Scalable and Energy Efficient Dram Refresh Techniques
Info: 8746 words (35 pages) Dissertation
Published: 16th Dec 2019
Tagged: Energy
SCALABLE AND ENERGY EFFICIENT DRAM REFRESH TECHNIQUES
To preserve data in its leaky capacitor, a DRAM cell needs periodic refresh operations. Previously, the overheads of refresh operations were insignificant. Refresh has become a dominating issue of DRAM performance and power dissipation, as the size and speed of DRAM chips have improved considerably within the past decade. The target is to conduct a comprehensive study of the problems associated with refresh operations in modern DRAM devices and thenceforth, propose techniques to minimize refresh penalties.
We tend to describe numerous refresh command schedule schemes; characterize the variations in DRAM cells’ retention time; and, analyze the refresh modes and timings in modern DRAM devices; to understand the consequences of refresh operations. By adjusting device speed, size, timings, and total memory capability, we tend to quantify refresh penalties. Moreover, we summarize previous refresh mechanisms and their relevance in future computing systems. Finally, we tend to propose techniques to boost refresh energy efficiency and reduce refresh scalability issues to support our experiments and observations.
Refresh operations create energy overheads and introduce performance penalty as well. Additionally, to the energy needed for refreshing can become vital in future devices, because of the background energy part, dissipated by DRAM peripheral electronic equipment and on-die DLL throughout refresh command. We tend to propose a group of techniques, within which scheduling of low power modes and refresh commands are synchronized in order that most of the specified refreshes are issued once the DRAM device is within the deepest low power self-refresh (SR) mode, referred jointly as coordinated refresh. As a result of the peripheral electronic equipment and clocks are turned off within the SR mode, our approach saves background power.
Moreover, we tend to observe that an outsized body of analysis on refresh reduction by using retention time and access focus is going to be rendered ineffective due to the fact the range of rows in DRAM scales. To possess fine-grained control over which portion of the memory is to be refreshed, these mechanisms need the memory controller, whereas, in JEDEC DDRx devices, a refresh operation is disbursed via associate auto-refresh command, that refreshes multiple rows from multiple banks at the same time. The interior implementation of auto-refresh is totally opaque outside the DRAM all the memory controller will do is inform the DRAM to refresh itself, the DRAM handles the whole thing else, crucial that rows within which banks are to be refreshed. We have a tendency to recommend a change to the DRAM that extends its present control-register access protocol to incorporate the DRAMs internal refresh counter and introduce a brand-new dummy refresh command that skips refresh operations and easily increments the interior counter. we tend to show that these modifications enable a memory controller to scale back as several refreshes as in previous work, whereas achieving vital energy and performance benefits by using auto-refresh most of the time.
TABLE OF CONTENTS
1.1.2 Understanding Refresh Issues
1.2 Refresh Overheads and Solutions
1.2.2 Scalability of Refresh Reduction Schemes
1.3 Contribution and Significance
CHAPTER 2 A DETAILED LITERATURE REVIEW
2.1 Refresh Penalty vs. Device Speed
2.2 Refresh Penalty vs. Device Density
2.3 Refresh Penalty vs. System Memory Size
2.5.2 Using Retention Time Awareness
2.6 Potential Refresh Improvements
2.6.1 Exploiting Retention Awareness
2.6.2 Utilizing Finer Granularity Options
CHAPTER 3 The DESIGN AND METHODOLOGY
3.1 Coordinated Refresh: An Energy-Efficient Technique
3.1.2 Coordinated Fast Refreshes in SR (CO-FAST)
3.1.3 Coordinated Flush Refreshes in SR (CO-FLUSH)
3.1.4 Coordinated First Immediate Refresh in SR (CO-FIRST)
3.2 Flexible Refresh: Scalable Refresh Solution
3.2.1 Auto-Refresh (AR) Command
3.2.3 Refresh Counter Access Architecture
3.2.4 Flexible Auto-Refresh (REFLEX) Techniques – Refresh Reduction in SR Mode
CHAPTER 4 IMPLEMENTATION AND RESULTS
4.1 Evaluations for Current-generation Devices
4.2 Evaluations for Future-generation Devices
4.3 Benefits of Auto-Refresh Flexibility
4.4 REFLEX with Low Power Modes
CHAPTER 1
INTRODUCTION
As the number of cores on the multicore processors increases and the increasing memory footprints of data-intensive application with higher speed I/O capabilities have prompted higher bandwidth and capacity for main memories. Static Random-Access Memory (SRAM) has lower density and other nonvolatile memory technologies such as Flash, Phase Change Memory (PCM), and magnetic disks have higher latency and lower bandwidth compared to Dynamic Random-Access Memory (DRAM), so it is used in most of the computing systems.
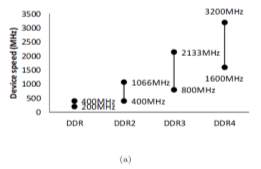
The current age DDR4 devices are more advanced than the DDR devices of the last decade as the magnitude is higher as DDR4 devices are specified with 32Gb density and 3.2Gbps speed [1]. Moreover, the extra time spent doing refresh operations increases the background power component. These DRAM scaling developments were propelled by the ever-increasing primary memory demands and had been achieved with the help of process technology and architectural innovations. After the introduction DRAM from JEDEC in the late 1990s, for every new technology generation, the speed and size of devices have continued to increase. (Figure 1‑1).
 |
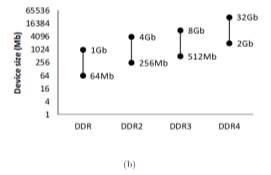 |
| Figure 1‑1: DRAM trends. Both size and speed increase with every DDR generation | |
1.1 Motivation
1.1.1 DRAM Refresh Trends
Data is stored in the capacitor as an electrical charge. A DRAM cell is composed of an access transistor and a capacitor., on the other hand, the charge leaks over time. DRAMs require periodic refresh operations to hold the records saved in their leaky capacitive cells which incur both overall performance and strength overheads. As DRAM get denser, three fundamental refresh penalties expand significantly. The time spent occupying the command bus with refresh commands will make bigger with the range of rows to be refreshed; the time in the course of which rows are unavailable due to the fact their storage capacitors are being recharged will extend with the number of simultaneous rows being refreshed (among many distinctive factors); and the strength wished to preserve the DRAM device refreshed scales with the vary of capacitors in the system.
The refresh contributes 20% of DRAM energy consumption because of these high-density 32Gb devices hence the system performance is decreased by 30%. These results are validated by current work [2] projecting refreshes by debasing memory throughput by 50% to account for up to 50% of the DRAM power in future 64Gb devices. As the distinction of DRAM refresh increases in future computing systems, this dissertation objectives, first, identify the existing refresh techniques, timings and challenges; and then, recommend mechanisms to mitigate refresh penalties.
1.1.2 Understanding Refresh Issues
There is an assumption by most of the refresh techniques [2] [3] [4] [5] that the DRAM Device will support refresh at low-level granularity, which is completely wrong. The older asynchronous interface is totally replaced with the aid of the present day synchronous DRAM devices and it only supports the auto-refresh (AR) command that refreshes countless rows simultaneously.
Micron technical report [6] specifies the previous refresh categorization such as Row Access Strobe-only, Column Access Strobe-before-Row Access Strobe, and hidden refresh, are no longer relevant to modern-day SDRAM devices. This prevailing false impression about the refresh command sequence wants to be clarified.
It is necessary to give an explanation for all refresh options and analyze their advantages due to the fact none of the preferences is best in all states, Refresh timings and command sequences carried out in DDR devices and power LPDDR devices are not the same, in addition, few refresh optimizations to decrease background energy are supported in LPDDR devices. Moreover, the retention period which is the capacity of a DRAM cell to hold charge suggests two interesting phenomena. [7] [8] [9]
- First, for every DRAM cell, the retention period changes over time, and the temperature is the main cause for the frequency of the changes.
- Second, across the cells of the DRAM devices, the retention period follows a normal distribution as most of the cells of the DRAM device hold the data for the very long period and only very few cells leak charge fast.
In order to design the refresh reduction mechanisms, we need to understand the characteristics in the modern-day DRAM device, as the retention duration directly influences refresh timings. The simulation infrastructure needs to easily enable covering device parameters, all relevant memory organization and representing systems of past, current and future. To examine refresh energy and timing penalty the following parameters should be changed: device size, speed, refresh timings, memory ranks and command granularity, etc.
After analyzing refresh issues, it would be useful to categorize the current refresh techniques based totally on their operating granularity, the required modifications, the influence on either performance or energy, and their applicability to present day and future memory systems.
1.2 Refresh Overheads and Solutions
The background energy component will be higher in general purpose DDRs as the memory speed and size increase. Some refresh techniques neglect power effects and focus only on performance impacts of refresh operations. Moreover, the current memory controllers use separate mechanisms to deal with background energy and refresh operations, and many times the mechanisms are in conflict with every other and frequently render each other ineffective. Secondly, row-level refresh commands are mostly used by the preceding refresh reduction techniques, which are no longer readily reachable in modern DRAM devices. As the DRAM device density, these techniques incur widespread complexity in the memory controller and furnish diminishing performance and power benefits.
1.2.1 Energy Efficiency
As DRAM devices become denser and quicker even when the memory system is not servicing any requests they consume greater energy. Increases in system speed, the peripheral circuitry causes will increase in device density and the greater background power dissipation and result in higher refresh energy. These trends cause the memory subsystem of current and future computing platforms to become an essential contributor to energy efficiency [10].
The whole clocked DRAM circuitry is turned off in the deepest low power Self Refresh (SR) mode because beyond the power required to refresh the DRAM cells there is no additional power dissipation. Our current work proposes a new technique called Elastic Refresh to lessen the impact of DRAM refreshes on performance, also for a busy DRAM rank it postpones up to eight refresh commands and when that rank becomes idle, those pending refresh requests are issued
These two sets of techniques battle with each other and often render each other ineffective. When the DRAM becomes idle, memory controller using the Elastic scheme issues pending refresh commands, for all these pending refreshes to be completed the DRAM need to be in the highest power active mode, which reduces the effectiveness of low power mode switching. Coordinating the operation of these two mechanisms can improve both the power efficiency and performance of the DRAM subsystem. We advise a new set of techniques, referred as Coordinated Refresh.
1.2.2 Scalability of Refresh Reduction Schemes
As refresh operations to a row can be skipped if the data stored in it are no longer required or if the row been accessed recently and access awareness exploits information of latest read/write activity [4] [5]. And also, this retention awareness feeds information about the characteristics of individual cells. The frequency of the refresh to preserve its stored charge is determined by the retention period of a DRAM cell. Most of the device cell shave high retention while very few have lower retention that needs frequent refreshes among the DRAM cells.
The problem is that JEDECs refresh mechanism in DRAMs render row-level refresh-reduction techniques so it takes away fine-grained control of refresh operations, relatively inefficient.
Table 1.1 Refresh completion time and the number of rows in the DDR4 device increases with device density
| Device Density | Number of Banks | Pre-Bank Rows | Total Rows | Refresh Interval |
| 8 Gb | 16 | 128 K | 2 M | 350 |
| 16 GB | 16 | 256 K | 4 M | 480 |
| 32 GB | 16 | 512 K | 8 M | 640 |
JEDECs Auto-Refresh (AR) command is used for refresh operations in DDRx devices as it refreshes several rows simultaneously. To simplify this refresh, the memory controller is given responsibility in the refresh process that it decides when an Auto-Refresh should be scheduled based on the pre-specified refresh interval.
As shown in Table 1.1, as the DDR4 device density increase from 16 GB to 32 GB, the total number of rows also increases from 4 million to 8 million. Therefore, in order to achieve row-level refresh, 16 GB DDR4 device requires four million Activate command and Pre-charge command, (8M total commands) in each refresh interval (64ms) period.
1.3 Contribution and Significance
- Earlier refresh categorization such as Row Access Strobe-only, Column Access Strobe-before-Row Access Strobe, and hidden refresh is no longer available in SDRAMs as the traditional asynchronous interface is completely replaced,
- Background energy becomes more significant as the total memory capacity increases. There is a difference in refresh penalties with device size, device speed, and total memory size.
- Categorizing refresh scheduling mechanisms based on command granularity such as row, rank, and bank.
- We propose CO-FAST and CO-FLUSH as there is a need in the preparation of low power mode and refresh operations in idle DRAM periods.
- When row-level refresh techniques are used, we analyze and quantify the issues caused by JEDECs Auto-Refresh (AR) scheme.
- Quantify the consequences of Flexible Auto-Refresh (REFLEX), by skipping refreshes through dummy-refresh, we serve most of the required refresh operations through Auto-Refresh.
CHAPTER 2
A DETAILED LITERATURE REVIEW
At first, performance effects of refresh operations are the focus in few of the refresh techniques. Secondly, row selective refresh commands used in most of the refresh mechanisms are not available in the current DRAM devices. Therefore, these techniques do not cause significant complexity in the memory controller scale with DRAM density. Thirdly, to deal with background power and refresh operations most of the existing memory controllers use separate mechanisms concluding that the refresh improvements are possible if refresh rates are reduced by using scalable refresh reduction techniques or by using finer-grained/per-bank refresh options
2.1 Refresh Penalty vs. Device Speed
The refresh energy and background increase with the device speed in the low bandwidth workloads, due to quick switching of circuits in the DRAM device. However, higher speeds result in good performance, in the high bandwidth workloads, and therefore low overall energy consumption. There is not much change in the performance loss with varying device speed; however, with the device speed, the penalty on average DRAM latency increases.
2.2 Refresh Penalty vs. Device Density
Background energy and refresh increase with device density. In high-density devices for high bandwidth programs, the performance penalty is more. As the device density increases the importance of energy efficiency gets higher. For example, irrespective of workload category more than half of the energy in 32Gb devices is consumed doing maintenance work. When the memory access is infrequent the severity of the problem increases, a common state in big memory systems helping many independent tasks with changeable access patterns.
2.3 Refresh Penalty vs. System Memory Size
Systems with more total memory capacity discharge more background power because many 8 Gb devices are utilized. For a system with 64 GB memory, background power and refresh are the main sources of DRAM energy consumption, when running high bandwidth programs. Finally, we see that refresh has a bigger performance impact on high bandwidth programs while disturbing average latency further on low bandwidth workloads.
2.4 Refresh Granularity
Based on the command granularity like row level, rank and bank we categorize refresh options. Moreover, we survey numerous refresh techniques and discuss their use in modern DRAM systems.
2.4.1 Row-Level
A refresh process at the row granularity can be attained by adding a new command that refreshes a few rows in a given bank or by clearly activating a row and pre-charging it. The former makes changes to the SDRAM devices; the latter does not make any changes but needs more command bandwidth.
The benefit of row-level refresh is that based on the status of each row the memory controller skips useless refresh operations. If a row is read or written more frequently and if a row has longer retention time, using normal refresh rate then refreshes to the row become useless. However, the time required for refresh operations use row-level refreshes in higher density devices, gets longer as compared to Auto-Refresh
2.4.2 Rank-Level
At the machine level, the memory controller can schedule Auto-Refresh instructions to each rank independently or to all the ranks simultaneously. The entire device is unavailable at some stage in the refresh completion period in the case of a simultaneous refresh. Some ranks in a multi-rank memory system are still accessible to service memory requests in the independent refresh case. Depending upon the range of processes and their address mappings, either simultaneous or impartial refresh could end result in higher performance.
2.4.3 Bank-Level
General purpose DDRx devices only have the Auto-Refresh commands at the granularity of the entire device. Until the refresh is complete, no banks are allowed to service any request as an Auto-Refresh is given to all the devices in a rank. This is called as all-bank refresh. On the other hand, to all-bank Auto-Refresh commands, LPDDRx devices have the option of per-bank Auto-Refresh, where only one bank is down when an Auto-Refresh is issued, while other banks could attend normal memory requests [11]. One all-bank refresh is equal to eight such per-bank sequential refreshes, assuming there are eight banks.
2.5 Refresh Schemes
2.5.1 Row-Level Refresh
Ohsawa and co [3] analyzed the growing impact of refresh operations on device performance and energy in DRAM/logic chips. The study anticipated two DRAM refresh architectures which reject unnecessary refresh operations. One of the methods is Selective Refresh Architecture (SRA), which allows refresh operations to select or skip refresh to a row and be performed at a finer granularity.
Another option to realize Selective Refresh Architecture which the memory controller can selectively issue to device row-level refresh command. The last option requires flags for each row in a DRAM device, while the final option presents storage overhead to the memory controller and refresh scheduling difficulty. Both options create substantial overheads as the number of rows increases.
In ESKIMO [5], they proposed a semantic refresh, which also performs the row selective approach to evade refreshing the rows that are free. They proposed to use Selective Refresh Architecture to skip some of the unwanted refreshes so that fine-grained row-level flags are used.
2.5.2 Using Retention Time Awareness
Variable Refresh Period Architecture (VRA) [3] reduces a vast range of refresh operations by placing an appropriate refresh length for every row. Flikker [12] and RAPID [13] use the data about the distribution of DRAM retention periods to minimize the variety of refresh operations. Flikker requires the utility to partition information into critical and non-critical sections, then it uses the sections with a normal refresh rate for vital information and the sections with slow refresh rate for non-critical data. This capability that the non-critical regions can tolerate some degree of records loss. In RAPID, the working device (OS) is conscious of the retention time of the pages and consequently prefers to use pages with extended retention time. This permits RAPID to select the shortest-retention period amongst only the populated pages, as an alternative than all memory pages. This mechanism involves solely software, which requires the OS to be conscious of the retention length of every page.
2.6 Potential Refresh Improvements
2.6.1 Exploiting Retention Awareness
We tested various data retention times and linked them in contrast to ideal memory without refresh. There is a performance and energy impact when altering the refresh timing, in 8 Gb and 16 Gb devices. We expect refresh decrease to be more real when applied on upcoming high-density devices, but to utilize its possible, by considering some trade-offs such as the scalability of row-level commands.
2.6.2 Utilizing Finer Granularity Options
With per-bank refresh command, general purpose DDR devices are enabled. Better usage of bank-level parallelism is provided by the Per-bank refresh command and is more effective in refresh decrease mechanisms. Moreover, the per-bank refresh should be more flexible in scheduling like commands can be distributed out-of-order to banks. Therefore, an automatic scheduling algorithm can be planned to decide between finer-granularity, per-bank and all-bank refresh commands for each rank.
2.7 Summary
Full-system simulation results and evaluation in this Chapter show that refresh operations in future DRAM devices will experience sizeable penalty each in terms of overall performance and energy. Also, we review and conclude that the prior research on refresh and background energy optimization has various shortcomings. In the following Chapters, we tackle two problems. First, many refresh strategies focus only on mitigating overall performance influences of refresh operations. Then, most of the refresh devices use row selective commands which are no longer conveniently available in cutting-edge commodity DRAM devices. Therefore, these methods do not scale with DRAM density and incur vast complexity in the memory controller.
CHAPTER 3
THE DESIGN AND METHODOLOGY
3.1 Coordinated Refresh: An Energy-Efficient Technique
Many revisions have projected clever systems to use these low power modes to save DRAM power. The idea behind these schemes is to change a DRAM rank to low power mode when the rank stays lazy for a time lengthier than a pre-determined threshold. While idle duration tracking was proposed for leveraging low power modes, lazy periods can be used for smart preparation of refresh operations. To ease the impact of DRAM refreshes on performance, a new work suggests a technique called Elastic Refresh, which suspends up to eight refresh orders for a busy DRAM rank and then subjects those pending refresh requests, when that rank becomes lazy.
Even though lazy period tracking can be leveraged to device both smart low power mode swapping and smart refresh arrangement, we see that these two sets of methods struggle with each other and often reduce each other unsuccessfully.
It is observed that organizing the process of these two devices can progress both the energy efficiency and performance of the DRAM. Hence new methods, together referred to as Coordinated Refresh is presented. The key idea behind these methods is to synchronize the arrangement of low power mode evolutions and refresh orders in such a way that most of the mandatory refreshes are arranged when the DRAM rank is in the previous power Self-Refresh mode.
3.1.1 Overview
Coordinated FLUSH refreshes in Self-Refresh (CO-FLUSH) and Coordinated FAST refreshes in Self-Refresh (CO-FAST) use the full elasticity of refresh arrangement by delaying refreshes when the memory is busy and examining them during periods of joblessness.
In its place of the memory controller delivering all the undecided refresh commands, the synchronized techniques first change DRAM to the Self-Refresh mode and then facility the undecided refreshes in the Self-Refresh mode, thus saving background power and justifying the influence of refreshes on performance at the similar time.
CO-FAST contents the timing constrictions for undecided refreshes by repetition the refresh rate through Self-Refresh mode, while CO-FLUSH flushes all the undecided refreshes directly upon entering the Self-Refresh method.
While working in Self-Refresh mode protects DRAM background control, there is a performance price related to the potential of swapping back to active mode. So, normal transitions between Self-Refresh and active methods could damage energy efficiency and performance. Thus, the actual use of the Self-Refresh method requires a correct and quick finding of long idle periods as well as the ability to issue more refreshes in the Self-Refresh mode. To that end, we suggest two additional machines to employ DRAM lazy periods in an energy-efficient way. We suggest History-based Memory Activity Prediction, which paths the distance of previous lazy periods to precisely predict the length of the current lazy period. We use this forecast to guide the thresholds for converting to low power modes in our coordinated refresh methods. We suggest Advance Refreshes (AR), which subjects multiple refresh processes ahead of time through a lazy period so that the latency drawback of these refreshes during the following active period is evaded. We improve the efficiency of CO-FAST and CO-FLUSH by means of Advance Refreshes, in adding to the undecided refreshes used in the Elastic system.
We are the first to addresses the necessity for organizing the preparation of low power mode transitions and refresh actions during idle DRAM periods. CO-FLUSH and CO-FAST: a set of original techniques (collected called Coordinated Refresh), which save DRAM related power by carrying out refreshes during the lowermost power Self-Refresh mode. The two original devices (Advanced Refreshes and History-based Memory Activity Prediction) use DRAM lazy periods in an energy-efficient method. This answer advances the DRAM energy efficiency by 10 % on regular and up to 25 %, as related to the baseline method across the whole SPEC CPU 2006 benchmark suite.
3.1.2 Coordinated Fast Refreshes in SR (CO-FAST)
In present DDR3 devices, there is a choice to double the refresh degree in Self-Refresh mode [14]. This is arranged by a method register, which could be altered any time earlier to swapping to the Self-Refresh mode. This choice is provided for DRAM to effort in the lengthy high-temperature variety. Though, we detect that one can use this choice in the steady temperature variety to affectedly surge the refresh rate. This is called Coordinated Fast Refreshes in Self-Refresh mode (CO-FAST), influences this choice to facility more refreshes in the Self-Refresh mode, thus dropping the number of refreshes delivered in the active method.
Similar to Elastic, CO-FAST uses the full elasticity of refresh plan. When a DRAM rank is full, CO-FAST delays any intermittent refresh commands (extreme of eight refreshes) and delays till the next lazy period chance to issue additional refreshes to recompense for undecided ones. The main alteration between Elastic and CO-FAST is that unlike Elastic, CO-FAST efforts to organize the arrangement of undecided refreshes with low power method evolutions. Exactly, for long lazy periods, CO-FAST switches to Self-Refresh mode before checking the undecided refreshes. Also, for long sufficient lazy periods, CO-FAST subjects up to eight progressive refreshes.
3.1.3 Coordinated Flush Refreshes in SR (CO-FLUSH)
To change a DRAM rank into the Self-Refresh mode, the memory controller subjects a self-refresh command. In current DDR3 devices, the self-refresh facility does not need any other quality, since the DRAM rank inside tracks the address of the following row to be refreshed and usages an interior timer to plan the essential refreshes. Our method, called Coordinated Flush refreshes in Self-Refresh mode (CO-FLUSH), needs a slight alteration in the DRAM device, where a definite amount of refreshes might be flushed (started as a batch), just after swapping to the Self-Refresh mode.
With this minor alteration in the DRAM device, CO-FLUSH can flush numerous refresh instructions in the Self-Refresh mode, which then would have been delivered in the active method. This alteration enables CO-FLUSH to be additional effective than CO-FAST in circumstances where the lazy periods are too small such that the simpler method of repetition the refresh rate is inadequate to issue additional refreshes.
Like CO-FAST, CO-FLUSH delays refreshes in a high action phase and then finds the suitable idle period for swapping to Self-Refresh mode, where those undecided refreshes are within repaired by the DRAM. Also, like CO-FAST, CO-FLUSH may plan some refreshes in advance dependent on the distance of the lazy period. Since CO-FLUSH could use lesser gaps to flush additional refresh instructions; it wants lesser threshold values to change to Self-Refresh mode if there is a possibility for delivering additional refreshes. So, small gaps in action could occasionally be used to change into Self-Refresh mode rapidly and flushing additional refreshes. Though, if the amount of undecided refreshes through the previous active phase is zero, then there is no instant condition for additional refreshes, and hence CO-FLUSH would not needlessly transition to the Self-Refresh mode.
3.1.4 Coordinated First Immediate Refresh in SR (CO-FIRST)
The JEDEC standard commands that soon upon entering the Self-Refresh mode, the DRAM device necessity inside schedule an instant refresh process. One more irregular of synchronized methods, named Coordinated First Immediate Refresh in SR (CO-FIRST), can influence this instant refresh knowledge to service an advanced number of DRAM refreshes in the Self-Refresh mode.
The benefit of CO-FIRST is that it can be used in combination with any refresh preparation algorithm. It needs only negligible alteration to the memory controller and no alteration to the DRAM device. The power developments provided by CO-FIRST hinge on the length and frequency of lazy periods. If the implementation time is subject by long lazy periods, then CO-FIRST would be able to organize Self-Refresh method transitions with greatest of the mandatory refresh instructions. Though, if lazy periods are comparatively rare, then CO-FIRST will not deliver any advantage over the Demand Refresh approach. Also, for small lazy periods, CO-FIRST’s method of examining refreshes in the Self-Refresh method may be counter-productive in terms of energy competence, as the Self-Refresh method background power savings may not balance the performance consequence of swapping back from the Self-Refresh method to the active method.
3.2 Flexible Refresh: Scalable Refresh Solution
Refresh process in DDRx plans is naturally performed via Auto-Refresh knowledge, which refreshes several rows concurrently. To shorten refresh management, the memory controller is assumed an incomplete duty in the refresh process. While DRAM device panels what rows to be refreshed in an Auto-Refresh and how refresh is applied inside. With this better flexibility, the device creators have enhanced Auto-Refresh by using the exact information of how the DRAM bank is inside prepared in numerous sub-arrays. Each sub-array can transmit out refresh actions autonomously by means of individual its local row-buffers; so, DRAM can plan numerous refreshes in similar, for numerous rows of a single bank, to diminish Auto-Refresh energy penalty and performance
3.2.1 Auto-Refresh (AR) Command
Overall, the refresh procedure can be detached into three phases: when a refresh command is delivered, what share (rows) of memory is refreshed, and lastly, how the refresh is applied in Auto-Refresh can be delivered at a per-bank or an all-bank level. In product DDR devices, only all-bank Auto-Refresh is maintained, while LPDDR devices have a per-bank Auto-Refresh choice in addition. In the all-bank Auto-Refresh operation, all the banks are concurrently refreshed and are inaccessible for the refresh period.
The benefit of all-bank Auto-Refresh is that with a solitary knowledge, numerous rows of all the banks are refreshed, overriding general less time than correspondent per-bank Auto-Refresh. Though, since per-bank Auto-Refresh permits non-refreshing banks to facility memory needs, the programs with high memory bank-parallelism do better in per-bank Auto-Refresh associated with all-bank Auto-Refresh.
3.2.2 Self-Refresh (SR) Mode
DRAM devices service low power modes during lazy periods to save background energy. The lowermost power mode, known as Self-refresh, goes off the whole DRAM clocked circuitry and the triggers and DLL refresh processes internally by a built-in analog clock without needful any knowledge from the memory controller.
When in a self-refresh mode, the development of refresh commands is wholly below the control of the DRAM device. The device routinely increases the interior refresh counter after each refresh operation. The number of refresh operations repaired during the Self-refresh method would vary liable on the time the DRAM employs in the Self-refresh method and how refresh processes are arranged by the DRAM device during that time. Thus, when the memory controller changes the DRAM back from the Self-refresh mode to the active mode, the precise value of the refresh security cannot be properly foreseen.
3.2.3 Refresh Counter Access Architecture
Our important remark is that the present DRAM devices previously have an interface existing to read and write some designated DRAM registers. Reading the refresh counter register (REFC-READ) can be applied similarly to multi-purpose register reads in DDR4 or mode register read in LPDDR3 devices. In reply to a REFC-READ knowledge, the DRAM yields the refresh counter value on its data-bus like a usual control-register read. Since the refresh counter is opened rarely, only at initialization and on departure from the self-refresh method, timing expenses are not dangerous.
Finally, a REFC-WRITE knowledge can overwrite the worth of the refresh security register, applied as additional Mode Register Set knowledge. The REFC-WRITE can be used to coordinate all the devices in a rank after going from the Self-Refresh method. In the Self-Refresh method, the DRAMs matter refreshes based on timing actions generated from their native ring oscillators. The controls of oscillators in each device are not matched, and so some devices in a rank may subject more refreshes than others. In this situation, the refresh counter standards read on Self-Refresh exit from devices of a rank may not match precisely. Therefore, the memory controller uses REFC-WRITE to harmonize all the devices on a rank.
3.2.4 Flexible Auto-Refresh (REFLEX) – Refresh Reduction in SR Mode
Through the future architecture, the memory controller can admission and harmonize the refresh counter standards of all devices in a rank. The memory controller can use dummy-refresh instructions to bounce refreshes when needed. We suggest a set of three refresh discount mechanisms, together referred to as Flexible Auto-Refresh (REFLEX).
With the future refresh architecture, a memory controller can harmonize the refresh counter on the wanted basis. Therefore, REFLEX methods are talented of swapping the DRAM to the lowermost power self-refresh method when the DRAM is lazy for adequately long periods. To additional save energy in the Self-Refresh method, the refresh rate can be condensed when switching to a Self-Refresh method based on, the holding period of the following rows to be refreshed. Even if some rows take weak cells, those rows can be refreshed through clear row-level refresh instructions before swapping to the Self-Refresh method. This scheme is like partial array self-refresh (PASR) choice in LPDDR devices where idle memory sites are automatic to bounce refreshes in the Self-Refresh mode.
CHAPTER 4
IMPLEMENTATION AND RESULTS
4.1 Evaluations for Current-generation Devices
We estimate the energy benefits of our methods for current generation 4 Gb devices. We also examine the influence of DRAM speeds on the efficiency of our methods. We show results for CO-FAST and single-core.
For DDR3 1333 Mbps, CO-FAST decreases DRAM energy by 3 % on regular and up to 8 % across all. As we raise the speed to 1886 Mbps, parallel to high-speed DDR3 parts available in the market, the power gains for CO-FAST increase to 3.7 % on regular and some plans exhibit energy savings up to 10 %. For 3.2 Gbps device, CO-FAST exhibits energy drops of up to 12 %.
4.2 Evaluations for Future-generation Devices
We give the performance and energy results of single and multi-core using the future DRAM devices of 3.2 Gbps speeds and 8 Gb density.
4.2.1 Single Core Evaluations
Both CO-FAST and CO-FLUSH achieve important performance and energy savings developments for the MEDIUM and HIGH groups. CO-FAST decreases DRAM energy by up to 17 % and rise performance by up to 13 %, CO-FLUSH delivers up to 25 % energy discount and up to 14 % IPC improvements. The energy discounts attained by the synchronized techniques are due to the advanced fraction of refreshes in the SR mode.
CO-FAST is as energy efficient as CO-FLUSH, but for programs such as cactusADM, astar and libquantum have lazy periods of intermediate length, in which CO-FAST will not be able to issue additional refresh commands. Related with Elastic, our synchronized techniques improve performance and save energy by logically using the refreshes in lazy periods. Also, the exact memory action predictions using History-based Memory Activity Predictions energetically control the thresholds to avoid needless transitions to the self-Refresh mode.
4.2.2 Multi-Core Evaluations
For multi-core tests, we use two types of assignments: (i) SPECRate-type homogeneous assignments, covering four copies of the similar program, (ii) heterogeneous assignments collected of program mixes, the results in this unit are based on 8 Gb DDR4 units running at 3.2 Gbps.
Most of the trends experimental in the single package assignments repeat in the multi-core scenarios. In homogeneous multi-core assignments, synchronized methods provide advanced energy benefits in MEDIUM and HIGH assignment categories. The results for heterogeneous assignment mixes prove significant benefits for synchronized methods, even if they have honestly casual memory request designs generated by features of basic programs.
4.3 Benefits of Auto-Refresh Flexibility
Performance development in 16 Gb devices for all the refresh options. Row-level refresh experiences a 30 % performance degradation though, as the amount of rows doubles in 32 Gb devices. The motive for this performance loss is using row-level refreshes, each bank stays mostly full in examining refresh operations through Activate command and Pre-charge command while parting insufficient bandwidth for regular memory requests.
Performance, as well as Energy aids by using only row-level refresh option, reduces at advanced DRAM densities when a large portion of the refresh operations is skipped. In contrast, our proposed REFLEX techniques deliver scalable aids by serving most of the refreshes through improved all-bank and per-bank Auto-Refresh options.
4.4 REFLEX with Low Power Modes
A rank switches to power-down slow departure after the demand queue for that rank will be empty, as proposed in [34]. If the rank stays lazy for a time length equal to Refresh Interval, average one Auto-Refresh command in this time, then the rank switches to the Self-Refresh mode. The Auto-Refresh options, both all-bank and per-bank, are in a position to save related energy by swapping to low power modes in low activity stages. In contrast, the row-level option decreases the opportunity to stay in power-down mode and is not compatible with SR mode. Therefore, the energy advantages of low power modes, quite important in assignments with medium to high idle stages, are lost when row-level refreshes are working.
CHAPTER 5
CONCLUSION AND FUTURE WORK
There are some refresh methods based totally on old DRAM units and asynchronous interfaces. These techniques are useful for DRAM caches, however, for standard cause DDR SDRAM devices, they are much less practical. With the increasing system density, JEDEC has supplied more than one refresh scheduling and timing options. Understanding diagram trade-offs such as refresh management complexity, machine level modifications for a refresh, available refresh scheduling flexibility, will be vital for designing practical refresh optimization schemes.
The methods that make use of built-in mechanisms existing in DDR units to decrease the refresh penalty are desirable. For example, strategies that make the most Self Refresh mode, techniques that utilize accessible refresh flexibility with auto-refresh commands, and methods that take gain of the finer-granularity alternatives in DDR4 devices. The auto-refresh command is optimized by means of DRAM vendors for energy and performance. Therefore, schemes that use row-level express commands to fulfil refresh requirements will have extra negative aspects
Moreover, their administration would become hard as the quantity of row in high-density DRAM increases. We have exposed that unless more than 70% of the rows are not essential to be refreshed. There is no advantage of the use of a row-level refresh for high capacity memory devices. The power overhead, controller complexity, command bandwidth makes row-level refresh even less eye-catching than auto-refresh.
Both the overall performance and energy penalties of refresh amplify up to 35% in near future 32 Gb devices. The background power in the high-density machine additionally will increase substantially. Therefore, refresh and background power management turns into key graph considerations. Future instructions could be the use of some methods accessible in LPDDRs (PASR, Temperature Compensated Self Refresh, etc.) extra aggressively barring sacrificing too a lot of performance.
The use of retention consciousness of DRAM cells and lowering refresh operations can be very advantageous in lowering refresh penalty. However, such schemes are able to use self-refresh and auto-refresh modes effectively. Otherwise, the features bought through retention consciousness will be misplaced via issuing row-selective refresh commands, specifically in high-density DRAMs.
Commodity DRAM devices can effortlessly afford to have refresh commands at unique granularity. Finer-granularity refresh commands in the DDR4 standard are carried beside the ordinary all-bank refresh. In future, per-bank refresh command can effortlessly be maintained in DDRx devices, has been done in LPDDRx devices. After that, the next project is to design online algorithms which can automatically change between these refresh options based on memory recreation so that the overall performance and energy benefits are maximized.
References
| [1] | JEDEC, “DDR4 STANDARD Specification,” Technical Report, September 2012. |
| [2] | J. Liu, B. Jaiyen, R. Veras, and O. Mutlu., “RAIDR: Retention-Aware Intelligent DRAM Refresh,” in ISCA, 2012. |
| [3] | T. Ohsawa, K. Kai, and K. Murakami., “Optimizing the DRAM refresh count for merged DRAM/logic LSIs.,” in ISLPED, 1998. |
| [4] | M. Ghosh and H. H. Lee., “Smart Refresh: An Enhanced Memory Controller Design for Reducing Energy in Conventional and 3D Die-Stacked DRAMs.,” MICRO, 2007. |
| [5] | C. Isen and L. K. John., “ESKIMO{Energy Savings using Semantic Knowledge of Inconsequential Memory Occupancy for DRAM subsystem.,” MICRO, 2009. |
| [6] | Micron Technology., “Various Methods of DRAM Refresh.,” Technical Report, 1999. |
| [7] | T. Hamamoto, S. Sugiura, and S. Sawada., “On the Retention Time Distribution of Dynamic Random Access Memory (DRAM).,” IEEE Transactions on Electron Devices, vol. 45, no. 6, pp. 1300-1309, June 1998. |
| [8] | K. Kim and J. Lee., “A New Investigation of Data Retention Time in Truly Nanoscaled DRAMs.,” IEEE Electron Device Letters, vol. 30, no. 8, pp. 846-848, Aug 2009. |
| [9] | D. S. Yaney, C. Y. Lu, R. A. Kohler, M. J. Kelly, and J. T. Nelson., “A Meta-Stable Leakage Phenomenon in DRAM Charge Storage Variable Hold Time.,” in IDEM, 1987. |
| [10] | L. Minas and B. Ellison., “The problem of power consumption in servers.,” Intel Press Report, 2009. |
| [11] | JEDEC, “Low Power Double Data Rate 3 (LPDRR3) Standard Specifications,” Technical Report, 2012. |
| [12] | S. Liu, K. Pattabiraman, T. Moscibroda, and B. G. Zorn., ” Flikker: Saving DRAM refresh-power through critical data partitioning.,” in ASPLOS, 2011. |
| [13] | R. K. Venkatesan, S. Herr, and E. Rotenberg., “Retention-Aware Placement in DRAM (RAPID): Software Methods for Quasi-Non-Volatile DRAM.,” in HPCA, 2006. |
| [14] | JEDEC, “JEDEC DDR3 Standard.,” Technical Report, July 2010. |
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Energy"
Energy regards the power derived from a fuel source such as electricity or gas that can do work such as provide light or heat. Energy sources can be non-renewable such as fossil fuels or nuclear, or renewable such as solar, wind, hydro or geothermal. Renewable energies are also known as green energy with reference to the environmental benefits they provide.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: