Malware Detection Using Machine Learning
Info: 11242 words (45 pages) Dissertation
Published: 20th Feb 2025
Tagged: Computer ScienceCyber Security
Abstract
As there is a continuous rise in the computer tech, the hackers and the hacking incidents are also increasing. As a result of which the demand of security is also elevating. Malwares have been a great pain for the computer users around the world. Huge organizations have gone into huge losses due to a loophole in security. In current world of technology, Machine learning is considered to be the future and the most powerful concept in technology. The aim is to utilize the concept of machine learning and to build a model using ensemble algorithm which can be trained efficiently to detect malwares in a system. This project is about the comparative study of general machine learning algorithms and hybrid algorithms to understand how much impact a hybrid machine learning algorithm can produce in identifying the malwares over general machine learning algorithms.
Table of Contents
Chapter 1. Introduction
1.1 “Malware”, (or specific field of expertise, problem name, etc.)..................6
1.2 “Working of a Malware” (or something similar)............................9
1.3 “Problem Statement” (or something similar)..............................9
1.4 “Motivation”..................................................11
1.5 "Purpose"…………………………………………………………………..12
Chapter 2. Background...................................................15
2.1 Literature Review...............................................15
2.2 Related Work..................................................21
Chapter 3. Methodology ..................................................22
Chapter 4. System Design and Specifications....................................39
Chapter 5. Implementation................................................45
Chapter 6. Results......................................................47
Chapter 7. Conclusions and Future Work.......................................65
References...........................................................66
Chapter 1: Introduction
Since, the discovery of the computer it has taken over the world. It is almost like the industrial revolution or even better than that. Every business sector has taken it in to their system which has resulted in a great profit for them. Running adds, marketing your products online. Marketing your company online, maintaining statistical records etc computer does it all. Computer has also acquired a place in the social life of each and every individual. It has resulted in getting the world closer. Anything happening in one part of the world is easily known to far remote corners through the medium of Internet. People are using computers for all sorts of things right from entertainment to learning. But along with all this there perks their also exist some drawbacks. Computer contains a good chunk of data stored to it due to several operations performed on it. This can be the data of an individual or large multinational company. The data also can be very sensitive or private for the individual or company. These data can be corrupted, changed or leaked. All this can happen by the use of malware. Malware can corrupt the data on the computer, it can leak the sensitive data to its operator or make it public it can also crash a computer. It can destroy a computer completely. It is also possible to remote control a computer with some malware by the hackers. These malwares can enter a computer system by an i/o drive or Internet. A user may just click on a link cluelessly and can download a malware without knowing. Malware is itself a very wide term. A virus, trojan, spyware all these tools comes under malware which hacker uses to get into a computer system. Due to all this chaos caused by malware antivirus and antimalware has come into development. These antiviruses are installed a computer system. The job of the antimalware is keep the computer clean or safe from any malware. Destroy or prohibit any malware from entering the system. Even after all these, there are still reports from all around the world of people and organizations getting hacked which resulted into a huge loss. This antimalware has definitely improved the security of computer but has not been effective to stop these malware attack to a large extent.
1.1 Malware
(Anon., n.d.)
Malware is nothing but a computer program which is programmed with a soul purpose of destruction. These programs are classified based on their usage or attack type. There exists a variety of malware like viruses, worms, Trojan horses, and spyware. Different kinds of attacks can be launched using these tools resulting in stealing, encrypting, deleting sensitive data.
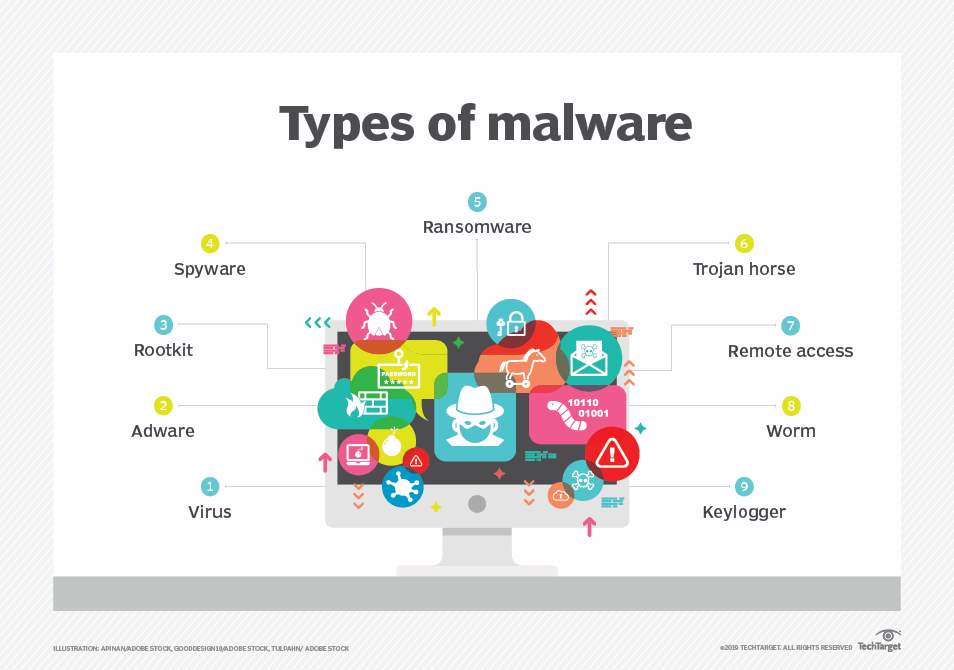
Fig 1-1 Types of Malware (Anon., n.d.)
Fig 1-1 displays the different types of malware that can damage a system.
Virus
(Anon., 2020)
A computer virus is nothing, but a computer program written by some hacker with a malicious intent. These viruses are generally attached to the torrent links. Once the virus enters the system it starts replicating itself. It can corrupt a system hard drive or RAM. It can completely malfunction a system. Viruses are executable code. It can gain admin control and can steal sensitive data.
Adware
(Anon., 2020)
Adware are computer programs which behaves as legitimate software’s. It tricks user into installing them through the browser. Once the user installs this software. It randomly generates pop-up adds on the use screen. The hacker earns revenue for these adds.
Root Kit
(Anon., 2020)
Root Kit are one of the most dangerous malware that can get installed on a system. Once it gets installed on a victims computer it bypasses all antivirus and starts establishing control over the system. It gives the hacker admin level privileges on the system. The attacker can do whatever he wants to do on the system, and no one will even notice.
Spyware
(Anon., 2019)
A spyware is a computer programs that generally hides behind some legit program and enters the system. As the name implies its job is to spy on the user everyday job and to send sensitive data and all current updates back to the hacker through a backdoor.
Ransomware
(Fruhlinger, 2018)
Ransomwares are computer malwares which once installed on the system usually encrypts all the systems sensitive data. These kinds of attacks generally happen to large organizations. It prohibits user to access his/her own data. The hacker than demands a ransom to give the decryption key for the encrypted data and specifies the mode of payment.
How ransomware works:
Ransomware attacks can happen with the help of phishing. Here user is generally tricked by the hacker to install the malware. Phishing can take place through emails. The user generally opens these emails and the files gets downloaded other vicious way is to find loopholes in the system and hack the system to install ransomware.
Trojan Horse
(Anon., n.d.)
A Trojan Horse or Trojan is a computer programs which acts all legit and deceives users into installing them. Once these Trojans are installed it can damage a system or perform task it is programmed to perform. It generally tricks user in believing that it is some legit software. The user has to execute the software in order for Trojan to get activated. It cannot activate itself.
Worms
(Anon., n.d.)
A worm is kind of computer software that does not needs a legit software or does not have requirement to act like a legit software. Once it finds a way into a system, it starts replicating itself from one system to another.
1.2 Working of a Malware
(Anon., n.d.)
Hackers use a variety of different applications to deploy these malwares on their victim’s computers. These methods can be based on physical or virtual means. For example, malicious programs can be installed on a computer with help of Flash drive or can enter a computer system using drive-by downloads, which automatically download malicious programs to systems without the user's approval or knowledge. Phishing is another way to install malware on a victim computer. Phishing is an art of social engineering which tricks user into download or installing a virus or malware through some external sources. The user believes that he/she is dealing with legit data, but in reality, he/she is just tricked by hacker to download the malicious software. For e.g.: A user may receive an email saying that he has won a lottery and he has to download some form from the lottery company website to claim the lottery. The user will download the malicious files thinking that he is downloading the lottery claim form instead. This is the very common example. As the security science is improving, new evasion techniques are also used by the malware people to fool security administrators and anti-malwares. Using source IP address and web proxies are some of the simple methods used by the malwares. There are definitely some sophisticated techniques used like polymorphic malware, it has the ability to continuously change its own code to distinguish itself from getting detected from signature-based detection tools, anti-sandbox techniques, which gives the power to malware to stall the action by the windows or antivirus after getting detected until after it leaves the sandbox. The genuine hideout for such kind of antivirus is the RAM.
1.3 Problem Statement
Malicious software or Malwares are the software which are programmed to harm or create issues for the user or the system (Anon., n.d.). This malicious software is definitely an increasing threat to computer systems and network which are owned by the giant organizations and big companies. And because of this issues malware analysis and detection has become a key issue in today’s era. It is a fact that plethora of malicious softwares like computer viruses has been created in the recent years. As we have seen the different continuous evolutions in the field of cyber securities and despite of those significant improvements of security mechanisms, malwares are still a major threat to the cyber space. Facing this problem many researchers and the vendors are coming together towards a way to find the faster alternate method of detection and analysis of malwares which can become a savage to protect the latest internet world from being attacked. There are various anti-malware companies that develop software to tackle malwares for e.g. Kaspersky, Norton, McCafee etc. But even after the presence of all this software, malware attack still happens in a large number. People are still facing losses (C, 2018).

Fig 1-2 Types of breaches (ZAHARIA, 2020)
Above graph is a result of research conducted by CopariTech (Andra Zaharia) on effects of cyber security around the globe. In this research the researcher is trying to analyse the effects of cyberattack on economy through statistics.
Some recent major malware attacks
1) Lucy: A File Encryption Android Malware that for Ransomware Operations (Anon., 2020)
This is a malware attack named Lucy on smartphones. This attack is based on the malwares file encryption capabilities. There is a cyber-criminal gang named Lucy in Russia. The gang became famous by launching a malware Botnet attack named Black Rose Lucy Service. As the android accessibility service feature has the ability to mimic a user once the screen is touched, this is the exploit used by this hacker gang. Once this malware is installed on smart phones through internet. It is able to grant itself all admin privileges. It then gives the authority to the hacker to attach files to the mobile device. The attackers then mimic to be FBI and attaches or sends notes files to the targeted android saying that he/she is found guilty of storing pornographic content and must pay a ransom of 500$ as penalty.
To make ransom look legit and threatening ,the attacker sends a note to user browser saying that they have the user photograph and all the details and mow he has to penalty if he is not payed the user may be apprehended.
2) (Anon., 2020) Microsoft warned the world about a malware hidden in pirated film files. Microsoft researchers have discovered a malware attack in which the attackers upload a payload into pirated film files. The files have been downloaded by tens and thousands of people from South America, Mexico, and Spain.
Microsoft researchers on a twitter thread said that attackers use to hide a malicious VBscript zip file inside the movie file. These ZIP files have names like"contagion:1080p, JohnWick Blue Rayes" etc. When the users click on this file, the vbscript is run and more files are downloaded from the internet. An autoIT script is downloaded with this the second stage DLL is decoded. Microsoft says that the use of torrent websites and torrent downloads have increased significantly as more and more people are staying at home due to quarantine because of Corona virus.
3) (Anon., 2020) At a Security Summit Held in Russia by Kaspersky the Kaspersky researchers talked about the malware Phantom Lance’s used by the hackers to upload malicious applications on playstore. The user on the other hand thinks that the applications are on playstore supported by google security hence must be secure. The users download these applications and get hacked. This kind of attacks are mostly targeted towards Asian countries like India, Bangladesh, Srilanka, China.
1.4 Motivation
The increase of malware that are exploiting the system, servers & networks have become a serious threat. Since the time I started learning about technologies, I always observed the security issues while using any kind of applications, websites or working in a real time environment. Talking about any other field or area in the technology, all are growing rapidly for the worldwide enhancement. But discussing about the cyber securities or viruses is the field which I think is still facing issues and challenges to protect the cyber space from being attacked. As I had studied about the malware approach regarding the security of the websites, it was very easy to crack or deal with their authentication & old classical standard signature encryption techniques. So, to protect the systems with the malware attacks it is very important to know and understand the detection and resolution of any malware techniques. Machine Learning is almost a revolution in the world of technology. The old “if else” system of programming is getting replaced by Machine Learning algorithms. Its greatest power is to learn from the existing environment and helps in decision making. I have always been curious about the implementation of this prediction concept of ML in the world of security.
1.5 Static Malware Analysis
The static malware analysis is the analysis in which one reviews , inspects source code and binaries to find the suspicious pattern in the code. In static analysis the executable or binary files are analysed without executing it. These executables files have different attributes like sections and memory. And the static features from the executables files can be extracted using the PEFILE (portable executable )which is a python library.
1.6 Dynamic Malware Analysis
Cuckoo Sandbox environment is used for dynamic analysis for malwares and traces the behaviours at run time execution. We are analysing the software while running it.The basic motive using the sandbox is to isolate the actual system from the testing environment and extracting the desired information from the malware execution.
1.7 Data Extraction and Analysis
This will be done with the help of samples provided in VirusShare.com and for dynamic analysis I have used Cuckoo Sandbox Environment is an Automated Malware Analysis websites which is used to record the API calls during execution with summarized code & Api response code.Data will be analysed on the basis of feature and dependent variable selection.
1.8 Purpose
The purpose of this thesis is to analyze all the important previous research conducted on cybersecurity. To understand how a particular researcher tackled a problem. I am going to analyse different concepts used to build the anti-malware and pick out some important features from them which actually had an impact in tackling the malwares. This research is completely Machine Learning based so my main goal will be to use these features as parameters for my model. My purpose is also to understand how Machine learning concepts deal with cybersecurity issues, is machine learning powerful enough to deal with all kinds of malware.
1.9 Research Question
The research uses the Machine learning concept to buid an anti-malware software. In past researchers have used machine learning to tackle malware attacks, but the succes was not very great. Previous researchers have used different algorithms like Random forest, Naïve Bayes, Clustering etc. The aim of this research is how efficently and accurately we can detect malware on a system using machine learning algorithms.
This Entire dissertation is divided into seven sections:
Chapter two: Literature review
Here I have listed the journals and sources studied by me to build this thesis. A complete detailed report on each journal used for this thesis is listed in this section
Chapter Three: Methodology
This chapter deals with the resources used for implementing the system. Here a complete discussion is given on the concepts used and the algorithm used for the development of the thesis. A discussion is also done on dataset and feature extraction for this thesis.
Chapter Four: Implementation
Here a discussion on actual implementation is done for this thesis. A step by step complete discussion is done for the implementation.
Chapter Five: Results
This section contains a discussion on the results obtained by different algorithms after implementation.
Chapter Six: Conclusion
Finally, a conclusion is put forward after the implementation and analysis of the results obtained.
Chapter Seven: Reference
Finally, here I will include all are research papers and references used by us for developing this thesis.
Chapter 2: Background
This chapter consist of the detailed discussion of the research papers studied for the development of this thesis. A complete analysis will be done on different methods and concepts used for the detection of malware on the computer system, their advantages, disadvantages. A discussion on the current system used for detection of malware will be done. After analysing all the previous research and concept a discussion will be done on the takeaways from the previous research that have been used while developing the current system.
2.1 Literature Review
(Wu, et al., 2011) proposed a concept to detect malware on a system using BOS and MBF features. BOS stands for Behaviour Operation Set. BOS is actually basic operations that are performed in the system and makes a change in the status of the system. This may include like creating a file, deleting a file etc.
(Wu, et al., 2011) defined four BOS types:
1) File Action(FA)
2) Process Action (PA)
3) Network Action (NA)
4) Registry Action(RA)
Features from these BOS which are found in malicious softwares are termed as MBF (Malicious Behaviour Features). Every MBF is defined by a triplet:

Table 2-1 Set of MBF features used by (Wu, et al., 2011) to detect malware.
The algorithm used was:

Sets ba and be are behaviour operation sets constructed from malware dataset. The value for each feature is calculated and stored in ‘dtr’. (SatisfiedMalFeature) a function performs a check on the value to see if its true or not. If the value is true, add the judgment gist by function AppendProof. The result obtained by (Wu, et al., 2011) was really fascinating .The accuracy of the system was 97%.Some of the features used by the system performed very efficiently to produce a great result.
Discussion
Although the result seems good for the software developed by (Wu, et al., 2011) with accuracy about 97% and a low false positive of 3%. But the problem with the system is that this false positive rate will definitely increase with increase in dataset and for malware detection a high false positive is a matter of concern. The low false positive rate of this system is due to small dataset used by them. The features used by (Wu, et al., 2011) are not all perfect, the behaviour of some features according to (Wu, et al., 2011) are common for both malicious and non-malicious software or code.
(Yeo, et al., 2018) gathered data from Stratosphere IPS and build a dataset for their system. On the basis of research done by (Stiborek, et al., 2014) and stratosphere ips organization, (Yeo, et al., 2018) downloaded the data of nine different malware from stratosphere ips.
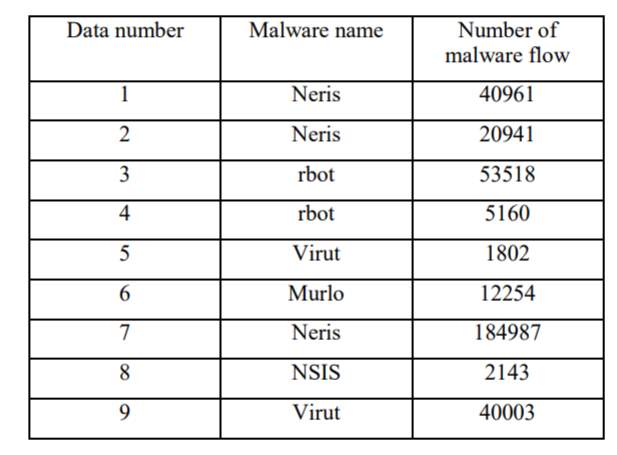
Table 2-2 (Yeo, et al., 2018)
Table 2-2 displays the name of malware and number of flows of the malware found by stratosphere ips. Based on these flows of different malware (Yeo, et al., 2018) used four Machine learning algorithms CNN, MLP, SVM and RF to create a dataset of features. This data set consisted of 35 features for detection of malware on a computer. The accuracy obtained by (Yeo, et al., 2018) was 80%.
Discussion
The dataset used by (Yeo, et al., 2018), its pre-processing, was very accurately done. The feature gathering for malware detection was done very precisely by using Stratosphere IPS dataset. On the data gathering and feature selection the work done by (Yeo, et al., 2018) is great. The algorithms used here for making prediction are CNN, MLP, RF and SVM. Out of these algorithms best results are found by CNN and RF with accuracy of about 85% and 93% respectively. There are not many disadvantages with this research other than using basic Machine Learning algorithms rather than using some hybrid algorithm to improve the accuracy.
(Loi & Olmsted, 2017) studied various Heuristic based methodologies to detect malware in a statistical manner. They found that the result obtained by most of the heuristic based research had a high rate of False Positive. They proposed their own system to check for Backdoor Malware. They proposed that the easiest way to check if a back door is running on the system is to check for any existing internet connection established. Also, the destination domain to which this connection is established. Then to check from online blacklist DNS detection websites API to check if the destination domain is legit or not.
Discussion
The system developed by (Loi & Olmsted, 2017) contains some great features, easy to develop and cost effective. It is good against backdoor attack using malwares. The system is solely focused on detecting backdoor based attacks and no other kinds of threats.
In the year of (Pirscoveanu, et al., 2015) used the cuckoo sandbox for capturing the malwares behavioural for malwares files. This classification system was developed by using the random forest algorithm which produces the 98% of the accuracy in malware classification. A malware detection technique with API features was proposed in the same year by Ki et al. This technique executes the malware samples in the dynamic environment and API sample were developed. The technique explained that every malware executes the almost same kind of API call sequence which perform the maliciousness and produced the 98% recall.
Discussion
This Sandboxing system of (Pirscoveanu, et al., 2015) shows different accuracy for different types of malware.

Table 2-3 Result of Testing Phase (Pirscoveanu, et al., 2015)
As, we can see the accuracy obtained for four types of malware are good. Overall, the results seem best. In the future work the researcher has mentioned that the accuracy of finding Trojan is high due to the high presence of Trojans in Dataset. According to (Pirscoveanu, et al., 2015) the research has also led to high false positive which has been over shadowed by the accuracy. The sandboxing method is also focusing on the four types of malware as shown in fig 2-3, but there are also other kinds of Malware like virus, Spyware, File less malware, Ransomware etc.
In the year of 2018, (Stiborek et al.,2018) had used the Sandbox approach to capture the behaviour of malwares by executing the samples of malwares in the sandbox environment. Here, every malware sample were executed as a pair of names and resources type for extracting the features from it. Then the different algorithms have been applied such as random forest, liner SVM and Multi-Layer Perception over the extracted features which gave approximately 95% of accuracy in the malware detection.
(Wang , et al., 2009) proposed a detection method based on SVM for detecting unseen portable executables. The model proposed by Wang et al. detects the virus and worms with the accuracy of 98.86% but its detection accuracy is lower for backdoors and trojans.
(Liao et al., 2012) in their research used a hand-crafted based algorithm for classification which resulted in selection of only five fields of PE headers as the feature. This algorithm achieved 99% accuracy in the classification of malwares.
(Alaeiyan et al. ,2019) proposed a triggered based malicious detection technique using the behavioural features. And then after experimenting results were evaluated with the 1100 approximately malicious programs which gave the 97.9% accuracy in the malware detection.
(Muhamad & Rahardjo, 2019) proposed a malware detection system using honeypot and machine learning. According to this system most of the internet traffic that enter the system has to funnel through the router. The router is responsible for establishing a connection between the outer network and the local network. The honeypot is placed at this location, what it does is capture all the packets that passes through. It runs an analysis on these packets. This analysis is done with the help of SVM and decision tree-based algorithm. The algorithm tries to identify the class of malware packets.
Honey pot is nothing, but a machine learning model trained using Support Vector Machine algorithm. The analysed packets are passed on as a popup to admin to decide whether to keep or remove the file.
The system diagram for honey pot is given in fig :

Fig 2-3 System Architecture (Muhamad & Rahardjo, 2019)
2.2 Related Works
As from (Muhamad & Rahardjo, 2019) and (Stiborek et al.,2018) I am also going to follow the machine learning approach to detect malware. For thesis I will use the RF algorithm as mentioned by (Muhamad & Rahardjo, 2019) which gave them the better results. Along with the RF I will also use some other Hybrid/ensemble algorithms like ADABoost, Gradient Boosting and perform a comparative study among them. This thesis also follows heuristic based approach like (Loi & Olmsted, 2017). But here I will not randomly select the features to train the model. A set of features will be gathered. Random Forest Feature selection classifier and other algorithms will be applied on these features to extract the best features out of them. The aim of the thesis is to find the best suitable machine learning algorithm than can increase the accuracy of malware detection using machine learning. In next section we will discuss this methodology in detail.
Chapter 3 Methodology
In the previous chapter a discussion is done on how different researchers utilized different concepts to detect malwares on a system. A deep analysis has been done regarding their drawbacks and advantages. In this section of the thesis, a discussion will be done regarding the methodology used for the development of this thesis, creation of dataset, feature extraction, algorithms used etc will be analysed for this thesis in depth.
The working of the thesis is highly depended on the concepts of machine learning, so first let us understand about machine learning.
Machine Learning
Machine learning is an art of computer science that automatically learns from its experience and surroundings. It contains development of algorithm that learns from experience or available data to predict the outcome. The world of computer is full of data and machine learning utilizes those data to predict the outcome of a task. We have still not utilized the power of machine learning to its full extent. First a dataset is fed to the machine learning algorithm. This dataset consists of the data of past generated outcomes and the features associated with them. The job of the machine learning is to analyse the feature which has the higher weights in the occurring of an outcome. It analyses those features and predicts what the result can be. The machine learning over comes the tradition “if else” method of writing code.
Overall, there exists two types of machine learning algorithms:
Supervised Machine Learning
The supervised learning consists of both input and output data as dataset. Here the goal of the algorithm is to understand the mapping between the input and the output. The algorithm should understand the relationship between particular sets of input and the specific output generated by them. For example, a training dataset can be fed to the algorithm which consist of temperature of the day and the number of people visited to the beach on that day. The algorithm will analyse this data. When a particular temperature of day is fed to the algorithm as input. It will predict the number of people who will visit the beach on that particular day.
Un-Supervised
Un-supervised machine learning is a type of learning in which only input data is given to the algorithm and the output is unknown. Here the algorithm has no supervision regarding the steps it should take. The algorithm has to analyse some pre-existing hidden pattern in the input dataset and make predictions or find a solution. This is the hardest learning method. The algorithm has to follow the try and error kind of approach to reach a conclusion. Using Un-supervised Machine Learning new methods can be developed to tackle any problem. Hence this kind of approach is also known as knowledge discovery approach.
The results obtained from a supervised ML model can be a category from a set given, if this is the case it decides how the given data should be classified, this is known as classification.
Alternatively, the output or results could be in the form of a number that is a scalar output:
In such cases, it is known as regression.
Classification
The concept of classification is to group similar data points together and separate different data points. Machine learning contains some algorithms that does these jobs.
Linear separability is one of the very basic concepts behind classification algorithm. Here a line is used to make separation between two different kinds of data points.
Regression
Regression is other form of supervised learning. Here the algorithms try to predict a number rather than to make some classification. Like stock market prices, the salary of employees of a company based on his/her experience.
Semi-supervised learning
Semi-supervised learning is kind of a combination of both supervised and un-supervised learning. Like supervised leaning it is given some sort of output or goal to achieve, but also like unsupervised learning the goal given to the model is not complete. The output is vague. It kind of follows a roadway between supervised and un-supervised learning.
Configuration
Python is as the language for the development of this thesis. Python is a high level and interpreted programming language. This language is very popular among the professionals working in data science field. Python provides a wide set of libraries that makes machine learning easier for developers.
The machine used for development = Dell XPS Intel i7 processor
RAM = 16GB
OS: Windows 10
Language = Python 6.3.3
Text Editor = VSCode
Data Set
The dataset for this thesis is obtained from Kaggle. Kaggle is an online platform that host various machine learning resources. These resources are generally open source research conducted by expert machine learning professional.
The thesis makes use of various machine learning algorithm to detect malware in a software. Each algorithm follows a separate path to reach a conclusion. This can describe the process of each algorithm. A flow chart is a diagram category which illustrates a procedure, an equation or method which displays the measures as boxes of different sorts and their order by connecting them to documents. The diagram shows a template of solution for a problem. Python is chosen for this application. Python is an intelligent tool for development. Python is widely regarded as the language of choice of computer models of education and learning. Python also has special tools that work with machine learning systems extremely helpfully. Some of them list a variety of frames and modules and plugins such as NumPy where Python's tasks are easier to carry out. Therefore, for these applicable uses, the meaning of the programming language itself is also relevant. The scikit module "Machine Learning in Python" provides a further resource that can guide professionals to Python (Pedregosa, et al., 2011).
We also use Ensemble Classifiers in the process to detect phishing websites. Ensemble Classifier is a classifier formed by combining two or more different classifiers. This newly created model or more precisely the hybrid model can be far more efficient than each one them to be used alone. In this hybrid model different learning and methods are used to produce N-different models using a single dataset. In a nutshell, the system than combines the output of all these models to get the most efficient output. The output obtained is a weighted average of all inputs for each model.
Feature Extraction
Features are one of the important factors while developing the model. For developing model to detect malware a set of 14 PE features are used. These features are been extracted from a set of 57 PE features. A set of algorithms are run on the dataset of 57 PE features to get 14 best features of them.
PE File
PE stands for Portable Executable. PE is a format used by files this kind of file format is used by windows applications. They are mostly used for executable object code, DLLs, FON font files, and core dumps.
The PE file format is a format used by the Windows Operating System to run applications consisting of wrapped executable codes.
Basic Structure
A PE executable consist of two section, which further sub-divides itself into multiple sections. One is Header and the other is Section. The diagram below explains everything

Fig 3-1 PE DOS Header (Anon., 2019)
DOS header starts with the first 64 bytes of every PE file. It is because with the help of this DOS is able to recognize that a given file is a valid executable file and it ca be run in the DOS stub mode.
Some basic and important sub-section belonging to the header section are:
- Signature
- Machines
- NumberOfSections
- SizeOfOptionalHeader
Feature Selection
Random Forest Algorithm is used for feature selection. Random Forest is one of the widely used algorithm for selecting features. It overcomes the problem of overfitting and interpretability to a high extent.
Random forest feature selection comes under the category of embedded method. The advantages of using embedded methods are:
- Similar to Wrapper methods feature interaction is considered here.
- Embedded methods have speed similar to the filter methods.
- Highly accurate.
- They find the feature subset for the algorithm being trained.
- Overcomes the problem of overfitting to some extent.
Random Forest Feature selection algorithm consist of decision tress. Feature sets are divided among these tress. Each node of the tree consist of the single feature. One tree will not have all the feature as its node thus avoiding the problem of overfitting. Each tree consist of the sequence of yes-no questions which is based on a combination of features used by the tree. Each tree has its own set of observations which are quite different from the other trees. The importance of a feature or its weight depends upon the impurity value of the feature. This impurity value is calculated using the gini index and the entropy.
The Algorithms used for Implementation
1) Random Forest
2) Naïve Bayes
3) ADABoost
4) Logistic regression
5) Gradient Boosting
Random Forest Algorithm
Random Forest Algorithm is itself an ensemble algorithm which consist of various decision trees. This decision trees works together to generate a result.
A decision tree consists of leaf node. There can be many leaf nodes in a decision tree. A decision is made at each leaf node and based on these decisions a conclusion is reached by the decision tree.

Fig 3-4 (Yiu, 2019)
Fig 3-2 shows an example of a decision tree. As we can see from the figure there are two leaf nodes present. That means two decision are made by the algorithm to reach a conclusion. At leaf node one the first decision is made, i.e whether the given data is red or blue. If the numbers are red then the second decision is made, whether the numbers are underlined or not.
When multiple decision trees like Fig 3-2 are stacked together to generate a result, then it is termed as random forest classifier. In random forest classifier the mistake done by one algorithm may not be done by the other using this principle, analysing the result of every tree a final result is obtained.

Random forest algorithm Fig 3-5 (Yiu, 2019)
Gradient Boosting
(Singh, 2018)
In boosting multiple trees are used for generating output. Each tree utilizes the output of the previous one and enhances its own output based on the error produced by the previous tree. AdaBoosting algorithm is quite similar to gradient boosting and gradient boosting can easily be explained using ADaBoosting. In ADABoost algorithm each decision trees consist of equal weight during the beginning of the training phase. After the first tree produces the results, based on the results of the first tree the other trees weights are changed. The weights of the observations are increased which have been difficult to classify while the weights of the particular observations are reduced which are easily classified. The next tree is therefore grown on this weighted data. Here the idea is simple which is to improve on the errors of the first or previous tree. Our new model will be the result of the sum of previous models in this case (tree1 +tree2). Again, the same steps takes place, the classification report of previous trees are summed up and a new tree is generated. The process is repeated for a specified number of iterations which is the number of trees specified by the developer in code. This subsequent way of summing up the previous classification report of trees and building on them leads towards a better classification accuracy. As a result of which the final model build will be a sum of all the previous models.
Gradient boosting is not very different from ADABoost as it also works in iteration of generating trees. Each new tree builds on the shortcomings of previous models. Increasing the weight of weak classified observation and reducing the weight of strongly classified observations. The huge difference here is the method to identify these weak learners.
Gradient boosting uses loss function (y=ax+b+e , e needs a special mention as it is the error term) to identify these weak learners. The loss function is nothing but a measure of the models coefficient ability to fit the underlying data. Logical interpretation of the loss function will depend on what we are trying to maximize. For example, if we attempt to forecast home prices by regression, the loss function will be based on the error between real and expected house prices.
Naive Bayes
(Gandhi, 2018)
It is a classification technique based on Bayes’ Theorem with an assumption of independence among predictors. In simple terms it can be said that the Naive Bayes classifier works on the principle that the presence and the output of a classifier in a class can be independent of the other classifiers.
The principle of naive Bayes is that, we can prediction the occurring of A, given the condition that B has already occurred. Here ‘B’ is the evidence and ‘A’ is the hypothesis.
Bayes Theorem:
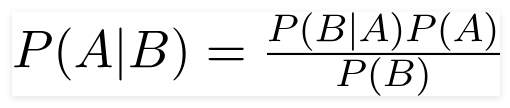
P(B|A) = Represents the posterior Probability. It shows the conditional probability of event A based on the idea that event B has already occurred.
P(A) and P(B): Represents the probability of A and B irrespective of one-another.
P(B|A) : Represents the posterior Probability. It shows the conditional probability of event B based on the idea that event A has already occurred.
The assumption made by bayes theorem is that each and every feature given in dataset is independent of one another. Hence the algorithm is termed as Naïve.
Example:
Consider an example of playing golf to understand Naive Byes. Consider the problem of playing golf. The dataset is represented as below.

Fig 3-6 Example Dataset (Gandhi, 2018)
Fig 3-6 consist of a set of features. The problem is to decide whether to go out and play golf based on the features available. Here each feature can individually capable of deciding the outcome. For example, if the Outlook is rainy, definitely we cannot go out to play golf. Hence the feature outlook is capable alone to decide the outcome.
Bayes theorem can be written as:
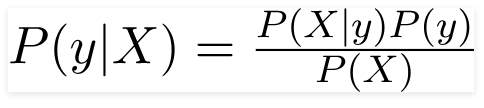
The variable ‘y’ is the output variable representing the output, whether to play golf or not. ‘X’ represents the parameter.
X can be given as,

By substituting X in bayes theorem the final equation formed will be:
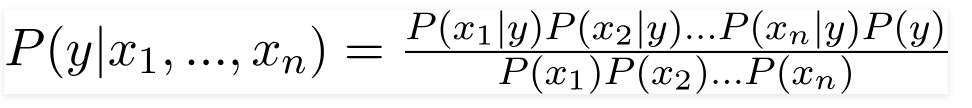

ADABoost
(Starmer, 20019)
ADABoost algorithm is quite has a similarity with random forest algorithm. The random forest algorithm consist of a number of tress and the final result obtained by a random forest is the average of all tress. ADABoost algorithm also consist of a number of trees to make classification, except here the number of tress has only two node and one decision making criteria. Such trees are termed as stump. Hence, we can say that ADABoost algorithm consist of stumps rather than trees. Each Stump inside the ADABoost algorithm has different weight associated to them, that is the result of each stump are not considered as equal. The selection or the ordering of features in these stumps are done on basis of their true positive and false positive rate.
The amount of say in final classification of a stump determined by its Total error.

The total error is just a value obtained by average of False positive and True positive calculated by a stump.

Fig 3-7 ADABoost stumps (Starmer, 20019)
Above shown is an example of ADABoost with multiple stumps grouped together. Bigger stumps has a higher say in classification than smaller stumps.
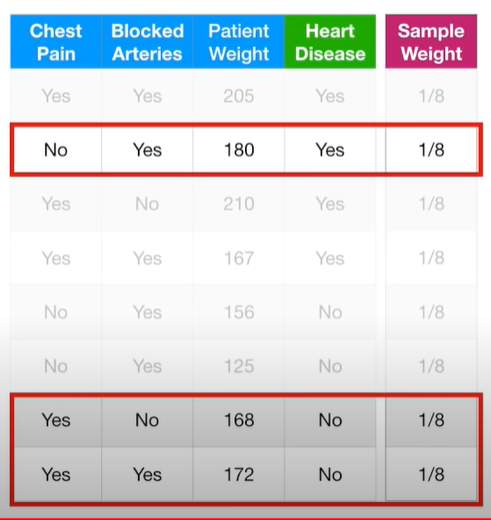
Fig 3-8 Example for predicting Hard disease (Starmer, 20019)
Consider the above example where there are multiple features mentioned, a stump will be created using each feature.
For
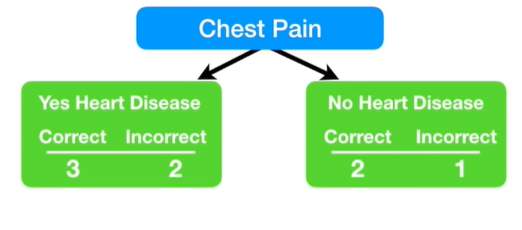
Fig 3-9 Stump(Starmer, 20019)
Algorithms
We should look at the situation for the last classifier.
The attribute D_t is a vector of loads, with one capacity for each preparation model in the preparation set. 'I' is the training model number. This situation tells you the finest way to restore the weight for the preparing model.
Logistic Regression
Logistic regression is very much like linear regression. In linear regression a threshold is used for making classification. While in case of logistic regression a sigmoidal function is used. Logistic regression is used when the output required is categorical data.
For example:
1) Predicting whether the email is spam or not.
2) Whether the software has malware or not.
Consider the example where we need to identify whether the given software is malicious or not. In case of linear regression, a threshold will be set based on the features used and training data. The huge problem with linear regression is the outliers and negative value of the threshold. The presence of an outlier can drastically change the complete equation of best-fit line and the threshold line which we will get will not be perfect. To deal with such kind of problems a sigmoidal function is used in case of logistic regression.
The sigmoidal function converts the regular output value by 0 and 1.
The output values here will be 0 and 1 in case of logistic regression.
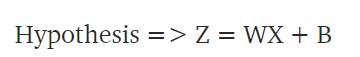
Here Z is the Output (W) is the weight or the intercept and (X) are training data points used. (B) is the error term.
Fig 3-10 Sigmoid Activation Function (Swaminathan, 2018)
Here if ‘z’ goes towards [positive infinity ‘y’ prediction will be 1 and if ‘z’ goes towards negative infinity ‘y’ prediction will be 0.
Chapter 4: System Design
Training Phase Detection Phase

fig 4-1 System Architecture
Above given is the architecture of the System developed. During the training phase, a classifier is generated with the help of a data set, which consists of malware and legitimate software. This collection of data is passed on to the feature extractor. The job of the feature extractor is to extract all features from these softwares. This feature extracting job depends upon the features we have selected for our feature’s extractor. Now, these extracted features act as input and are passed to the classifier generator. The classifier generator generates a classifier in return, with the help of this newly generated input and some machine learning algorithm which I have selected. Now for the detection phase, whenever a software is selected, feature extractor extracts the required features of this currently chosen software. These extracted features are then transmitted to the classifier. On the basis of the knowledge gained by the classifier from its previous training, it makes the decision whether the software is legitimate or not. It then displays a pop-up to the user based on its results.
|
Library |
Description |
|
NumPy |
Used for performing operation with arrays. |
|
Scikit-Learn |
A python library consists of learning algorithms like supervised learning and unsupervised learning. |
|
Matplotlib |
It is a plotting library for the Python programming language. |
|
Pandas |
Python library for analyzing and manipulating data. |
|
WX |
To create programs with a robust, highly functional graphical user interface. |
|
Seaborn |
The data visualization library is an extension to matplotlib. A top-class user-interface for drawing informative and statistical graphs. |
Table 4-6 Python Libraries and its Description
Pandas
( McIntire, et al., 2020) Pandas is an open source python library. It can be used to explore a CSV dataset.
- It can be used for data cleaning like removing the missing values from the table.
- Visualization of data or the distribution of data can be done with the help of this library.
- After cleaning and transforming the data it stores it back to its original source like CSV or any other database specified.
Numpy
(Anon., n.d.)
Numpy an open source library in python. Its basic or soul concept in python is to deal with arrays.
It also contains functions that can work with domains like linear algebra, Fourier transform, and matrices.
NumPy stands for Numerical Python.
Sklearn
Sklearn or scikit learn is an open source python library that contains a large amount of supervised and unsupervised machine learning algorithms.
The functionality that scikit-learn provides include:
- Regression : Includes Linear as well as logistic regression.
- Classification: K-nearest Neighbours.
- Clustering: includes K-Means and K-Means++
- Model selection
- Pre-processing: includes Min-Max Normalization
Matplotlib
(Hunter, 2020) Data Visualization in python can be done with the help of Matplotlib. It is for creating two-dimensional graphs in ML from data set available in form of arrays. It makes use of GUI tool PyQt in python for creating user friendly graphs.
wxPython
(Anon., 2020) A combination of wxWidgets and python library is wxPython. It is quite similar to Tkinter or also can be considered as an alternative to Tkinter. It is also a wrapper class for wxWidgets. User Interfaces or front-end design in python can be done with the help of wxPython.
The system uses different Machine Learning algorithms to predict the detection of malware via machine learning models. Each algorithm follows different approach to reach the final prediction. Python is chosen for this application. Python is generally the go to language for any developer working with machine learning with a coding background. Python is widely regarded as the language of choice of computer models of education and learning. Python has some special libraries specially designed for dealing with machine learning problems. Some of them list a variety of frames and modules and plugins such as NumPy where Python's tasks are easier to carry out. Therefore, for these applicable uses, the meaning of the programming language itself is also relevant. The scikit module "Machine Learning in Python" provides a further resource that can guide professionals to Python (Pedregosa, et al., 2011).
Chapter 5: Implementation
This section discusses the complete implementation done for the development of the system. It includes all the algorithms carried to build the anti-malware software.
Feature selection
Steps used for feature selection:
- Organizing the dataset of features
- Training RF classifier
- Identifying or obtaining the important features to be used based on the impurity value.
- Generating a new dataset of features based on the results formed by the impurity value of decision trees.
- Training the newly formed classifier.
The Algorithms used for Implementation
1) Random Forest
2) Naive Bayes
3) ADABoost
4) Gradient Boosting
The above-mentioned algorithms are ensemble i.e. hybrid machine learning algorithms.
Initially a set of 57 PE features are fed to the feature extracting algorithm. After application of Random Forest classifier for feature selection a set of 14 feature is obtained:
The Set of features obtained are:
- feature DllCharacteristics (0.141259)
- feature Characteristics (0.136174)
- feature Machine (0.102237)
- feature SectionsMaxEntropy (0.093866)
- feature MajorSubsystemVersion (0.076185)
- feature ResourcesMinEntropy (0.054568)
- feature ResourcesMaxEntropy (0.048843)
- feature ImageBase (0.047034)
- feature VersionInformationSize (0.046712)
- feature SizeOfOptionalHeader (0.041392)
- feature SectionsMeanEntropy (0.025279)
- feature Subsystem (0.022657)
- feature MajorOperatingSystemVersion (0.019587)
- feature CheckSum (0.019544)
These 14 features are used for training the model with different hybrid algorithms mentioned in methodology section.
Implementing Random Forest
Here the input .exe file is fed to the algorithm the algorithm uses the set of 14 features and generates the number of tress as mentioned in the code. Each tree makes its own prediction and the final prediction is the average of all the prediction made by each tree in the forest.
Implementing ADABoost
The algorithm is fed with the input data (.exe file). Based on these 14 set of features, the algorithm creates several stumps as provided in the code. All these stumps make its own calculation in making the classification, that is deciding whether the given .exe file is malware or not. The stump with highest say has the more weight in the final result which is the average of all the results.

Implementing Naïve Bayes
Similarly, training data is used for training for Naïve Bayes. During the training phase, the Naïve Bayes analyses all the given predictors and identifies their weights for a particular outcome to occur. Each predictor is independent of one another here. So, the presence of one strong feature may directly lead to the outcome that the software is malicious.
Implementing the Gradient Boosting
The three algorithms ADABoost, XGBoost, and Random Forest have been used in the stacking classifier as mentioned in the Methodology section. Here the prediction is made by combing the output of all these algorithms. So, the error generated by one can be overcome by another. Here ADABoost is the meta classifier, which means it makes the final prediction based on the output of XGBoost and RF.
References
McIntire, G., Martin, B. & Washington, L., 2020. Python Pandas Tutorial: A Complete Introduction for Beginners. [Online] Available at: https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/
Anon., 2019. PE File. [Online] Available at: https://resources.infosecinstitute.com/2-malware-researchers-handbook-demystifying-pe-file/#gref
Anon., 2019. spyware. [Online] Available at: https://searchsecurity.techtarget.com/definition/spyware
Anon., 2020. Adware. [Online] Available at: https://www.malwarebytes.com/adware/
Anon., 2020. Lucy: A File Encryption Android Malware that for Ransomware Operations. [Online] Available at: https://go.newsfusion.com//security/item/1638195
Anon., 2020. Microsoft Warns of Malware Hidden in Pirated Film Files. [Online] Available at: https://go.newsfusion.com//security/item/1638307
Anon., 2020. ROOTKIT: WHAT IS A ROOTKIT?. [Online] Available at: https://www.veracode.com/security/rootkit
Anon., 2020. Schneier on Security. [Online] Available at: https://go.newsfusion.com//security/item/1641641
Anon., 2020. Welcome to wxPython!. [Online] Available at: https://wxpython.org/
Anon., 2020. What is a Computer Virus and its Types. [Online] Available at: https://antivirus.comodo.com/blog/computer-safety/what-is-virus-and-its-definition/
Anon., n.d. CYBER EDU. [Online] Available at: https://www.forcepoint.com/cyber-edu/malware [Accessed 2020].
Anon., n.d. Malware. [Online] Available at: https://us.norton.com/internetsecurity-malware-what-is-a-trojan.html
Anon., n.d. malware (malicious software). [Online] Available at: https://searchsecurity.techtarget.com/definition/malware
Anon., n.d. NumPy. [Online] Available at: https://numpy.org/
Anon., n.d. NumPy Introduction. [Online] Available at: https://www.w3schools.com/python/numpy_intro.asp
Anon., n.d. Pandas Basics. [Online] Available at: https://www.learnpython.org/en/Pandas_Basics
Anon., n.d. scikit-learn. [Online] Available at: https://scikit-learn.org/stable/
Anon., n.d. What is a computer worm, and how does it work?. [Online] Available at: https://us.norton.com/internetsecurity-malware-what-is-a-computer-worm.html
C, E., 2018. Are Antivirus Programs Effective. [Online] Available at: https://www.safetydetectives.com/blog/are-antivirus-programs-effective/ [Accessed 2020].
Collins, M., Schapire, R. E. & Singer, Y., 2002. Logistic Regression, AdaBoost and Bregman Distances. IEEE.
Desarda, A., 2019. Understanding AdaBoost.
Dutta, A., 2019. Stacking in Machine Learning. [Online] Available at: https://www.geeksforgeeks.org/stacking-in-machine-learning/
Fruhlinger, J., 2018. Ransomware explained: How it works and how to remove it. [Online] Available at: https://www.csoonline.com/article/3236183/what-is-ransomware-how-it-works-and-how-to-remove-it.html
Gandhi, R., 2018. Naive Bayes Classifier. [Online] Available at: https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c
G., G., Stiborek, M. & Zunino, J., 2014. An empirical comparison of botnet detection methods.” computers & security. IEEE.
Gupta, A., 2019. ML | Extra Tree Classifier for Feature Selection. [Online] Available at: https://www.geeksforgeeks.org/ml-extra-tree-classifier-for-feature-selection/ [Accessed 2020].
Huilgol, P., 2019. Accuracy vs. F1-Score. [Online] Available at: https://medium.com/analytics-vidhya/accuracy-vs-f1-score-6258237beca2
Hunter, J., 2020. matplotlib. [Online] Available at: https://matplotlib.org/
Loi, H. & Olmsted, A., 2017. Low-cost Detection of Backdoor Malware. IEEE.
Morde, V., 2019. XGBoost Algorithm: Long May She Reign!. [Online]
Available at: https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d
Muhamad, I. M. & Rahardjo, B., 2019. Malware Detection Using Honeypot and Machine Learning. IEEE.
Narkhede, S., 2018. Understanding AUC - ROC Curve. [Online]
Available at: https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5
Pedregosa, F. et al., 2011. Scikit-learn: Machine learning in Python. IEEE.
Pirscoveanu, R. S. et al., 2015. Analysis of Malware Behavior: Type Classification using Machine Learning. IEEE.
Shmueli, B., 2019. Multi-Class Metrics Made Simple, Part II: the F1-score. [Online] Available at: https://towardsdatascience.com/multi-class-metrics-made-simple-part-ii-the-f1-score-ebe8b2c2ca1
Shung, K. P., n.d. Accuracy, Precision, Recall or F1?. [Online] Available at: https://towardsdatascience.com/accuracy-precision-recall-or-f1-331fb37c5cb9
Singh, H., 2018. Understanding Gradient Boosting Machines. [Online]
Available at: https://towardsdatascience.com/understanding-gradient-boosting-machines-9be756fe76ab
Srinidhi, S., 2019. Backward Elimination for Feature Selection in Machine Learning. [Online] Available at: https://towardsdatascience.com/backward-elimination-for-feature-selection-in-machine-learning-c6a3a8f8cef4
Starmer, J., 20019. AdaBoost, Clearly Explained. [Online] Available at: https://statquest.org/
Wang , T.-Y., Wu, C.-H. & Hsieh , C.-C., 2009. Detecting Unknown Malicious Executables Using Portable Executable Headers. IEEE.
Wu, L., Ping, R., Ke, L. & Hai-xin, D., 2011. Behavior-based Malware Analysis and Detection. IEEE.
Yeo, M. et al., 2018. Flow-based Malware Detection Using Convolutional Neural Network. IEEE.
Yiu, T., 2019. Understanding Random Forest. [Online] Available at: https://towardsdatascience.com/understanding-random-forest-58381e0602d2
ZAHARIA, A., 2020. 300+ Terrifying Cybercrime and Cybersecurity Statistics & Trends [2020] EDITION]. [Online] Available at: https://www.comparitech.com/vpn/cybersecurity-cyber-crime-statistics-facts-trends/
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: