A Low Power Near Sub-Threshold Design for Large Scale Graphical Inference
Info: 9516 words (38 pages) Dissertation
Published: 1st Feb 2022
Tagged: Engineering
The message passing (MP) algorithm operates on a probabilistic graphical model (PGM) which is a powerful method in artificial intelligence and machine learning. It combines graph theory and probability theory in such a way it can represent a complete probabilistic distribution over a multi-dimensional space in a factorized representation using a graph. This factorization is the successful key of this method since it provides the modularity mechanism where a complex system can be built by combining its simpler parts while ensuring the consistencies during the process. The PGM can solve optimization and inference problems in various applications such as the error-correction coding, stereo matching, statistical physics, and machine learning [6,13-17]. In this work, we investigate inference schemes in the domain of graphical models and to develop new minimalistic inference schemes which it can implement in hardware. This low-level expandable hardware implementation will be useful, for example, with autonomous robotics, where hardware resources are limited and power consumption is one of the main constraining factors. To interface with enormous real-time data from robotics sensors, we propose an implementation using sub-threshold analog signal processing MP design with near-threshold front end multi gigabit/s RF interface. We present two low power, subthreshold, analog VLSI architecture for MP. We exploit two aspects of MP to mitigate error from analog non-ideality.
First, the relative likelihoods between the possible outcomes are sufficient to reach the decision in MP. Second, the accuracy is critical in earlier iterations when the probabilities are closer together. We implement our architecture in TSMC 65nm and simulate with Spectre SPICE-level circuit simulator for the all analog design. MATLAB is used to simulate the ideal message passing and mixed signal with circuit characteristics for analog components extracted from Spectre results. The MP algorithm reached correct decision in all simulated test cases.
ACM Reference format:
Chenxi Dai, Ratchaneekorn Thamvichai, Mark Neifeld, Dung Nguyen and Janet Roveda. 2018. An Analog VLSI Implementation of Message Passing Algorithm. ACM J. Emerg. Technol. Comput. Syst. 14, XXXX. 2 (May 2018), 20 pages. https://doi.org/XXXX
Introduction
Built upon the scientific disciplines of signal processing and artificial intelligence, Cognitive Computing (CC) is emerging as an important technology platform for vision, decision making, machine learning, human-computer interface, and many more applications. One important components of CC is inference from incomplete or erroneous data. Inference can be found in many modern applications including video analytics, compressive sensing, and big data (e.g., drug discovery, stock prediction, bioinformatics, etc.). While it can be cast rigorously in terms of underlying probabilities and therefore benefits from strong theoretical foundation, inference may also lead to high computational complexity. For example, Maximum a Posteriori (MAP), a popular way to optimal solutions for inference within Bayesian framework, is unfortunately NP hard in general. In order to reduce computational cost, powerful modern approaches seek approximate solutions via message passing (MP) on graphical models.
Although MP is based on simple computational primitives, overall complexity can become intractable for large scale graphs. For instance, one iteration of MP on an N node graph with D connection density and K-element probability distributions requires over DN2K2 computational steps. In order to implement a 1 million node graph therefore, a modern digital ASIC implementation for MP will consume 1.5GW and require 5776m2 (roughly 3x increased area and power consumptions are expected for CPU based implementations). It is clear that a brute force mapping to digital VLSI implementation will rapidly become intractable with the increasing size of graph.
The goal of this paper is to investigate new approaches in computing that can achieve circuit and system-level robustness with small power consumption and small area requirement for computation. There are several variants of the MP algorithm (e.g., sum-product, log-sum, approximate, Be the free energy minimization, etc.) that we will study in the context of implemental efficiency. We will focus on large scale problems for which digital electronic solutions are prohibitive. An important aspect of this work will be an evaluation of the robustness of these various algorithms to implementation imperfections. In addition to traditional problems in graphical inference, our recent work has also suggested that MP can be applied to solving generalized Ising problems (i.e., finding a collection of spins that minimize the Ising Hamiltonian) which is NP hard.
Our initial work shows that good approximate solutions emerge from casting the Ising problem in terms of graphical inference. One attractive MP implementation will employ the log-sum algorithm and leverage the mathematical primitives of Log(), Sum(),exp(), and normalization. Our initial results suggest that 5% perturbation in the computation accuracy can be tolerated within this algorithm for large graphs with connection density > 20%. Based on these computational primitives we select the near-threshold analog circuit implementation. In particular, we investigated the implementation using Carver Mead’s subthreshold design. Using only 2T (two transistors), Mead’s Log() and exp() are the natural choices for the proposed MP based graphical inference implementation. We implemented the proposed graphical inference approach using TSMC 65nm. Our preliminary results suggest that it is possible to achieve MP computation convergence with less than 10% message errors, considering imperfections such as process variations, transistor layout mismatch, and 1/f noise. Projecting our results to 14nm technology node, we demonstrated that the near threshold computation has substantial benefits: 70kW power consumption for 1 million nodes, with 2cm2 per node as area consumption. Our initial findings also indicate that the communication power becomes dominant in the proposed implementation.
Having reduced the power and area of the “computation” via use of near-threshold analog VLSI, the remaining challenge is to support the very high communication requirements of the MP algorithm. For a 1 million node fully connected graph there are O(1012) edges. Our initial study indicated that one potential solution to reduce communication power is by using optical interconnects. We have developed an analog time-multiplexed optical solution that provides full connectivity. Low noise, high error tolerance, and low power have made the optical interconnect as a much better choice than the electrical one. In order to provide an interface between the near-threshold implementation and the large optical interconnect networks, we propose a new “shift-hold” dynamic capacitance bank based analog deMux design to allow 1GHz serial input and 1MHz parallel output.
Several important findings from this proposed research will contribute to the on-chip learning AI applications. 1) The scalability can be achieved through graphical models with message-passing algorithms. 2) The near-threshold design improves computation density and enhance robustness of the circuit and system. 3) The near-threshold implementation (i.e. subthreshold implementation), together with 1) and 2), provides a recursive and error resilient framework that consumes very low power.
The proposed idea can be viewed as a potential breakthrough based on the neuromorphic computing. Our previous work has already shown that MP in highly connected graphical models by probabilistic inference is solvable through the use of optical devices (we have published our findings in several recent papers). However, this fully optical topology struggles in its creation of computational components such as multiplication, log(), exp() and normalization necessary for graphical inference problems. Our initial implementation using 65nm technology node demonstrated the possibility of using near threshold analog design to achieve MP based graphical inference implementation.
Message Passing Algorithm
The message passing (MP) algorithm can be used to solve numerous optimization and inference problems in various applications such as error-correction coding, stereo matching, statistical physics, and machine learning [6,13-17]. The algorithm is operated by passing messages between nodes in a graphical model representing a problem of interest and recursively updating the messages using computations performed at nodes. The nodes in the graphical model are random variables that can be in one of a discrete number of possible states or alphabets, K, and edges between two nodes represent conditional dependencies. The number of states or alphabets, K, is determined by its applications e.g. K equals to 2 if the model is used to represent an Ising model where each node can have a spin of -1 or +1, K can be 256 representing an image pixel with an 8-bit gray-level encoding.
For this work, we use K = 3 in order to represent a more generalized MP architecture. The belief propagation [18] also known as a sum-product message algorithm is a well-known method in finding exact or estimated marginal probabilities of the nodes given observations from other nodes. The marginal probability of a node, node i, is proportional to the product of all messages from its neighboring nodes. The messages contain knowledge or influence that its neighbor has on node i. After several iterations in which the message of each node is updated appropriately with the message-update rule, the value at each node eventually reaches the exact or estimated marginal probability, in other words, the most probable state of the nodes can be obtained.
There exists various research on hardware implementation of the message passing algorithm in various fields in order to enhance its performance [4,7,9] such as algorithm accuracy, power consumption and memory requirement.
Message Passing Decision Making
In the message passing algorithm, the graph consists of N fully connected nodes. Each node represents a random variable, which has a domain of values α. The size of the domain is K, and in general, the set of possible outcomes in domain are
α1,α2, …αK. The goal is to determine value
αi in the domain, for every node. Every node i represents its current probability for each α in the domain as a column vector,
Pi=P(α1),…,P(αK)iT. Every node i passes the probability vector at time t as a message Pi(t) to the other nodes, after which a new updated probability can be calculated Pi(t+1). This process is repeated iteratively until a decision is reached. Fig 1 illustrates the MP algorithm at one node for K=3, with the three components of Pi as function of the iteration number plotted as circles, triangle, and diamonds. As iteration increases, the distance, or separation, between the correct αi for that node and the other α should increase.
Fig 2a shows the range where the probability can fall, divided into three regions.
Def 1: The High probability region is where
PHL≤Pαk≤PHH. In the high probability region, the probability is high enough to reach a decision that the node is αk.
Def 2: The Low probability region is where
PLL≤Pαk≤PLH. In the low probability region, the probability is small enough to reach a decision that the node is not αk.
Def 3: The Decision Margin region is where
PLH≤Pαk≤PHL. In the decision region, the probability is note sufficiently high or low for the node to be determined
In the high probability and low probability regions, the probability give enough confidence to reach a decision.
Fig 2b applies the regions into the iterations of the message passing. In this scenario, the probabilities have all fallen within the High probability or Low probability regions by iteration 3, where a decision is reached. Afterwards, the new values from any further iterations should converge to a steady value without leaving the high or low regions. The goal of MP is to move the probabilities of the αk in the domain staring in the decision region to either the high probability or low probability regions, such that the correct αi that the node is in the high probability region. This classification is similar to the noise margin in digital logic. [cite Jan Rabaey]
We observe that the MP algorithm separates a decision among K options in the domain into K binary decisions for each option αk, MP decides if the node is or is not αk. The K decisions we define regions of operations in Def. 1-3 similar to the regions in CMOS logic. It is important to note that the wrong alpha having the highest probability is not sufficient to reach the wrong decision. Also, as the iterations increase, the probabilities tend to be farther apart, causing the margin to tend to increase. Intuitively speaking, the more confident we are, the more evidence required to change our mind and choose a different answer.
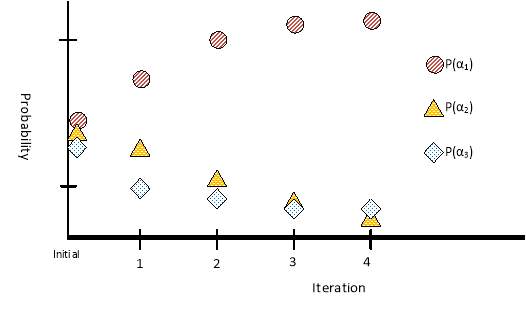
Fig. 1. Probability Messages in Message Passing Algorithm for a Node with K=3
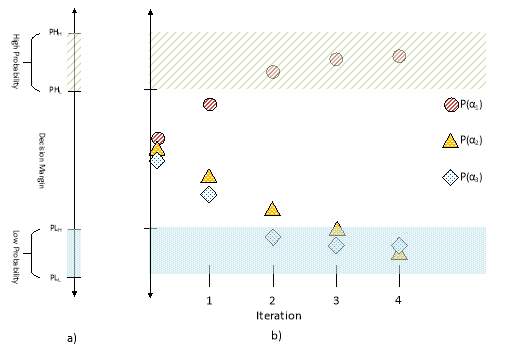
Fig. 2. a) Regions for probability messages b) Message Passing algorithm with regions
Message Passing Arithmetic
The message passing arithmetic is the same in each node and uses the probability vector passed from the N-1 other nodes to compute the new probability for the node. For a given node
n∈1, 2, 3,…, Nevery other node
i=1, …, N and i≠n, each probability vector Pi is multiplied with a C Matrix which is K by K, resulting in row vectors Yi corresponding to the messages passed from the other nodes, with each row corresponding to a different alphabet in the domain. The process of mapping a problem to the MP algorithm determines the C Matrix values, as well as the meaning for the random variable α in the node. The C Matrix can be different between every node though is remains the same throughout all iterations. Each row of the K-1 vector matrix multiplication outputs Yi are multiplied together to create a single
K×1 column vector Zfrom the K-1 vectors. As described in Eq. 2, a single Z column vector is formed from N-1 vector matrix multiply output Y vectors, with
k∈1, 2, …, K. The Z vector is normalized to calculate the new probability for node i. The magnitude of the kth row in Z can be thought of as the likelihood the node being αk, with larger values representing higher certainty. The Z vector is normalized so that the probabilities add up to one, since the previous operations are not normalized.
For node iCi(11)⋯Ci(1K))⋮⋱⋮Ci(K1)⋯Ci(KK)Piα1⋮PiαK =Yi(1) ⋮Yi(K)
(1)
The parenthesis represents the location in the matrix, and subscript represents which node, and every node has different values for the matrices.
Zi(k)=∏i=1N-1Yi(k)
The normalization is described by Eq. 3 where Imax is the current representing the maximum probability, using the mapping the probability to a current.
Pnewi= Pnewiα1⋮PnewiαK where for k∈1,2,…K, Pnewi(αk)=Pnewiαk ×Imax∑j=1KZi(j)
The nodes compute their new probability message in parallel. After a period T, the messages from each of the N nodes are passed to all the other nodes. This marks the start of a new iteration, and the process is repeated until the probability of the nodes converge, where for each node, the probability for one of the alpha in the alphabet is near one and others are zero.
Architecture
We present two VLSI architectures for computing the message passing algorithm. A subthreshold multiplier [1,2] functions as building block for multiply or divide for both designs, which is discussed in detail in Section 3. Since the subthreshold multiplier circuit is actually a multiply and divide, both designs use a ratioed multiply where the free parameter is fixed at a designer chosen value to maintain the range of the output current multiplier. This does not negatively affect accuracy because the goal of the MP algorithm to find which of the possible alpha in the domain of the random variable is most likely. In fact, the ratioed multiply is more accurate since it reduces the range of possible currents. Though the free parameter affects the absolute value of the calculation, the same operations are allied to all messages, and normalization ensures the probabilities are correct relative to one another. The decision making criteria relies relative likelihood of the probability of one alpha compared to that of the other choices rather than the absolute value of the probability.
Analog Architecture
The first architecture is completely analog shown in Fig. 3Fig. 2. The VMM, multiplier tree, and normalizer modules are built using the multiplier blocks. In this design, the denominator in the ratioed multiplier must be carefully chosen to control the range of the output and maintain the correct ratio. Because the goal is to decide which alpha in the alphabet the node is rather than the absolute probability of each alphabet, our design approach is to minimize the relative error between the entries in the probability vector. The final normalization of the calculations for the new probability causes relative magnitude, or ratio between, probabilities to compute the same results as the absolute probability. This is advantageous because even if the absolute value of the new message has a high error, the normalization step will ensure that the output error is small as long as the ratios between the values are maintained. This strategy enables the algorithm to be resilient against analog non-ideality of the multiplication circuit which is shown in circuit implementation section described in more detail in Section 4.
Results
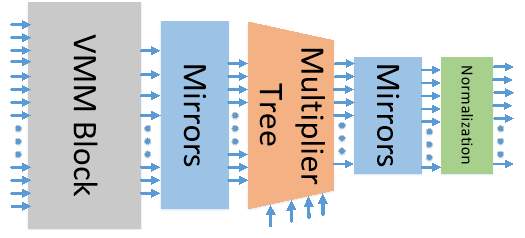
VMM. The subthreshold multiplier unit are used to create vector matrix multiply units. The multiply units are discussed in more detail in Section 3. This module computes the matrix multiplication in Eq. 1. Currents representing the probability and the C matrix are multiplied with the multiplier unit. Connecting the output currents from K multiply units sums the products (due to KCL) to compute the row-column dot product in the matrix multiplication. Creating this structure K times creates a matrix vector multiply with K2 subthreshold multipliers.
Multiplier Tree. The multiplier tree implements the product in Eq. 2. Multipliers are arranged in a binary tree like arrangement, where the input from VMM is at leaf, and output at the root. To reduce time needed for multiplication, the amount of stages should be minimized, thus the tree structure. Before the multiplication computation of the tree, the signal from the VMM is divided by 10 so that the current is scaled down and bounded within the more accurate range for the multiplier units. If N-1 is a power of two, the tree is exactly a binary tree. Otherwise, the first multiply stage multiplies the inputs from the VMM block, two at a time for the first floor (log2(N-1)) nodes. Multipliers are inserted (e.g. In9) at outputs of the aforementioned multipliers until all N-1 multiplications are carried out. Current mirrors are inserted into the multiplier tree to change the direction of current input into the multiplier blocks as needed. Two copies of the final multiplication current are needed for the normalization. The copy block and divide by 10 also double as the mirrors shown in Fig. 3 Fig. 2.
Normalization. The result from the multiplier tree is normalized so that the sum of the values corresponds to 100% or P=1. The output of the normalization circuit is the new probabilities for all the possible values of the node. The sum in normalization is computed with KCL the same way as the sum of a row in the VMM.
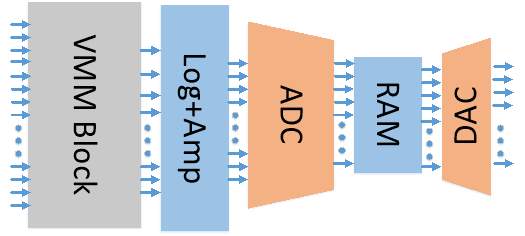
Fig. 4. Mixed Signal Architecture
Mixed Signal Architecture
The second architecture is mixed signal. The matrix multiplication uses the same analog VMM block as the analog. The multiplication is implemented through log-sum exponential. Next, the analog signal is then converted into digital with ADC so that normalization is done through look up table. The ADC is a low voltage successive approximation ADC with 10 bit precision. Finally, the message is converted back into an analog signal using a DAC for the next iteration.
Circuit implementation
Preliminary
The most common model for MOS transistors have three regions of operations: cutoff, triode, and saturation. In this model, the off region when VGS
VGS≈VT [1]. This is depicted in Fig. 12 which plots drain current as function of gate voltage. For an NMOS transistor operating in subthreshold, the drain current is given by the following equation. [1, 2]
IDS= I0nWLeκnVGBVTe-VSBVT-e-VDB/VT
Where Ion is a constant that depends on mobility μ, W and L are width and length of the transistor respectively. κ depends on oxide and depletion capacitance of the transistor [1]. When the source of the transistor is connected to the body, they have the same voltage, so the equation becomes
IDS= I0nWLeκnVGSVT1-e-VDS/VT
When the transistor is in saturation, typically VGS ≥ 4VT, then term in parenthesis becomes close to unity, and the drain current is approximately
IDS= I0nWLeκnVGSVT
For PMOS transistors, the drain current is given by the equation
ISD= I0pWLe-κnVGBVTeVSBVT-eVDB/VT
The corresponding equations for VSB=0 and for saturation can be derived in the same way as for NMOS using Eq. 7.
Subthreshold Multiplier
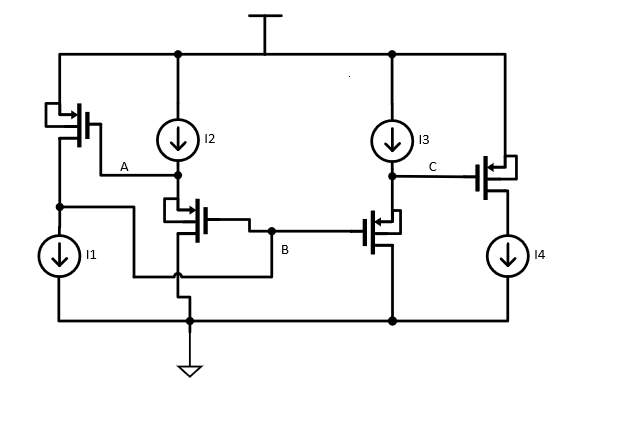
Fig. 5 Subthreshold Multiplier
A basic block used in the system is a subthreshold multiplier proposed in [1,2] shown in Fig. 5 Fig. 6. The circuit operation can be described simply by applying translinear principle, which can be stated as: in a closed loop containing equal number of oppositely connected translinear elements, the product of current through the elements facing the clockwise direction is equal to product of current through elements facing counterclockwise direction [1, 3]. By applying the principle to the loop VDD-A-B-C-VDD, we get the following [1, 2]:
I1I2=I3I4 or I4=I1I2I3
Alternatively, this can be derived using KVL using the same loop, then
V1+V2-V3-V4=0
Assuming the transistors are in saturation and VSB=0, we can rearrange to solve for VGS and substitute into the KVL equation, resulting in
VTκnlnI1I0WL +lnI2I0WL – lnI3I0WL -lnI4I0WL =0
If all the W/L are the same, then simplifying, we get the same equation. We implement the multiplier with PMOS since VSB=0, implementing the design in NMOS requires a triple well process to separate the body connections from the substrate, increasing device size drastically. The multiplication is a radioed multiply with the ratio between I2, and I3, where I3 is usually a fixed current chosen to keep the multiplication in range.
Analog Architecture
Fig. 6 Fig. 7 is a detailed overview of the analog implementation of one node. All the nodes have an identical structure, and our implementation has ten nodes with an alphabet size of three. The message from the other nine nodes has three components, one for each α in alphabet. The output of the VMM similarly has three components, and there are three multiplier trees, one for each component. The multiplier tree calculates the product of one component, and sends the result to the normalizer, which calculates the normalizes the result across the components. We implement the architecture with TSMC 65nm using Cadence Virtuoso EDA tools. Simulations shown in this section were generated with Spectre circuit simulator unless otherwise stated.
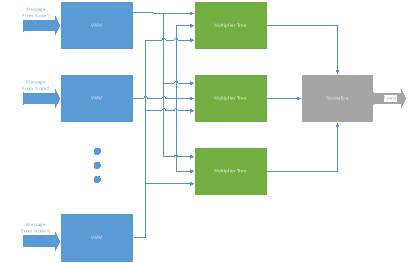
VMM . The subthreshold multiplier unit are used to create vector matrix multiply units. I1 is from the probability message; for clarity we designate it Ip. I2 is chosen to create the C matrix value which is designated as Ic. The denominator current I3 is fixed at a chosen value Iscale which is used to control the magnitude of the result. The C matrix weights are implemented using I2 and I3. Recall that summing the output currents from the multiplier units using KCL computes the matrix multiply.
The VMM is implemented with multipliers drawn in schematic editor. Fig. 5 Fig. 6 shows the Spectre simulation output of the multiplier on the left and ideal multiplication on the right, both as a function of Ip and Ic, with Iscale fixed at 100nA. If we take the cross section at a fixed Ic, ideally, we should get a line. We found that generally, the closer the ratio Ic:Iscale is to 1, the closer the multiplication result follows the ideal. For Ic = 100n, the subthreshold multiplier is closer to linear than when Ic is larger. This is true for Ip as well, though in the VMM, the probability maps to 10nA to 100nA for 0 to 1.
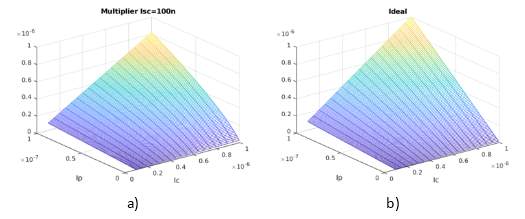
Fig. 7 a) Multiplier Output Current Simulation with Iscale=100n. b) Ideal Multiplication
Multiplier Tree. The multiplier tree implements the product of N-1 VMM outputs, Yk, to compute Zk, the unnormalized result. The subthreshold multiply units are arranged in a tree structure, so the depth of the tree is
ceil(log2N-1). The deeper the tree, the error from analog non-idealities multiplier tree is cascaded and increases, as well as increasing the time needed for the output to reach steady state. Our design approach is to minimize the relative error between the entries in the probability vector. When N is a power of two, the tree can be symmetrical, which reduces relative error. Since one multiplier tree computes one product, then K multiplier trees in parallel computes the entire column vector Zi. In each multiply cell, the free parameter in the denominator is chosen so that the multiplier operates in the accurate region. Recall that the generally, the multiplication is less accurate when the ratio is far from one.
Fig. 8 Fig. 9 shows the output of the multiplier tree when all nine inputs have the same current, isweep. We determined experimentally that the smallest and largest current from our VMM before the solution converged which was used as the lower and upper bound for isweep.
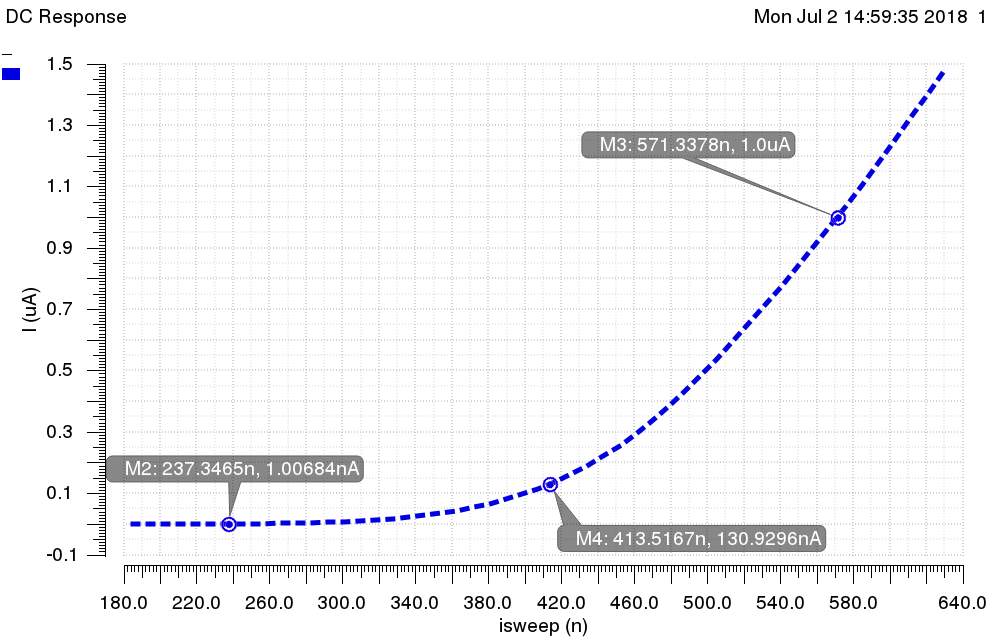
Fig. 8. Multiplier Tree Simulation
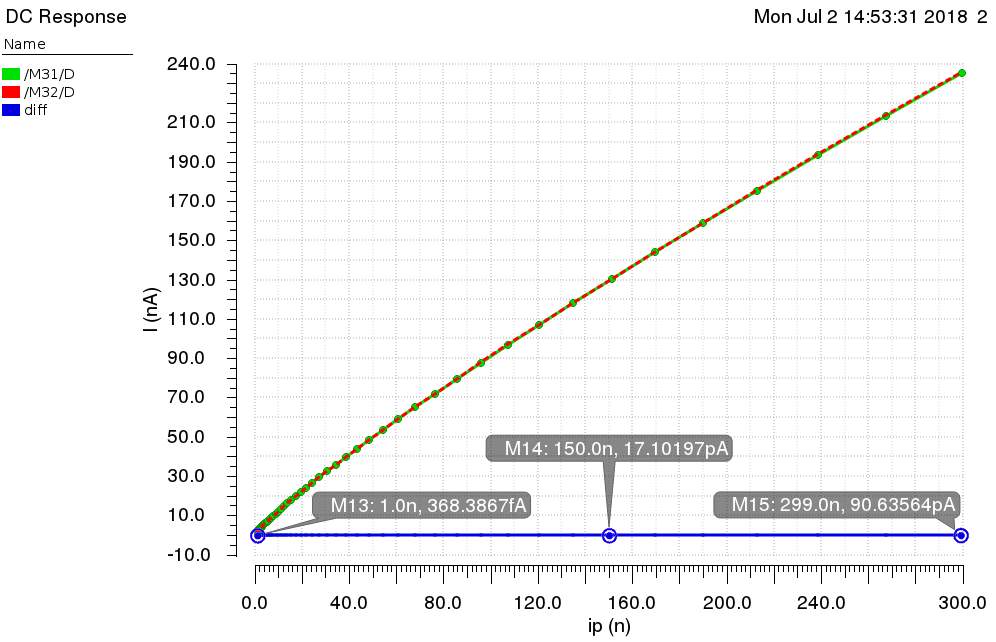
Fig. 9. Current Mirror Simulation
Current Mirror. A current mirror is used to change the direction of current flow to a circuit, as well as duplicate the current. The mirror performs better when it operates in subthreshold, so the mirror is cascoded, reducing gate voltage of each transistor. Fig. 9 Fig. 10 is a simulation of the current mirror; the green M2 is input, red M31 is output, and blue diff is the difference.
Normalization. The result from the multiplier tree is normalized so that the sum of the values corresponds one. The output of the normalization circuit is the new probabilities for all the possible values of the node. A subthreshold multiplier is used for each normalization, with a copy of the sum being divided, result from a multiplication tree being multiplied, and Imax being the other multiplied current.
I4=I1I2I3 thus for αk: I1=Zk, I2=Imax, I3=∑j=1KZi(j)
(10)
In the circuit implementation, the Imax multiplication to map the probability to current is split across two operations with
Imaxa×Imaxb=Imax, which reduces the error. Recall from simulations in Fig. 7 Fig. 8, that larger ratio decreases the accuracy of the multiplication result; splitting the multiplication keeps the ratio closer to 1. The multiplier tree block outputs two copies of the multiplication result. The circuit sums one copy of the result from each multiplication tree using KCL and multipliers copy the sum to distribute to the normalizing multiplier. The copy of the sum is done with a multiplier to add in adjustability to correct for the analog non-ideality, as well as divide by Imaxa. Each normalization is computed with a subthreshold multiplier with
Zk×Imaxb/(sum(Z)/Imaxa)
Simulation of the normalization is plotted in Fig. 10 Fig. 11 on the left, and ideal result is plotted on the right. One of the numerator current is fixed at Imaxb, the other is Ip, and the denominator is Iscale. The simulation shows that the multiplier output is inaccurate when Iscale is low, esp. when Ip is high. This supports our observation made in multiplication that the circuit is accurate when the current multiplied with ratio between other two current is close to one. Overall, the normalizer is less accurate than multiplication.
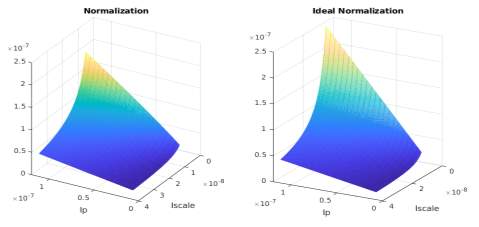
Fig. 10 Normalization Output Current Simulation Ic fixed
Scalability. The number of transistors required for each of the components in the architecture is shown in Table 1. The total number of transistors per node is given by:
EM2×4T+E-1+floorE2M×4T+M×8T+EM×8T+floorE-12M×6T (11)
Where T strands for transistors, E is number of edges, since we assume a fully connected graph, E=N-1, and K is the alphabet size. The architecture scales linearly with respect to number of nodes, which corresponds to variables.
Table 1 Transistors per Circuit
| Function | # Transistors |
| Multiply | 4 |
| Multiply with mirror (VMM) | 8 |
| Current Mirror (Multiplier tree) | 6 |
| Add (current) | 0 |
| Normalization | 8 |
Mixed Signal
The mixed signal uses the same VMM block for the matrix multiplication. The range for the multiplication tree is much larger than the matrix multiplication since matrix multiplication multiply two values and add, whereas multiplier tree need multiply all the inputs together. The larger range and the cascading of multiplier units increases the inaccuracy of the subthreshold multiply cell. The mixed signal approach converts the current into the digital domain and uses a look up table to correct for inaccuracies.
ADC. A successive approximation register (SAR) ADC with 10 bit precision converts the analog signal to digital. We follow the design of ADC in [5], but in 65nm. The SAR style of ADC starts from the MSB of the digital value. The digital output which is transformed back into analog and compared with the sampled input analog using a track and hold. The result of the comparison can be used to update the bit, and moves on to the next most significant bit. The DAC is an R-2R style DAC which is the same type used to convert the LUT result back into analog. Since it is the same, we present details of DAC in later section. The comparator is a dynamic design which compares the values on the edge of a clock input.
RAM. A look up table (LUT) corrects analog multiply and computes the normalization. The memory is a 128 address SRAM with 10-bit words. The signals for the SRAM are shown in Table 2 Table 1. The memory cell is a standard 6T memory cell, which is two cross coupled inverters with two access transistors [11]. The access transistors and transmission gate select the cells to be read/written to, with the control signal from the row and column decoders. The sense amplifier is a differential op amp that reads the value of the cells in read mode. The write driver, write enable buffer, and data buffer are used in write operations.
| Port | Type | pins | description |
| Clk | Input | 1 | Clock, active high |
| Addr | Input | 7 | 7-bit address |
| Din | Input | 10 | 10-bit word, input data |
| Dout | Output | 10 | 10-bit output data |
| RW | Input | 1 | Read=0/write=1 |
| En | Input | 1 | Enable when 1 |
| VDD, GND | Power | 2 | Power and ground |
DAC. The DAC is an R-2R style and block diagram is shown in Fig. 11 Fig. 12. The R-2R resistance ladder follows the current splitting principle, where at each junction, the current is split in half. The branch in the deepest of the ladder has the least current, and we can see two resistances with resistance 2R in parallel which is equivalent to R. The current in each branch is equal, and these are in series with a resistance of R. Now this equivalent resistance of 2R placed in parallel with another resistance with 2R, so that the current in these branches are twice the current in the previous 2R parallel. By continuing this configuration, the ladder divides the current in half every time there is a new branch. The resistances are implemented with MOS transistors. Recall that the current though MOS transistor is always proportional to the W/L ratio, so resistances can be implemented with 2W/L and W/L transistors as described in [8]. The current mirror proposed by Prodanov et. al. [12] requires less input and output voltage headroom compared to the traditional design.

Experimental Setup
The possible configurations for the nodes and C matrices were generated using MATLAB. The C Matrix is determined by the mapping of problem to the graph, though the rows and column represent likelihoods of neighbors so the column and row sum to 1. First, we generate C matrix with three probabilities that represent low, medium and high arbitrarily chosen as 0.2, 0.45 and 0.8. The first simulation we implement the message passage algorithm using MATLAB, storing the new probabilities every iteration. Next, we generated ten random C matrices test cases for each desired configuration and simulated for 4 iterations in the MATLAB script.
We implement analog architecture using TSMC 65nm technology using Cadence Virtuoso EDA tools with ten nodes and alphabet size of three. The system was built using the subthreshold multiplier as building block described in Sections???. The area of our preliminary layout is less than 1mm2. We run multiple Spectre simulations in Cadence using OCEAN scripts simulating iterations of the 10-node system. The initial probability is assumed all alphabet are equally likely except one node we assume a priori knowledge of the correct answer, which the probability for correct is 50%, and other two are 25%. In this node, the probability is pinned to always be the same in every iteration. The inputs are simulated as ideal current sources. We record the steady state value at the output of the node, which is the new probability message, except for the pinned node which is fixed at the initial probability. The simulation is run again with new message as input probability and theoretically should be repeated until the output reaches decision boundaries. We found through experimentation that the circuit simulation converged between 3-6 iterations, so we ran the simulations for at least 6 iterations.
Results
Analog Implementation and Discussion . First, we simulate the message passing arithmetic in MATLAB shown in Fig. 13 for the configuration 1222213121, where the alphas are {1,2,3}. There is a graph for each node, with three lines plotting the probability of each α. Node 1 is pinned so its probability is the same, and pinning the node also causes faster convergence. We compare the resulting probability from simulation, with highest probability being the decided alphabet, to the desired configuration of alphabet in each node to determine if the systems solved the graph correctly. For ideal MATLAB simulation with no noise, the MP reached correct decision in all configurations. The MATLAB simulations of message passing started to converge within 2 iterations. For the ten node system, there are
310=59049 possible configurations, and we simulate the 10 randomly generated C Matrices. The Spectre circuit simulator takes roughly 5 minutes to simulate finish simulations for one test case. It is infeasible to simulate all test cases for all the possible configurations. We arbitrarily chose 80 configurations and simulated with all ten test cases per configuration, and they all converged to the correct answer. That is, the correct α for each node had the highest probability by the end of the iterations with P>90nA (recall 100nA is mapped to 1). Fig. 15 plots analog architecture probabilities converging in 10 iterations for configuration 1222213121.
Another perceptive to view the MP algorithm processes the present likelihoods of all nodes and separate them in the next iteration., separating the probability meaning the ratio between the most likely and the next most likely. When the probabilities are very far apart, or when the ratio is large (e.g. P(α1)>>P(α2)), we can make a decision since we know one is much more likely than the other. Conversely, if the likelihoods are close together, then we know with less certainty, and so decisions made may not be correct. Fig. 16 graphs the distribution of values at output of the modules in the architecture as a histogram though three iterations of the MP. The stages of the multiplier tree refer to the level of the multiplier arrange in a tree as described in Section 3. The values in the earlier iterations are closer together, in the middle of the range, and as iteration increases, the values spread out. Thus, we see that initially, the values fall in the decision region, and gradually become more or less certain, until they reach regions with high certainty mentioned in Fig. 2 Fig. 1.
Since the operations in the message passing arithmetic are applied to all the probability messages, we see that the intermediate values are separated along with the new probability message. The decision region for message passing thus corresponds to the middle region of the range shown in Fig. 16. In this region, the probabilities for the possible αk have not all reached the threshold. In this region, the accuracy is critical because inaccurate computation may flip which α is the most likely, and cascade through the iterations of the message passing to result in the wrong decision. We design our circuits so that they are accurate in the decision region. To control where the circuit is accurate, we adjust scaling and the free parameter in our multiply unit. Scaling the transistor W/L allows us to control the region here transistors operate so that decision region in our algorithm coincides with the linear region. Recall in Eq. 8 that the subthreshold multiplier output is I4 = I1I2/I3, so regardless if the unit implements a multiplication or division, there is a free parameter we use to adjust the magnitude of the current. This parameter must be the same for the arithmetic regardless of which node the message is from to maintain the ratio or relative order probabilities. For example, the denominator I4 in the VMM multipliers are all the same and the denominator in first stage of multiplication tree where results from two VMMs are multiplied are the same, but different from VMM.
The consequence of the scaling can be seen by comparing Fig. 15 and Fig. 16. The first two iterations in Fig. 15 closely match the ideal MATLAB simulations. We can confirm in Fig. 16, that the values are close together, in the first two iterations which was designed to be in our accurate region. By the third iteration, the values have separated and are farther apart, with all the initial probabilities in regions 0-20nA and 80-100nA. This causes all the intermediate calculations during new probability to be separated even more since operations are mostly multiplication and addition. The range of current values, especially for multiplication tree, grows such that the leave the accurate region of the circuit. For example, in the last stage of the multiplier tree in the third iteration, the current ranged from 1.8uA to 5.8nA. However, we design the circuit to be accurate in decision region where the probabilities and intermediate values are close together, so as values leave the decision region and are less accurate, the closer the values are to reaching the decision boundaries. We design the circuit with high accuracy in the calculations where we have less confidence (probabilities are close) and is less accuracy when we are reaching a decision.
Power Consumption. Using the results of circuit simulation, we calculate the power consumption of the ten node circuit. The maximum power consumption is 980µW which corresponds to the last iteration. Since the later iterations the currents have converged, we compute the average power consumption for first four iterations where the decision made which is 855.5µW.
To extrapolate the power consumption from our experiment to graphs with N nodes, we use Eq. 11 to calculate power per transistor. The average power per transistor is 109.7 nW and maximum power per transistor is 125.6 nW. The advantage of subthreshold analog design is that operating currents are reduced as shown in, leading to lower power consumption. Our implementation operates in near-threshold region where there is moderate inversion. To achieve the goal of low power, a direction for future work is to push our architecture into the weak inversion region. For the current design in moderate inversion, extrapolating to N=106 nodes, the average power consumption is 9.4GW which is comparable to digital CPU at 14nm. Scaling the subthreshold architecture to 14nm would reduce the power consumption further. Table 3 presents average power after extrapolating to million nodes, weak subthreshold, and 14nm process.
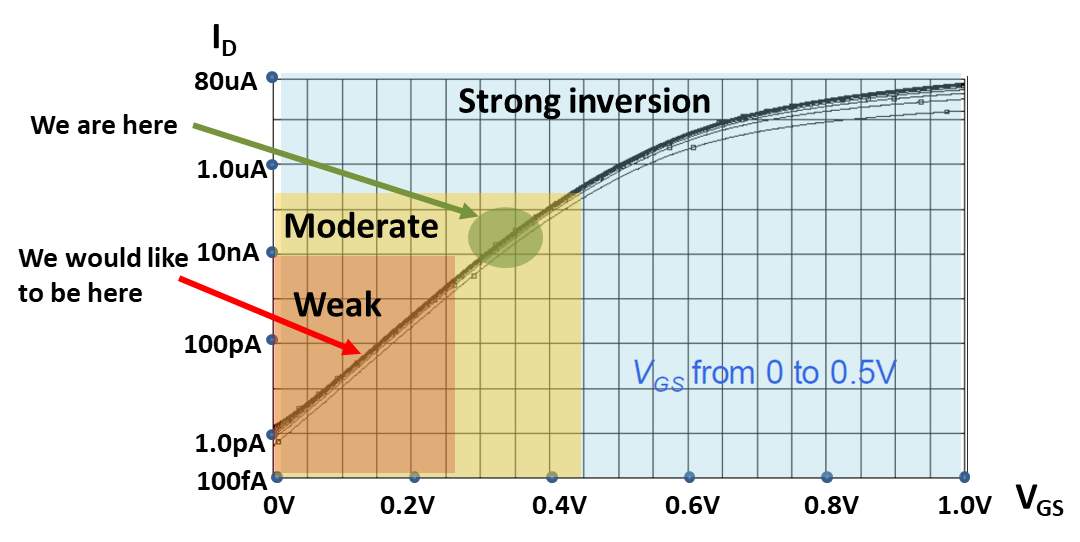
Fig. 12 Transistor Regions Operation
Area . Using the results of circuit simulation, we calculate the power consumption of the ten node circuit. The total area for ten node circuit not including IO pads and loading circuity is
1.6×10-3cm2. For extrapolating results, we measure that our layout for a multiplier cell is
2.3×10-7cm2 and current mirror is
8×10-8cm2. We present equations for number of multipliers and current mirrors per node, assuming normalization has same area as two multipliers. Eq. 12 describes number of multipliers per node and Eq. 13 describes number of current mirrors per node as a function of E edges and alphabet size M. Using the size of multipliers and current mirrors with Eq. 12 and Eq. 13 can compute a lower bound estimate for chip area, extrapolating to larger number of nodes. This estimate is lower than measured area for 10 nodes since additional space is needed to route connection of signals. Table 3 shows extrapolation of area for larger number nodes, weak inversion design, and scale down to14nm.
EM2+E-1+floorE2M+2M+EM
(12)
EM+floorE-12M
(13)
Table 3 Power and Area with Extrapolation
| Multiplication | Current Mirror | Single Node | All Nodes (total) | |
| Average Power | 570nW | 219nW | 85.5 µW | 855µW |
| Raw Area | 2.3×10-7cm2 | 8×10-8cm2 | 1.6
×10-4cm2 |
1.6
×10-3cm2 |
| Extrapolate to 106 Nodes Power | 570nW | 219nW | 9.54W | 9.54GW |
| Extrapolate to 106 Nodes Area | 2.3×10-7cm2 | 8×10-8cm2 | 4.16cm2 | 4.16×106cm2
=415m2 |
| Extrapolate to Weak Inversion 106 Nodes Power | 0.57nW | 0.22nW | 9.54mW | 9.54MW |
| Extrapolate to Weak Inversion 106 Nodes Area | 4.6×10-8cm2 | 1.6×10-8cm2 | 0.832 cm2 | 83 m2 |
| Extrapolate Weak inversion and 14nm Process Power | 0.57pW | 0.22pW | 9.54µW | 9.54kW |
| Extrapolate 14nm Area | 2×10-10cm2 | 1×10-10cm2 | 3.75×10-3 cm2 | 3750cm2 |
Mixed Signal. The mixed signal simulation was done with MATLAB. We extract the analog circuit behavior of the multipliers to create a look up table in MATLAB. MATLAB simulates the ADC, RAM, and DAC assuming ideal conditions, with the same generated C Matrix as previous simulation. The results are shown in Fig. 14 MATLAB Simulation of Mixed Signal Implementation graphed in the same manner as previous graphs. Compared to the all analog implementation, the final probability nodes converge to is 100nA, thus the mixed signal has a more accurate normalization under all ranges of current. This is expected, since typically digital calculations will have more precision, as analog has inherent issues with non-linearity and random noise.
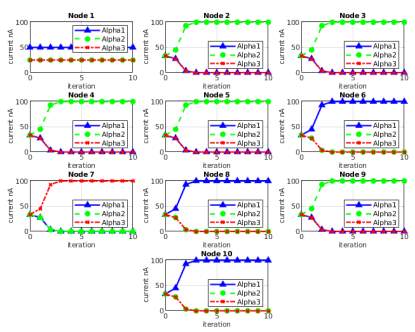
Fig. 13 MATLAB Ideal Simulation of MP algorithm
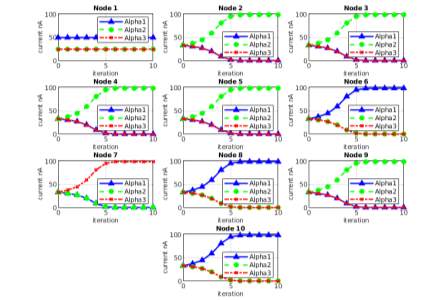
Fig. 14 MATLAB Simulation of Mixed Signal Implementation
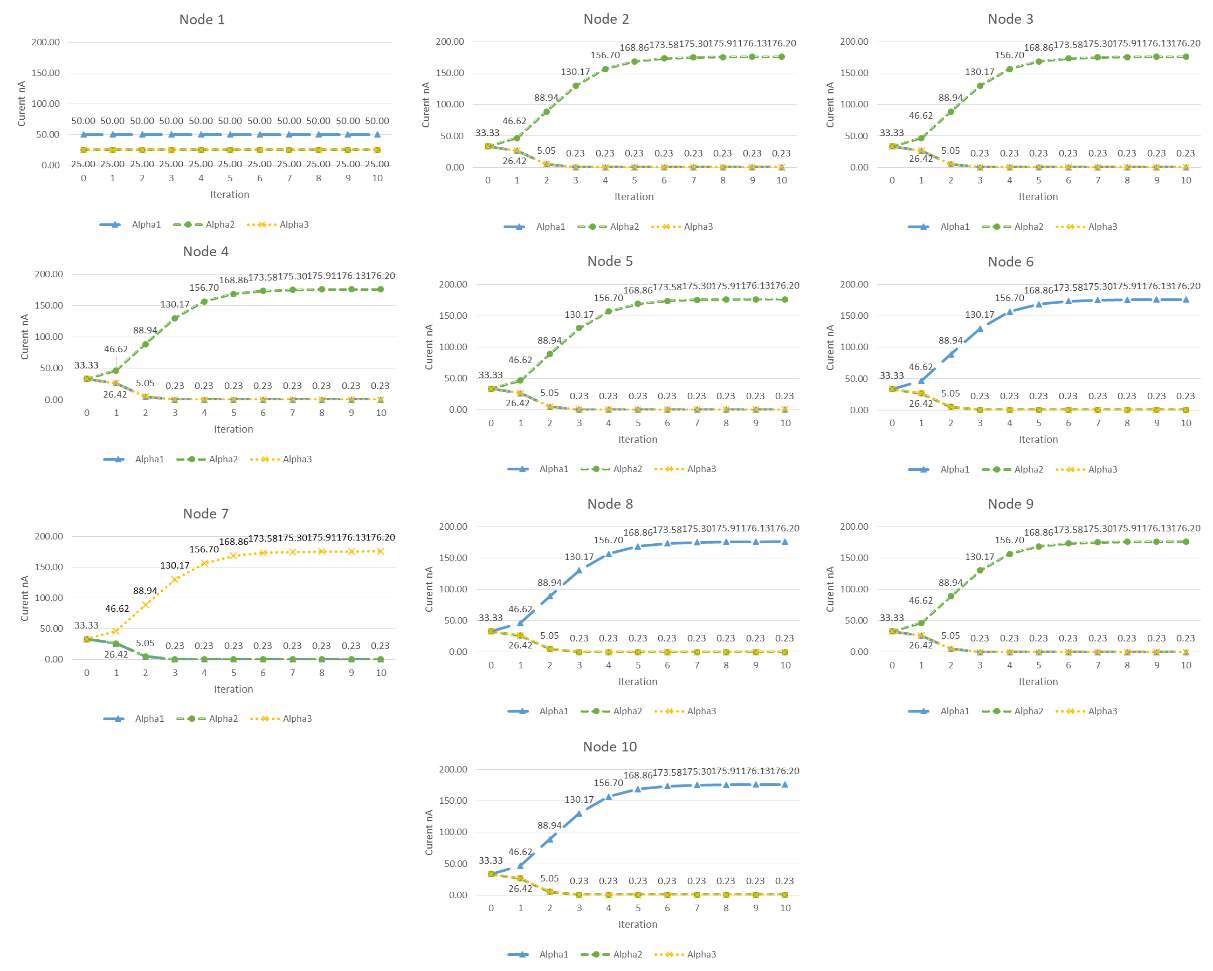
Fig. 15. Simulation of Analog Architecture for MP
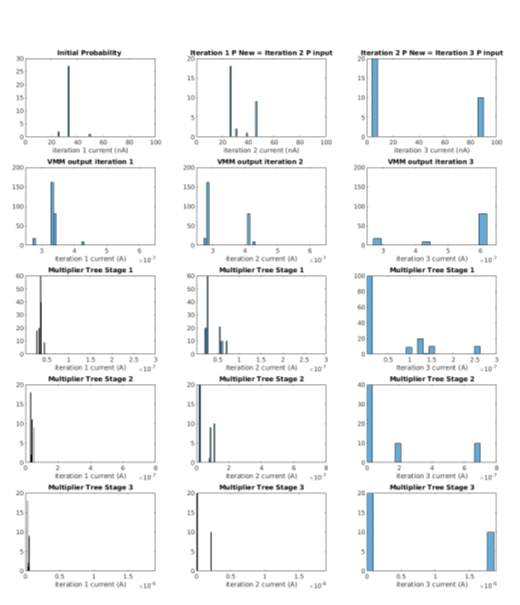
Fig. 16 Distribution of Values in All Analog Implementation of MP Arithmetic
Conclusion
We proposed two low power architectures for MP using subthreshold circuits. Circuit simulations show our implementation of the architecture are promising in terms of accuracy. We found two design choices that were critical for MP arithmetic to reach the correct decision. First, the relative likelihoods between messages passed are sufficient for the MP to converge. Though there is significant error due to the analog computation in subthreshold, the operations applied to the different probabilities in the message are the same, thus have similar non-ideality so we can minimize the error in relative probabilities. Second, we need to take into account that the most important region for correct decision is the decision region where the probabilities are close together. In this region, it takes less absolute error to change the relative likelihood more. Therefore, the circuits in all modules of the architecture should be in the middle of the linear region so that they are most accurate, when the probabilities are in the decision region.
For future work, we aim to answer the following questions. Is there a general formulation of noise margin at each iteration of the MP that the system can take? We observe that the values in the iterations vary slightly as C Matrix and node configuration change, so the amount of noise needed to change the final outcome appears variable. Next, what is the period T, needed between iterations. Currently, we wait 1ms for the circuit to reach steady state value; however, we can speed up the algorithm by reducing the period. Understanding of the noise margin would allow trade off speed for accuracy, as we could pass messages when it reaches a threshold near the steady state value.
References
[1] Andreas G. Andreou, 1999. Exploiting device physics in circuit design for efficient computational functions in analog VLSI. In: Low-Voltage/Low-Power Integrated Circuits and Systems (1999), 85-132.
[2] Andreas G. Andreou, et. al. 1991 Current-mode subthreshold MOS circuits for analog VLSI neural systems. IEEE Transactions on Neural Networks. Vol 2, no 2. (Mar 1991), 205-213
[4] Shen F. Hsiao, Jun M. Huang, and Po S. Wu. 2014. VLSI implementation of belief-propagation-based stereo matching with linear-model message update.2014 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), 73-76. DOI: 10.1109/APCCAS.2014.7032722
[5] Ryan Hunt. 2014. Low Voltage CMOS SAR ADC Design. Retrieved June 29, 2018 from http://digitalcommons.calpoly.edu/eesp/246/
[6] Frank R. Kschischang, Brendan J. Frey, and Hans A. Loeliger. 2001. Factor graphs and the sum-product algorithm. IEEE Transactions on Information Theory, vol. 47, no. 2 (Feb 2001), 498-519. DOI: 10.1109/18.910572
[7] Chia K. Liang, et al. 2011. Hardware-Efficient Belief Propagation. IEEE Trans. on Circuits and System for Video Technology, vol.21, no. 5 (May 2011), 525-537. DOI: 10.1109/TCSVT.2011.2125570
[8] Bernabé Linares-Barranco, Teresa Serrano-Gotarrendona, and Rafael Serrano-Gotarrendona. 2003. Compact Low-Power Calibration Mini-DACs for Neural Arrays With Programmable Weights. IEEE Transactions on Neural Networks, vol 14, no. 5 (Sept. 2003), 1207 – 1216. DOI: 10.1109/TNN.2003.816370
[9] Mohammad M. Mansour and Naresh R. Shanbhag. 2002. Low-power VLSI decoder architectures for LDPC codes. Proceedings of the 2002 international symposium on Low power electronics and design (ISLPED ’02). ACM, 284-289. DOI: https://doi.org/10.1145/566408.566483
[10] Carver Mead. 1989. Analog VLSI and Neural Systems. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA.
[11] Andrei Pavlov and Manoj Snchdev. 2008. SRAM Circuit Design and Operation. In: CMOS SRAM Design and Parametric Test in Nano-Scaled Technologies. Frontiers in Electronic Testing, vol 40. Springer, Dordrech
[12] V. I. Prodanov and M. M. Green, CMOS current mirrors with reduced input and output voltage requirements, 1995. Electronics Letters, vol. 32, no. 2 (18 Jan 1996) , 104-105
DOI: 10.1049/el:19960076
[13] Erik B. Sudderth and William T. Freeman. 2008. Signal and Image Processing with Belief Propagation. IEEE Signal Processing Magazine, vol. 25, 114-141. DOI: 10.1109/MSP.2007.914235
[14] Jian Sun, Nan-Ning Zheng and Heung-Yeung Shum. 2003. Stereo matching using belief propagation. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 25, no. 7, 787-800. DOI: 10.1109/TPAMI.2003.1206509
[15] Nana Traore, Shashi Kant and Tobias Lindstrm Jensen. 2007. Message Passing Algorithm and Linear Programming Decoding for LDPC and Linear Block Codes. Institute of Electronic Systems Signal and Information Processing in Communications, Aalborg University.
[16] Jonathan S. Yedidia. 2011. Message-Passing Algorithms for Inference and Optimization. Journal of Stat. Phys, vol. 145 (November 2011), 860-890. DOI: https://link.springer.com/article/10.1007/s10955-011-0384-7
[17] Jonathan S. Yedidia, William T. Freeman, and Yair Weiss. 2000. Bethe Free Energy, Kikuchi Approximations, and Belief Propagation Algorithms. MERL T.R., 20.
[18] Jonathan S. Yedidia, William T. Freeman, and Yair Weiss. 2003. Understanding Belief Propagation and Its Generalizations. Exploring Artificial Intelligence in the New Millennium, Lakemeyer, G. and Nebel, B. (Eds.), Morgan Kaufmann Publishers (January 2003), 239-269.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Engineering"
Engineering is the application of scientific principles and mathematics to designing and building of structures, such as bridges or buildings, roads, machines etc. and includes a range of specialised fields.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: