Altering availability or proximity of food, alcohol or tobacco products for changing their selection and consumption
Info: 12017 words (48 pages) Dissertation
Published: 18th Feb 2022
Tagged: Health and Social Care
BACKGROUND
Description of the condition
Non-communicable diseases, principally cardiovascular diseases, diabetes, certain forms of cancer and chronic respiratory diseases, accounted for an estimated 68% of all deaths worldwide in 2012 (WHO 2016). Major risk factors for these conditions are in part determined by patterns of behaviour that are in principle modifiable, including consumption of food, alcohol and tobacco products. Identifying interventions that are effective in achieving sustained health behaviour change has therefore become one of the most important public health challenges of the 21st century.
Description of the intervention
It is increasingly recognised that the physical environments that surround us can exert considerable influences on our health-related behaviours and that altering these environments may provide a catalyst for behaviour change (Das 2012; Marteau 2012). In a recent systematic scoping review, we described a set of interventions that involve altering the small-scale physical environment – or physical micro-environment – with the intention of changing health-related behaviours (Hollands 2013a; Hollands 2013b). Such interventions, which could also be described as choice architecture (or nudge) interventions under different terminology, involve changes to the placement or properties of objects or stimuli within environments such as shops, restaurants, bars or homes.
These interventions have received increased policy and research interest in recent years as a result of several factors including shifts in theoretical understanding and some supportive preliminary empirical evidence (Marteau 2015). Their standing has also likely been influenced by political acceptability (with governments preferring ‘light-touch’ intervention rather than legislation and regulation), public acceptability (with preliminary evidence suggesting these types of interventions are relatively acceptable (Petrescu 2016)), and feasibility and likely cost (such interventions may be perceived as inexpensive and easily implemented without complex legislative or regulatory processes or the need for individual delivery).
The placement of food, alcohol and tobacco products within the physical environment can influence their selection and consumption. Within our provisional typology of physical micro-environment interventions, generated as an outcome of the aforementioned scoping review (Hollands 2013a), we proposed that ‘placement’ interventions comprise two key, more specific intervention types.
First, there are interventions targeting the ‘availability’ of products within a specific environment. An example would be the reduction of the number of high-fat meal options in a school cafeteria (Bartholemew 2006).
Second, there are interventions targeting the positioning of those products that are available.
The term we have used – ‘proximity’ – reflects the fact that the predominant intervention of this type within the current context involves moving food, alcohol or tobacco products closer to or further away from people in order to alter the degree of convenience, and of effort required to engage with the product. An example would be placing a healthy product such as fruit in a convenient position within a shop to encourage its purchase (Kroese 2015).
Whilst there are likely other ways of altering the positioning of products that do not impact on their proximity, we have purposefully limited our scope to proximity interventions. This is because any such other studies would be difficult to assess within the same framework specified for use in the current review, which focuses on the effects of altering the quantity or degree (i.e. increase vs decrease; high vs low) of a specific property (i.e. availability, proximity).
How the intervention might work
There are considerable influences on behaviour that are beyond individuals’ deliberative control. Indeed, it has been suggested that most human behaviour occurs outside of awareness, cued by stimuli in environments and resulting in actions that may be largely unaccompanied by conscious reflection (Hollands 2016; Marteau 2012; Neal 2006). This proposition has led to increasing policy and research attention being placed on interventions with mechanisms of action that are less dependent on the conscious engagement of the recipients, including interventions that involve altering the placement of objects within the physical environments that surround and cue behaviour.
Various mechanisms of action have been proposed for both availability and proximity interventions. In relation to availability, whether options are available (or absent) within a given environment inevitably shapes and constrains people’s possible responses. The more available product options that there are, the more likely it is that an actor will encounter an option they are willing to select or consume (Chernev 2011), particularly given the ‘mere-exposure’ effect, whereby simple repeated exposure to a product can elicit increased liking (Dalenberg 2014). Therefore, increasing the range of options for a given product or category should increase its selection or consumption – although this is of course subject to people engaging with the product in the first place, which will be influenced by many factors, including characteristics of the person (such as hunger) and of the product (such as its attractiveness or healthiness).
Furthermore, it has been suggested that if the range of available products is increased, choosing between these options becomes more reliant on a reasoning process, meaning that people may be more likely to choose those options that are easier to justify, such as more healthy options (Sela 2009). If the range of product options does not increase but the amount of units of those available products does, this may increase their degree of visibility or salience and therefore encourage selection or consumption.
In relation to proximity, the central role of physical and mental effort has been highlighted (Wansink 2004; Bar-Hillel 2015). Humans tend to take the least effortful course of action without the need for conscious deliberation, and so physical environments can shape responses by capitalising on this phenomenon. Consequently, products placed nearer an actor require less effort to obtain than do those placed farther and this may correspondingly impact on motivation to select or consume them. Other than the effort needed (or perceived as such), more distal products may also be less visible and less salient (Maas 2012). Increasing physical distance may increase ‘psychological distance’ – the subjective experience of distance from the self in that time and place (Trope 2010) – and so more distal products may be focused on less prominently or subject to more deliberation or rationalisation. It should also be noted that whilst increasing distance should in theory decrease how often a product is selected or consumed (i.e. frequency), it is possible that it may still increase overall levels of selection or consumption (i.e. amount). This is because those who have performed the effortful behaviour of selecting a product may compensate for that effort by selecting or consuming more of it.
Why it is important to do this review
A recent systematic scoping review of evidence for the effects of physical micro-environment interventions identified a substantial number of randomised controlled trials that have investigated the effects of altering availability and proximity of products on health-related behaviours (Hollands 2013a). The majority of these studies focused on food products, where intervention has significant potential given the necessity of their consumption and their ubiquity within many environments. However, because both tobacco and alcohol use also involve the selection and consumption of products, such interventions may also have the potential to change these behaviours via similar mechanisms.
We propose synthesising evidence for the effects of availability and proximity interventions within a single systematic review because we conceptualise them both as interventions that alter the placement of products within physical micro-environments. To our knowledge, evidence from these studies has yet to be synthesised using rigorous systematic review methods that include assessment of risk of bias and investigation of potential effect modifiers, nor to encompass alcohol and tobacco use, although parts of this evidence base have been reviewed (Grech 2015). As such, we do not yet have reliable estimates of the effects of these types of interventions on product selection and consumption, nor of the influence of factors that may modify any such effects.
Both are necessary to inform the selection and design of effective public health interventions, particularly given increasing research and policy interest in interventions that alter the physical environment to make unhealthier behaviours less likely and healthier behaviours more likely. This interest is evidenced by the substantial public and policy interest in a previous Cochrane review on portion, package and tableware size (Hollands, Shemilt, 2015), which has had an impact on policy documents in the UK and Australia (cite Kirsty Jones et al 2016 Journal of Public Health article; and Public Health England Report ‘Sugar Reduction: The evidence for action’).
It has been found that person-centred behaviour change interventions that focus on provision of educational information to individuals and encourage them to make active choices potentially widen health inequalities (Lorenc 2013; McGill 2015). Interventions that instead aim to alter the environments that people are exposed to and are less reliant on conscious, reflective engagement, may have greater potential to reduce, or at least not increase, health inequalities. It has been suggested that this may be because they rely less on recipients’ levels of literacy, numeracy and cognitive control, which have been found to be lower in population subgroups experiencing higher levels of social and material deprivation (Marteau and Hall BMJ; Spears 2010).
The current review therefore includes a focus on identifying evidence for differential effects of exposure to these interventions between socioeconomic subgroups within studies, and between studies conducted in LMIC and high-income countries (HIC). This will enable us to highlight any identified gaps in this aspect of the evidence base, and seek to draw implications for the potential of such interventions to affect health inequalities.
OBJECTIVES
- To assess the impact of altering the availability or proximity of food products on their selection or consumption;
- To assess the impact of altering the availability or proximity of alcohol products on their selection or consumption;
- To assess the impact of altering the availability or proximity of tobacco products on their selection or consumption;
- For each of the above, to assess the extent to which the impact of such interventions is modified by: i) study characteristics, ii) intervention characteristics, iii) participant characteristics.
METHODS
Criteria for considering studies for this review
Types of studies
Randomised or cluster-randomised controlled trials with between-subjects (parallel group) or within-subjects (cross-over) designs, conducted in laboratory or field settings. We will exclude non-randomised studies because a recent scoping review indicates that a sufficient number of eligible randomised studies will be available to enable quantitative synthesis of evidence for intervention effects using meta-analysis (Hollands 2013a). An additional consideration is that compared with randomised controlled trials, non-randomised studies rely on more stringent and sometimes non-verifiable assumptions in order to confer confidence that the risk of systematic differences between comparison groups beyond the intervention of interest (i.e. confounding) is sufficiently low to permit valid inferences about causal effects. If randomised assignment is not clear in studies considered otherwise eligible for inclusion at the full-text assessment stage, we will only include the study if study authors confirm that randomisation occurred.
Types of participants
Adults and children exposed to the interventions, but we will exclude studies where the product is being selected and fed directly by one person to another (e.g mother-child dyads). We will set no other exclusion criteria in relation to demographic, socioeconomic or clinical characteristics. We will exclude studies involving non-human participants (i.e. animal studies).
Types of interventions
Interventions eligible to be considered in this review are those that involve altering the availability or proximity of food, alcohol or tobacco products within what can be termed physical micro-environments – defined here as small-scale physical environments where people gather for specific purposes and activities, such as restaurants, workplaces, schools, homes, bars, supermarkets and shops (Swinburn 1999). We define availability interventions and proximity interventions separately below.
Availability interventions
Interventions eligible to be considered in this review are those that involve comparing the effects of exposure to at least two differing (i.e. higher versus lower) levels of availability of a manipulated food, alcohol or tobacco product. This will allow us to examine whether, for example, making a food more available increases its consumption, or making a food less available decreases its consumption. Availability can be manipulated by providing the following:
a) A greater or lesser range of different options of a product;
b) A greater or lesser available amount (number) of discrete units of a product;
c) A combination of a) and b).
The product can be operationalised at varying levels of specificity and as such could apply to types of a specific product (e.g. fruit, chocolate bars) or to broader categories of products (e.g. energy-dense snack foods; low-fat meals). The nature of these potential interventions can be illustrated by examples from the three product types that the review will focus on:
a) A greater or lesser range of different options of a product:
Food – a narrower range of types of chocolate bar on display in a supermarket; a wider range of low-fat meal options available in a restaurant;
Alcohol – a wider range of types of wine or beer in a bar or pub;
Tobacco – a narrower range of types of cigarettes in a shop.
b) A greater or lesser available amount (number) of discrete units of a product;
Food – a lesser amount of an entire range of chocolate bars, or of particular types of chocolate bar within that range, on display in a supermarket; a greater amount of a range of low-fat meal options, or of particular products within that range, available in a restaurant;
Alcohol – a greater amount of an entire range of wines or beers, or of particular products within that range, in a bar or pub;
Tobacco – a lesser amount of an entire range of cigarettes, or of particular products within that range, in a shop.
For alcohol and tobacco products, we will also consider including interventions in which the availability of specific recognised alternatives to those products that are not themselves alcohol and tobacco products is manipulated within alcohol or tobacco selection and consumption contexts (e.g. alcohol-free drinks in the case of alcohol, and e-cigarettes in the case of tobacco).
Additional inclusion criteria:
The comparison of different levels of availability must be explicitly described, as opposed to this being inferred by the review team. For example, a reviewer could infer that a supermarket sales promotion might increase the number of products on display in store, but a study would only be included if this alteration was clearly stated by authors.
We will include multi-component interventions in which there are concurrent intervention components that are unrelated to availability, providing those additional components are implemented wholly within the same micro-environment as the product is located and are limited to changes to the product itself or to its proximal physical environment. Examples include labelling on the product itself, or promotional signage placed near to the product.
We will exclude:
Multi-component interventions in which there are concurrent intervention components that are unrelated to availability, where those additional components are not implemented wholly within the same micro-environment as the product is located or extend beyond changes to the product itself or to its proximal physical environment. Examples of such ineligible intervention components include health education programmes and widespread marketing campaigns.
Interventions in which availability may be altered indirectly as a result of a higher-level intervention but is not directly and systematically altered (e.g. organisational-level interventions to encourage the wider availability of healthier products within a workplace or set of workplaces, or national- or regional-level policy interventions to encourage schools to modify their environments). While changes in availability may be achieved as a result of the higher-level intervention, this is not directly manipulated to safeguard implementation fidelity.
Interventions within analogue studies that do not manipulate real food, alcohol or tobacco products but instead may use written vignettes, computer or questionnaire tasks, or mock products to assess the impact of altering availability.
Interventions where the range of product options is unchanged in terms of the different types or categories of products that are available but changes are made in the range of ways in which those same products are formulated or presented (e.g. flavour, energy-density, colour, size or shape).
Interventions where the environmental contexts or opportunities for selection and consumption are not comparable in intervention and control groups. Therefore, we will exclude interventions that involve removing (or adding) the entire range of food, alcohol or tobacco products (e.g. studies examining the effectiveness within a specified environment of complete smoking or alcohol bans), as well as those which involve substantial changes to the infrastructure of the environment. We will also exclude interventions where availability differs between intervention and control due to additional exposure to foods via assigned dietary programmes (e.g. prescribed diets), education (e.g. taste-testing sessions, cooking lessons or food education) or other means of free or prescribed distribution of products to participants.
Interventions where the availability of a product is not altered in terms of its range or amount but as a result of temporal (e.g. changing hours of sale) or spatial (e.g. changing the places in which a product can be selected or consumed) factors.
Proximity interventions
Interventions eligible to be considered in this review are those that involve comparing the effects of exposure to at least two differing (i.e. higher versus lower) levels of proximity of a manipulated food, alcohol or tobacco product. Proximity interventions are those in which the spatial positioning of products within environments is altered with the intention of reducing or increasing the distance to be travelled necessary for any potential consumers to select or consume them. To enable this, the proximity of a product (how close or far away it is) is altered in relation to key points in environments that are specified by those intervening, such as typical or expected walking routes, building entrances, checkouts in supermarkets or shops, or seating.
Examples include positioning a display of food products close to a shop’s entrance (placed 1 metre from the entrance), allowing convenient selection of the products, versus this being located at a distance that requires customers to walk a substantial distance to engage with the display (placed 20 metres from the entrance). Alternatively, altering the positioning of a food product to be within easy arm’s reach of a potential consumer seated in a chair (placed 20cm from the chair) versus requiring them to leave the chair and walk to select the food product (placed 2 metres from the chair).
Additional inclusion criteria:
The comparison of different levels of proximity must be explicitly described, as opposed to this being inferred by the review team. For example, a reviewer could infer that a redesigned layout of a cafeteria or restaurant might increase or decrease proximity from a given point of reference, but a study would only be included if this change in proximity was clearly stated by authors.
We will include multi-component interventions in which there are concurrent intervention components that are unrelated to proximity, providing those additional components are implemented wholly within the same micro-environment as the product is located and are limited to changes to the product itself or to its proximal physical environment. Examples include labelling on the product itself, or promotional signage placed near to the product.
We will exclude:
Multi-component interventions in which there are concurrent intervention components that are unrelated to proximity, where those additional components are not implemented wholly within the same micro-environment as the product is located or extend beyond changes to the product itself or to its proximal physical environment. Examples of such ineligible intervention components include health education programmes and widespread marketing campaigns.
Interventions in which proximity may be altered indirectly as a result of a higher-level intervention but is not directly and systematically altered (e.g. organisational-level interventions to encourage the redesign of the layout of school or workplace cafeterias). While changes in proximity may be achieved as a result of the higher-level intervention, this is not directly manipulated to safeguard implementation fidelity.
Interventions within analogue studies that do not manipulate real food, alcohol or tobacco products but instead may use written vignettes, computer or questionnaire tasks, or mock products to assess the impact of altering proximity.
Interventions in which the proximity of text, symbols or images that relates to products is altered (e.g. on a sign, advertisement, poster, menu, leaflet or computer screen), but the proximity of the actual products to be selected or consumed is not.
Types of outcome measures
Primary outcomes
Behavioural endpoints
Eligible studies must incorporate one or more measures of unregulated consumption or selection (with or without purchasing) of food, alcohol or tobacco products subject to manipulation. By unregulated, we refer to behaviour of participants that is not regulated by either explicit instructions or some other action of the researcher. For example, we will exclude studies that manipulate the availability of the constituent foods within meals that are plated or served not under the direction of the participant, and given to participants with the instruction to select or consume them. Eligible studies may have measured consumption or selection in terms of the manipulated products only, or also include an assessment of non-manipulated products. For example, a study investigating the effects of increasing the availability or proximity of fruit within a shop on healthier purchasing, may include a specific measure of fruit (i.e. the manipulated product) selected only, or a broader measure that encompasses both fruit selection and selection of other non-fruit options (e.g. a measure of selection of all healthier food options).
There may also be a specific measure of selection of other non-fruit options only. Quantities consumed or selected may have been measured over a time period less than (immediate) or exceeding one day (longer-term). Our choice of eligible outcome constructs reflects a focus on the assessment of the effects of eligible interventions in terms of the types and amounts of food, alcohol and tobacco people consume, coupled with recognition that amount selected (with or without purchasing) is an important intermediate endpoint in pathways to consumption. We anticipate encountering a range of measures of these outcome constructs within included studies, and present the following examples of likely measures below:
1. Consumption (intake) of a product
Assessment of the amount of products (e.g. food, drink, alcohol or tobacco products), energy (e.g. calories), or substances (e.g. saturated fat, alcohol, carbon monoxide) consumed, measured in applicable natural units (e.g. kcals, kilojoules, grams). Objective measurement may involve sales data or calculating the amount of a product consumed by subtracting the amount remaining after consumption from the total amount presented to the participant. Alternatively, it may involve direct observation of consumption behaviour by outcome assessors. Subjective measurement would involve participant self-report.
2. Selection of a product
a) Without purchase
b) With purchase
As per consumption, assessment of the amount of products, energy or substances selected for consumption, measured in applicable natural units. Depending on the study setting, a product may be selected with or without this act enjoining a purchase (that is, a transfer of money to the vendor).
Secondary outcomes
Measures of unregulated consumption or selection (with or without purchasing) of food, alcohol or tobacco products that are not subject to manipulation, but are available in the same micro-environment at the same point of selection and consumption as the manipulated product.
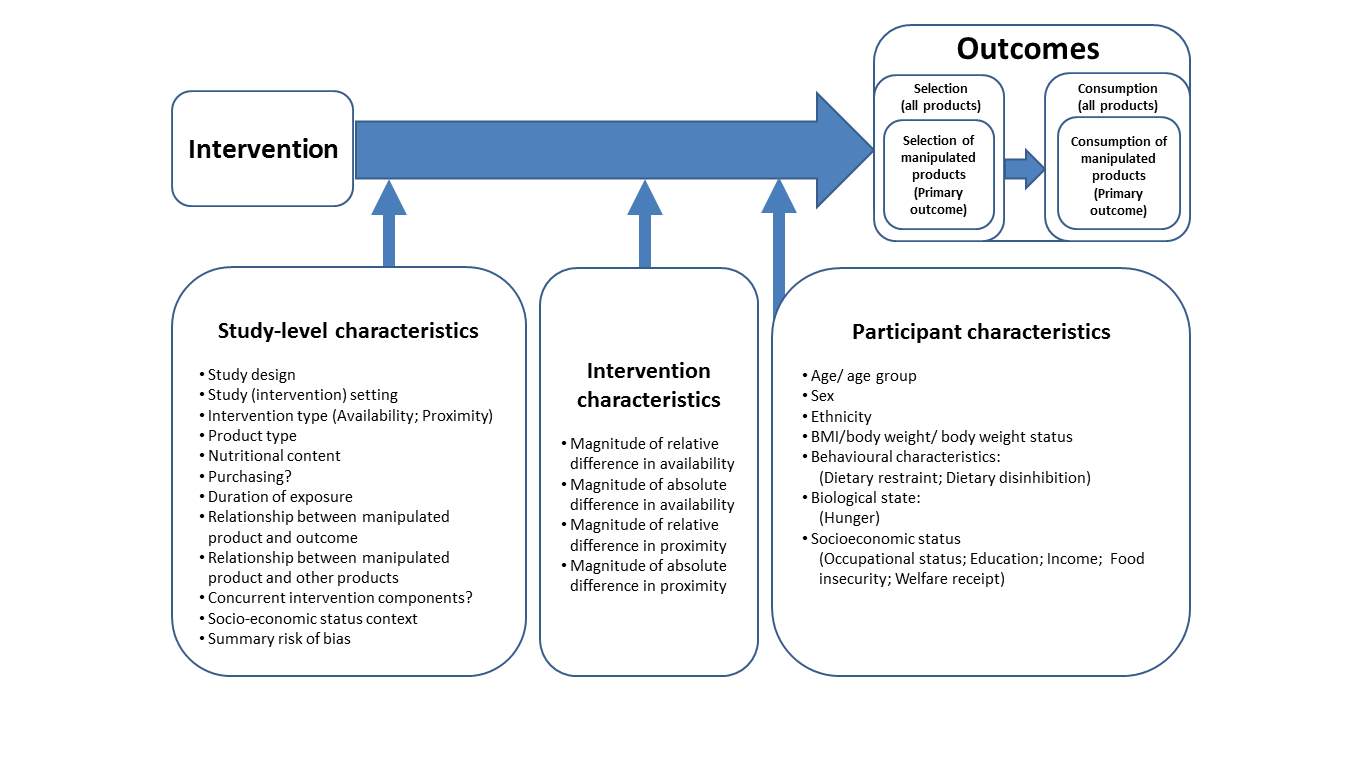
Conceptual model
To supplement study eligibility criteria, we have developed a provisional conceptual model (Figure 1). The conceptual model is design-oriented in the sense that it is intended to help direct the review process (Anderson 2011) by providing a simplified visual representation of the causal system of interest, i.e. the proposed causal pathway between eligible interventions and their outcomes (behavioural endpoints), and potential moderators of that relationship (effect modifiers) given that differential effects are plausible (Anderson 2013).
The provisional conceptual model will be used to inform the development of search strategies, data extraction forms and a provisional framework for the statistical analysis of the data collected from the eligible studies (see Search methods for identification of studies and Data collection and analysis). We propose to revise the conceptual model iteratively as we encounter evidence from eligible studies during the course of the review process, and will document all revisions including the rationale for each revision and supporting evidence.
As such, initial and subsequent iterations of the conceptual model will be used as a reference point for the design (in the protocol) and conduct (post-protocol) of all stages of the systematic review up to and including data synthesis, and as a conceptual basis for explicit reporting of the methods and assumptions used within the synthesis (Anderson 2013). We anticipate that, in practice, iterative refinement of the conceptual model will primarily involve incorporating further potential effect modifiers that we encounter when collecting the data from the eligible studies, which will then be considered for inclusion in the proposed meta-regression analysis.
Within the provisional conceptual model (Figure 1) we distinguish between three sets of potential effect modifiers: study characteristics; intervention characteristics; and participant characteristics. Within our proposed analytic framework for quantitative synthesis of data collected from the included studies (see Data collection and analysis), potential effect-modifying impacts of study characteristics can only be investigated based on between-study comparisons, whereas potential effect-modifying impacts of intervention characteristics can be investigated based on within-study comparisons between participant groups (for example, between different arms of a randomised controlled trial). Potential effect-modifying impacts of participant characteristics may be investigated based on either between-study comparisons or within-study comparisons, depending on the level of reporting of results by participant subgroups within the included studies.
Search methods for identification of studies
Electronic searches
We developed a MEDLINE search strategy by combining sets of controlled vocabulary and free-text search terms based on the eligibility criteria described above (see Criteria for considering studies for this review). It was developed with the intention of being highly sensitive (at the expense of precision) to give confidence in its ability to detect potentially eligible title and abstract records. This search strategy was externally peer-reviewed by an information retrieval specialist and Co-convenor of the Cochrane Information Retrieval Methods Group and revised based on their peer-review comments. We tested and calibrated the MEDLINE search strategy for its sensitivity to retrieve a reference set of 24 records of reports of potentially eligible studies that were identified within a preceding, broader scoping review of interventions within physical micro-environments (Hollands 2013a).
In addition, the search strategy was then reviewed by the Trials Search Co-ordinator of the Cochrane Public Health Review Group and further revised based on their comments. The final MEDLINE search strategy is presented in Appendix 1. We then adapted the final MEDLINE search strategy for use to search each of the other databases listed based on close examination of the database thesauri and scope notes. There were no restrictions for publication date, publication format or language. No study design filters were incorporated. Full details of the final search strategies will be provided in an appendix to the published review.
We will conduct electronic searches for eligible studies within each of the following databases:
- MEDLINE (including MEDLINE In-Process) (OvidSP) (1946 to present);
- EMBASE (OvidSP) (1980 to present);
- PsycINFO (OvidSP) (1806 to present);
- Cochrane Central Register of Controlled Trials (CENTRAL) (1992 to present);
- Applied Social Sciences Index and Abstracts (ASSIA) (ProQuest) (1987 to present);
- Science Citation Index Expanded (Web of Science) (1900 to present);
- Social Sciences Citation Index (Web of Science) (1956 to present);
- Trials Register of Promoting Health Interventions (EPPI Centre) (2004 to present).
Searching other resources
We will conduct electronic searches of the following grey literature databases using search strategies adapted from the final MEDLINE search strategy as described above:
- Conference Proceedings Citation Index – Science (Web of Science) (1990 to present);
- Conference Proceedings Citation Index – Social Science & Humanities (Web of Science) (1990 to present);
- OpenGrey (1997 to present).
We will search trial registers (ClinicalTrials.gov, the World Health Organization (WHO) International Clinical Trials Registry Platform (ICTRP), and the EU Clinical Trials Register) to identify registered trials, and the websites of key organisations in the area of health and nutrition including the following:
- UK Department of Health;
- Centers for Disease Control and Prevention (CDC), USA;
- World Health Organization (WHO);
- International Obesity Task Force;
- EU Platform for Action on Diet, Physical Activity and Health.
In addition, we will search the reference lists of all eligible study reports and undertake forward citation tracking (using Google Scholar) to identify further eligible studies or study reports. If non-English language articles are found, we will use Google Translate in the first instance to determine potential eligibility. If an article cannot be excluded on this basis, we will have the article translated by a native language speaker or professional translation service.
Data collection and analysis
Selection of studies
Title and abstract records retrieved by the electronic searches will be imported into EPPI Reviewer 4 (ER4) systematic review software (Thomas 2010). Duplicate records will be identified, reviewed manually and removed using ER4’s automatic de-duplication feature.
Two researchers, working independently, will undertake duplicate screening of title and abstract records retrieved by the electronic searches. Title and abstract records will be coded as ‘provisionally eligible’, ‘excluded’ or ‘duplicate’ by applying the eligibility criteria described above (see Criteria for considering studies for this review). Any disagreements in the coding of title and abstract records will be identified and resolved by discussion to reach consensus between the two researchers.
In relation to the electronic searches, search terms based on relevant intervention and comparator concepts (for example, availab$, increas$, add$, introduc$, close$, near$, far$) are unlikely to be specific to title-abstract records of eligible studies (even when configured in multi-strand search strategies); they are also likely to feature frequently in irrelevant title-abstract records. This is likely to result in large numbers of records being retrieved by electronic searches, which need to have sufficient sensitivity to capture all eligible studies. To address this challenge, we will use a semi-automated screening workflow to manage the title-abstract screening stage, deployed in ER4, which will use machine learning to assign title-abstract records for duplicate manual screening (O’Mara-Eves 2015). This workflow is designed to maximise recall of eligible studies while reducing screening workload to match the available resource, which we expect to allow for duplicate manual screening of up to a maximum of one third of retrieved records (the ‘overall screening budget’). Further details of the semi-automated screening workflow are provided in Appendix 2.
Full-text copies of corresponding study reports will be obtained for all records coded as ‘provisionally eligible’ at the title and abstract screening stage. Duplicate screening of full-text study reports will be undertaken by two researchers working independently. Full-text study reports will be coded as ‘eligible’ or ‘excluded’ by applying the eligibility criteria described above (see Criteria for considering studies for this review), with the reasons for exclusion recorded. Any disagreements in the coding of full-text study reports or reasons for exclusion will be identified and resolved by discussion to reach consensus between the two researchers. A third researcher will act as arbiter in the event that any coding disagreements cannot be resolved between the two researchers. Bibliographic details of study reports excluded at the full-text screening stage will be provided, along with the primary reason for exclusion, in a ’Characteristics of excluded studies’ table within the published review. Multiple full-text reports of the same study will be identified, linked and treated as a single study. Full text reports comprising multiple eligible studies will be identified and each study will be treated separately. We will document the flow of records and studies through the systematic review process and report this using a PRISMA flow diagram (Moher 2009).
Data extraction and management
An electronic data extraction form will be developed based on the Cochrane Public Health template and that used in a previous Cochrane review (Hollands, Shemilt 2015) modified to allow extraction of all data required for this review. An initial draft of this form will be piloted using a selection of included studies, to ensure that it enables reliable and accurate extraction of appropriate data, and amended in consultation with the review team. Data pertaining to the characteristics of included studies will be extracted by one researcher. Outcome data will be extracted in duplicate by two researchers working independently. If a study with more than two intervention arms is included, only outcome data pertaining to the intervention and comparison groups that meet the eligibility criteria described above will be included in the review, but the table ’Characteristics of included studies’ will include details of all intervention and comparison groups present in the study.
Any discrepancies in extracted outcome data will be identified and resolved by checking against the study report, discussion and consensus between two researchers, with a third researcher acting as arbiter in case of any unresolved discrepancies. Key unpublished data that are missing from reports of included studies will be sought by contacting the study authors. At the outset we intend to collect the data summarised below. This represents a maximum core dataset that we can reasonably anticipate will be required based on our study eligibility criteria and the design-oriented conceptual model (Figure 1). This dataset will likely evolve as the review develops. For example, the process of extracting data from the included studies may identify unanticipated potential effect modifiers (moderators or mediators) that prompt revisions to our design-oriented conceptual model, as described above. This dataset relates to the process of data extraction only and as such not all of these variables will be included in the statistical analysis process.
Study characteristics
- Study design: between-subjects or within-subjects design; individually or cluster randomised
- Study (intervention) setting: laboratory; field
- Intervention type: availability; proximity (and, if applicable, type of availability intervention (range of options; amount of units; combination) or type of proximity intervention (distance altered from which point, e.g. seating, walking route; checkout; entrance))
- Product type: food (including non-alcoholic beverages); alcohol; tobacco
- If applicable, nutritional content of product
- If applicable, selection with purchasing or selection without purchasing
- Duration of exposure
- Relationship between manipulated product and outcome (how outcome maps on to manipulated product)
- Relationship between manipulated product and other available products (for example, the availability of the product may be accompanied by increases, decreases or no changes in the availability of other products. Coding schemes for characterising such different permutations in the environment will be developed iteratively based on the nature of studies that are encountered)
- Concurrent intervention component in factorial design
- Concurrent intervention components confounded with comparison of interest
- Socioeconomic status context
- Summary risk of bias assessments
- Information on funding source and potential conflicts of interest from funding
Intervention characteristics
- If applicable, magnitude of relative difference in availability (range, amount)
- If applicable, magnitude of absolute difference in availability (range, amount)
- If applicable, magnitude of relative difference in proximity
- If applicable, magnitude of absolute difference in proximity
Participant characteristics
- Age/age group
- Sex (male, female)
- Ethnicity
- Body mass index (BMI); body weight; body weight status
- Behavioural characteristics (dietary restraint; dietary disinhibition)
- Biological state (hunger)
- Socioeconomic status (e.g. occupational status; education; income; food insecurity; welfare receipt)
These participant characteristics cover several categories of social differentiation relevant to health equity. The incorporation of study-level data on these participant characteristics into our proposed meta-regression analysis (see ‘Data synthesis’) is in part intended to enable us to draw inferences concerning any differential effects of the intervention on health equity (Welch 2012). For example, within our proposed meta-regression (see ‘Data synthesis’) we intend to enter proxy measures of socioeconomic status as participant characteristics that may moderate the observed effects of the intervention on product selection and consumption.
In addition, to complement investigations based on participant characteristics, we will use the most commonly available measure of socioeconomic status to construct a binary study-level covariate of ‘socioeconomic status context’ (see ‘Study characteristics’, above) that will serve as a proxy for the overall study context in terms of baseline levels of social and material deprivation amongst study participants. Analysis of this study-level covariate as a potential effect modifier will allow us to investigate specifically whether eligible interventions are more or less effective in a study context characterised by high versus low levels of social and material deprivation. In practice, given experience with a previous Cochrane review in a similar area (Hollands, Shemilt, 2015), we consider it unlikely that any single proxy measure of participants’ socioeconomic status, such as education or income, will be commonly measured in and reported by included studies, and it is likely that we will be limited to coding a study-level covariate based on authors’ explicit descriptors of the study sample and/or setting.
Outcome data
It is anticipated that some eligible primary studies will include more than one eligible measure of consumption or selection. We will use the measure of consumption or selection that maps most closely on to the focus of the intervention e.g. where only fruit products have been manipulated, we will if possible use a measure that related specifically to fruit consumption or selection only. Where multiple products have been manipulated, we will if possible use a measure that either relates specifically to one of those products (if it was discernible that that product was the primary intervention focus), or captures selection and consumption of all manipulated products.
If a study includes only a measure that captures consumption or selection of a wider set of products beyond those that have been manipulated (but including the manipulated product), this would still represent an eligible outcome for the purposes of this review, but would be considered less desirable because it may require assumptions to be made about the direction of effect in relation to the manipulated product itself. Following the application of these criteria, if there remain multiple eligible outcome measures, we will select the single measure of consumption or selection that has been (pre)specified by study authors as the primary outcome. If no primary outcome has been specified by study authors, we will select the measure of consumption or selection most proximal to health outcomes in the context of the specific intervention. For example, if a study reports measures of both energy intake and the amount of food eaten (in grams), we will select energy intake as the measure most proximal to diet-related health outcomes.
For all outcome data, we will collect information on: outcome variable type (dichotomous, continuous); outcome variable definition; unit of measurement (if relevant); timing of measurement (immediate (≤1 day) or longer term (>1 day)); and type of measure (objective, self-report). For dichotomous outcomes we will extract event rates in each comparison group. For continuous outcomes we will extract mean differences, or mean changes in final measurements from baseline measurements, for each comparison group with associated standard deviations (or, if standard deviations are missing, standard errors, 95% confidence intervals or relevant t-statistics, f-statistics or p values); we will also indicate whether a high or low value is favourable from a public health perspective. For included studies using factorial designs to investigate the effects of multiple experimental manipulations, we will combine groups to capture the main effects of each relevant randomised comparison.
Assessment of risk of bias in included studies
Risk of bias in the included studies will be assessed using the Cochrane ’Risk of bias’ tool addressing eight specific domains, namely: random sequence generation and allocation concealment (selection bias); blinding of participants and personnel (performance bias); blinding of outcome assessors (detection bias); incomplete outcome data (attrition bias); selective outcome reporting (reporting bias); and baseline comparability of participant characteristics between groups, and consistency in intervention delivery (other bias) (Higgins 2011b). The Cochrane risk of bias tool will be applied to each included study by two researchers working independently and supporting information and justifications for judgments of risk of bias (high, low or unclear) will be recorded, and where possible, will include verbatim text extracted from study reports.
Any discrepancies in judgements of risk of bias or justifications for judgements will be identified and resolved by discussion to reach consensus between two researchers, with a third researcher acting as arbiter in the case of any unresolved discrepancies. We will derive a summary risk of bias judgement (high, low, or unclear) for each specific outcome, based on those domains judged to be most critical in this specific review. We will use an algorithm suggested in Section 8.7 (Table 8.7a) of the Cochrane Handbook for Systematic Reviews of Interventions (Higgins 2011b).
Specifically, if the judgement in at least one of these domains is ’high risk of bias’ then we will determine summary risk of bias to be high. If no judgements of ’high’ risk are made in these domains, but the judgement in at least one of these domains is ’unclear risk of bias’ then we will determine the summary risk of bias to be unclear. We will only judge summary risk of bias to be ’low’ if judgements in all of these domains are ’low risk of bias’. Completed risk of bias tables will be presented in the published review, including justifications for each judgement. Where judgements are based on either assumptions or information provided outside publicly available documents (for example supplementary information provided by study authors) this will be explicitly stated.
We will include a summary assessment of risk of bias for each specific outcome included in our statistical analysis as a covariate in our proposed meta-regression analysis (see Data synthesis). We will also consider the summary risk of bias in determining the strength of inferences drawn from the results of the data synthesis and in developing conclusions and any recommendations concerning the design and conduct of future research.
Measures of treatment effect
For continuous outcomes, we will calculate the standardised mean difference (SMD) with 95% confidence intervals to express the size of the intervention effect in each study relative to the variability observed in that study. For dichotomous outcomes, we will calculate the odds ratio (OR) for each included study to express the size of the relative intervention effect between comparison groups, with the uncertainty in each result being expressed by the confidence interval. We will then re-express the odds ratio as a standardised mean difference by applying the formula described in Section 9.4.6 of the Cochrane Handbook for Systematic Reviews of Interventions (Deeks 2011).
Unit of analysis issues
In the case of cluster-randomised trials, where an analysis is reported that accounts for the clustered study design, we will estimate the effect on this basis, using reported test statistics (t-statistics, F-statistics or P values) to calculate standard errors if necessary. If this is not possible and the information is not available from the authors, then an ’approximately correct’ analysis will be carried out according to current guidelines (Higgins 2011). We will impute estimates of the intra-cluster correlation (ICC) using estimates derived from similar studies or by using general recommendations from empirical research. If it is not possible to implement these procedures, we will give the effect estimate as presented but report the unit of analysis error.
For included studies with a within-subjects design, we will calculate the standardised mean difference for continuous outcomes using the methods described in Section 16.4 of the Cochrane Handbook for Systematic Reviews of Interventions (Higgins 2011), and compute standard errors for outcome data in a similar way as for cluster-randomised trials if necessary. Final outcome values will serve as the primary unit of analysis. For studies assessing changes from baseline as a result of an experimental manipulation, we will calculate final values based on either reported data or supplementary data obtained by contacting study authors, if available.
Dealing with missing data
Data that are missing from reports of included studies will be sought by contacting the study authors. Where data are missing due to participant dropout we will conduct available case analyses and record any issues of missing data within the assessments conducted using the Cochrane ’Risk of bias’ tool.
Assessment of heterogeneity
We will assess statistical heterogeneity in results by inspecting a graphical display of the estimated treatment effects from included studies along with their 95% confidence intervals, and by formal statistical tests of homogeneity (Chi2) and measures of inconsistency
(I2) and heterogeneity (τ2).
Assessment of reporting biases
We will draw funnel plots (plots of effect estimates versus the inverse of their standard errors) to inform assessment of reporting biases. We will conduct statistical tests to formally investigate the degree of asymmetry using the method proposed by Egger et al (Egger 1997). Results of statistical tests will be interpreted based on visual inspection of the funnel plots. Asymmetry of the funnel plot may indicate publication bias or other biases related to sample size, though it may also represent a true relationship between trial size and effect size.
Data synthesis
We will describe and summarise the findings of included studies to address the objectives of the review. We will provide a narrative synthesis describing the interventions, participants, study characteristics and effects of eligible interventions upon pre-specified outcomes (see Criteria for considering studies for this review), and will consider presenting the narrative syntheses in disaggregated form by type of product: food, alcohol and tobacco. Our statistical analysis of the results of included studies will use a series of random-effects and fixed-effects models to estimate summary effect sizes as SMDs with 95% confidence intervals in terms of each specified outcome. The precise configuration of our proposed statistical analysis will be determined based on the final iteration of our design-oriented conceptual model. Our statistical analysis will comprise the following stages:
- Stage 1. Conduct separate meta-analyses for each product type (food, alcohol and tobacco) and, within each product type, conduct separate meta-analyses for (i) availability interventions and (ii) proximity interventions.
Then for each meta-analysis:
- Stage 2: Conduct a meta-regression analysis with study characteristics as additional covariates.
- Stage 3: Conduct a meta-regression analysis with intervention characteristics as covariates. This is likely to include, for example, measures of the magnitude by which availability or proximity of the product is altered. In this stage we may decide to incorporate multivariate analysis to deal with studies with multiple treatment arms in order for direct comparisons between each treatment arm and a control condition to be modelled, using mvmeta (White 2011). The latter decision will be contingent on the extent to which outcome data are derived from studies with multiple treatment arms (that is if there are few or no included multi-arm studies, multivariate analysis may not be appropriate).
- Stage 4: Conduct a meta-regression analysis with participant characteristics and summary risk of bias as covariates.
Study-level effect sizes that are calculated based on outcome data from independent within-study comparisons will be directly incorporated into Stage 1 meta-analyses. For studies that include three or more eligible comparison groups (for example, an included study of a proximity intervention measured energy consumed from a food product placed either 1m, 2m or 3m from participants), we will treat each eligible within-study comparison as providing independent outcome data, and handle the dependency in two ways: first, by using data from incremental comparisons only (for example, 1m versus 2m and 2m versus 3m; but not 1m versus 3m). This approach assumes a linear ’dose-response’ relationship between the size of the experimental manipulation and amounts consumed/selected and is conservative in terms of its impact on summary effect sizes. Second, we will halve the sample sizes of groups that feature in two incremental comparisons (for example, the 2m group features in both the 1m versus 2m comparison and the 2m versus 3m comparison), to adjust corresponding study weights in the analysis.
A covariate will be excluded from Stages 2, 3 or 4 of a meta-regression analysis if data are available from fewer than 10 eligible studies incorporated into the corresponding Stage 1 meta-analysis, and/or the characteristics of available data do not enable sufficient discrimination between studies. Within each stage of a meta-regression analysis, we will test each covariate separately to identify those variables statistically associated with each outcome. Finally, we will estimate and present a meta-regression model that incorporates the set of covariates that best explain statistical heterogeneity observed in the corresponding Stage 1 meta-analysis. We will use the following procedure to select and incorporate covariates into this multi-variable model:
- Rank those covariates identified as potentially important predictors of the outcome in Stages 2, 3 or 4 in order of the corresponding adjusted R2 values;
- Starting with the top-ranked covariate, use a stepwise procedure to add each consecutively ranked covariate into the multi-variable meta-regression model.
- Retain a covariate in the multi-variable model only if it increases the adjusted R2 for the multi-variable and no collinearity or multicollinearity with other retained covariates is detected.
For each covariate represented as a categorical or binary variable and retained in the final multi-variable meta-regression model, we will also estimate and present summary effect sizes for each subgroup. For each covariate represented as a categorical or binary variable and retained in the final model, we will present a bubble plot to illustrate the statistical association.
Treatment of multi-component studies
For included studies using factorial designs to investigate the effects of multiple experimental manipulations, we will combine groups to capture the main effects of each relevant randomised comparison.
However, we also anticipate that we will encounter studies featuring concurrent intervention components unrelated to product availability or proximity that are intrinsically confounded with those comparisons of interest. For these studies, we will treat the concurrent components as study characteristics. At a minimum we will then code all included studies using a dummy variable that represents the presence or absence of one or more additional intervention components (although we may iteratively develop a more detailed coding scheme should sufficient data be available). Our primary analyses will exclude comparisons where confounded components are present. We will subsequently conduct sensitivity analyses whereby these comparisons will be reinstated, in order to assess their impact on the results.
Summary of findings table
We will use the standard GRADE system to rate the quality of each body of evidence incorporated into meta-analyses for (1) consumption and (2) selection (with or without purchasing) outcomes in terms of the confidence that may be placed in summary estimates of effect. GRADE criteria for assessing quality of evidence encompass study limitations, inconsistency, imprecision, indirectness, publication bias and other considerations. Justifications underpinning all assessments will be documented and presented in a series of Summary of Findings tables developed using GRADEpro GDT (Brozek 2008), alongside a summary of the estimated intervention effect and the number of participants and studies for each outcome. We will present separate summary effect sizes and quality of evidence ratings for food, alcohol and tobacco products, and for availability and proximity interventions. Results of meta-analyses will be presented as standardised mean differences (SMDs) with 95% confidence intervals (CIs). To facilitate interpretation of these estimated effect sizes, we will also re-express them using selected familiar metrics of food, alcohol or tobacco selection or consumption (for example, in relation to average daily energy intake) (Hollands 2015; Schünemann 2011).
Sensitivity analysis
In addition to the aforementioned treatment of studies featuring confounded additional intervention components, sensitivity analyses will also be conducted to explore the impact of any outcome data that are imputed due to missing data.
Figure 1 – Design-oriented conceptual model
REFERENCES
Bar-Hillel, M. (2015). Position effects in choice from simultaneous displays: A conundrum solved. Perspectives on Psychological Science, 10, 419–433.
Chernev A: Product assortment and consumer choice: An interdisciplinary review. Foundations and Trends in Marketing 2011, 6:1–61.
Dalenberg JR, Nanetti L, Renken RJ, de Wijk RA, ter Horst GJ (2014). Dealing with Consumer Differences in Liking during Repeated Exposure to Food; Typical Dynamics in Rating Behavior. PLoS ONE 9(3): e93350.
Grech A, Allman-Farinelli M (2015). A systematic literature review of nutrition interventions in vending machines that encourage consumers to make healthier choices. Obesity Reviews; 16, 1030–1041
Hollands GJ, Marteau TM, Fletcher PC. Non-conscious process etc. Health Psychology Review, In press
Hollands. Shemilt 2015. Portion, package and tableware size Cochrane review. Cochrane Database of Systematic Reviews.
Miwa M, Thomas J, O’Mara-Eves A, Ananiadou S (2014) Reducing systematic review workload through certainty-based screening. Journal of Biomedical Informatics. 51: 242–253
O’Mara-Eves A, Thomas J, McNaught J, Miwa M, Ananiadou S (2015) Using text mining for study identification in systematic reviews: a systematic review of current approaches. Systematic Reviews 4:5. doi:10.1186/2046-4053-4-5
Pedregosa et al (2011). Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
Sela A, Berger J, Liu W: Variety, vice, and virtue: How assortment size influences option choice. Journal of Consumer Research 2009, 35(6):941–951.
Thomas J, Brunton J, Graziosi S (2010) EPPI-Reviewer 4.0: software for research synthesis. EPPI-Centre Software. London: Social Science Research Unit, Institute of Education.
Trope, Y., & Liberman, N. (2010). Construal-level theory of psychological distance. 585 Psychological Review, 117, 440–463.
Wansink, B. (2004). Environmental factors that increase the food intake and consumption value of unknowing consumers. Annual Review of Nutrition, 24, 455–479.
World Health Organization (2016). World Health Statistics 2016. Geneva: World Health Organization.
Appendix 2
Details of the semi-automated screening workflow
The semi-automated workflow will proceed in three phases: ‘initial sample’, ‘active learning’, and ‘topic modelling’.
Initial sample
First, we will screen a random sample of title-abstract records to establish an initial estimate of the baseline inclusion rate (see Shemilt 2013), in order to both inform prospective monitoring of the performance of the semi-automated screening workflow, and supply an unbiased initial sample of records for machine learning.
Active learning
Second, we will deploy active learning to identify records of potentially eligible studies as rapidly as possible. In this phase, title-abstract records will be prioritised for manual screening using active learning, whereby the machine ‘learns’ iteratively to distinguish between relevant and irrelevant records in conjunction with manual user input (Miwa 2014). We have previously deployed this method in two large-scale systematic scoping reviews of interventions to change health behaviour (Shemilt 2013, Hollands 2013a, Shemilt 2014). Active learning will be trained initially using a ‘reference set’ of 24 records of potentially eligible studies identified by a published scoping review on physical micro-environment interventions (Hollands 2013a) and the sample of citations screened in phase 1 (‘initial sample’). In order to deploy active learning, a stopping criterion is needed which pre-specifies when this phase will be truncated. We have set the stopping criterion in terms of the maximum marginal resource the review is prepared to ‘pay’ in order to identify one additional title-abstract record of a potentially eligible study. We will prospectively monitor and record screening time-on-task and stop the active learning phase of the semi-automated workflow if the reviewers complete 15 hours of duplicate screening (i.e. 30 hours time-on-task in total for two reviewers) without identifying any further records of potentially eligible studies. At this point, we will also screen a second random sample of records to establish a second estimate of the baseline inclusion rate (Shemilt 2013).
Topic modelling
Active learning can be expected to have identified the large majority of title-abstract records of potentially eligible studies that are present in the full set retrieved by electronic searches before the above stopping criterion for that phase is enacted. However, given that active learning iteratively prioritises further title-abstract records for screening based on the researchers’ preceding eligibility decisions about records that were also prioritised by active learning (that is, the algorithm progressively finds ‘more of the same’), we will next introduce an entirely different, novel method into the semi-automated workflow, to provide a check and balance on the use of active learning alone. In this third phase of title-abstract screening, records will be allocated for duplicate manual screening based on topic modelling using Latent Dirichlet Allocation (LDA) and/or Non-negative Matrix Factorisation (NMF) (Pedregosa 2011). Topic modelling essentially clusters title-abstract records according to the combinations of terms they contain and returns a set of ‘topic terms’ for each cluster (hereafter, a ‘topic’).
Topic modelling will be used to generate 50 topics underlying the full set of title-abstracts retrieved by electronic searches (or included among the ‘reference set’), and concurrently to generate a series of ‘membership scores’ for each unscreened record, by topic. The membership score is based on the computed probability that a record is described by the topic (that is, a higher membership score reflects a higher probability of membership of the topic) and is >0 for all records in all topics. Each unscreened title-abstract record will next be allocated to the single topic that corresponds with its highest membership score. Results of a preliminary simulation study, conducted to simulate this phase of the workflow in a screening dataset curated from another Cochrane review (Hollands 2015), indicated that the large majority of topics contain no unscreened records of potentially eligible studies (that is, most topics are irrelevant), and also that the review authors were able to discriminate accurately between topics that contained the most and fewest records of potentially eligible studies when blinded to this information. Two reviewers will therefore next examine each topic, blinded to the number of records allocated to each, and place the 50 topics in rank order based on their inter-subjective judgement of the likelihood that each set of terms describes a set of records that includes eligible studies. A second ranking of the 50 topics will also be generated based on the number of potentially eligible title-abstract records each contains among records already screened up to the end of the active learning phase. We will then compute a composite ranking by adding together the reviewers’ ranking and the data-generated ranking, once the latter has been multiplied by 0.5. This procedure assigns ‘double weight’ to the reviewers’ judgements in the composite ranking, which ‘promotes’ those topics that the reviewers rank higher but contain a relatively low number of ‘potentially eligible’ title-abstract records among those already screened (and, conversely, ‘demotes’ those topics that the reviewers rank lower but contain a relatively low number of ‘potentially eligible’ title-abstract records among those already screened). At the end of the active learning phase, the ‘remaining screening budget’ (that is, the ‘overall screening budget’ minus the number of records already screened) will be calculated and allocated between topics, by drawing a random sample of unscreened title-abstract records from each topic (that is, the sum of the sizes of the 50 random samples will equal the remaining screening budget). The sizes of random samples drawn from topics will be scaled to approximate a beta distribution (α=0.3, β=3.0) across rank ordered topics (highest to lowest), to reflect our prior belief (informed by results of the simulation study) about the likely distribution of any further ‘potentially eligible’ title-abstract records across rank ordered topics. Sampled records will next be allocated for duplicate manual screening in topic rank order, from highest to lowest ranked. This procedure will ensure that records assigned to higher ranked topics are more likely to be allocated for screening, relative to records in lower ranked topics. We will continue the topic modelling phase of title-abstract screening until either all records allocated using the above procedure have been screened, or the following early stopping criterion is enacted: based on prospective monitoring of time-on-task, we will truncate the semi-automated screening workflow if the reviewers complete 15 hours of duplicate screening (i.e. 30 hours time-on-task in total for two reviewers) without identifying any further records of potentially eligible studies.
In the active learning phase of the semi-automated screening workflow described above, we will alternate between title-abstract and full-text screening stages after each set of 2,400 title-abstract records have been manually screened, in order to promote more accurate initial title-abstract screening decisions, and to enable retrospective modelling of the impact of using full-text screening decisions in training data for active learning.
IGNORE
The current review will use what are in the context of Cochrane reviews novel and atypical methods to identify studies. Typically in a Cochrane review, all electronic searches are completed following the acceptance of a peer-reviewed review protocol. However, the process of developing our search strategy for the purposes of the protocol indicated that a conventional approach would not suffice for the current review because initial attempts at developing a sufficiently sensitive MEDLINE search returned sets of records in the region of over 90,000 title and abstract records. This clearly represented a ‘too many records’ problem, i.e. a set of records unable to be screened in totality by the author team (as is traditional) within available resources. This reflects the nature of the current evidence base, as, for example, the nature of the interventions of interest mean that language used in reports is highly inconsistent and non-specific. Whilst search strategies would be able to be further optimised and refined, we were confident that the set of records returned would inevitably continue to be unmanageably large. Therefore, we have developed specific methods and processes for dealing with this problem, which will be summarised in the review and further detailed in separate methods-focused publications. In order to understand the extent and nature of the record set to be searched so as to be able to inform the development and piloting of this process, it was necessary to conduct the electronic database searches in advance of submitting this protocol.
The principal processes that differ from a traditional approach concern running electronic database searches prior to the submission of the review protocol (see ‘Electronic searches’) and the application of text-mining and machine learning software technologies to enable and support the title and abstract screening process (see ‘Selection of studies’).
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Health and Social Care"
Health and Social Care is the term used to describe care given to vulnerable people and those with medical conditions or suffering from ill health. Health and Social Care can be provided within the community, hospitals, and other related settings such as health centres.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: