Study on the Method of Association Rules Data Mining: An Analytical Review
Info: 3215 words (13 pages) Dissertation
Published: 10th Dec 2019
Study on the Method of Association Rules Data Mining : An Analytical Review
| Article Info | ABSTRACT | |
| Article history:
Received Jun 12th, 201x Revised Aug 20th, 201x Accepted Aug 26th, 201x |
Association rule mining is a data-mining technique to find out about the association rule between item combinations. The rule of association algorithm used the exercise data, based on the meaning of the data mining to create knowledge. High frequency pattern analysis: this stage looked for the item combinations which fulfilled the minimum requirement from value support in the database then after all patterns were found, next it tried to find out the association rules which fulfill the minimum requirement for confidence by calculating the confidence association rule A→B. Data Mining is an analysis process to find out the pattern from the hidden collective data by using the data. Data mining technique has been used to solve the problems, such as by applying the association rule algorithm to find out the association rules which is formed from the dataset. This research consists of some surveys which were identified by using association rule method to know about solving the problems. | |
| Keyword:
Association rule Algoritma Support Confidence Data mining |
||
| Copyright © 201x Institute of Advanced Engineering and Science. All rights reserved. |
||
- INTRODUCTION (10 PT)
Data Mining is a process to explore the added value of information that has not been known manually from a database by extracting patterns of data in order to manipulate data into information obtained by extracting and recognizing the important or interesting patterns of data that is in the database [1][2]. Data is a representation of a real event that represents an object like a human.
Utilization of existing data to assist the activities in decision-making not only by relying on operational data alone, it takes a data analysis to explore all existing information. In taking a decision, utilizing an existing database is to assist in making a decision. To deal with extracting important or interesting information or patterns from large amounts of data called data mining [3]. Data mining methods are expected to provide knowledge previously hidden in the database so as to produce more valuable information [4][5].
This paper discussed about the issues related to mining data using association rule method. The association rule method is explained in part 2, then in section 3 contains a comparative study of the methodology used for association rule in each case, in part 4 contains our ideas or suggestions on how to solve problems related to the association rule and the 5th part conclusions and recommendations.
- RESEARCH METHOD
Data Warehouse Database is a set of interrelated data groups that are organized in such a way so that later can be reused quickly and easily. The database is the highest part of the data system. Database is a collection of several files that have links between one file with another file to form a data. While the database system is a foundation or basic framework consisting of systems and sub systems used to serve certain applications in order to achieve goals. The management of a database system is a device system [6][7].
Data warehouses are databases that store current data and past data derived from various operational systems and other sources (external sources) of critical importance to management within the organization and intended for management analysis and reporting purposes in decision-making [8][9][10].
-
- Association Rule
Association analysis or association rule mining is a data mining technique for finding association rules between combinations of items. The association rules algorithm will use exercise data, in accordance with the definition of data mining, to generate knowledge. What knowledge will be generated in the association’s rules to know shopping items that are often purchased simultaneously at a time. Association rules in the form of “if … then …” or “if … then …” are the knowledge generated from the association rules function. Association rule is one method that aims to find patterns that often appear among many transactions, where each transaction consists of several items. Rule A→B= Support =
Frequency (A,B)N, Confidence=
Frequency (A,B)Frequency (A), Lift=
SupportSupport Ax Support (Y)[11][12].
- Algoritma Apriori
The apriori algorithm is a market basket analysis algorithm used to generate association rules, with the “if-then” scheme of an a priori algorithm to find frequent item sets run on a set of data. Apriori analysis defined a process to find all a priori rules that meet minimum requirements for support and minimum requirements for confidence. Support is the value of the support, or percentage of the combination of an item in the database, while the confidence is the value of certainty is the strength of the relationship between items in an a priori, a priori principle support as follows : ∀X,Y (: X ⊆ Y ) ⇒ s(X ) ≥ s(Y ) [13].
- RELATED WORK
Analysis of association rule mining is a procedure to find relationships between items in a specified data set, in determining an association rule, there is an interestingness measure (size of trust) obtained from the data processing with certain calculations. Much research has been done and most focus on data mining issues using association rule to analyze a case.
- Feng et.al [14] has done a research Soft Set Based Association Rule Mining he designed some algorithm for M-realization calculation or identifies õ-M-Strong and γ-M-reliable. In the experiment on the first case study successfully applied a new method performed in testing association rule. In the second experiment it was found that researchers from China, Korea or Pakistan were more likely to collaborate with foreign researchers in the soft set field whereas researchers from India, Malaysia or Turkey tended to cooperate with co-workers from their own countries and the most active researchers in soft fields ie from China and Korea.
- Qiu Hong Sun et.al [15] in his research on Association Rules Mining on seawater. Focusing on the application of genetic algorithms to the Association rule mining method, this paper proposes a genetic algorithm for the structure of fitness functions, encoding data, such as the title of improvement program, especially through initial problem studies, proposing Pc, Pm adaptation algorithms better applied to genetic algorithms, efficiency algorithm. Finally, genetic algorithm-based Association rule mining is applied in a database of seawater samples in data mining and proves to be effective. But he did not provide any conclusions and suggestions or developments that could be made for further research.
- Agus Sasmito Aribowo et.al [16] has promised a loan system research on banks with association rule. Classification The process will separate the lenders into two groups: good credit and bad credit groups Research uses prototyping for design implementation into an application using programming languages and development tools The rules association rule process uses the Weighted Item set Tidset (WIT) -tree method. The results indicate that the method can predict the prospective customer credit. The data collection exercise uses 120 customers who already know their credit history. By using WIT-Tree can be used to build the rules of data cooperative members. Rules can be used to classify new customers. This model can predict prospective credit customers. The results of this model can reduce the risk of bad loans but this model is less efficient.
- Byeongjoon Noh et.al [17] in this study, proposed a new evaluative methodology for the analysis of factors affecting energy efficiency derived from selected commercial buildings in the U.S. by utilizing the CBECS dataset. In the preprocessing stage, the CBECS dataset is enhanced by filtering out most of the important features that affect the energy consumption profile within a building. Thus, records containing missing or noisy values are removed for a more precise analysis. As a result, 5134 notes and 10 features were used in this study. The core of this methodology is the creation of a cube data model for handling large amounts of data about building variables and measuring energy consumption accumulated in the data. The proposed analysis model suggests useful pieces of information that reveal beneficial and disadvantageous combinations of materials and types for the buildings studied depending on climatic conditions and energy consumption modes (heating or cooling) by applying association rule mining to confirm the feasibility and application of the proposed analysis model with apply it using the R tool; and then apply it to an identification analysis of building energy consumption patterns in the US. The results of this study provide a useful knowledge acquisition method that can help decision makers identify critical building factors that potentially increase energy efficiency so as to be environmentally friendly. and energy-efficient buildings can be designed without heavy computer simulations with a set of specific conditions. The designed system has not been perfect even though the research was successful.
- Gabriele Prati et.al [18] analyzing and classifying motorcycle accidents occurring in Italy from 2011 to 2013 using latent class analysis using categorical indicators relating to the characteristics of infrastructure, road users, vehicles, and environment / time to classify motorcycles by association rule mining method. To identify a homogeneous subgroup, a latent class analysis was used, segmented motorcycle accident collections on the 19th class, representing 19 different types of motorcycle accidents. Logistic regression Analysis is used to identify relationships between class membership and severity of accidents, association rules performed for each latent class to reveal factors associated with the most severe possibilities. The result of this design can be a solution to reduce the accident rate of motorcyclists in Italy.
- So Hyun Park et.al [19] doing a research based on a framework to understand lifestyle risk behaviors About 72% of adults in Korea are less healthy lifestyles, many women today are smoking, obesity, and sleep deprivation. While men rarely do sports, smoking, obesity and lack of sleeping.. Currently many are smoking after doing breakfast and it is not very good. With association rule results from this study providing information on lifestyle risk behavior patterns that are unhealthy and able to provide information about lifestyle risk behavior patterns can help in planning interventions on several behaviors simultaneously.
- Vaishali Patil et.al [20] did a research on association rule mining with FP growth for horizontal partitions in the database. Data security item sets are a very important aspect. Various techniques are proposed to achieve this goal using third-party or homomorphic encryption techniques. Thus, to overcome using association rule method using FP Growth algorithm and to simplify the system. For the next can be done using different data mining algorithms and security on different datasets in other partitioning schemes of the database.
- Sallam Osman Fageeri et.al [21] has evaluated the performance of association rule mining algorithms in execution and memory usage using the Java VisualVM CPU profiler. Results from the CPU profiler from Java VisualVM show that the Binary-Based algorithm performs better than Eclat algorithm in terms of the speed of time during execution and memory usage. According to the results of the actual research, the results show that the Binary-Based algorithm is better than the Eclat algorithm.
4. PROSPECTIVE OBJECTIVE
The propose of this paper is to apply the method of Association Rule Mining by considering the things that have been done by the above research, The following figure shows the outline of the proposed objectives.
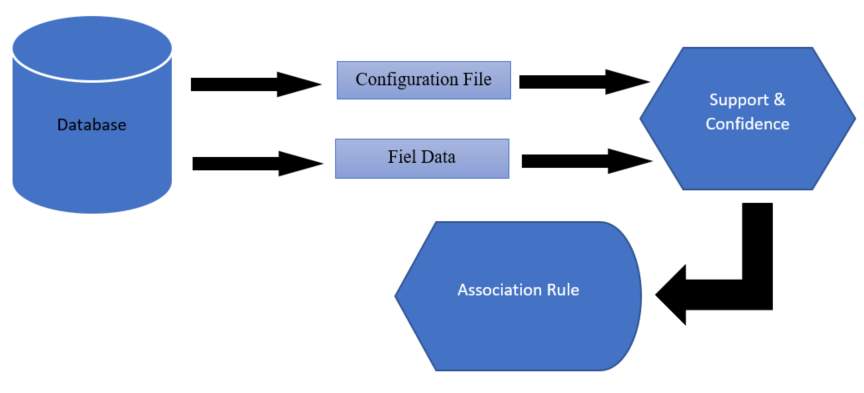
Figure 1. Scheme of the proposed Objective
Database is the source of data which was analyzed using the Association Rule method then divided into two data configuration files and data files. The data are analyzed using FP Growth to initiate the data which often appear and will be known that association rule can give significant result and able to solve the problems that exist in the database.
- CONCLUSION
The Association Rule Mining method is very efficient for use in data analysis which often appears and can be used to map data. This method can be used to simplify the system with FP Growth for the database to function optimally. The proposed model applies the Association Rule to solve a problem in the database by defining its parameters first.
REFERENCES
[1] C. Angeli, S. K. Howard, J. Ma, J. Yang, and P. A. Kirschner, “Data mining in educational technology classroom research: Can it make a contribution?,” Comput. Educ., vol. 113, pp. 226–242, 2017.
[2] J. M. Adamo, Data Mining for Association Rules and Sequential Patterns: Sequential and Parallel Algorithms. Springer New York, 2012.
[3] M. Zechner and W. Kienreich, “Scalable realtime glyph rendering on consumer level graphics hardware: A hybrid approach,” in Proceedings of the 7th IASTED International Conference on Visualization, Imaging, and Image Processing, VIIP 2007, 2007.
[4] A. Houari, W. Ayadi, and S. Ben Yahia, “Mining Negative Correlation Biclusters from Gene Expression Data using Generic Association Rules,” Procedia Comput. Sci., vol. 112, pp. 278–287, 2017.
[5] J. Han, J. Pei, and M. Kamber, Data Mining: Concepts and Techniques. Elsevier Science, 2011.
[6] V. Rainardi, Building a Data Warehouse: With Examples in SQL Server. Apress, 2014.
[7] L. W. Santoso and Yulia, “Data Warehouse with Big Data Technology for Higher Education,” Procedia Comput. Sci., vol. 124, pp. 93–99, 2017.
[8] A. K. Agarwal and N. Badal, “A novel approach for intelligent distribution of data warehouses,” Egypt. Informatics J., vol. 17, no. 2, pp. 147–159, 2016.
[9] F. A. Khan, A. Ahmad, M. Imran, M. Alharbi, Mujeeb-ur-rehman, and B. Jan, “Efficient data access and performance improvement model for virtual data warehouse,” Sustain. Cities Soc., vol. 35, pp. 232–240, 2017.
[10] W. H. Inmon, Building the Data Warehouse. Wiley, 2005.
[11] M. Kaur and S. Kang, “Market Basket Analysis: Identify the Changing Trends of Market Data Using Association Rule Mining,” Procedia Comput. Sci., vol. 85, no. Cms, pp. 78–85, 2016.
[12] G. Toti, R. Vilalta, P. Lindner, B. Lefer, C. Macias, and D. Price, “Analysis of correlation between pediatric asthma exacerbation and exposure to pollutant mixtures with association rule mining,” Artif. Intell. Med., vol. 74, pp. 44–52, 2016.
[13] A. Gkoulalas-Divanis and V. S. Verykios, Association Rule Hiding for Data Mining. Springer US, 2010.
[14] F. Feng, J. Cho, W. Pedrycz, H. Fujita, and T. Herawan, “Soft set based association rule mining,” Knowledge-Based Syst., vol. 111, pp. 268–282, 2016.
[15] I. Publishing, Q. Sun, W. Bi, and F. Wang, “S e n s o r s & T r a n s d u c e r s Study on the Method of Association Rules Mining Based on Genetic Algorithm and Application in Analysis of Seawater Samples,” vol. 168, no. 4, pp. 53–60, 2014.
[16] A. S. Aribowo and N. H. Cahyana, “Feasibility study for banking loan using association rule mining classifier,” Int. J. Adv. Intell. Informatics, vol. 1, no. 1, pp. 41–47, 2015.
[17] B. Noh, J. Son, H. Park, and S. Chang, “In-Depth Analysis of Energy Efficiency Related Factors in Commercial Buildings Using Data Cube and Association Rule Mining,” Sustainability, vol. 9, no. 11, p. 2119, 2017.
[18] G. Prati, M. De Angelis, V. M. Puchades, F. Fraboni, and L. Pietrantoni, “Characteristics of cyclist crashes in Italy using latent class analysis and association rule mining,” PLoS One, vol. 12, no. 2, pp. 1–28, 2017.
[19] S. H. Park, S. Y. Jang, H. Kim, and S. W. Lee, “An association rule mining-based framework for understanding lifestyle risk behaviors,” PLoS One, vol. 9, no. 2, pp. 1–9, 2014.
[20] V. Patil, R. Vasappanavara, and T. Ghorpade, “Securing association rule mining with FP growth algorithm in horizontally partitioned database,” no. Iccccm, 2016.
[21] S. O. Fageeri, R. Ahmad, and H. Alhussian, “A performance analysis of association rule mining algorithms,” in 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), 2016, pp. 328–333.
BIBLIOGRAPHY OF AUTHORS
 |
Tri Andi, S.T was born in Bantul, 30 Agustus 1990. He graduated from Ahmad Dahlan University, major in Informatics and now, he is still studying at Amikom University, Jogjakarta to get his magister of Informatics Engineering. |
 |
Prof. Dr. Ema Utami, S.Si, M.Kom was born in Lampung, on February 21, 1975. She received bachelor, master and doctoral degrees in computer science from Universitas Gadjah Mada, Yogyakarta, Indonesia in 1997, 2002 and 2010 respectively. Since 1998 she has been a lecturer and researcher in Universitas Amikom Yogyakarta. Since 2010 she has been a vice director in magister of informatics engineering in Universitas Amikom Yogyakarta. She has wrote more than 15 computer science related books and published nationally. Prof. Dr. Ema Utami, S.Si, M.Kom is member of several professional societies such as IEEE, IAENG, MASTEL and also as secretary general of national professional societies, IndoCEISS. Her current research interest area are natural language processing, intelligent systems, computer algorithms and database programming. |
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Data Protection"
Data Protection refers to the privacy and security provided to data that is collected and stored by businesses. Data related to both customers and employees is protected from being misused by others as part of scams or fraud.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: