DiploCloud: Efficient and Scalable Management of RDF data in the Cloud
Info: 15246 words (61 pages) Dissertation
Published: 10th Dec 2019
Tagged: Information Systems
ABSTRACT
AIM:
The main aim of the project is to design a cloud in which we can deploy the management of RDF data into the cloud efficiently and easily.
INTRODUCTION:
Despite recent advances in distributed RDF data management, processing large-amounts of RDF data in the cloud is still very challenging. In spite of its seemingly simple data model, RDF actually encodes rich and complex graphs mixing both instance and schema-level data. Sharing such data using classical techniques or partitioning the graph using traditional min-cut algorithms leads to very inefficient distributed operations and to a high number of joins. In this paper, we describe DiploCloud, an efficient and scalable distributed RDF data management system for the cloud. Contrary to previous approaches, DiploCloud runs a physiological analysis of both instance and schema information prior to partitioning the data. In this paper, we describe the architecture of DiploCloud, its main data structures, as well as the new algorithms we use to partition and distribute data.
We also present an extensive evaluation of DiploCloud showing that our system is often two orders of magnitude faster than state-of-the-art systems on standard workloads.
(v)
INTRODUCTION
The advent of cloud computing enables to easily and cheaply provision computing resources, for example to test a new application or to scale a current software installation elastically. The complexity of scaling out an application in the cloud (i.e., adding new computing nodes to accommodate the growth of some process) very much depends on the process to be scaled. Often, the task at hand can be easily split into a large series of subtasks to be run independently and concurrently. Such operations are commonly called embarrassingly parallel. Embarrassingly parallel problems can be relatively easily scaled out in the cloud by launching new processes on new commodity machines. There are however many processes that are much more difficult to parallelize, typically because they consist of sequential processes (e.g., processes based on numerical methods such as Newton’s method). Such processes are called inherently sequential as their running time cannot be sped up significantly regardless of the number of processors or machines used. Some problems, finally, are not inherently sequential per se but are difficult to parallelize in practice because of the profusion of inter-process traffic they generate.
The critical situation is that to find a necessary data from a huge content.
The query plans to reorder operations and use distributed versions of the Problem statement. The complexity of scaling out an application in the cloud very much depends on the process to be scaled. Often, the task at hand can be easily split into a large series of subtasks to be run independently and concurrently. Here we are using RDBMS which is not flexible and we cannot alter the table architecture at run time once the particular structure is fixed.
- SCOPE AND OBJECTIVE OF THE PROJECT:
We propose DiploCloud, an efficient, distributed and scalable RDF data processing system for distributed and cloud environments. Our storage system in DiploCloud can be seen as a hybrid structure extending several of the ideas from above. Our system is built on three main structures: RDF molecule clusters (which can be seen as hybrid structures borrowing both from property tables and RDF subgraphs), template lists (storing literals in compact lists as in a column-oriented database system) and an efficient key index indexing URIs and literals based on the clusters they belong to.
- EXISTING SYSTEM:
The complexity of scaling out an application in the cloud very much depends on the process to be scaled. Often, the task at hand can be easily split into a large series of subtasks to be run independently and concurrently. Here we are using RDBMS which is not flexible and we cannot alter the table architecture at run time once the particular structure is fixed.
The disadvantages of the existing system is that:
- Difficult to parallelize in practice.
- A traditional algorithm leads to very inefficient distributed operations and to a high number of joins.
- PROPOSED SYSTEM:
We propose DiploCloud, an efficient, distributed and scalable RDF data processing system for distributed and cloud environments. Our storage system in DiploCloud can be seen as a hybrid structure extending several of the ideas from above. Our system is built on three main structures: RDF molecule clusters (which can be seen as hybrid structures borrowing both from property tables and RDF subgraphs), template lists (storing literals in compact lists as in a column-oriented database system) and an efficient key index indexing URIs and literals based on the clusters they belong to.
CHAPTER – 2
LITERATURE SURVEY
2.1 Survey on TripleProv: Efficient Processing of Lineage Queries in a Native RDF Store
Abstract:
Resource Description Framework (RDF) is an initially composed metadata information display. RDF has come to be utilized as a general strategy for applied depiction or displaying of data that is executed in web asset. Preferred standpoint of RDF model is comprised of triple. The essential RDF model can be handled even without more detail data on the semantics. In the current framework database recovery process is substantial weighted and tedious data should be tended to by RDF based. Inquiry handling from RDF compare to idea of the essential chart design. Each inquiry speak to in a diagram design comprise of set of triple example. Coordinating an inquiry chart is upheld by different RDF stores. While proficiency of recovery information rely on upon physical information association ordering. Here we reason a framework for effectiveness and adaptable dispersion method called ace RDF information administration framework (MRDF).constructing the file can be utilized as pseudo Schema for questioning and perusing semi organized RDF information on web. All RDF are joined in ace RDF information for productivity and adaptable conveyed RDF information administration framework.
The heterogeneity of the information consolidated with the capacity to effortlessly incorporate it—utilizing benchmarks, for example, RDF and SPARQL—imply that following back the provenance (or genealogy) of inquiry results ends up plainly basic, e.g., to comprehend which sources were instrumental in giving outcomes, how information sources were joined, to approve or refute comes about, and to dive further into information identified with the outcomes recovered. Inside the Web people group, there have been a few endeavors in creating models and punctuations to trade provenance, which brought about the current W3C PROV proposal. In any case, less consideration has been given to the effective treatment of provenance information inside RDF database frameworks. While a few frameworks store quadruples or named diagrams, to the best of our insight, no present elite triple store can naturally infer provenance information for the outcomes it produces. We plan to fill this crevice. In the accompanying, we introduce TripleProv, another database framework supporting the straightforward and programmed induction of nitty gritty provenance data for discretionary inquiries. TripleProv depends on a local RDF store, which we have reached out with two diverse physical models to store provenance information on circle in a reduced manner. Likewise, TripleProv bolsters a few new question execution methodologies to infer provenance data at two unique levels of granularity.
Given the heterogeneity of the information one can discover on the Linked Data cloud, having the capacity to follow back the provenance of inquiry results is quickly turning into an unquestionable requirement have highlight of RDF frameworks. While provenance models have been widely talked about as of late, little consideration has been given to the productive execution of provenance-empowered inquiries inside information stores. This paper presents TripleProv: another framework extending a local RDF store to proficiently deal with such questions. TripleProv executes two distinctive stockpiling models to physically co-find ancestry and occurrence information, and for each of them actualizes calculations for following provenance at two granularity levels. In the accompanying, we show the general engineering of our framework, its distinctive ancestry stockpiling models, and the different question execution methodologies we have actualized to productively answer provenance-empowered inquiries. Furthermore, we exhibit the aftereffects of a far reaching exact assessment of our framework more than two distinctive datasets and workloads.
Conclusions:
In this paper, we portrayed TripleProv,an open-source and proficient framework for overseeing RDF information while additionally following provenance. To the best of our insight, this is the main work that deciphers hypothetical bits of knowledge from the database provenance writing into a superior triple store. TripleProv not just executes straightforward following of hotspots for inquiry answers, additionally considers fine-grained multilevel provenance. In this paper, we actualized two conceivable stockpiling models for supporting provenance in RDF information administration frameworks. Our exploratory assessment demonstrates that the overhead of provenance, despite the fact that significant, is worthy for the subsequent arrangement of a nitty gritty provenance follow. We take note of that both our question calculations and capacity models can be reused by different databases with just little adjustments. As we coordinate a bunch of datasets from the Web, provenance turns into a basic angle in discovering trust and building up straightforwardness. TripleProv gives the framework expected to uncovering and working with fine-grained provenance in RDF-based situations. We plan to keep creating TripleProv in a few bearings. In the first place, we plan to stretch out provenance support to the dispersed variant of our database framework. Additionally, we plan to amplify TripleProv with a dynamic stockpiling model to empower advance improvement between memory utilization and inquiry execution times. We additionally would like to cut down the general cost of following provenance inside the framework. As far as provenance, we plan to stretch out TripleProv to yield PROV, which would open the way to questions over the provenance of the inquiry comes about and the information itself – blending both inward and outside provenance. Such an approach would encourage trust calculations over provenance that consider the historical backdrop of the first information and in addition how it was prepared inside the database. Also, we expect to take into consideration versatile inquiry execution systems in view of provenance. For instance, executing a question that would just consider an arrangement of especially trusted information sources.
2.2 Survey on A survey of RDF store solutions
Abstract:
This paper dissects the capability of Semantic Web advances to bolster development in modern situations. The review concentrates specifically on RDF stores, the product segments committed to the capacity, portrayal and recovery of semantic data. Beginning from a writing survey, a subjective examination is completed considering an arrangement of these frameworks. RDF stores are assessed to discover the usage that are most appropriate to assume the part of spine in a product design sharing data between the product devices received by the different partners. This can be accomplished if the design conquers the issues getting from the absence of mix between the included programming applications, giving along these lines a coordinated view on pertinent building learning.
The brought together capacity approach contains triple-stores in view of social database administration frameworks, lattice, XML, and chart. Sakr and Al-Naymat arranged triple-stores in view of social database administration frameworks into three classifications: a) vertical (triple) table stores, b) property (n-ary) table stores, and c) even (parallel) table stores. This arrangement plan is additionally clarified in the above instructional exercises. The center grouping structure presented in these papers is practically the same.
Each review paper gives a characterization structure that arranges look into endeavors so far by concentrating on the recognizing parts of inquires about. These study papers give valuable bits of knowledge and points of view about segment innovations of RDF stockpiling directors. Notwithstanding, most research execute model or pragmatic frameworks that are outfitted with mixes of helpful innovations. It will be helpful for specialists intrigued by RDF stockpiling supervisor executions to give another kind of arrangements that gives a few credits to each examination framework. The commitments of this paper can be condensed as takes after: Provides methodical grouping of RDF stockpiling administrator executions. Effectively distinguishes contrasts between given RDF stockpiling administrator usage. Get traits concerning successful procedures by multi-handle conditions. There are Internet pages that group RDF stockpiling administrators.
A Wikipedia page gives the most exhaustive rundown of RDF stockpiling directors (triple stores) with permit and API work data. The W3C page gives benchmark consequences of RDF stockpiling administrators for putting away substantial scale RDF informational indexes. While this paper gives inside utilitarian data, those Internet pages may give a valuable point of view of RDF stockpiling directors by joining data. Whatever is left of this paper is sorted out as takes after. The Classification of RDF Storage Managers Based on Local Cache Approach area presents an arrangement system of RDF stockpiling administrators. The RDF stockpiling administrators segment reports every normal for existing RDF stockpiling directors utilizing the order structure.
Conclusions:
Thus of this review one might say that different executions of RDF store are reasonable to be utilized as spine of semantic applications that need to store and process vast measure of RDF information in a protected and dependable way. Besides, a large portion of them more often than not offer help for basic components, for example, the ability to ensure information insurance, data protection and security. Be that as it may, most of the overviewed RDF stores don’t yet bolster forming and dealing with gushing information in a compelling way. As from a capable mechanical point of view they exemplify basic components, their need is a critical hole speaking to the most squeezing innovative boundary that analysts and experts need to overcome in the following future. Some key qualities of a RDF store have not been considered in this study. A standout amongst the most essential is the support to induction, i.e. the capacity to get new learning specifically from data officially accessible. This is a pivotal usefulness and hence it has set the target to lead another review considering it as assessment basis, likewise augmenting the arrangement of overviewed innovations. At long last, a quantitative investigation of RDF stores execution has not been done in this review and it will require encourage relative assessments. The point is to face this test in future work, depending on new benchmarks, right now under review.
2.3 Survey on an Analysis of RDF Storage Models and Query Optimization Techniques
Abstract:
The Web gives access to considerable measure of data. Metadata that implies information about information empowers the revelation of such data. At the point when the metadata is adequately utilized, it expands the handiness of the first information/asset and encourages the asset disclosure. Asset Description Framework (RDF) is a reason for dealing with these metadata and is a diagram based, self-depicting information design that speaks to data about online assets. It is important to store the information steadily for some Semantic Web applications that were produced on RDF to perform compelling questions. In light of the trouble of putting away and questioning RDF information, a few stockpiling procedures have been proposed for these undertakings. In this paper, we display the inspirations for utilizing the RDF information demonstrate. A few stockpiling procedures are examined alongside the techniques for enhancing the inquiries for RDF datasets. We show the contrasts between the Relational Database and the XML innovation. Moreover, we determine a portion of the utilization cases for RDF. Our discoveries will reveal insight into the ebb and flow accomplishments in RDF explore by looking at the changed approaches for capacity and advancement proposed up until this point, in this manner distinguishing further research ranges.
The Resource Description Framework (RDF) is a W3C proposal that has quickly picked up prevalence as a mean of communicating and trading semantic metadata, i.e., information that indicates semantic data about information. RDF was initially intended for the portrayal and handling of metadata about remote data sources and characterizes a model for depicting connections among assets as far as particularly distinguished characteristics and qualities. The fundamental building obstruct in RDF is a straightforward tuple show, (subject, predicate, protest), to express unique sorts of information as certainty articulations. The understanding of every announcement is that subject S has property P with esteem O, where S and P are asset URIs and O is either a URI or an exacting quality. In this way, any question from one triple can assume the part of a subject in another triple which adds up to affixing two marked edges in a diagram based structure. In this way, RDF permits a type of reification in which any RDF articulation itself can be the subject or question of a triple. One of the unmistakable preferred standpoint of the RDF information model is its construction free structure in contrast with the substance relationship display where the elements, their credits and connections to different elements are entirely characterized. In RDF, the outline may advance over the time which fits well with the cutting edge thought of information administration, dataspaces, and its compensation as-you-go reasoning. Figure 1 represents a specimen RDF diagram. The SPARQL question dialect is the authority W3C standard for questioning and separating data from RDF diagrams. It speaks to the partner to choose extend join inquiries in the social model. It depends on an effective chart coordinating office, enables restricting factors to segments in the information RDF diagram and backings conjunctions and disjunctions of triple examples. Furthermore, administrators much the same as social joins, unions, left external joins, determinations, and projections can be consolidated to fabricate more expressive questions.
Social database administration frameworks (RDBMSs) have over and over demonstrated that they are exceptionally productive, adaptable and effective in facilitating sorts of information which have in the past not been expected to be put away inside social databases. What’s more, RDBMSs have demonstrated their capacity to deal with inconceivable measures of information productively utilizing intense ordering systems.
Conclusion:
RDF is an information configuration that is guaranteed to be extremely alluring for accomplishing interoperability over the Web. In any case, the test stays to manufacture adaptable frameworks that give effective capacity and inquiry of the RDF information over a broadly circulated system, for example, the Web. From our review, we unmistakably observe that examination in RDF is exceptionally divided tending to various situations. We relate this issue to the absence of genuine cases accessible that actualize RDF on an expansive scale, and along these lines studies are for the most part utilizing speculative information. We have additionally watched that diverse methodologies for putting away and questioning the RDF information have been proposed, each with their own particular advantages and disadvantages. Despite the fact that, benchmarks exist to look at the outcomes, there is no accord among specialists to think about their outcomes on a shared conviction. We discover this a genuine impediment and propose facilitate examination around there. At the point when contrasted with the social model, we trust that RDF is as yet an exceptionally ripe territory of research, particularly with regards to the most ideal approach to store and inquiry the information that should be shared crosswise over various frameworks.
2.4 Survey on RDF-3X: a RISC-style Engine for RDF
Abstract:
RDF is a data representation format for schema-free structured information that is gaining momentum in the context of Semantic-Web corpora, life sciences, and also Web 2.0 platforms. The “pay-as-you-go” nature of RDF and the flexible pattern-matching capabilities of its query language SPARQL entail efficiency and scalability challenges for complex queries including long join paths. This paper presents the RDF-3X engine, an implementation of SPARQL that achieves excellent performance by pursuing a RISC-style architecture with a streamlined architecture and carefully designed, pure data structures and operations. The salient points of RDF-3X are: 1) a generic solution for storing and indexing RDF triples that completely eliminates the need for physical-design tuning, 2) a powerful yet simple query processor that leverages fast merge joins to the largest possible extent, and 3) a query optimizer for choosing optimal join orders using a cost model based on statistical synopses for entire join paths. The performance of RDF-3X, in comparison to the previously best state-of-the-art systems, has been measured on several large-scale datasets with more than 50 million RDF triples and benchmark queries that include pattern matching and long join paths in the underlying data graphs.
RDF is a data model for schema-free structured information that is gaining momentum in the context of Semantic-Web data, life sciences, and also Web 2.0 platforms. The “pay-as-you-go” nature of RDF and the flexible pattern-matching capabilities of its query language SPARQL entail efficiency and scalability challenges for complex queries including long join paths. This paper presents the RDF-3X engine, an implementation of SPARQL that achieves excellent performance by pursuing a RISC-style architecture with streamlined indexing and query processing. The physical design is identical for all RDF-3X databases regardless of their workloads, and completely eliminates the need for index tuning by exhaustive indexes for all permutations of subject-property-object triples and their binary and unary projections. These indexes are highly compressed, and the query processor can aggressively leverage fast merge joins with excellent performance of processor caches. The query optimizer is able to choose optimal join orders even for complex queries, with a cost model that includes statistical synopses for entire join paths. Although RDF-3X is optimized for queries, it also provides good support for efficient online updates by means of a staging architecture: direct updates to the main database indexes are deferred, and instead applied to compact differential indexes which are later merged into the main indexes in a batched manner. Experimental studies with several large-scale datasets with more than 50 million RDF triples and benchmark queries that include pattern matching, many way star-joins, and long path-joins demonstrate that RDF-3X can outperform the previously best alternatives by one or two orders of magnitude.
Conclusion:
This paper has exhibited the RDF-3X motor, a RISC style design for executing SPARQL inquiries over expansive stores of RDF triples. As our analyses have appeared, RDF-3X beats the already best frameworks by an extensive edge. Specifically, it addresses the test of construction free information and, not at all like its rivals, adapts exceptionally well to information that shows expansive assorted qualities of property names. The striking components of RDF-3X that prompt these execution increases are 1) comprehensive however extremely space-proficient triple records that dispose of the requirement for physical-outline tuning, 2) a streamlined execution motor based on quick union joins, 3) a shrewd inquiry analyzer that picks cost-ideal join orderings and can do this effectively notwithstanding for long join ways (including 10 to 20 joins), 4) a selectivity estimator in light of measurements for regular ways that nourishes into the enhancer’s cost demonstrate. Our future work incorporates encourage upgrades of the inquiry streamlining agent (e.g., in light of enchantment sets) and support for RDF look highlights that go past the current SPARQL standard. Along the last lines, one bearing is to permit all the more effective special case designs for whole ways, in the soul of the X Path relative’s hub however for charts instead of trees. Recommendations for expanding SPARQL have been made, yet there is no execution yet. A moment heading is to give positioning of question results, in view of use particular scoring models. This calls for top-k inquiry preparing and postures testing issues for calculations and question improvement. At last, full SPARQL bolster requires some extra data, specifically writing data. We feel this can be incorporated into the word reference, yet deciding the best encoding with respect to runtime execution and pressure rate needs more work.
2.5 Survey on DOGMA: A Disk-Oriented Graph Matching Algorithm for RDF Databases
Abstract:
RDF is an inexorably critical worldview for the portrayal of data on the Web. As RDF databases increment in size to approach countless triples, and as modern chart coordinating questions expressible in dialects like SPARQL turn out to be progressively critical, versatility turns into an issue. To date, there is no chart based ordering technique for RDF information where the file was outlined in a way that makes it plate occupant. There is hence a developing requirement for records that can work effectively when the list itself dwells on plate. In this paper, we initially propose the DOGMA file for quick sub diagram coordinating on plate and after that build up an essential calculation to answer questions over this record. This calculation is then altogether accelerated by means of an enhanced calculation that utilizations effective (however right) pruning techniques when consolidated with two distinct augmentations of the list. We have executed a preparatory framework and tried it against four existing RDF database frameworks created by others. Our tests demonstrate that our calculation performs extremely very much contrasted with these frameworks, with requests of greatness changes for complex diagram inquiries.
RDF is turning into an inexorably imperative worldview for Web information portrayal. As more RDF database frameworks come “on the web” and as RDF gets expanding accentuation from both built up organizations like HP and Oracle, and in addition from a huge number of new companies, the need to store and productively question huge RDF datasets is winding up noticeably progressively critical. Besides, vast parts of inquiry dialects like SPARQL progressively require that inquiries (which might be seen as diagrams) be coordinated against databases (which may likewise be seen as charts) – the arrangement of all conceivable “matches” is returned as the appropriate response
Doctrine, that utilizes ideas from chart hypothesis to proficiently answer inquiries, for example, that appeared previously. Authoritative opinion is tuned for versatility in a few ways. Initially, the file itself can be put away on circle. This is critical. From encounters in social database ordering, when the information is sufficiently substantial to require plate space, the list will be very huge and should be circle occupant too. Creed, is the primary chart based list for RDF that we know about that is particularly intended to live on circle. We characterize the DOGMA information structure and build up a calculation to take a current RDF database and make the DOGMA list for it. We create calculations to answer chart coordinating inquiries expressible in SPARQL (we stress that we don’t assert DOGMA bolsters all SPARQL questions yet). Our first calculation, called DOGMA fundamental, utilizes the list in a basic way. In this way, we give the enhanced calculation DOGMA adv. what’s more, two augmentations of the file called DOGMA ipd and DOGMA epd, that utilization complex pruning strategies to make the hunt more productive without trading off rightness. Third, we demonstrate the aftereffects of a trial appraisal of our methods against four contending RDF database frameworks. We demonstrate that DOGMA performs exceptionally all around contrasted with these frameworks.
Conclusions:
In this paper, we proposed the DOGMA record for quick sub diagram coordinating on circle and created calculations to answer inquiries over this list. The calculations utilize proficient (however right) pruning procedures and can be joined with two distinct augmentations of the file. We tried a preparatory execution of the proposed methods against four existing RDF database frameworks, demonstrating great inquiry noting execution. Future work will be given to an inside and out investigation of the focal points and disservices of each of the proposed lists when managing specific questions and RDF datasets. Besides, we plan to extend our lists to bolster productive updates, likewise attempting to enhance over common list support plans, for example, those in light of a halfway utilization of the space in list hubs.
CHAPTER-3
SOFTWARE REQUIREMENTSSPECIFICATION
3. SOFTWARE REQUIREMENTS SPECIFICATION
3.1 Requirement Analysis
The prerequisites gathering process takes as its information the objectives recognized in the abnormal state necessities area of the venture arrange. Every objective will be refined into an arrangement of at least one necessities. These necessities characterize the real elements of the planned application, characterize operational information ranges and reference information regions, and characterize the underlying information substances. Real capacities incorporate basic procedures to be overseen, and in addition mission basic sources of info, yields and reports.
1. Problem statement
2. Data flow diagrams
3. Use case diagram
4. Other UML diagrams.
The above-mentioned documents gives us diagrammatical view of the system what we are going to develop.
The software requirements for the above-mentioned project are:
Operating System : Windows Family
Technology : Java and J2EE
Web Technologies : Html, JavaScript, CSS
Web Server : Tomcat
Database : My SQL
Java Version : JDK 1.7
3.2 Problem Statement
The problem statement system only requires a semi-trusted third party, responsible for carrying out simple matching operations correctly.
3.3 Functional Requirements
- The application should results from a search engine (Bing).
- The application must have a user friendly interface that stores user details.
- The application must have a view of the listing of links present in Bing by using Jsoup API.
- The application will crawl all internal links particular URL.
- The application ranks the top 10 links by using adaptive learning.
- Search results user can get in accurate.
3.4 Software Requirements Specification
The project is developed in Java Programming Language by using the Eclipse Juno Integrated Development Environment (IDE). We use the Java Development Kit (JDK) which includes a variety of custom tools that help us to develop web applications on the Apache Platform. At the Server side Apache Tomcat Server is used. For Data Storage Purpose we use MySQL as a database server. And we can run our application in Windows and Linux any version.
3.4.1 Purpose
The purpose of this document is to present a detailed description of “Diplo Cloud: Efficient and Scalable Management of RDF Data in the Cloud” application. It will explain the purpose and features of the system that it will provide, constraints under which it must operate and how the system will react. The document also describes the non-functional requirements of the system.
3.4.2 Technologies Used
The developer composes Java source code in a content manager which underpins plain content. Regularly the software engineer utilizes an Integrated Development Environment (IDE) for programming. An IDE underpins the software engineer in the assignment of composing code, e.g. it gives auto-designing of the source code, highlighting of the essential catchphrases, and so forth.
Sooner or later the software engineer (or the IDE) calls the Java compiler (javac). The Java compiler makes the byte code directions. These guidelines are put away in .class records and can be executed by the Java Virtual Machine.
J2SE
J2SE is a gathering of Java Programming Language API (Application programming interface) that is exceptionally valuable to numerous Java stage programs. It is gotten from a standout amongst the most powerful programming dialect known as “JAVA”
J2SE is a gathering of Java Programming Language API (Application programming interface) that is exceptionally valuable to numerous Java stage programs. It is gotten from a standout amongst the most powerful programming dialect known as “JAVA” and one of its three essential versions of Java known as Java standard release being utilized for composing Applets and other online applications.
J2SE stage has been created under the Java umbrella and principally utilized for composing applets and other Java-based applications. It is for the most part utilized for individual PCs. Applet is a sort of quick working subroutine of Java that is stage free yet work inside different structures. It is a smaller than usual application that play out an assortment of capacities, extensive and little, conventional and dynamic, inside the system of bigger applications.
J2SE give the office to clients to see Flash motion pictures or hear sound records by tapping on a Web page connect. As the client clicks, page goes into the program condition and start the way toward propelling application-inside an-application to play the asked for video or sound application. Such a variety of internet diversions are being produced on J2SE. JavaBeans can likewise be created by utilizing J2SE.
J2EE
Java 2 Platform Enterprise Edition. J2EE is a platform-independent, Java-centric environment from Sun for developing, building and deploying Web-based enterprise applications online. The J2EE platform consists of a set of services, APIs, and protocols that provide the functionality for developing multitier, Web-based applications.
Key features and services of J2EE:
- At the client tier, J2EE supports pure HTML, as well as Java applets or applications. It relies on Java Server Pages and servlet code to create HTML or other formatted data for the client.
- Enterprise JavaBeans (EJBs) provide another layer where the platform’s logic is stored. An EJB server provides functions such as threading, concurrency, security and memory management. These services are transparent to the author.
- Java Database Connectivity (JDBC), which is the Java equivalent to ODBC, is the standard interface for Java databases.
- The Java servlet API enhances consistency for developers without requiring a graphical user interface.
3.4.3 JAVA DATA BASE CONNECTION
JDBC stands for Java Database Connectivity, which is a standard Java API for database-independent connectivity between the Java programming language and a wide range of databases.
The JDBC library includes APIs for each of the tasks commonly associated with database usage:
- Making a connection to a database
- Creating SQL or MySQL statements
- Executing that SQL or MySQL queries in the database
- Viewing & Modifying the resulting records
Fundamentally, JDBC is a specification that provides a complete set of interfaces that allows for portable access to an underlying database. Java can be used to write different types of executables, such as:
- Java Applications
- Java Applets
- Java Servlets
- Java Server Pages (JSPs)
- Enterprise JavaBeans (EJBs)
All of these different executables are able to use a JDBC driver to access a database and take advantage of the stored data.
JDBC provides the same capabilities as ODBC, allowing Java programs to contain database-independent code.
JDBC Architecture:
The JDBC API supports both two-tier and three-tier processing models for database access but in general JDBC Architecture consists of two layers:
- JDBC API: This provides the application-to-JDBC Manager connection.
- JDBC Driver API: This supports the JDBC Manager-to-Driver Connection.
The JDBC API utilizes a driver administrator and database-particular drivers to give straightforward availability to heterogeneous databases. The JDBC driver director guarantees that the right driver is utilized to get to every information source. The driver supervisor is equipped for supporting different simultaneous drivers associated with numerous heterogeneous databases. Taking after is the design chart, which demonstrates the area of the driver director as for the JDBC drivers and the Java application.
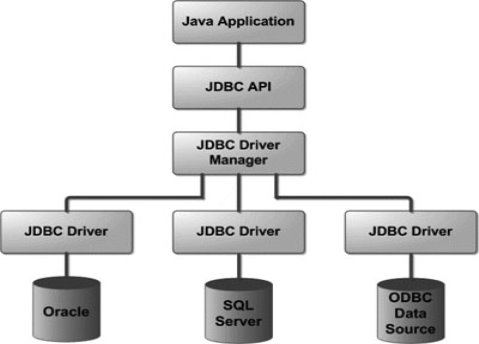
Fig 3.4.3.1: Architectural Diagram
3.5 Software Requirements
The software interface is the operating system, and application programming interface used for the development of the software.
Operating System: Windows XP or higher / Linux
Platform: JDK
Application Server: Apache Tomcat 7 or higher
Database: MySQL
Technologies used: Java, J2EE.
3.6 Hardware Requirements
| CLIENT | ||||
| OPERATING SYSTEM | SOFTWARE | PROCESSOR | RAM | Hard disk |
| Windows/Linux | Any Advanced Browser. Chrome/Opera | Intel/AMD processor | 256 Mb | 160 GB |
Table 2:1 Client Requirements
| SERVER | ||||
| OPERATING SYSTEM | SOFTWARE | PROCESSOR | RAM | HARD DISK |
| Windows/Linux | Any Browser.
JDK 1.7 or above Apache 7 or above MySQL 5.0 or above |
Intel/AMD processor | 256Mb | 160 GB |
Table 2:2 Server Requirements
3.7 Functional Requirements (Modules)
The project having its own respective specific functionalities.
Admin is a main user of our cloud application. Admin add data of a students like his/her name, email, contact, courses, etc. in RDF file, this will help to distribution of cloud data. So based on key attribute we convert it to hash id to form subject. Those subjects and templates will add to hash table (Key Index). Admin can view the RDF and cloud data.
3.7.2. User:
Here user may faculty or student. They can login to application using login credentials, and those will get by signup. Here user is end user of our application. According to their access privileges they access data, like student can see his own data, faculty can search and view total datasets of all students.
3.7.3. Storage Model
Our storage system in DiploCloud can be seen as a hybrid structure extending several of the ideas from above. Our system is built on three main structures: RDF molecule clusters (which can be seen as hybrid structures borrowing both from property tables and RDF subgraphs), template lists (storing literals in compact lists as in a column-oriented database system) and an efficient key index indexing URIs and literals based on the clusters they belong to.
3.8 Non-Functional Requirements
3.8.1 Flexibility & Scalability
Oracle itself has given a set of applications with JDK but the whole developer community can develop their own applications and they have access to same resources and public API which are accessible to core applications.
3.8.2 Robust
The application is blame tolerant as for unlawful client/recipient inputs. Mistake checking has been inherent the framework to avoid framework disappointment.
3.8.3 Fragmentation
Java gave a similar domain which is open; the whole API’s which is interested in every one of the gadgets which decreases fracture. On the off chance that you build up a java application, it will keep running on every one of the gadgets.
3.8.4 Open Source:
Java open source is free and simple to download. Java is a stage in ward based programming dialect and The Java virtual machine (JVM) is a product usage of a PC that executes programs like a genuine machine.
3.8.5 Scalability:
The framework can be reached out to coordinate the changes done in the present application to enhance the nature of the item. This is implied for the future works that will be done on the application.
3.8.6 Reliability:
Since the application is being produced through java, the most popular, effective and solid dialect, so it is dependable in each viewpoint until and unless there is a blunder in the programming side. Consequently the application can be a perfect and dependable one.
3.8.7 Portability:
This System must be sufficiently instinctive to such an extent that client with normal foundation in utilizing cell phones can rapidly try different things with the framework and figure out how to utilize the venture. The framework has easy to understand interface.
3.9 Feasibility study
A key part of the preliminary investigation that reviews anticipated costs and benefits and recommends a course of action based on operational, technical, economic, and time factors. The purpose of the study is to determine if the systems request should proceed further.
3.9.1 Organisational Feasibility
The application would contribute to the overall objectives of the organization. It would provide a quick, error free and cost effective solution to the current process CRM marketing. It would give an answer for some issues in the present framework. As the new framework is adaptable and versatile it can likewise be overhauled and stretched out to meet other complex prerequisites which might be brought up later on. Be that as it may it is up to the association to redesign or amplify it.
3.9.2 Economic Feasibility
The project is economically feasible as it only requires a system with window or Linux operating system. The application is free to get once released into real time host server. The users should be able to connect to internet through machine and this would be the only cost incurred on the project.
3.9.3 Technical Feasibility
To develop this application, a high speed internet connection, a database server, a web server and software are required. The current project is technically feasible as the application was successfully deployed on Lenovo ThinkPad L60 having Windows 7 operating system and also Intel I5 Processor.
3.9.4 Behavioural Feasibility
The application is behaviourally feasible since it requires no technical guidance, all the modules are user friendly and execute in a manner they were designed to.
CHAPTER – 4
4.1 Introduction
4.1.1 Purpose
In this section the purpose of the document and the project is described.
4.1.1.1 Document Purpose
An SDD (Software design description) is a representation of a software system that is used as a medium for communicating software design information.
4.1. Project Purpose
The prime purpose of this of “DiploCloud: Efficient and Scalable Management of RDF Data in the Cloud” is to create a full-fledged web application which would communicate with the remote server to send and retrieve data as per requirement. This application works when there is internet connectivity.
The application recovers client subtle elements from the server and matches up it to the client machines. These points of interest can be put away in the MySQL database. We propose DiploCloud, an effective, dispersed and adaptable RDF information preparing framework for circulated and cloud conditions. Our capacity framework in DiploCloud can be viewed as a cross breed structure amplifying a few of the thoughts from above. Our framework is based on three fundamental structures: RDF atom groups (which can be viewed as crossover structures getting both from property tables and RDF subgraphs), format records (putting away literals in reduced records as in a section arranged database framework) and an effective key list ordering URIs and literals in light of the bunches they have a place with.
4.1.2 Scope
In this section the scope of the document and the project is explained in brief.
4.1.2.1 Document Scope
This document contains a thorough description of the high level architecture that will be used in developing the system. Communicating at a purposefully high level, it will only form the basis for the Software Detailed Design and implementation. However, the SDD itself will not be in sufficient detail to implement the code. It will convey the overall system design of the system, the user interface design and higher level module design and the architecture working of the Java Virtual Machine. Design details that will not be included in the SDD are:
- Low level classes that will be used in the implementation. The full description of the implementation of each module is not needed, but the public modules that will be interfaced will be described.
- Exact detailed description of interactions within each module
4.2 System Overview
4.2.1 Development Tools
Java framework uses certain development tools which are as follows:
The Java Development Kit (JDK) is provided by Sun Microsystems as a basic development environment for Java. The JDK provides similar facilities to the cc compiler for C programs, plus a JVM simulator and some additional facilities such as a debugger. To use the JDK, programs are constructed as ASCII text files (by using an editor, for example). The program files are compiled, which translates the Java code to JVM bytecode in .class files.
Each public class must be in a file having the class name (case sensitive on UNIX) followed by a .java suffix. There may be any number of classes defined in a .java file, but the compiler produces a separate .class file for each class. A file is compiled with the javac command, which is similar to the cc (or gcc) command. A class is executed (or more precisely, the method main in a class is executed) by the command java with the class name (not the .class file) as the parameter. Thus, for example, to compile the program in file Hi.java, we would use the command
javac Hi.java
and then to execute the program we would use the command
java Hi
Both compile-time and execution-time (exceptions) error messages include the file name and line where the error occurred. No class file is produced if there is a compile-time error.
4.2.1.2 TOMCAT 7.0 WEB SERVERS
Apache Tomcat is a web container developed at the Apache Software Foundation (ASF). Tomcat executes the servlet and the Java Server Pages (JSP) particulars from Sun Microsystems, giving a situation to Java code to keep running in participation with a web server. It includes instruments for design and administration however can likewise be arranged by altering setup records that are regularly XML-organized. Tomcat incorporates its own HTTP server inside.
Environment:
Tomcat is a web server that backings servlets and JSPs. The going with Tomcat Jasper compiler accumulates JSPs into servlets.The Tomcat servlet motor is frequently utilized as a part of blend with an Apache HTTP Server or other web servers. Tomcat can likewise work as an autonomous web server. Prior in its improvement, the discernment existed that independent Tomcat was appropriate for advancement conditions and different situations with negligible necessities for speed and exchange taking care of. Nonetheless, that observation does not exist anymore; Tomcat is progressively utilized as an independent web server in high-activity, high-accessibility situations.
Tomcat is cross-stage, running on any working framework that has a Java Runtime Environment. The accompanying properties can be determined, either as framework properties, or by utilizing a deployer. Properties file located in the root folder of the deployer package:
- Build: The build folder used will be, by default, ${build}/web app${path}. After the end of the execution of the compile target, the web application WAR will be located at ${build}/webapp${path}.war.
- Web app: Folder containing the expanded web application which will be compiled and validated. By default, the folder is myapp.
- Path: Deployed context path of the web application, by default /myapp.
- URL: Absolute URL to the manager web application of a running Tomcat server, which will be used to deploy and undeploy the web application. By default, the deployer will attempt to access a Tomcat instance running on local host, at http://localhost:8080/manager.
- Username: Username to be used to connect to the Tomcat manager.
- Password: Password to be used to connect to the Tomcat manager
A web application which is programmatically developed by the developer is stored in the webapps folder and WEB-INF folder also saved in that location which consists of folder named classes which supports to run application automatically.
- The deployer package includes a ready to use Ant script, with the following targets:
- compile (default): Compile and validate the web application. This can be used standalone, and does not need a running Tomcat server. The compiled application will only run on the associated Tomcat 5.0.x server release, and is not guaranteed to work on another Tomcat release, as the code generated by Jasper depends on its runtime component. It should also be noted that this target will also compile automatically any Java source file located in the /WEB-INF/classes folder of the web application.
- deploy: Deploy a web application (compiled or not) to a Tomcat server
- undeploy: Undeploy a web application
- Start: Start web application
- reload: Reload web application
- Stop: Stop web application
4.3 MySQL
The MySQL (TM) software delivers a very fast, multi-threaded, multi-user, and robust SQL (Structured Query Language) database server. MySQL Server is intended for mission critical, heavy-load production systems as well as for embedding into mass-deployed software. MySQL is a trademark of MySQL AB. The MySQL software has Dual Licensing, which means you can use the
MySQL software free of charge under the GNU General Public License (http://www.gnu.org/licenses/). You can also purchase commercial MySQL licenses from MySQL AB if you do not wish to be bound by the terms of the GPL. The MySQL web site (http://www.mysql.com/) provides the latest information about the MySQL software.
What Is MySQL?
MySQL, the most popular Open Source SQL database, is developed and provided by MySQL AB. MySQL AB is a commercial company that builds its business providing services around the MySQL database. The MySQL web site (http://www.mysql.com/) provides the latest information about MySQL software and MySQL AB.
MySQL is a relational database management system.
A relational database stores data in separate tables rather than putting all the data in one big storeroom. This adds speed and flexibility. The tables are linked by defined relations making it possible to combine data from several tables on request. The SQL part of “MySQL” stands for “Structured Query Language” the most common standardized language used to access databases.
Why use the MySQL Database Server?
The MySQL Database Server is quick, solid, and simple to utilize. On the off chance that that is the thing that you are searching for, you ought to try it out. MySQL Server additionally has a reasonable arrangement of components created in close participation with our clients. You can discover an execution examination of MySQL Server to some other database administrators on our benchmark page.
The technical features of MySQL Server
For advanced technical information, The MySQL Database Software is a client/server system that consists of a multithreaded SQL server that supports different back ends, several different client programs and libraries, administrative tools, and a wide range of programming interfaces (APIs).
4.4 System Architecture
- Architectural Design
The J2EE stage utilizes a multitier circulated application demonstrate. This implies application rationale is partitioned into segments as per capacity, and the different application segments that make up a J2EE application are introduced on various machines relying upon which level in the multitier J2EE condition the application segment has a place.Figure shows multi-tier J2EE applications divided into the tiers described in the bullet list below. The J2EE application parts shown in Figure 1 are presented in J2EE Application Components.
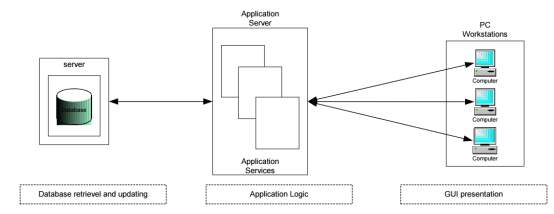
Fig 4.1 Architectural Design
Application Processing provided by multiple tiers
1. Database Server
2. Application Server
3. PC Workstation J2EE applications use a thin client. A thin client is a lightweight interface to the application that does not do things like query databases, execute complex business rules, or connect to legacy applications. Heavyweight operations like these are off-loaded to web or enterprise beans executing on the J2EE server where they can leverage the security, speed, services, and reliability of J2EE server-side technologies.
Web Components:
J2EE web parts can be either JSP pages or servlets. Servlets are Java programming dialect classes that powerfully procedure demands and develop reactions. JSP pages are content based archives that contain static substance and pieces of Java programming dialect code to produce dynamic substance. At the point when a JSP page stacks, a foundation servlet executes the code bits and returns a reaction.
Static HTML pages and applets are packaged with web parts amid application gathering, however are not considered web segments by the J2EE detail. Server-side utility classes can likewise be packaged with web parts, and like HTML pages, are not considered web segments.
Benefits
- Divides Application Processing across multiple machines:
- Non-critical data and functions are processed on the client
- Critical functions are processed on the server.
- Optimizes Client Workstations for data input and presentation (e.g., graphics and mouse support)
- Optimizes the Server for data processing and storage (e.g., large amount of memory and disk space)
- Scales Horizontally – Multiple servers, each server having capabilities and processing power, can be added to distribute processing load.
- Scales Vertically – Can be moved to more powerful machines, such as minicomputer or a mainframe to take advantage of the larger system’s performance
- Reduces Data Replication – Data stored on the servers instead of each client, reducing the amount of data replication for the application.
4.4 Data Design
4.4.1 Databases:
MySQL RDBMS
| Name |
| Diplocloud |
Table 4.2 MySQL Database
4.4.2.1 Table: Course
Columns
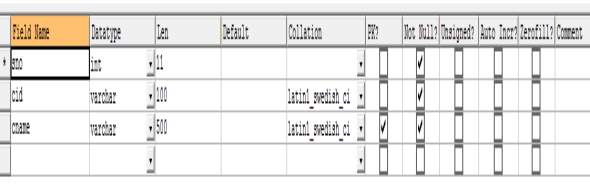
Table 4.3 Structure of Course table of MySQL Database
Definition
CREATE TABLE `course` (
`sno` int(11) NOT NULL,
`cid` varchar(100) NOT NULL,
`cname` varchar(500) NOT NULL,
PRIMARY KEY (`cname`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.4.2.2 Table: coursedata
Columns:
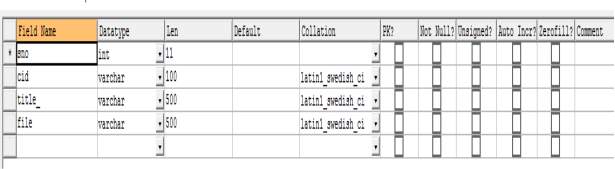
Table 4.4 Structure of coursedata table MySql Database
Definition:
CREATE TABLE `coursedata` (
`sno` int(11) DEFAULT NULL,
`cid` varchar(100) DEFAULT NULL,
`title_` varchar(500) DEFAULT NULL,
`file` varchar(500) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.4.2.3 Table: faculty
Columns:
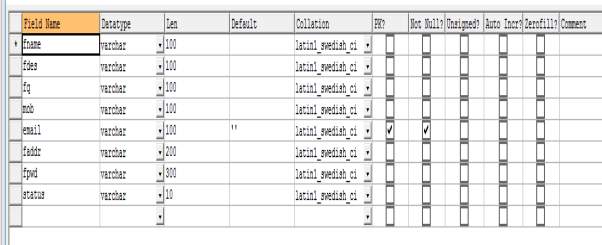
Table 4.5 Structure of faculty table of MySQL Database
Definition:
CREATE TABLE `faculty` (
`fname` varchar(100) DEFAULT NULL,
`fdes` varchar(100) DEFAULT NULL,
`fq` varchar(100) DEFAULT NULL,
`mob` varchar(100) DEFAULT NULL,
`email` varchar(100) NOT NULL DEFAULT ”,
`faddr` varchar(200) DEFAULT NULL,
`fpwd` varchar(300) DEFAULT NULL,
`status` varchar(10) DEFAULT NULL,
PRIMARY KEY (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.4.2.4 Table: keyindex
Columns:
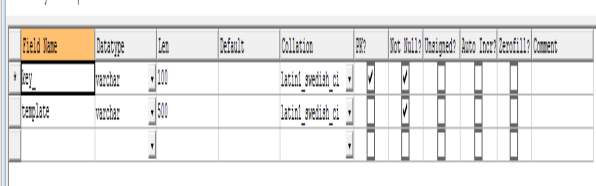
Table 4.6 Structure of keyindex table of MySQL Database
Definition:
CREATE TABLE `keyindex` (
`key_` varchar(100) NOT NULL,
`template` varchar(500) NOT NULL,
PRIMARY KEY (`key_`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.4.2.4 Table: student
Columns:
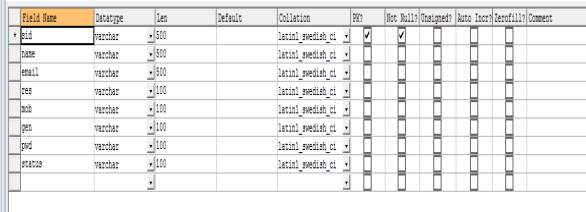
Table 4.7 Structure of student table of MySQL Database
Definition:
CREATE TABLE `student` (
`sid` varchar(500) NOT NULL,
`name` varchar(500) DEFAULT NULL,
`email` varchar(500) DEFAULT NULL,
`res` varchar(100) DEFAULT NULL,
`mob` varchar(100) DEFAULT NULL,
`gen` varchar(100) DEFAULT NULL,
`pwd` varchar(100) DEFAULT NULL,
`status` varchar(100) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
CHAPTER -5
MODELING
5.1 Design
Requirements gathering followed by careful analysis leads to a systematic Object Oriented Design (OOAD). Various activities have been identified and are represented using Unified Modeling Language (UML) diagrams. UML is used to specify, visualize, modify, construct and document the artifacts of an object-oriented software-intensive system under development.
5.1.1. Use Case Diagram
In the Unified Modeling Language (UML), the utilization case graph is a kind of behavioral outline characterized by and made from a utilization case investigation. It speaks to a graphical review of the usefulness of the framework as far as on-screen characters, which are people, associations or outside framework that assumes a part in at least one collaboration with the framework. These are drawn as stick figures. The objectives of these performing artists are spoken to as utilize cases, which portray a grouping of activities that give something of quantifiable incentive to an on-screen character and any conditions between those utilization cases. In this application there is just performer – warrior and beneath is the utilization case chart of this application.
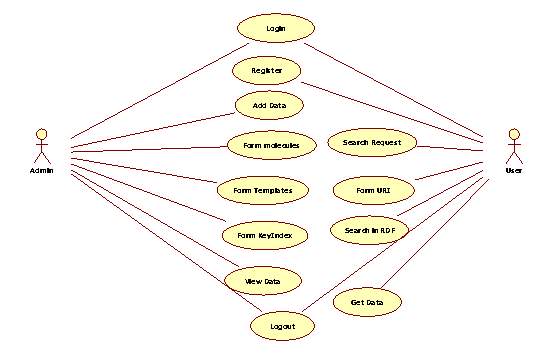
Figure 5.1 Use Case Diagram for System
5.1.2 Sequence Diagram
UML grouping outlines are utilized to show how objects collaborate in a given circumstance. A vital normal for a succession outline is that time goes through and through: the communication begins close to the highest point of the chart and closures at the base (i.e. Bring down equivalents later).
A prominent use for them is to record the elements in a protest situated framework. For each key, joint effort graphs are made that show how objects communicate in different delegate situations for that coordinated effort.
Arrangement chart is the most well-known sort of communication graph, which concentrates on the message exchange between a quantities of helps.
The accompanying hubs and edges are ordinarily attracted an UML grouping graph: life saver, execution determination, message, consolidated piece, collaboration utilize, state invariant, continuation, decimation event.
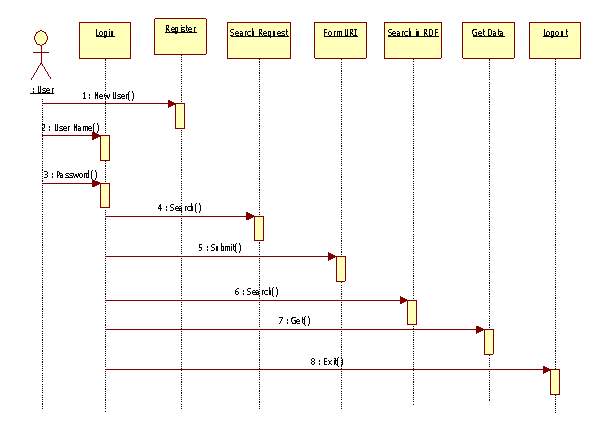
Figure 5.2 Sequence Diagram for User
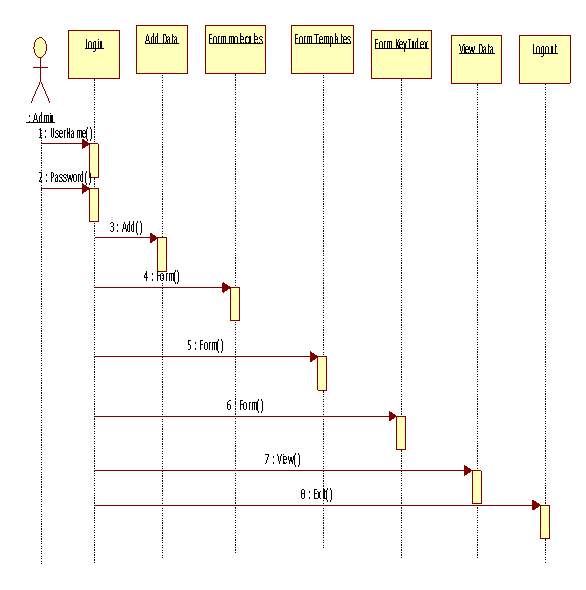
Figure 5.2 Sequence Diagram for Admin
5.1.3 Activity Diagram
Activity diagram is another important diagram in UML to describe dynamic aspects of the system. Activity diagram is basically a flow chart to represent the flow form one activity to another activity. The activity can be described as an operation of the system.So the control flow is drawn from one operation to another. This flow can be sequential, branched or concurrent. Activity diagrams deals with all type of flow control by using different elements like fork, join etc. Activity is a particular operation of the system.
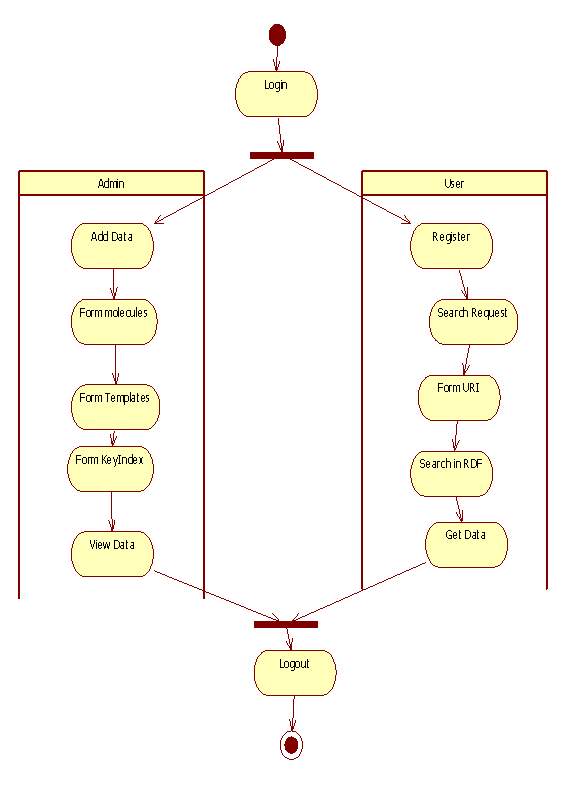
Fig 5.4 Activity Diagram
5.1.4 Class Diagram
In software engineering, a class diagram in the Unified Modeling Language (UML) is a type of static structure diagram that describes the structure of a system by showing the system’s classes, their attributes, operations (or methods), and the relationships among the classes.
The class diagram is the main building block of object oriented 1odeling. It is used both for general conceptual 1odeling of the 1odeling1c of the application, and for detailed 1 modeling translating the models into programming code. Class diagrams can also be used for data modeling. The classes in a class diagram represent both the main objects, interactions in the application and the classes to be programmed.
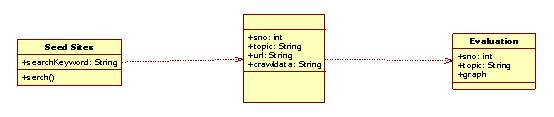
Figure 5.5 Class Diagram
5.1.5 E-R Diagram
Let us now learn how the ER Model is represented by means of an ER diagram. Any object, for example, entities, attributes of an entity, relationship sets, and attributes of relationship sets, can be represented with the help of an ER diagram.
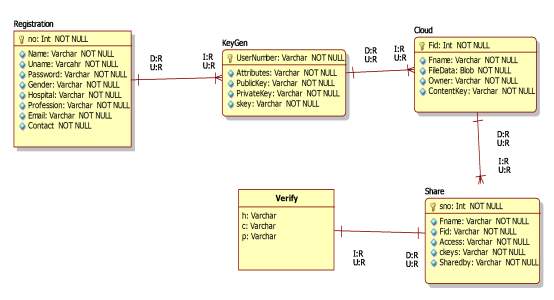
Fig 5.6 E-R Diagram
5.1.6 Deployment Diagram
Deployment diagram shows execution architecture of systems that represent the assignment (deployment) of software artifacts to deployment targets (usually nodes).
Nodes represent either hardware devices or software execution environments. They could be connected through communication paths to create network systems of arbitrary complexity. Artifacts represent concrete elements in the physical world that are the result of a development process and are deployed on nodes.
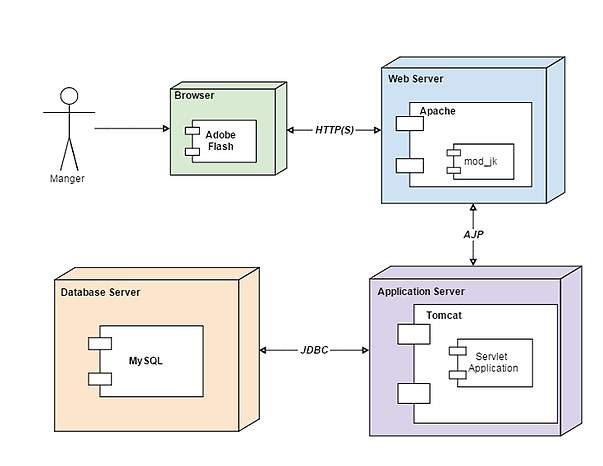
Figure 5.7 Deployment Diagram of the system
5.1.7 State chart Diagram:
A State chart diagram describes a state machine. Now to clarify it state machine can be defined as a machine which defines different states of an object and these states are controlled by external or internal events.
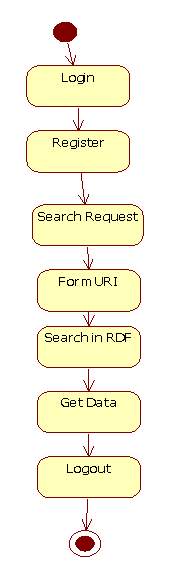
Figure 5.8 State Chart Diagram of User
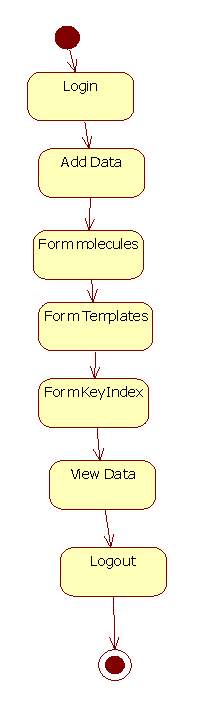
Figure 5.9 State Chart Diagram of Admin
5.1.8 Component Diagram:
Component diagrams are different in terms of nature and behavior. Component diagrams are used to model physical aspects of a system. Component diagrams can also be described as a static implementation view of a system. Static implementation represents the organization of the components at a particular moment.
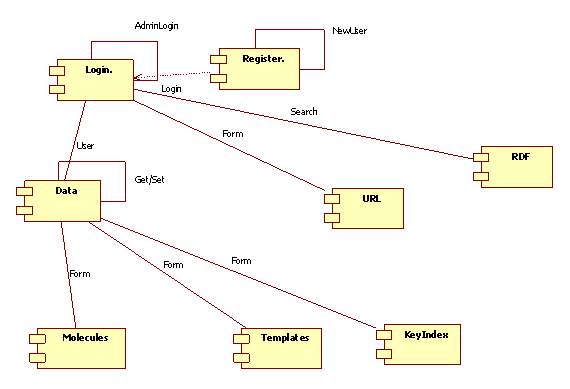
Figure 5.10 Component Diagram
CHAPTER – 6
IMPLEMENTATION
6.1 CODE SNIPPETS:
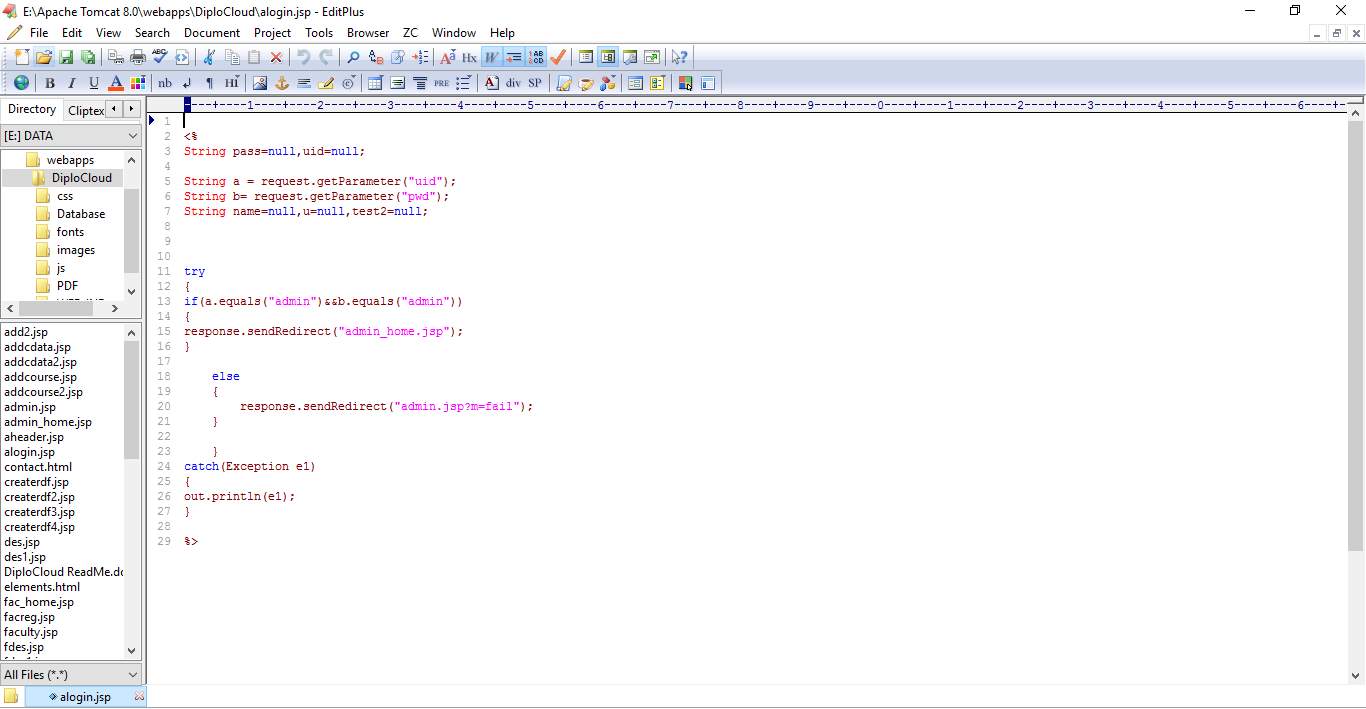
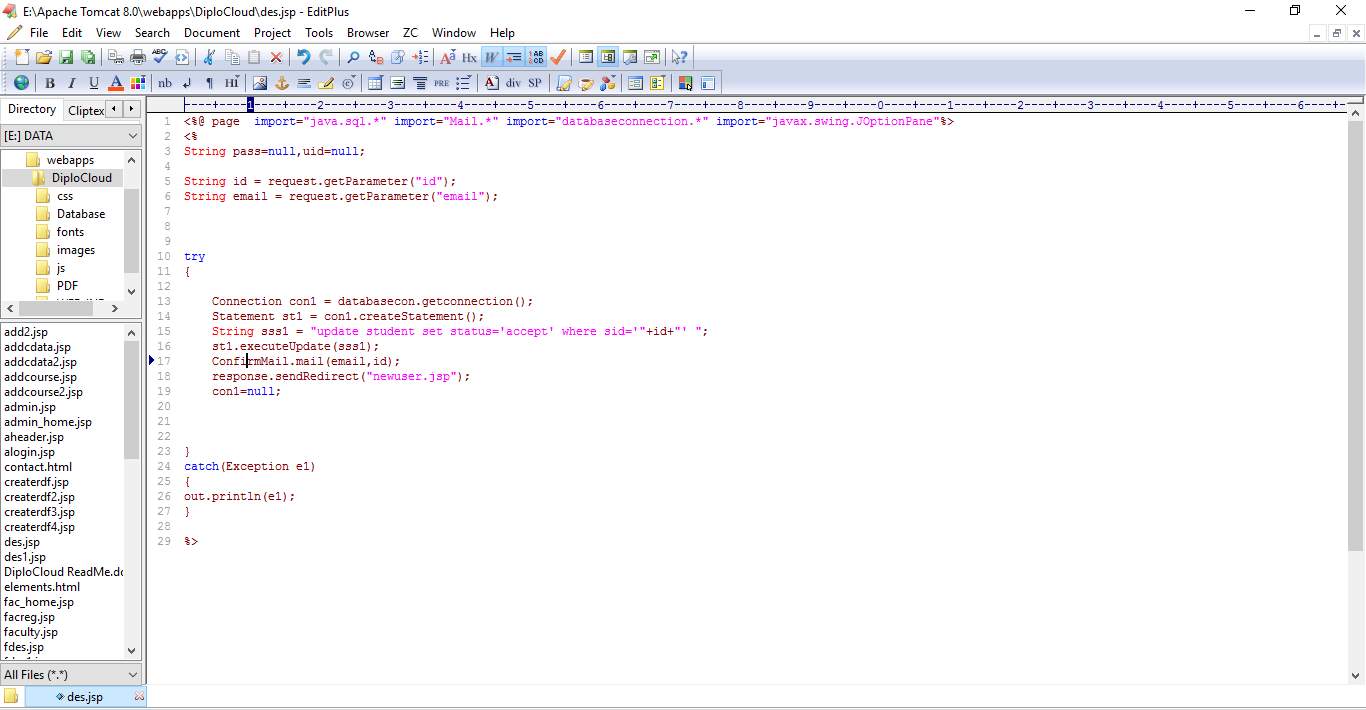
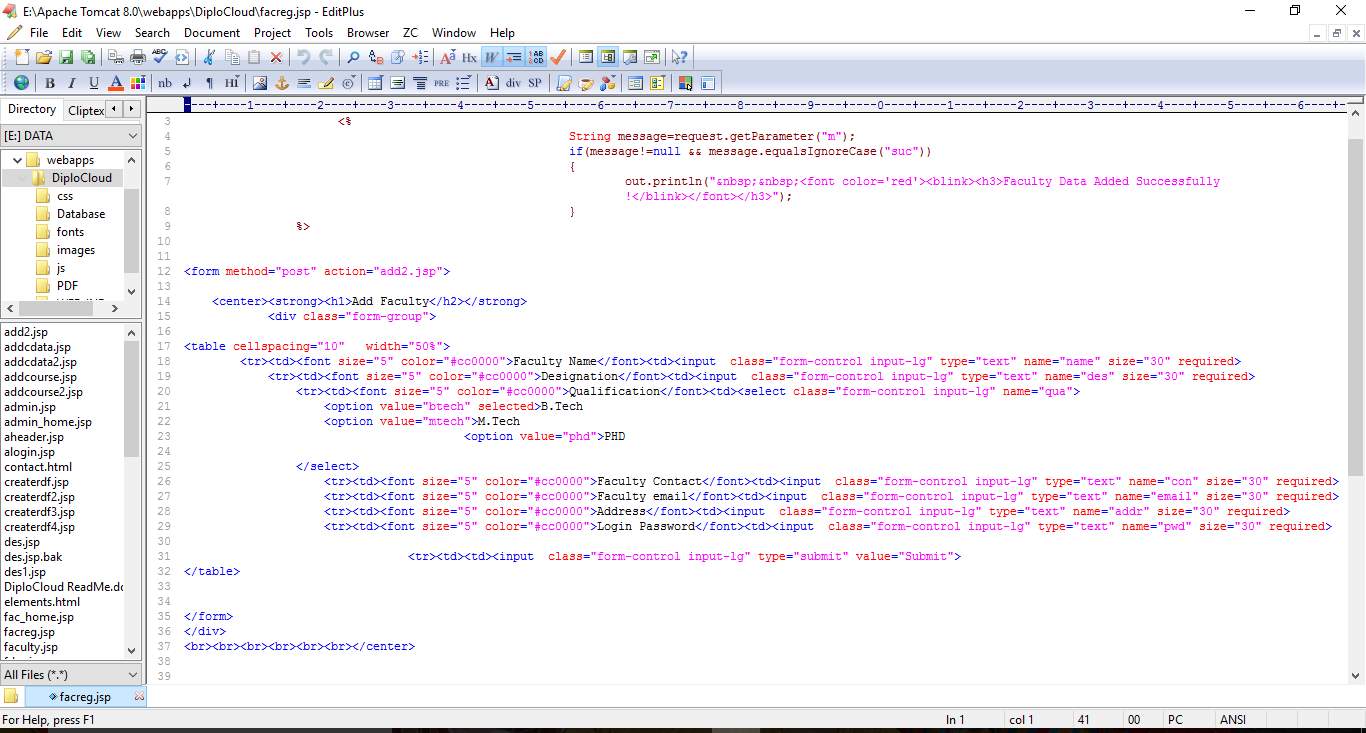
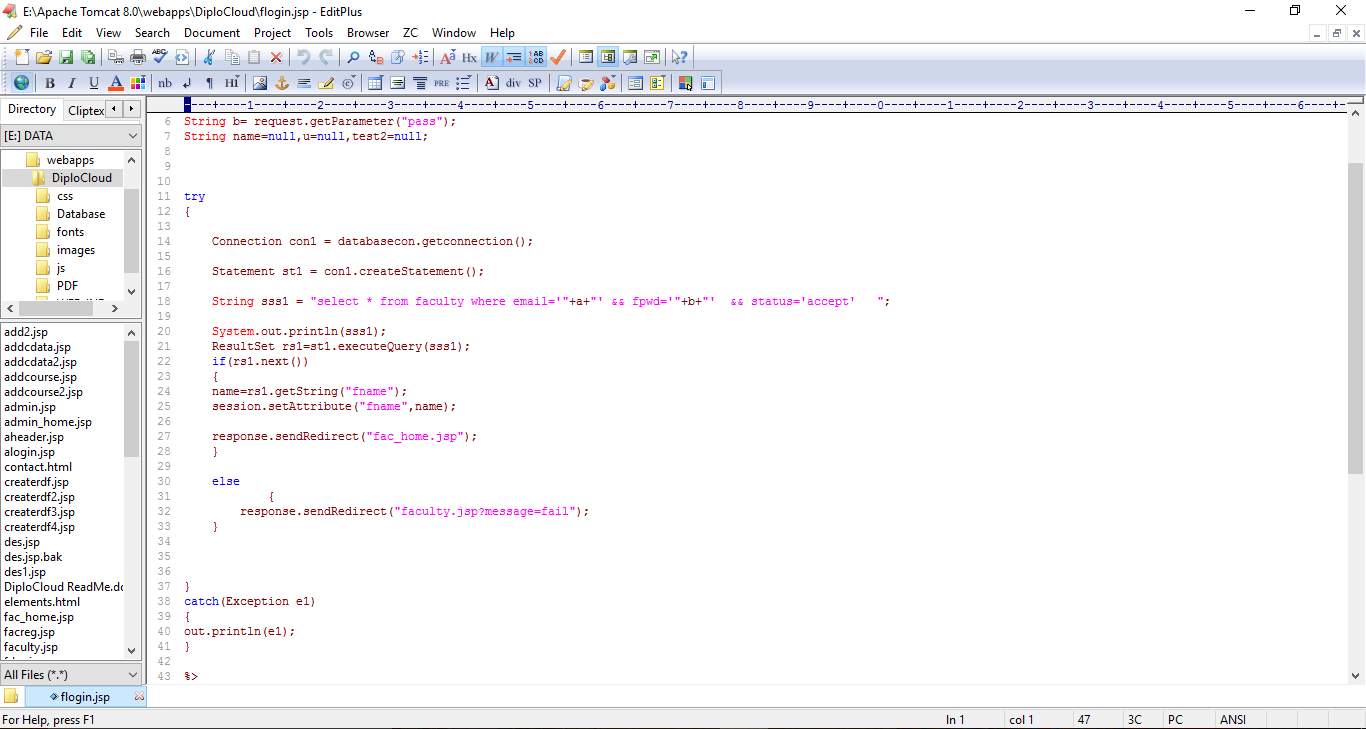
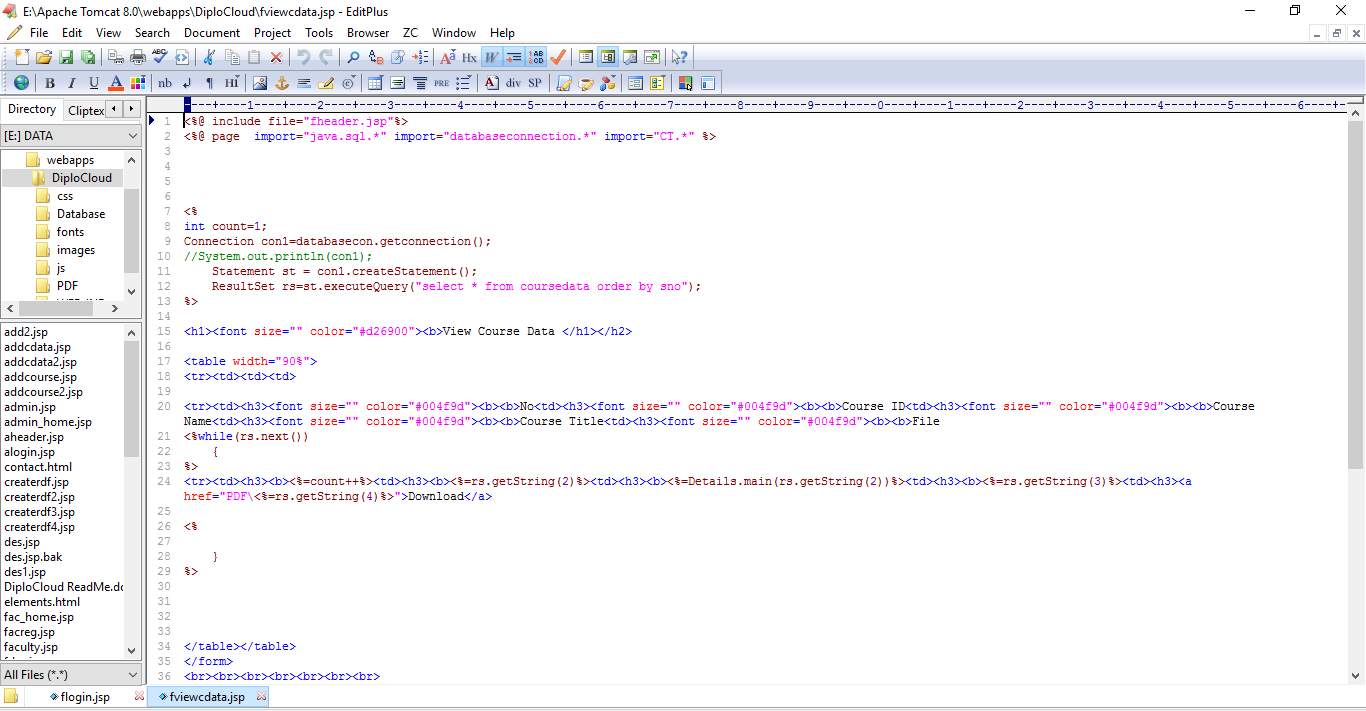
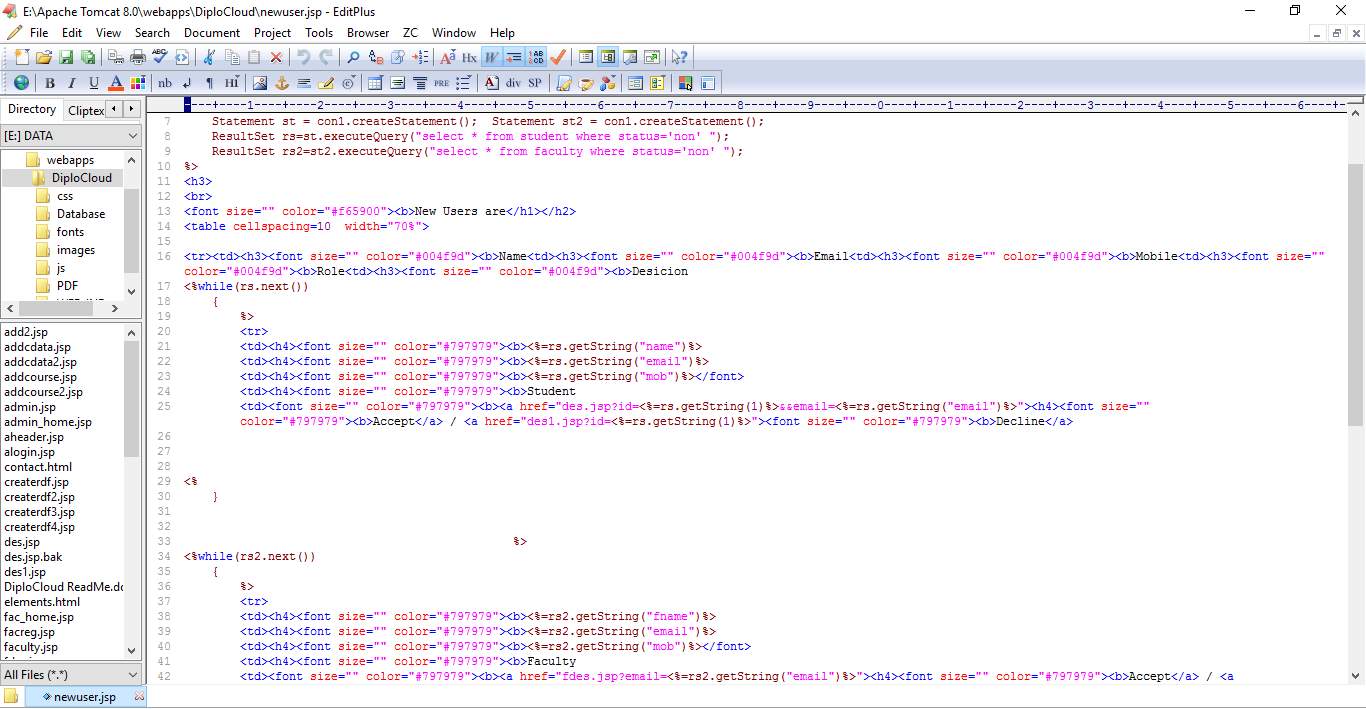
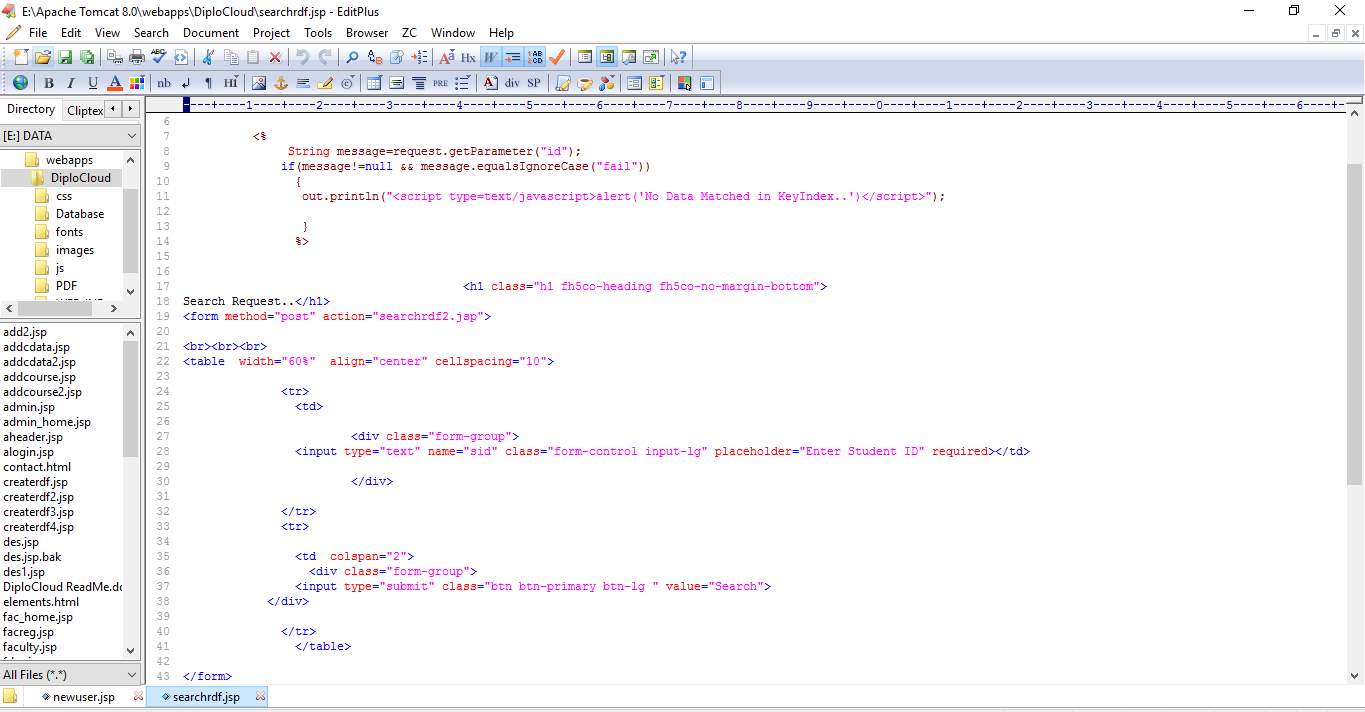
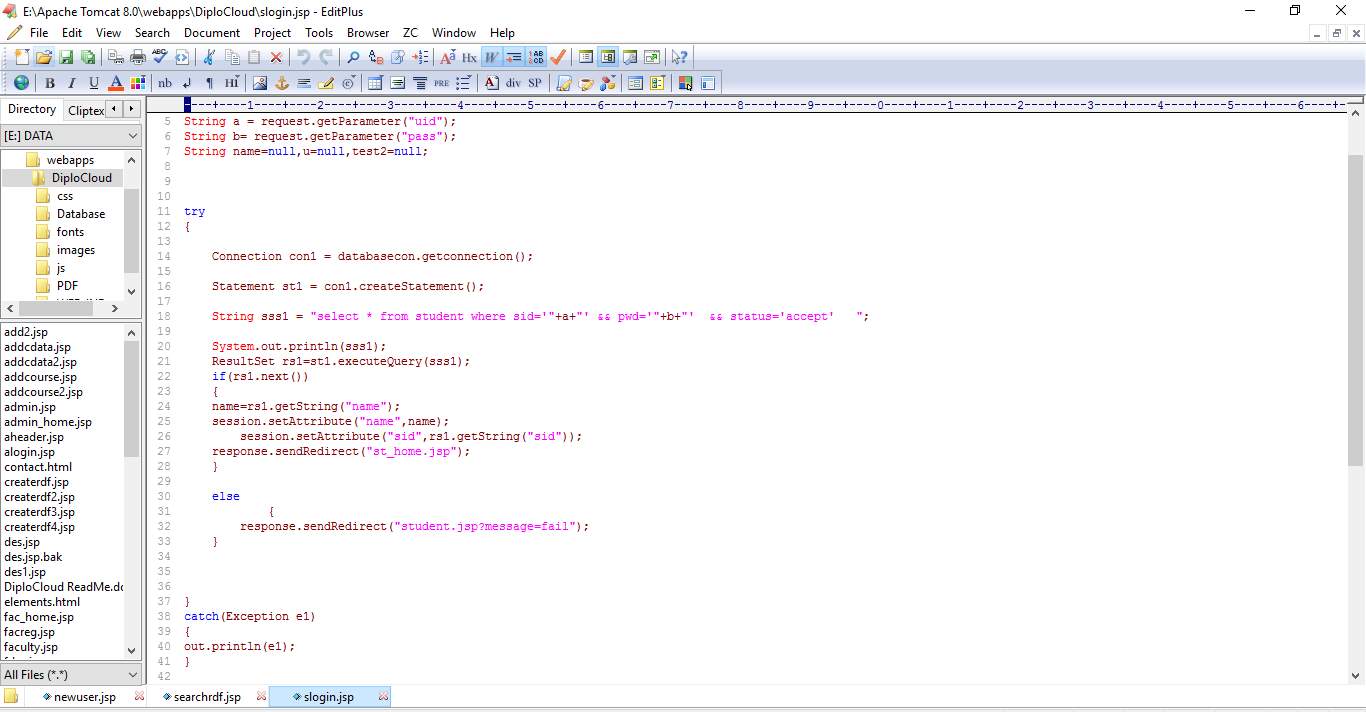
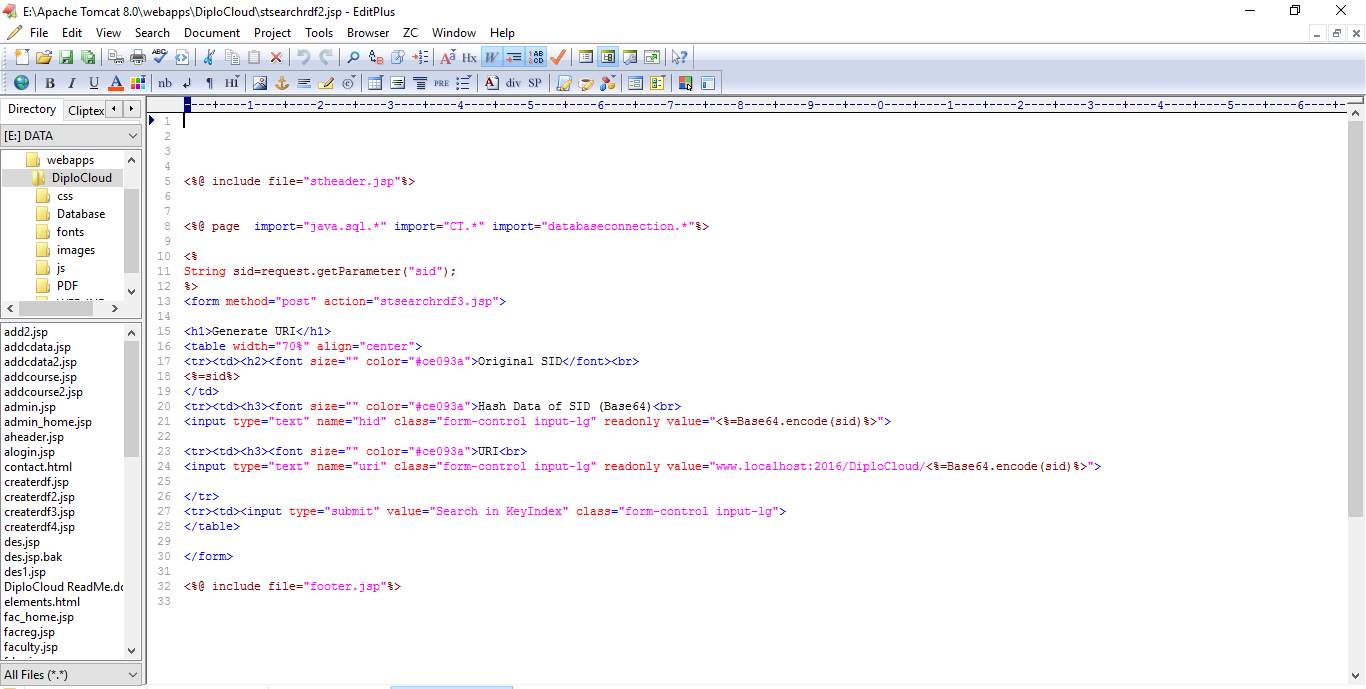
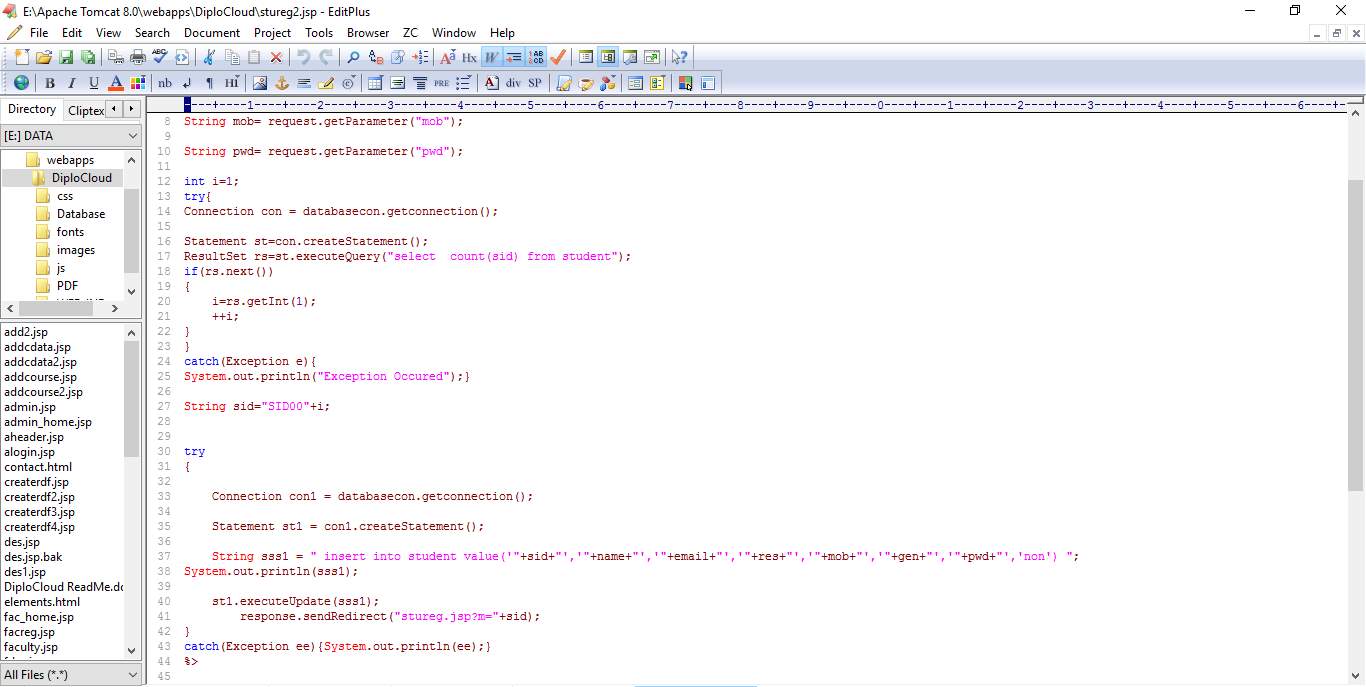
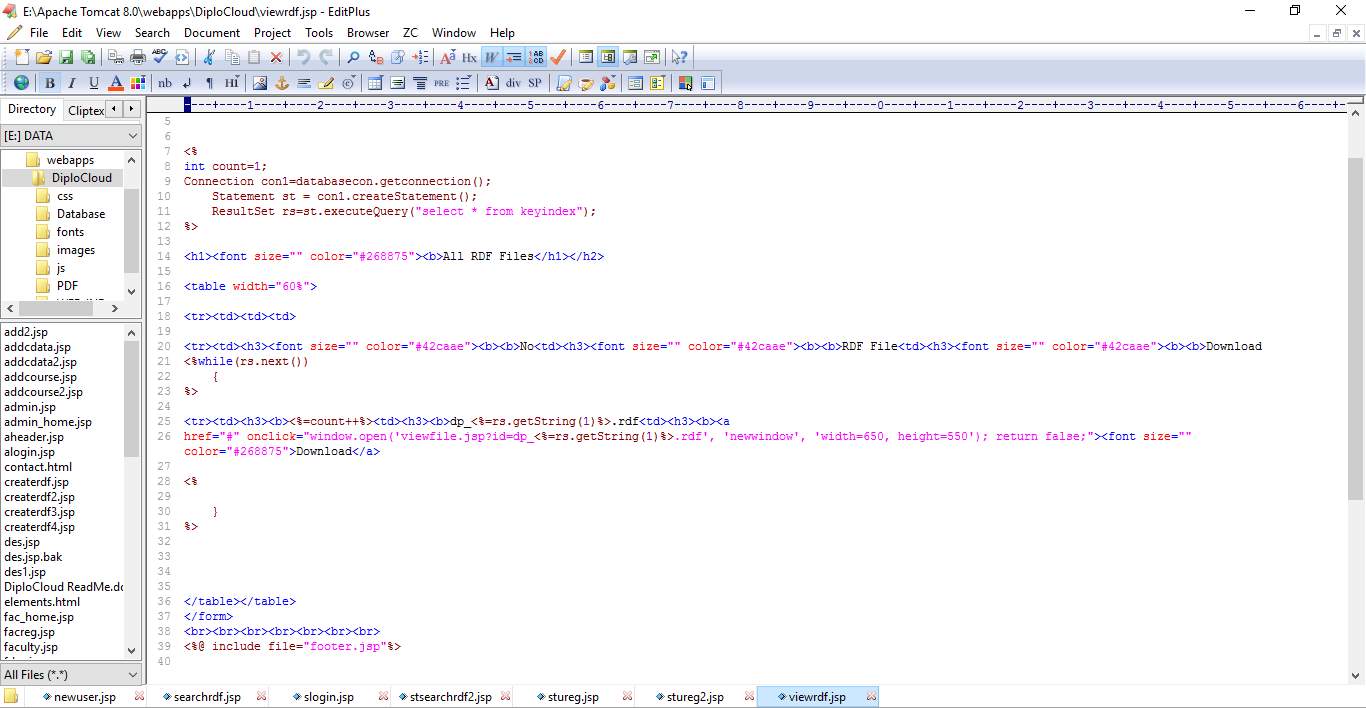
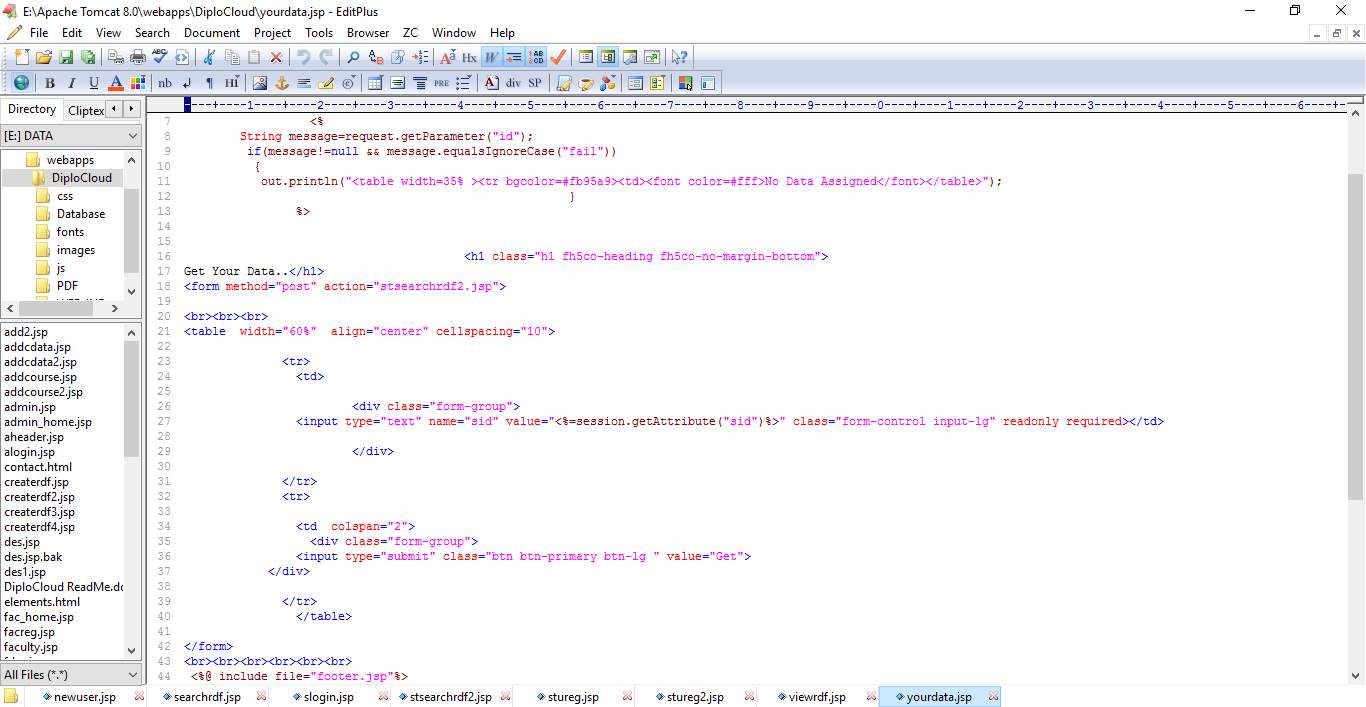
6.2 SCREEN SHOTS:
 Fig 6.1: Home Page
Fig 6.1: Home Page
Fig 6.2 Admin Login
Fig 6.3 Student Sign up
Fig 6.4 New Users Accept/Decline List

Fig 6.5 Welcome Page of Student
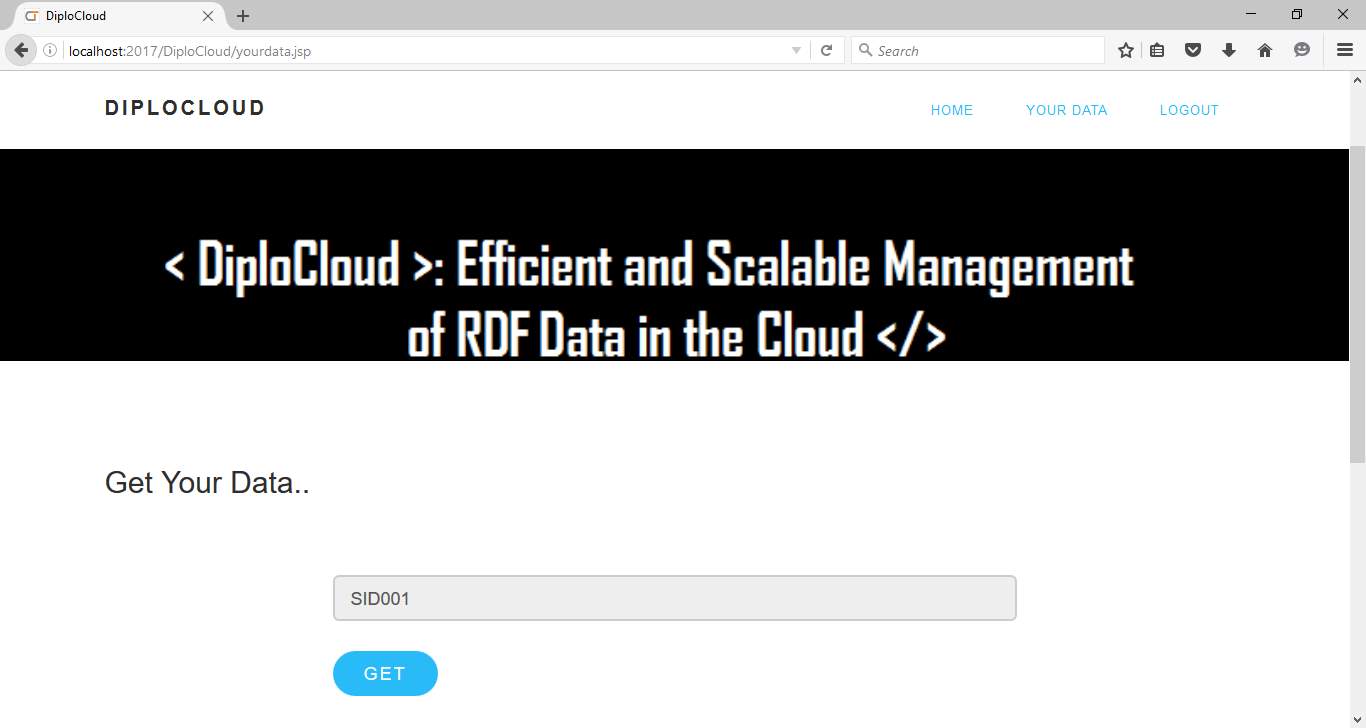
Fig 6.6 Student Data
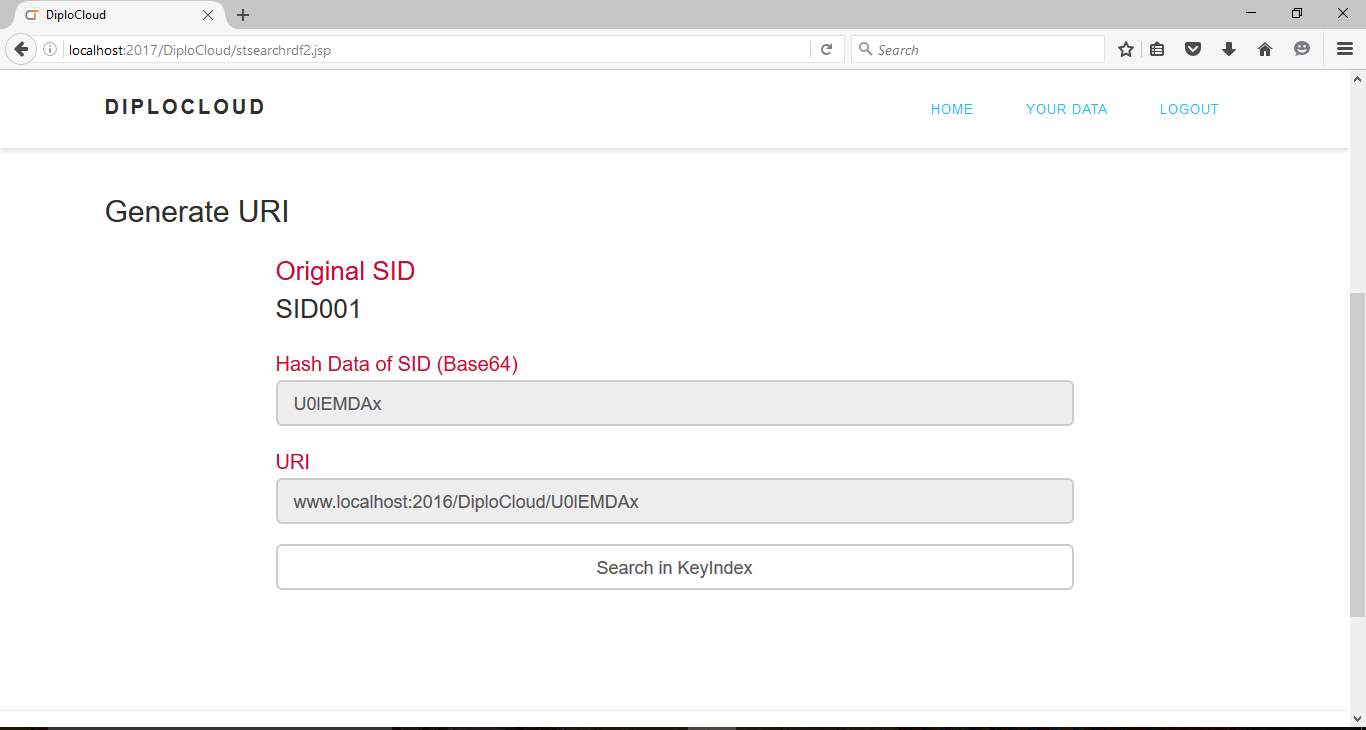
Fig 6.7 Generation of URI
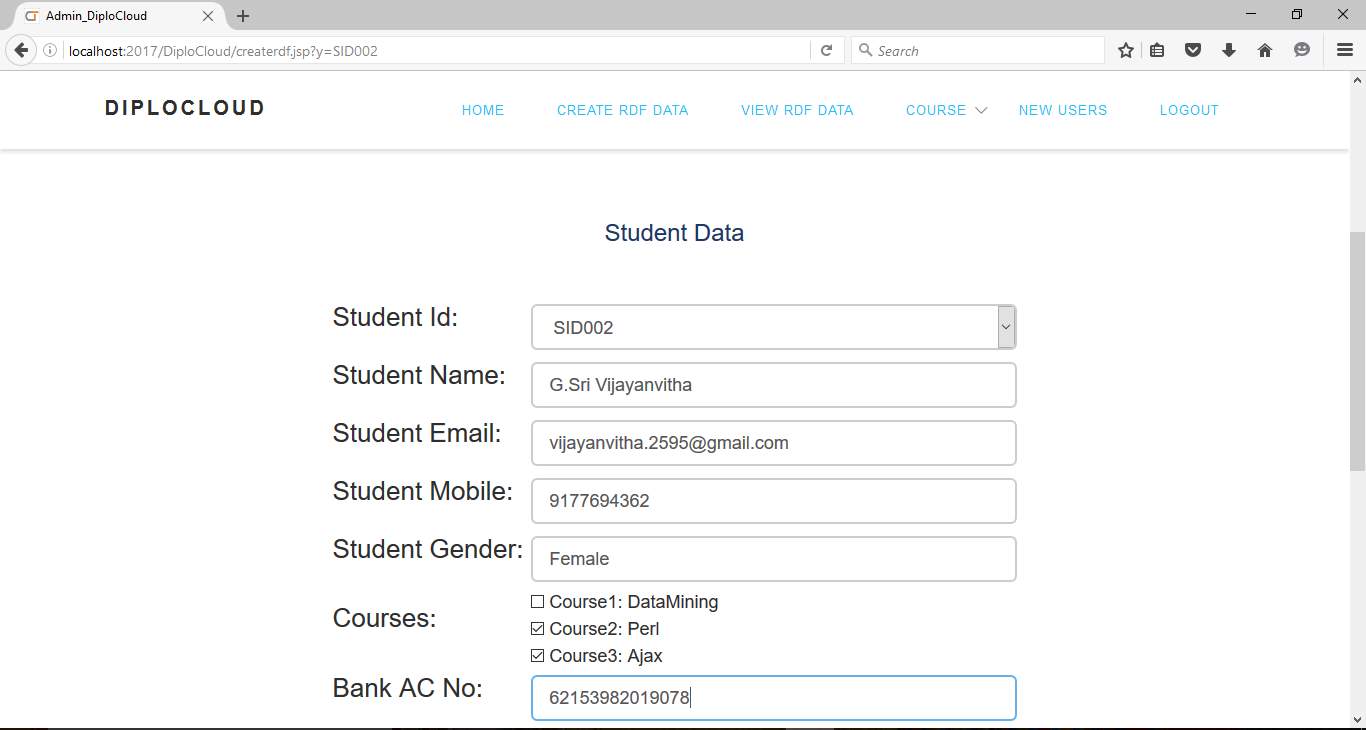
Fig 6.8 Student data and Course Selection
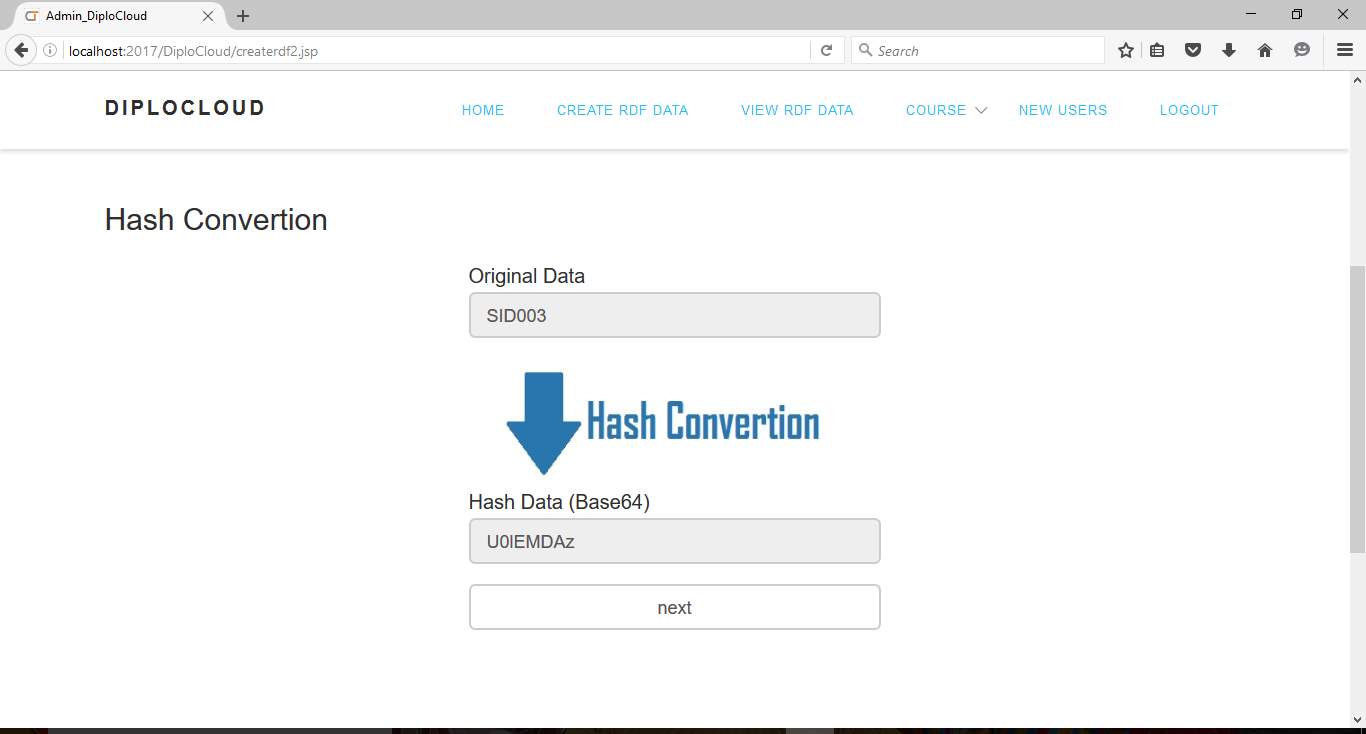
Fig 6.9 Hash Conversion
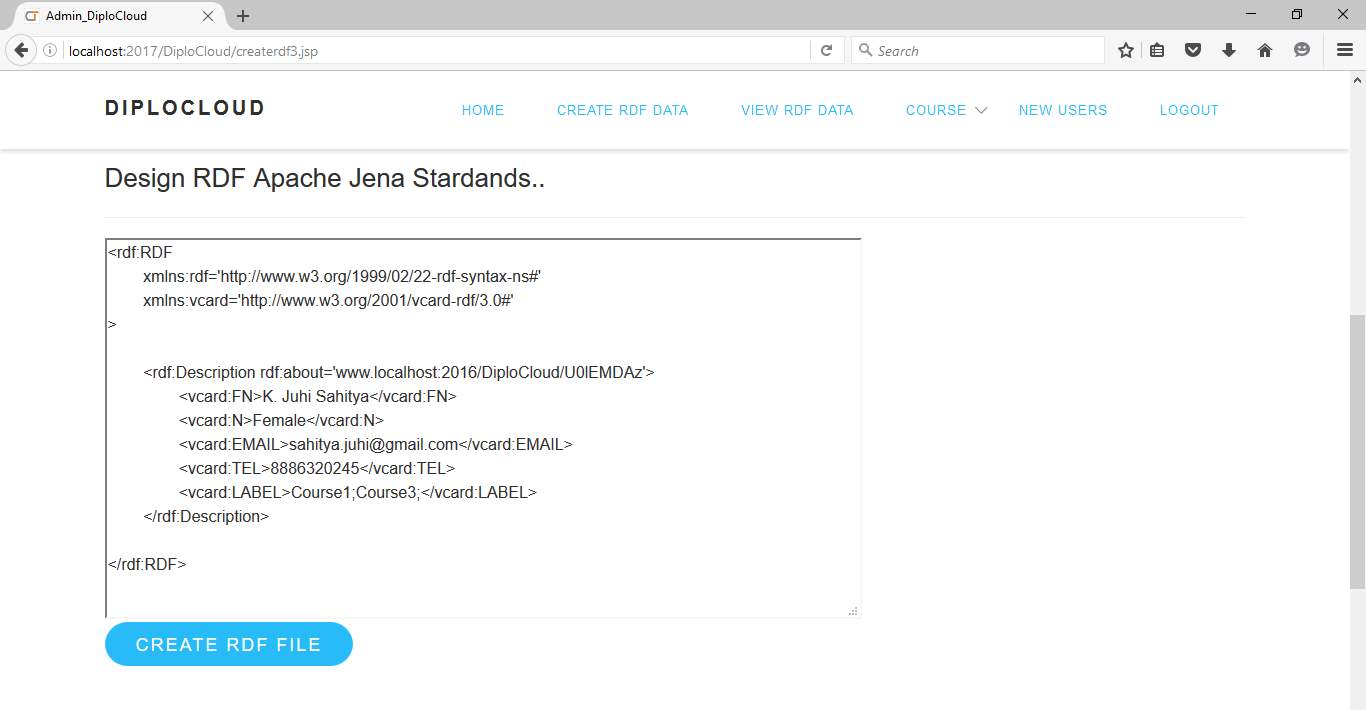
Fig 6.10 RDF Creation
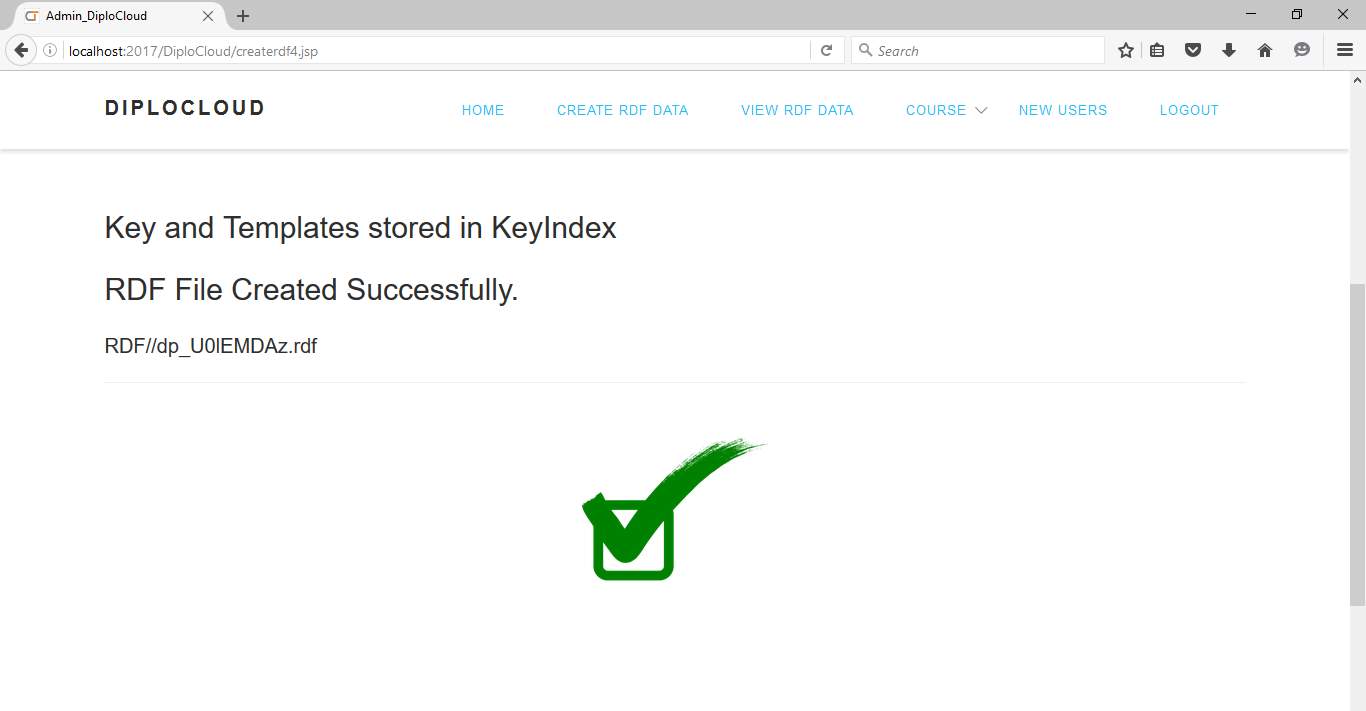
Fig 6.11 RDF file created
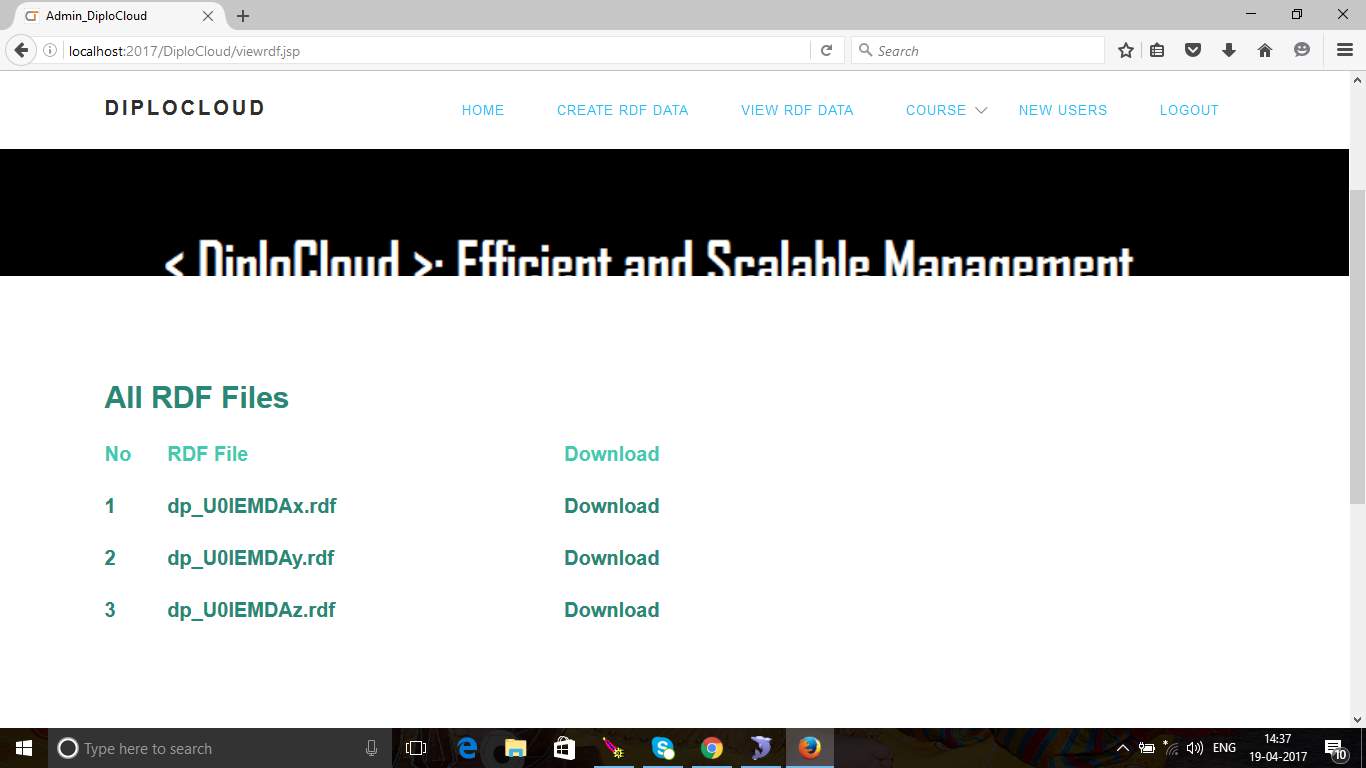
Fig 6.12 List of RDFs created
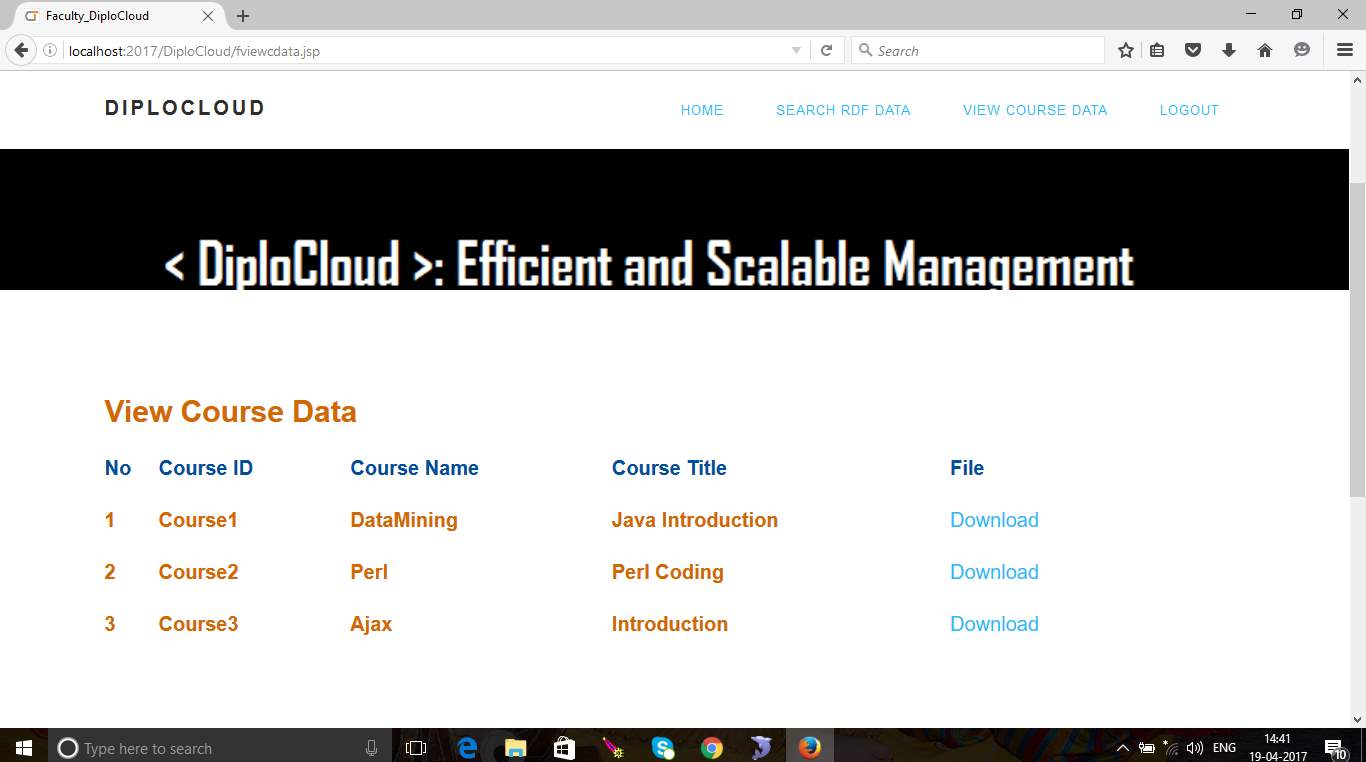
Fig 6.13 Course Data
CHAPTER – 7
TESTING
7. TESTING
7.1 Software Testing
Software testing is the process of validating and verifying that a software application meets the technical requirements which are involved in its design and development. It is likewise used to reveal any imperfections/bugs that exist in the application. It guarantees the nature of the product. There are many sorts of testing programming viz., manual testing, unit testing, discovery testing, execution testing, stretch testing, relapse testing, white box testing and so forth. Among these execution testing and load testing are the most essential one for an android application and next segments manage some of these sorts.
7.2 Black box Testing
Black box testing treats the software as a “black box”—without any knowledge of internal implementation. Black box testing methods include: equivalence partitioning, boundary value analysis, all-pairs testing, fuzz testing, model-based testing, traceability matrix, exploratory testing and specification-based testing.
7.3 White box Testing
White box testing is when the tester has access to the internal data structures and algorithms including the code that implement these.
7.4 Performance Testing
Performance testing is executed to determine how fast a system or sub-system performs under a particular workload. It can also serve to validate and verify other quality attributes of the system such as scalability, reliability and resource usage.
7.5 Load Testing
Load testing is primarily concerned with testing that can continue to operate under specific load, whether that is large quantities of data or a large number of users.
7.6 Manual Testing
Manual Testing is the process of manually testing software for defects. Functionality of this application is manually tested to ensure the correctness. Few examples of test case for Manual Testing are discussed later in this chapter.
| Test Case 1 | |
| Test Case Name | Empty login fields testing |
| Description | In the login screen if the username and password fields are empty |
| Output | Login fails showing an alert box asking to enter username and password. |
Table 7.1 Test Case for Empty Login Fields
| Test Case 2 | |
| Test Case Name | Wrong login fields testing |
| Description | A unique username and password are set by administrator. On entering wrong username or password gives. |
| Output | Login fails showing an alert box username or password incorrect. |
Table 7.2 Test Case for Wrong Login Fields
| Test Case 3 | |
| Test Case Name | Add to MySQL testing |
| Description | Entity code and Name are mandatory fields. If left empty. |
| Output | Insert Fails and a toast message appears asking to enter entity code and name. |
Table 7.3 Test Case to add to MySQL
| Test Case 4 | |
| Test Case Name | Data Storing Testing |
| Description | Testing at database server side weather data is stored or not. |
| Output | n rows effaced |
Table 7.4 Test Case for Data storing
CHAPTER – 8
CONCLUSION AND FUTURE SCOPE
8.1 CONCLUSION
Regardless of late advances in appropriated RDF information administration, handling a lot of RDF information in the cloud is still extremely difficult. Regardless of its apparently basic information demonstrate, RDF really encodes rich and complex diagrams blending both occurrence and outline level information. Sharing such information utilizing established methods or dividing the diagram utilizing customary min-slice calculations prompts exceptionally wasteful circulated operations and to a high number of joins. In this paper, we depict DiploCloud, an effective and adaptable disseminated RDF information administration framework for the cloud. In spite of past methodologies, DiploCloud runs a physiological investigation of both occasion and construction data before dividing the information. In this paper, we depict the engineering of Diplo Cloud, its principle information structures, and in addition the new calculations we use to segment and circulate information. We likewise introduce a broad assessment of DiploCloud demonstrating that our framework is frequently two requests of size quicker than the cutting edge frameworks on standard workloads.
DiploCloud is an effective and versatile framework for overseeing RDF information in the cloud. From our viewpoint, it strikes an ideal harmony between intra-administrator parallelism and information collocation by considering repeating, fine-grained physiological RDF segments and appropriated information designation plans, driving however to conceivably greater information (repetition presented by higher extensions or versatile atoms) and to more mind boggling supplements and updates. Our exploratory assessment demonstrated that it positively looks at to best in class frameworks in such conditions.
8.2. FUTURE SCOPE
We plan to continue developing DiploCloud in several directions: First, we plan to include some further compression mechanisms. We plan to work on an automatic templates discovery based on frequent patterns and untyped elements. Also, we plan to work on integrating an inference engine into DiploCloud to support a larger set of semantic constraints and queries natively. Finally, we are currently testing and extending our system with several partners in order to manage extremely-large scale, distributed RDF datasets in the context of bioinformatics applications.
BIBLIOGRAPHY
[1] K. Aberer, P. Cudre-Mauroux, M. Hauswirth, and T. van Pelt, “GridVine: Building Internet-scale semantic overlay networks,” in Proc. Int. Semantic Web Conf., 2004, pp. 107–121.
[2] P. Cudre-Mauroux, S. Agarwal, and K. Aberer, “GridVine: An infrastructure for peer information management,” IEEE Internet Comput., vol. 11, no. 5, pp. 36–44, Sep./Oct. 2007.
[3] M. Wylot, J. Pont, M. Wisniewski, and P. Cudre-Mauroux. (2011). dipLODocus[RDF]: Short and long-tail RDF analytics for massive webs of data. Proc. 10th Int. Conf. Semantic Web – Vol. Part I, pp. 778–793 [Online]. Available: http://dl.acm.org/citation.cfm? id=2063016.2063066
[4] M. Wylot, P. Cudre-Mauroux, and P. Groth, “TripleProv: Efficient processing of lineage queries in a native RDF store,” in Proc. 23rd Int. Conf. World Wide Web, 2014, pp. 455–466.
[5] M. Wylot, P. Cudre-Mauroux, and P. Groth, “Executing provenance- enabled queries over web data,” in Proc. 24th Int. Conf. World Wide Web, 2015, pp. 1275–1285.
[6] B. Haslhofer, E. M. Roochi, B. Schandl, and S. Zander. (2011). Europeana RDF store report. Univ. Vienna, Wien, Austria, Tech. Rep. [Online]. Available: http://eprints.cs.univie.ac.at/2833/1/ europeana_ts_report.pdf
[7] Y. Guo, Z. Pan, and J. Heflin, “An evaluation of knowledge base systems for large OWL datasets,” in Proc. Int. Semantic Web Conf., 2004, pp. 274–288. [8] Faye, O. Cure, and Blin, “A survey of RDF storage approaches,” ARIMA J., vol. 15, pp. 11–35, 2012.
[9] B. Liu and B. Hu, “An Evaluation of RDF Storage Systems for Large Data Applications,” in Proc. 1st Int. Conf. Semantics, Knowl. Grid, Nov. 2005, p. 59.
[10] Z. Kaoudi and I. Manolescu, “RDF in the clouds: A survey,” VLDB J. Int. J. Very Large Data Bases, vol. 24, no. 1, pp. 67–91, 2015.
[11] C. Weiss, P. Karras, and A. Bernstein, “Hexastore: sextuple indexing for semantic web data management,” Proc. VLDB Endowment, vol. 1, no. 1, pp. 1008–1019, 2008.
[12] T. Neumann and G. Weikum, “RDF-3X: A RISC-style engine for RDF,” Proc. VLDB Endowment, vol. 1, no. 1, pp. 647–659, 2008. [13] A. Harth and S. Decker, “Optimized index structures for querying RDF from the web,” in Proc. IEEE 3rd Latin Am. Web Congr., 2005, pp. 71–80.
[14] M. Atre and J. A. Hendler, “BitMat: A main memory bit-matrix of RDF triples,” in Proc. 5th Int. Workshop Scalable Semantic Web Knowl. Base Syst., 2009, p. 33.
[15] K. Wilkinson, C. Sayers, H. A. Kuno, and D. Reynolds, “Efficient RDF Storage and Retrieval in Jena2,” in Proc. 1st Int. Workshop Semantic Web Databases, 2003, pp. 131–150.
[16] A. Owens, A. Seaborne, N. Gibbins, et al., “Clustered TDB: A clustered triple store for Jena,” 2008. [17] E. PrudHommeaux, A. Seaborne, et al., “SPARQL query language for RDF,” W3C Recommendation, vol. 15, 2008.
[18] Y. Yan, C. Wang, A. Zhou, W. Qian, L. Ma, and Y. Pan. (2009). Efficient indices using graph partitioning in RDF triple stores. Proc. IEEE Int. Conf. Data Eng., pp. 1263–1266 [Online]. Available:
http://portal.acm.org/citation.cfm?id=1546683.1547484
[19] L. Ding, Y. Peng, P. P. da Silva, and D. L. McGuinness, “Tracking RDF graph provenance using RDF molecules,” in Proc. Int. Semantic Web Conf., 2005, p. 42.
[20] S. Das, D. Agrawal, and A. El Abbadi, “G-store: A scalable data store for transactional multi key access in the cloud,” pp. 163–174, 2010.
[21] M. Br€ocheler, A. Pugliese, and V. Subrahmanian, “Dogma: A diskoriented graph matching algorithm for RDF databases,” in Proc. 8th Int. Semantic Web Conf., 2009, pp. 97–113.
[22] H. Kim, P. Ravindra, and K. Ayanwu, “From SPARQL to Map- Reduce: The journey using a Nested TripleGroup algebra,” Proc. VLDB Endowment, vol. 4, no. 12, pp. 1426–1429, 2011
.Websites Referred:
http://java.sun.com
http://www.sourcefordgde.com
http://www.networkcomputing.com/
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: