Design of a Counsellor Chat Bot Service
Info: 8580 words (34 pages) Dissertation
Published: 21st Dec 2022
Tagged: Information TechnologyTechnology
Introduction
-
Theoretical Background
-
Motivation
-
Aim of the proposed work
-
Objective(s) of the proposed work
Literature Survey
-
Survey of the Existing Models/Work
-
Summary/Gaps identified in the Survey
Overview of the Proposed Systems
-
Introduction and Related Concepts
- Happy
- Surprise
- Sadness
- Contempt
- Disgust
- Anger
-
Framework, Architecture or Module for the Proposed System (with explanation)
Corpus: Text corpus is a large and structured set of texts. Anc.org – Open American Corpus – Chat corpus theinkblot.com - Rorschach Test corpus thecrisistext.com - Counsellor corpus AIML - ALICE – Psychiatrist and Therapist corpus NLTK – Eliza – Chat corpus NLTK- Python Natural Language Toolkit. It provides suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries. Scikit-learn : It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy. Tensorflow is an open source software library for machine learning. It is used for systems capable of building and training neural networks to detect and decipher patterns and correlations, analogous to the learning and reasoning which humans use. Pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series. Matplotlib - Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. Numpy - NumPy is the fundamental package for scientific computing with Python. RE – Regular Expressions Sqllite3 - SQLite is a self-contained, high-reliability, embedded, full-featured, public-domain, SQL database engine. Models - PyModels is a lightweight framework for mapping Python classes to schema-less databases. Psycopg2: PostgreSQL , is an object-relational database with an emphasis on extensibility and standards compliance. Pickle is the standard mechanism for object serialization. Pickle uses a simple stack-based virtual machine that records the instructions used to reconstruct the object. Virtualenv – Virtualenv is a tool to create isolated Python environments and with this the programs can be hosted with all their dependencies. Postman - The Postman Rest Client is a HTTP Request composer that makes it easy to call web services. It provides as an alternative for autogenerating request calls that makes it easier to call existing services but does require users to install the Postman Rest Client. CUDA – is a parallel computing platform and application programming interface which uses NVIDEA GPU’s for computation. Telegram API - This API allows us to build customized Telegram clients. It is open source. Messenger API – This API allows us to build customized Messenger clients. NGROK- ngrok secure introspectable tunnels to localhost webhook development tool and debugging tool. LUIS - Language Understanding Intelligent Service. LUIS is designed to enable developers to build smart applications that can understand human language and accordingly react to user requests. LUIS can interpret conversations in terms of their intents and entities. Watson - Watson is a question answering (QA) computing system that IBM built to apply advanced natural language processing, information retrieval, knowledge representation, automated reasoning, and machine learning technologies to the field of open domain question answering. Architecture The chatbot flow can be divided into 3 flows. The message triggers which are the Intro which happens when there is a starting of the chat or after a gap. The next one is System where the chatbot wants to send a message and the last one is User where a response is given when the user completes a task. The next is Message flows which defines how a conversation flows after the starting of the conversation. The last is Message Copy Matrix which is basically interconnected flows of the messages which may lead from one to another or showing the ends of the flows.
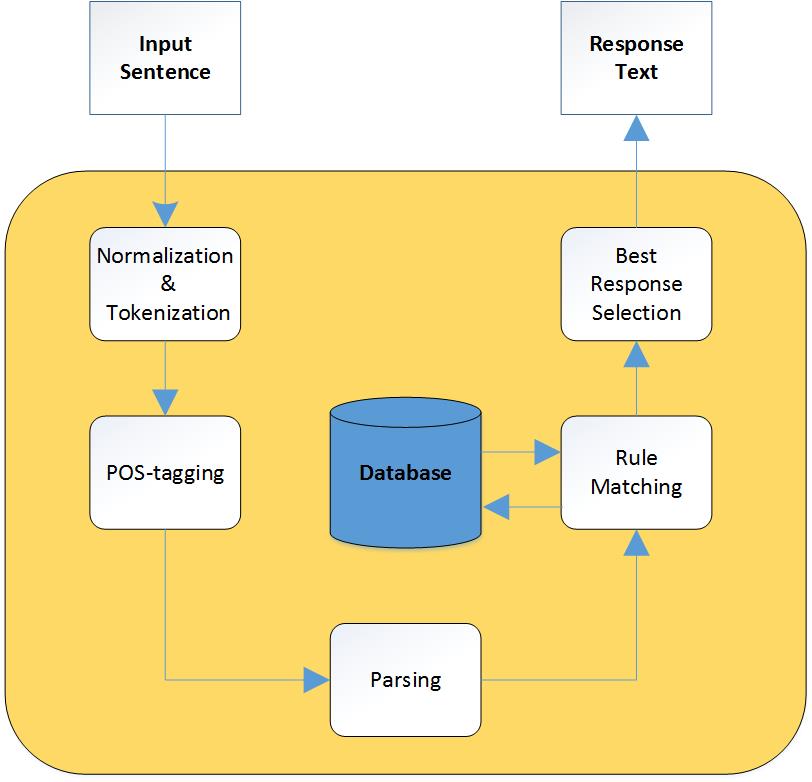
There are two types of flows. Linear flows are when the conversation goes in the same direction irrespective or the response which are used while gathering the initial idea and gathering the data before it can be analyzed. The other part is conditional flows where the conversation flows according to the response. 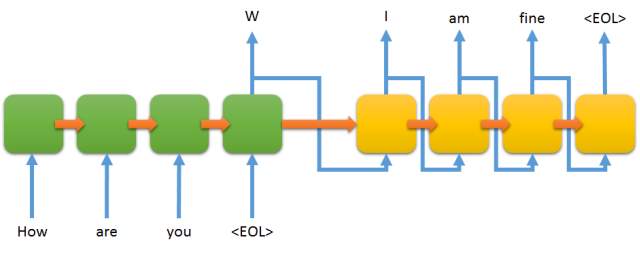
Content Modules are the various functions which are applied on the text to modify and gather more data from it along with adjust the responses in the manner to give an overall better output. Sentiment Analysis or Subjectivity or Polarity Analysis or Summarizer are few of the types.
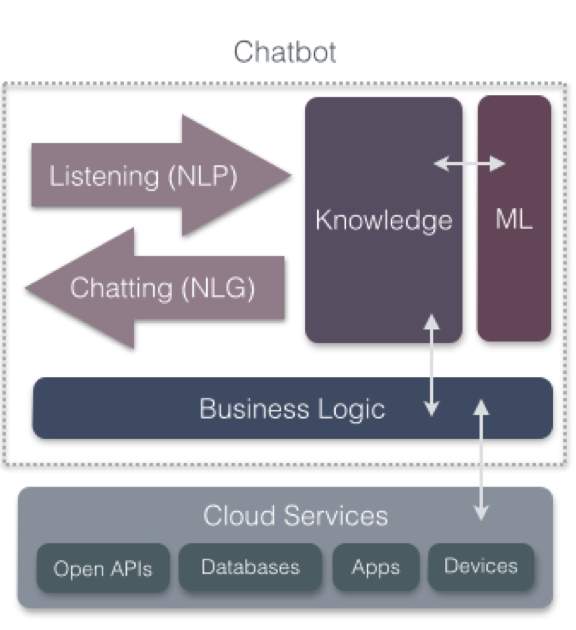
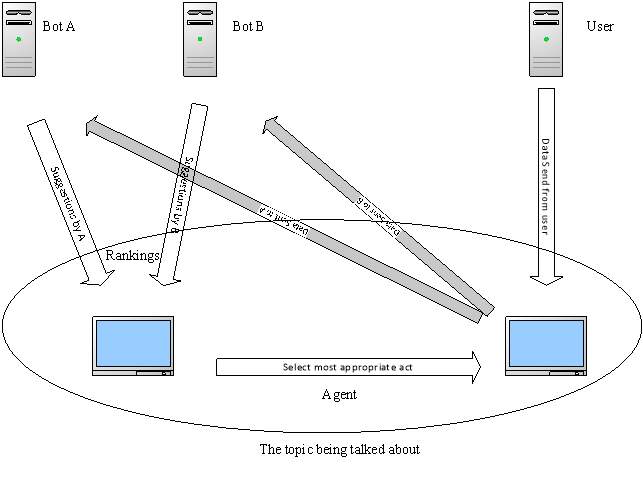
Content Classification Context classification judgments are based on the retrieval of stored exemplar information. Specifically, we assume that a probe stimulus functions as a retrieval cue to access information stored with stimuli similar to the probe. This mechanism is, in a sense, a device for reasoning by analogy inasmuch as classification of new stimuli is based on stored information concerning old exemplars, but one should also note its similarity to contemporary memory models. Domain Classifier classifies input into one of a pre-defined set of conversational domains. Only necessary for apps that handle conversations across varied topics, each with its own specialized vocabulary. Intent Classifiers determine what the user is trying to accomplish by assigning each input to one of the intents defined for your application. Entity Recognizers extract the words and phrases, or entities, that are required to fulfill the user’s end goal. Role Classifiers assign a differentiating label, called a role, to the extracted entities. This level of categorization is only necessary where an entity of a particular type can have multiple meanings depending on the context. NER – Named Entity Recognizer. Standford NLP or Microsoft LUIS can be used for it. Mixed Initiative - It is that the conversation can be started either by the chat-bot or the user and as well continue based on that and thus have a two-way flow of the conversation. The text is processed by a generative chat bot and a reply is generated based on this inputted text. In parallel, a sentiment/emotion recognition engine extracts the sentiment by processing the text. The same text acts as an input to the chat bot and a response is generated based on the text input to the chat bot engine Modules General Chat-bot : Where the user can chat generally with the bot and have a casual conversation which will continue in the direction to get to know the user better. Summarizer : Shortening to the point that the user wants to make from the whole conversation with the user and give normalized results so that the flow of the conversation if not influenced too much based on how much content has been given on a particular topic by the user. Sentiment Analysis : Language is an easy, natural way for humans to express themselves. Sentiment Analysis or opinion mining is the process of understanding which sentiment is being conveyed through text and take the context with respect to that. Rorschach Test : Get the response for each image in the test from the user and understand the meaning and continue the conversation from that point based on the aspect each image represents. Conclusion : Give a conclusion if the chat-bot reaches any about the person and accordingly suggest remedies. Self-Learning : The conversations done with the bot are analysed and they are thereafter saved in the database from where they are used by the bot to converse. The basic version where there will be only one bot analysing and based on that sentence will be giving the response and this type of version will need internet connection so that it can analyse the given query and responds and will also have a ranking system. It will be upgraded in the manner that other bots will be added which will think of the mood of the conversation and as well about the whole topic rather than the last sentence. It will further be upgraded to become a stand-alone software and improve its ranking and have login pages for databases for the people who chat often so that the chat-bot becomes accustomed to them and give better responses. As the last stage it will become an integration of any software like digital assistants, dragon and improve their efficiency or engines.
Auto Talk Engine This engine makes your chat-bot respond automatically if the user hasn't chatted in a specific period of time. You can also improve this engine by making your chat-bot wait if the user is typing a message. Assume that two minutes is the defined period of time before this engine works. If the time is up, your chat-bot sends a response from the Auto Talk Database.
-
Proposed System Model(ER Diagram/UML Diagram/Mathematical Modeling)
This chat-bot able to understand the mood and respond in respond to that and understand the whole conversation and continue the flow. Instead of building a chatbot that is hard-coded with a set of responses, the proposed model will be capable of generating responses that it has never seen before. Instead of just identifying the context, intents and entities and using these to structure a response manually, it is capable of using sequential neural networks and deep learning to identify context and respond accordingly to the text input to it
. 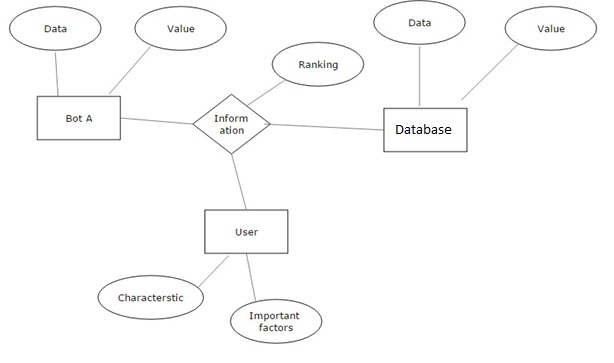
Internal software data structure The software will have a database which contains a column degree of usefulness, and phrase set, which will be separated from each other by semi-colons. The information will be mined from this database at a degree of similarity and it will not be case-sensitive until and unless it is not specified beforehand. This database can be updated. Global data structure The information will be scraped from the internet and will be ranked and checked as to how useful it is for the conversation going on. With the help of this database the software can discuss topics which it has no prior knowledge about and thus, it broadens the scope of the software Temporary data structure This database stores information from the present conversation going on so that it can change itself for the better experience of the user. This database will be discarded at the end of the session but in the later parts of the software, i.e. after the login page is implemented, all this data will be stored on the cloud so that the software changes itself and reacts differently for every user and gives them a better experience.
Proposed System Analysis and Design
-
Introduction
 RNN: Recurrent Neural Networks use sequential information. They want to predict the next word in a sentence you better know which words came before it. They perform the same task for every element of a sequence, with the output being depended on the previous computations. LSTM: LSTM networks have memory blocks that are connected through layers. A block has components that make it smarter than a classical neuron and a memory for recent sequences. A block contains gates that manage the block’s state and output. A block operates upon an input sequence and each gate within a block uses the sigmoid activation units to control whether they are triggered or not, making the change of state and addition of information flowing through the block conditional. Each unit is like a mini-state machine where the gates of the units have weights that are learned during the training procedure. AIML: AIML is Artificial Intelligence Modelling Language. It is an XML based markup language. The basic unit of knowledge in AIML is called a category. Each category consists of an input question, an output answer, and an optional context. The question, or stimulus, is called the pattern. The answer, or response, is called the template. The two types of optional context are called "that" and “topic." The AIML pattern language is simple, consisting only of words, spaces, and the wildcard symbols _ and *. The words may consist of letters and numerals, but no other characters. The pattern language is case invariant. Words are separated by a single space, and the wildcard characters’ function like words. AIML tags transform the reply into a mini computer program which can save data, activate other programs, give conditional responses, and recursively call the pattern matcher to insert the responses from other categories. Most AIML tags in fact belong to this template side sublanguage. AIML currently supports two ways to interface other languages and systems. The
RNN: Recurrent Neural Networks use sequential information. They want to predict the next word in a sentence you better know which words came before it. They perform the same task for every element of a sequence, with the output being depended on the previous computations. LSTM: LSTM networks have memory blocks that are connected through layers. A block has components that make it smarter than a classical neuron and a memory for recent sequences. A block contains gates that manage the block’s state and output. A block operates upon an input sequence and each gate within a block uses the sigmoid activation units to control whether they are triggered or not, making the change of state and addition of information flowing through the block conditional. Each unit is like a mini-state machine where the gates of the units have weights that are learned during the training procedure. AIML: AIML is Artificial Intelligence Modelling Language. It is an XML based markup language. The basic unit of knowledge in AIML is called a category. Each category consists of an input question, an output answer, and an optional context. The question, or stimulus, is called the pattern. The answer, or response, is called the template. The two types of optional context are called "that" and “topic." The AIML pattern language is simple, consisting only of words, spaces, and the wildcard symbols _ and *. The words may consist of letters and numerals, but no other characters. The pattern language is case invariant. Words are separated by a single space, and the wildcard characters’ function like words. AIML tags transform the reply into a mini computer program which can save data, activate other programs, give conditional responses, and recursively call the pattern matcher to insert the responses from other categories. Most AIML tags in fact belong to this template side sublanguage. AIML currently supports two ways to interface other languages and systems. The -
Requirement Analysis
- Functional Requirements
- Product Perspective
- Functional Requirements
- Product features
- User characteristics
- Assumption & Dependencies
- Domain Requirements
- User Requirements
-
Non Functional Requirements
- Product Requirements
- Efficiency (in terms of Time and Space)
- Product Requirements
- Reliability
- Portability
- Usability
- Organizational Requirements
- Implementation Requirements (in terms of deployment)
- Engineering Standard Requirements
- Operational Requirements (Explain the applicability for your work w.r.to the following operational requirement(s))
- Economic
- Environmental
- Social
- Ethical
- Sustainability
- Legality
- Inspectability
- System Requirements
- H/W Requirements(details about Application Specific Hardware)
- S/W Requirements(details about Application Specific Software)
- Numpy
- Pandas
- Tensorflow
- Matplotlib
- Sqlite3
- Aiml
- Nltk
- Virtualenv
- Telegram or Messenger Webhook
- NGROK
- CUDA
- Implementation
- Methodology with Pseudo code
Incorporated context: To produce sensible responses systems may need to incorporate both linguistic context and physical context. In long dialogs people keep track of what has been said and what information has been exchanged. The approach is to embed the conversation into a vector. Understanding what is important and continuing the conversation in that manner and to gain more information. Personalized responses which means that there aren’t a set of responses so everyone doesn’t continue getting the same response in a similar situation. The responses depend on a lot more factors and are generated based on those factors. Coherent: Finding what is important and asking the right questions so as to approach the right direction. Evaluation of models to understand if the conversational agent is to measure whether or not it is fulfilling its task and thus be modified accordingly. As well finding the boundary values where the chatbot works and fails and the closeness of these models to the real world. Classification of the models into similar categories where the relation between them can be seen and understanding if one category intersects with another and how much of it flows in the other thus affecting it and making it another aspect which will need to be considered. The sentiment of the user will need to be considered so that the user is comfortable while interacting to the chatbot and is able to do it with ease.
Conversational Chatbot:
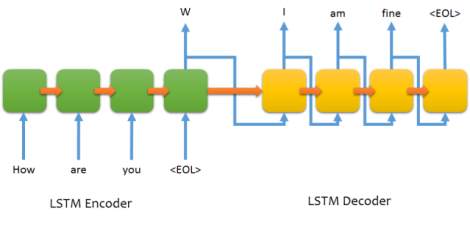
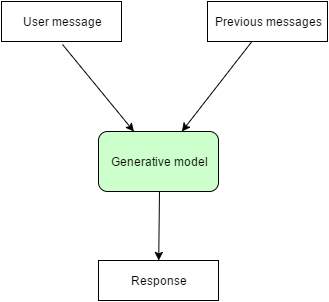
At the base of the generative model, likes a seq2seq model that is capable of taking a sentence as an input and generating another sentence as a response. The Seq2Seq model has two primary layers: the encoder and the decoder. The encoder is comprised of several layers of left-stack LSTMs. The decoder side has several layers of right-stacked LSTMs. The purpose of the encoder is to encode the input sequence (context vector). This context vector is used as an input by the decoder to generate an output sequence. Bot.py import pandas as pd import numpy as np from matplotlib.pyplot import ion , draw import matplotlib.pyplot as plt import matplotlib.image as im import sys import os import re import sqlite3 from collections import Counter from string import punctuation from math import sqrt from nltk.chat import eliza import nltk from nltk import * from login import log ion() x = log() if x == 1: path = "/home/gifty/PycharmProjects/bot/Pics" pics = os.listdir("/home/gifty/PycharmProjects/bot/Pics") for i in pics: img = im.imread(path+'/'+str(i)) x = plt.imshow(img) plt.draw() print ("Please enter the image description according to you :") print("Therapist\n---------") print("Talk to the program by typing in plain English, using normal upper-") print('and lower-case letters and punctuation. Enter "quit" when done.') print('=' * 72) print("Hello. How are you feeling today? Can you explain me about the image?") execfile('brain.py') else : print "Reload" Brain.py import aiml import sys import os import re from collections import Counter from string import punctuation from math import sqrt import random from nltk import compat import sqlite3 conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() os.chdir('/home/gifty/PycharmProjects/bot') def get_words(self, text): wordsRegexpString = '(?:\w+|[' + re.escape(punctuation) + ']+)' wordsRegexp = re.compile(wordsRegexpString) wordsList = wordsRegexp.findall(text.lower()) return Counter(wordsList).items() def get_id(self, entityName, text): tableName = entityName + 's' columnName = entityName cursor.execute('SELECT rowid FROM ' + tableName + ' WHERE ' + columnName + ' = ?', (text,)) row = cursor.fetchone() if row: return row[0] else: cursor.execute('INSERT INTO ' + tableName + ' (' + columnName + ') VALUES (?)', (text,)) return cursor.lastrowid kernel = aiml.Kernel() kernel.setBotPredicate("name","Xen") kernel.learn("std-startup.xml") kernel.respond("LOAD AIML B") while True: input = raw_input(">> User :") if input == "quit": exit() else: bot_response = kernel.respond(input) # Do something with bot_response res = bot_response words = get_words(input) words_length = sum([n * len(word) for word, n in words]) sentence_id = get_id('sentence', res) for word, n in words: word_id = get_id('word', word) weight = sqrt(n / float(words_length)) cursor.execute('INSERT INTO associations VALUES (?, ?, ?)', (word_id, sentence_id, weight)) conn.commit() cursor.execute('CREATE TEMPORARY TABLE results(sentence_id INT, sentence TEXT, weight REAL)') words = get_words(res) words_length = sum([n * len(word) for word, n in words]) for word, n in words: weight = sqrt(n / float(words_length)) cursor.execute( 'INSERT INTO results SELECT associations.sentence_id, sentences.sentence, ?*associations.weight/(4+sentences.used) FROM words INNER JOIN associations ON associations.word_id=words.rowid INNER JOIN sentences ON sentences.rowid=associations.sentence_id WHERE words.word=?', (weight, word,)) cursor.execute( 'SELECT sentence_id, sentence, SUM(weight) AS sum_weight FROM results GROUP BY sentence_id ORDER BY sum_weight DESC LIMIT 1') row = cursor.fetchone() cursor.execute('DROP TABLE results') if row is None: cursor.execute( 'SELECT rowid, sentence FROM sentences WHERE used = (SELECT MIN(used) FROM sentences) ORDER BY RANDOM() LIMIT 1') row = cursor.fetchone() cursor.execute('UPDATE sentences SET used=used+1 WHERE rowid=?', (row[0],)) print(">> Xen :"+res) Login.py import sqlite3 def log(): conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() sql = "SELECT display_name FROM users WHERE email='%s' and password='%s'" %(raw_input("Email : "),raw_input("Password : ")) try: tmp = cursor.execute(sql).fetchall() if tmp: x = 1 else : print "Error: Sign Up" conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() sql = "INSERT INTO users(email, display_name, password) \ VALUES ('%s', '%s', '%s' )" % \ (raw_input("Enter email:"), raw_input("Enter User Name : "), raw_input("Enter Password : ")) try: cursor.execute(sql) conn.commit() except: conn.rollback() conn.close() x = 1 except: print "Error: Sign Up" conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() sql = "INSERT INTO users(email, display_name, password) \ VALUES ('%s', '%s', '%s' )" % \ (raw_input("Enter email:"), raw_input("Enter User Name : "), raw_input("Enter Password : ")) try: cursor.execute(sql) conn.commit() except: conn.rollback() conn.close() x = 1 return x if __name__=='__main__': print log() Sign_Up.py import sqlite3 from login import log import bot x = log() if x == 0: conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() sql = "INSERT INTO Users(email, display_name, password) \ VALUES ('%s', '%s', '%s' )" % \ (raw_input("Enter email:"), raw_input("Enter User Name : "), raw_input("Enter Password : ")) try: cursor.execute(sql) conn.commit() except: conn.rollback() conn.close() else : execfile(bot) def sign_up(): conn = sqlite3.connect('counselorchatsqlite.db') cursor = conn.cursor() sql = "INSERT INTO Users(email, display_name, password) \ VALUES ('%s', '%s', '%s' )" % \ (raw_input("Enter email:"), raw_input("Enter User Name : "), raw_input("Enter Password : ")) try: cursor.execute(sql) conn.commit() except: conn.rollback() conn.close() Datasets: AIML psycology, personality among others. theinkblot.com dataset eliza dataset.
- Snapshots
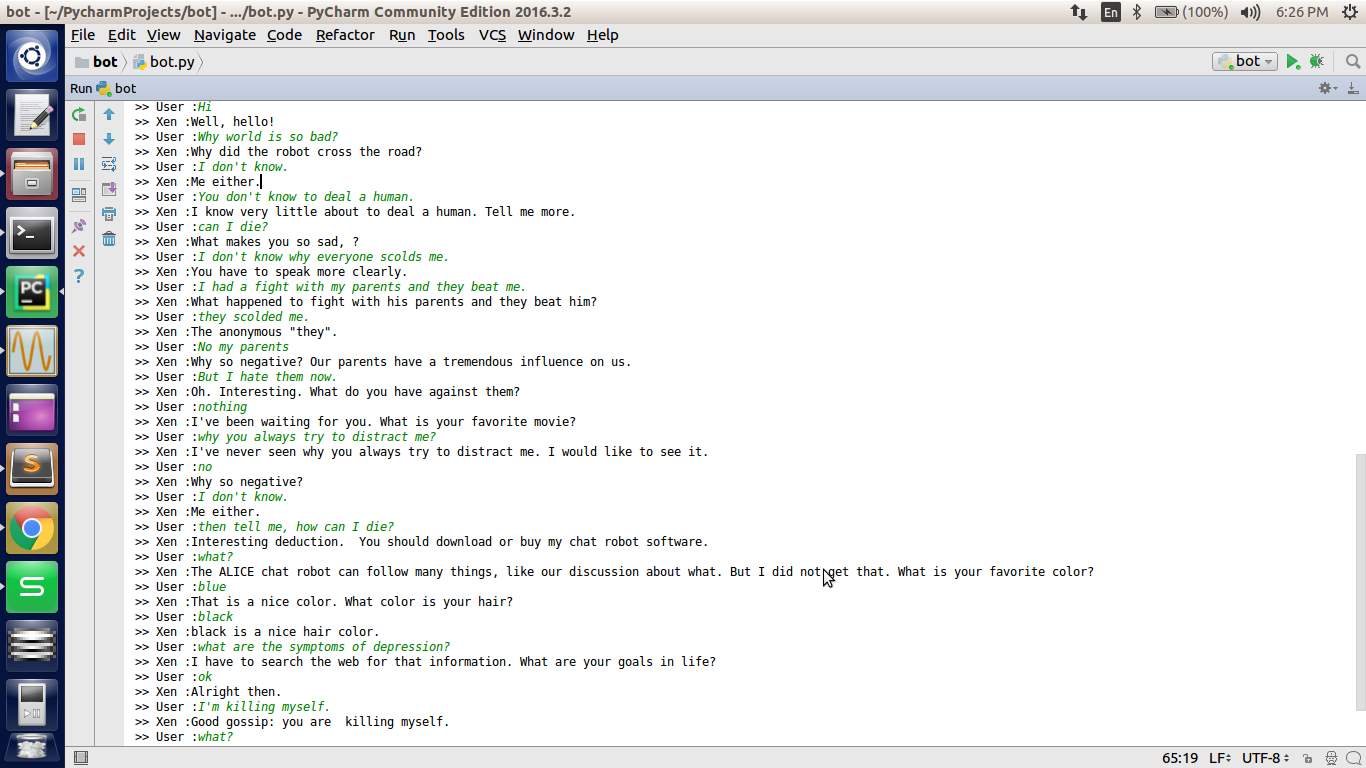
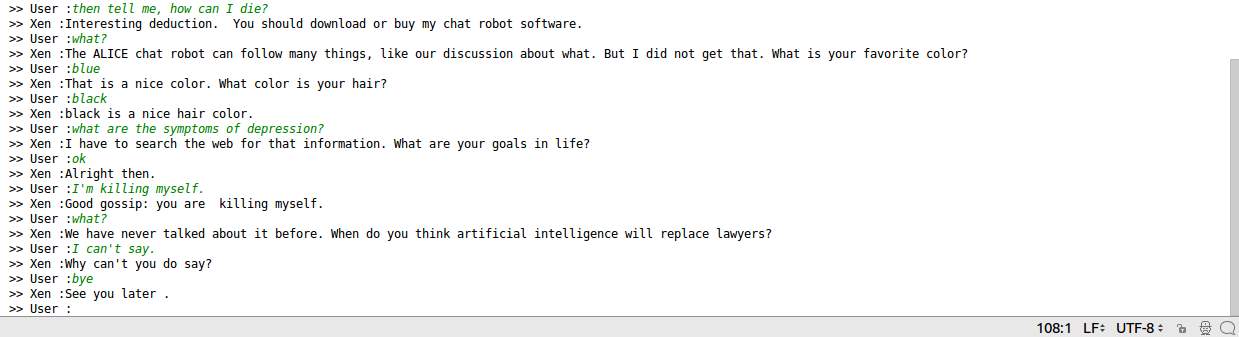
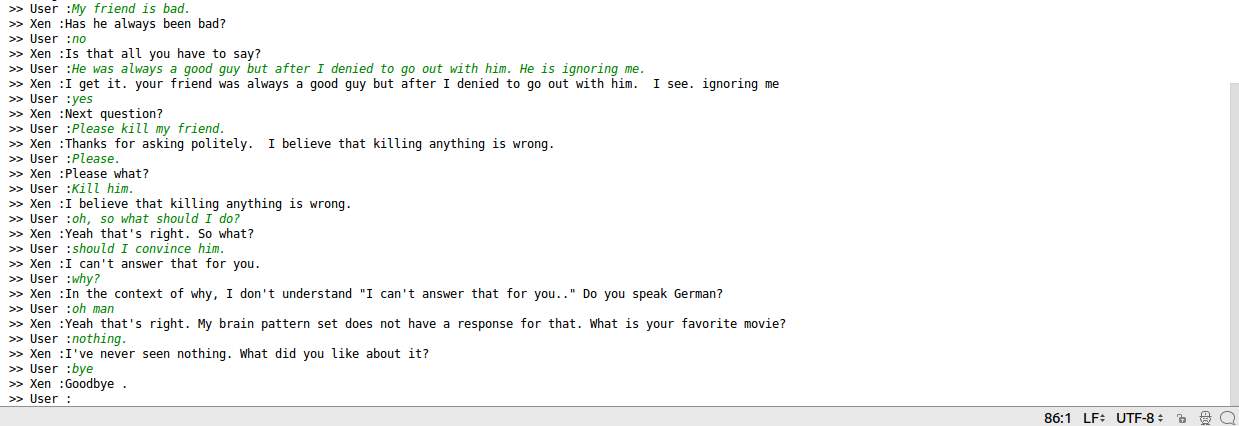
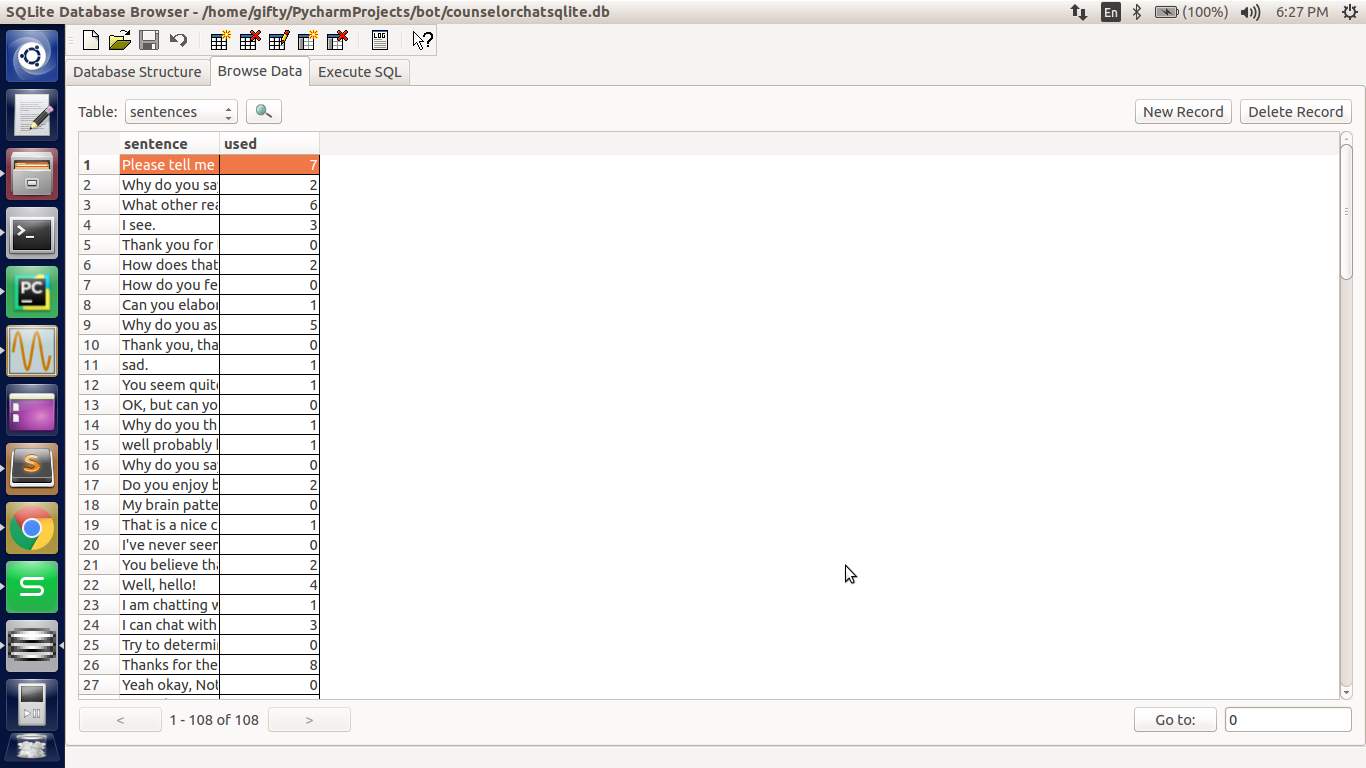
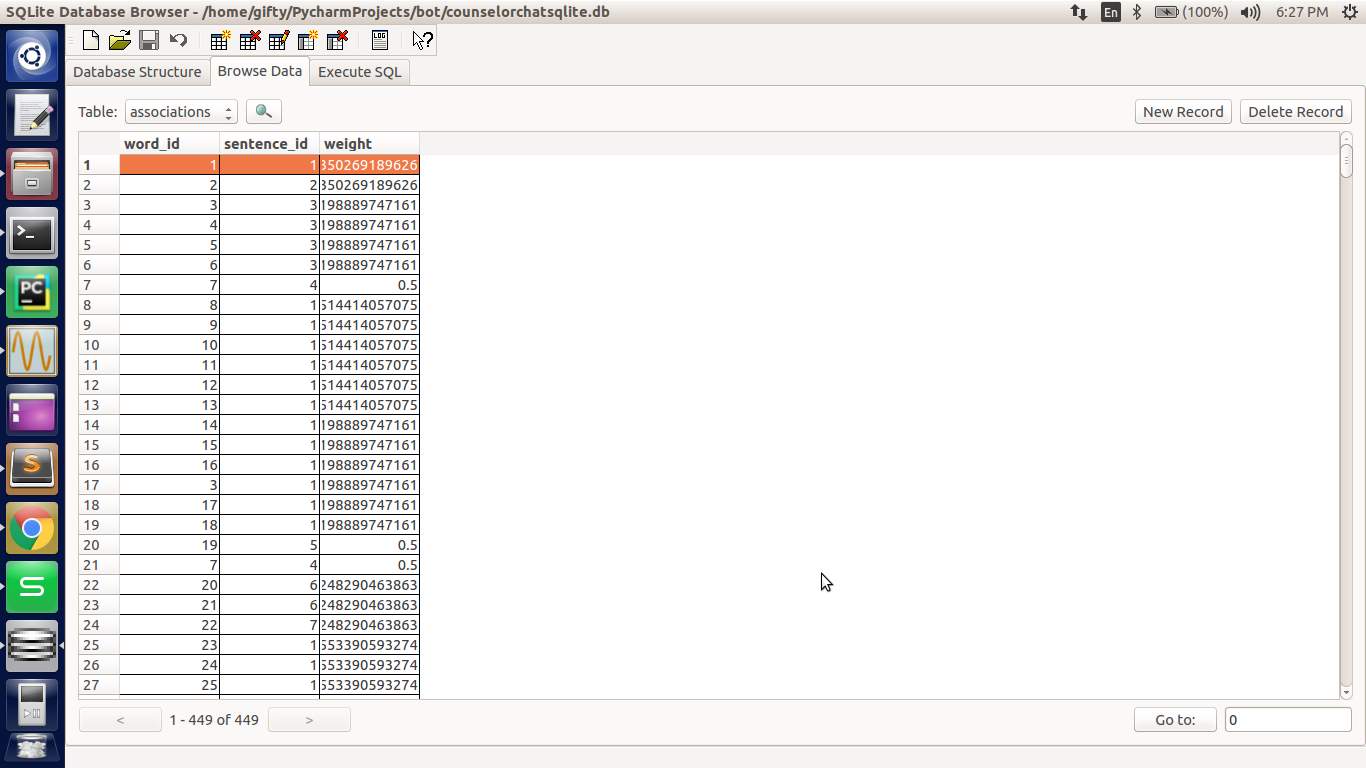
Results and Discussion
-
Testing
-
Performance Metrics
-
Results obtained (Graph if required)
Conclusion, Limitations and Scope for future Work
Conclusion: It also understands the interests of the end user and tries to keep the user interested in the ongoing conversation. The bot is able to direct the user in the right direction and isolate the problem to a certain extent. Limitations: The bot can be lead astray or fooled easily by the user. The bot doesn’t easily change topics. Requires a lot of data before it can be trained again. The bot can’t answer questions if the user asks it to explain something. Future Work: The categories for classification can be improved using the following methods. Randomforest: Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks, that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. A Random Forest consists of a collection or ensemble of simple tree predictors, each capable of producing a response when presented with a set of predictor values. For classification problems, this response takes the form of a class membership, which associates, or classifies, a set of independent predictor values with one of the categories present in the dependent variable. Alternatively, for regression problems, the tree response is an estimate of the dependent variable given the predictors. Xgboost: XGBoost (eXtreme Gradient Boosting) is an advanced implementation of gradient boosting algorithm. The user can be trained with the help of the data it has gathered and reduce the percentage of retrieval responses it sends. The bot can use grammatically correct English while using generative responses.References
Douglas L. Medin,Marguerite M. Schaffer,"Context Theory of Classification Learning",Psychological Review Ryan Kiros , Yukun Zhu,"Skip Thought Vectors",nips.cc https://www.pandorabots.com Python DocumentationCite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Technology"
Technology can be described as the use of scientific and advanced knowledge to meet the requirements of humans. Technology is continuously developing, and is used in almost all aspects of life.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: