Linguistic Forensic Analysis of Texts
Info: 14813 words (59 pages) Dissertation
Published: 16th Dec 2019
Tagged: Linguistics
Index
Most frequent words –Author Unknown
Most frequent words (Author A)
Most frequent words (Author B)
INTRODUCTION
To start with, I would like to define what is forensic linguistic. I would like to focus on two definitions in particular. One of the definitions is given by Mcmenamin (2002) and the other one by Coulthard and Johnson (2007). Mcmenamin stated that forensic linguistics as the ‘science study of language as applied to forensic purposes and contexts’, in other words, it is the application of the science of language (linguistics) to legal issues (i.e. the law and law enforcement). (2002, p.67) Whereas Coulthard and Johnson approach the subject from two distinct perspectives (i.e. the language of the legal process and language as evidence). Coulthard separates these into three distinct interrelated areas:
- Language and the law
- Language of the legal process
- Language as evidence
In order to accomplish this assessment, it is essential to use the ‘Language as evidence’, which means language used as proof in cases where discourse analysis is applied in documents to uncover what might have happened, for instance: bomb threats, obscene phone calls suicide notes, disputed emails, wills, text messages, authorship, and plagiarism). Notwithstanding, how can evidence from linguistics be used for the purposes of law enforcement? The two most frequent types of cases are:
- Disputed meanings
- Questioned authorship
The principal question of this analysis is to recognise or distinguish the authorship of the unknown text. Whether it belongs to Author A or Author B. Consequently, the methodological issue of this analysis is based on quantitative and qualitative analysis, which are based on the following methods: stylistic approaches, lexical richness, average sentence length and average word length
METHODOLOGY
To establish whether the unknown text given belongs to Author A or B it is essential to perform a deep analysis. As far as I know, both writers are professors in a university and they are writing for the same purpose so it is likely to see similar language markers. Therefore, we have to identify individual style markers in the unknown text and compare against both texts. According to McMenamin the analysis can be a descriptive analysis or a quantitative analysis or both. (McMenamin, 2002, p.122-123) For this assessment we will see a combination of descriptive and quantitative analysis. On one side, a descriptive analysis specify the range of variation by describing the aggregate set of all deviations and variations, at every linguistic level, for the questioned and known writings, based on the combination of markers identified from the reading analysis plus those from the concordance analysis. On the other side, a quantitative analysis determines the need for quantitative analysis of selected style markers.
To develop this analysis the following methods have been used:
Stylistic approaches
To start with, we should be aware that every person has his/her own idiolect, which the Longman Dictionary of Language Teaching and Applied Linguistics (1992) defines as:
‘’The Language system of an individual as expressed by the way he or she speaks or writes within the overall system of a particular language. In its widest sense, someone’s idiolect includes their way of communicating; for example, their choice of utterances and the way they interpret utterances made by others. In a narrower sense, an idiolect may include those features, either in speech or writing, which distinguishes an individual from others’ (p.172)
In other words, every person has way of communicating (written and oral). We all are constantly making choices when we speak or write and that choices have been key to help us to distinguish whether the text from the Unknown Author belongs to Author A or B
On the one hand Luff stated ‘’Style is not a uniform concept in language. Style in spoken language relates to linguistic variation resulting from the social context of conversation’’. On the other hand, he stated that ‘’style in written language refers to the variable ways that language is used in certain genres, periods, situations, and individuals’’.
What is more, according to Mcmenamin ‘’style is a reflection of group or individual variation in written language’’. As McMenamin stated ‘’stylistic variation as a use of different variant forms to express a similar linguistic meaning is reflected in the distinct dialects of groups who speak the same language; it thus reflects the class characteristics of speaking and writing for the subgroup, e.g. the form and function of women’s and men’s language’’. (McMenamin, 2002, p.111) Furthermore, ‘’ Stylistic variation is also reflected in the idiolect of individuals who speak the same dialect and language, thus reflecting the individual characteristics of speakers and writers. The idiolect is ‘the totality of the possible utterances of one speaker at one time in using a language to interact with one other speaker…’’ (Bloch, 1948: 7)
As McMenanimm stated ‘’ Social or physical separation of groups will result in the formation of distinct communities and microcommunities’’ (McMenamin,2002, p.116)
Social norms relate to group acceptance of language forms and uses. Examples of norms for language behaviour in communities or groups, as discussed by EcKert (1989:249), Grice (1975), Hudson (1980:116), Labov (1972:120), and Wolfram and Fasold (1974:17), include the following, which are neither exhaustive of the possibilities nor mutually exclusive:
• Prestige norms (of acceptance by upper social classes)
• Norms of social convention or necessity
• Norms of governing use of registers, varieties and other languages
• Class norms (age, sex, ethnicity, race, socioeconomic status, etc.)
• Regional norms (of geographic location)
• Circumstantial norms (of situation: purpose, topic, reader, time, place, etc.)
• Appropriate-language norms (of proper social behaviour)
• Correct-language norms (of correct linguistic behaviour)
(McMenamin, 2002, p.116)
Apart from these, we have to take into account specify style-markers that are found in all linguistic levels:
- Format or layout of these of the document itself such as margins, spacing, etc.
- Punctuation of all types
- Spelling, all the various kinds of patterned variants and mistakes
- Word formation, including inflectional variation
- Syntax (sentence structure, coordination, subordination, and punctuation)
Lexical richness
According to Laufer & Nation ‘’measures of lexical richness attempt to quantify the degree to which a writer is using a varied and large vocabulary. However, there are many factors besides vocabulary, size that could affect lexical richness in writing. These could include familiarity with the topic, skill in writing and communicative purpose. This means that a change of the topic could result in market change in lexical richness’’. (1995, p.307)
In Laufer & Nation study of lexical richness in L2 writing production, they highlighted four measures of lexical richness:
1. Lexical originality (LO)
2. Lexical density (LD)
3. Lexical sophistication (LS)
4. Lexical variation (LV)
Even though, we are going to focus on lexical density and lexical variation to accomplish this analysis.
In the first place, it is essential to comprehend what lexical density and lexical variation is.
Lexical density is defined as the percentage of lexical words in the text, i.e. nouns, verbs, adjectives, adverbs and is a useful measure of the difference between texts (e.g. between a person’s written language and their speech):
LD = (number of lexical tokens/ total number of tokens) x 100
Lexical words include lexical verbs, nouns, adjectives and adverbs.
Function words, therefore, include the remaining auxiliary verbs, numerals, determiners, pronouns, prepositions and conjunctions.
Lexical variation is the type/token ratio, i.e. the ratio in percent between the different words in a text and the total number of running words:
LV= (number of types/number of tokens) x 100
The type/token ratio has been shown to be unstable for short texts and can be affected by differences in texts length. Lexical variation is dependent on the definition of a word.
Average sentence length
According to Nordquist ‘’In English grammar, sentence length refers to the number of words in a sentence’’.
Average word length
Word length refers to the number of letters in a word.
Cusum method
As Grant stated ‘’the significance of this method is that there have not been many explicit examples of forensic methods in authorship attribution that have been presented in and accepted as forensic evidence by the courts, but this was. However, this was only for a short period of time and the method was ultimately shown to be flawed’’ (2004, p.25)
According to Grant ‘’Cusum analysis faces the problem that there is no theoretical or linguistic explanation for how it works. As Morton admits, there is no theoretical foundation to his system’’. (2004, p.33)
‘’There has no been study undertaken that could demonstrate its reliability. For example, foreign insertions into texts sometimes go unnoticed, and texts without insertions or with insertions made from other texts by the same author can produce cusum charts in which there were apparent disturbances’’. (2004, p.38)
Due to all of these reasons, I have chosen not to use cusum because it fails to identify a clearly defined marker that can be shown to discriminate reliably between authors. (Grant, 2004, p.41)
ANALYSIS
Author ‘A’
Text 1 is written in Times New Roman, size 10. The total number of words in the text is three hundred and it has eighty eight words and four paragraphs. They do not have the same length. The first paragraph has three sentences and it is composed of fifty hundred and one words but it also has a mistake because when the sentence ’The precise articulation of this dissertation comes as somewhat of a surprise’ ends the author forgot to write the stop. There is also a word in bold ‘analysis’. The second one is the shortest paragraph, it is composed of three sentences and fifty eight words. The length of the sentences are shorter than in the first paragraph. The third paragraph is the longest composed of one hundred and forty one words and five sentences. The last paragraph is composed of eighty eight words and three sentences. But in this paragraph the first sentence does not has a stop, instead we find the following: (?). What is more, the word of the beginning of the second sentence is written with capital letters – AND.
Text 2 is also written in Times New Roman, size 10. The total number of words in the text is four hundred and thirty three words and it has five paragraphs. The first paragraph has two sentences and it is composed of forty eight words. The second is the longest paragraph, which is composed of one hundred and thirty five words and seven sentences. The third one is composed of one hundred and thirty two words and five sentences. The fourth paragraph has 4 sentences and it is composed of eighty eight words. The last paragraph is the shortest, which is composed of thirty words and two sentences.
Text 3 is again written in Times New Roman, size 10. The total number of words in the text is three hundred and six and it has five paragraphs. The first one is composed of sixty one words and three sentences. The second one has eight sentences. The third one has two sentences and it is composed of thirty three words. The fourth paragraph is composed of fifty one words and three sentences. The last paragraph has one sentence composed of thirteen words.
Similarities and differences
Concerning to the total number of words in the Unknown Author texts it seems to match with Author A given that it is the one that gets closer.
Also, the number of sentences in all texts of Author B are much long than the ones written by Author A and the Unknown Author; Author A is again the one that is more similar.
The number of paragraphs are also longer in all of the three texts of Author B, while Author A and the Unknown Author are once again similar.
To start with the analysis, firstly I would like to focus on the average word length. (See graphics and table in the appendix)
The analysis done shows similarities between Author A, Author B and Unknown Author. The text that is closer to the average word length of the Unknown Author is Author B. The average word length of the Unknown Author is 4.98 while the mean of Author B is also 4.98. Although, the difference between the mean of Author A and B is not that big, we can observe that the mean of Author A is 4.87.
Secondly, the average sentence length of the texts of the three authors shows that Author A is the one with the closest result to be the Unknown Author. The results show that the Unknown Author has an average sentence length of 21.62 while Author A mean is 21.73, being the closest one to the Unknown Author.
Thirdly, we need to focus on the lexical richness of the texts. In order to do that, we need to analyse the lexical density and lexical variation.
After seeing the result of the analysis we can observe that the Lexical Density of the Unknown Author is 52.65 and the author who has the closest result to the unknown author is Author B, which has a mean of lexical density of 49.81. Although, we can observe that there is not a big difference between the mean of the Lexical Density of Author A and B. Author A has a mean of Lexical Density of 48.37 while Author B Lexical Density has a mean of 49.81.
Lexical variation shows us that Author A is the one closest to the result of the Unknown Author. The Lexical variation of the unknown text is 56.69 and of the Author A is 51.77. In this case, Author A is more likely to be the Unknown Author. On the contrary, ‘Author A’ lexical variation is 47.19, this result is further to the result of the Unknown Author.
The majority of the characteristics in the texts such as total number of words, total number of sentences and total number of paragraphs found in the text of the unknown writer are similar to the texts of Author A.
Observing the margins and font type of three texts, all of them coincide having 2.54 of margins and times new roman as font type. Therefore, these data is not significant to identify the author of the unknown text.
The paragraph spacing matches with Author A.
The use of numbering is present in the texts of Author B and in the text of the Unknown Author. The only difference is that one uses numbers and other letters.
Author A and the unknown author coincide with the same acronym, which is ST (Special Topics)
All three texts have different forms of page referencing. The Unknown author is consistent with the page referencing, while Author A and B are not consistent. But Author B and the Unknown Author use page once, while Author A uses it fifteen times.
Concerning to commas, the unknown author has 20 commas, so the Author who is closer to this number is Author A because text 1 has 18 commas, text 2 16 and text 3 23, while the number of commas that are present in texts of Author B are less (15, 5, 12). Also, the use of parenthesis is similar in text 1 of author A and the text of the unknown writer, while author B has 8 in the first text, 7 in the second and 5 in the third.
Regarding the passive voice, text three of the author A has three forms of passive voice which gets closer to the unknown author, who uses four forms of the passive voice. While, Author B uses much more forms in each text: 12 in the first text, 6 in the second and 10 in the last one.
Misspelling ua 1 ab 7
Self reference 2 / ua 4/ a5
CONCLUSION
On the one had, the qualitative analysis has shown that Author A is the autor of the unknown text. On the other hand, in some occasions the quantitative analysis was not as helpful as the qualitative analysis. This is due to the similarities in the results. To conclude, in my opinion the author of the unknown text is more likely to be ‘Author A’.
APPENDIX
Average sentence length
| Average sentence length | Author A | Author B | Unknown Author |
| Text 1 | 28.21 | 16.94 | 21.62 |
| Text 2 | 21.65 | 15.07 | |
| Text 3 | 15.35 | 17.1 | |
| Mean | 21.73 | 16.37 |
Graphics – Average sentence length
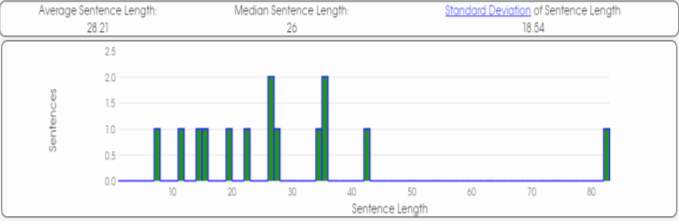
Graphic 1. Text 1 (Author A)
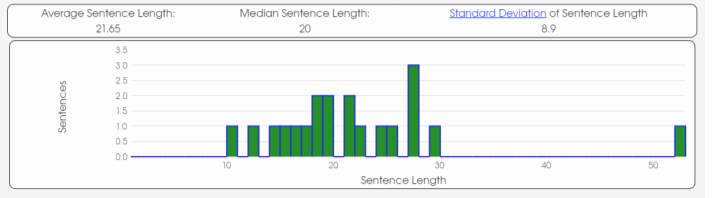
Graphic 2. Text 2 (Author A)
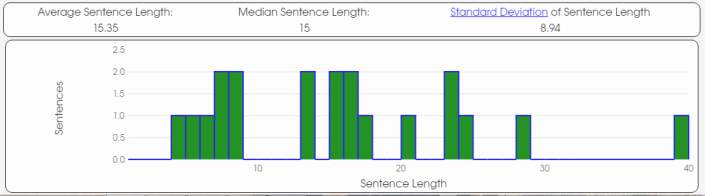
Graphic 3. Text 3 (Author A)
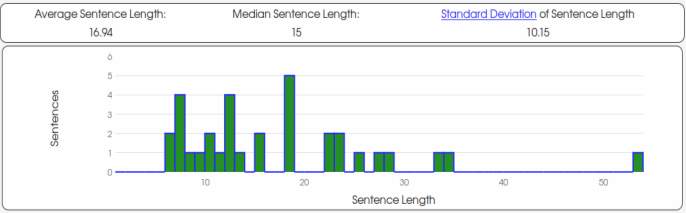
Graphic 4. Text 1 (Author B)
Graphic 5. Text 2 (Author B)
Graphic 6. Text 3 (Author B)
Graphic 7. Unknown Author
Average word length
| Average word length | Author A | Author B | Unknown Author |
| Text 1 | 4.7 | 4.91 | 4.98 |
| Text 2 | 4.93 | 4.93 | |
| Text 3 | 4.99 | 5.1 | |
| Mean | 4.87 | 4.98 |
Graphics – Average word length
Graphic 8. Text 1 (Author A)
Graphic 9. Text 2 (Author A)
Graphic 10. Text 3 (Author A)
Graphic 11. Text 1 (Author B)
Graphic 12. Text 2 (Author B)
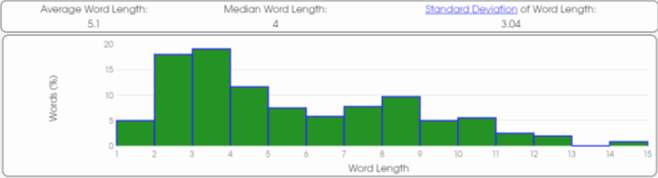
Graphic 13. Text 3 (Author B)
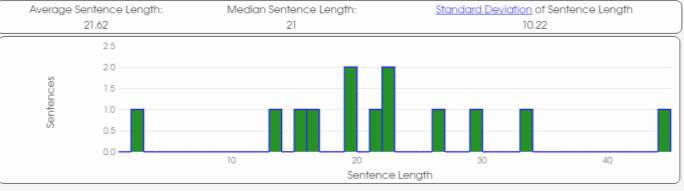
Graphic 14. Author Unknown
Lexical density and variation
| Lexical Density | |||
| Author A | Author B | Unknown Author | |
| Text 1 | 192/385 = 0.4987 x 100 = 49.87 | 282/556=0.5071 X100=50.71 | 52.65 |
| Text 2 | 202/453 = 0.4459 X 100 = 44.59 | 214/448=0.4776 X100= 47.76 | |
| Text 3 | 155/306=0.5065 X100= 50.65 | 183/359=0.5097 X100= 50.97 | |
| Mean | 48.37 | 49.81 | |
| Lexical Variation | |||
| Author A | Author B | Unknown Author | |
| Text 1 | Number of types(186) / Number of tokens (371) = 0.50 x 100 = 50.13 | Number of types(264) / Number of tokens (555) = 0.47 x 100 = 47.56 | Number of types (161) / Number of tokens (284) = 0.56 x 100 = 56.69 |
| Text 2 | Number of types (216)/Number of tokens (434) = 0.49 x 100 = 49.76 | Number of types (206)/Number of tokens (427) = 0.48 x 100 = 48.24 | |
| Text 3 | Number of types (168) / Number of tokens (303) = 0.55 X 100 = 55.44 | Number of types(303) / Number of tokens (662) = 0.45 x 100 = 45.77 | |
| Mean | 51.77 | 47.19 | |
Stylistic approaches
Unknown Author
| UNKNOWN AUTHOR TEXT | |
| TOTAL NUMBER OF WORDS | 281 |
| TOTAL NUMBER OF SENTENCES | 12 |
| TOTAL NUMBER OF PHARAGRAPS | 5 |
| STYLISTIC APPROACHES | |
| FORMAT | |
| MARGINS | 2,54 cm (Top, left, bottom and right) justified |
| FONT TYPE | Times New Roman (Body) |
| FONT SIZE | 12 |
| PARAGRAPH & LINE SPACING | 1,15 |
| VARIATION IN FORMAT | EXAMPLES |
| PARAGRAPH 1-3 SPACES: 4 | |
| BOLDING FOR EMPHASIS: 1 | However, I did think that to devote just two to three pages to this strategy at text level towards the end of the dissertation. |
| NUMBER AND SYMBOLS | EXAMPLES |
| NUMERALS 1-10 INSTEAD OF NUMBER-WORDS: 1 | Chapter 4 |
| USE OF NUMBERING (i), (ii): 3 | (ii) the B&B brochure as a marketing tool |
| ABBREVIATIONS | EXAMPLES |
| ALL CAPITAL LETTER ABBREVIATIONS: 4 | (iii) the relevance of functional and communicative translation theories. Chapter 4, in which the STs and writer’s TTs are presented…
The commentary section is based on the key elements of B&B brochures, which again allows the writer to structure coherently what she presents to the reader. |
| PAGE REFERENCING: 1 | However, I did think that to devote just two to three pages to this strategy at text level towards the end of the dissertation, pages 73,74,75
|
| CHARACTERISTIC USAGE OF NUMBER-WORDS: 2 | However, I did think that to devote just two to three pages to this strategy at text level… |
| USE OF ORDINALS: 1 | The writer has come a long way since submitting her first major assignment. |
| PUNCTUATION | NUMBER PER TEXT |
| COMMAS | |
| TOTAL NUMBER OF COMMAS | 20 |
| COMMA SPACING: 17 | 1 space after;
As a result, her prose style, though not perfect, is sufficient to enable uninterrupted reading. |
| SEMICOLON | |
| TOTAL NUMBER OF SEMICOLONS | 0 |
| COLON | |
| TOTAL NUMBER OF COLONS | 0 |
| QUESTION | |
| TOTAL NUMBER OF QUESTION MARKS | 0 |
| DASH (HYPHEN) | |
| TOTAL NUMBER OF HYPHENS | 0 |
| DASH TO SEPARATE JOINED COMPUND WORDS | |
| 0 | |
| QUOTES | |
| TOTAL NUMBER OF QUOTE MARKS | 0 |
| QUOTES AROUND PHRASES | 0 |
| APOSTROPHE | |
| TOTAL NUMBER OF APOSTROPHES | 3 |
| INSTRUCTIVE APOSTROPHES: 3 | EXAMPLES |
| ‘The writer’s thesis is that promotional texts of this kind require a hybrid creative translation strategy’
‘Her English proficiency has significantly improved thanks to the efforts she has made with the support of the University’s Academic Skills Unit’ |
|
| APOSTROPHES FOR EMPHASIS | 0 |
| PARENTHESIS | |
| TOTAL NUMBER OF PARENTHESIS | 3 |
| SYNTAX | |
| PASSIVE VOICE: 4 | EXAMPLES |
| ‘the guidance which was provided with particular regard to structuring and exemplification’.
‘Chapter 4 in which the STs and writer’s TTs are presentedis followedby a full discussion of key translation issues’. |
|
| OTHER STILYSTIC APPROACHES | |
| MISSPELLING: 1 | ‘The analysis is accompanied by a numerous examples, the quality of which is assessed by the second marker, a Chinese native speaker’ |
| SELF-REFERENCE: 4 | EXAMPLES |
| ‘I did think, to which I referred earlier’
‘the writer takes us’ ‘she presents to the reader’ |
|
Most frequent words –Author Unknown
| Author unknown | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | 7 | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
Author A
| AUTHOR A | |
| TEXT 1 | |
| TOTAL NUMBER OF WORDS | 385 |
| TOTAL NUMBER OF SENTENCES | 14 |
| TOTAL NUMBER OF PHARAGRAPS | 4 |
| TEXT 2 | |
| TOTAL NUMBER OF WORDS | 453 |
| TOTAL NUMBER OF SENTENCES | 20 |
| TOTAL NUMBER OF PHARAGRAPS | 5 |
| TEXT 3 | |
| TOTAL NUMBER OF WORDS | 306 |
| TOTAL NUMBER OF SENTENCES | 14 |
| TOTAL NUMBER OF PHARAGRAPS | 5 |
| STYLISTIC APPROACHES | |
| FORMAT | |
| PARAGHRAPH SPACING | Text 1: 3
Text 2: 4 Text 3: 4 |
| MARGINS | 2,54 (Top, left, bottom and right) justified |
| FONT TYPE | Times New Roman (body) |
| FONT SIZE | 10 |
| LINE AND PARAGRAPH SPACING | 1.0 |
| DOUBLE SPACING | 2 |
| VARIATION IN FORMAT | EXAMPLE |
| FONT TYPE: use of bold | analysis (line 4) |
| CAPITAL LETTERS FOR WORD EMPHASIS | AND that no explanation is given |
| NUMBERS AND SYMBOLS | EXAMPLE |
| NUMERALS INSTEAD OF NUMBER-WORDS | 90 pages; 350 word per page; 12,000 to 15,000 words |
| ORDINAL NUMBERS | First |
| PERCENTAGE | 50% |
| ABBREVIATIONS AND ACRONYMS | EXAMPLE |
| ABBREVIATIONS IN ALL LOWER CASE LETTERING | e.g. (exempli gratia) ; i.e (id est) |
| ACRONYMS: 2 | TM (Trados); ST(Special Topics) |
| DIFFERENT ABRREVIATION TO GIVE EXAMPLES | e.g. (exempli gratia) ; i.e (id est) |
| GENERAL USE OF ABBREVIATIONS | Approx. (approximately); e.g. (exempli gratia) |
| PUNCTUATION | EXAMPLE |
| NO PUNCTUATION AT THE END OF THE SENTENCE | The precise articulation of this dissertation comes as somewhat of a surprise |
| PAGE REFERENCES: variation within the text | pages 86 to 91; (p.38); (page 22) |
| PARENTHESIS: 7 | Text 1: 2
Text 2: 5 (sections 6.1 and 6.2); (trados) |
| COMMAS: 57 | Text 1: 18 commas
Text 2: 16 commas Text 36: 23 commas |
| LONG DASHES: 7 | Most of it is taken up with terminology – pages 86 to 91, a total of fives pages |
| COMMA BEFORE SUBORDINATE CLAUSE: 2 | (There is simply not enough evidence to support to writer’s contention that cultural elements constitute an element of technical translation, of which the translator should be aware.); (For a resubmission the student will be required to produce a new version of Chapter 6, taking the above points into account.); (Significantly the findings concur with those of a similar dissertation, which suggests that the methodology applied by the writer was fit for purpose.) There is an instance of subordination without a comma observed line 22 |
| SEMI-COLONS AND COLONS | text 1: semi-colon (1) colon(1)
text 2: semi-colon (0) colon(1) text 3: semi-colon (2) colon(0) total semi-colons: 3 total colons: 2 |
| SUSPENSION POINTS | more rigour and objectivity.. |
| APOSTROPHE: 7 | Text 1: 2
Text 2: 5 Atril’s; reader’s; writer’s |
| QUESTION MARK: 1 | for the parallel texts (?) |
| QUOTES | EXAMPLE |
| QUOTES AND QUOTATION MARKS | Text 2: 1 (double quotation mark) |
| QUOTES AROUND SINGLE WORDS | ‘technical translation’ and ‘culture’ |
| SYNTAX | EXAMPLE |
| PASSIVE VOICE: 22 | Text 1:
‘…the ways in which cultural elements are articulated in technical translation and an analysis of…’. ‘While this shape has been retained the space allocated to the various sections of the dissertations was not expected’. ‘Of the 90 pages devoted to the dissertation some 60 are taken up by the corpus…’. ‘The highly limited investigation of a substantial corpus and it should be noted that no details on the texts are provided beyond a list of website addresses for the st and a list of…’ ‘And that no explanation is given as to why these texts in particular were selected means that the dissertation cannot be accepted as a pass’. ‘For a resubmission the student will be required to produce a new version of chapter 6 taking the above points into account’. Text 2: ‘The writer’s command of English is very good and communication with the reader is generally not impeded’. An example is provided on page 5 where the writer is reporting on Trados’ adoption of Atril’s integrated approach’. ‘Expressions like huge mistake’ p 38 and not to be sneezed at’ p 40 also suggest that an academic writing style is not consistently maintained’. ‘The lack of rigour is manifested elsewhere in the dissertation’. ‘However no attempt is made to correlate the purported lesser use of tm by women…’ ‘So for example the geographical location of the respondents is pinpointed on page 20 but…’ ‘Greater, rigour could have been achieved through better use of concluding summaries at the end of key chapters’. ‘And the same applies to chapter 3 where a linking section between the report on the findings of the survey and the interviews would have been welcome’. ‘The methodology employed is basically sound but could have been applied with more rigour and objectivity’. Text 3: ‘…the quotation on page 26 appears to be misquoted’. ‘Could the dissertation be improved?’ ‘Well yes the data provided could have been more detailed more use could have been made of tables and of appendices for example’. |
| OTHER STYLISTIC APPROACHES | EXAMPLE |
| MISSPELING | fives pages; worrying; rigour |
| SELF REFERENCE | As a reader I; I suppose; we referenced 3 times |
Most frequent words (Author A)
| Author A (Text 1 ) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | 7 | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
| Author A (text 2) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
| Author A (text 3) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 30 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 48 | 8 | pages |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | t | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
Author B
| AUTHOR B | |
| TEXT 1 | |
| TOTAL NUMBER OF WORDS | 556 |
| TOTAL NUMBER OF SENTENCES | 33 |
| TOTAL NUMBER OF PHARAGRAPS | 9 |
| TEXT 2 | |
| TOTAL NUMBER OF WORDS | 421 |
| TOTAL NUMBER OF SENTENCES | 27 |
| TOTAL NUMBER OF PHARAGRAPS | 8 |
| TEXT 3 | |
| TOTAL NUMBER OF WORDS | 359 |
| TOTAL NUMBER OF SENTENCES | 21 |
| TOTAL NUMBER OF PHARAGRAPS | 5 |
| STYLISTIC APPROACHES | |
| FORMAT | |
| MARGINS | 2,54 cm (Top, left, bottom and right) justified |
| FONT TYPE | Times New Roman (Body) |
| FONT SIZE | 10 |
| PARAGRAPH & LINE SPACING | 1,0 |
| VARIATION IN FORMAT | EXAMPLES |
| PARAGHRAP SPACING 1-3 SPACES: 19 | Text 1: 8
Text 2: 7 Text 3: 4 |
| BLODING FOR EMPHASIS: 1 | (Student name) has submitted a first class dissertation which shows a detailed grasp of context, literature and method. |
| NUMBER AND SYMBOLS | EXAMPLES |
| NUMERALS 1-10 INSTEAD OF NUMBER-WORDS: ON PAGE 2; ON PAGE 6. | The format is fine but this reader would have liked to see (1) more sources used before identifying the ‘gap’ on page 2; and (2) perhaps 200 words on the history of Taiwan.; Another tension in the text is the relationship between WTC, exams and speaking (this begins of page 6) |
| USE OF NUMBERING: (1), (2): 1 | The format is fine but this reader would have liked to see (1) more sources used before identifying the ‘gap’ on page 2; and (2) perhaps 200 words on the history of Taiwan. |
| USE OF FIGURES FOLLOWED BY A NOUN: 1 | …and (2) perhaps 200 words on the history of Taiwan. |
| NUMERALS IN PARENTHESIS WITH NO ACCOMPANYING WORDS: 1 | The personal thread may explain a sense of frustration in the findings (4.1.2). |
| ABBREVIATIONS | EXAMPLES |
| ALL CAPITAL LETTER ABBREVIATIONS: 2 | The dissertation looks at the constructs of motivation, WTC, anxiety and SPCC and applies them to his students at a university in Taiwan. |
| NONSTANDARD ABBREVIATION: 4 | Although the research is sensitive to the context in the most part in is here (p28) that the particularity of… |
| ABBREVIATIONS IN ALL LOWER CASE LETTERING: 12 | There are also occasions where more discussion (and showing the diagrams) of the models would have aided in the explanations (e.g. p12). |
| USE OF THE ABBREVIATION INSTEAD OF THE FULL WORD: 4 | The summary on p19 and p20 was a very useful digest of the earlier specialised and technical discussion. |
| PAGE REFERENCING: 8 | 1. identifying the ‘gap’ on page 2
2. explanations (e.g. p12) 3. exams and speaking (this begins of page 6). 4. The summary on p19 and p20 5. description of the participants (p.27) 6. the most part in is here (p28) |
| PUNCTUATION | NUMBER PER TEXT |
| COMMAS | |
| TOTAL NUMBER OF COMMAS: 32 | Text 1: 15 commas.
Text 2: 5 commas. Text 3: 12 commas. |
| COMMA SPACING: 32 | 1 space after;
Text 1: 15 Text 2: 5 Text 3: 12 |
| SEMICOLON | |
| TOTAL NUMBER OF SEMICOLONS: 3 | Text 1: 2 semicolons.
Text 2: no semicolons. Text 3: 1 semicolon. |
| COLON | |
| TOTAL NUMBER OF COLONS: 1 | Text 1: no colons.
Text 2: 1 colon. Text 3: no colons. |
| QUESTION | |
| TOTAL NUMBER OF QUESTION MARKS: 2 | Text 1: no question marks.
Text 2: 2 question marks. Text 3: no question marks. |
| DASH (HYPHEN) | |
| TOTAL NUMBER OF HYPHENS: 5 | Text 1: 2 hyphens.
Text 2: 3 hyphens. Text 3: no hyphens. |
| DASH TO SEPARATE JOINED COMPUND WORDS: 5 | EXAMPLES |
| Nevertheless, there is a clear suggestion that the student has provided a solid and well-meaning structure to a difficult problem. | |
| QUOTES | |
| TOTAL NUMBER OF QUOTE MARKS: 8 | Text 1: 4 quote marks.
Text 2: 4 quote marks. Text 3: no quote marks. |
| QUOTES AROUND PHRASES: 8 | EXAMPLES |
| …the particularity of the participants becomes most evident [the argument that they are at “the top of their game” is debatable;… | |
| APOSTROPHE | |
| TOTAL NUMBER OF APOSTROPHES: 9 | Text 1: 5 apostrophes.
Text 2: 4 apostrophes. Text 3: no apostrophes. |
| INSTRUCTIVE APOSTROPHES: 3 | EXAMPLES |
| The results section is impressive and seems to reflect the student’s strengths with text analysis. | |
| APOSTROPHES FOR EMPHASIS: 6 | EXAMPLES |
| …but this reader would have liked to see (1) more sources used before identifying the ‘gap’ on page 2;… | |
| PARENTHESIS | |
| TOTAL NUMBER OF PARENTHESIS: 20 | Text 1: 8 parentheses.
Text 2: 7 parentheses. Text 3: 5 parentheses. |
| PARENTHESES ONLY AROUND EXAMPLES OR NOTES: 4 | EXAMPLES |
| There are errors in terminology (e.g. stratified). | |
| PARENTHESES IN THE PLACE OF COMMAS: 5 | EXAMPLES |
| This is a bold and structured approach to a longstanding educational problem (evaluating new materials) applied to… | |
| PARENTHESES TO ENCLOSE PHRASE OR SENTENCE: 3 | EXAMPLES |
| This contributes to (or may be a consequence of) the methodological limitations. | |
| PARENTHESES TO ENCLOSE SINGLE WORDS: 1 | EXAMPLES |
| and (importantly) ones on second language learning. | |
| SQUARE BRACKETS FOR NOTES: 1 | EXAMPLES |
| …the particularity of the participants becomes most evident [the argument that they are at “the top of their game” is debatable; that if they are anxious then anxiety is a “grave problem for all” more so. | |
| SYNTAX | EXAMPLES |
| USE OF PASSIVE VOICE: 28 | Text 1: 12
Text 2: 6
Text 3: 10
|
| OTHER STYLISTIC APPROACHES | EXAMPLES |
| MISSPELLING: 7 | The use of apostrophe is missed on: ‘these variables for the target students needs more explanation’ it should be ‘these variables for the target students’ needs more explanation.’; Less space is given to pedagogical implications than might have been expected in a dissertation inspired by a enthusiasm to improve teaching. |
| SELF REFERENCE: 2 | The format is fine but this reader would have liked to see (1) more sources used before identifying the ‘gap’ on page 2; and (2) perhaps 200 words on the history of Taiwan.; All that said, I was impressed, on a page by page basis, in the level of understanding, |
Most frequent words (Author B)
| Author B (text 1) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | 7 | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
| Author B (text 2) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | 7 | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
| Author B (text 3) | ||
| Rank | Frequency | Word |
| 14 | 23 | dissertation |
| 17 | 22 | writer |
| 19 | 18 | research |
| 23 | 16 | text |
| 27 | 15 | page |
| 28 | 15 | student |
| 30 | 13 | texts |
| 32 | 11 | approach |
| 36 | 10 | number |
| 40 | 9 | section |
| 46 | 8 | chapter |
| 49 | 8 | translation |
| 54 | 7 | method |
| 57 | 7 | study |
| 58 | 7 | terms |
| 59 | 6 | analysis |
| 64 | 6 | example |
| 66 | 6 | genre |
| 67 | 6 | literature |
BIBLIOGRAPHY
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Linguistics"
Linguistics is a field of study that explores the science of languages and their structures. Linguistics covers how factors such as history, culture, society, and politics, amongst other elements, can have an impact on language.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: