)
Deng et al (2017) |
Giatsoglou et al (2017) |
| Behavior research | Zavattaro et al (2017) | Stieglitz and Xuan (2014) | |
| Public policy | Chung and Zeng (2016) |
Table 3 sample papers on sentiment analysis
3.1 Semantic orientation approach
Semantic orientation approach(SOA) is more common approach which uses predefined sentiment lexicons such as Wordnet, SentiWordNet providing lists of sentiment words, or uses external data sources such as corpus providing massive text data sentiment expression and dictionary showing the polarity of words(Choi and Lee, 2017). By counting the words from tweets or messages that match categories in lexicon, this approach recognizes words with positive polarity, negative polarity or no polarity (neutral). Yang and Chao (2015)stated that statistical analysis and pattern matching could be applied to match words from text documents with the sentiment lexicon. Scores are given to matched words then the document-level sentiment scores are calculated from both positive and negative score (Deng et al., 2017).
In the field of financial market, Daniel et al. (2017)utilized 4 text analysis tool based on lexicons to assess sentiment of tweets from financial community which gave a basis for event popularity detection on financial market. Prollochs et al. (2016)examined the negation scope of financial news using net-optimism which measured the content according to the frequencies of words from the pre-defined dictionaries. In the domain of social media research, Stieglitz and Dang-Xuan (2013)examined whether sentiment from social media was associated with people’s information sharing behavior using a lexicon to extract sentiment level. Chung and Zeng (2016)described a system of imood which addressed the sentiment and network analysis based on lexicon orientation approach in order to build a framework for social-media-based public policy informatics. More interestingly, a recent paper by Deng et al. (2017)proposed a lexicon expansion method to adapt existing sentiment lexicons for domain-specific sentiment classification.
SOA is quite simple and intuitive. It is applicable with external sources and is free from domain problem since the lexicon stores general words for sentiment expression in all domains. However it will come cross the problem of word multiple meaning, different language, and long documents. The accuracy with the solving these problems is still uncertain concerns(Choi and Lee, 2017).Moreover, this approach involves a number of linguistic techniques which requires intensive labour and are not always effective and robust in specific situation.
3.2 Machine learning approach
Machine learning approach (MLA) on sentiment analysis is typically implementing a supervised classification task as discussed in section 2. It classifies the polarity of a document based on the features extracted from training set. Different classifier or classification algorithms could be chosen to realize the function, such as Decision trees, support vectors machines, or Naïve Bayes. For example, both Yu et al. (2013) and Nguyen et al. (2015)applied machine-learning approach separately with Naïve Bayes algorithm and support vector machine algorithm aiming to investigate the impact of sentiment from social media on their company stock market.
Several machine learning classifiers are also applied together in order to obtain better performance or deep technical comparison. For example Fersini et al. (2014) addressed an ensemble of different classifiers including Naïve Bayes, support vector machines and other algorithms in order to get more accurate classification under the situation of no consensus regarding which classifier should be applied for a specific domain. Chan and Chong (2017) proposed a sentiment analysis engine which extends sentiment analysis on both the word token level and the phrase level. Two machine-learning classifiers decision tree and support vector machine were built to realize the classification task. Moreover Pang and Lee (2002)investigated the pros and cons of different classifier chosen for MLA. Support vector machines can be robust to noise and good for long document while will takes longer time than decision tree and Naïve Bayes which are relatively fast but have weakness in high dimensional processing.
Additionally, machine learning approach could be also effectively utilized in other language context. By contrast, semantic orientation approach is rarely applied on other language than English, mainly due to the seldom lexicons based on other language. For instance, Yang and Chao (2015) utilized selected morpheme-level features to build a SVM classier which concentrated on the context of Chinese. Tellez et al. (2017)identified that text transformations, tokenizers and token-weighting schemes could make the most impact on the performance of support vector machine classifier, based on Spanish context.
Some researchers are dedicated to improve new superior sentiment analysis technology beyond the existing machine learning approach. For example, Lau et al. (2014)proposed a new system which could predict the polarities of aspect-level sentiments without requiring training examples. Furthermore Meire et al. (2016)first time indicated that both leading information (i.e previous post) and lagging information (i.e likes) increased the classifier’s performance (support vector machine and random forest) as well. As for the latest research, Yousefpour et al. (2017) proposed two methods for feature subset selection, then used four machine-learning classifier algorithms to test those selected subset feature in order to reduce dependency of feature selection techniques and obtain high-quality minial feature subset. Comtemporaneously, Chen et al. (2017)proposed a Novel approach which first time classifies sentences into different types for separate sentiment analysis. Neural network based algorithm are applied to improve performance of sentence-level sentiment analysis.
3.3 Comparison and Combination of both methods
Generally, MLA shows better performance than SOA with superior accuracy if enough training set is ready. However it is usually not easy to have reliable training sets for classification for both researcher and practitioners (Choi and Lee, 2017). And if the training data comes from different domain with test data, the accuracy will be decreasing compared with the situation of training data and test data coming from the same domain(Denecke 2009).
Deng et al. (2017)stated that MLA required a large training dataset for better performance. However this might be a big obstacle for social media content based datasets which is short and highly heterogeneous. Choi and Lee (2017)evaluated 4 different sentiment classification techniques (Decision tree, Support vector machine and Naïve Bayes from machine learning, sentiment orientation approaches) to social media database in e-commerce to learn if database features including data size, length and subjectivity affect the performance of these techniques. The results imply that SVM and Naïve Bayes can be good choice in general with higher accuracy than SOA if training sets are available. If the length of test document is relative short, SOA could show good performance as well.
Ortigosa et al. (2014)compared lexicon-based approach with machine-learning methods and highlighted the great advantage of lexicon-based approach is no need to have a labeled training set although it got a lower accuracy. The authors had to use the lexicon-based approach firstly to build a labeled training set, then a combination of 2 methods were applied to analyze students’ facebook in the case of e-learning in order to detect significant emotional changes. Likewise Giatsoglou et al. (2017)proposed a hybrid approach for the sentiment analysis. Several documents’ vector representations including lexicon-based are used as inputs for the machine-learning system. And support vector machines classifier got the best results on efficiency and processing time.
From the above review, machine learning is still one emerging analytics tool on sentiment analysis compared with conventional lexicon-based methods. Inter-disciplinary nature required researcher to employ skills from computer science, statistic and natural language process which might slow down the developing steps. However machine learning do outperform the other lexicon-based methods on accuracy rate which could bring more deep and accurate insight.
4. Textual analysis
Text mining seems also an emerging research area which aims to explore more valuable information from huge volumes of text documents. Since user-generated content from social networks attracts a large number of attention from all kinds of fields, text mining combined with natural language process, machine learning algorithms, statistics became more prevalent to discover hidden features from unstructured text.
Nassirtoussi et al. (2014) systematically review related work on text mining aiming to provide a theoretical and technical guide on this inter-disciplinary methodology. The major textual input seems financial website such as the wall-street journal, Bloomberg and Yahoo! Finance, etc. Social media text content is newly developing and still got fewer researcher’s concerns. Corporate conventional disclosure like annual reports, or press release is the third source of textual input. According to Nassirtoussi et al. (2014), almost all learning machine algorithms had been used to realize the classification function, such as naive Bayesian, support vector machine and decision trees, etc. And Naïve Bayesian classification method is considered as the old one and the most wildly employed algorithms especially in accounting and financial literature (Sprenger et al., 2014).
Loughran and McDonald (2016)investigated the literature in accounting and finance which adopted textual analysis. One of the sub-fields on which the authors were concentrated is the employing of naïve bayes methods. According to Loughran and McDonald (2016), naïve bayes methods were firsly used in finance by (Antweiler and Frank, 2004) who examined the impact of stock message postings on Yahoo! Finance on stock returns. A few years later, Li (2010) used the same method to examine the association of tone from MD&A section of the 10-K and earnings. More recently, naïve Bayesian methods were used to determine classification of 10-K filing (Jegadeesh and Wu, 2013) (Purda and Skillicorn, 2015)and gauge the sentiment in analysist reports. Furthermore, Bartov et al. (2015) suggested that the opinion in tweets could predict quarterly earnings based on 4 kinds of measures on information from twitter. One of them is employing enhanced naïve bayes classifier which was developed (Narayanan et al., 2013).
Sprenger et al. (2014)brought the learning machine classifier into the field of event study. The authors suggested that the using of microblogging messages from social media could accurately identify the timing of events. Furthermore, naïve Bayesian methods were employed to classify news events from twitter into comprehensive kinds of company-specific categories (i.e corporate governance, financial issues, operations, etc). The authors argued the insufficiency of news volume as an indicator of information and suggested that event studies need to have more concern specially with only one single event type rather than the whole volume (Sprenger et al., 2014).
Li (2010) firstly used the machine learning method to analyze financial disclosure. Naïve bayes classifier was employed to examine the association of tone from MD&A section of the 10-K and future performance. More importantly, Li (2010) empirically compared dictionary-based approach and naïve bayes approach on the same training data and suggested that dictionary-based approach had a low power in sentence-level analysis. This might give some implication on whether to choose diction-based approach or learning machine methods to analyze corporate disclosure on social media which are mainly based on sentences level. Follow Li (2010)step, Purda and Skillicorn (2015)chose support vector machine as classifying method to classify MD&A sections into truthful or fraudulent in order to improve fraud detection through language-based methods. The accuracy rate was evaluated to be high as 82% in this task. These two papers should be reviewed as pioneer on how to bring data mining techniques into the area of corporate disclosure. They will shed the lights on a new methodology to examine the information contents of corporate disclosure after the conventional methods based on word list.
Ku et al. (2014)explored whether text mining techniques can be effectively used to identify the unhealthy information from the web or Internet forums. Both bag-of words and part-of-speech were employed to exact the text features which would be classified again through SVM and NB algorithms. SVM proved to be slightly higher than NB on the average accuracy, however NB had been more popular due to its easy implementation. Likewise, Schniederjans et al. (2013)classified social media data mix gathered from blog, forums and websites into 5 Impressions management dimensions based IM assertive strategies. SVM similarly outperform NB on the accuracy rate. Moreover Nassirtoussi et al. (2015) employed 3 different learning machine techniques (SVM, naive Bayes and K-NN) to assign the news headline into ”up” and “down” class. SVM was evaluated to strongly outperform the other two due to its high accuracy rate in that task as well.
Naïve bayes is still quite prevalent in research of text mining while more work attempts to employ new machine learning techniques as well, for example SVM seems next generation classifier on natural language process. However, comparing algorithms has never been an easy task and meanwhile is full of drawbacks. More research efforts should be put on what is used and what lacks, especially under the situation of machine learning being one emerging methodology on textual analsis.
| Diversity industry | Machine learning | ||||
| SVM | Naive Bayes | K-NN | N-gram | Radom forest | |
| Finance | Antweiler and Frank (2004)
Jegadeesh and wu (2013) Purda and skillicorn (2015) |
||||
| Corporate disclosure | Lynnette and David (2015)
Schniederjans(2013) |
Li (2010b)
Schniederjans(2013) |
|||
| Event study | Sprenger et al(2014) | ||||
| Web mining | Ku et al (2013) | Ku et al (2013) | |||
| News | Nassirtoussi et al (2015) | Nassirtoussi et al (2015) | Nassirtoussi et al (2015) | ||
| Software | Suarez-Tangil et al(2014) | ||||
| plagiarism | Oberreuter and Velasquez(2013) | ||||
| crowdfunding | Yuan et al (2016) | ||||
Table 4 sample papers on textual analysis
5. Future research direction
As discussed in section 3&4, data mining techniques have already successfully improved the accuracy of sentiment analysis and textual analysis. As Al-Hassan et al. (2013)demonstrated before, text mining of corporate document brought new research concerns on financial disclosure as well. To a large extent, data mining improved the performance of textual analysis, sentiment analysis and opinion mining, with a breakthrough on high-dimensional processing. All research domains adopting these methodology should get benefits. Nowadays under the context of big data, social media has become the prevailing platform for both people’s self- presentation and organizational business disclosure (Yang and Liu, 2017). More and more companies choose to expand their extra business disclosure through online methods. These social behaviors without question require big data analysis or data mining methodology due to the unstructured and mass volume characteristics of social media data. Hence how we employ data mining techniques to improve social media analysis in specific domain (i.e corporate financial disclosure research) will be our next step consideration.
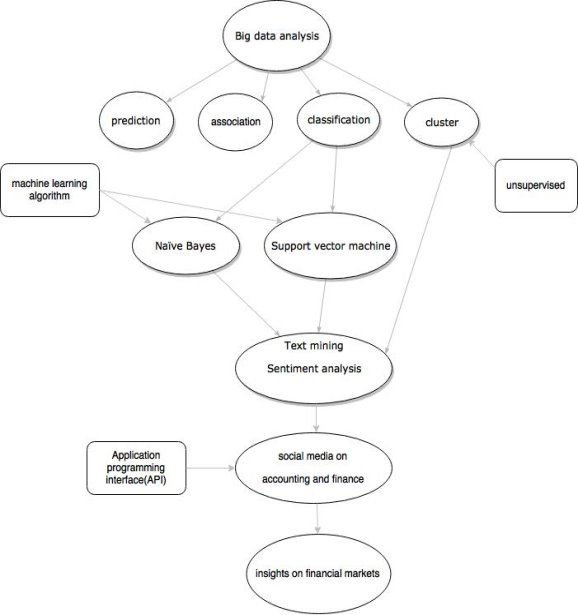
Figure 1 Data mining employed to analyze social media data
Figure 1 illustrated briefly the idea of data mining techniques employed on text mining and sentiment analysis. As we reviewed in section 2, big data analytics could realize different functions such as prediction, association, classification and cluster analysis. Without question, classification and cluster analysis will be most related to natural language process due to the characteristic of text and sentiment. On one hand, supervised machine learning algorithms (Support vector machine or Naïve Bayes) could be employed as classifier to categorize text into different defined groups. For example, Schniederjans et al. (2013) classify 150 publicly traded companies’ social media text data (blogs, forums, websites) into 5 behavior groups which are ingratiation, intimidation, organizational promotion, exemplification and supplication due to direct-assertive impression management strategy.
Similar work could be also experimentally implemented on IM defensive strategy. Another example is event study by Sprenger et al. (2014). Different news from microblogging were classified into company-specific categories such as corporate governance, financial issues, etc. Therefore there is still a lot of research work which haven’t been explored on impression management and event study via social media. On the other hand, sentiment or tone of social media text (i.e posting or twitter) could be classified into positive, negative and neutral with classifier feed with training sets. Then statistical analysis could be applied to find the link between social media and financial markets. This is quite similar with sentiment words analysis (lexicon-based methods) which had already been a prevalent trend in current accounting and finance literature. However with the emerging of big data, social network quite possibly become the next generation main information dissemination platform. Lexicon-based methods or dictionary-based approach obviously can’t deal with mass volume, real-time updated, strongly diverse variety of social media text data such as huge volume of posting, officially or private. Data mining techniques show its advantages on high-dimension and big volume processing ability with superior accuracy rate because of its superiority combination from computer science and statistics.
Li (2010) was the pioneer scholar who bring machine learning into financial disclosure. Tone of MD&A sections were analyzed by naïve bayes classifier, with far higher accuracy rate than lexicon-based approach. We should follow Li’s research to put more efforts on financial disclosure via social media with help of big data analytics. The third interesting aspect is cluster analysis on text. Al-Hassan et al. (2013) employed cluster analysis to classify company legal document which aims to detect if the system cluster similar company into same industrial sections. Quite little research had been dedicated on cluster analysis on text now. One possible reason might be that cluster only classify the text into similar big clusters, rather than into defined categories like machine learning classifiers. However exploration study could be still done to cluster financial posting from social media and examine if the similarity of posting or twitter is same with similarity of financial variables.
Since social media analysis for disclosure will be our next research, the access to social media data become the first consideration. Manual collection only support hundred-dimension sample which is far not enough for big data analysis. Application process interface is a set of computer programming system which could help researcher to connect user data from social media platform such as Facebook or Twitter. Jung et al. (2015) used Twitter Application Program Interface to collect the full text of each tweet of 1500 sample firms. Sprenger et al. (2014) employed the same method to collect 439,960 tweets. This can’t be realized obviously by manual work. Bartov et al. (2015) obtained 10,894,037 tweets from GNIP which is the first authorized reseller of twitter data. This might be another access way for researcher since Facebook only provides open API connection for 30 days period and Twitter limits 2400tweets request per day now.
Another issue is about the data mining techniques employed in the research field of social science. Zorrilla and García-Saiz (2013)described a data mining service addressed to non-expert data miners. The users simply indicate the location of the test data, then the service itself could realize all the function. Research on Data mining techniques requires a huge amount of expertise, therefore a data mining service for non-professional data scientist would be great mascot.
6. Conclusion
This literature review discussed the most prevailing data mining techniques machine-learning and cluster analysis. Machine-learning algorithms could realize different functions such as classification, prediction and association. These function systems and cluster analysis could outperform the traditional methods on text mining and sentiment analysis, obtaining better accuracy and larger capacity tolerance. Future research directions concentrated on social media analysis in financial disclosure based on data mining and data access to social media are stated in the last. One limitation which should be claimed here is the time period of the reviewed papers in this literature review. Only papers published between2013-2017 are chosen for review which might lead to the uncompleted descriptions but the latest opinions brought.
References
Abdelhamid, N., Ayesh, A. & Thabtah, F. (2014). Phishing detection based Associative Classification data mining. EXPERT SYSTEMS WITH APPLICATIONS, 41, 5948-5959.
Al-Hassan, A. A., Alshameri, F. & Sibley, E. H. (2013). A research case study: Difficulties and recommendations when using a textual data mining tool. Information and Management, 50, 540-552.
Antweiler, W. & Frank, M. Z. (2004). Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards. The Journal of Finance, 59, 1259-1294.
Ariyajunya, B., Chen, Y., Chen, V. C. P. & Kim, S. B. (2017). Data mining for state space orthogonalization in adaptive dynamic programming. EXPERT SYSTEMS WITH APPLICATIONS, 76, 49-58.
Bandaru, S., Ng, A. H. C., Deb, K., Institutionen för, i., Högskolan i, S. & Forskningscentrum för Virtuella, s. (2017). Data mining methods for knowledge discovery in multi-objective optimization: Part A – Survey. EXPERT SYSTEMS WITH APPLICATIONS, 70, 139-159.
Bartov, E., Faurel, L. & Mohanram, P. S. (2015). Can Twitter Help Predict Firm-Level Earnings and Stock Returns? 2016 Canadian Academic Accounting Association (CAAA) Annual Conference.
Campagni, R., Merlini, D., Sprugnoli, R. & Verri, M. C. (2015). Data mining models for student careers. EXPERT SYSTEMS WITH APPLICATIONS, 42, 5508-5521.
Carneiroa, N., Figueira, G. & Costa, M. (2017). A data mining based system for credit-card fraud detection in e-tail. DECISION SUPPORT SYSTEMS, 95, 91-101.
Chan, S. W. K. & Chong, M. W. C. (2017). Sentiment analysis in financial texts. DECISION SUPPORT SYSTEMS, 94, 53-64.
Chemchem, A. & Drias, H. (2015). From data mining to knowledge mining: Application to intelligent agents. EXPERT SYSTEMS WITH APPLICATIONS, 42, 1436-1445.
Chen, T., Xu, R. F., He, Y. L. & Wang, X. (2017). Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. EXPERT SYSTEMS WITH APPLICATIONS, 72, 221-230.
Chen, Y., Fay, S. & Wang, Q. (2011). The Role of Marketing in Social Media: How Online Consumer Reviews Evolve. Journal of Interactive Marketing, 25, 85-94.
Choi, Y. & Lee, H. (2017). Data properties and the performance of sentiment classification for electronic commerce applications. Information Systems Frontiers, 19, 993-1012.
Chung, W. & Zeng, D. (2016). Social‐media‐based public policy informatics: Sentiment and network analyses of U.S. Immigration and border security. Journal of the Association for Information Science and Technology, 67, 1588-1606.
Daniel, M., Neves, R. F. & Horta, N. (2017). Company event popularity for financial markets using Twitter and sentiment analysis. EXPERT SYSTEMS WITH APPLICATIONS, 71, 111-124.
Denecke , K. (2009). Are SentiWordNet scores suited for multi-domain sentiment classification? Fourth International Conference on Digital Information Management(ICDIM). IEEE.
Deng, S. Y., Sinha, A. P. & Zhao, H. M. (2017). Adapting sentiment lexicons to domain-specific social media texts. DECISION SUPPORT SYSTEMS, 94, 65-76.
Ferguson, R. B. (2014). Elevating Data, Analytics to the C-Suite. MIT Sloan Management Review, 55, 1.
Fersini, E., Messina, E. & Pozzi, F. A. (2014). Sentiment analysis: Bayesian Ensemble Learning. DECISION SUPPORT SYSTEMS, 68, 26-38.
Garcia-Rudolph, A. & Gibert, K. (2014). A data mining approach to identify cognitive NeuroRehabilitation Range in Traumatic Brain Injury patients. EXPERT SYSTEMS WITH APPLICATIONS, 41, 5238-5251.
George, G., Haas, M. R. & Pentland, A. (2014). BIG DATA AND MANAGEMENT. ACADEMY OF MANAGEMENT JOURNAL, 57, 321-326.
Giatsoglou, M., Vozalis, M. G., Diamantaras, K., Vakali, A., Sarigiannidis, G. & Chatzisavvas, K. C. (2017). Sentiment analysis leveraging emotions and word embeddings. EXPERT SYSTEMS WITH APPLICATIONS, 69, 214-224.
Jegadeesh, N. & Wu, D. (2013). Word power: A new approach for content analysis. JOURNAL OF FINANCIAL ECONOMICS, 110, 712-729.
Jung, M. J., Naughton, J. P., Tahoun, A. & Wang, C. (2015). Do Firms Strategically Disseminate? Evidence from Corporate Use of Social Media. The Accounting Review, Forthcoming.
Kim, M. Y. & Lee, D. H. (2014). Data-mining based SQL injection attack detection using internal query trees. EXPERT SYSTEMS WITH APPLICATIONS, 41, 5416-5430.
Ku, Y., Chiu, C., Zhang, Y., Chen, H. & Su, H. (2014). Text mining self‐disclosing health information for public health service. Journal of the Association for Information Science and Technology, 65, 928-947.
Latkowski, T. & Osowski, S. (2015). Data mining for feature selection in gene expression autism data. EXPERT SYSTEMS WITH APPLICATIONS, 42, 864-872.
Lau, R. Y. K., Li, C. P. & Liao, S. S. Y. (2014). Social analytics: Learning fuzzy product ontologies for aspect-oriented sentiment analysis. DECISION SUPPORT SYSTEMS, 65, 80-94.
Lee, I., Cai, G. C. & Lee, K. (2014). Exploration of geo-tagged photos through data mining approaches. EXPERT SYSTEMS WITH APPLICATIONS, 41, 397-405.
Li, F. (2010). The Information Content of Forward-Looking Statements in Corporate Filings—A Naïve Bayesian Machine Learning Approach. Journal of Accounting Research, 48, 1049-1102.
Liao, S.-H. & Chou, S.-Y. (2013). Data mining investigation of co-movements on the Taiwan and China stock markets for future investment portfolio. Expert Systems with Applications, 40, 1542-1554.
Loughran, T. & McDonald, B. (2016). Textual Analysis in Accounting and Finance: A Survey. Journal of Accounting Research, 54, 1187-1230.
Marcano-Cedeño, A., Chausa, P., García, A., Cáceres, C., Tormos, J. M. & Gómez, E. J. (2013). Data mining applied to the cognitive rehabilitation of patients with acquired brain injury. Expert Systems with Applications, 40, 1054-1060.
McAfee, A. & Brynjolfsson, E. (2012). Big Data: The Management Revolution. Harvard Business Review. Boston: Harvard Business Review.
Meire, M., Ballings, M. & Van den Poel, D. (2016). The added value of auxiliary data in sentiment analysis of Facebook posts. DECISION SUPPORT SYSTEMS, 89, 98-112.
Miller, G. S. & Skinner, D. J. (2015). The Evolving Disclosure Landscape: How Changes in Technology, the Media, and Capital Markets Are Affecting Disclosure. Journal of Accounting research, 53, 221-239.
Moreno Sáez, R., Sidrach-De-Cardona, M. & Mora-López, L. (2013). Data mining and statistical techniques for characterizing the performance of thin-film photovoltaic modules. Expert Systems with Applications, 40, 7141-7150.
Moro, S., Rita, P. & Vala, B. (2016). Predicting social media performance metrics and evaluation of the impact on brand building: A data mining approach. JOURNAL OF BUSINESS RESEARCH, 69, 3341-3351.
Narayanan, V., Arora, I. & Bhatia, A. (2013). Fast and accurate sentiment classification using an enhanced Naive Bayes model. Intelligent Data Engineering and Automated Learning IDEAL 2013. Lecture Notes in Computer Science, 8206, 194-201.
Nassirtoussi, A. K., Aghabozorgi, S., Teh, Y. W. & Ngo, D. C. L. (2014). Text mining for market prediction: A systematic review. EXPERT SYSTEMS WITH APPLICATIONS, 41, 7653-7670.
Nassirtoussi, A. K., Aghabozorgi, S., Teh, Y. W. & Ngo, D. C. L. (2015). Text mining of news-headlines for FOREX market prediction: A Multi-layer Dimension Reduction Algorithm with semantics and sentiment. EXPERT SYSTEMS WITH APPLICATIONS, 42, 306-324.
Nedic, V., Cvetanovic, S., Despotovic, D., Despotovic, M. & Babic, S. (2014). Data mining with various optimization methods. EXPERT SYSTEMS WITH APPLICATIONS, 41, 3993-3999.
Nguyen, T. H., Shirai, K. & Velcin, J. (2015). Sentiment analysis on social media for stock movement prediction. EXPERT SYSTEMS WITH APPLICATIONS, 42, 9603-9611.
Ortigosa, A., Martin, J. M. & Carro, R. M. (2014). Sentiment analysis in Facebook and its application to e-learning. COMPUTERS IN HUMAN BEHAVIOR, 31, 527-541.
Pachidi, S., van de Weerd, I. & Spruit, M. (2014). Understanding users’ behavior with software operation data mining. Computers in Human Behavior, 30, 583-594.
Pang, B. & Lee, L. (Year). Thumbs up? Sentiment Classi¯cation using Machine LearningTechniques. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2002 Philadelphia. Association for Computational Linguistics, 79-86.
Prollochs, N., Feuerriegel, S. & Neumann, D. (2016). Negation scope detection in sentiment analysis: Decision support for news-driven trading. DECISION SUPPORT SYSTEMS, 88, 67-75.
Purda, L. & Skillicorn, D. (2015). Accounting Variables, Deception, and a Bag of Words: Assessing the Tools of Fraud Detection. Contemporary Accounting Research, 32, 1193-1223.
Samuel, A. L. (2000). Some studies in machine learning using the game of checkers. IBM Journal of Research and Development, 44, 206-226.
Sanders, N. R. (2016). How to Use Big Data to Drive Your Supply Chain. California Management Review, 58, 26-48.
Schniederjans, D., Cao, E. S. & Schniederjans, M. (2013). Enhancing financial performance with social media: An impression management perspective. Decision Support Systems, 55, 911-918.
Schumaker, R. P., Jarmoszko, A. T. & Labedz, C. S. (2016). Predicting wins and spread in the Premier League using a sentiment analysis of twitter. DECISION SUPPORT SYSTEMS, 88, 76-84.
Senadheera, V., Warren, M. & Leitch, S. (2017). Social media as an information system: improving the technological agility. Enterprise Information Systems, 11, 512-533.
Singh, S., Okun, A. & Jackson, A. (2017). Artificial intelligence: Learning to play Go from scratch. Nature, 550, 336.
Sprenger, T. O., Sandner, P. G., Tumasjan, A. & Welpe, I. M. (2014). News or Noise? Using Twitter to Identify and Understand Company‐specific News Flow. Journal of Business Finance & Accounting, 41, 791-830.
Stieglitz, S. & Dang-Xuan, L. (2013). Emotions and Information Diffusion in Social Media-Sentiment of Microblogs and Sharing Behavior. Journal of Management Information Systems, 29, 217-248.
Tahmasebi, P., Javadpour, F. & Sahimi, M. (2017). Data mining and machine learning for identifying sweet spots in shale reservoirs. EXPERT SYSTEMS WITH APPLICATIONS, 88, 435-447.
Tellez, E. S., Miranda-Jimenez, S., Graff, M., Moctezuma, D., Siordia, O. S. & Villasenor, E. A. (2017). A case study of Spanish text transformations for twitter sentiment analysis. EXPERT SYSTEMS WITH APPLICATIONS, 81, 457-471.
Traore, B. B., Kamsu-Foguem, B. & Tangara, F. (2017). Data mining techniques on satellite images for discovery of risk areas. EXPERT SYSTEMS WITH APPLICATIONS, 72, 443-456.
Yang, H.-L. & Chao, A. F. Y. (2015). Sentiment analysis for Chinese reviews of movies in multi-genre based on morpheme-based features and collocations. Information Systems Frontiers, 17, 1335-1352.
Yang, H. F. & Chen, Y. P. P. (2015). Data mining in lung cancer pathologic staging diagnosis: Correlation between clinical and pathology information. EXPERT SYSTEMS WITH APPLICATIONS, 42, 6168-6176.
Yang, J. H. & Liu, S. (2017). Accounting narratives and impression management on social media. Accounting and Business Research, 47, 673-694.
Yousefpour, A., Ibrahim, R. & Hamed, H. N. A. (2017). Ordinal-based and frequency-based integration of feature selection methods for sentiment analysis. EXPERT SYSTEMS WITH APPLICATIONS, 75, 80-93.
Yu, Y., Duan, W. & Cao, Q. (2013). The impact of social and conventional media on firm equity value: A sentiment analysis approach. Decision Support Systems, 55, 919-926.
Yu, Y. & Wang, X. (2015). World Cup 2014 in the Twitter World: A big data analysis of sentiments in US sports fans’ tweets. COMPUTERS IN HUMAN BEHAVIOR, 48, 392-400.
Zolbanin, H. M., Delen, D. & Zadeh, A. H. (2015). Predicting overall survivability in comorbidity of cancers: A data mining approach. DECISION SUPPORT SYSTEMS, 74, 150-161.
Zorrilla, M. & García-Saiz, D. (2013). A service oriented architecture to provide data mining services for non-expert data miners. Decision Support Systems, 55, 399-411.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: