Mobile Crowdsensing Privacy Issues
Info: 22852 words (91 pages) Dissertation
Published: 10th Dec 2019
mobile crowdsensing PRIVACY ISSUES
Table of Contents
2.2 Community Sensing Architecture
2.2.1 Client-Server Architecture
2.2.2 Trusted Third-Party Architecture
2.2.3 Peer-to-Peer (P2P) Architecture
2.4 Location-based MCS (LBMCS)
2.5.5 Cryptographic Hash Function
2.5.8 Private Information Retrieval (PIR)
3.1.2 Non-functional Requirements
3.3.1 Mobile Application Requirements
3.3.2 Database Server Requirements
3.3.3 Crowdsensing Data Generator (CDG) Requirements
4.2.1 Motivation to use Android
4.3.1 Motivation to use Oracle Database
4.3.3 Entity-Relationship Diagram (ERD)
5.1 Mobile Application Implementation
5.1.3 Implementation of the different modules
5.2 Database Server Implementation
5.2.3 Implementation of the different modules
5.3 Crowdsensing Data Generator Implementation
5.3.2 Implementation of the different modules
List of Figures
Figure 1: Client-server architecture
Figure 2: Trusted Third-party (TTP) Architecture
Figure 3: P2P Architecture whereby vehicles are communicating with each other.
Figure 5: Overview of the Big Data Analytics workflow (Assunção, et al., 2015)
Figure 9: 3-Diverse dataset (Machanavajjhala, et al., 2006).
Figure 10: Original dataset (Li, et al., 2007)
Figure 11: 3-diverse version of original dataset (Li, et al., 2007)
Figure 14: Two-server Private Information Retrieval
Figure 16: The Android software stack (Android, n.d.)
Figure 17: Mobile Application Top-down design
Figure 18: Service Request screen
Figure 19: Service Reply screen
Figure 20: Data Collection screen
Figure 21: Database server Top-down design
Figure 22: ERD for privacy schema
Figure 23: ERD for precision schema
Figure 27: Android virtual device configurations
Figure 28: Service request screen Figure 29: AutoCompleteTextViews suggesting values
Figure 32: StrictPrivacy service response Figure 33: Data collection screen
Figure 36: Android Lint results
Figure 37: Issue #3 where AndroidManifest.xml has been modified to set the allowBackup flag to false
Figure 39: Issue #4 after correction whereby variable maxDummyCount is declared locally
Figure 40: Issue #5 before correction where variable doc is redundant in class AsyncGMapDirection
Figure 41: Issue #5 after correction where variable doc has been removed
Figure 42: Issue #7 before correction where for loop is used in class AsyncPull
Figure 43: Issue #7 after correction where foreach is used
Figure 44: Issue #8 before correction where Arrays.asList() is used in class AsyncJourney
Figure 45: Issue #8 after correction where Collections.singletonList() is used instead
Figure 46: Issue #8 before corrction where Arrays.asList() is used in class GlobalVariables
Figure 47: Issue #8 after correction where Collections.singletonList() is used instead
Figure 48: Results for test case #1 and #2
Figure 49: Results for test case #3 and #4
Figure 50: Results for test case #6
Figure 51: Results for test case #5 and #7
Figure 52: Result for test case #8 and #9
Figure 53: Results for test case #10
List of Tables
Table 2: Functional requirements
Table 3: Non-functional requirements
Table 4: Mobile application modules’ description
Table 5: Static testing solutions
Table 7: Evaluation of requirements
Table 8: StrictPrivacy mode privacy evaluation
List of Abbreviations
| CSP | Cloud Service Provider |
| MCS | Mobile Crowdsensing |
| LBMCS | Location-based Mobile Crowdsensing |
| IoT | Internet of Things |
| TV | Television |
| GPS | Global Positioning System |
| PIR | Private Information Retrieval |
| P2P | Peer-to-Peer |
| TTP | Trusted Third Party |
| IP | Internet Protocol |
Executive Summary
Being versatile, highly scalable, and of low cost, mobile crowdsensing (MCS) has revolutionised the way data is collected, making static sensing infrastructures obsolete in many areas. MCS has enabled a broad range of applications including traffic planning, urban dynamics planning, environment monitoring, and public safety. Mobile devices, being more and more sophisticated and in greater numbers, have enabled big data analytics to produce more precise results with data provided by MCS. However, this new sensing paradigm is far from being perfect when it concerns the privacy of data providers.
Privacy preservation is very important in MCS applications and even more in location-based MCS because, by utilising GPS sensor readings, sensitive data about the day-to-day commutes of users may be revealed. Since decades, researchers have been deriving ways to preserve privacy while enabling users to share private information hassle-free. However, each solution has its own characteristics and requirements, and is applicable to certain specific scenarios. This project attempts to preserve privacy in a specific context whereby a lightweight and inexpensive solution is required for a location-based MCS application.
1 Introduction
This chapter introduces the area of big data analytics, presents the problem under investigation along with the scope, aims and objectives, and the structure of the project.
Smart cities, smart homes, smart grids, smart agriculture, and intelligent transportation are some of the innumerable examples that show to what extent Internet of Things (IoT) has eased our life. Phones, watches, TVs, CCTV cameras, and even cars have embedded sensors such as accelerometer, digital compass, GPS, gyroscope, microphone, and camera representing a new type of geographically distributed sensor network connected to the internet (Talasila, et al., 2015). According to estimates, there are currently about 15 to 20 billion IoT devices and this figure will increase to 28 billion by 2021 (Ericsson, 2016). The devices altogether are generating massive volumes of data, reportedly amounting to zettabytes, which characterises Big Data.
Big data refers to datasets of collected data which are not solely large in volumes, but which are high in variety, velocity, veracity and value. Volume refers to the amount of data. Variety is about having a broad range of data types. Data velocity refers to the speed of data processing, for instance, data captured in real-time or periodically (Laney, 2001). Veracity refers to the reliability of the data’s origin whereas value corresponds to the monetary worth a company can gain from that data (Russom, 2011). Big data has proved to be useful in numerous areas such as understanding human behaviour, optimising business processes, studying disease patterns, science and research, weather forecast, financial decision making, and optimising traffic flows in cities. Big data enables more accurate statistics, better analysis and better decisions (Assunção, et al., 2015).
Big data is worthless without analytics. Its potential value is unlocked only when leveraged to drive decision making through analytics. Big data analytics is about using advanced analytic techniques on big data sets. Some of these techniques include Knowledge Discovery in Data (KDD), predictive analytics, text mining, data mining, statistical and quantitative analysis, data visualisation, fact clustering, and artificial intelligence (Davenport & Harris, 2007) (Davenport, et al., 2010) (Davey, et al., 2012). The analytic techniques used usually differ from one organisation to another depending on the context and analytic requirements of the organisation. The aim is to be able to draw conclusions by examining collected data for better decision making and actions (Elgendy & Elragal, 2014).
Mobile crowdsensing (MCS) is a fast-growing sensing model which takes advantage of IoT and the emergence of smart phones, tablets, and wearable technologies. It makes use of these mobile devices to collect big data which is then aggregated and processed using big data analytics to provide services and results of new dimensions. This paradigm has pushed analytic possibilities even further given the broad range of applications including environment monitoring, traffic planning, weather monitoring, price-dispersion monitoring and public safety (R & K, 2016). The knowledge acquired can not only enhance people’s day-to-day life but also help utility providers, healthcare providers and the social sphere (Gilbert, et al., 2010).
1.1 Problem Statement
Despite its huge potential, MCS applications have been scarcely used by the public in general due to the related security concerns. Since all collected data are aggregated and stored in a server hosted away from the data providers (end users), the latter fear inappropriate use or disclosure of their personal data. This discourages end users from contributing data and hence preventing the proper functioning of MCS by not being able to collect big data (Mokbel, 2007).
In sensitive areas typically, end users wish to be able to provide and retrieve information while being anonymous since, often, MCS applications need to deal with sensitive data which users wish to keep secret. Examples of sensitive data include symptoms and diseases of end users for a disease stage prediction application, location of end users for a road traffic forecast application, and votes of end users in an electronic voting system. All these mentioned applications need to store an identifier for end users in order to track the latter’s participation. Also, anonymous participants may send incorrect, low-quality or even fake data (Guo, et al., 2015).
Even worse, hiding the identity of users is not enough. For instance, consider a MCS application which collects users’ locations for processing. An attacker may infer the identity of the user by investigating on their location details given that the user may have transmitted the location of his house or office. Moreover, by observing the movement of users, an attacker may get to know confidential information about the users. For example, the religious preferences of a user can be revealed if the user visits a temple or the health issues of the user may be known if the latter visits a specialised hospital (Labrinidis & Jagadish, 2012). González, et al. have shown that there is a close correlation between people’s movement patterns and their identities. Also, users’ movements can be predicted by analysing their past movements (González, et al., 2008).
Undeniably, compromised privacy can be very harmful to individuals. A privacy breach can also affect service providers. Apart from impacting its reputation, the service provider may face significant compliance liabilities owing to the presence of laws protecting users’ confidential data such as the Budapest Convention (Council of Europe, 2001) or ,locally, the Computer Misuse and Cybercrime Act 2003 (Anon., 2003).
1.2 Aim and Objectives
The aim of this research work is to study the data collection, aggregation and analytics of data provided by crowdsensing applications. Existing mechanisms used to provide privacy of data is to be investigated so as to identify and propose an efficient privacy preserving method for MCS data. This research work has been done in the context of a mobile crowdsensing application which allows users to push their location information as they travel. Such location information provided by commuting users, allows the system to capture average speed of flow of traffic along different routes which can be used to dynamically inform the population at large about the road congestion levels. However, it is clear that participating users would also wish to maintain the privacy about their journeys. In this project, user identity related data such as email address and location data is to be kept private to ensure that they are not used maliciously. Network-based identifiers such as IP addresses are not discussed in this project since they have already been addressed by mechanisms such as Onion Routing (Goldschlag, et al., 1999) and Crowds (Reiter & Rubin, 1998).
To achieve this aim, the following set of objectives has been defined:
- Develop a mobile application to perform crowdsensing
The first objective is to develop an Android mobile application which will perform crowdsensing by sending collected data to a centralised server. Since the data being collected is the location of the device, the application should allow manual input for simulation purposes.
- Implement the service request feature in the mobile application
The application should also allow a user to request road traffic details from a given source location to a destination. Once the server responds to the request, the application should present the information received on a map by using Google Maps and Google Directions API.
Only two routes are to be considered for this project. The email address used to register to Google Play Store is to be used as an identifier for users.
- Set up a database server and collect data for data aggregation
This objective here is to set up an Oracle database locally on a computer and create a JDBC connection with the mobile application.
The client-server connection is to be done internally since having a database server publicly available on the internet may invoke costs. Data is to be collected from mobile devices and stored in a database table ready to be processed.
Since, it is beyond the scope of this project to deploy the mobile application on a large number of smart phones of users travelling at different points in time, a program has been designed to simulate and generate input for a number of users randomly. This will enable proper testing of the data analytics & privacy preserving mechanisms proposed in this dissertation.
- Implement data analytics
Since large amounts of data will be collected, the MapReduce programming model is to be used for processing data. Simple analytics is to be performed on the data to calculate average speed of traffic flow for the different road stretches.
- Design and implement privacy preserving mechanisms
Several privacy-preserving mechanisms are to be implemented in order to suitably preserve the privacy of users.
- Evaluate the efficiency of the proposed security mechanism
The objective is to show how far users’ privacy has been kept.
1.3 Research Methodology
This research project is of an applied nature whereby a problem has been identified in a particular type of system, namely, MCS. A quantitative methodology will be used which involves the design and implementation of proposed security techniques for privacy preserving of crowdsensing big data.
1.4 Thesis Structure
This section describes how the different chapters of this report have been structured.
| Chapter | Description | |
| 1 | Introduction | Introduces report, defines problem statement, and states the aims and objectives of the project. |
| 2 | Background Study | Explores the field of MCS and the existing privacy-preserving mechanisms. |
| 3 | Analysis | The requirements of the project are defined and the alternative solutions along with the proposed solution are described. |
| 4 | Design & System Modelling | The proposed system is designed using Unified Modelling Language. |
| 5 | Implementation | An in-depth description of the proposed system is presented along with screenshots of codes and screens. |
| 6 | Testing | Static and dynamic testing of the implemented system is performed. The test cases are described and the obtained results are shown. |
| 7 | Evaluation | The proposed system is evaluated against each of the requirements set in the Analysis section. |
| 8 | Conclusion & Future Works | Concludes report with an overview on the accomplishments and possible future works which could not be realised due to time constraint and resource limitation. |
2 Background Study
This chapter explores the field of Mobile Crowdsensing and discusses on the existing privacy-preserving mechanisms.
2.1 Sensing Applications
Sensing applications, also known as remote sensing applications, are software applications used to process data that has been collected by sensors located in a remote location. Sensing applications can be classified into two categories, namely, personal sensing and community sensing as described below.
2.1.1 Personal Sensing
Personal sensing applications are meant for one individual and do not involve aggregation of data from several individuals. An example can be the monitoring of the number of kilometres ran for personal record-keeping or healthcare reasons (Ganti, et al., 2011).
2.1.2 Community Sensing
Contrary to personal sensing, community sensing involves a large number of individuals and comprises of data aggregation. Community sensing can be further categorised into participatory sensing and opportunistic sensing. Participatory sensing requires the active data contribution of individuals. One example can be individuals providing pictures of the road traffic at their current locations. On the other hand, opportunistic sensing requires minimal user involvement and is more autonomous. Data is usually collected by a smart device and automatically sent to a centralised server (Ganti, et al., 2011).
MCS consists of community sensing and can be participatory, opportunistic or a combination of both (Ganti, et al., 2011).
2.2 Community Sensing Architecture
There are three main architectures which are usually used for community sensing applications, namely, the client-server architecture, the trusted third party architecture, and the peer-to-peer architecture.
2.2.1 Client-Server Architecture
The client-server architecture consists of only two parties. The client is the device sensing data and requesting services (left side of Figure 1). The server is the system which collects data from numerous clients, perform processing, and responds to clients’ requests (right side of Figure 1).
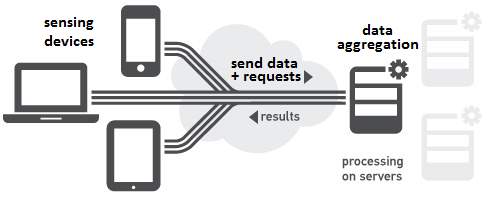
Figure 1: Client-server architecture
2.2.2 Trusted Third-Party Architecture
The trusted third-party (TTP) architecture is the most used architecture when data is being collected from individuals. This 3-tier architecture is used to preserve user privacy by having a middleware, known as the TTP anonymity server, responsible to make users unidentifiable.
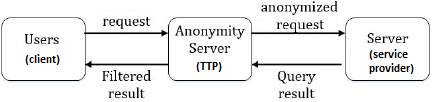
Figure 2: Trusted Third-party (TTP) Architecture
In this architecture, clients do not communicate directly with the service provider server, instead, sensed data and requests are sent to the TTP anonymity server where data anonymization (see definition in section 0) and data perturbation (section 2.5.2) are performed. Then the TTP anonymity server sends anonymised requests to the service provider server. In this way, the service provider is not able to identify users. Query results from the service provider are also directed to the TTP anonymity server for the filtering of noise data added by the anonymity server during data perturbation. Also, this prevents the service provider from having the IP address of the users and ultimately be able to trace users.
The TTP architecture is the costliest one among the architectures being discussed since it involves the fee of a permanent third-party.
2.2.3 Peer-to-Peer (P2P) Architecture
In the P2P architecture, sensing devices are inter-connected and share resources among themselves. There is no centralised server (at the service provider) unlike the previous architectures. Storage and computational functions are performed on the devices. An example of a sensing application using P2P architecture is vehicular application used to collect traffic information from all surrounding vehicles and determining the best route. The main disadvantage is that there is no service when there are no peers nearby.
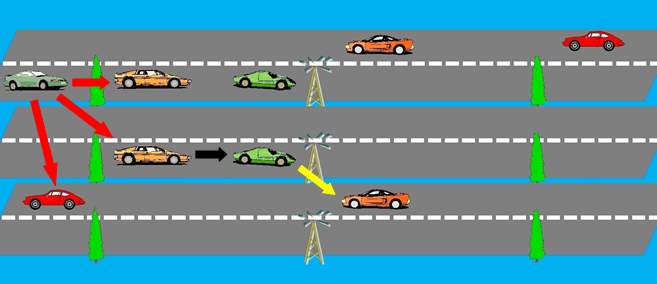
Figure 3: P2P Architecture whereby vehicles are communicating with each other.
2.3 Mobile Crowdsensing (MCS)
MCS is a type of sensing application whereby data is collected from a large number of users via their mobile sensing devices, which is usually their smartphones. The smartphones also allow users to request services. Typically, MCS applications have six main processes as described below (Talasila, et al., 2015).

Figure 4: End users are providing data to for aggregation and participants, who can be end-users, are retrieving processed information.
2.3.1 User Registration
The user registration process is a one-time process enabling data providers to register to the service and give details about themselves for identification. The process is usually performed during the first use of the crowdsensing application. This process can be by-passed when acquiring the application using Play Store (Android) or App Store (iOS) since the latter has its own registration process which is inherited by the downloaded application.
2.3.2 Service Request
This process is performed by the end-user whereby the mobile phone requests a particular service from the service provider (or other mobile phones if using a peer-to-peer architecture). For instance, a request is sent to obtain road traffic details for the different routes available from a source location to a destination.
2.3.3 Data Collection
The mobile phones collect data using embedded sensors such as light sensor, temperature sensor, GPS, digital compass, camera, accelerometer, microphone, and Bluetooth as proximity sensor. The captured data is sent to a centralised server, a TTP or other mobile phones depending on the application architecture for aggregation and processing.
This process may be performed on periodically, continuously, on request, or when a certain condition is met.
2.3.4 Data Aggregation
The system receiving the collected data aggregates the latter with all the other data collected. The centralised approach is used for aggregation whereby all nodes sends information to a single centralised server, TTP, or mobile phone requesting data. Data is usually aggregated in chronological order (Bhatlavande & Phatak, 2015).
2.3.5 Data Processing
The aggregated data is processed using advanced analytic techniques to produce meaningful results and respond to queries (sensing tasks). Traditional analytics of big data constitutes of several phases (see Figure 5 below).
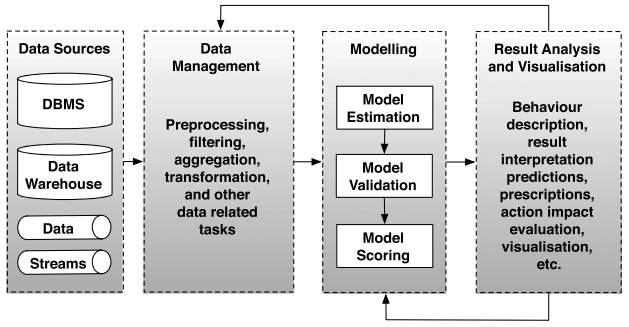
Figure 5: Overview of the Big Data Analytics workflow (Assunção, et al., 2015)
Raw data may require pre-processing tasks such as conversion, filtering and cleaning. Once prepared, the data is used to train a model and estimate parameters. The created model is then validated with original data. After being successfully validated, the model is set up and applied to data as it arrives. The results are interpreted and evaluated. The output is also used to generate new models or adjust existing ones, or are added to pre-processed data (Assunção, et al., 2015).
There are three categories of analytics, namely, descriptive, predictive and prescriptive. Descriptive analytics consists of analysing data from the past in order to find patterns and be able to model or explain past events or behaviour. Predictive analytics aims at predicting the future by analysing trends and patterns using current data and data from the past. Prescriptive analytics help achieving the best outcomes by assessing the business impacts and outcomes of each solution while taking into consideration the business requirements, objectives and constraints (Kaisler, et al., 2013).
Technological advances in storage, computations, and communication have enabled cost-effective collection of the data in a timely manner, which was not feasible decades ago. As a result, big data analytics has rapidly proliferated around the globe and companies are investing huge amount of resources in it (Gandomi & Haider, 2014).
2.3.6 Service Reply
In the case of client-server architecture or TTP architecture, the server sends processed information to clients (mobile devices) depending on requests. This process is not applicable to P2P architecture since processing is performed by the mobile device itself.
2.4 Location-based MCS (LBMCS)
LBMCS is a popular form of MCS whereby the locations of users are collected via their mobile phones. The Global Positioning System (GPS) is usually used to determine exact locations.
A typical example of a LBMCS application is the Traffic Congestion Detector which collects location details of users while they travel to determine the level of congestion of routes by calculating the average time taken.
2.5 Privacy Preservation
Privacy preservation is very important in MCS applications since users will be reluctant to contribute information if they are not persuaded that their privacy is being protected adequately. The privacy concerns include disclosure of the identity of end-users, disclosure of sensitive attributes such as age or location, and disclosure of processed information such lifestyle or sickness evolution of end-users. Attributes can be categorised into explicit identifiers, quasi identifiers and sensitive identifiers. The first clearly identifies an individual – for instance passport number. Quasi identifiers are attributes whose values can potentially identify an individual when taken together. Sensitive identifiers are kept and may be required for data processing (Ras & Li-Shiang, 2009).
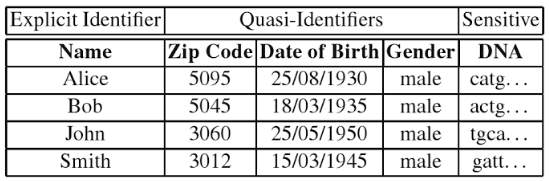
Figure 6: A dataset categorised into explicit identifiers, quasi-identifiers and sensitive identifiers (Ras & Li-Shiang, 2009).
Data disclosure can be by the service provider to other end-users or third parties such as advertising companies, or by administrators and hackers while accessing the database of the service provider. The disclosure can be direct or indirect. An example of direct disclosure is the sharing identification numbers and exact locations of end users. Indirect disclosure may involve guessing the identity of end-users by disclosing certain attributes such as trajectories and destination (Pournajaf, et al., 2015).
A lot of research have been conducted by specialists in order to find ways to preserve privacy. The approaches developed are described below.
2.5.1 Data Anonymization
Data anonymization involves masking or removing information, that may lead to user identification, from captured data. The identifying information may not necessarily be the name or identification number of an individual. It has been found that the combination of some attributes of a population can uniquely identify individuals (Sweeney, 2000). For instance, the ZIP code, date of birth and gender may be enough to identify individuals (Ganti, et al., 2011). Some of the popular approaches for data anonymization include k-anonymity (Sweeney & Samarati, 1998), l-diversity (Machanavajjhala, et al., 2006) and t-closeness (Li, et al., 2007).
2.5.1.1 k-Anonymity
In this approach, explicit identifiers of a dataset are suppressed and quasi-identifiers are generalised until each record is identical to as least k-1 other records. Attribute suppression involves removing the attribute for a particular record or replacing part of the attribute with a special character whereas attribute generalisation includes replacing an attribute with a range of values, for instance replacing age 13 with age 10-15 (Sweeney, 2002). Of course, attribute suppression and attribute generalisation may render the dataset useless. However, the larger the dataset, the fewer number of attributes will need to be removed and the shorter will be the range of values used for generalisation (Emam & Dankar, 2008).
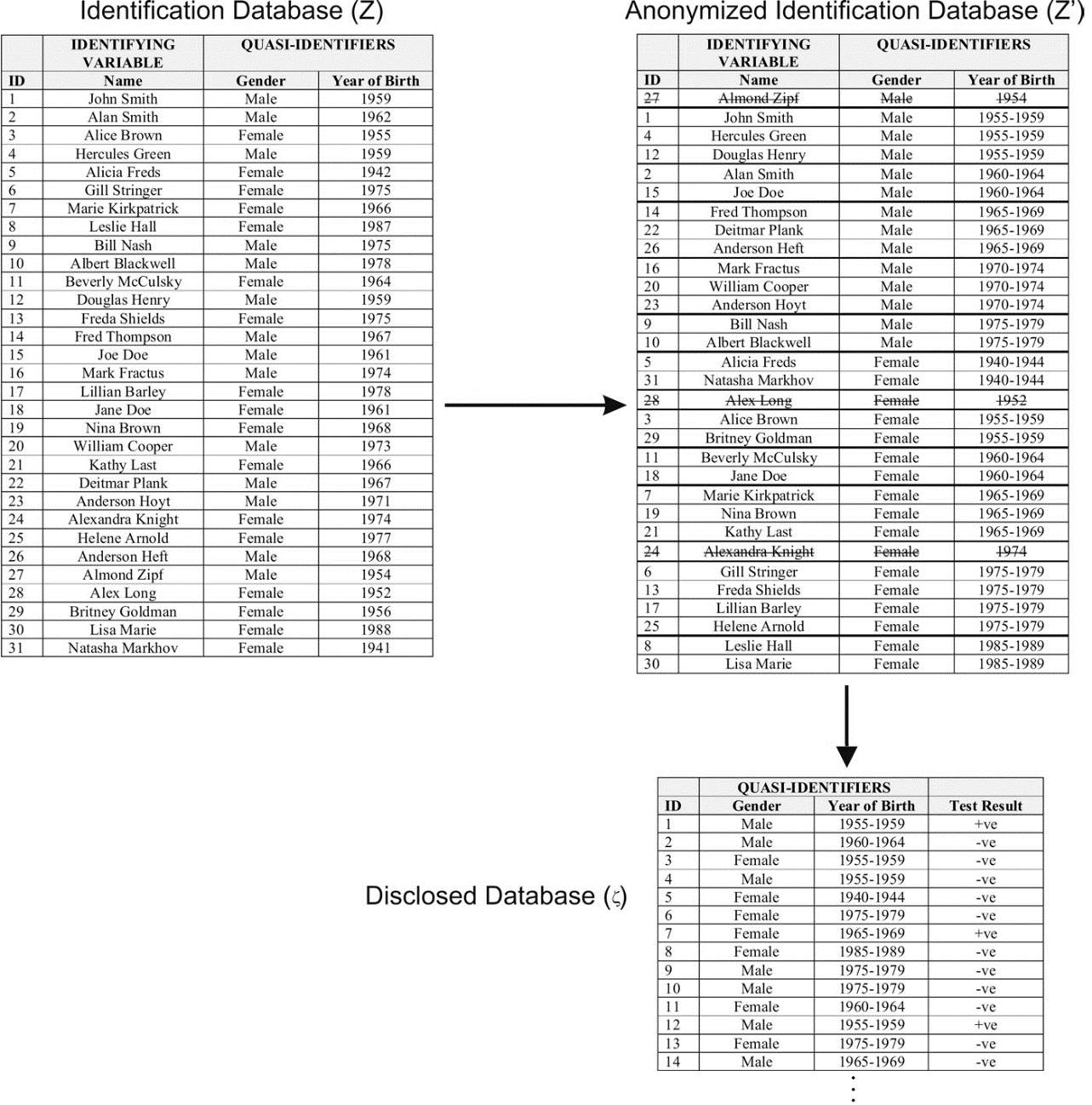
Figure 7: An illustration of k-anonymity where attributes have been suppressed and generalised (Emam & Dankar, 2008).
K-anonymity is a promising approach in dealing with privacy problems. However, optimised k-anonymity are NP-hard and requires intensive computation (K.Deepika, et al., 2014). Machanavajjhala, et al. have shown that a k-anonymous dataset can be compromised through two attacks, namely, homogeneity attack and background knowledge attack. The homogeneity attack is where the dataset has little or no diversity in their sensitive attributes. In such datasets, it is easy to know the sensitive attribute of an individual given that a large range of quasi-identifiers point to a single sensitive attibute.
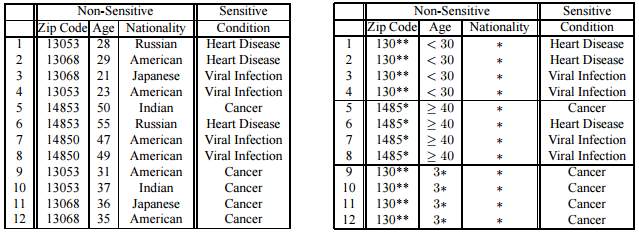
Figure 8: The table on the left shows a raw dataset and the table on the right shows a k-anonymous dataset (Machanavajjhala, et al., 2006).
Figure 8 shows a k-anonymised dataset whereby it is clear that a patient about 35 years old has cancer (Machanavajjhala, et al., 2006). Background knowledge attack is where the attacker knows certain information about an individual and uses his knowledge to find the record pertaining to that target individual (Machanavajjhala, et al., 2006).
2.5.1.2 l-Diversity
l-diversity is derived from the k-anonymity principle. The problem with k-anonymity is that it lacks diversity in sensitive attributes and cannot fight against attackers with some background knowledge. The l-diversity principle addresses these problems and is not prone to homogeneity attack and background knowledge attack since it assumes that the attacker has knowledge of l-1 non-sensitive attributes of a particular individual.
The l-diversity principle states that every set of records whose non-sensitive attribute values have been generalised to have the same values should have at least l different sensitive values where l > 1 such that the l most frequent values have roughly the same frequency. In other words, a table is l-diverse if every quasi-identifier block contains at least l different sensitive values (Machanavajjhala, et al., 2006).
Figure 9: 3-Diverse dataset. below shows a 3-diverse table where each generalised quasi-identifier block (group of records having the same non-sensitive values) have three different sensitive attributes. In this way, even if the attacker knows the zip code and age of an individual, the attacker will not be able to the sensitive attribute of that individual since there are 3 different values.
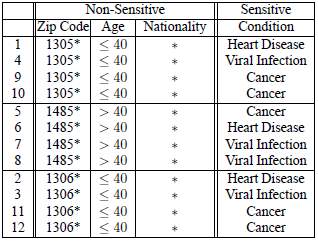
Figure 9: 3-Diverse dataset (Machanavajjhala, et al., 2006).
The problem with l-Diversity is that it is possible for an adversary to gain information about a sensitive attribute if the former has information about the global distribution of that particular attribute (Li, et al., 2007). The following example shows how.
Figure 10 shows a dataset with sensitive attributes Salary and Disease. The figure next to it (Figure 11) shows the dataset anonymised using l-Diversity.
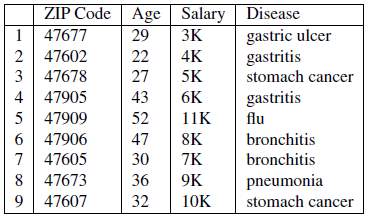
Figure 10: Original dataset (Li, et al., 2007)
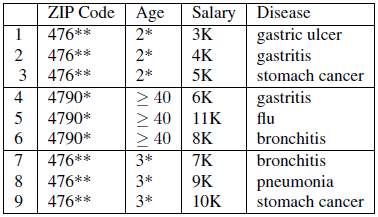
Figure 11: 3-diverse version of original dataset (Li, et al., 2007)
If we know that Bob’s record is among the first three records, then we can infer that Bob’s salary is relatively low since it is in the range 3K to 5K. We can also infer that Bob has some stomach-related problems since all the diseases in the class are related to stomach.
2.5.1.3 t-Closeness
t-closeness is an improvement of l-diversity group-based anonymization. It solves the problem faced by l-diversity by requiring that the distribution of a sensitive attribute in any equivalence class is close to the distribution of the attribute in the overall table. That is, the distance between the distribution of a sensitive attribute in a class and the distribution of the attribute in a whole table should not be more than a threshold t (Li, et al., 2007). This notion restricts the amount of individual-specific information an attacker can learn. The Earth Mover Distance metric (Rubner, et al., 2000) is used to measure distances between values of sensitive attributes (Li, et al., 2007).
Consider the dataset in Figure 11 which is 3-diverse. The list of values for the attribute salary Q={3k,4k,5k,6k,7k,8k,9k,10k,11k}, the list of attribute values for the first class C1={3k,4k,5k}, and the list of attribute values for the second class C2={6k,8k,11k}. The distance is calculated between each class and the list Q. The distance between C1 and Q is 0.375, and the distance between C2 and Q is 0.167.
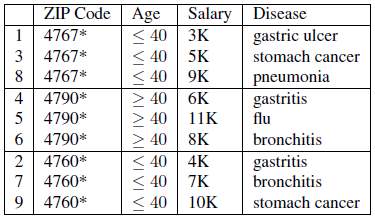
Figure 12: Dataset having 0.167-closeness w.r.t. Salary and 0.278-closeness w.r.t. Disease (Li, et al., 2007)
Figure 12 shows a dataset which is not affected by the similarity attack and is protected against attribute disclosure. The shortcoming of t-closeness is that it does not protect against identity attacks (Li, et al., 2007).
Data anonymization does not fully preserve privacy. There exist data de-anonymization techniques such as linkage attack with auxiliary information which have proven to be successful by correctly identifying members of a Netflix anonymised dataset (Narayanan & Shmatikov, 2008). Moreover, data anonymization is effective for large datasets and should not be used for small ones.
2.5.2 Data Perturbation
Data perturbation is the process of adding noise to data. In the context of MCS, noise is added to preserve privacy while still allowing the desired processing of data with high accuracy. A popular approach for data perturbation is randomised data distortion. This technique adds random noise in order to hide individual data values of different attributes.
It has been found that the noise added can be separated from the perturbed dataset by studying the spectral properties of the data and hence compromise privacy (Kargupta & Datta, 2003).
2.5.3 Differential privacy
Differential privacy (Dwork, 2006) is a privacy-preserving technique which gives a guarantee to a data subject that the latter will not be affected by sharing their data. For instance, let us assume that the analysis of a dataset shows that smoking causes cancer. Jane, who is a smoker, is affected by this analysis since her insurance premiums will rise. Jane will be affected by this analysis whether or not the dataset contains her data given that she is harmed by the finding “smoking causes cancer” and not by her participation (Dwork, 2011).
Differential privacy aims at ensuring that a particular person is only affected by the conclusion of analyses, not by the person’s participation. This can be demonstrated by focusing on the probability that a given output change with the addition or deletion of any record in the dataset. In her research (Dwork, 2011), Cynthia Dwork has shown that the outcome will not significantly change with the addition or deletion of one record provided that the dataset is big. This said, differential privacy provides inaccurate results for small populations and should be used when there already exists a big dataset of information.
2.5.4 Encryption
Encryption may help in preserving the privacy of individuals. Privacy preserving forms of encryption include functional encryption and homomorphic encryption. Functional encryption is a method of public key cryptography which can provide secret keys with limited functionality. That is, it enables users to decrypt only part of the cipher text and hence protecting other information present in the cipher text (Chakraborty & Patra, 2014).
Functional encryption simplifies several existing primitives including Identity-based encryption (IBE) and Attribute-based encryption (ABE) (Pedersen, et al., 2007). In IBE, the user’s identity attributes are used instead of public keys. ABE allows data to be decrypted based on a person’s role or privileges. Only those who have a particular set of attributes will be able to decrypt the cipher text. Functional encryption helps in providing restricted access to certain resources which must be protected or accessed by limited set of users.
On the other hand, fully homomorphic encryption enables the conversion of data to a form which is meaningless without decryption (cipher text) while allowing operations to be performed on that cipher text.
In fact, functional encryption and homomorphic encryption can be combined to better preserve privacy. For instance, if the coordinates of the location of a population needs to be kept private, the latter may be encrypted while allowing operations to be performed on the encrypted coordinates (Dijk & Juels, 2010).
2.5.5 Cryptographic Hash Function
Mostly used for indexing or integrity checks, hash functions can also be used to preserve privacy in the form of pseudonyms thanks to its irreversible transformation property and uniqueness. The only way to get back a plain text from its hash value is by using brute-force techniques which takes a lot of time unless the attacker has powerful supercomputers.
The major drawback of using hash functions to preserve privacy is that once data has passed through a hash function, the output can only be used to identify a record uniquely. The hashed value is meaningless and cannot be used for processing. However, this drawback is not applicable when using hash values as an alias for the sole purpose of identifying a user. For example, an application could be using an email address to uniquely identify users but that address can be maliciously used to find other information about the users unlike with the use of hashed values (Pournajaf, et al., 2015).
Some of the popular hash functions include MD5, SHA-3, and BLAKE.
2.5.6 Spatial Cloaking
Spatial cloaking is similar to data perturbation in the sense that false data is created to prevent attackers from distinguishing the true data. Spatial cloaking is a mechanism designed to achieve specifically location privacy. It can be used for LBMCS to hide the location of users in applications where having the exact location is not necessary. This approach hides the location of a user by sending dummy locations or by sending a cloaked region obtained by performing generalisation and spatial transformations. An anonymiser is responsible for performing spatial cloaking whereby the anonymiser acts as a trusted intermediate between the user and the service provider. The anonymiser takes the location of the user, places the latter in a cloaked region and transmit the region details to the service provider.
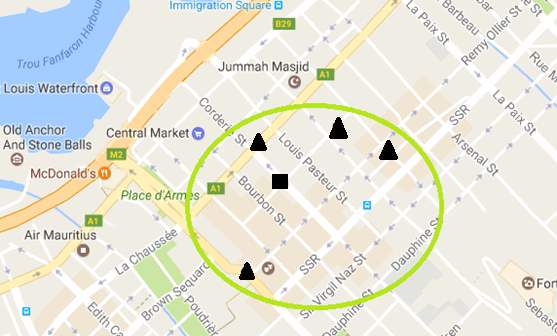
Figure 13 shows part of a map where a square represents the exact location of a user. To prevent the receiver from knowing the exact location of the user, either a cloaking region is determined (big circle) and sent or the exact location is sent along with dummy locations (triangles). However, this method affects the accuracy of services and adds processing overhead to the server since analytics have to be performed for an entire cloaked region or several dummy requests for each user (Pournajaf, et al., 2015).
2.5.7 Temporal Cloaking
Temporal cloaking, also known as temporally constrained sharing, is an approach similar to spatial cloaking except that instead of reducing the accuracy of locations it reduces the accuracy in time. Location based attacks are prevented by controlling the timing of disclosures. Its implementation consists of splitting the map into a set of regions and then a subset of users is chosen in each region at a time to send their exact locations according to a certain probability distribution. The algorithm may also wait until a number of users are in a particular region before sending location data. In this way, the attacker may know the exact location of the user but will not know when the user was at that particular location (Gruteser & Grunwald, 2003).
2.5.8 Private Information Retrieval (PIR)
PIR is a mechanism used to safeguard privacy by allowing users to retrieve records from a database while not letting the database owner to know which records have been retrieved. There are two types of PIR, namely, single-database PIR and multiple-database PIR.
There exist several ways of implementing single-database PIR; the simplest one is where a whole copy of the database is sent to the client and the client retrieves required data locally. Obviously, this is inefficient and involves high communication costs. Another way is to request a group of records which is then filtered locally to obtain required information.

Figure 14: Two-server Private Information Retrieval
In the multiple database PIR, there exist multiple servers having the same copy of the database each. The user requests different parts of information from multiple databases and then combine the responses to obtain the required record. Cryptographic protocols ensure that the database server is not aware which information is retrieved in both types of PIR (Yi, et al., 2013).
2.6 Chapter Summary
The background study started by exploring the types of sensing applications and the architectures used for sensing applications. Then mobile crowdsensing has been described along with each of its processes. Finally, several existing privacy-preserving mechanisms applicable to MCS have been described and analysed.
3 Analysis
This chapter consists of the requirements of the system. The alternate ways to solve the problem are describes along with the proposed solution.
3.1 Requirements
Herein, the functional and non-functional system requirements are discussed.
3.1.1 Functional Requirements
| ID | Description |
| FR1 | The system shall allow a user to perform a service request. |
| FR2 | The system shall process the service requests. |
| FR3 | The system shall provide a response to the user. |
| FR4 | The system shall allow users to contribute data periodically or in an ad-hoc manner. |
Table 2: Functional requirements
3.1.2 Non-functional Requirements
| ID | Description |
| NFR1 | The system shall preserve the privacy of users. |
| NFR2 | The mobile application should be compatible with most devices. |
| NFR3 | The system shall keep minimum user information. |
| NFR4 | The system shall have a user-friendly interface. |
| NFR5 | The system shall prevent erroneous input and alert the user when required. |
| NFR6 | The system shall be responsive. |
| NFR7 | The system should involve minimal costs. |
Table 3: Non-functional requirements
3.2 Alternative Solutions
In this project, a MCS system comprising of a client-side mobile application, a server-side data processor, and a possible third party acting as an anonymizer is to be implemented. The benefits of several privacy-preserving mechanisms will be combined to produce a MCS system which adequately preserves the privacy of users. There are several privacy-requiring areas or scenarios where MCS systems can be implemented. Some are described below:
- Healthcare services
The healthcare area requires the privacy of users since very often patients do not want the public to know about that their diseases. Hence a MCS system dealing with the symptoms or diseases of patients should preserve privacy. One possible MCS application providing healthcare services is a health monitoring tool which collects information about the daily activities of patients along with their healthiness information and pushes the collected data to a server which analyses trends on similar patients and provides suggestions on how the patients can improve their health or even predict symptoms based on the daily activities of the patients.
- News/information sharing
An information sharing MCS application consists of users sending information in the form of messages, photos, videos, or audio to a centralised server which will filter the contents to later share with users interested with this information. One possible scenario could be a user identified that some people are selling drugs near his workplace. He records and sends their conversation to the centralised server which relays the information to concerned authorities while safeguarding the privacy of the user.
3.3 Proposed Solution
The MCS application chosen to be implemented is a LBMCS application due to its higher complexity in tackling privacy problems. The reason for this complexity is that not only attributes about the user have to be protected but the queries and responses too. For instance, a MCS application for health monitoring may only require that diseases of patients are not disclosed. In a LBMCS application, the current location of users must be protected plus the queries of the user since the latter may be requesting road traffic details from a source location to a destination and this information may lead to an attacker knowing where the victim will be in some time. Moreover, the results of the queries sent from the server should also be protected since it may be revealing the best route and hence enabling the attacker to know the trajectory of the user.
The main functionality of the proposed LBMCS application is to be able to identify traffic jams in real-time by collecting traffic details from a large number of users. There will be predefined points on the map and whenever a user reaches one of these points a feed is sent to a server which will compute the time taken from the previous point to the current one. For demonstration, the points will be set every 10 kilometres on the map but will ideally be every 1 kilometre or less in real life. Analytic algorithms will compute the time taken for a large number of users from every point to its adjacent points to determine the congestion levels. An average time taken greater than 20 minutes will infer the route is highly congested, less than 10 minutes means not congested and in between slightly congested.
The client-server architecture will be used since the TTP architecture is a costly one and the P2P architecture is complex to implement and inappropriate when there are not a sufficient number of peers in the surrounding all the time. The client will consist of an Android mobile application capable of collecting location details with the help of its GPS and sending that information to the server. The mobile application will also be able to request and present details about the congestion levels for different available routes from a source location to a destination. An emulator will be used to run the mobile application. For the server side, an Oracle database will be set up locally on a computer system and will be responsible for data aggregation and processing. A computer system and an emulator are used to avoid deployment costs.
Since purpose of MCS is to collect a large amount of data, a program will be developed to randomly generate location values of users at random time intervals to simulate users travelling from a specific source location to a destination.
Privacy-preserving Mechanisms
- The first mechanism is to allow the user to set privacy preferences when performing a service request. The privacy preferences include settings to share little details about their current location for occasions where the user wishes to stay incognito. The preferences will also allow the user to share more precise location details occasions where there is no need to stay private, such as, while going to school since this information is already publicly available on social media. However, these two preferences, named ‘StrictPrivacy’ and ‘HighPrecision’, presents a trade-off such that the Strict Privacy settings will give results of lower precision and the High Precision preferences will be vulnerable to privacy attacks.
- Cryptographic hash values are to be used to uniquely identify users instead of their email address. In this way, the identity of participants is protected in case the database of the service provider is compromised since the hash values are meaningless and cannot divulge information about users if looked for elsewhere. Moreover, a different hash value is used for each trip by using the hash value of the email address of the user concatenated with the trip’s source and a random number. This mechanism is applied to ‘Strict Privacy’ and ‘High Precision’ preferences.
- In order to preserve privacy, the ‘Strict Privacy’ mode will share the current region of participants instead of their exact location. Each region will consist of a number of location points which could be the current location of the user. For instance, Ebene and Reduit belongs to the same region and by sending their region code, the exact location of the user will remain unknown. This mechanism is known as Spatial Cloaking and the process of converting the exact location into a region is performed by a trusted third-party (anonymiser). This project attempts to implement this mechanism in a two-tier architecture.
- When a service request is performed, the user has to input a source location and a destination. The same principle is used whereby the regions of the source and destination points entered are shared with the server and the server will respond with all the possible routes from the source region to the destination region. The mobile application will then filter the results to display only the routes which matches the source point to the destination point provided by the user. This mechanism is applied to the ‘Strict Privacy’ mode.
- Another privacy-preserving mechanism present in the ‘Strict Privacy’ mode consists of sending dummy service requests and dummy crowdsensing data to the server. When a new service request is issued, a few threads (zero to two threads) are created which act exactly as a real service request and automatically push crowdsensing data to the server. These threads will have different identifiers, random sources and random destinations. They will send route durations that are close to those provided by the server. In this way, the data analytics will not be largely affected and if database of the service provider is compromised, the real records will be undistinguishable among the fake ones.
3.3.1 Mobile Application Requirements
The MCS application has several requirements for the proper functioning of the system. Firstly, a mobile device or a mobile device emulator having a compatible Android operating system is required. The mobile device/emulator should have internet access (preferably 3G or better). Finally, the mobile device/emulator should have a GPS location sensor.
If a mobile device emulator is used, a computer will be required for the emulator to run.
For demonstration, the system will be tested at one site and consequently the GPS sensor cannot be used to capture locations. The mobile application will enable manual input for locations and hence the GPS sensor will not be required for this purpose. Also, a mobile device emulator will be used to run the application. Therefore, a computer will also be required.
The mobile device emulator requirements are as follows:
- Microsoft Windows 7/8/10 (32- or 64-bit) operating system
- 3 GB RAM minimum plus 1 GB for the Android Emulator
- 2 GB of available disk space minimum
- 1280 x 800 minimum screen resolution
3.3.2 Database Server Requirements
A server having an operating compatible with the Oracle database will be required for the database server. Moreover, the server should have access to the internet and allow ad-hoc communication with a large number of mobile devices. The server should have sufficient processing capacity and memory to respond to all requests. The database should have enough space to accommodate information about all routes and requests.
For demonstration, the Oracle database will be set up on the computer which will run the emulator. Since the emulator and the Oracle database will communicate locally, internet connection will not be required for the database.
The Oracle database requirements for demonstration are as follows:
- Microsoft Windows 7/8/10 (32- or 64-bit) operating system (Professional, Enterprise or Ultimate edition)
- 1.5 GB of available disk space minimum
- 256 MB of RAM minimum
3.3.3 Crowdsensing Data Generator (CDG) Requirements
As explained in section 3.3, a Crowdsensing Data Generator will be implemented to produce a large amount of data in order to simulate a large number of users using the MCS application and feeding information to the server. The CDG will be used for demonstration only.
The CDG will be developed and executed using Eclipse Integrated Development Environment (IDE). The requirements are as follows:
- Microsoft Windows 7/8/10 (32- or 64-bit) operating system
- Java 5 JRE/JDK or greater
- 300 MB of available disk space minimum
- 512 MB of RAM minimum
3.4 Assumptions
The proposed system deals with privacy of users at application level. It is assumed that users cannot be tracked using SIM card identifiers, hardware identifiers or even network-based identifiers such as IP address. There are several mechanisms which provide anonymity at these levels, for instance, at the network layer techniques such as Onion routing (Goldschlag, et al., 1999) or Crowds (Reiter & Rubin, 1998) can be used to hide the IP addresses of users from the centralised server, hence making the participants untraceable. It is also assumed that the communication between the mobile devices and the centralised server is encrypted.
3.5 Chapter Summary
The functional and non-functional requirements of the system have been listed followed by the description of alternative solutions. The alternative solutions included a healthcare service system and an information sharing system. The proposed solution consisted of a location-based MCS application which enables users to have real-time route congestion details. Privacy-preserving mechanisms for the proposed system have been described along with the requirements of the system. Finally, the system assumptions were described.
4 Design & System Modelling
This chapter describes the proposed system and presents a detailed analysis of the various design aspects of the project.
4.1 Design Methodology
The top-down design methodology has been chosen for the design of the proposed system. Top-down design, also known as stepwise refinement, refers to breaking down of a big and complex problem into several modules, where each module is further broken down until the sub-modules accomplish only one particular task. Ultimately, these sub modules become easy to understand, straightforward to implement and simpler to debug.
Benefits of Top-down Design Methodology:
- At each step of refinement, the parts of the system become simpler and better understandable.
- Splitting the program facilitates testing since testing can be performed module-wise. Moreover, small self-contained modules are easier to debug compared to a single huge program.
- Top-down design approach aids program readability and makes it easier to add or modify functionalities.
- Breaking up a problem into modules makes development more efficient since each developer can work on a particular module and then later combine them.
4.2 Mobile Application Design
This section consists of a technical analysis of the various design aspects of the mobile application proposed above.
4.2.1 Motivation to use Android
The main reason to choose Android is because it is the most used and fastest growing operating system. Android has numerous benefits as listed below:
- Used by over a billion devices (greater audience)
- Compatible with most mobile devices
- Open source
- Free Software Development Kit (low development costs)
- Built-in GPS receiver
- Easy use of the Google Maps and Google Directions API
The advantages show that Android operating system is best fitted for MCS and hence an Android mobile application will be developed.
4.2.2 Android Architecture
The major components of the Android platform include Linux Kernel, Hardware Abstraction Layer, Android Runtime, Native C/C++ Libraries, Java API Framework, and System Apps as shown in the figure below.
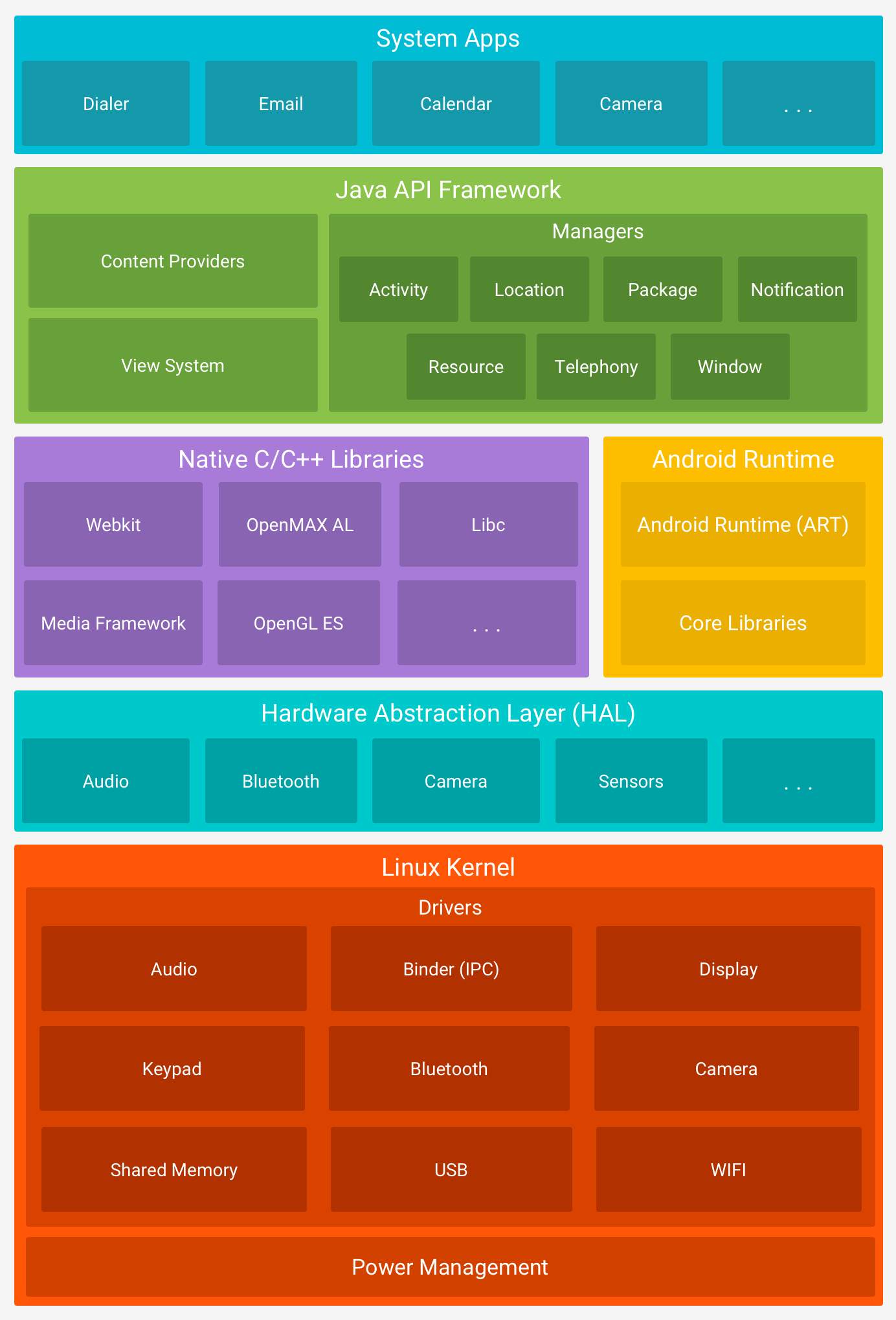
Figure 16: The Android software stack (Android, n.d.)
Linux Kernel
The Linux Kernel is at the root of the Android architecture. It is responsible for device management, low-level memory management, power management and resource access.
Hardware Abstraction Layer (HAL)
The HAL is an intermediate between the libraries and the device hardware. It consists of several modules which implements an interface for each type of hardware component. Some of the modules include Audio, Bluetooth, and Camera.
Android Runtime (ART)
Each application running on Android version 5.0 or higher has its own process with its own instance of the ART. It provides a set of core libraries to enable applications to be developed using standard Java programming language.
Native C/C++ Libraries
The native C/C+++ libraries are required by applications or system components that have been written using native codes. For instance, ART and HAL are built using native codes that require libraries written in C and C++.
Java API Framework
The Java API Framework allows the creation of Android applications by simplifying the reuse of system and user-interface components such as embedded web browser, graphics, custom alerts, navigation buttons, etc.
System Applications
The system includes core applications such as email, internet browsing, contacts, and SMS messaging. Third-party applications will also be on the same layer.
4.2.3 Top-down Design
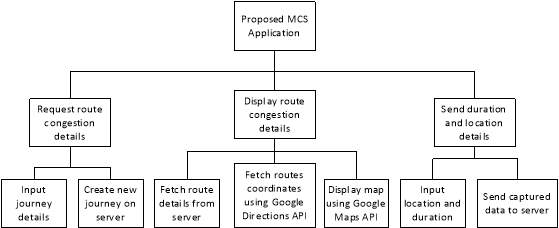
Figure 17: Mobile Application Top-down design
The figure above shows how the proposed solution has been broken down into seven sub-modules. The class chosen names and details for the sub-modules are listed below:
| Sub-module | Class name | Functionality |
| Input journey details | ServiceRequest | Input source, destination, travel mode and privacy mode |
| Create new journey on server | AsyncJourney | Connect to DB server and insert the new journey details |
| Fetch route details from server | AsyncPull | Connect to DB server and query details of routes from the source to the destination entered |
| Fetch routes coordinates using Google Directions API | GMapDirection and AsyncGMapDirection | Retrieve a list of points to be drawn on the map for each route |
| Display map using Google Maps API | ServiceResponse | Display a new screen with a map having routes coloured according to congestion levels |
| Input location and duration | ServiceResponse | A pop up on the existing ServiceResponse screen will be used to input location and duration |
| Send captured data to server | AsyncPush | Connect to DB server and insert new location and duration captured |
| Send dummy data to server | DummyThread | Mimic a real service request and send periodic false captured data to the server. |
Table 4: Mobile application modules’ description
4.2.4 Interface Design
In this section, the various screens that have to be implemented are designed.
4.2.4.1 Service Request
The service request is the starting point whereby the users provide details about their new trip in order to have congestion details about the available routes and hence be able to choose the best one.
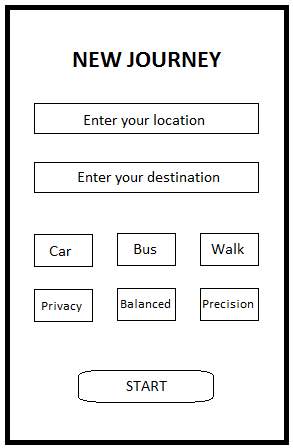
Figure 18: Service Request screen
The figure above shows the service request screen where the user has to input a source location, a destination, the mode of transportation (Car, Bus, or Walk), and mode of processing (Privacy, Balanced, or Precision as proposed in section 3.3.5). The Privacy mode (named StrictPrivacy in implementation) is designed for trips which the users wish to remain private. The Precision mode (named HighPrecision in implementation) is designed for daily trips where it is not essential that the trip remains confidential since for instance the trip information is already publicly available on social media. However, the precision mode provides high precision while estimating congestion levels since more accurate location details are transmitted to the server for processing. Since there is a trade-off between privacy and precision, the Balanced mode will be a combination of parts of Privacy and Precision modes in order to produce the best results.
Note that the transportation modes Bus and Walk, and the mode of processing Balanced will not be available for demonstration since they are meant for future works.
4.2.4.2 Service Response
The service reply screen appears when the user clicks on the Start button in the Service Request screen. This screen aims at presenting the congestion levels of routes in a meaningful manner.
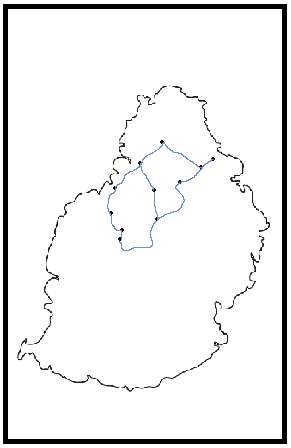
Figure 19: Service Reply screen
The figure above shows the service reply screen where the different possible routes will be displayed on a map. The congestion levels are illustrated using colours: red route means highly congested, green route means not congested, and yellow route means slightly congested. Google Maps API will be used for the map and Google Directions API will be used to draw the routes.
The service reply screen will be updated automatically when congestion levels change.
4.2.4.3 Data Collection
The Data Collection screen has been designed solely for demonstration purposes. It allows a user to input location and duration details manually since the demonstration will be done at one location and the application will not be able to automatically transmit location details when predefined locations are reached.
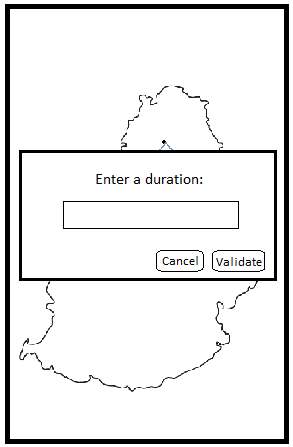
Figure 20: Data Collection screen
The figure above shows an input box which represents the Data Collection screen. This input box appears when the user clicks on a marker (represented by dots in the previous figure). It signifies that the user has reached that marker’s location and the time taken to reach that location is provided via the Data Collection screen.
When the user click on validate, the marker’s location plus the duration is sent to the centralised server for processing (crowdsensing part). Note that this process will be automated when the application will be deployed for real use.
4.3 Database Server Design
This section consists of a detailed technical analysis of the design specifications of the database server for the proposed system.
4.3.1 Motivation to use Oracle Database
There are several reasons for using an Oracle database. The main reasons include its performance, stability and robustness in handling big data. Another major reason is the availability of an Express Edition of the Oracle database which is free. Some of the other advantages are listed below:
- Portability to more than 100 hardware platforms
- On-line backup
- Point-in-time recovery
- Supports PL/SQL
- Has ability to manage multiple databases within the same transaction
4.3.2 Top-down Design
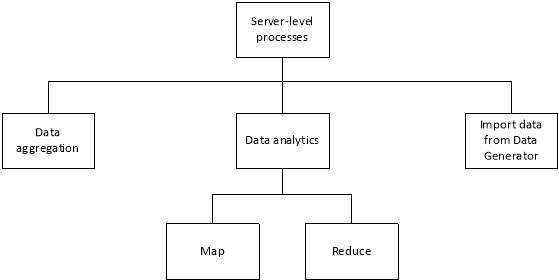
Figure 21: Database server Top-down design
The processes to be performed by the server have been broken down into 4 sub-modules as shown above. The MapReduce model will be used for the analytics part. The details for each sub-module are listed below:
| Sub-module | Functionality |
| Data aggregation | This module is responsible in inserting new journeys (table user_journey) and crowdsensing data (table user_feeds) in their respective tables for processing |
| Map | All unprocessed records are arranged and placed in tables corresponding to each route associated. For instance, all crowdsensing data for point AA2 to point AA5 are placed in table route_AA2AA3. |
| Reduce | The average duration for each route table are calculated and stored in the routes_duration table. |
| Import data from Data Generator | Retrieve data from the flat file created by the Crowdsensing Data Generator and insert the records in their respective tables for processing. |
4.3.3 Entity-Relationship Diagram (ERD)
Since the proposed system consists of two modes of processing data, namely, the StrictPrivacy and the HighPrecision mode, two database schemas will be created to separate data collected.
The ERD for the StrictPrivacy mode is shown below.
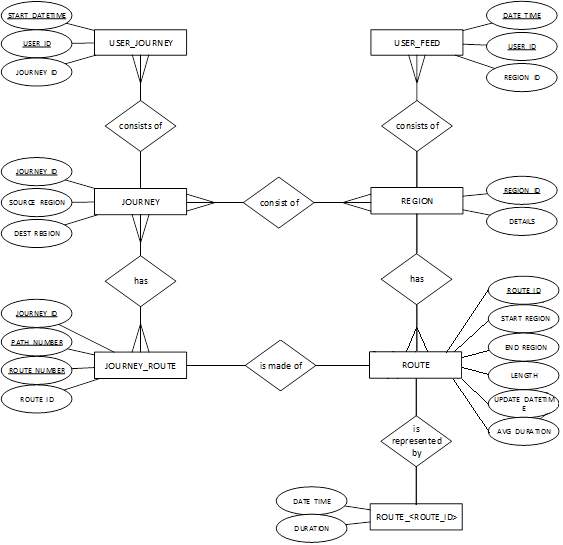
Figure 22: ERD for privacy schema
The ERD for HighPrecision is shown in the figure below:
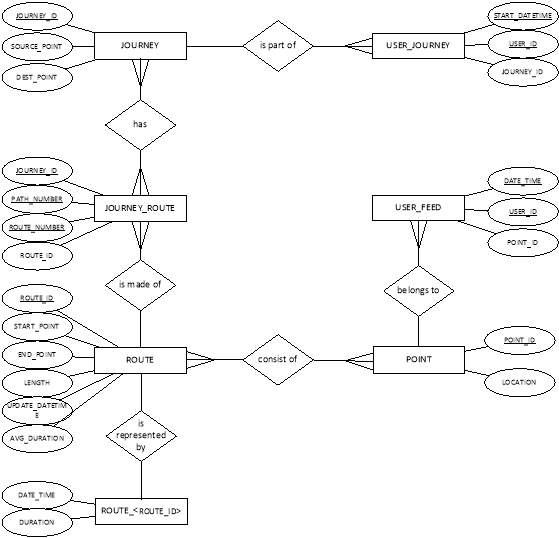
Figure 23: ERD for precision schema
4.4 System Modelling
This section consists of use case diagrams, sequence diagrams and class diagrams for the proposed system.
4.4.1 Use case diagram
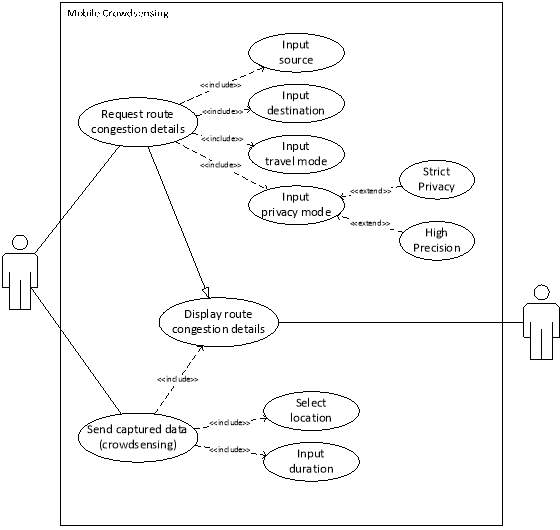
4.4.2 Flowchart diagram
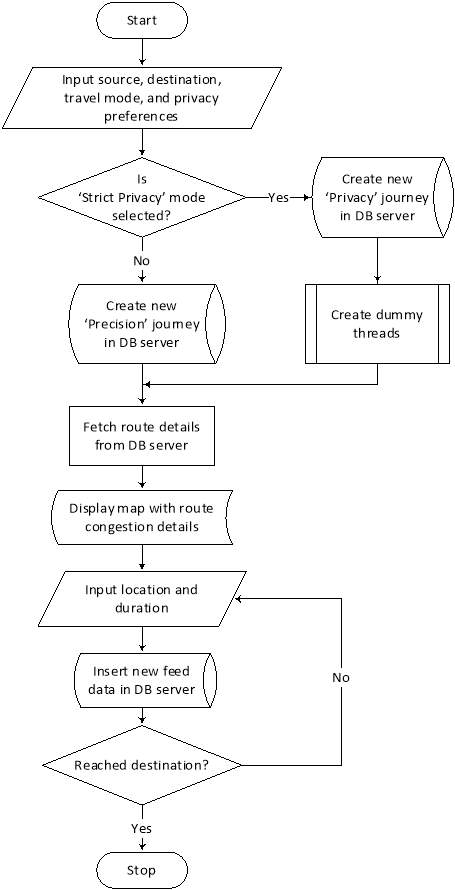
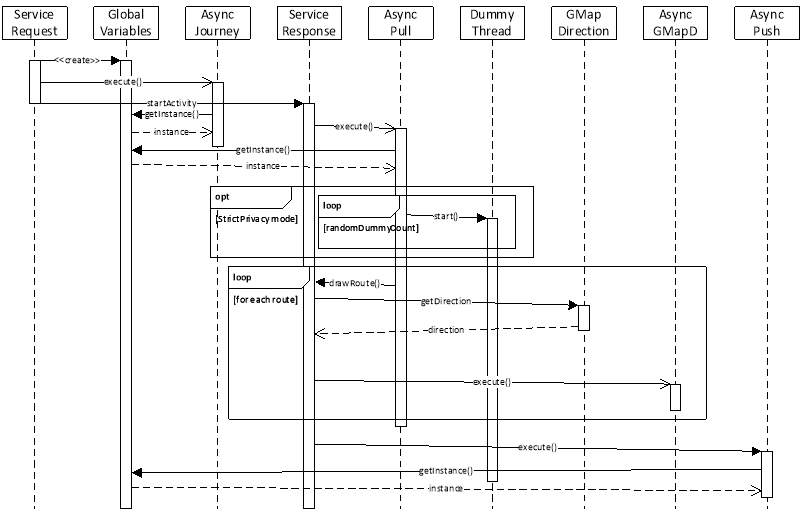 Figure 26: Sequence diagram
Figure 26: Sequence diagram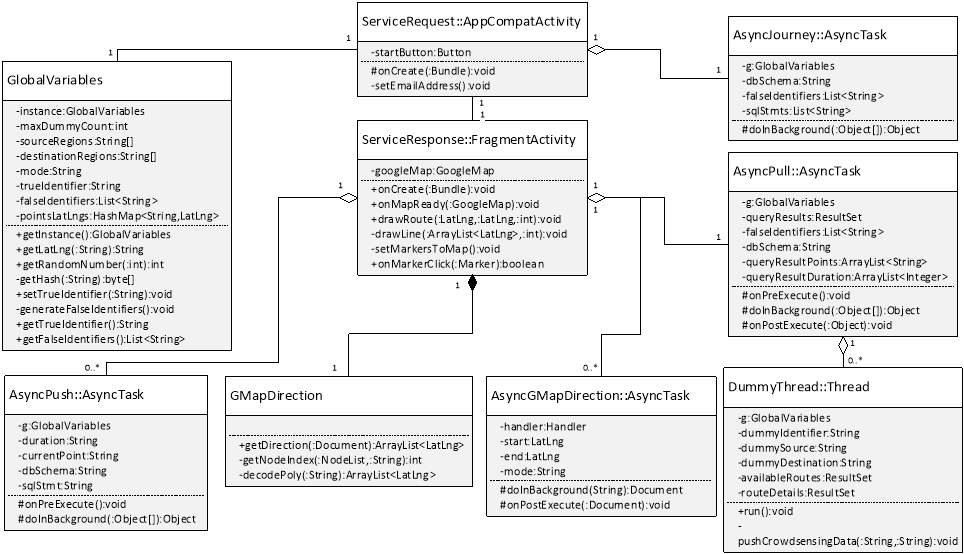
4.5 Chapter Summary
To start with, the design methodology has been chosen and described. Then, the motivation to use Android for the mobile application and Oracle for the database have been listed. The mobile application and the database server have then been designed using the chosen design methodology. The system modelling section consisted of a use case diagram, flowchart diagrams, a sequence diagram and a class diagram.
5 Implementation
In this chapter, the implementation issues, the standards and conventions used, the development tools used and the implementation of different modules are discussed. Sample codes have also been provided for the modules discussed.
5.1 Mobile Application Implementation
5.1.1 Development Tools Used
Android Studio 2.3.1 and Java Runtime Environment (JRE) 1.8 were utilised for the implementation of the Android mobile application.
5.1.2 Hardware configurations
The mobile application will be executed on an Android emulator. The Android virtual device was configured as follows:
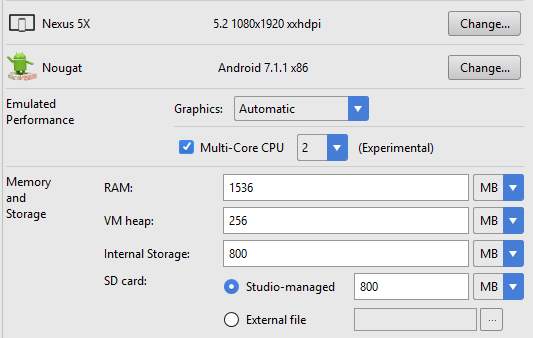
Figure 27: Android virtual device configurations
5.1.3 Implementation of the different modules
The MCS application required the development of several modules and each module is implemented by a Java class as described in section 4.2.3. The Java class names include ServiceRequest, AsyncJourney, AsyncPull, GMapDirection, AsyncGMapDirection, ServiceResponse, AsyncPush, and DummyThread. An additional Java class named GlobalVariables has been implemented to store data which have to be available to the other classes throughout the execution of the application. This section describes the implementation of each of these classes.
GlobalVariables.java
The class GlobalVariables is a singleton (only one instance of this class is kept at a time) and is used to keep data throughout the process and accessible to all the classes. Section 4.4.3 shows how this class is used by several classes to retrieve data.

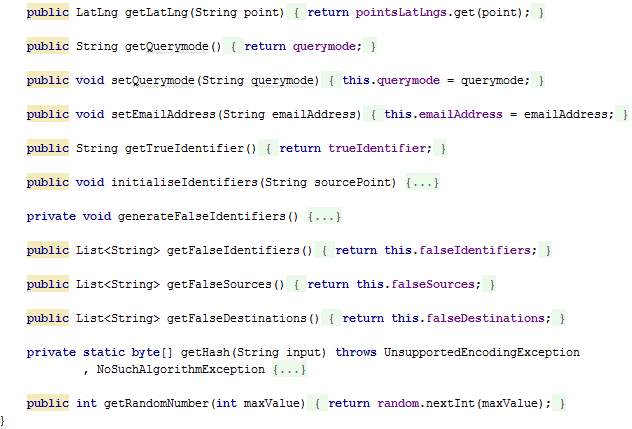
When created, the coordinates and names for the markers are set.

The getInstance() method returns a synchronized class to protect access to resources since they are accessed concurrently. Hence, only one thread can execute inside the GlobalVariables class at the same time. All other threads attempting to enter the class are blocked until the thread inside it exits the block.

The method initialiseIdentifiers() sets the current source, clears existing lists (will have values in case the user is starting another journey), and calls the method generateFalseIdentifiers.

The method generateFalseIdentifiers() generates a random number between 1 and 3 inclusive to denote the number of dummy threads which will be created. Next, false sources, destinations and identifiers are created for each of these dummy threads and stored in lists.

The method getHash takes a text as input and returns the Secure Hash Algorithm (SHA) value of that text. The SHA-256 generates a 256-bit (32-byte) fixed-size hash.

The method getRandomNumber generates a random number greater or equal to zero and less that a maxValue.
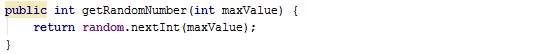
ServiceRequest.java
The class ServiceRequest extends AppCompatActivity and has a method named setEmailAddress. It also overrides the method onCreate.
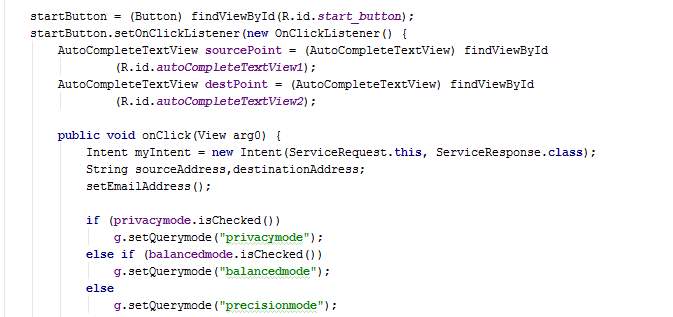
In the overridden method onCreate, toggle buttons for travel mode are disabled and toggle button Balanced for operation mode is disabled. Car travel mode is chosen since the other modes will not be implemented for demonstration. The attributes trueSource, trueDestination and querymode of the class GlobalVariables are set. The class AsyncJourney is also executed. When the button Start is clicked, a new intent is created whereby the class ServiceResponse is activated.
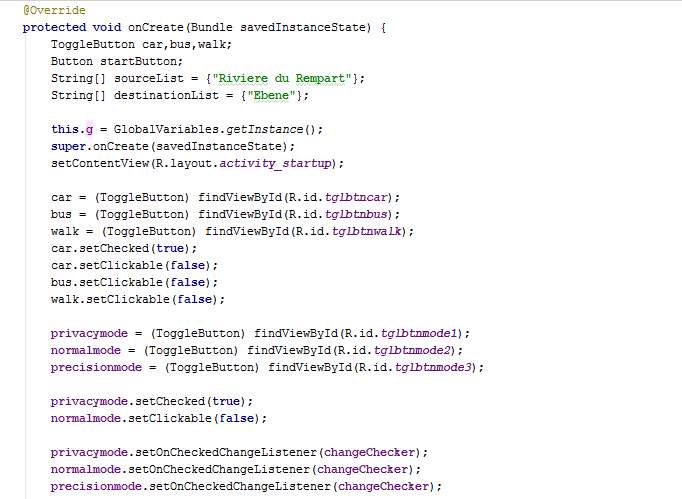
The togglebuttons are programmed in the OnCheckChangedListener whereby the other buttons are unchecked when one button is clicked for the mode selection.

The method setEmailAddress() loops through the AccountManager and takes the first email address found. The AccountManager is an inbuilt module in Android which stores the primary and secondary email addresses of the device owner. Android usually requires at least one email address to be able to download applications on Google Play Store. The emulator will be using the default email address hardcoded.
AsyncJourney.java
The class AsyncJourney is triggered by the class ServiceRequest. The former is an asynchronous task which allows data to be sent to the database server in the background while enabling other processes to run in parallel. This method sends information about the journey requests to the server, including requests for the dummies.
When AsyncJourney is instantiated, several attributes from GlobalVariables are retrieved and the method initialiseIdentifiers is called.

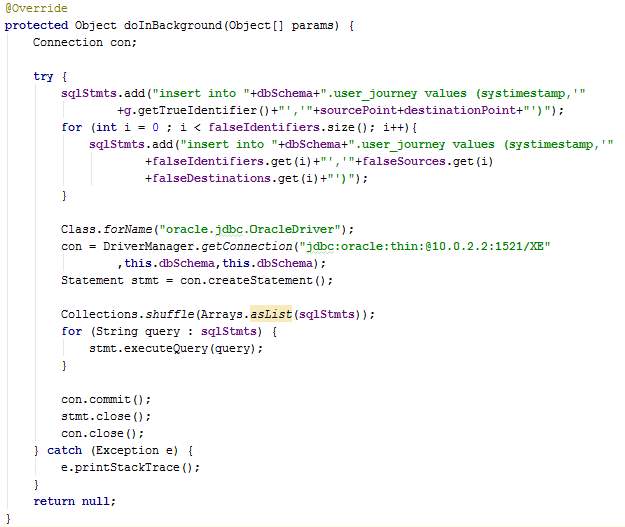
In the overridden method doInBackground, several SQL statements are added to a list and then each of these SQL statements are executed on the DB server after establishing a JDBC connection. The list of SQL statements will include new journey information of for the dummies too. Therefore, the list is shuffled before execution to prevent identification of the true request.
Note that this is an internal connection and will be different if the server was not in the same machine or network.
AsyncPull.java
The method AsyncPull is an asynchronous task used to fetch route details from the centralised server. The information fetched include the available paths (set of routes from the source to the destination) and the congestion levels of individual routes.
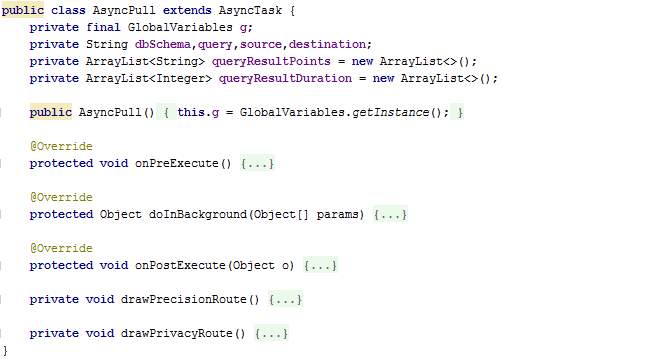
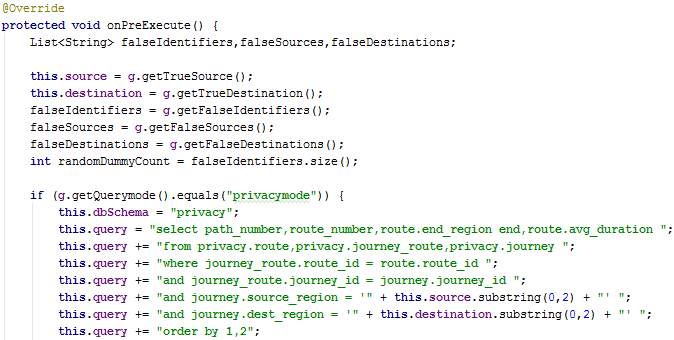
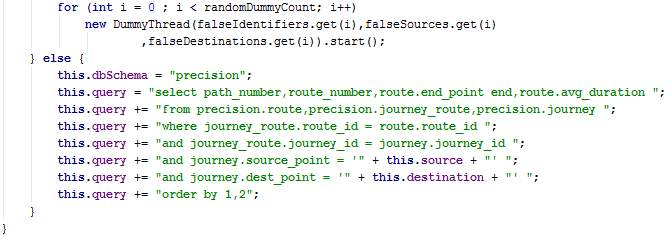
The overridden method onPreExecute fetches data from GlobalVariables and creates the SQL statement depending on the mode of privacy. Also, DummyThreads are created and launched.
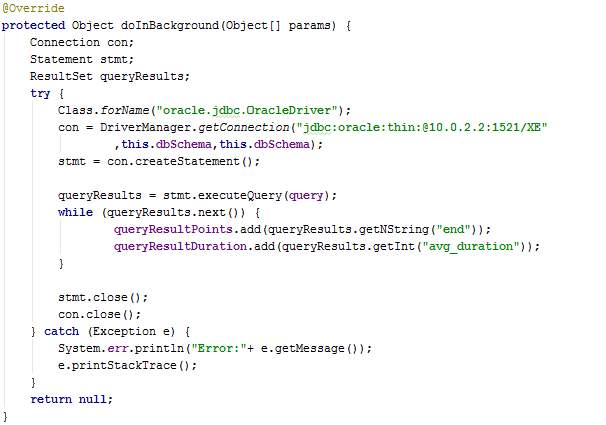
The overridden method doInBackground created a connection with the DB, executes the query and stores the results in lists.
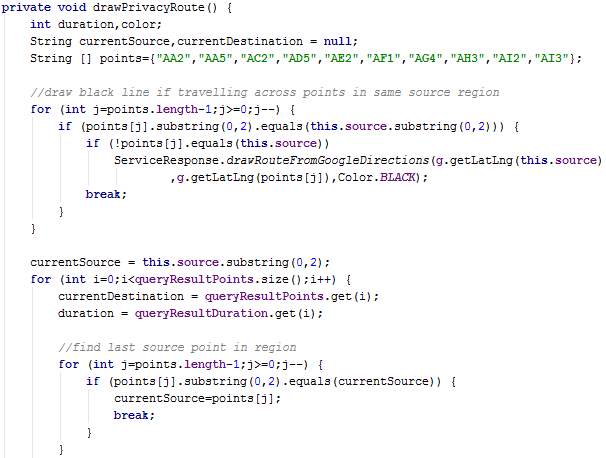
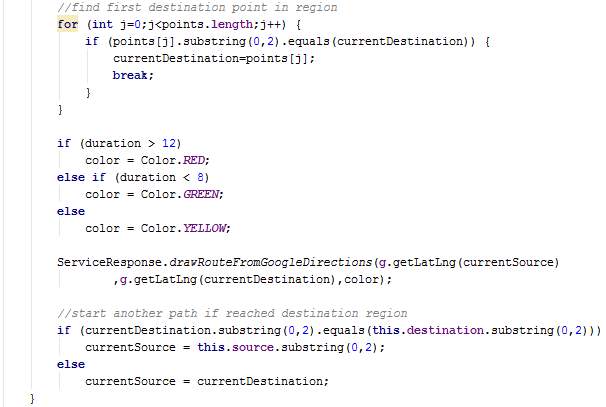
The overridden method onPostExecute is executed automatically after the execution of doInBackground. The method drawPrivacyRoute or drawPrecisionRoute is called depending on the processing mode chosen by the user.
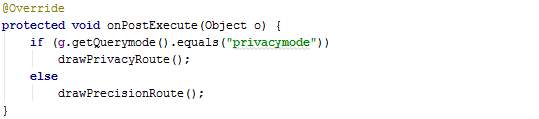
The method drawPrecisionRoute loops through the query results obtained and sets a colour for each route depending on the time taken to traverse the routes. Then the method drawRouteFromGoogleDirections found in the class ServiceResponse is executed.
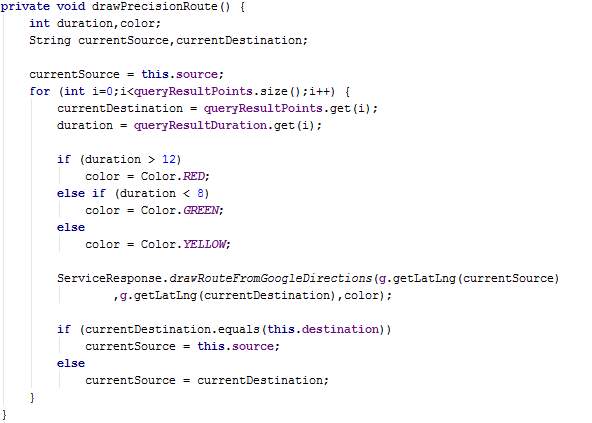
The method drawPrivacyRoute is similar to drawPrecisionRoute, however it contains more operations since regions are used. Since a region contains several points and the time taken to travel between points in the same region cannot be determined, a black route is drawn between points in the same region. The known durations pertain to the last point in a particular region to the first point in the destination region. Hence, route colours red, yellow and green are assigned only between points where the duration is known.

ServiceResponse.java
The class ServiceRequest extends FragmentActivity and implements the interfaces OnMapReadyCallback and OnMarkerClickListener. This class implements the next screen which is launched when the start button is clicked in the ServiceRequest screen. The ServiceResponse screen displays a Google Map with routes coloured depending on their congestion level. It also displays markers on the map to represent points at which data should be sent to the server to store the travel duration until that point. When instantiated, latitude and longitude values for markers on the map are set.
The overridden method onCreate sets the layout of the screen and gets the map.

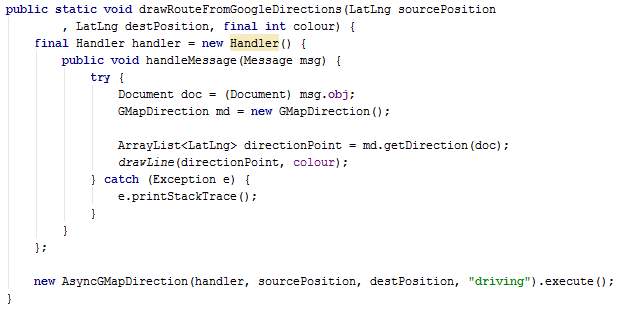
The overridden method onMapReady zooms on the map and displays Mauritius. The method setMarkersToMap is called and the class AsyncPull is triggered.
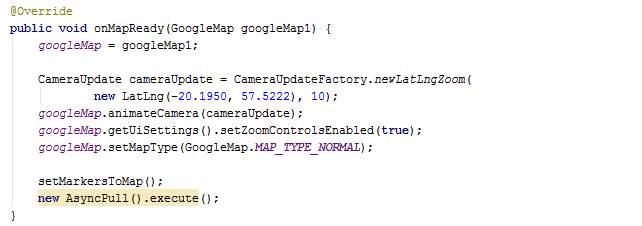
The method drawRouteFromGoogleDirections is used by the class AsyncPull. The parameters passed are source corrdinates, destination coordinates and colour. This method draws a line on the map across the road from the source to the destination with the colour requested. The class GMapDirection is created and its method getDirection is called in a handler. The list of points obtained from getDirection is passed to the local method drawLine. The AsyncGMapDirection is also created and executed. The methods called are described below.
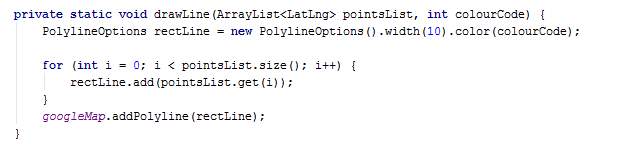
The method drawLine takes a list of points’ coordinates and a colour code as parameter. It draws a line across the points on the map using the colour code.
The method setMarkersToMap places markers on the map using their coordinates. A title is also given to the markers, which is displays when clicked.

The onMarkerClick method is triggered when the user clicks on a marker. This method displays an input box on the screen to request the user to enter a duration. The aim of this input box is to bypass the sensing part in MCS whereby the user enters data manually instead of the application sensing data and sending to the server automatically. As explained in the design chapter, this has been implemented for demonstration purposes.
The onMarkerClick method implements the Validate and Cancel buttons on the input box. When Validate is clicked, the class AsyncPush is created and executed. The message “Data sent to server” is displayed to inform the user when the input box closes.

GMapDirection.java
The class GMapDirection is in fact used by the class AsyncGMapDirection. The class GMapDirection is defined in a handler which is later passed as a parameter to execute AsyncGMapDirection. AsyncGMapDirection uses GMapDirection to decode the polyline obtained from the Google Directions API so that the points become drawable.
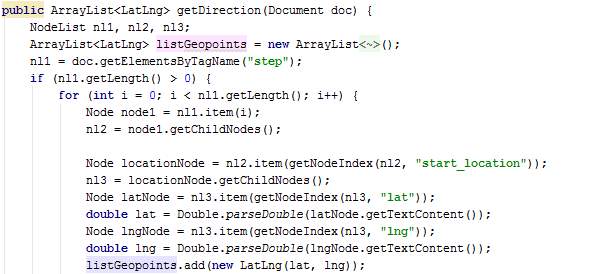
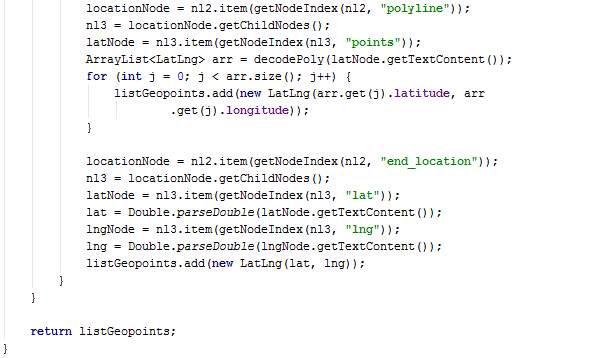

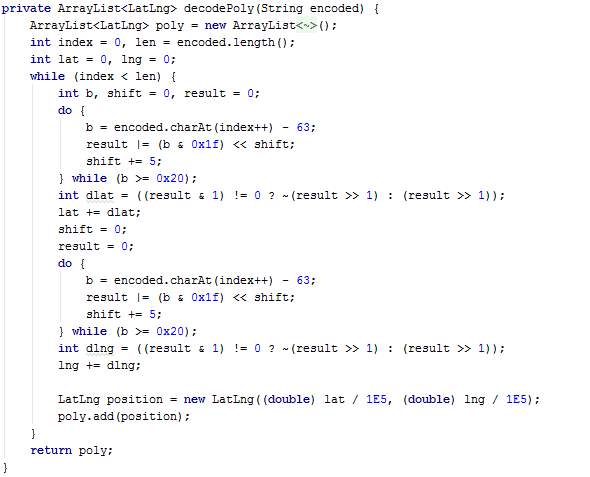
AsyncGMapDirection.java
The class AsyncGMapDirection is an asynchronous task used to connect to the internet and fetch road paths from Google Directions API. Without this method, the lines between points on the map would be straight lines. It takes as parameter the handler which contains methods of the class GMapDirection, a start point, an end point, and the mode of travel. There are 3 modes of travelling, namely, car, bus and walk. Currently “driving” mode is being used for demonstration.
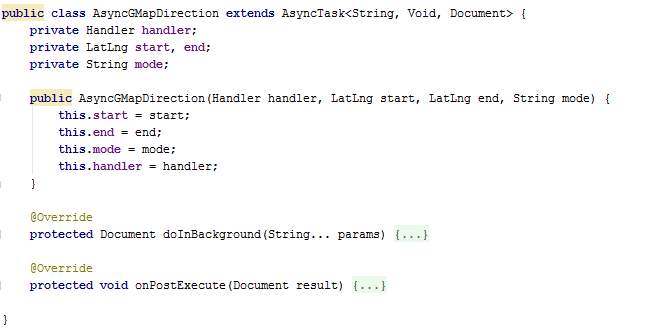
The method doInBackground creates a URL using the parameter values and then connects to the internet to go through the URL. The URL goes to an XML page. The XML content is fetched.
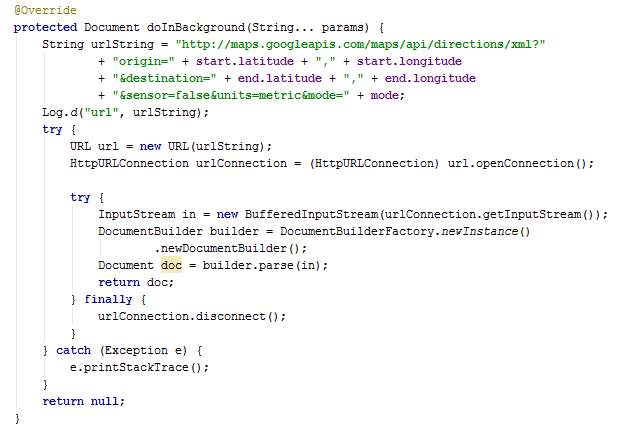
Once the XML retrieved, the onPostExecute method passes the former to the handler via a message. As explained earlier, the handler has methods of GMapDirection inside and is used to decode the XML document.

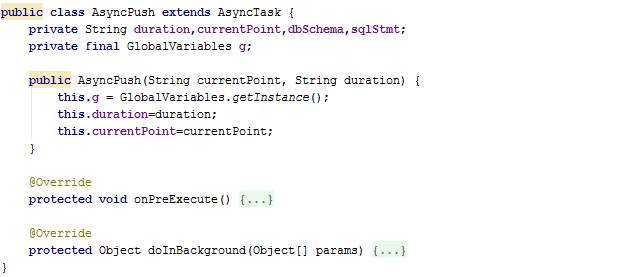
AsyncPush.java
The method AsyncPush is an asynchronous task used to send captured data to DB server. The class takes a point and duration as parameter because for demonstration, the user will be requested to enter a duration (for simplicity) and this class will mimic real crowdsensing data by sending a time with the duration added to it to the server.
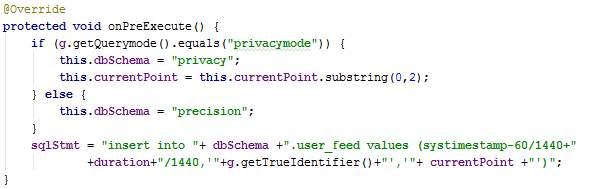
The method onPreExecute creates the query statement to insert in the DB server.
The method doInBackground executes the SQL statement and commits the changes made.
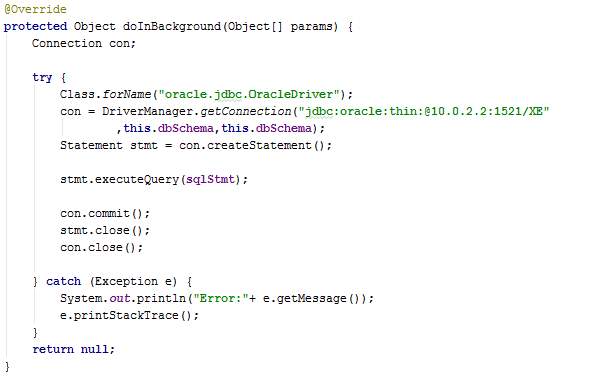
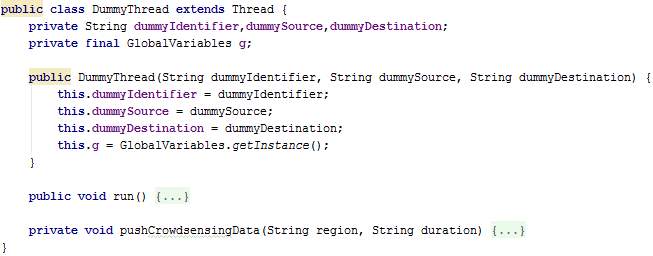
DummyThread.java
The class DummyThread extends thread in order to work independently in the background. Several DummyThread instances are created when StrictPrivacy mode is chosen. Each thread is programmed to mimic a random user by participating in mobile crowdsensing.
When executed, the thread performs a service request and receives a list of paths which from the specified source to the destination. A path is chosen randomly and the average duration of each route in the chosen path is stored. The thread sleeps for a duration close to the existing average duration (-1, same, or +1 minutes) and then send crowdsensing data to the server. In this way, the average duration of the routes are not distorted excessively due to dummy threads.

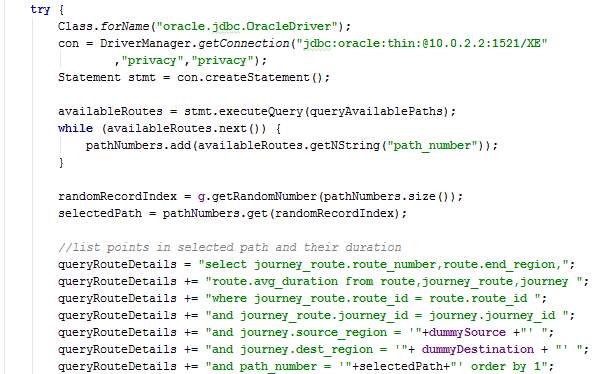
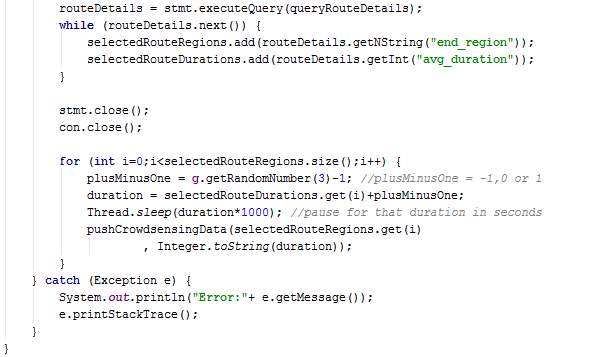
The method pushCrowdsensingData sends route duration for the dummy thread to the server.
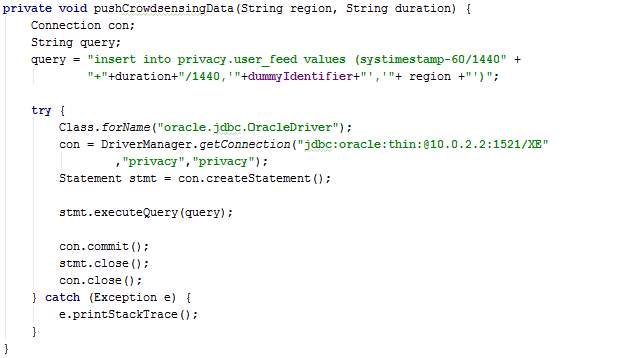
5.2 Database Server Implementation
This section describes the implementation of modules on the database (server-side).
5.2.1 Development Tools Used
Oracle SQL Developer 4.1.5 was used to create database objects in the Oracle database.
5.2.2 Hardware configurations
Since a computer is used, there are no specific hardware configurations that have to be done for the database. The oracle database has been installed in a computer with the following specifications:
- Processor: Core i7 @ 2.40 GHz
- RAM: 8 GB
- Operating system: Windows 10 64-bit
5.2.3 Implementation of the different modules
Two database schemas were created since StrictPrivacy mode requires a different architecture compared to HighPrecision mode. Moreover, data from these two modes needs to be separated for fairness and precision given that the HighPrecision mode does not send dummy data and provides precise location data. The schemas “Privacy” and “Precision” pertain to StrictPrivacy and HighPrecision modes respectively.
5.2.3.1 Privacy schema
The privacy schema consists of two main objects, namely, tables and procedures.
Tables
In this section, scripts for the creation of tables as designed in the ERD in section 4.3.3 are presented. The table names include journey, journey_route, processed_user_feed, region, route, user_feed, user_journey and route_<route_id>. The table name route_<route_id> represents table names for each route whereby <route_id> is the route’s identifier. Having a table for each route allows the implementation of MapReduce and prevents having a large amount of read-write on a single table.
The section table also consists of scripts for indexes and constraints creation.
Table: Journey
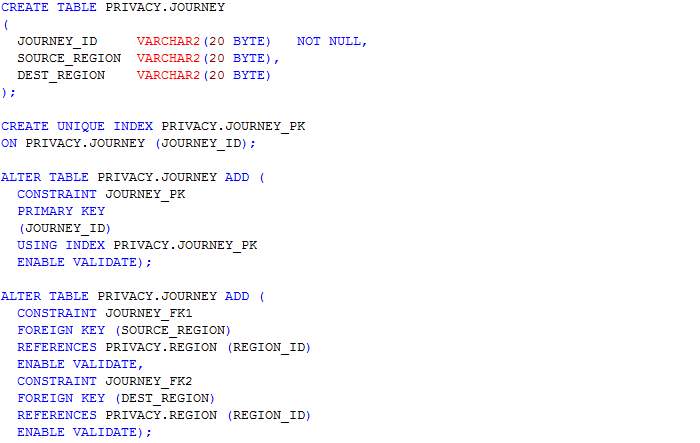
Table: Route
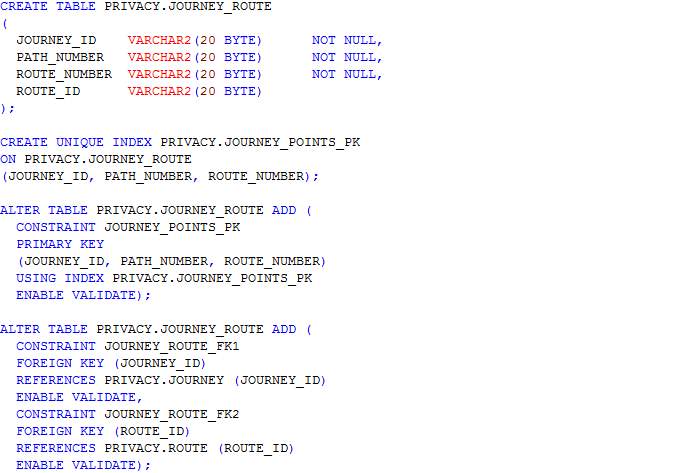
Table: Region
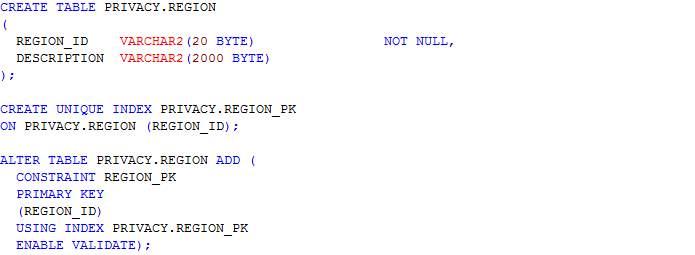
Table: Route
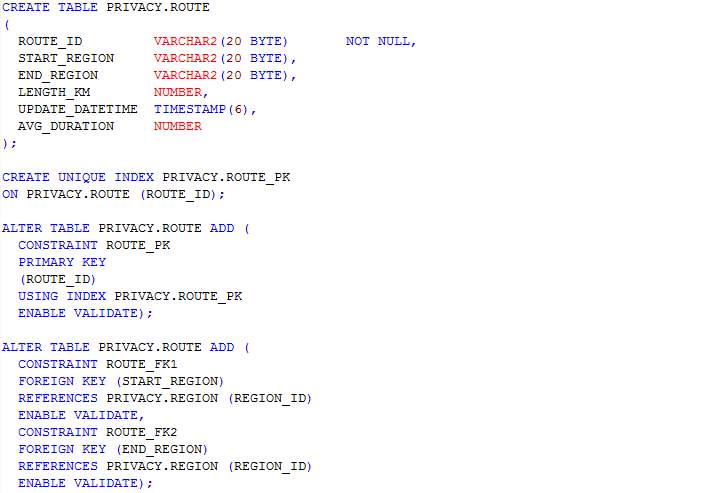
Table: User_feed
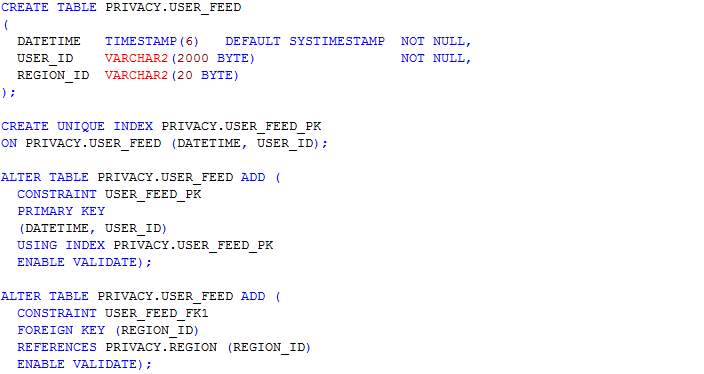
Table: Processed_user_feed

Table: User_journey
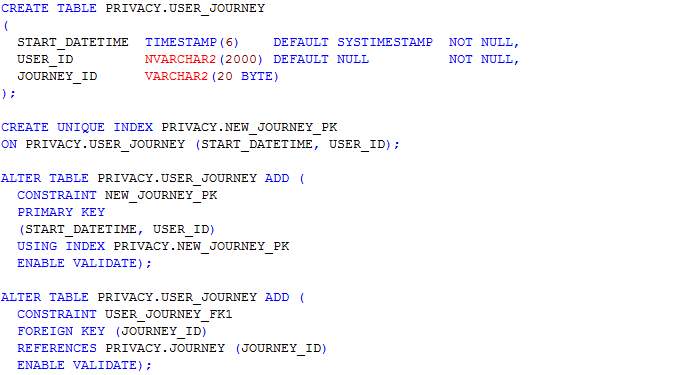
Table: Route_<route_id>

Procedures
Procedure: Import_data
This procedure reads the file created by the Crowdsensing Data Generator and inserts data in the tables User_journey and User_feed.

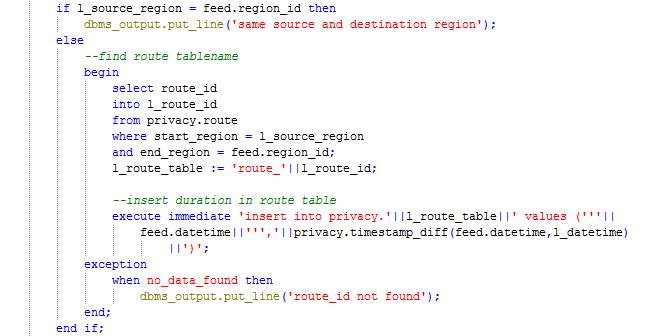
Procedure: Map
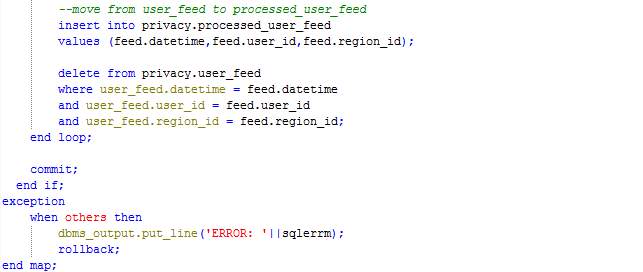
The procedure Map loops through the records in table User_feed and processes each record by calculating the time difference since the last feed sent by the user or start of the journey. The duration is inserted in the table corresponding to the route (route_<route_id>) and the record being processed is moved from the table User_feed to the table Processed_user_feed.
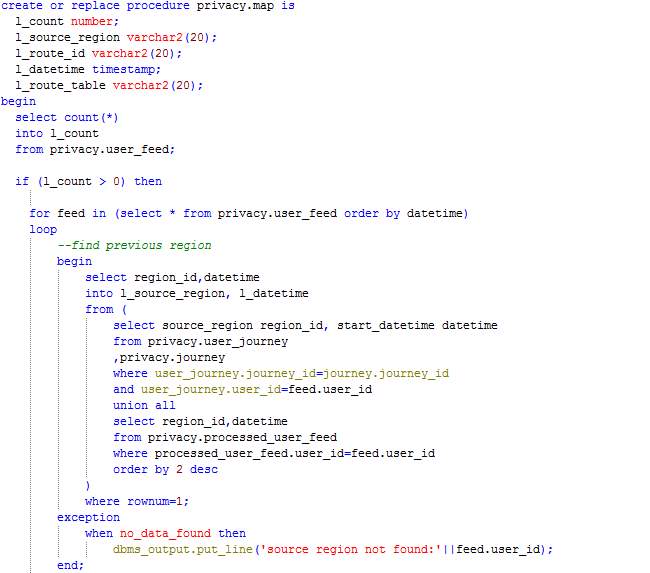
Procedure: Reduce
The procedure Reduce loops through each route table and calculates the average duration for each route in the past one hour. The table Route is then updated with the new route duration. If no feed has been received in the past one hour, the table Route is not updated.

5.2.3.2 Precision schema
Tables
In this section, scripts for the creation of tables as designed in the ERD in section 4.3.3 are presented. The table names include journey, journey_route, processed_user_feed, point, route, user_feed, user_journey and route_<route_id>. The tables are similar to those belonging to the Privacy schema except that the Precision schema has the table Point whereas the schema Privacy has table Region. Hence, the tables related have point_id instead of region_id.
The section table also consists of scripts for indexes and constraints creation.
Table: Journey
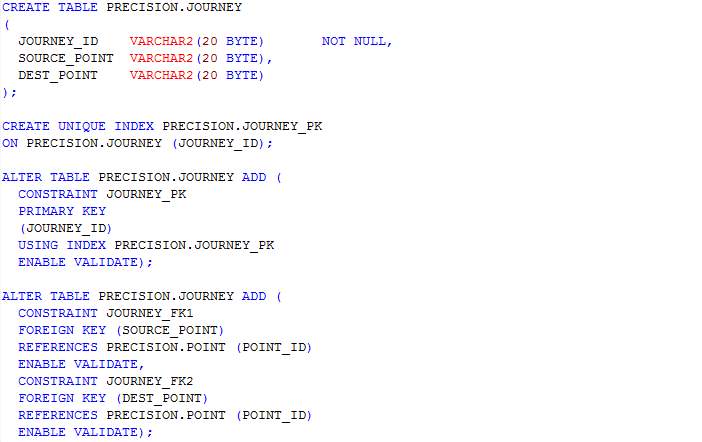
Table: Journey_route
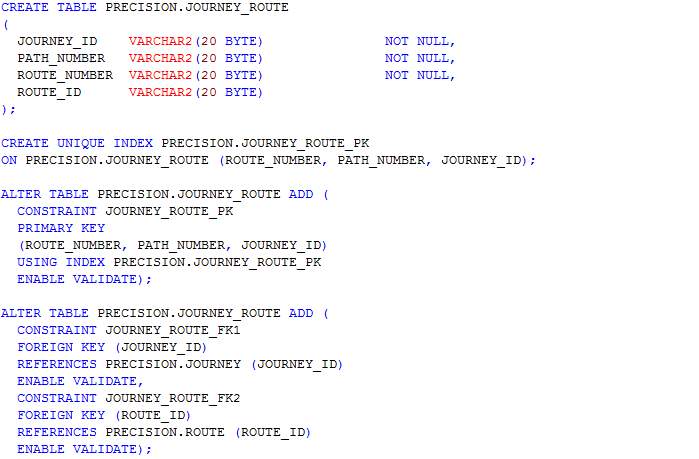
Table: Point
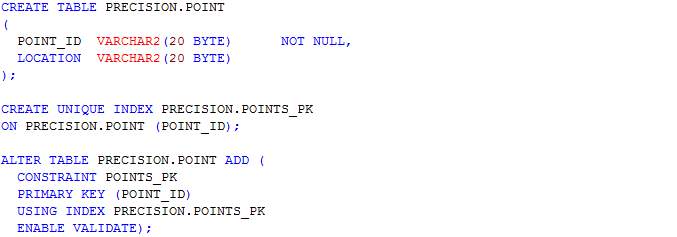
Table: Route
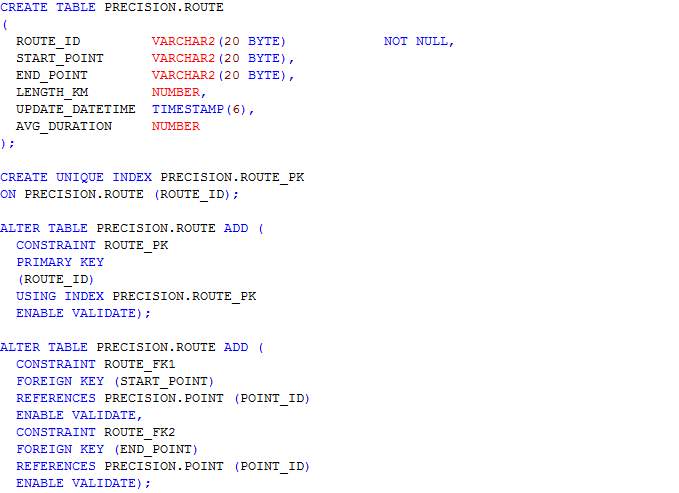
Table: User_feed
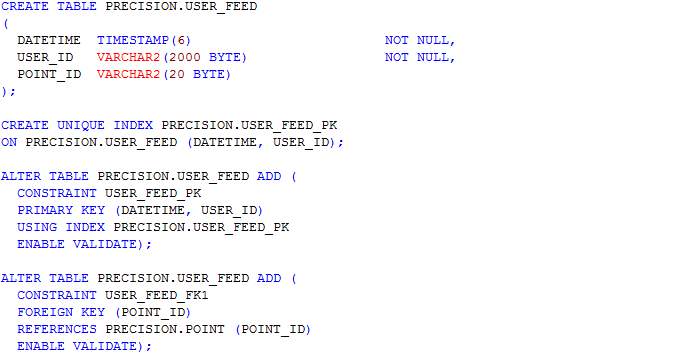
Table: Processed_user_feed

Table: User_journey
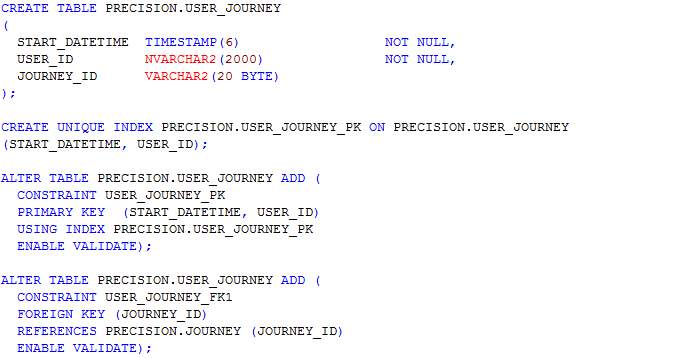
Table: Route_<route_id>
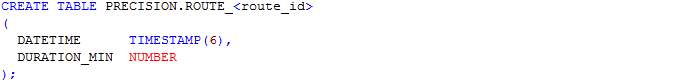
Procedures
Procedure: Import_data
The procedure Import_data is similar to the one belonging to the Privacy schema.

Procedure: Map
The procedure Map loops through the records in table User_feed and processes each record by calculating the time difference since the last feed sent by the user or start of the journey. The duration is inserted in the table corresponding to the route (route_<route_id>) and the record being processed is moved from the table User_feed to the table Processed_user_feed.
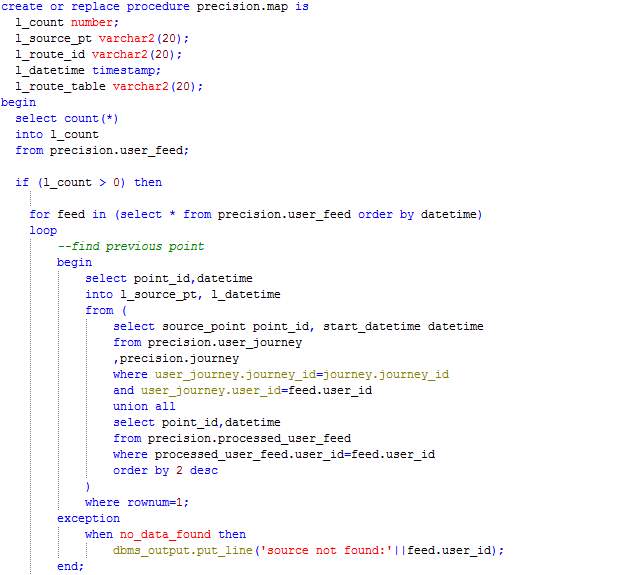
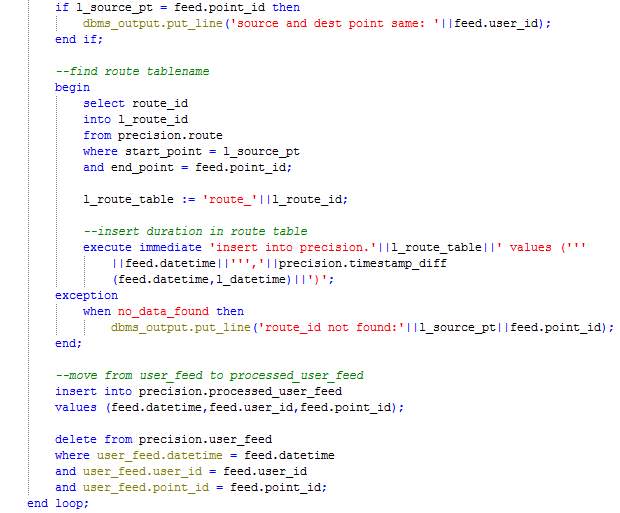

Procedure: Reduce
The procedure Reduce loops through each route table and calculates the average duration for each route in the past one hour. The table Route is then updated with the new route duration. If no feed has been received in the past one hour, the table Route is not updated.

5.2.4 User Interface
This section shows the implemented user interfaces as designed in section 4.2.4.
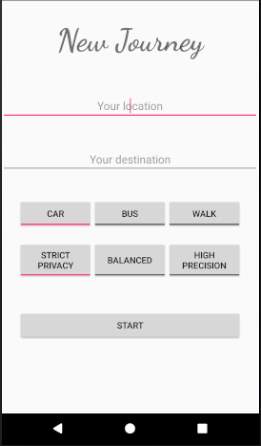
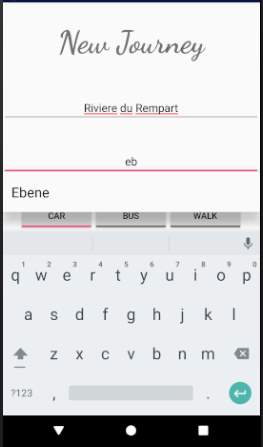
Figure 28: Service request screen Figure 29: AutoCompleteTextViews suggesting values
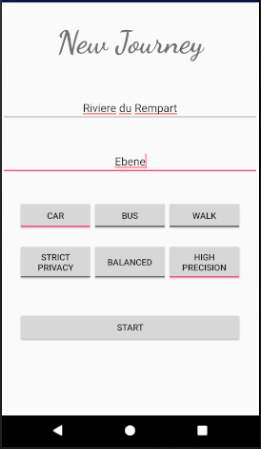
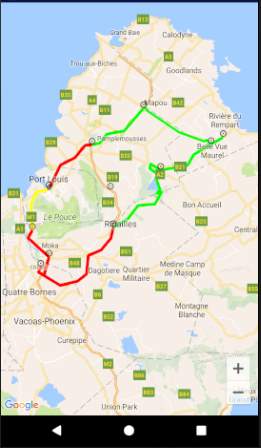
Figure 30: Service request with HighPrecision selected Figure 31: HighPrecision Service response screen
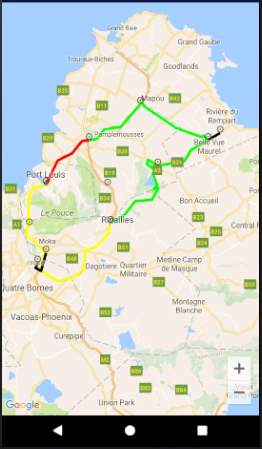
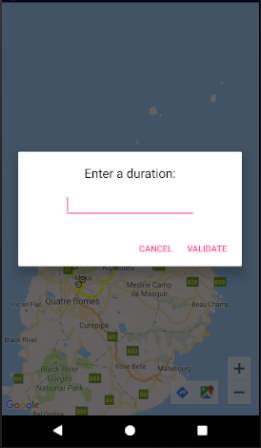
Figure 32: StrictPrivacy service response Figure 33: Data collection screen
(Routes with same region are coloured black)
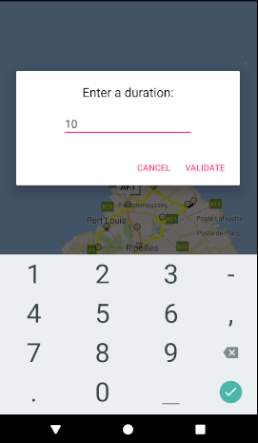
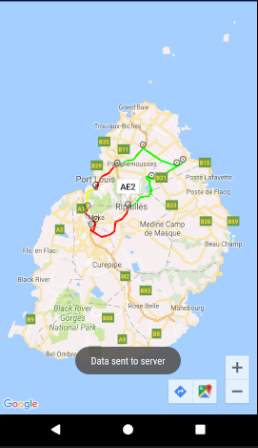
Figure 34: Data collection screen with input Figure 35: Message informing data is beng sent to server
5.3 Crowdsensing Data Generator Implementation
5.3.1 Development Tools Used
Eclipse IDE for Java Developers version 4.5.2 has been used to implement the Crowdsensing Data Generator.
5.3.2 Implementation of the different modules
The Crowdsensing Data Generator is a separate program which takes as input a number, representing the number of users for which data has be created, and outputs data to a file for import to the database. The program takes random email addresses from a pool of email addresses and randomly chooses a path for the chosen email address. The identifier is generated by calculating the hash value of the chosen email address concatenated with the source and a random number between 0 and 999999. The start time for the journey is also randomly calculated. Feeds are generated for each user at a random time and written to the file.
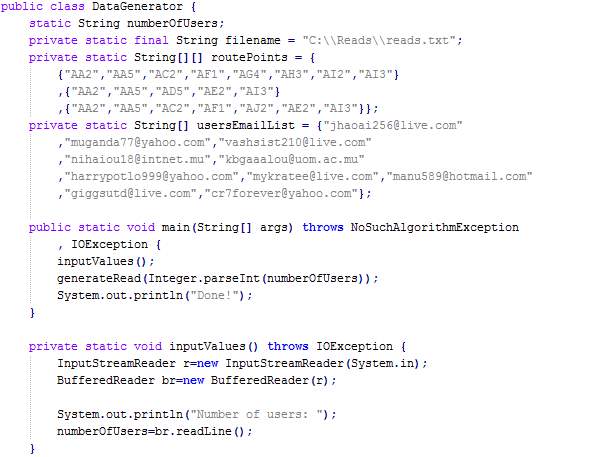


5.4 Chapter Summary
The implementation chapter consisted of sections, namely, mobile application implementation, database server implementation, and crowdsensing data generator implementation. Each of these sections included the development tools used, the hardware configurations and the description of the different modules implemented along with the screenshot of codes.
6 Testing
6.1 Static Testing
An automatic static analysis tool, called Android Lint, has been used to identify and correct problems with the structural quality of the Android application. The results obtained is shown below:
 Figure 36: Android Lint results
Figure 36: Android Lint results
| Issue # | Description | Action/Solution |
| 1 | Correctness > Obsolete Gradle Dependency | No action since an older version has been used deliberately to make the application compatible with more devices (having older versions of Android) |
| 2 | Performance > Unused resources | Unused resources have been removed since they make applications larger and slow down builds. |
| 3 | Security > Allow Backup
This feature allows application data to be backed up and can be later restored. By default, this feature is set to True. |
The backup feature has been disabled since application data can be extracted from mobile phones when USB debugging is ON and restored to another device to have full access to all data stored by the Android application. |
| 4 | Class structure > Field can be local | Variable moved to method |
| 5 | Data flow issues > Redundant local variable | Local variable removed |
| 6 | Explicit type can be replaced with <>.
Example: List<String> listName = new ArrayList<String>(); Can be converted to List<String> listName = new ArrayList<>(); |
No action since <> syntax is not supported under Java 1.6 or earlier JVMs. |
| 7 | ‘for’ loop replaceable with ‘foreach’ | For loop converted to foreach |
| 8 | Performance issues > Call to Arrays.asList() with too few arguments | Call to Collections.singletonList() is used instead in order to save memory. |
Table 5: Static testing solutions
The figures below show the corrections made as per the table above.
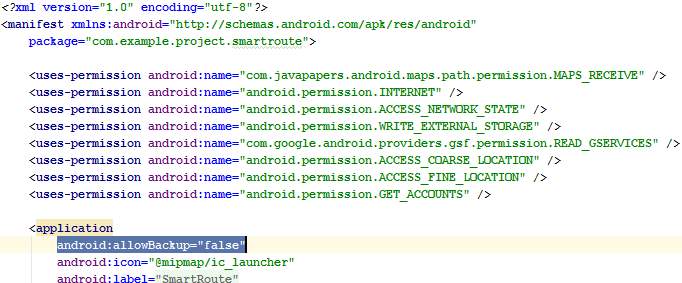
Figure 37: Issue #3 where AndroidManifest.xml has been modified to set the allowBackup flag to false
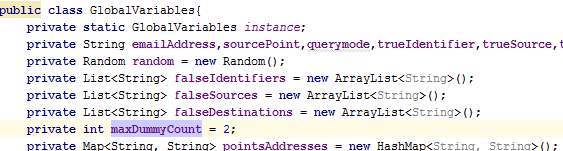
Figure 38: Issue #4 before correction where varable maxDummyCount is declared in class GlobalVariables
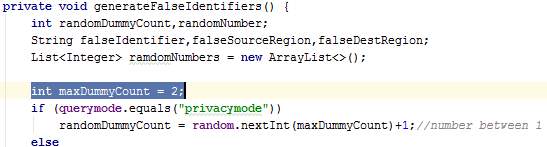
Figure 39: Issue #4 after correction whereby variable maxDummyCount is declared locally
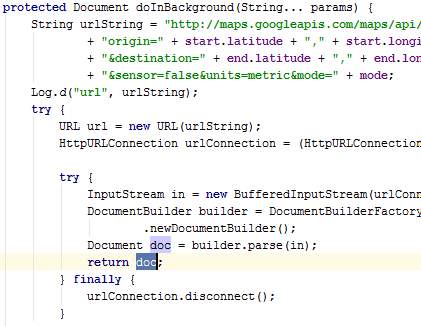
Figure 40: Issue #5 before correction where variable doc is redundant in class AsyncGMapDirection
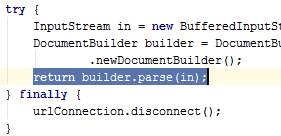
Figure 41: Issue #5 after correction where variable doc has been removed
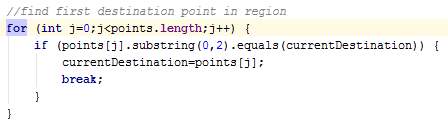
Figure 42: Issue #7 before correction where for loop is used in class AsyncPull
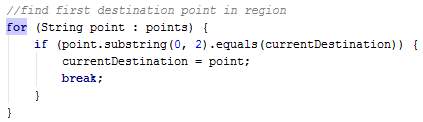
Figure 43: Issue #7 after correction where foreach is used
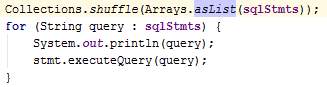
Figure 44: Issue #8 before correction where Arrays.asList() is used in class AsyncJourney

Figure 45: Issue #8 after correction where Collections.singletonList() is used instead

Figure 46: Issue #8 before corrction where Arrays.asList() is used in class GlobalVariables

Figure 47: Issue #8 after correction where Collections.singletonList() is used instead
6.2 Dynamic Testing
In this section, a functional testing of the MCS application is performed against the requirements listed in the section 3.1.13.1. Black-box testing method is used.
6.2.1 Test Cases
| Test Case # | Category | Description | Type of Data | Expected Result | Actual Result |
| 1 | Service request | Enter an incorrect source and click on Start | Invalid | User notified | An error message is displayed requesting the user to enter a correct source |
| 2 | Service request | Enter a correct source but an incorrect destination and click on start | Invalid | User notified | An error message is displayed requesting the user to enter a correct destination |
| 3 | Service request | No text is entered for source address | Extreme | User notified | A message is displayed requesting the user to enter a source address |
| 4 | Service request | No text is entered for destination address | Extreme | User notified | A message is displayed requesting the user to enter a destination address |
| 5 | Service request | Enter a correct source and destination | Valid | Input accepted | No error message displayed and next screen displayed |
| 6 | Process service requests | Crowdsensing data is processed to obtain duration for each route | Valid | Route table updated on DB | The procedures MAP() and REDUCE() are called. Tables involved are updated including route durations. |
| 7 | Service Response | A successful service request is performed and route details are fetched from server | Valid | Display route details | A map is displayed with routes coloured depending on congestion levels |
| 8 | Data contribution | Invalid time taken to travel a route is entered and Validate button is clicked | Invalid | User notified | A message is displayed at the bottom of the screen to request the user to input a duration again. |
| 9 | Data contribution | No value is entered for duration and Validate button is clicked | Extreme | User notified | A message is displayed at the bottom of the screen to request the user to input a duration again |
| 10 | Data contribution | A valid duration is entered and Validate button is clicked | Valid | Input accepted | A message is displayed to inform the user that the data is being sent to the server |
6.2.2 Test Results
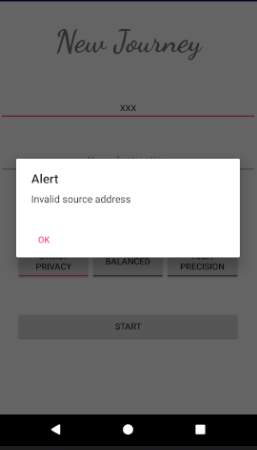
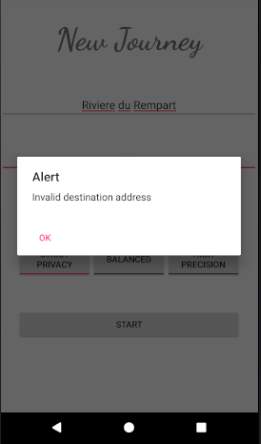
Figure 48: Results for test case #1 and #2
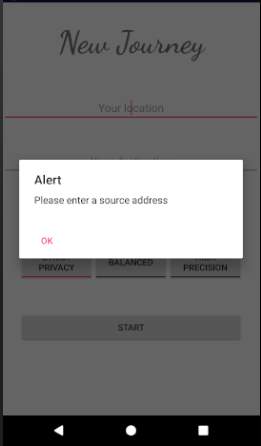
Figure 49: Results for test case #3 and #4
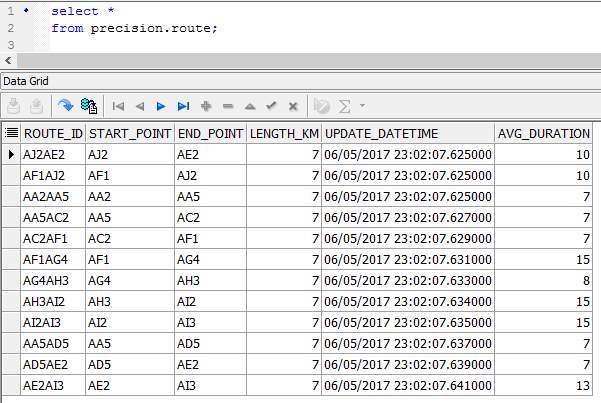
Figure 50: Results for test case #6
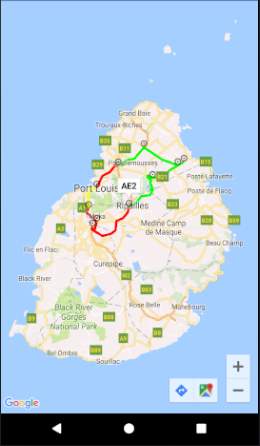
Figure 51: Results for test case #5 and #7
Figure 52: Result for test case #8 and #9
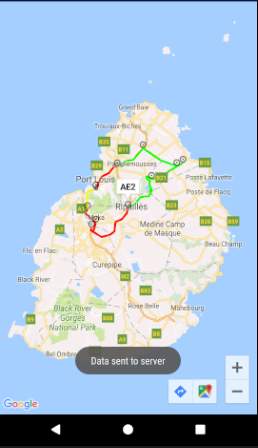
Figure 53: Results for test case #10
6.3 Chapter Summary
The testing chapter consisted of two testing methods, namely, static testing and dynamic testing. Static testing involved testing the application using Android Lint and the dynamic testing involved defining test cases and showing test results. All the warning obtained using static testing were corrected and the dynamic testing were successful.
7 Evaluation
In this section, the implementation is evaluated against the functional and non-functional requirements stated in section 3.1.
| ID | Description | Requirement
Status |
Proof |
| FR1 | The system shall allow a user to perform a service request. | Entirely met | Test case #5 |
| FR2 | The system shall process the service requests. | Entirely met | Test case #6 |
| FR3 | The system shall provide a response to the user. | Entirely met | Test case #7 |
| FR4 | The system shall allow users to contribute data periodically or in an ad-hoc manner. | Entirely met | Test case #10 |
| NFR1 | The system shall preserve the privacy of users. | Entirely met | Explained below |
| NFR2 | The mobile application should be compatible with most devices. | Entirely met | Android is compatible with most devices |
| NFR3 | The system shall keep minimum user information. | Entirely met | ERD in section 4.3.3 shows that only required |
| NFR4 | The system shall have a user-friendly interface. | Entirely met | The mobile application has been designed with simple and user-friendly screens comprising of AutoCompleteTextViews and toggle buttons for ease of input. |
| NFR5 | The system shall prevent erroneous input and alert the user when required. | Entirely met | Test case #1,2,3,4,8 and 9 |
| NFR6 | The system shall be responsive. | Entirely met | Several asynchronous tasks have been used in the application to make use of parallel processing and obtain results fast |
| NFR7 | The system should involve minimal costs. | Entirely met | The whole setup including the DB server has been implemented on a single computer |
Table 7: Evaluation of requirements
To prove NFR1, an extreme scenario is assumed whereby the attacker has accessed the whole database of the service provider (centralised server). Hence the attacker knows all data captured by users, users’ journeys, as well as processed information such as routes’ durations. The StrictPrivacy mode is used for the assessment.
To further worsen the scenario, it is assumed that the attacker has some background knowledge on users. The following table matrix shows which information can be acquired by the attacker if some of the attributes are already known by the attacker. A tick shows that the information can be known and a cross means that the information cannot be known.
| Query | Response | |
| Source | Destination | Trajectory |
| Known | Known | X |
| Known | X | Known |
| X | Known | Known |
Table 8: StrictPrivacy mode privacy evaluation
The most important attribute, namely user’s identity, is not present in the table above because the proposed system keeps users anonymous by using pseudo-identifiers for user identification. The pseudo-identifiers are meaningless since they are hashed values and brute forcing by hashing email addresses is not enough given that a random number in the range 0 to 999999 plus the user’s source have been concatenated to the email address. Moreover, a different identifier is used for users at each service request to make it impossible for the attacker to link several requests of a particular user. Therefore, the identity of users cannot be known.
In case the source and the destination of the users is already known by the attacker, the trajectory of the user will not be known since there will be several users having the same source and destination. The attacker may determine the best route, hence the most probable route used, if the former knows the exact time at which the user started his journey since the best routes changes with time. Moreover, there will be users or dummies using the other routes (not the best route) and the victim can be one of them. Therefore, the trajectory of a target user can only be guessed but not known for sure.
If the attacker knows the trajectory and the source of a user, the destination cannot be determined given that a route can lead to several destinations. Moreover, regions are kept instead of exact locations. The same logic applies to an unknown source.
In the case where all the 3 attributes are known and the attacker wish to know the current location of a target user, the exact location will not be known since crowdsensing data contributed by users include the regions and the user can be anywhere in that particular region. Moreover, the DB server does not have any information about the address of the regions. Only an identifier is stored for each region and the coordinates for each region is stored in the mobile application at the client-side.
The dummy threads, which imitates real users, are helpful in minimising the probability of correctly matching background knowledge with the data stored on the database by the attacker.
8 Conclusion & Future Works
This chapter summarises the overall contribution in this research work and some future works are proposed.
8.1 Conclusion
Undeniably, privacy preservation is a must to enable the widespread adoption of MCS applications. In this project, privacy issues were tackled in a specific type of LBMCS application whereby the client-server architecture is used. Existing privacy-preserving mechanisms were analysed thoroughly and a combination of mechanisms were derived to provide the desired security level. This combination of mechanisms has allowed the privacy of users to be adequately preserved in extreme conditions whereby the attacker gained access to the DB server and had background knowledge on users. The proposed solution not only concentrates on preserving privacy, but also has the ability to deal with big data. MapReduce was implemented to cope with large volumes of data since MCS comprises of big data. Moreover, the MCS application implemented is a powerful and promising one in the sense that it can provide real-time information about the congestion levels of routes. The popular Google Maps application provides static estimates of journey durations whereas the proposed MCS application provides more precise travel time estimates and the best routes can be chosen depending on actual congestion levels.
8.2 Future works
There are several features and enhancements which could not be implemented due to time constraint. Firstly, the transportation modes Bus and Walk can be implemented to allow users travelling by bus or walking to use the application. The balanced mode which consists of a combination of parts of the StrictPrivacy and the HighPrecision modes can be implemented. It will provide both privacy and precision while taking into consideration the trade-off between privacy and precision. An enhancement to the proposed system can be to make the application intelligent and able to analyse regions in order to automatically adjust region sizes and number of points in each region depending on the number of users in that region. Another enhancement can be the ability to analyse crowdsensing data and reject the incorrect or biased ones.
References
- Android, n.d. Android Developer. [Online]
Available at: https://developer.android.com/guide/platform/index.html
[Accessed April 2017]. - Anon., 2003. National Computer Board: Computer Misuse and Cybercrime Act. [Online]
Available at: http://www.ncb.mu/English/Legislations/Pages/Computer-Misuse-and-Cybercrime-Act-2003.aspx
[Accessed 2017]. - Assunção, M. D. et al., 2015. Big Data computing and clouds: Trends and future directions. J. Parallel Distrib. Comput0, pp. 3-15.
- Bal, H. & Hujol, J., 2007. Java for Bioinformatics and Biomedical Applications. s.l.:Springer Science & Business Media.
- Bhatlavande, A. S. & Phatak, A. A., 2015. Data Aggregation Techniques in Wireless Sensor Networks: Literature Survey. International Journal of Computer Applications, 115(10).
- Chakraborty, N. & Patra, G. K., 2014. Functional Encryption for Secured Big Data Analytics. International Journal of Computer Applications, 107(16).
- Council of Europe, 2001. Budapest Convention and related standards. [Online]
Available at: https://www.coe.int/en/web/cybercrime/the-budapest-convention
[Accessed 2017]. - Davenport, T. & Harris, J., 2007. Competing on Analytics: The New Science of Winning. Harvard Business Review Press.
- Davenport, T., Harris, J. & Morison, R., 2010. Analytics at Work: Smarter Decisions, Better Results. Harvard Business Review Press.
- Davey, J., Mansmann, F., Kohlhammer, J. & Keim, D., 2012. Visual Analytics: Towards Intelligent Interactive Internet and Security Solutions. In: The future internet. s.l.:s.n., pp. 93-104.
- Dijk, M. v. & Juels, A., 2010. On the Impossibility of Cryptography Alone for Privacy-Preserving Cloud Computing. Proceeding HotSec’10 Proceedings of the 5th USENIX conference on Hot topics in security.
- Dwork, C., 2006. Differential privacy. 33rd International Colloquium on Automata, Languages and Programming, part II (ICALP 2006).
- Dwork, C., 2011. The Promise of Differential Privacy: A Tutorial on Algorithmic Techniques. Proceeding FOCS ’11 Proceedings of the 2011 IEEE 52nd Annual Symposium on Foundations of Computer Science.
- Elgendy, N. & Elragal, A., 2014. Big Data Analytics: A Literature Review Paper. Advances in Data Mining. Applications and Theoretical Aspects.
- Emam, K. E. & Dankar, F. K., 2008. Protecting Privacy Using k-Anonymity. Journal of the American Medical Informatics Association, 15(5).
- Ericsson, 2016. Ericsson Mobility Report, s.l.: s.n.
- Fourment, M. & Gillings, M. R., 2008. A comparison of common programming languages used in bioinformatics. BMC Bioinformatics, 9(82).
- Gandomi, A. & Haider, M., 2014. Beyond the hype: Big data concepts, methods, and analytics. International Journal of Information Management, 35(2), pp. 137-144.
- Ganti, R. K., Ye, F. & Lei, H., 2011. Mobile Crowdsensing: Current State and Future Challenges. IEEE Communications Magazine, 49(11), pp. 32-39.
- Gilbert, P., Cox, L. P., Jung, J. & Wetherall, D., 2010. Toward Trustworthy Mobile Sensing. HotMobile.
- Goldschlag, D., Reed, M. & Syverson, P., 1999. Onion routing for anonymous and private internet connections. Communications of the ACM, pp. 39-41.
- González, M. C., Hidalgo, C. A. & Barabási, A.-L., 2008. Understanding individual human mobility patterns. Nature, pp. 779-782.
- Gruteser, M. & Grunwald, D., 2003. Anonymous Usage of Location-Based Services Through Spatial and Temporal Cloaking. Proceedings of the 1st international conference on Mobile systems, applications and services, pp. 31-42.
- Guo, B., Yu, Z., Zhou, X. & Zhang, D., 2015. From Participatory Sensing to Mobile Crowd Sensing. ACM Computing Surveys (CSUR), 48(1).
- Iida, I. & Morita, T., 2012. Overview of Human-Centric Computing. FUJITSU Sci. Tech. J., 48(2), pp. 124-128.
- K.Deepika, et al., 2014. A Survey on Approaches Developed for Data Anonymization. International Advanced Research Journal in Science, Engineering and Technology, 1(3).
- Kaisler, S., Armour, F., Espinosa, J. A. & Money, W., 2013. Big Data: Issues and Challenges Moving Forward. System Sciences (HICSS), 2013 46th Hawaii International Conference.
- Kargupta, H. & Datta, S., 2003. Random data perturbation techniques and privacy preserving data mining. IEEE International Conference on Data Mining.
- Kerr, A., 2011. Using R: a guide for complete beginners | The Bioinformatics Knowledgeblog. [Online]
Available at: http://bioinformatics.knowledgeblog.org/2011/06/21/using-r-a-guide-for-complete-beginners/
[Accessed 6 March 2015]. - Labrinidis, A. & Jagadish, H., 2012. Challenges and opportunities with big data. Proceedings of the VLDB Endowment 5(12):2032-2033.
- Laney, D., 2001. 3D Data Management Controlling Data Volume, Velocity, and Variety. Application Delivery Strategies.
- Li, N., Li, T. & Venkatasubramanian, S., 2007. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. 23rd IEEE International Conference on Data Engineering.
- Machanavajjhala, A., Gehrke, J. & Kifer, D., 2006. l-Diversity: Privacy Beyond k-Anonymity. Proceedings of ICDE, p. 24.
- Martin, J., 2014. C# Compiler Released As Open Source. [Online]
Available at: http://www.infoq.com/news/2014/04/roslyn_oss
[Accessed 5 March 2015]. - Mokbel, M. F., 2007. Privacy in Location-Based Services: State-of-the-Art and Research Directions. Mobile Data Management, 2007 International Conference.
- Narayanan, A. & Shmatikov, V., 2008. Robust De-anonymization of Large Sparse Datasets. Proceedings of the 2008 IEEE Symposium on Security and Privacy, pp. 111-125.
- Orwant, J., 2003. Games, Diversions & Perl Culture: Best of the Perl Journal. 1st ed. s.l.:O’Reilly Media, Inc..
- Pedersen, T. B., Saygın, Y. & Sava, E., 2007. Secret Sharing vs. Encryption-based Techniques For Privacy Preserving Data Mining. Sciences-New York.
- Peritus, n.d. Outsourced Software Product Development. [Online]
Available at: http://www.peritusglobal.com/expertise.php?id=5
[Accessed October 2016]. - Pournajaf, L., Garcia-Ulloa, D. A., Xiong, L. & Sunderam, V., 2015. Participant Privacy in Mobile Crowd Sensing Task Management: A Survey of Methods and Challenges. SIGMOD Record, 44(4).
- Ras, Z. W. & Li-Shiang, T., 2009. Advances in Intelligent Information Systems. s.l.:Springer.
- Reiter, M. K. & Rubin, A. D., 1998. Crowds: anonymity for Web transactions. ACM Transactions on Information and System Security, 1(1), pp. 66-92.
- R, P. A. & K, A. V., 2016. Enforcing Security for Smartphone user by Crowdsourcing Model Using Internet of Things. International Journal of Advanced Research in Computer Science & Technology (IJARCST 2016), 4(2).
- Rubner, Y., Tomasi, C. & Guibas, L. J., 2000. The earth mover’s distance as a metric for image retrieval. International Journal of Computer Vision, pp. 99-121.
- Russom, P., 2011. Big Data Analytics. TDWI Research.
- Sherchan, W. et al., 2012. Using On-the-Move Mining for Mobile Crowdsensing. Mobile Data Management (MDM), 2012 IEEE 13th International Conference.
- Sweeney, L., 2000. Simple Demographics Often Identify People Uniquely. Data Privacy Working Paper 3.
- Sweeney, L., 2002. k-ANONYMITY: A MODEL FOR PROTECTING PRIVACY. International Journal on Uncertainty,Fuzziness and Knowledge-based Systems, 10(5), pp. 557-570.
- Sweeney, L. & Samarati, P., 1998. Protecting Privacy when Disclosing Information: k-Anonymity and Its Enforcement through Generalization and Suppression. Technical Report SRI-CSL-98-04.
- Talasila, M., Curtmola, R. & Borcea, C., 2015. Handbook of Sensor Networking: Advanced Technologies and Applications. s.l.:CRC Press.
- Yi, X., Paulet, R. & Bertino, E., 2013. Private Information Retrieval. s.l.:s.n.
- Zhang, D., Wang, L., Xiong, H. & Guo, B., 2014. 4W1H in mobile crowd sensing. IEEE Communications Magazine, 52(8).
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Internet of Things"
Internet of Things (IoT) is a term used to describe a network of objects connected via the internet. The objects within this network have the ability to share data with each other without the need for human input.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: