Software Architecture Robustness Analysis: A Case Study Approach
Info: 8293 words (33 pages) Dissertation
Published: 26th Jan 2022
Tagged: Information Systems
Abstract
Software Solution providers sell products saying their system is robust. To this day, no hard and fast rules exist that demarcate the standards for measuring this quality attribute. Implementation of software architecture is often conceived through patterns. Each pattern has its own way of employing tactics. Considering robustness to be a deciding factor, the competing architectural patterns can be evaluated and analyzed so that best application can be chosen. This paper provides an outline of Software system robustness and a study of patterns and impact of tactics on them. It discusses generic means through which a system can be designed to be stronger and less prone to faults. Also, the study encompasses different elements in architectural style that contribute to the aspect. Moreover, in support of the applicability of suggested analysis methods, it adds a case study to garner evidence towards the claim. An attempt is made to justify the selection of a pattern based on documented and undocumented design experiences as well as comparative exploration for achieving quality of robustness.
Keywords: Robustness; Software Architecture; Architectural style; Patterns; Tactics
Introduction
As we are drawn towards the age of the machines, software systems are means to control everything. From microwave to aircraft, large servers with thousands of nodes and petabytes of memory to hand-held devices; we are dependent on reliable software that can result in an undeterred usage experience. Not only is it just a fancy luxury, it is fast becoming our necessity and part and parcel of life that we can’t live without. Hence it is of utmost importance that design and development of the software is done with careful study.
From usage perspective, software solutions broadly can be thought of belonging to two categories – 1) utility applications that are used by individuals 2) Commercial software that are used by corporates for their business needs. Most commercial software incurs higher cost and so, developing and deploying them involves more intricate planning and follows calculated steps. Large software solutions in public services are also extremely complex and need to be flawless.
Fault in some of them, can be considered insignificant and ignored but in others, may cause substantial economic loss. There are still others that directly impact our lives and any failure in them can lead to fatalities. Software for these systems need to be extremely stable and thus their architecture needs to be designed in such a way that it become robust enough to sustain virtually any adverse incident. Now, such incidents can result from external activities or natural calamities.
Imagine we need to send a critical message to someone. There can be multiple possibilities to avail. Let’s see what those are and what could be possible limitations and impediments in them.
- Text message: Probably quickest option if we have a mobile phone handy. But typing on a small screen can be cumbersome. In some phone number of characters that can be typed at one go is limited. If network is down or unreachable then it can’t be done. Also, there could be snag in the texting software in the phone.
- Email: We can compose an electronic mail and send it immediately to the recipient’s mailbox. This is convenient as it gives freedom to annotate, attach further reference documents and importance can be marked. But for phone, it needs to have a mail software configured and data should be enabled. For laptop or desktop computer, internet access is required. In any case the mail software can have a glitch or the operating system can even crash.
- Traditional postal letter: This is by far the slowest even if we consider overnight delivery. There is need for human effort to collate documents and put in envelope and then take it to a mailing service.
As we mentioned above, each system can be thought of as an alternative and we can say that there is redundancy in messaging service. If there is no network, the message will remain saved in the phone and when network is up, it will be sent, similar thing applies to email. Although slow, the physical mail service stands on a tried and tested system and a way to send original document. There are some P2P messaging apps available today, like whatsapp, that indicate acknowledgement of whether message is delivered or read.
From the above example, we can infer that providing solution to a requirement needs consideration of all means and we have think of design that has provision to pursue an alternate when one fails. Furthermore, it is worthy to note that depending on requirement (type of message), which would produce consistent result.
An unexpected scenario can be handled only if it is envisaged even before the system is built. For smaller systems, the developers can list out improper way of usage or write test cases with invalid or illegal inputs in mind (Extreme Programming approach). However, for complex systems, it would be immensely difficult to put such an effort. In addition to requiring huge manpower and time, it is almost impossible to figure out if some of the cases are missed. This in turn can leave subtle but dangerous bugs in the system. If such an issue propagates, it may cause the entire system to crash.
Therefore, we need to think one step ahead and try to design the system by breaking it down to components; which can communicate through connectors and rules can be defined by configuration. We can also put constraints onto them. This higher-level design is called software architecture. Thus, we employ divide and conquer mechanism to make components and their connections enduring thereby achieving overall system strength.
Although design in terms of implementation techniques and methodologies is a well-established field with on-going research for quite some time, Software architectural design has drawn relatively lesser attention. Over the last couple of decades however, the trend seems to be changing. As the systems become increasingly complex, it is perceived that analysis and design of systems at a higher level of abstraction is the key to tackle most of the issues that arise in later parts. This also benefits investors immensely as maintenance costs are reduced by a huge margin. Although it is not obvious where and how the design can be optimized, architects use empirical data to measure effectiveness. Furthermore, software architecture analyses are often executed on a need basis for projects and there’s very few available structured comparisons for an attribute. To find a solution to design goals, an architect must perform painful study and manually assess software architectures for product evolution and trade-off analysis.
Firstly, we will need to layout a considerable definition of robustness on the backdrop of software quality and non-functional requirements. We need to understand that different stakeholders have distinct perspective of robust system design. Lung and Kalaichelvan [1] presented the concept of software architecture robustness. In the paper, they handsomely lay down framework by recognizing more concrete influences of the impact of robustness in software architecture. They also an outline of metrics for analysis through case studies.
Because of ever-growing struggle to come-up with revolutionary ideas, the evolution of the software engineering is probably one of the fastest among all industries. Hence, the parameters and process used for assessment could be outdated. Identification of measurable metrics is needed first to be able to compare different patterns. If we think from low-level design point of view, there are various parameters available at the code level. Some researchers have also shed light on the design metrics. On the other hand, no widely accepted and codified method for analyzing high-level design parameters exists. Partly because this field is still evolving and is open to new findings; and partly because they differ greatly based on the size and complexity of the system under consideration.
An architectural pattern can be assessed from qualitative as well as quantitative perspective. This paper proposes some ways of quantitative evaluation for finding out how they compare with each other to achieve a robust system. This can help an architect to consider and make informed decisions as he goes ahead with design.
Organization of the paper is as follows: Part II provides some term details that we will encounter later in the paper. Part III has a discussion on exploring what software architecture robustness is. Part IV contrasts the quality of robustness with other similar ones like reliability and availability. Part V discusses how requirement specification and design can be approached keeping robustness in mind.
Part VI shows some sub-characteristics, depicts a scenario and puts forward thoughts on tactics that can be employed. Finally, Part VIII shares what this research achieves through a case study. To conclude, part IX identifies future directions in this area.
Background and Terminologies
Software Intensive System: It is a generic term for multitude of systems wherein software development and integration plays a dominant role and occupies lions share of the whole system. They are usually complex to configure and comprise of many sub-components working in tendem to achieve a common end goal. So, software intensive systems are extremely difficult to maintain and even harder to design. Large scale deployment and multi-point communication are the salient features of such a system.
System Under Test: It refers to a system that has to be tested to see if it performs properly with respect to various kinds of input. The application under test should respond uniformly and consistently as expected. In our case study section, which is about a integrated automation testing framework, we will briefly describe the system under test and point out how considering it has a major impact on design of the framework itself.
Pattern: From the software architecture point of view, patterns are generic solution to recurring problems that can be fine-tuned to produce desired outcome and attain qualities. Christopher Alexander[2] was the one who first formulated the idea from the physical architecture’s point of view, but we can corelate it to a software architect’s as well. Each pattern serves a particular set of purposes and depending on requirement, can be mixed and matched with dedicated interfacing.
Quality Attribute and Tactics: The factors that potentially impact the application’s behavior. It affects the system’s design and user experience. Usually they can be thought of as non-functional requirements. Tactics are design decisions that have impression on attainment of quality attributes. It’s about how the system responds to a stimuli.
Software Architecture Robustness
In this section, we will try to articulate the quality attribute robustness. Literature on software architecture has expressed it in many ways, there seems to be no common universally accepted definition. Although architects and clients alike consider it to be a critical aspect. A system is ‘robust’ when it does not crash too often and can withstand myriad range of inputs. In the event of extreme situation like malformed command or power failure, the system should at least – a) Log the reason and b) Terminate by closing all open resources. Based on study of various literature and books, we can express it as:
“Robustness is the degree to which a system can handle unexpected or abnormal conditions and terminate gracefully.”
Let us examine with examples. First, consider a simple program that provides functionality to divide one number with another. Now, this can be implemented through c++ programming language in a very basic way like:
—————————————————————————-
#include
int main() {
int x, y;
std::cout
std::cin >> x >> y;
std::cout
return 0;
}
This program follows neither procedural nor object oriented principles. However, even if we don’t consider these, it is a terrible program. Think about the points below:
- It assumes numbers are integers. For any large number, there will be overflow. For floating point numbers, it will lose precision. For non-numbers, behavior is undefined, more likely to crash.
- The division operation is blindly applied. If the denominator is zero, again, the program will fail.
In a software project, the requirement specification document (SRS) provides guidelines as to what should be the approach to design. For non-trivial applications like the one above, we should, at minimum consider the above-mentioned points. Getting a clear picture of stuffs to consider designing a robust application can be challenging. It also depends on number and type of intended user-base. For a fellow programmer, comments and the signature of a method can tell the story; but for a naïve end-user, this would be impossible to comprehend. Hence, notifying the user of program behavior is very important as well. This adds to a robust application experience and can be further analyzed to make a quantitative guess of productivity of the system. Continuous delivery is the need of the hour and very much in demand.
With these in mind, the program can be rendered as below:
—————————————————————————-
#include
int divideIntegers(int numerator, int denominator) {
if(denominator == 0) {
std::cout
return 0;
}
else {
return numerator / denominator;
}
}
int main() {
int x=0, y=0;
std::cout
try{
std::cin >> x >> y;
std::cout
std::cout
}catch(…) {
std::cout
return -1;
}
return 0;
}
Social media applications are very popular these days. An application cannot rise to popularity with tendency to fail every now and then. In fact, it must take care of users from a wide range of social, cultural and technical background. One thing that stands out for this category of application is the constant change in requirement. Based on user experience analysis and feedback a feature may need to be entirely re-designed. For instance, one of the most fundamental feature is logging in. Adding ability to login using mobile number instead of a username would be a daunting task. Also, if the application has global outreach, each government of country may have specific rules to be applied or extra validation to be done. We can characterize a few extreme situations:
- Unicode character data
- Very large media
- Concurrency control
- Network or browser application failure
These sorts of situations put the system under stress. Now, this stress can result in A) internal fault and B) external fault. Any individual component that the system is comprised of can develop a snag. This in turn makes the components downstream to process wrong and incorrect data. Eventually the entire system fails. Corrupt data, communication channel pointing to different endpoint, memory leak, loading of wrong configuration values are some of the symptoms of erroneous design. The end-user may not notice an internal fault unless he has a monitoring alert configured for it. But consequently, the fault generates further faults in components and ultimately can result in system failure. So, we can see that even though we handle exceptional scenarios at a granular level, it is the chain of responsibility that defines what happens with it in the long run. We can employ a combination of monitoring and notification tactics to overcome such a situation.
The environment plays a key role in terms of the external faults getting generated. From bad input data to going out of memory, from running out of disk space to network cable getting unplugged, all fall under this category. Each module should have strong validation rules so that before starting to process first check should be done to make sure it can be processed. The architects use various tactics like ping/echo, heart-bit etc. to periodically take a stock of system health. Serialization provides a way to the application to dump the current state into a binary file in case of sudden failures like power outage. This can later be loaded up to resume processing from it left off. System as well as application logs are scanned to analyze most common means of failure and this knowledge can later be used to enhance the system. This way of dynamic self-healing mechanism is also catching up in the research of robustness quality.
Robust architecting involves handling all possible combinations of scenarios that potentially can make system unstable and make sure it doesn’t end abruptly. The steps to be performed in case of non-natural termination has to be well-defined. Often these steps are combined and a module is formed which can be invoked if any of the termination condition is met. Memory deallocation, temporary file system cleanup saving changed configuration data – all fall under this set. Another effective way is using tactic of separation of concern. This may identify smallest possible unit of the application that can act independently and run them in detachment from the main application. This helps the main application keep track of failed sub-processes and take necessary steps. The Google Chrome browser is an apt example of this. Each tab is responsible for handling specific URLs and thus there is a web application to tab mapping. Each tab runs as a separate process in its own address space and when an application crashes, it only takes down the tab and the application window can notify the user, who can try to restore (i.e. relaunch the application).
Assessment of Software architecture robustness can be done in many ways. We can have quantitative as well as qualitative evaluations. In this paper, we will figure out sub-factors of robustness attribute and discuss about what are the ways to measure them by distributing them among the two lines. One thing to note here is that specified requirement has the highest priority during the design phase.
Robustness & other quality attributes
Although quality is an abstract term, we humans have always found ways to justify marking one item to be of better quality then another. For physical products, we can distinguish based on size, color etc. When it comes to software products, we should come up with parameters of measurements. And we can find out which parameters affect qualities in which way. For instance, increasing virtual memory of a system can result in better performance of the application; or maybe using a different algorithm. Quality also can be specified with respect to how closely it conforms to the requirement. The first one is referred as ‘Quality of Design’ and the second one as ‘Quality of conformance’. In modern world, software producers strive to provide best user experience to their clients. Naturally, quality attributes and their inter-dependency has caught eyes to researchers who have worked to model them.
Many efforts have been made to map quality models. Earliest of them all is probably McCall’s. He listed high-level factors to present a view of quality. Boehm extended it and added a level of abstraction for utility. He also lists two-stage constructs of quality attributes. The ISO 9126 is also based on McCall’s model that hierarchically categorizes six main qualities into sub-characteristics. These however, don’t explicitly mention robustness as an independent quality. Karl Wiegers, in his taxonomy has listed it and mapped it to the criteria like error handling and hazard analysis.
As we go through the attributes, we can imagine some of them having some common sub-characteristics. Measuring those closely related quality attributes would thus involve common steps. Let us contrast robustness quality attribute with two of its most closely related ones.
Reliability and Robustness:
Reliability and dependability are interchangeable concepts. It refers to the quality of consistently producing same output for given set of inputs. If, for some reason it fails on a certain portion, the same behavior can be expected as long as the design remains same. Some experts claim robustness as a part of reliability. This would imply that a system will always be reliable if it is robust. We know from experience that it may not always hold. For instance, a system can continue to operate for a prolonged period without any failures but differ in output for same input from different sources from different time. That is, there can be inherent bugs that render the output but never generate faults.
Reliability has been widely covered in the literature, most notable in the handbook of reliability engineering. There is no doubt though that the two, share mutual interest and the design goals for both cross roads in characteristics like – Fault tolerance, exception management, recoverability etc. A fault that makes output of the system contradict the expected result creates a reliability issue. Robustness specification can tell us how that kind of faults can be handled. We can further work to make amendments to the system so that we gather the correct response in the handler section. This way a robust system can be very reliable.
Availability and Robustness:
Another quality attribute that grabs a lot of spotlight and has shared characteristics with robustness is availability. Bass et al say that “The availability of a system can be calculated as the probability that it will provide the specified services within required bounds over a specified time interval.” Now, a system can be shut down intentionally or it can unexpectedly terminate. It will be said that the system adheres to availability requirements if total uptime remains within the limits. We cannot say the same thing for robustness. If an abnormal input brings the system down, it fails to maintain the quality requirement. However, fault management occupies indispensable part of both the attribute.
If we have a web server with only a limited number of requests per day, it is likely to remain available unless an internal bug makes it crash. If the number of requests has a steep hike or the server is relocated to a new place, then it has to handle different kinds of input and chances for failure increases manifolds. So, we can argue that a system that is not robust is more likely to be unavailable. A system can be unavailable but robust in quality as well.
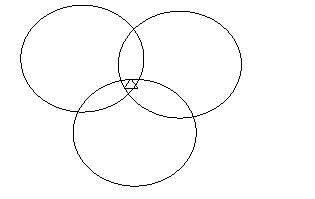
Fig: The three quality attributes share characteristics.
The triangle marks common to all factors like fault tolerance.
Characteristics and measuring of Robustness
Levy et al have paved the way for demonstrating how sub-characteristics can be used to assess software architecture for quality attributes. Based on their work, we now disclose the characteristics for robustness and discuss about how they can be used to find out qualitative and quantitative measure of robustness.
The motivation comes from the ISO 9126-1 quality model, in which sub-characteristics have been given for quality characteristics like Functionality, Efficiency etc. It is noteworthy that some of the sub-characteristics are re-used across multiple quality characteristics. As we mentioned in our comparison section, we would want to re-use the fault tolerance characteristics. However, we will rather introduce an umbrella characteristic called ‘Fault Handling’ which not only deals with tolerating but also incorporates fault reporting/notification. Compliance to requirement continues to be a sub-characteristic consistent with others.
Robustness



| Fault handling | Productivity | Failsafe behavior | Compliance |
Let us go through each of them and explain what are they and why they are considered a sub-characteristic.
- Fault handling: This is the ability to keep the system functioning and maintain accepted level of performance in case an unexpected fault occurs. This can be implemented by means of mechanisms like –
- Exception handling: The architects identify components and sub-modules of the components where exceptional situation may arise and emply handlers which prevent propagation and log proper message. Issarny et al have proposed an approachable way to design and implement exception handling support at architectural level.
- Redundancy: Since number of components are finite, we can mark the resources where we can introduce redundancy to ensure system doesn’t fail. For example, if a component is disk I/O intensive, we can add RAID rack. So, this is quantifiable since we can keep track of number of changes being done and then we can see how many times (if any) the disk was switched.
- Productivity: It is the ability to keep producing expected output; even in the face of adverse situations. For a system to be robust it should be productive. If there is a fall in productivity (more exceptional cases occurring) then gradually the system stops being robust. Some factors that affect this characteristic are:
- Learning curve: If the system is too complex for users to get used to, there are more chances of them providing wrong input. We can enumerate user’s efficiency with respect to their usage time on average. This will give us an idea of how easy or difficult the system is to get used to.
- Changes Inflicted: If users are particularly sensitive about a component, it is more likely to get more feature add/remove requests. These requirement changes may adversely affect productivity. Less change requests help the architect keep the system robust. We can measure ratio of total change requests and component specific ones to point less productive components.
- Fixes: Patchwork is good quick work-arounds but components that have had more fixes later on are prone to fault. This means with time it gets difficult to maintain them and they lose productivity. We can keep a tab on bug-trackers and demarcate components that have been patched. This include architectural modification as well.
- Failsafe Behavior: It is the capability of the system to move to an alternate state when a sudden failure renders generally used state of the system unusable. Failsafe is a very important aspect of implementation of robustness. It defines a special state of application that has restricted access to critical resources and provides a way to repair by pointing out failed components. For instance, all major operating systems have failsafe mechanisms. In case of a fatal error, system can be restored and on diagnosis if a resource is found to be missing or corrupt, the system switches to the failsafe mode. This way it remains available with working features and demonstrates robustness. We can come to know of failsafe issues from diagnostic data. Architecturally speaking, this may seem like a design overhead, but it can be a component by itself keeping its concern separate and only getting invoked on extreme situations.
- Compliance: The ability to adhere to standards and protocols. Architecturally significant requirements (ASRs) [7][8] are cases where care needs to be taken to ensure the design in compliant to the requirements. It basically implies a Boolean value that signifies whether the attribute is achieved or not. Compliance to an architectural style can be referred as to whether it satisfied the associated architectural constraints.
Robustness scenarios and tactics
Source
Response measure
Artifact: Process



Stimulus Response
Exception Issue logged
Invalid Handler User notified Resume
Input Invoked next
operation
Fig: Sample concrete robustness scenario
The above figure, we can see an instance of robustness scenario in which when a user inputs some invalid data, an exception is raised in the process. The control then goes to the handler section which pushes a log message and prints appropriate message to the user and then goes on to the next operation.
The table below describes general scenario for robustness.
| Portion of scenario | Possible Values |
| Source | People, hardware, Software, physical infrastructure, physical environment |
| Stimulus | Fault: Exception, Crash, incorrect timing |
| Artifact | Processors, Communication Channels, Persistent storage, processes, RAM |
| Environment | Normal operation, Startup, Shut Down, Failsafe mode |
| Response | Exception gracefully handled, resources deallocated, handles relinquished
|
| Response measure | Part of system where the exception occurred
Number of exceptions raised in a period Number of time failsafe was invoked Time interval of exceptions |
A case study of robust design
In this section, we will start with requirement for a automation testing framework, briefly describe its architecture and how it’s supposed to work and then point out what measures have been taken as well as can be taken to stress on robustness of the system. We will try to apply the characteristics based measuring principles we discussed above. For brevity, we will omit unnecessary details such as team member information and project duration. We will focus on the various components and their connections. We will also mention different tools and infrastructure that were in use and how configurations were deployed across cloud systems as well as client devices.
Requirements: The system works as a common framework for integration as well as system testing teams who want to run their test cases targetting a video streaming service provider platform. The platform is already in place with all service provider system deployed into the cloud infrastructure. It should employ a continuous integration environment to acquire users input and publish results to a globally accessible server.
Objective:
The primary goal of the framework is to provide testers with an end-to-end solution so that they don’t have to care about elementary services and utilities. Also, management of running multiple test cases targeting corresponding devices is to be handled by it. Apart from these, it should have the following qualities/facilities:
- Platform independent: It can be hosted on any platform as desired – Microsoft Windows, Linux (Ubuntu) or Apple MAC OS X.
- Time calculation: It should report how long each scenario in the test case took to run and how much time overall was consumed.
- Seamless integration: It should support continuous integration model and any newly deployed test case implementation should be immediately available to run.
- Tracking: As agile methodology is to be used for developing the framework, each functionality can be easily traced back to corresponding requirement. This way, if a ticket is raised for a bug, side by side comparison can be made to understand if there was a gap in interpreting.
- Scaling: The framework should be able to handle more and more devices as they are added to be used and registered on the server. If hardware limitations don’t come into picture, it should trigger tests on an increasing number of servers as well.
- Portability: Upgrading the hardware should not require re-deployment. At the same time, version upgrade of the framework should be backwards compatible with test case implementations.
However, the operations have to follow a specific order and the whole request/response set is atomic i.e. if one test case fails or any unexpected situation arises in the middle, the framework should stop further execution and elegantly abort all future requests in the set. The order of actions is given below:
- Get user input from interface
- Extract request parameters
- Validate whether given tests are available
- Run sanity check on test server
- Connect to all provider servers to check reachability
- Connect to target device based on platform preference
- Collect all test cases information and mapping details of results
- Run tests parallelly and collate results
- Publish the results in server
- Push formatted logs to ELK server for analysis
- End execution and terminate application.
- If an exception occurs, put in ELK log and void results bucket, delete temporary files, unload configuration data and return with failure information.
The test results are kept in a global repository. Later, they are sorted and published to the client through an interface. The entire process being automated, there is no scope of manually altering result files. Tests are run by geographically separated teams from across the world. So, if a test case fails, client will be able to see it in the reports. This directly impacts business and future economic prospect of the project. Therefore, it is imperative that the system is designed in a very robust way. If there is any issue in the system, it is the failure of the entire system.
We designed the system with the above-mentioned points in mind and while designing the architecture optimized it to handle robustness quality attribute. The following steps were taken to ensure this:
- All resource handling components were identified.
- All network connections were done on the ‘create once use till the end’ principle. So connections made at the beginning of framework initialization were utilized and automatically destroyed through framework destructor module.
- Opening and closing of resource handle was done on the RAII principle i.e automatic destruction on termination.
- All allocation/deallocation were made sure to occur under a exception block (try/catch). And the handler segment would notify the controller which in turn would log the proper message.
- A separate failsafe module was developed dedicated to the cause of handling a situation of system crash while executing a test case. This helps in cleaning up any dangling resource and update server as required.
- There were two levels of log monitoring designed. Test result output were scaned and analyzed to understand trend. And Run log were monitored on the fly for any exceptional condition.
- If an exception log was found the server was updated with system health with appropriate timestamp. This would be later used to see how often a system failed.
Based on the sub-characteristics of Robustness tactics as we explained in the previous section, we can compare and contrast architectural patterns from the implementation perspective. Buschmann [6] first conceived this idea in his book and although usually architects consider a blend of different architectures to achieve a tactic, a marking with respect to it its characteristic is nevertheless beneficial as it provides important insight into aspects a pattern stresses. This leads to more educated decision making which in turn results in better implementation. We consider a handful of patterns and discuss the responsibilities.
| Patterns | Robustness | ||||||
| Productivity | Fault handling | Failsafe Behavior | Compliance | ||||
| Find Learning Curve | Enumerate Changes | Enumerate Fixes | Exception Handling | Redundancy | |||
| Layered | X | X | X | ||||
| Pipe & Filter | X | X | X | X | X | ||
| Pub-Sub | X | X | X | X | |||
| MVC | X | X | X | ||||
| Micro-services | X | X | X | X | X | X | X |
Table: Viability of Robustness tactics and characteristics with respect to patterns
The above table gives us an idea of how some of the prominent patterns fare for implementing architecture of our case study requirements with an eye for implementing robustness. We will follow a problem and solution approach to discuss about them but to briefly describe, finding learning curve was difficult for Publish-Subscribe whereas enumerating changes and fixes was hard for MVC and Layered. Pipe and Filter wasn’t great with Fault handling mechanisms nut Microservices pretty much provided good support for most of the characteristics.
We got through the patterns mentioned above and jot down a design problem that was faced and point out how the pattern was used to solve it. In this process, the main goal is to achieve robustness which is explained through the characteristics.
Layered: This pattern is used to add levels of abstraction by dividing the system into sub-modules and structure them together in such a way that each module seems to be designed on top of the other. In our case study project, management of test run through wrapper script, performing screening and recording of device details, running and publishing results, all need to be handled at once instance. If we club all into one single module, it will be difficult to keep track of events and the user may get overwhelmed with various kinds of alerts. The solution is to take a layered approach and accomplish tasks within modules so that we can group similar tasks and the main script can enquire of their status. User only gets to know the report or any issue that may come in a formatted manner. User doesn’t have to learn all the internal modules and hence we can limit the amount he should go through. However, requirement changes could need multiple places to be modified and the same thing goes for bug fixes. So, it is not non-trivial to quantify changes or fixes. We can handle faults in this approach effectively and it can point out exactly which sub-task the error originated in. We can make resources stand-by so that if one task fails we can procure that part and allocate it to another instance. There is no alternative readily available in case the system goes down, rather we run diagnostics and re-run the application.
Pipe & Filter: This pattern is useful when we have processes responsible for providing some output which can in turn be filtered and fed into another process downstream. We can combine multiple processes in diverse set of groupings to get the desired outcome. In the case study project, we have certain related test cases to be run and they should be run in the given order. That is, the next test case should run on the environment created and data generated by its predecessor. If we try to run them parallelly or blindly run them sequentially without any regard for checking, we may end up in an unstable state and test results may also be wrong. So, we employ the pipe and filter pattern wherein we can run additional environment check after each process and filter and send data to the next test-case. It doesn’t require user to know too much apart from the corresponding input and output of the processes. As we can point out which part of the test-case running script the changes were asked for, we can list them out easily. If a test-case fails constantly for its implementation is wrong, we and find which ones are needed to be fixed. Although we can get code-coverage with exception handling, we won’t gain much with redundancy of resources as each process downstream must act on its own. If the system fails, then we re-run the application, but we know which process it failed in. Lastly, we can mark which processes achieve the requirements properly.
Publish-Subscribe: The pub-sub pattern has the principle of ‘get only what you need’. A module works as a publisher that keeps track of its subscriber modules and provides service to the corresponding ones that they have opted for. In our case study, there are multiple ways test results can be published; viz. local web server(JSON), remote file server(XML), ELK server, mongo db. When the user runs, he selects what type of reporting should be done. Based on that the parameters should be provided to the wrapper. Pub-Sub can help us evade unnecessary processing of result-data. For example, if remote file server is not selected, we don’t have to convert json into xml. We can document what are the options available to the user and he can make an educated decision when he runs the tests. Based on the type of subscription of any new requirement come or one needs changes, we know what kind of data handling need to be altered. If a report comes as distorted, we can easily compare with other forms and fix the one. There may not be any specific way to find where exactly we need to put the exception handling mechanisms. The report processing has vast implementation and errors could be in file handling or wrong subscription which are completely distinctive features. Redundant process or server may not be helpful as the user will not get the desired service. If the system fails, then we don’t get any reports. But we can find if a specific formatting or report is according to specification.
MVC: The Model-View Architecture has been a very popular pattern in medium to large projects. It basically decomposes system into three parts – the model implements the business logic, views are interfaces to the user and controllers are a means to regulate behavior. In our study, we have the user selecting the required tests in the interface, the wrapper script managing the running and the individual tests run as separate processes incorporating logic to test functionalities. MVC gives us privilege to see if there is any protocol breach in running the tests. We can also check for number of devices or servers connected. This doesn’t necessarily affect the stuff user needs to know. The changes inflicted may not be localized and bugs and propagate within a module. But the controller gives us way to handle faults and we can isolate them either tying them to interfacing or logic implementation. If the controller finds which process or server is giving errors, we can introduce alternative resources. We can even build another module which remains dormant until the application crashes and the controller can terminate it gracefully and pass the control to the failsafe module. It is cumbersome to trace requirement compliance.
Microservices: This pattern is more of a new development into the software architecture arena. It believes in grouping similar functionalities and providing independent self-sufficient components. It is particularly useful if support for various range of platforms and environments is desired. In our study, we need to deploy our server applications into different cloud infrastructure. Also, we need to run our tests targeting platforms like iOS, Android, set-top box etc. Since it abstracts features into separate service, user just needs to start the desired service and run instances. This significantly reduces learning to a bunch of commands and few instructions. Furthermore, we can segregate deployment from running which help us figuring out changes needed if client requirement changes. If a service has issues, we know which module to fix. It has good exception handling support as each service can report to the main hosting service of any part going wrong. If an instance fails, was can have a second one ready to take its place; and all of it can done automatically. The best part is if the system crashes, it’s only the micro-service and a distributed architecture helps another service take control and restart instances that are down. This very mechanism has made it very popular and compliant to user specification.
We have reviewed the patterns from our case study perspective and all of them fit to different parts of the whole project that involve formidable infrastructure.
FUTURE WORK & CONCLUSION
The longevity of robust software systems depends considerably on the time and resource spent on the design and implementation of its architecture. In general, the handling of failures is achieved using fault tolerance mechanisms within both the system’s software implementation (i.e. exception handling and possibly versions programming) and the underlying runtime system. With an architectural focus for software development, the former issue must be addressed through at least exception handling at the architectural level. Considering an elevated level of abstraction, although it is possible to use formal methods, it may not be feasible. The architectural descriptions languages (ADL) are there in the industry for quite a while. They help express the system architecture through a programming language like syntax. This is very convenient as the design can even be tested even before low-level design kicks off. Investigations can be made on existing base solutions to exception handling within ADL-based environments. The only prerequisite for the ADL is then to enable specifying the exceptions that may be raised and handled by components and connectors to at least allow for checking that exceptions will be handled, which is required for checking system robustness. However, they have been mostly limited to embedded systems and certain critical fields like avionics. Plans to extend them have been there but not much have been gained so far. For robustness, we can extend our study to attempt to quantify the core characteristics mentioned and compare them after taking more measures for the tactics. This way we can gradually improve the architecture and end up having a robust system improbable to fail.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: