Sentiment Analysis of Twitter Using Machine Learning
Info: 22338 words (89 pages) Dissertation
Published: 12th Jan 2022
Tagged: TechnologySocial Media
Abstract
With the advent of mobile technologies and ubiquitous accessibility of internet, huge amount of opinionated content is being posted daily on the social media sites like Twitter and Facebook. Since these social media sites are accessed globally, those opinionated posts may not necessarily be in English language. In recent years, the amount of tweets in Nepali language has seen a rapid growth and thus opening doors for research in sentiment analysis of social media content for Nepali language. In this research we intent to classify sentiments in Nepali tweets using machine learning approach coupled with various feature extraction techniques.
Extracting lexical and syntactic features from Nepali language text is difficult because of unavailability of any sentiment lexicon and lack of linguistic feature tools such as stop words list, stemmers, part of speech taggers, negation tagging. Hence, in this research we focus on extracting semantic features from Nepali tweets with the use of shallow neural network network tool known as word vectors (Word2vec) and paragraph vectors (Doc2vec) and feed those feature vectors as input to three machine learning classifiers namely Logistic Regression, Random Forest and Gaussian Naïve Bayes to classify sentiments in Nepali tweets. We use traditional bag of words method and the neural network method (Word2vec and Doc2vec) to create feature vectors and do a comparative study on the performance of three different machine learning classifiers when coupled with different feature extraction methods. We use ten-fold cross validation and F1-score as an evaluation metric. Different experiments are carried to figure out the best performing architecture and optimal feature vector dimension for both Word2vec and Doc2vec. Unlabeled corpus of Nepali tweets is used to create feature vectors using Word2vec and Doc2vec tool. In this research, we also study the effect of varying amount of data in the unlabeled corpus used to create feature vectors on the performance of the machine learning classifiers. Our experiments demonstrate that feature vectors created using neural network tools result in better performance when used with all three machine learning classifiers compared to using feature vectors created using traditional bag of words method.
Chapter 1 INTRODUCTION
Sentiment Analysis / Sentiment Analysis and Nepali language
All forms of communicative media such as written text, spoken words, sign languages communicate some form objective or subjective information. The subjective impressions such as feelings, attitudes, evaluations, emotions and opinions associated with any form of communication is known as sentiment. Sentiment Analysis, also referred to as opinion mining is the field of study which aims at classifying sentiments associated with any written or spoken language. Sentiment analysis is a field of study which makes use of Natural Language Processing (NLP), machine learning, statistics, linguistic features, etc. to evaluate if the contents of the spoken words or written text is favorable, unfavorable, or neutral, and to what degree. Sentiment Analysis have wide range of applications. Sentiment Analysis can be a useful tool for information extraction, answering questions of public opinion and summarization of viewpoints of multiple people. Sentiment Analysis is widely used in the fields of Business Analytics, law and policy making, politics and political science, psychology, sociology, etc. The amount of opinionated content on the web is burgeoning daily. Since, internet is more accessible to people in all parts of the world, such content on the web may not necessarily be in English language. Hence it is important to expand the tools and techniques developed for sentiment analysis to cover other lesser known languages with opinionated content on the web.
Nepali language is a morphologically rich Indo-Aryan language written in Devanagari script. Nepali language is the official language of Nepal. It is spoken by about 17 million people in Nepal and approximately by 45 million people worldwide including people from various parts of India, Bhutan and Burma [ref www.ethnologue.com/language/nep]. Because of its peculiarity in morphology, structure and grammar, the techniques developed for sentiment analysis in popular languages such as English may not yield good results when used for the task of sentiment analysis of Nepali language. In this research we analyze different techniques for the sentiment analysis of tweets in Nepali language and expand upon the existing work in academics that focus on sentiment analysis of Nepali language.
Problem Statement
The amount of Nepali content on the world has been increasing day by day. There are about 15 regularly updated News portal in Nepali language. Some of the prominent news portal in Nepali language are Kantipur, Nagariknews, Onlinekhabar, Gorkhapatra, etc. In addition, Wikipedia [ref http://ne.wikipedia.org/wiki] consists of about 25,444 content pages and 59,744 total number of pages (including talk pages and redirects) in Nepali language. Further, social media sites such as twitter and Facebook also increases the amount of Nepali content on the web. Everyday large amount of tweets and Facebook posts are being updated using Nepali language. The hidden information and sentiment in this increasing amount of web content in Nepali can be very useful to the large number of local advertising industries, recommendation systems, government offices and so on. There are some preliminary language processing and applications have been developed for Nepali language [ref lexicon pool 6,7,8,9,10]. However, these researches just focus on morphology and syntax of Nepali language.
Very limited amount of work has been done in the field of sentiment analysis of Nepali language. Till date three research papers have been published which explains the sentiment analysis techniques in Nepali text [ref three Nepali papers]. These previous researches focus on using resource based approach and machine learning approach to perform sentiment analysis in Nepali text. In resource based approach a comprehensive lexicon containing sentiment scores for words in the vocabulary of the given language is used.
For English language, SentiWordNet (SWN) is widely used which contains sentiment scores for all wordnet entries. However, since Nepali language is under researched there is no availability of such lexicon with sentiment scores for majority of Nepali words. Using Machine learning approach also has its own disadvantages. Machine learning approach would require a large corpus of pre-labeled data for training the machine learning model. There is no such pre-labeled corpus of data for Nepali text, hence the researchers have to manually prepare a labeled dataset. In addition, previous research in Nepali sentiment classification involving machine learning approach makes use of Bag of Words or Bag of n-grams model to create feature vectors to train the machine learning classifiers, hence it misses out on the semantic meaning of the sentence.
In popular languages like English, many linguistic tools like stop words removal, part of speech (POS) tagging, stemming, negation tagging, etc. [ref if possible] are used with bag of words model to obtain the better performance from the machine learning classifiers. Since, Nepali is a lesser known language, it lacks accurate basic linguistic resources such as stop words list, stemmers, Part of Speech (POS) tagger, negation taggers, etc.
In order to mitigate all those above mentioned existing problems in the task of sentiment classification of Nepali text, in this paper we make use of unsupervised shallow neural word embedding models namely Word Vector (Word2vec) and Paragraph Vector (Doc2vec) to create feature vectors and use them to train the machine learning classifiers. Word2vec and Doc2vec have distinct advantages over the Bag of Words model as they preserve the semantic meaning of the words in the sentence. Also, Word2vec and Doc2vec can be used to prepare feature vectors by training them on unlabeled data, which is very useful for our use case because of the unavailability of huge amount of labeled corpus of Nepali text.
In this research, we attempt to answer following research questions:
- Do Machine learning classifiers which makes use of feature vectors created using Word2vec and Doc2vec perform the task of sentiment classification of Nepali tweets better than the machine learning classifiers which employ traditional Bag of Words and TF-IDF as feature extraction method?
- Does the performance of machine learning classifiers vary with the amount of unlabeled data used to create feature vectors using Word2vec and Doc2vec?
- For our task of sentiment classification of Nepali tweets, what is the optimal feature vector dimension and the best training architecture forWord2vec and Doc2vec?
Contributions
All the existing works in sentiment classification in Nepali language has been done in Nepali subjective texts at a document level using a corpus of Nepali news stories [1,2,3 nepali ref]. This is a first research of its kind that attempts to performs sentiment analysis at sentence level using Nepali content from social media site twitter. In this research, we use twitter to develop a corpus of Nepali tweets and perform a sentiment analysis on it.
This research also contributes resources to Nepali language processing, in form of labeled Nepali tweets corpus and unlabeled Nepali tweets corpus.
The approach described in this research can be easily extended to perform sentiment classification of tweets in any other under researched or less spoken languages lacking in basic linguistic resources.
Chapter 2 Background
Natural Language Processing (NLP)
Human beings use different types of languages as a form of communication. If two individuals have a knowledge of any common language they can share ideas and opinions with each other conveniently. However, no languages as in its current form can be used by any individual to communicate with computers. It is not feasible for computers to understand any human spoken languages. Thus there is a field of computer science that makes use of techniques such as artificial intelligence, machine learning and computational linguistics in order to enable computers to make sense out of any human language which may be in the form of spoken words or written text. This sub field of computer science dealing with the interaction of computers with the human languages is known as Natural Language Processing (NLP). Many researches have been conducted to study how humans use and understand languages so that it can be used to develop systems to help computers understand natural language and finally assist in carrying out some designated tasks.
All natural language processing tasks has one major core barrier i.e. to make computer systems understand the human language which is a difficult task mainly because language is an outcome of human thought process and have different representation and meaning to the world knowledge. Thus, it is only prudent for the NLP system to start understanding the morphological structure from the word level and then proceed to the sentence level to make sense of word order and grammatical structure. According to Liddy and Feldman [ref Liddy, E. (1998). Enhanced text retrieval using natural language processing. Bulletin of the American Society for Znformation Science, 24(4), 1P16. — Feldman, S. (1999). NLP meets the jabberwocky. Online, 23,62-72.] , humans use seven independent levels in their daily communication to make sense of speech or a text. These seven levels are namely, phonetic level, morphological level, lexical level, syntactic level, semantic level, discourse level and pragmatic level. Natural language processing deals with building computer systems that can analyze and understand human speech or text in those seven distinguishable levels. In addition to understanding of natural language, there are few other challenges in the field of natural language processing such as connecting language, natural language generation, machine perception of language, human –computer dialog system management, etc.
Commonly researched tasks and applications of NLP
Information Retrieval
Information retrieval deals with obtaining relevant information on a given topic or subject from a huge collection of information source. Information retrieval primarily focus on finding metadata from databases, finding the relevant document themselves or searching information form a sound, image, text or document. One of the major application area of Natural language processing is considered to be information retrieval and many different researches has been conducted in this area.
Lewis and Sparck Jones in 1996 [ref] first described about the fundamental issue for natural language processing in information retrieval which was regarding the possibility of combining non-statistical and statistical data i.e. combination of individual documents and whole files. In 1999, Feldman [ref] suggested using natural language processing techniques along with other technologies such as speech recognition, intelligent agents and visualization in order to achieve better results in information retrieval. Linguistic variation and variation in presenting the subject matter also poses a challenge in information retrieval. Lehtokangas and Jarvelin in 2001[ref ] studied the consistency of linguistic usage using news stories as an example.
Information Extraction
The major goal of information extraction is to make use of machine readable unstructured and semi-structured documents to extract structured information automatically. The process of information extraction leverage natural language processing techniques to make sense of texts which are in human languages. Information extraction also aims at drawing inferences from unstructured data based on the logical content present in the data to make logical reasoning possible. Using natural language processing and information extraction can be used to solve problems such as text management which is one step beyond the prevalent text storage, display and transmission. According to Gaizauskas and Wilks [ref] “Information extraction is a subset of knowledge discovery and data mining that aims to extract useful bits of textual information from natural language texts”
The information extracted as an output of information extraction techniques can be beneficial for numerous purposes such as populating databases, drafting a summary of texts, identifying keywords and phrases to facilitate information retrieval process, etc. Information extraction technique can be utilized to specify predefined categories and classify texts to the respective categorizers. Reuters in 1992 developed such categorization system called CONSTRUE [full form? ] to classify news stories using information extraction techniques. [ref Hayes, 1992]
Abstracting
Automated abstracting also referred to as text summarization is becoming commonly used application of natural language processing research. The process of abstracting and summarization involves taking a huge chuck of text as an input and using some statistical and linguistic criteria to select the core part of the text that implies the crux of the longer input text. Numerous research is being conducted in this area of natural language processing. In this research [ref Goldstein, Kantrowitz, Mittal, and Carbonell (1999)], the authors aimed at generating summarized versions of news article using the conventional information retrieval method to get linguistic cues. In another research, the authors Silber and McCoy [ref Silber and McCoy 2000] proposed an algorithm to calculate lexical chains for automatic summarization of documents.
Machine Translation
Machine Translation is a widely popular application of natural language processing. Machine translation makes use of computational linguistics and computer software to translate spoken speech and written text from one language to another. Modern day software applications like google translator, Bing translator, Baidu translator, etc. all make use of natural language processing and machine translation. With the advent of mobile technology and ubiquitous access of internet the amount of multilingual digital content is on the rise. Technologies like machine translation enable people to understand and extract information form any foreign languages.
On the basic level machine translation involves word to word substitution from one language to another. However, this alone does not make for a robust translation of texts or speech. Machine translation is categorized as one of the difficult problems to solve in natural language processing because it requires computer system to have human like knowledge of the languages such as grammar, semantics, part of speech, sarcasm, etc. Usually text translation is carried in two levels full text translation and queries translation. Full text translation translates an entire text from a one language to another and the translated text is used for search and retrieval. Full text translation is better for translating small collections and usually employed for specific applications. The second approach just takes certain queries and translate it from one language to another. The approach of taking small chunk of queries and translating them at a time is considered more practical and the results of using this approach has been highly rated in the literature.
Optical character recognition (OCR)
Optical character recognition is the technique that converts handwritten, typed or printed text from a scanned document or image into machine-encoded text. Optical character recognition technique is also an application of natural language processing which is widely used in the digital world. Using optical character recognition all the classic printed texts which do not have digital presence can be digitized and an electronic version can be created which makes availability of such documents easier. Optical character recognition technique can also help in data entry tasks from printed book records, invoices, passports, business cards, etc. In addition to natural language processing techniques, optical character recognition has ties to other sub-field of computer science such as computer vision, pattern recognition, artificial intelligence, etc.
Named entity recognition (NER)
Named entity recognition is an application of natural language processing which aims at extracting items from a given text and mapping it to proper names which may be person, places, organization or entity. Named entity recognition is also referred to as entity identification, entity extraction and entity chunking. Generally, named entity recognition system takes an unannotated block of text and aims at producing an annotated block of text with specified names of entities. Researchers have made huge progress in the field of named entity recognition at least for English language. The best performing state of the art named entity recognition system demonstrated in Mutual Understanding Conference (MUC-7) resulted in F-measure score of 93.39% which is very close to the score of 97.60% and 96.95% obtained by human annotators [ref Elaine Marsh, Dennis Perzanowski, “MUC-7 Evaluation of IE Technology: Overview of Results”, 29 April 1998][ref MUC-07 Proceedings (Named Entity Tasks) ].
Sentiment analysis
With the proliferation of opinionated content on the web, this particular application of natural language processing to determine the sentiment of the given speech or text is gaining more popularity. In layman’s term sentiment analysis aims at identifying and classifying spoken words or written text as positive, negative or neutral.
Among all above mentioned research applications of natural language processing, in this research we analyze the sentiment analysis in depth and discuss different natural language processing techniques used to perform sentiment analysis of Nepali tweets.
What is sentiment analysis?
In the field of Natural language processing, sentiment analysis also known as opinion mining is task of classifying a given text as positive, negative or neutral based on the opinion or subjectivity of the text. Sentiment analysis can be considered a sub filed of text classification which involves classifying a text in to predefined categories. Sentiment analysis can be used to evaluate the attitude of the people about a topic, comments of Facebook posts, tweets, product review, political agenda, review sites, etc. Once important characteristics of sentiments and opinions is that unlike factual information, they are subjective. Examining the opinion of single individual reflects the subjective view point of that given individual which doesn’t hold much value. Thus sentiment analysis involves the analysis of opinions from a collective group of people to get some kind of summary of the opinions. Such opinion summary may be in the form of structured summary of short text summary which usually include the generalized opinions about different entities and have a quantitative perspective.
Since sentiment analysis mainly involves analyzing the opinions expressed in the text, it is important to discuss the different types of opinions. Broadly opinions can be categorized as regular opinion [ref Liu, 2006 and 2011] and comparative opinion [ref Jindal and Liu, 2006b].
Regular opinion, often referenced to simply as an opinion in literature has two main sub-types [ref liu, 2006 and 2011] known as direct opinion and indirect opinion. Any opinions which expresses a views bluntly to an entity or object can be categorized as direct opinion. For e.g. “The iPhone takes pictures of great quality”. An indirect opinion forms an opinion on an entity or object indirectly and usually references to an external entity for forming such opinion. For e.g. “After sitting in chair for ten hours, I suffered from severe back pain” explains the reason for the “back pain” and indirectly gives a negative opinion about sitting in chair. Most of the current research in the field of sentiment analysis, deals with handling direct opinions because of its simplicity.
Comparative opinion expresses the preference of the opinion holder towards an entity after a comparative analysis of similarities and differences between that particular entity with other entities. [ ref Jindal and Liu, 2006; Jindal and Liu, 2006b].
Comparative or superlative form of an adjective is usually used to express a comparative opinion. “iPhones have better performance than android phones” is an example of a sentence with comparative opinion.
Based on how the opinions are expressed, opinion can also be classified as implicit opinion and explicit opinion.
Explicit opinion can give either a regular or comparative opinion and usually involves a subjective statement. For e.g. “iPhone is the best” and “iPhones have better performance than android phones”.
Implicit opinion also known as implied opinion makes use of objective statement to imply a regular or comparative opinion. For e.g. “I bought an Android phone a week ago, it is already starting to lag every now and then”.
Most of the current research in sentiment analysis has focused on examining explicit opinions since they are easier to detect and classify that the implicit opinions. However, few study has been conducted on implicit opinions (ref Zhang and Liu, 2011b) and (ref Green and REsnik, 2009).
Levels of Sentiment Analysis
In academics, sentiment analysis has been studied at three levels of granularities:
Document Level: Document-level sentiment classification is a process of classifying an entire document as either positive or negative based on the sentiment polarity of that particular document [1]. It is assumed that the entire document is subjective and carries either a negative or positive polarity towards a single particular entity such as product review, customer feedback, news article, etc. This level of sentiment analysis is not suitable in cases where comparison of sentiments of multiple entities are required.
According to Liu [2] “Given an opinion document d evaluating an entity e, determine the overall sentiment s of the opinion holder about the entity e, i.e. determine s expressed on the aspect GENERAL in the quintuples (e, GENERAL, s, h, t). (_, GENERAL, s, _, _) where, the entity e, opinion holder h, and time of opinion t are assumed to be known or irrelevant (do not care)”.
Sentence Level: The task of sentiment analysis at sentence level is to determine the sentiment polarity of a text at a sentence level and classify it as either positive, negative or neutral. Unlike the sentiment analysis at document level, this level of sentiment analysis does not assume that the given text only contains the subjective information. Sentence level sentiment analysis can also relate to subjectivity classification (Wiebe, Bruce and O’Hara, 1999) which involves classifying a sentence as either subjective or objective. If a sentence contains factual information, then it is considered an objective sentence while sentence which expresses opinions and emotions rather than facts are considered subjective sentence. However, subjectivity does not necessarily reflect the sentiment of the sentence in all cases because many objective sentences can imply opinions. In a nutshell, sentiment analysis at sentence level deals with classifying sentences as positive, negative or neutral and may also include the subjectivity classification of the sentence.
Entity and Aspect Level: Both the document level and sentence level sentiment analysis focus on classifying the opinion of the opinion holder. However, both the document level and sentence level sentiment analysis misses out on identifying exactly what positive and negative aspect of the entity are expressed by the opinion holder. Aspect level analysis, initially known as feature level (feature-based opinion mining and summarization) (Hu and Liu, 2004) performs a finer-grained analysis by analyzing the sentiment itself rather than analyzing the language constructs such as documents, paragraphs, sentences, clauses, phrases, etc.
Aspect level sentiment analysis focus on three important aspects in an opinion; opinion expression, opinion targets and opinion holder.
For example:
“Although the 4.7-inch screen size is small for my daily use, I still love my iPhone 6s”
Opinion holder is the author of the opinion. In the above example, “I” is the opinion holder. Opinion expression is the terms which express the opinions in the sentence. In the above example, the term “love” expresses positive opinion in sentence, while the term “small” expresses a negative opinion. Opinion target is the object or entity about which the opinion is provided. In the above example “iPhone 6s” is the opinion target.
Aspect level sentiment analysis makes use of the concept that every opinion is attached to an opinion target. This level of sentiment analysis focuses on determining the sentiments on the entities or aspects described in the opinion expression by the opinion holder. In the above example sentence, the expressed opinion is positive about the iPhone 6S. However, it also expresses a negative sentiment on the screen size aspect of the iPhone 6S but with a relatively low emphasis.
Applications of Sentiment Analysis
Opinions are an integral part of all human activities as they influence our behavior and play a major role in the decision making process. More often than not we tend to care about other people’s opinions when making a decision. In ancient days, people used to ask friends and families when the seek for opinions. Similarly, every time businesses and organizations needed some opinions, they conducted surveys, opinion polls, and focus groups. In fact, collecting public opinions and consumer view point has been a business of its own for marketing, public relations, and political campaign companies.
Today with the burgeoning increase in the use of web and increased accessibility of internet in many parts of the world, the amount of content generated in web such as review, forum discussions, micro-blogs, twitter, blogs, posts in social networking sites is growing at an explosive rate. Today, people seldom ask their friends or family for an opinion, they leverage the reviews and opinions available in the web. For businesses and organizations as well, they seldom need to conduct surveys and opinion polls in order to gather public opinions because they could gather such opinions from publicly available sources in internet such as review forums or micro blogs and social networking sites. However, collecting and monitoring opinionated content on the web and extracting concrete usable information from such content is still an arduous task. Because of the diverse nature of the sites and huge volume of opinionated text, it is nearly impossible for an average human reader to extract and summarize the opinions from such content available in the web. Thus, there is a necessity of automated sentiment analysis system.
Sentiment analysis can be used for information extraction by discarding the subjective information in the text and only leveraging the objective content. It can also help recognize opinion oriented questions and seek out in answering such question. In addition, sentiment analysis accounts for multiple viewpoints thus creating a summarization of the opinions. It can also be used form “flame” detection, bias identification in news, filtering inappropriate content for ad placement, filtering swear words and unsuitable video based on comments, etc. Applications of sentiment analysis can be noticed in every possible domain, from businesses and services, consumer products, healthcare, financial services to social events and political elections.
Application of sentiment analysis in Business Intelligence
Businesses these days can hardly overlook the application of sentiment analysis. If leveraged properly, the information obtained from sentiment analysis can result in complete revitalization of brands. Based on the summarized opinion review obtained after sentiment analysis, businesses can estimate their customer retention rate, adjust to the present market situation and make plans to address the dissatisfaction of the customer. Sentiment analysis enables business to be more dynamic by helping them make immediate decisions with automated insights. Concept testing is very important in business to roll out any major change or introduce the next big idea. With sentiment analysis, business can easily roll out any new ideas such as new product, campaign, new logo, etc. for concept testing and analyze the sentiments attached to it.
Since sentiment analysis can be applied to any piece of text, it is prudent for businesses to perform sentiment analysis on publicly available opinionated texts of their competitors as well. This enables businesses to understand what their competitors are doing better and come up with a plan to poach customers from their competitors. Sentiment analysis also gives insights on current customer trends enabling business to implement better strategies and gain a leading edge over their competitors. Having a good product or services is not always enough for business to build up their reputation and attract customers. Online marketing, social campaigning, content marketing and customer support plays and important role in making a business popular and retaining customers. Sentiment analysis takes in to account all these factors and quantifies the perception of the current and potential customers. With the knowledge of negative sentiments, business can make the required changes in their branding and marketing strategy to appeal more customers and enabling them to make a quick transition.
Application of sentiment analysis in politics
Sentiment analysis have been widely used by political campaigners to analyze trends and identify ideological bias. In political campaigns, gauging reactions of group of people and figuring out the suitable message or agenda for a specific target group of people is quintessential, sentiment analysis can be leveraged to do all those above mentioned tasks. Similarly, sentiment analysis helps political parties gain an insight of general public opinions on their policy and evaluate the public or voter’s opinion.
Application of sentiment analysis in Sociology
In Sociology, idea propagation through groups is an important concept ( ref Rogers 1962, diffusion of innovations) . Identifying opinions and reactions to ideas play an important role in deciding whether to adopt any new ideas or not. Sentiment analysis can be used to detect mass reactions to any new concept or ideas.
In addition to real-life applications, many application-oriented research work has been published using sentiment analysis. A sentiment model for predicting sales performance was proposed by Liu et al in 2007 [ref liu et al. 2007] . An approach for ranking products and merchants using sentiment analysis was proposed by McGlohon, Galnce and Reiter in 2010 [ref McGlohon, Galnce and Reiter, 2010]. In 2010, Hong and Skiena, studied if the public opinions in blogs and Twitter has any connection with the NFL betting line [ref hong and Skiena, 2010]. Researchers have used twitter sentiments to link with public opinion polls [ref O’conner et al., 2010] , to predict election results [ref Tumasjan et al., 2010] and to study political standpoints [ref chen et al. 2010]. In [ref Asur and Huberman, 2010] [ ref Joshi et al., 2010] [ Sadikov, Parameswaran and Venetis, 2009], researchers have made use of Twitter data, movie reviews and blogs to predict box-office revenues for movies. Miller et al. in 2011 [ref Miller et al. 2011] studied the flow of sentiment in social networks.
Emotional differences between genders were analyzed using sentiments in mails [ref Mohammad and Yang, 2011] and emotions in novels and fairy tales were also studied [ref Mohammad,2011]. Researches have also been conducted to use sentiment analysis for predicting stock prices. Twitter moods were analyzed to predict the stock market [ref Bollen, Mao and Zeng 2011]. Similarly, in another research, sentiment analysis of microblogs post of expert investors were used to predict the stock price fluctuations [ref Bar-Haim et al., 2011] [ref Feldman et al, 2011]. Blogs and news sentiments were also used to study trading strategies [ref zhang and Skiena, 2010]. In addition, social influences were studied using online book reviews [ref Sakunkoo and Sakunkoo, 2009] and sentiment analysis was also used to characterize social relations [ref Groh and Hauffa, 2011].
In a nutshell, human being are subjective creates. Opinions and sentiment hold greater importance to human beings and being able to interact with people on that level has some major significance to the information systems.
Challenges in Sentiment Analysis
In addition to its real life applications, sentiment analysis is a popular research problem as it is a highly challenging Natural Language Processing (NLP) research topic. Although sentiment analysis has lots of applications, it is challenging to build a state of the art sentiment detection tools because of many barriers. Sentiment analysis deals with the opinions expressed by people, and people use many complex ways to communicate their views. Also the context in which the opinion has been expressed also plays a significant role in determining the sentiment. For e.g. “My whole seller does an exceptional job when it comes to charging more money for the goods”. Taking the complexity and context of the expressed opinion in to consideration while performing sentiment analysis is very challenging. In addition, sentiment ambiguity and sarcasm are also very difficult to take in to account while performing sentiment analysis and may result in labeling the sentences in to incorrect group.
Sometimes, a sentence with positive or negative words doesn’t necessarily mean it expresses such sentiment. For e.g. “can you recommend an awesome phone to buy?”. Although, the sentence has positive word “awesome”, it doesn’t express a positive sentiment. Similarly, some sentences can express sentiments although there are no sentiment words in the expressed sentence. For e.g. “This software makes use of lot of computer memory.”, holds negative sentiment although it doesn’t contain any sentiment words. Sarcasm is another factor which can alter the whole sentiment of the expressed sentence. For e.g. “Sure, I have plenty of time to proof read your article today when my thesis is due for submission tomorrow.”. Furthermore, the language used to express the opinion itself is a challenge for doing a sentiment analysis. It is very challenging to account for all the slang, dialects, and language variations.
Sentiment words also known as opinion words are without a doubt most important identifiers of sentiments. Positive sentiment words such as awesome, mind blowing, good, amazing, etc. and negative sentiment words such as horrible, bad, awful, etc. are usually used to indicate positive or negative sentiments. In addition to individual sentiment words, phrases and idioms can also be used as sentiment identifiers and play significant role in sentiment analysis. Sentiment lexicon also known as opinion lexicon is a list of such words, phrases and idioms. Many researchers have used different techniques to compile and make use of such sentiment lexicons for the task of sentiment analysis and are useful in many cases, however, they also have few limitations which are listed below:
- The orientation of sentiment word may depend on the application domain. For example, the word “suck” usually indicates negative sentiment, e.g., “This phone sucks” but can reflect positive orientation when used in different domain, e.g., “This vacuum tube sucks air really quick”.
- Sentiment words in sarcastic sentences are very hard to account for. Sarcasms are mostly prevalent in political discussions compared to product reviews making political opinions hard to work with.
- A sentence may not necessarily express sentiment although it contains a sentiment words. Interrogative and conditional sentences are two examples of such sentences. For e.g. “Can you tell me if Samsung Note 7 is good phone?”. Although, the sentence contains the word “good”, it doesn’t reflect positive sentiment.
Finally, it is important to address the fact that the underlying problem of sentiment analysis is Natural Language Processing (NLP). Sentiment analysis closely relates with the major elements of NLP such as negation handling, segregating word disambiguation, resolution of conference, etc. Although sentiment analysis is a very narrower NLP problem, it is very difficult one because of the major elements of NLP mentioned above which are tied with the sentiment analysis. Those problems do not itself have a concrete solution in NLP to utilize in the sentiment analysis tasks.
Challenges in Social Media Sentiment Analysis
With the advent of social networking sites and mobile technologies, the amount of opinionated content on the web is on the rise. People from all over the globe can express their views and opinions freely in the web. People seldom have to worry about the consequences of posting their thoughts on the web and they may even use anonymity to express their opinion. Even though, these opinions of people extremely valuable for social media analysts and sentiment analysis, it comes with a price. Regardless to say that when people don’t have to fear about the consequence of their opinion on the internet, it is very likely that people with malicious agendas can take advantage of such freedom. People can fake their opinion and post biased reviews on the internet to belittle any person, products, organization, etc. Not only people some organizations and commercial companies also do not shy away from posting fake reviews, forum discussions and online posts to spread negative rumors about their competitors to gain a competitive edge in the market. These individuals and organizations posting fake reviews and opinions are known as opinion spammers and this tendency of posting biased views is known as opinion spamming [ref Jindal and Liu 2008; Jindal and Liu 2007].
Opinion spammers and opinion spamming is a major problem when studying social media sentiment analysis. Opinion spammers tends to skew the results of the sentiment analysis and show biased results, hence it is of utmost importance to detect any spamming activates. Number of researches has been conducted to detect spams and spammers in social media sites such as Twitter. [ref Spam filtering in twitter using sender-receiver relationship ,, Don’t follow me: Spam detection in Twitter;; Spam detection on twitter using traditional classifiers] Only trusted sources and reviews can be taken in to consideration to mitigate the effect of opinion spammers and opinion spamming when conducting a social media sentiment analysis.
Chapter 3 Classifier and Feature Vector Construction / OUR APPROACH
Feature selection/feature vector Creation
A n-dimensional vector of numerical features representing some object is known as feature vector. Feature vectors play an integral role in pattern recognition and machine learning tasks. A vector space called feature space is associated with these feature vectors. Since numerical features ease the processing and statistical analysis, most machine learning algorithms require a numerical representation of objects as features. For example, in the task of image classification, corresponding pixel values of images can be used as features.
Since, machine learning algorithms require numerical features as input to train the classifiers, feature extraction techniques are employed to convert the textual data into numerical features for the task of sentiment analysis. In this research we employed Bag of Words with and without term frequency – inverse document frequency (tf-idf) and word embedding models like word vector and paragraph vector to create feature vectors from the texts. These feature extraction techniques are described below:
http://machinelearningmastery.com/feature-selection-machine-learning-python/
Bag of Words (BOW)
Bag of words model is a technique used in information retrieval and natural language processing which is based on a basic idea of representing a document as an unordered list of words. The advent of “bag of words” in linguistic context dates back to 1954 in an article published by Zelling Harris [ref Harris, Zellig (1954). “Distributional Structure”. Word. 10 (2/3): 146–62.]. In addition to its application in natural language processing and document classification, bag of words model has also been used for computer vision applications [ref Sivic, Josef (April 2009). “Efficient visual search of videos cast as text retrieval” (PDF). IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 31, NO. 4. IEEE. pp. 591–605.].
In bag of words model, a document or a text is represented as an unordered list of the words contained in the document. Bag of words model does not take the grammatical structure, semantic meaning and word order of the document in to consideration. However, the multiplicity of occurrence of each word is of high significance. The Bag of words model creates its vocabulary list from the documents, then models each documents by counting the number of times each word appears in that particular document.
For example, consider below three text documents:
- Ronaldo is an exceptional footballer. Messi is also an exceptional footballer.
- Ronaldo is from Portugal.
- Ronaldo plays professional football for RealMadrid.
Base on the above documents, a bag of words model will create a list of vocabulary as follows:
[“Ronaldo”, “is”, “an”, “exceptional”, “footballer”, “Messi”, “also”, “from”, “Portugal”, “plays”, “professional”, “football”, “for”, “RealMadrid”]
In machine learning applications for text classification, bag of words model is widely used as a technique for feature generation. The frequency of occurrence of each words in the given document, also known as term frequency is given high priority while creating features using the bag of words model.
In the above example, for the first document, we can count the number of times each words occurs in the document and create the feature vector as follows:
[1, 2, 2, 2, 2, 1, 1, 0, 0, 0, 0, 0, 0, 0]
where each number in the list corresponds to the number of times that particular word from the vocabulary list appears in the first sentence. We see that for the first sentence, words such as “exceptional”, “footballer” appears two times. However, other words from vocabulary list such as “professional”, “plays”, etc. are missing in the sentence.
Bag of words model just considers only one word at a time and ignores the continuous sequential occurrence of the words. To overcome this limitation of the bag of words model, an extension of the bag of words also known as bag of n-grams model can be employed. An n-gram model will consider n number of items such as phonemes, syllables, characters, base pairs, words, etc. that occur sequentially in a given text and speech. Unigram is an n-gram of size one. Similarly, n-grams models with size 2 is known as bigram, size 3 as trigram and so on. In addition to the inability of bag of words model to account for multi-word expressions and phrases it also doesn’t consider the potential word variations and misspellings. Using n-gram model can overcome such issues of misspellings and different variations of the same word. Like bag of words model, the n-gram model also has its own sets of disadvantages. Bag of n-grams model is not suitable for applications where the major goal is modeling long range dependencies, since n-grams model is unable to explicitly capture long range dependencies because of its inability to distinguish unbounded dependencies from noise.
Word2Vec
Word2vec is a group of related shallow, two-layer neural networks used to produce word embeddings. A large corpus of text is used as an input for Word2vec and it outputs a vector space. The vector space output obtained from Word2vec has each unique words from the input corpus which is being assigned as a corresponding vector in the space, usually of several hundred dimensions. Word2vec approach is able to understand the semantic and syntactic patterns in the words and reconstruct the linguistic contexts of words, the output vector space contains the word vectors such that the analogous words and words with common contexts in the corpus are located at closer proximity to one another [ref Mikolov, Tomas; et al. “Efficient Estimation of Word Representations in Vector Space].
Word2vec was published by a team of researchers led by Tomas Mikolov at Google in 2013 [ref Mikolov, Tomas; et al. “Efficient Estimation of Word Representations in Vector Space]. Word2vec is more popular compared to all other existing deep or neural network models for learning distributed representations because of its relatively fast speed compared to other models. Word2vec has also been applied to other applications such as twitter network analysis, network traffic analytics, named entity association, etc [ref https://gab41.lab41.org/anything2vec-e99ec0dc186].
Word2vec is not a single monolithic algorithm, it consists of two model architectures namely, continuous bag of words (CBOW) and continuous skip-gram. In the continuous bag of words architecture, the model makes use of the window of surrounding context words to predict the current word irrespective of the order of the context words. While, skip-gram architecture gives more importance to the nearly context words compared to the more distant context words [ref Mikolov, Tomas; Sutskever, Ilya; Chen, Kai; Corrado, Greg S.; Dean, Jeff (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems.]. According to the author’s note [ref “Google Code Archive – Long-term storage for Google Code Project Hosting.”. code.google.com. ], CBOW is faster compared to skip-gram model, however, skip-gram model is preferred in cases where more infrequent words are present. Both of the above mentioned architecture can be trained with two different training algorithms, hierarchical softmax and negative sampling. According to the authors, hierarchical softmax is preferred for infrequent words while negative sampling is preferred for frequent words. They also state that negative sampling is better with low dimensional vectors [ref 5 “Google Code Archive – Long-term storage for Google Code Project Hosting.”. code.google.com. ] while hierarchical softmax are better suited when less training epochs are used [ref Parameter (hs & negative)”. Google Groups. Retrieved 2016-06-13.6].
One of the major advantage of Word2vec is that it does not require labeled dataset to create distributed representations for words, which is most likely the case in real word scenarios. If the model is provided with enough unlabeled training data, Word2vec can cluster word vectors with similar meanings together. Such clusters are spaced out in such a manner that some word relationships, such as semantic and syntactic patterns, analogies, etc. can be reproduced with vector arithmetic. With highly trained word vectors, the vector representation of “Brother” – “Man” + “Woman” can yield a result with vector representation of “Sister” in the model.
Doc2Vec (Paragraph vectors)
https://cs.stanford.edu/~quocle/paragraph_vector.pdf
Doc2vec also known as paragraph vectors, is a group of unsupervised, shallow, two-layered neural network to generate vectors for sentence, paragraphs or documents. Doc2vec is considered an extension of Word2vec which produce vectors for words. Although stochastic gradient descent and backpropagation [ref Rumelhart, David E, Hinton, learning representation by back-propagating errors] was used to train both word vectors and paragraph vectors, paragraph vectors are unique among paragraphs while the words vectors are shared. Using Doc2vec an entire sentence or paragraph or documents can be represented as a fixed-length vector which can be used as an input for all standard machine learning classification algorithms. Each document is represented by a dense vector and is trained to predict words in the document. Unlike existing fixed-length features bag-of-words and bag-of-n-grams which loses the ordering and ignore the semantics meaning of words, paragraph vector aims to preserve them and overcome the shortcomings of bag-of-words and bag-of-n-grams model.
Paragraph vector is general and is capable of constructing vector representations of input sentences of variable length: sentences, paragraphs, and documents. There is no necessity of task-specific tuning of the word weighting function and parse trees.
Doc2vec have shown exceptional results in cases of text classification and sentiment analysis. According to the paper [ref distributed representation of sentences and documents, Tomas Mikolov], paragraph vectors achieved relative improvement of more than 16% in terms of error rate on sentiment analysis task compared to any other existing complex methods. Also, for the task of text classification, paragraph vectors achieved a relative improvement of about 30%.
Paragraph vector consists of two different architectures that can be used to create vectors for any text documents. They are Distributed Memory Model and Distributed Bag of Words Model. Distributed Memory Model is inspired by learning methods of word vectors and makes use of the word vectors to predict the next word in the sentence despite being initialized randomly. While the Distributed Bag of Words model force the model to predict the output words based on random samples from the paragraph, ignoring the context words in the input.
In addition to addressing the important weakness of bag-of-words and bag-of-n-grams model to create fixed length feature vectors by inheriting the semantics of the words, paragraph vectors can make use of unlabeled data. In most real word classification problems, where limited amount of labeled data is available, Paragraph vectors can be employed to make use of the unlabeled data to train the model and create feature vectors.
Machine learning Classifiers
What is machine learning? Supervised and unsupervised and reinforcement learning? Why use different classifiers? Applications of machine learning? Why use machine learning for sentiment classification? Shortcommings of machine learning for sentiment classification? TOD0 word count increase
Machine learning is an extension of artificial intelligence which makes use of pattern recognition and computational learning theory to automate analytical model building and construct algorithms with the ability to iteratively learn from data and make predictions. In 1959, Arthur Samuel described machine learning as “subfield of computer science that gives computers the ability to learn without being explicitly programmed” [ref machine learning and optimization Andres Munoz ]. Machine learning algorithms can be used to build model from sample inputs, overcoming the limitation of static program instructions and thus making data driven prediction or decision task easier. Machine learning holds close ties with fields like computational statistics and mathematical optimization. Tom M. Mitchell defined machine learning in fundamentally operational sense as: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” [ref Mitchell T 1997, machine learning. McGraw Hill]. Depending upon nature of learning and feedback available to the learning system, machine learning algorithms can be broadly classified in to three categories namely supervised learning, unsupervised learning and reinforcement learning.
In supervised learning tasks the machine learning model is provided with the labeled training data consisting of an input object which is usually a vector and the output class associated with that object. Based the labeled training data, supervised machine learning models should infer the underlying association between the input object and the output class and should correctly predict the output class for any new input object provided to the model.
Unlike in supervised learning, unsupervised learning is provided with unlabeled data as training data. The training data only contains the input object and is not associated with any output value. It is left to the unsupervised machine learning classifier to figure out the structure and association in its input and create a cluster of similar inputs and therefore categorizing them in to different output classes. Clustering, Anomaly detection, Neural Networks, etc. are some of the approaches associated with unsupervised learning.
Reinforcement learning inspired by the field of behaviorist psychology is an area of machine learning in the machine learning model interacts with the dynamic environment with an aim of achieving certain goal. A feedback is provided to the machine learning model based on its performance to enable the model to learn from it. Unlike in supervised learning, reinforcement learning is never provided with the labeled correct pairs of input and output and the sub-optimal actions are also not explicitly corrected. For problems which requires the long-term versus short-term reward trade-off, reinforcement learning excels at solving them. Some examples of applications of reinforcement learning are elevator scheduling, robot control, backgammon, Alpha Go, checkers, etc.
Application of machine learning
Machine learning is a widely researched field in Computer science these days and the prowess of machine learning have been utilized to make lots of real life applications. Skype, online messaging and video calling app owned by Microsoft used machine learning to develop real time speech conversion from one language to another enabling both parties to speak in their native language. [ref http://www.skype.com/en/translator-preview/].
Machine learning techniques has been utilized to monitor video surveillance content from CCTV. Using machine learning daily feeds of the surveillance video is used to detect any suspicious actions of robbery, terrorist attacks, etc. Proper extension and implementation of such systems can indeed make our society much safer by giving real time information of suspicious activities to the security authorities. [ref http://www.wisdom.weizmann.ac.il/~vision/Irregularities.html].
Machine learning has seen its application in hospitals and doctors are using computational approach to assist them in diagnosing diseases. IBM designed a system which could make use of x-ray images to correctly determine the cancers tissues in the images with an astonishing accuracy of 95% which is much higher than the doctor’s manual accuracy of 75%-84%. [ref https://www.ibm.com/blogs/research/2016/11/identifying-skin-cancer-computer-vision/] Machine learning systems with its application in health care can really enable doctors to make informed decisions in shorter period of time. In addition, many startup companies are leveraging the power machine learning technology to make products in the field of Health care. Healint [ref https://www.healint.com/], a Singapore based startup created an app called JustShakeIt which allow the end user to shake their phone with one hand to notify of emergency to emergency contacts. Machine learning algorithm used in the app can distinguish actual emergency shakes from normal everyday shake. Furthermore, Health care companies are employing a technique known as Discrete Event Simulation in order to predict wait duration for patients in emergency waiting rooms.
Google’s self-driving car is also an example where the application of Machine learning can be seen. The car uses laser and creases a 3D map of its near surrounding which when coupled with high resolution real word map can produce different types of data models which can be analyzed by software to help navigate the car safely. [ref https://www.google.com/selfdrivingcar/ https://waymo.com/]
Machine learning has also been utilized to create applications for environment protection. A joint effort of Marinexplore and Cornell University is trying to come up with a system to locate whales in the oceans based on the audio recordings of the sounds produced by whales. Whales have the ability to produce half a dozen different types of sounds. Using the audio recordings data and applying concept of Machine learning, the researchers are trying to pinpoint the location of the marine whale animals so that the ships can avoid colliding with them. [ref https://www.kaggle.com/c/whale-detection-challenge]. In addition, Oregon State University conducted a research in which they applied machine learning techniques to identify the species of birds based on their sounds. Since birds are the good indicator of biodiversity, the research of this sort can be utilized to assess environmental problems like climate change and habitat loss. [ref http://engineering.oregonstate.edu/finding-notes-in-noise]
In addition, there are numerous applications of machine learning we see in everyday life. Search engines like Google, Yahoo, Bing, etc. makes use of machine learning to autocomplete search queries in their search bar. Email providers like gmail, yahoo mail, outlook, etc. also makes use of machine learning and natural language processing to identify spam emails. Companies like Netfilx and Amazon has developed recommendation engine to show recommended movies or products to their users. Such recommendation engine makes heavy use of machine learning under the hood. Personal assistance systems in mobile operating system such as siri and google assistance makes use of machine learning for voice commands and speech recognition. Similarly, Facebook posts ranking, face detection in photos app, handwriting classification in smartphones, credit card fraud detection etc. all are the applications of machine learning.
In this research we make use of the three different types of machine learning algorithms. One each from the most common types of linear, probabilistic and ensemble algorithms are chosen which are described in brief in the section below.
Logistic Regression
http://shodhganga.inflibnet.ac.in:8080/jspui/bitstream/10603/118189/4/thesis.pdf
Logistic Regression is a regression based statistical technique developed by statistician David Cox in 1958 [Cox, DR (1958). “The regression analysis of binary sequences (with discussion)”] where the dependent variable is categorical. The dependent variable can either be a binary dependent variable or can have multiple outcomes. Logistic Regression is widely used as a linear machine learning algorithm. In simple machine learning classification problem, the logistic regression algorithm is used to obtain a best-fit logistic function to classify a given input in to various classes. Since the independent variables don’t have equal variance in each group or don’t have to be normally distributed, logistic regression is considered as one of the robust algorithms. In addition, logistic regression can also handle nonlinear effects as it does not assume a linear relationship between the independent variables and dependent variables. Logistic regression is less prone to over-fitting as has low variance and is intrinsically simple and will work better in cases with single decision boundary.
Random Forest
Random forest, also known as random decision forests first proposed by Ho in 1995 [ Ho, Tin Kam (1995). Random Decision Forests (PDF). Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14–16 August 1995. pp. 278–282.] is an ensemble based learning algorithm for classification or regression tasks. Paper published by Leo Breiman [ Breiman, Leo (2001). “Random Forests”. Machine Learning. 45 (1): 5–32. doi:10.1023/A:1010933404324.] illustrated the approach of using CART like procedure combined with randomized node optimization and bagging to build a forest of uncorrelated tress which served as the basis for modern practice of random forests.
Random Forest is considered one of the simplest algorithm to understand and interpret as the tress and nodes in the tress can be visualized graphically [16 Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Robert (2015). An Introduction to Statistical Learning. New York: Springer. p. 315.]. Random Forest is superior to other classification algorithms because of its ability to handle both numerical and categorical data [16]. Random Forest algorithm is a type of decision tree algorithm which closely replicates human decision making process, thus making it useful in cases where modeling human decisions or behavior are required [16]. Unlike other algorithms, random forest does not require data normalization. It can handle qualitative predictors thus removing the necessity of creating dummy variables and easing the task of data preparation [16]. In addition, random forest can analyze very large datasets in reasonable time using standard computing resources.
Random Forest also comes with their own set of short comings. They are neither considered to be accurate nor robust [16]. Decision-tree algorithms like random forest are prone to create over-complex or overfitting models which may not generalize well from the training data.
Naïve Bayes
In Machine learning, Naïve Bayes falls under the category of probabilistic classifiers. Naïve Bayes is a simple statistical technique for constructing classifiers based on Bayes theorem[ref]. Generally, for Naïve Bayes classification models, class labels drawn from some finite set are assigned to problem instances and are represented as vectors of feature values. Given the class variable, all Naïve Bayes classifiers assume that all features have their own independent value and will contribute independently to the probability that the given item with fall in that particular class.
Although, Naïve Bayes classifiers are considered to have naïve design and simplistic assumptions, researches have proven that in real-world scenarios their performance are quite good. A research conducted in 2004 illustrated few theoretical reasons behind the effectiveness of the naïve Bayes classifiers [ Zhang, Harry. The Optimality of Naive Bayes (PDF). FLAIRS2004 conference.]. However, another research in 2006 made an empirical comparison with other classification algorithms and concluded that Bayes classification is outperformed by approaches, such as random forests and boosted trees [Caruana, R.; Niculescu-Mizil, A. (2006). An empirical comparison of supervised learning algorithms. Proc. 23rd International Conference on Machine Learning.].
Naïve Bayes algorithms are very popular for the task of text categorization. Text categorization involves the task of categorizing a given document to a category class. Few examples of text categorization involve spam or legitimate email detection, topic wise webpage categorization, etc. Naïve Bayes algorithms are also popular for creating hybrid recommender system.
Despite the fact that Naïve Bayes algorithm are fast to train, fast to classify, not sensitive to irrelevant features, and handles real, discrete and streaming data very well; it also has few short comings. Since, Naïve Bayes classifier makes a strong assumption that any two features are independent of the given output class, the classification result can be potentially bad. Naïve Bayes classifiers are also not suited in cases with data scarcity where frequentist approach is required to estimate a likelihood value for any possible value of a feature. A paper published in 2003 [ Rennie, J.D., Shih, L., Teevan, J. and Karger, D.R., 2003. Tackling the poor assumptions of naive bayes text classifiers. In ICML (Vol. 3, pp. 616-623).] elaborate on additional drawbacks of using a Naïve Bayes classifier for text categorization, it explains cases where the classes are imbalanced and cases of using continuous features.
Naïve Bayes Classifier makes use Bayes theorem under the hood. Bayes theorem provides a way of calculating the posterior probability. According to Bayes theorem:
Pcx= P(x|c)P(c)P(x)
whre,
Pcxis the posterior probability of class given the predictor
P(c)is the prior probability of the class
P(x)is the prior probability of the predictor
Pxcis the probability of the predictor given the class
Naïve Bayes classifier assumes that the effect of the values of a predictor(x) on a given class (c) is independent of the values of other predictors. This assumption is also known as conditional independence. Hence, given a dependent feature vector (x1, x2, x3,…,xn) and class variable (c) and using Naïve Independence assumption,
Pcx1,x2,…,xn= P(x1,x2,…,xn|c)P(c)P(x1,x2,…,xn)
A frequency table for each attribute against the target can be constructed and the posterior probability can be calculated at first. Then those frequency tables can be transformed to likelihood tables and the posterior probability for each class can be calculated using the Naïve Bayesian equation and finally the class which ever results in highest probability is the designated as the outcome of the prediction. There are different types of naïve Bayes classifier which mainly distinguishes themselves in the way they assume the distribution of the probability of the predictor given the class. Some variants of Naïve Bayes classifiers are Multinomial Naïve Bayes, Bernoulli Naïve Bayes and Gaussian Naïve Bayes.
Literature Review
Sentiment analysis works
The overall general concept and approaches to consider for carrying a sentiment analysis tasks have been mentioned in the books published by Liu [ref Bing Liu sentiment analysis and opinion mining, 2012 morgan and claypool], and Pang and Lee [ref opinion mining and sentiment analysis. Foundations and Trends in information retrieval ]. Basically, according to these books they take sentiment analysis as a classification problem where a given text must be assigned with a label either positive, negative or neutral. They also mentioned that in cases requiring continuous output, sentiment analysis can also be considered as a regression problem. The major application and challenges in the field of sentiment analysis is described by Feldman [ref Techniques and applications for sentiment analysis]. In another paper [ref monotyo overview of current state of the area and envisaged], the authors discussed about the subjectivity analysis and studied sentiment analysis as a tool for identifying, extracting and classifying opinions regarding different topics in a given textual context. They proposed a clustering algorithm to classify adjectives into different orientations.
Majority of initial work dealing with sentiment analysis made use of some kind of partial knowledge based techniques. A research by Hatzivassiloglou and McKeown focused on identifying and classifying the semantic orientation of conjoined adjectives using a log-linear model [ref hatzivassiloglou and Kathleen Mckeown—predicting the semantic orientation of adjectives]. In another similar research, the author made use of web search engine and point wise mutual information to categorize the orientation of words from a corpus of one hundred billion words which included adjectives, adverbs, nouns, and verbs [ref Peter D.turney and Michael L littman – unsupervised learning of semantic orientation]. Both of these research made use of pre-defined set of seed words and linguistic heuristics in their research. Previous work that focused on sentiment categorization of the entire documents involved two different models. The first one is a model that made use of cognitive linguistics [ref hearst, 1992 direction based text interpretation ] and the other one focused on constructing manual or semi-manual discriminant word lexicons. [ref huettner and Subasic 2000 Fuzzy typing for document management] [ref Das and Chen, 2001 Yahoo! for Amazon: Extracting market sentiment from stock message boards]. In addition to works that deals with sentiment classification of documents, few research has been conducted to determine whether a given document expresses an opinion or not. These researches attempted at determining the subjective genres of texts [ref Karlgren and Cutting 1994 Recognizing Text Genres With Simple Metrics] [Kessler et al 1997 Automatic detection of text genre]. Other work attempted to detect the features to identify if a given document has subjective language or not [ref Hatzivassiloglou and wiebe 200 Effects of adjective orientation and gradability] [wiebe et al 2001 Identifying Collocations for Recognizing Opinions ].
Machine learning approaches are widely popular for the task of sentiment analysis. In 2002 Pang, Lee and Vaithyanatham made use of the movie reviews data set of classify the overall sentiment of the reviews. They concluded that machine learning techniques produced better relative performance for the task of sentiment classification compared to human generated baselines. Amongst the different machine learning classifiers employed on their research they found that Support Vector Machine (SVMs) had the best performance while Naïve Bayes performed the worst [ref pang, lee ref Thumbs up? Sentiment classification]. In another research the author attempts at using machine learning techniques for sentiment classification task taking the domain and time in to consideration besides having matching training and testing data in accordance to a topic.
The author made use of emoticons to create a labeled training data to ensure that the training data is independent of domain, topic and time. They concluded that the domain, topic, temporal and language style are closely dependent in the task of sentiment classification [ref J.read Using emoticons to reduce dependency ]. In 2012, researchers Wang and Manning, used machine learning approach with model variation and feature variation for the task of text classification. The concluded that using bigrams features resulted in better results for the task of sentiment classification.
Furthermore, regarding the choice of machine learning algorithm they author concluded that for short snippet sentiment analysis task Naïve Bayes outperformed Support Vector Machine (SVMs), however, the results were reversed when the document lengths were increased. [ref Wang and manning baselines and bigrams]. Traditional approaches in sentiment analysis using machine learning makes use of Bag of Words (BOW) model to map documents to a feature vector and then feed in as an input to machine learning classifiers. Although Bag of Words model is widely adopted because its simplicity and efficiency, it lacks in retaining the information from the original natural language text because bag of words method tend to break the syntactic structure and do not consider the odering of the words [ref Xia & Zong 2010, research gate, exploring the use of word relation features for sentiment classification]. To overcome such issues of bag of words method researchers have opted to employ different features for sentiment analysis tasks such as higher order n-grams [ref pak and paroubek, twitter as a corpus for sentiment analysis] and Part of Speech (POS) tagging. Using Part of Speech tagging is usually preferred for syntactic analysis process and have resulted in accuracy nearing 90% [ref Gimpel- part of speech tagging for twitter ].
Sentiment analysis in other language
With the proliferation of non-English textual content on internet, many researches have be conducted which apply sentiment analysis techniques in non-English text. Tan & Zhang [ref empirical study of sentiment analysis for Chinese documents] used four feature selection approaches and five machine learning algorithms on chine review documents which were parsed and tagged using Chinese text POS tagger tool. The feature selection methods they used were document frequency, information gain, mutual information and CHI. Using document corpus from three domains education, movie and house as dataset they concluded that information gain feature selection method when used together with Support Vector Machine resulted in maximum accuracy. Similarly, Duwairi & Qarqaz [ref Arabic sentiment analysis using supervised classification] analyzed sentiment classification using supervised machine learning approach in Arabic text. Kaya, Fidan, & Toroslu [ref sentiment analysis of Turkish Political News ] classified sentiments in political news domain in Turkish language.
They used bag of n-grams model coupled with three different machine learning algorithms namely Maximun Entropy, Naïve Bayes and SVM. Zhang, Ye, Zhang, & Li [ref sentiment classification of Internet restaurant reviews written in Cantonese ] used online restaurant reviews in Cantonese language and performed a sentiment analysis on them. They used SVM and Naïve Bayes classifier to train their model and concluded that Naïve Bayes coupled with bigrams as feature and Information gain as feature selection method outperformed trigrams and unigrams. Phani, Lahiri & Biswas [ref sentiment analysis of Tweets in three Indian languages] used the SAIL dataset [ref Braja Gopal Patra, shared Task on Sentiment Analysis in Indian Languages (SAIL) tweets] to classify sentiment on tweets in three major Indian language namely Hindi, Bengali and Tamil. They focused on using language independent simple, scalable, robust features rather than complex and language specific features in their research.
Sentiment analysis on social media twitter
With the advent of social media and the burgeoning of opinionated content on the social media, the sentiment analysis of posts in social media platform such as Facebook and Twitter has been of greater area of interest. One of the initial studies of Twitter sentiment analysis was done in 2009 by Go et al. [ref Alec Go, Richa Bhayani, lei huang, Twitter Sentiment classification using Distant Supervision]. They focused on solving the problem of query driven classification tasks. They used emoticons to labels the tweets which resulted in noisy corpus but still achieved an accuracy above 80%. A corpus consisting of 300,000 labeled tweets as positive, negative and neutral was developed by Pak and Paroubek in 2010 [ref Twitter as a corpus for sentiment analysis and opinion mining].
They made use of newswire tweets and happy and sad emoticons query to create that corpus. The authors in that research aimed at investigating the POS tags and sentiment labels of a tweets. In 2011, Kouloumpis et al. concluded that using part of speech as features does not improve the performance of classifiers for the task of Twitter sentiment analysis [ref Twitter sentiment analysis: The Good the Bad and the OMG! ]. Entity level Twitter sentiment analysis was performed by Zhang et al. [ref Combining Lexicon based and learning based methods for twitter sentiment analysis]. Furthermore, in 2012, Wang et al. created a real-time Twitter sentiment analysis system for analyzing tweets relating to US Presidential elections [ref Hao Wang , a system for real time twitter sentiment analysis of 2012 us presidential election cycle].
Deep learning and word2vec
Compared to the traditional approaches adopted in sentiment analysis, the advent of deep learning techniques has opened new horizons and possibilities. Deep learning has shown excellent results in Natural language processing tasks including sentiment analysis [ref Collobert et al., 2011natural language processing (almost) from scratch ]. Deep learning makes use of deep neural networks [ref alpaydin, 2014 Introduction to machine learning MIT press] to learn complex features extracted from data with the help of minimum external contribution [ref Bengio 2009 learning deep architectures from ai]. However, it has been noted that deep learning approaches require huge amount of data to get significant performance boost [ref Mikolov, Chen, Corrado & Dean, 2013 efficient estimation of word representation in vector space]. Pouransari and Ghili used deep learning techniques to classify sentiment of movie reviews [ref Deep learning for sentiment analysis of movie reviews].
They experimented with two different data sets with binary lables and multi-class labels. They used deep learning methods namely skip-gram word2vec and recursive neural tensor networks (RNTN) to create feature vectors for machine learning classifiers. In a research by Su et al. they used a neural network tool, word2vec to classify sentiments in Chinese text [ref Chinese sentiment classification using a neural network tool]. This research aims at extracting semantic features from text compared to the existing researches which focus mainly on syntactic and lexical features. The author made use of a neural network tool called word2vec which creates vector representation of words in high dimension and thus easing the extraction of deep semantic relationship between the words. They used a data set consisting of comments on Chinese clothing products and obtained an accuracy of over 90 percent. Likewise in another research by Xue, Fu and Shaobin also used the shallow neural network model word2vec to classify sentiment of posts made in Chinese sina weibo[ref a study on sentiment computing and classification of sina weibo with word2vec].
Nepali language sentiment analysis
Till date three different research work has been published that explicitly address the issue of sentiment analysis of Nepali text. In 2014, S. Thakur and V. Singh employed a hybrid approach to classify sentiments in Nepali texts [ref S. Thakur and V. Singh augmented lexicon pooling]. First they used Naïve Bayes machine learning classifier and then used domain based multinomial lexicon pooling to augment the results. The authors used Nepali news article from five different domains namely arts and entertainment, business and economics, politics, science and technology, and sports as the dataset for conducting their experiments. They concluded that this hybrid approach of using augmented multinomial lexicon pool outperforms the baseline results obtained by just using the Naïve Bayes classifier.
The authors also claim that using this approach will help to mitigate the unavailability of linguistic resources in Nepali language such as stemmer, stop words list, part of speech tagger, negation words, etc. Another research by C. Gupta and B. Bal also made use of news articles in Nepali language to perform a document level sentiment analysis of Nepali text [ref detecting sentiment in Nepali language, a bootstrap approach]. The extracted editorial articles from popular news platform in Nepali ekantipur and nagariknews to create a Nepali sentiment corpus. Since there is no available lexical resource for Nepali language, they developed their own Nepali sentiWordNet called Bhavanakos. They used the developed lexical resource to detect sentiment words in the Nepali text to identify the sentiment polarity of the document.
Furthermore, they also used the machine learning approach to classify the sentiment of the document and compared the result with the previous resource based approach. The authors conclude that the resource based approach rely heavily on the sentiment words in the lexicon dictionary thus they are prone to error compared to the machine learning approach. They also suggested that increasing the amount of training data will yield better performance out of the machine learning classifiers. L. Thapa and B. Bal used machine learning approach to classify sentiments in Nepali book and movie reviews [ref classifying sentiments in Nepali subjective texts].
In this research the authors compared three different machine learning classifiers namely Logistic Regression, Support Vector Machine and Multinomial Naïve Bayes for the task of sentiment classification of book reviews and movie reviews written in Nepali language. They used five-fold cross validation technique to compare the performance of the three machine learning model taking F-measure score and accuracy score as the performance evaluation metrics. They used four different feature sets for feature extraction namely bag of words, bag of words with stop words removed, tf-idf and tf-idf with stop words removed. They conclude that multinomial Naïve Bayes algorithm yields better F1 score when taking tf-idf as feature set without removing the stop words. Furthermore, Multinomial Naïve Bayes also showed better results when using bag of words as feature compared to logistic regression and support vector machine classifiers.
Our Approach / Proposed Research Methodology, can be a separate chapter of its own, like in the Nepali paper, Data preparation, packages used, parameters used and so on
Conceptual Framework/Overview
In this research we use machine learning approach to to perform sentiment analysis on Nepali tweets. Our conceptual framework is quite similar to other machine learning model and has five stages namely Data Collection, Data Preprocessing, Feature Extraction, Model Preparation and Model Evaluation. However, we have employed various techniques to create the feature vectors to perform the comparative study of the results obtained from the machine learning model.
Data Collection
In the first stage, we collected a raw corpus of Nepali tweets from Twitter servers. We used Twitter REST API to collect tweets. Twitter REST API provides the search functionality where we could specify the language and the API will return tweets containing the specified language [ref https://dev.twitter.com/rest/public/search]. By setting the language parameter to Nepali: lang = “ne”, we could retrieve Nepali tweets using the twitter REST API. Since, there is no publicly available corpus of labeled data to perform sentiment analysis on Nepali text, we manually created a labeled corpus of positive and negative Nepali tweets. In addition to the language parameter we also used emoticons as query parameter of Twitter REST API to automatically label tweets as positive and negative. All Nepali tweets returned by the API when positive emoticons such as :), :D, :-), etc. were used as the search query were labeled as positive. Similarly, all Nepali tweets returned by the API when negative emoticons such as :(, :-(, :’‑( ,
We checked for redundant tweets and all the retweets were removed from the corpus. Similarly, tweets containing no emoticons or both positive and negative emoticons were also removed. Finally, two individual raters were assigned to check for the validity of the annotated tweets and remove any tweets that hold sarcastic or objective information. Our final labeled corpus of Nepali tweets contains a total of 4238 unique original Nepali tweets consisting of 2119 positive and 2119 negative tweets. In addition to the labeled corpus, we also created an unlabeled corpus of Nepali tweets which contains a 50,000 original Nepali tweets. Python programming language package called Tweepy [ref http://www.tweepy.org/] was used to make request to the Twitter API and retrieve the tweets. TODO check for the number of tweets in labeled and unlabeled corpus
Data Preprocessing
Once we have the corpus of labeled and unlabeled tweets, we need to preprocess the Nepali tweets to make it ready for the feature extraction process. In order to ensure that the classifier would use the textual content rather than the emoticons to classify the tweets, the first thing we did was we removed those label generating emoticons from all the tweets. In addition, we also removed few other things from the tweets such as URLs, all non-Nepali words, user-names, hash tags and the pictures.
Feature Extraction
Once we have preprocessed data set of labeled and unlabeled Nepali tweets, the next step is to create feature vectors. Since the machine learning classifiers doesn’t accept variable length of raw text as input, we need to convert our text data into some form of numerical vectors. In this research, we use three different techniques to extract feature vectors for the machine learning classifiers and do a comparative study on the performance of the classifiers for each feature extraction technique. Three techniques used for feature extraction in our research are described below:
Bag of Words or Bag of n-grams
In this research we have used open sourced Python library called scikit-learn [ref] to get feature vectors for our text data using Bag of Words model. Most common ways for extracting numerical features from text content such as tokenizing, counting and normalizing are in built in to scikit-learn library. The tokenizing process involves breaking the text in to string tokens and assigning them with integer id using white-space or any other punctuation as token separators. Counting involves keeping the track of occurrences of tokens in each document. Normalizing involves weighting and diminishing importance tokens for words with high occurrence in the data samples. Vectorization is the general process of using this specific strategy (tokenization, counting and normalization) to convert text documents into numerical feature vectors.
In this research, we used two different Vectorizers present in feature_extraction.text module of scikit-learn namely CountVectorizer and TfidfVectorizer. TfidfVectorizer differs from CountVectorizer in the sense that TfidfVectorizer normalizes its results i.e. each vector in its output has norm one. In addition to simple collection of unigrams we also created feature vectors using collection of bigrams which accounts for the occurrences of pairs of consecutive words along for both CountVectorizer and TfidfVectorizer. All the default parameters defined in the scikit-learn library were chosen for both CountVectorizer and TfidfVectorizer
Word Vector (Word2vec)
Word Vector is another method which is employed to create feature vectors. Each individual words in the text is taken and converted in to a vector preserving the semantics relation between the words. Word vector can make use of the unlabeled data to train the word vectors, we have used the unlabeled corpus of Nepali tweets to create the word vectors. In addition to the regular preprocessing of the Nepali tweets, we split each tweets in to lists of words and obtain the vector for each words. To perform sentiment analysis, we require feature vector for each individual tweet. We average the word vectors of all the words in a tweet to get the feature vector for individual tweets.
In this research we have made use of python library known as Gensim[ref ] to create word vectors. Gensim library facilitate us to define different parameters to create the word vectors. In this research we tune some parameters which are described below:
- sg: this parameter defines which training algorithms to use to create word vector, the value of 0 specifies continuous bag of words algorithm while the value of 1 specifies skip-gram training algorithm.
- Window: this parameter specifies the distance between the predicted and the current word in a sentence. For a given word, the size of context window specifies the number of words before and after to be included as context words. According to the literature [ref Mikolov, Tomas; et al. “Efficient Estimation of Word Representations in Vector Space”], a value of 10 for skip-gram training algorithm and a value 5 for continuous bag of words algorithm have shown the best results.
- Size: it specifies the dimension of feature vector for each individual tweet. According to the author [ref above], with higher dimensionality the quality of word embedding is supposed to increase. However, after reaching a certain threshold we will notice the marginal gain and the quality will diminish. The optimal value of feature vector dimension is usually between 100 and 1000.
- Workers: Creating feature vectors using word2vec is a time consuming process. In order to save computational time, we make use of multicore machines to train the model in concurrent threads. This workers parameter define the number of threads to be used.
- min_count: this specifies a threshold for words to occur in our corpus. Words with occurrence lower than this threshold are ignored.
- sample: some words may have high occurrence in our corpus, so this parameter specifies a threshold for down sampling such high occurring words.
- hs: word2vec model can be trained with or without hierarchical softmax. The value of 1 specifies to use hierarchical softmax to train the model while the value of 0 specifies to make use of negative sampling to train the model.
- Negative: this parameter specifies the number of “noise words” to be drawn. The default is set to 5 while the usal value is between 5-20. If the value of negative is set to greater than zero, negative sampling will be used to train the model. On the other hand, if the value of negative is set zero, no negative sampling will be used.
Paragraph Vector (Doc2vec)
Another method to create feature vectors is by using paragraph vector. This method is very similar to word vector but unlike in word vector method instead of taking words to create the vectors we make use of the entire sentence to create the feature vectors. In addition to regular preprocessing of tweets, we considered each tweet as sentences and are used by paragraph vector to create the feature vectors. Like word vectors, paragraph vectors can also make use of unlabeled data to train the model thus, we have used the unlabeled corpus of Nepali tweets to extract the feature vectors.
In this research, we use the open sourced python Library called Gensim to create feature vectors using doc2vec. Similar to word2vec, Gensim provides different parameters that can be tuned when creating feature vectors using doc2vec model. Those parameters are briefly defined below:
- dm: This parameter defines which training algorithm is to be used. The value of 0 sets the training algorithm as distributed bag of words while the value of 1 makes use of the distributed memory training algorithm.
- Window: this parameter specifies the distance between the predicted and the current word in a sentence.
- Size: it specifies the dimension of feature vector for each individual tweet. According to the author [ref above], with higher dimensionality the quality of word embedding is supposed to increase. However, after reaching a certain threshold we will notice the marginal gain and the quality will diminish. The optimal value of feature vector dimension is usually between 100 and 1000.
- Workers: Creating feature vectors using word2vec is a time consuming process. In order to save computational time, we make use of multicore machines to train the model in concurrent threads. This workers parameter define the number of threads to be used
- min_count: this specifies a threshold for words to occur in our corpus. Words with occurrence lower than this threshold are ignored.
- sample: some words may have high occurrence in our corpus, so this parameter specifies a threshold for down sampling such high occurring words.
- hs: word2vec model can be trained with or without hierarchical softmax. The value of 1 specifies to use hierarchical softmax to train the model.
- Negative: this parameter specifies the number of “noise words” to be drawn. The default is set to 5 while the usual value is between 5-20. If the value of negative is set to greater than zero, negative sampling will be used to train the model. On the other hand, if the value of negative is set zero, no negative sampling will be used.
Model Preparation
In this stage we use the feature vectors produced by different techniques as an input for training the machine learning classifiers. For this research we have chosen three different type of classifiers namely Logistic Regression (a linear model), Random Forest (an ensemble model) and Gaussian Naïve Bayes ( a probabilistic model). We used the inbuilt classes in scikit-learn [ref] library to train these classifiers and compute the mean F1 score. Default parameters defined in the scikit-learn library were used for all three classifiers.
Model Evaluation
Once we have our machine learning model; we evaluate the performance of the model using F1 score as performance evaluation metrics. F1 score also known as F-score or F-measure makes use of the precision and the recall of the test to compute the F1 score. Precision also known as positive predictive value is the ratio of true positive to the total number or positive results returned by the classifier. Recall also known as sensitivity is the ratio of true positive to the total number of actual positive instances in the sample. In broader sense, both precision and recall is a measure of relevance. In simple terms, F1 score is the weighted average i.e. harmonic mean of precision and recall. F1 score ranges between 0 to 1, where value of 1 reflects the best performance and 0 reflects the worst performance. Generally, high precision and recall results in high F-measure score.
Using the same data set to train and test the is a methodological mistake which rewards the overly complex models and would produce perfect score for samples that it has seen, however, would fail to predict any unseen data. This would lead to overfitting of the training data and the model won’t necessarily generalize. One of the approach to avoid such problem is to split the data set as training set and testing set so the classifier can be trained and tested on different data sets. Test train split would give a better estimate of out-of-sample performance, but still it will result in high variance estimate. Test train split can be useful in cases where faster computation time, simplicity and flexibility is desired.
In this research we have used k-fold cross validation technique to obtain the F1 scores, where the value of k is set to 10. K-fold cross validation will systematically split the data in to k folds. In each iteration the model is trained using a k-1 folds as training data and the model is tested using the remaining part of the data. The performance measure is computed by taking the average of the values calculated for each single iteration. In this research we used the scikit-learn cross_val_score [ref] helper function to perform k-fold cross validation and compute the mean F1 score.
Chapter 4 Experiments and Results
Overview
In this chapter we discuss about the experiments that were carried out to evaluate the sentiments in Nepali tweets. We employed various techniques to create the feature vectors for the machine learning classifiers and made use of both labeled and unlabeled preprocessed Nepali tweets to conduct the experiments. We also discuss the results obtained from all three classifiers for different experiments after evaluating the machine learning model using 10-fold cross validation.
Experiment 1: using bag of words and bag of n-grams as features
In this experiment tradition bag of words method was used to convert Nepali tweets as feature vectors and passed as input to train three machine learning classifiers namely, Logistic Regression, Random Forest and Gaussian Naïve Bayes. Since, this approach requires labeled data set, only labeled corpus of Nepali tweets was used for training the classifiers. 10-fold cross validation was used as an evaluation metrics to calculate the mean F1 score.
| MEAN F1 | |||
| Features | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| Count Vectorizer+Unigrams | 0.561372335 | 0.530865946 | 0.275298157 |
| Count Vectorizer+Bigrams | 0.569768357 | 0.557077225 | 0.556639269 |
| Tfidf Vectorizer+unigrams | 0.560402147 | 0.561226044 | 0.305039854 |
| Tfidf Vectorizer+Bigrams | 0.572099984 | 0.578769252 | 0.572159892 |
Table m
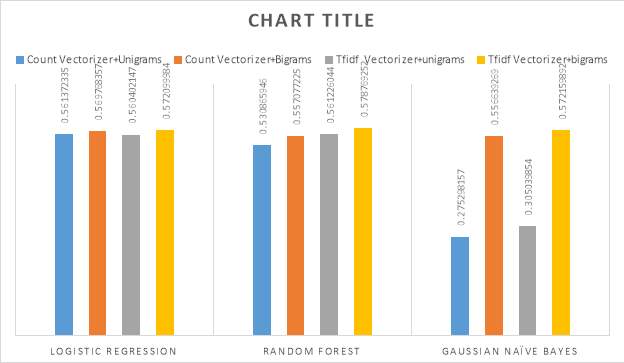
figure n
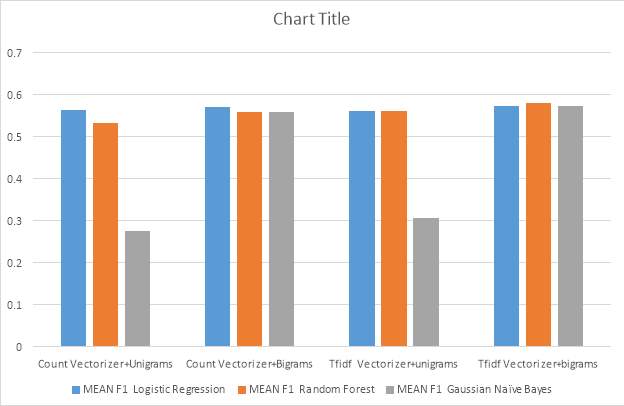
Figure m
Table m presents the result of Logistic Regression, Random Forest and Gaussian Naïve Bayes classifier applying different feature sets i.e Bag of Words with Unigrams, Bag of Words with Bigrams, TFIDF with Unigrams and TFIDF with Bigrams. 10-fold cross validation was involved as performance evaluation and the mean F1 score for each classifier for different feature sets was obtained. Figure m and figure n is the visual bar graph representation of data in table m. Figure n illustrates that all three classifiers performed better when TFIDF with bigrams were chosen as the feature set. From Figure m it can be visualized that Logistic Regression classifier outperforms the other two irrespective of the chosen feature sets.
Experiment 2: using word2vec to create feature vectors
In this experiment, we used word vector algorithm i.e. word2vec [ref google article from above] to create feature vectors for the machine learning classifiers. Open sourced python library called Gensim [ref] was used to produce word vectors for our unlabeled corpus to feed into the machine learning classifiers. Word2vec has two different architectures to produce word vectors known as skip-gram (SG) model and Continuous Bag of Words (CBOW) model. In this experiment, we used both skip-gram and continuous bag of words architecture to study the variation in mean F1 score accuracy for varying feature vector dimension using three different machine learning algorithms for the task of sentiment classification. Unlabeled corpus of Nepali tweets was used to create feature vector model using word2vec. The feature vectors generated using word2vec and the labeled corpus was used to train the machine learning algorithms and 10-fold cross validation was used to calculate the accuracy scores.
Once we figure out the optimal feature vector dimension and the better architecture for the word2vec, we varied the amount of data in our unlabeled corpus to see if the size of data in the unlabeled corpus has any effect on the performance of the classifiers.
Following parameters were chosen to get word vectors using Gensim in this experiment.
| Parameter | Value |
| sg | 1, for skip-gram
0, for CBOW |
| workers | 4 |
| size | Varying length from 50-1000 |
| min_count | 3 |
| window | 10, for skip-gram
5, for CBOW [ref wiki] |
| sample | 0.001 |
| hs | 1 |
| negative | 0 |
Table x defines the different parameters used to instantiate the Word2Vec class in genism for this experiment. Varying length of feature vector dimension was chosen ranging from 50 to 1000 [ref]. Context size of 10 was chosen when skip-gram architecture was used while context size of 5 was chosen for CBOW [ref]. Since we wanted to include as many words in the vocabulary created by word2vec the minimum word count of only 3 was chosen. Hierarchical softmax was used as training algorithm for both skip-gram and continuous bag of words architecture.
Variation in mean F1 scores using skip-gram architecture for different feature vector dimension
| word2vec-skipGram-Mean F1 Score Variation | |||
| Feature Vector Dimension | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 50 | 0.733291965 | 0.727695844 | 0.637590686 |
| 100 | 0.753999659 | 0.7531248 | 0.63889375 |
| 200 | 0.765990862 | 0.753492148 | 0.636463079 |
| 300 | 0.770537621 | 0.752001386 | 0.639516661 |
| 400 | 0.763657964 | 0.758828318 | 0.648239632 |
| 500 | 0.778993358 | 0.760777284 | 0.649300031 |
| 600 | 0.776688735 | 0.759400716 | 0.6407212 |
| 700 | 0.795219374 | 0.76549418 | 0.658615838 |
| 800 | 0.777156142 | 0.755311994 | 0.636506923 |
| 900 | 0.782143545 | 0.758471142 | 0.634718167 |
| 1000 | 0.792156653 | 0.77227027 | 0.63356346 |
Table 1
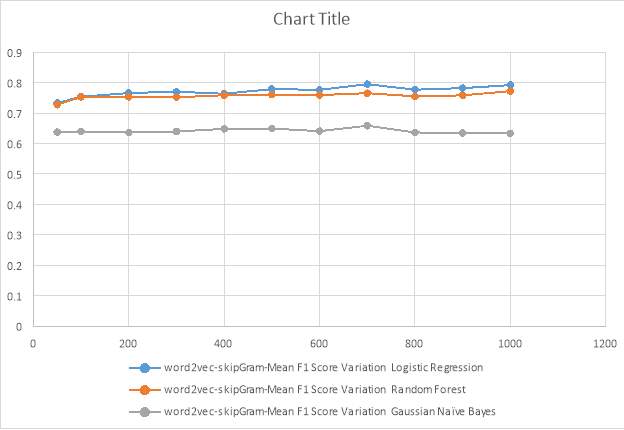
chart 1
Table 1. displays the mean F1 score produced by the three machine learning classifiers for different dimension of feature vectors ranging from 50 to 1000 when skip-gram model was used as the architecture for creating word vectors using word2vec. Figure 1 is the visual representation of data presented in table 1.
From figure 1, we could see that all three classifiers obtain the optimal value of F1 score when the feature vector dimension of 700 is used. The maximum F1 score accuracy of 0.795, 0.765, 0.658 was obtained for Logistic Regression, Random Forest and Gaussian Naïve Bayes respectively.
Variation in mean F1 scores using continuous bag of words architecture for different feature vector dimension
| word2vec-CBOW-Mean F1 Score Variation | |||
| Feature Vector Dimension | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 50 | 0.720638231 | 0.71431504 | 0.590205858 |
| 100 | 0.733803358 | 0.716526557 | 0.602680572 |
| 200 | 0.764543113 | 0.72566013 | 0.593640208 |
| 300 | 0.768806261 | 0.729038592 | 0.5942683 |
| 400 | 0.764389596 | 0.72107409 | 0.603301595 |
| 500 | 0.789777079 | 0.730378515 | 0.604396463 |
| 600 | 0.769565657 | 0.723889047 | 0.589177705 |
| 700 | 0.772036272 | 0.718955105 | 0.58702752 |
| 800 | 0.77686693 | 0.716131304 | 0.596695876 |
| 900 | 0.774959865 | 0.727812079 | 0.588102843 |
| 1000 | 0.77795207 | 0.729137538 | 0.585046809 |
Table 2
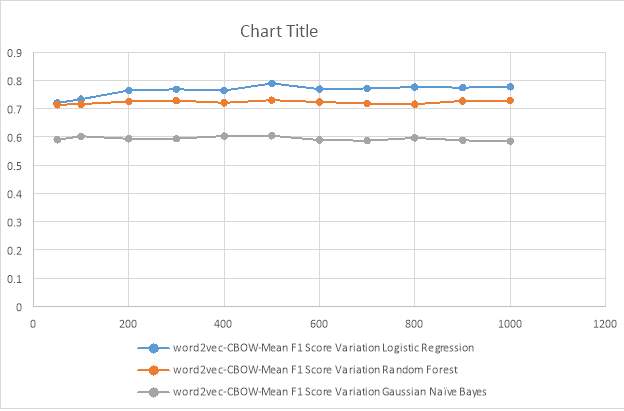
figure 2
Table 2 represents the output F1 scores of 10-fold cross validation produced by three different classifiers for the task of sentiment analysis when feature vectors produced by word2vec using continuous bag of words architecture was fed as features to the classifiers. Figure 2, is the visual representation of data in table 1 as a scatter plot. The F1 scores for three classifiers was calculated for different size of feature vectors. From the figure 2, it can be noted that the feature vector dimension of 500 is enough to get optimal value using continuous bag of words architecture. From table 2, it can be noted that maximum F1 score of 0.789, 0.7303, 0.604 was obtained for Logistic regression, Random Forest and Gaussian Naïve Bayes classifiers respectively.
Comparison of optimal mean F1 scores for skip-gram and continuous bag of words architecture in word2vec model
| Mean F1 score | |||
| Architecture Used | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| skip-gram | 0.795219374 | 0.765494187 | 0.658615838 |
| CBOW | 0.789777079 | 0.730378515 | 0.604396463 |
Table 3
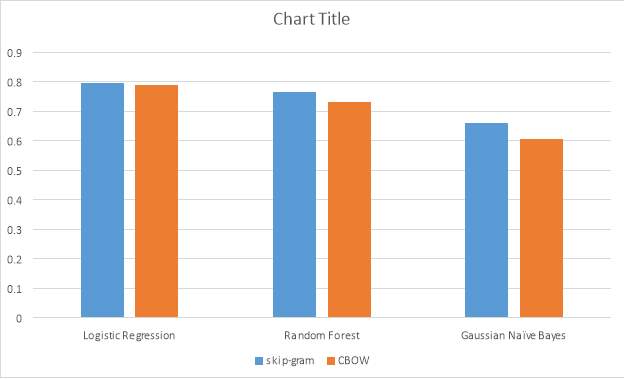
figure 3
Table 3 lists the optimal mean F1 accuracy scores produced by each machine learning classifiers when skip-gram with feature vector dimension of 700 and continuous bag of words with feature vector dimension of 500 was used to produce word vectors using Word2vec. Figure 3 is the visual representation of data in table 3 as a bar graph. Figure 3 illustrates that for all three machine learning classifiers, Logistic Regression, Random Forest and Gaussian Naïve Bayes, skip-gram architecture produced optimal results compared to the continuous bag of words architecture.
Variation in mean F1 score for different data size of the unlabeled corpus
| Unlabeled Data Size Variation-sg-700 | |||
| Data Size | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 10000 | 0.763561514 | 0.705341243 | 0.574417947 |
| 20000 | 0.761417631 | 0.728106849 | 0.607035155 |
| 30000 | 0.767038727 | 0.743748712 | 0.625448317 |
| 40000 | 0.77043261 | 0.755919613 | 0.631329362 |
| 50000 | 0.795219374 | 0.765494187 | 0.658615838 |
Table 4

Figure 4
From A, B, C we conclude that for the word2vec model, the best results is obtained by when skip-gram architecture with feature vector dimension of 700 is used. In this experiment, skip-gram architecture with feature vector of length 700 was used to produce the word vectors and fed in to the machine learning classifier. However, we varied the data size of the unlabeled corpus to create the word vector model. Unlabeled corpus containing unique Nepali tweets ranging from 10k to 50k was used for this section of the experiment. Table 4, lists out the mean F1 score produced by the three classifiers when different data size of unlabeled corpus was used to create the word vector models. Figure 4, is the visual representation of the data is table 4. Figure 4 illustrates that from all three machine learning classifiers, Logistic Regression, Random Forest and Gaussian Naïve Bayes, the mean F1 score increases with the increase in the size of unlabeled corpus. Thus, it can be deduced that large amount of unlabeled corpus can produce better word embedding for the task of sentiment analysis of Nepali tweets. It can also be visualized from figure 4, that amongst the three classifiers, Logistic regression outperforms the other two classifiers.
Optimal dimension of feature vector for both algo?
Which architecture performed better?
Which classifier performed better?
Experiment 3: using doc2vec to create feature vectors
In this experiment, paragraph vector (doc2vec) [ref] was used to create word embeddings to generate feature vectors for the machine learning classifiers. Gensim[ref], open sourced python library was used to produce the paragraph vectors. Paragraph vector has two different architectures known as Distributed Memory (DM) and Distributed Bag of Words (DBOW). In this experiment, both Distributed Memory and Distributed Bag of Words architecture are used to produce the feature vectors and fed in to the machine learning classifiers. We aim at determining the optimal dimension of feature vector for both architectures by calculating the mean F1 score produced by three different machine learning classifiers after 10-fold cross validation. Unlabeled corpus of Nepali tweets containing 50k unique Nepali tweets is used to create the paragraph vector model using doc2vec.
Once we determine the best performing architecture and the optimal feature vector dimension for that particular architecture, we vary the size of data in the unlabeled corpus and study if the amount of data present in the unlabeled corpus impacts the performance of the machine learning algorithms for our use case.
Following parameters were chosen to be used with doc2vec in the Gensim for this experiment.
| Parameter | Value |
| dm | 1, for distributed memory
0, for DBOW |
| workers | 4 |
| size | Varying length from 50-1000 |
| min_count | 3 |
| window | 10 |
| sample | 0.001 |
| hs | 1 |
| negative | 0 |
Table x
Table x defines the different parameters used to instantiate the Doc2vec class in Gensim for this experiment. Varying length of feature vector was chosen ranging from 50 to 1000. We used the lower value of 3 for min_count, as we intend to include as many words are possible in the vocabulary. Hierarchical softmax was used as the training algorithm for both distributed memory and Distributed Bag of Words architecture. The trained the doc2vec model for 20 epochs.
Variation in mean F1 score using Distribute Memory architecture for different feature vector dimension
| Mean F1 for Feature Vector Dimesion Variation-DM | |||
| Feature Vector Dimension | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 50 | 0.645191503 | 0.599305156 | 0.624014579 |
| 100 | 0.712512976 | 0.653336258 | 0.624407627 |
| 200 | 0.733642591 | 0.653083724 | 0.626934061 |
| 300 | 0.753103624 | 0.660636663 | 0.633919178 |
| 400 | 0.754846215 | 0.664530405 | 0.631472633 |
| 500 | 0.762073782 | 0.667059777 | 0.636466978 |
| 600 | 0.749595629 | 0.661711718 | 0.620857186 |
| 700 | 0.753053362 | 0.663234096 | 0.624436681 |
| 800 | 0.75769724 | 0.655969215 | 0.630124318 |
| 900 | 0.748431583 | 0.646802724 | 0.625408974 |
| 1000 | 0.76056756 | 0.665587799 | 0.630029459 |
Table x
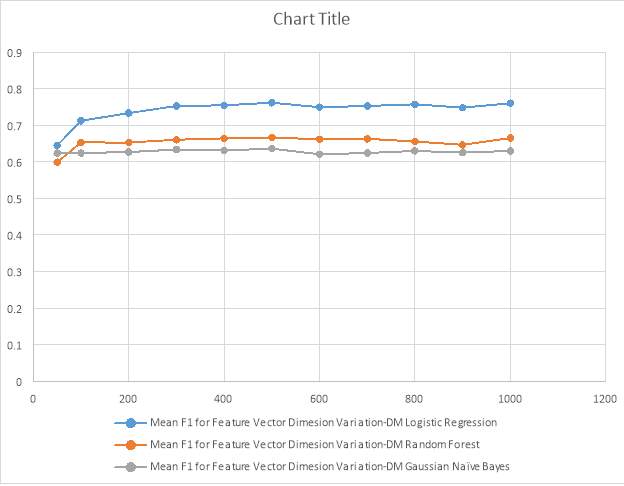
Figure x
Table x is a tabular representation of mean F1 score produced by three machine learning classifiers for different dimension of feature vectors when distributed memory was used as the architecture for Doc2vec. Figure x is the visual representation of data presented in Table x. Figure x, visualizes that the feature vector dimension of 500 is enough for getting optimal results for all three classifiers when distributed memory architecture is chosen. The maximum mean F1 score of 0.762, 0.667, 0.636 was obtained by Logistic Regression, Random Forest, Gaussian Naïve Bayes respectively. From the Table x, we also notice that Logistic Regression outperforms other two classifiers and Gaussian Naïve Bayes has the lowest mean F1 score using Distributed Memory algorithm for Doc2vec.
Variation in mean F1 scores using Distributed Bag of Words architecture for different feature vector dimension
| Mean F1 for Feature Vector Dimension Variation-DBOW | |||
| Feature Vector Dimension | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 50 | 0.653915622 | 0.628553512 | 0.65202986 |
| 100 | 0.717139353 | 0.684472502 | 0.697622913 |
| 200 | 0.748550472 | 0.690827358 | 0.705729955 |
| 300 | 0.758210675 | 0.691235733 | 0.706611442 |
| 400 | 0.756119469 | 0.683647315 | 0.700024497 |
| 500 | 0.757370221 | 0.698756479 | 0.704000061 |
| 600 | 0.764153192 | 0.692475119 | 0.703118275 |
| 700 | 0.760691629 | 0.684686029 | 0.703637866 |
| 800 | 0.764871814 | 0.707765971 | 0.713082894 |
| 900 | 0.758173631 | 0.686063222 | 0.697914239 |
| 1000 | 0.752993072 | 0.691010936 | 0.702373661 |
Table y
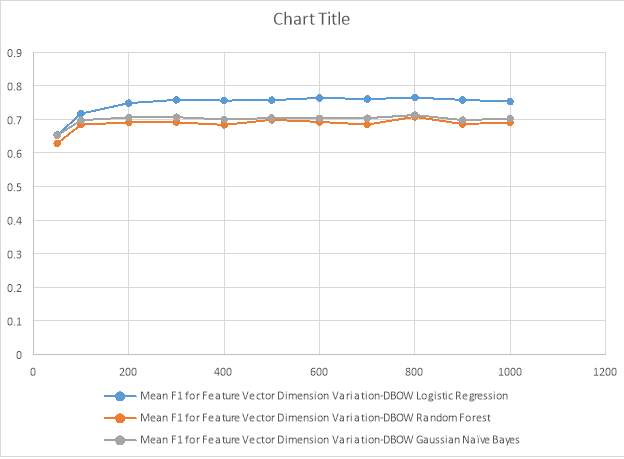
figure y
Table y represents the output F1 scores of 10-fold cross validation produced by three different machine learning classifiers when feature vectors produced by doc2vec using distributed bag of words architecture was fed in as features to the classifiers. Figure y is the visual representation of data in table y. Figure y depicts that the feature vector dimension of 800 gives the optimal results for all three classifiers. From table y, we see that Logistic Regression has the best performance with the mean F1 score of 0.764. Unlike in the case of Distributed Memory, Gaussian Naïve Bayes outperforms Random Forest when Distributed Bag of Words architecture is chosen.
Comparison of optimal mean F1 scores for Distributed Memory and Distributed Bag of Words architecture in Doc2vec model.
| Mean F1 score | |||
| Architecture Used | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| Distributed Memory | 0.762073782 | 0.667059777 | 0.636466978 |
| Distributed Bag of Words | 0.764871814 | 0.707765971 | 0.713082894 |
Table a
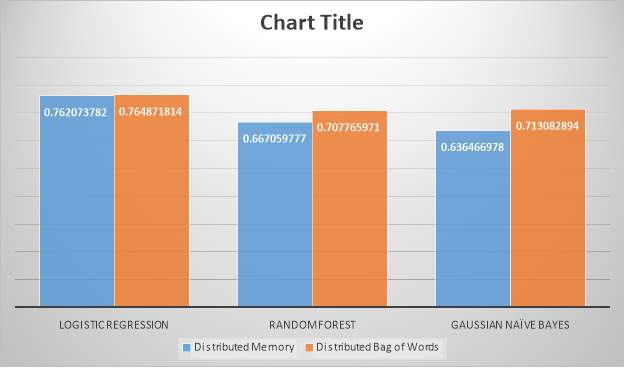
Figure a
Table a depicts the optimal mean F1 accuracy scores for each machine learning classifiers when Distributed Memory with feature vector dimension of 500 and Distributed Bag of Words with feature vector dimension of 800 was used to train the Doc2vec model. Figure a, is the visualization of data in Table a. It can be noted from the figure a that for all three classifiers, distributed bag of Words contribute towards better performance compared to Distributed Memory.
Variation in mean F1 score for different size of the unlabeled corpus
| Unlabeled Data Size Variation-dbow-800 | |||
| Data Size | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| 10000 | 0.728379374 | 0.598953465 | 0.583580949 |
| 20000 | 0.739601287 | 0.622238559 | 0.591686513 |
| 30000 | 0.751146729 | 0.645952218 | 0.607408553 |
| 40000 | 0.76213877 | 0.661113426 | 0.6271016 |
| 50000 | 0.764871814 | 0.707765971 | 0.713082894 |
Table z
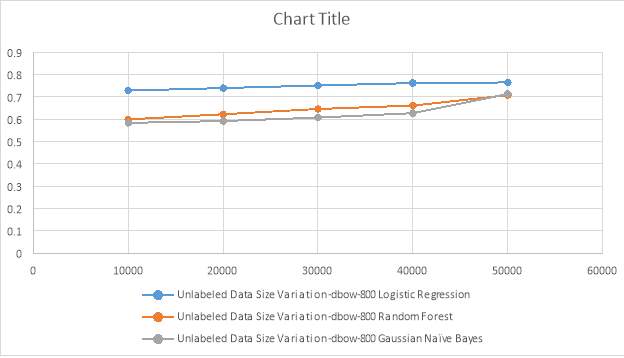
fig
From A, B, C it can be noted that all three classifiers produce optimal results when Distributed Bag of Words architecture with feature vector dimension of 800 was chosen for Doc2vec model. In this section of the experiment, we use DBOW architecture with 800 feature dimension to produce feature vectors for the machine learning classifiers. However, the size of unlabeled corpus to train the Doc2vec model is varied ranging from 10k to 50k unique Nepali tweets. Table z, lists out the mean F1 score produced by the three classifiers when different data size of unlabeled corpus was used to train the doc2vec model. Figure z is the visualization of data in table z as a scatter plot. Figure z illustrates that all three machine learning classifiers Logistic Regression, Random Forest, Gaussian Naïve Bayes produced better results when the feature vectors produced by using bigger size of unlabeled corpus was used. Thus, larger the amount of unlabeled corpus used to train Doc2vec model, better is the performance of the machine learning classifiers.
Overall comparison
Based on the results from experiments 1,2,3 we took the best performing parameters for all the feature extraction methods and did a comparative study on which feature extraction method yield a best result for each machine learning classifiers.
| Features Used | Logistic Regression | Random Forest | Gaussian Naïve Bayes |
| Tfidf Vectorizer+bigrams | 0.572099984 | 0.578769252 | 0.572159892 |
| w2v-skip-gram-700 | 0.795219374 | 0.765494187 | 0.658615838 |
| d2v-Distributed Bag of Words-800 | 0.764871814 | 0.707765971 | 0.713082894 |
Table 1
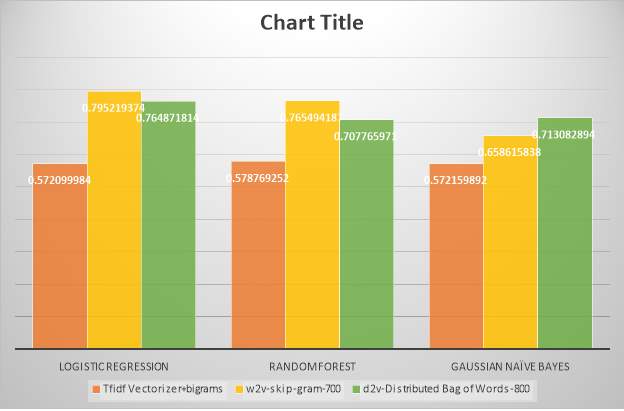
Figure 1
Table 1 represents the output of the three classifiers when different feature selection methods are employed. We chose the best performing parameters for each feature selection methods i.e. bag of words with Tf-idf and bigrams, word2vec with skip gram model and feature vector of 700 dimension and doc2vec with distributed bag of words architecture with feature vector of 800 dimension. Figure 1 is the visual representation of data in table 1. Figure 1 illustrates that for logistic regression and random forest, word2vec feature extraction method gives the best results while for Gaussian Naïve Bayes, doc2vec feature extraction technique increase the performance of the classifier. It can also be noted that the performance of all three machine learning classifiers is significantly improved when the word embedding shallow neural network models word2vec and doc2vec are used to create feature vectors compared to the traditional bag of words model.
Conclusion
In this research we focused on classifying the sentiments of Nepali tweets in to two different classes; positive and negative. It was difficult to extract lexical and syntactic features from Nepali text because Nepali language do not have any kind of sentiment lexicon and lack in linguistic feature tools such as stop words list, stemmers, and part of speech taggers. Hence, in this research we focused on extracting semantic features from Nepali text with the use of shallow neural network tool known as Word Vectors (Word2vec) and Paragraph Vectors (Doc2vec). We took the machine learning approach and used three different algorithms namely Logistic Regression, Random Forest and Gaussian Naïve Bayes for modeling the classifiers and used 10-fold cross validation and F-measure score as evaluation metric to evaluate the performance of the classifiers.
In this research we extracted feature vectors for the machine learning classifiers using three different techniques namely bag of words, word2vec, and doc2vec to figure out the optimal parameters for each feature extraction techniques.
For the bag of words model we experimented using unigrams and bigrams with and without tf-idf for feature extraction. The results demonstrated that using bigrams along with the tf-idf as feature set resulted in best performance for all three classifiers. Logistic regression resulted in the best F1 score of 0.57 compared to the other two.
For the word2vec model the experiment results illustrated that using skip-gram as training architecture resulted in better performance for all three machine learning algorithms compared to using continuous bag of words as training architecture. We also experimented with different dimension of feature vectors for both training architectures. All of the three classifiers outputted optimal results when the feature vector dimension was 700 for the skip-gram architecture and feature vector dimension was 500 for the continuous bag of words model. For skip-gram model with feature vector 700 dimension, Logistic Regression outperformed other two classifiers with a F1-score of 0.79. Similarly, for continuous bag of words model Logistic Regression resulted in better F1-score of 0.789 compared to other two algorithms
Similarly, when experimented with paragraph vector (Doc2vec) as feature extraction method and using those features as input for the machine learning classifiers to classify sentiment of Nepali tweets, the outputted results demonstrate that distributed bag of words architecture outperformed the distributed memory architecture. The optimal results were obtained at a feature vector dimension of 500 for distributed bag of words architecture and at a feature vector dimension of 700 for distributed memory architecture. For both distributed memory and distributed bag of words architecture Logistic regression outperformed both Random Forest and Gaussian Naïve Bayes algorithm. F1-score of 0.762 was noted for the distributed memory and 0.764 was noted for the distributed bag of words architecture.
Word vectors and paragraph vectors create vector representation of words and paragraphs respectively in high dimension vector space. One major advantage of using word vectors and paragraph vectors compared to traditional bag of words model is that they can make use of unlabeled corpus of Nepali tweets to create feature vectors. In this research we experimented with varying size of data in the unlabeled corpus ranging from 10,000 tweets to 50,000 unlabeled Nepali tweets. The experimental results demonstrated that for both word2vec and doc2vec models, the performance of all three classifiers improved with the increase in the amount of data in the unlabeled corpus which was used to extract the feature vectors for the classifiers. This proves the claim made by the authors of word vector and paragraph vectors that these technologies require large number data for improved performance. [ref google paeper on word vec and para vec]
We chose the best performing parameters for all three feature extraction methods bag of words, word2vec and doc2vec and carried a comparative study of the F1-score resulted by the three machine learning classifiers. The results illustrated that compared to the traditional bag of words method, word2vec and doc2vec models had significant improvement in the performance of the classifiers. Logistic regression and random forest classifier had the best F1 score when the feature vectors extracted using word2vec were used while Gaussian Naïve Bayes had optimal performance using doc2vec for feature extraction. The traditional bag of words model had the worst performance for all three classifiers.
Future Work
In this research we used machine learning approach coupled with different feature extraction techniques based on shallow neural network to perform sentiment analysis of Nepali tweets. The approach used in this research can be extended to be used for sentiment analysis in any other morphologically rich non-English language which lack in sentiment lexicon and linguistic resource tools.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Social Media"
Social Media is technology that enables people from around the world to connect with each other online. Social Media encourages discussion, the sharing of information, and the uploading of content.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: