Web Browser Fingerprinting Effect on Privacy
Info: 25499 words (102 pages) Dissertation
Published: 27th Jan 2022
Abstract
Millions of users across the online community access an abundance of available free services and information from various websites on a daily basis. And while providing these services websites track and profile their users. This ability to track can be lucrative for businesses but intrusive for the privacy of a user. This dissertation investigates and describes the concept of web browser fingerprinting and its effect on user privacy. This paper examines the role browser fingerprinting plays in the real world as well as providing an in depth look at the technology, techniques and countermeasures associated with fingerprinting. This paper also analyses the effectiveness of browsers add-ons/extensions when attempting to protect a user or system from fingerprinting. In addition, exploring the evolution of technology, and the strength of mobile devices at resisting fingerprinting in comparison to desktops.
Table of Contents
Click to expand Table of Contents
Chapter 1
1.1 Introduction
1.2 Aims of research
Chapter 2
2.1 Web Browser Fingerprinting
2.1.1 Passive fingerprinting
2.1.2 Active fingerprinting
2.1.3 Cookies for Everyone
2.1.4 Private mode and Do not track
2.2 Identifying browser fingerprints
2.3 Real world use of Fingerprinting
2.3.1 Protection against fraud
2.3.2 Paywalls
2.3.3 Advertising, analytics and behavioural tracking
2.3.4 Protection of HTTP sessions
Chapter 3: Security, Privacy and EU Policy
3.1 Current culture on Privacy
3.2 Detection and Prevention
3.3 Laws and Policy protection privacy
3.3.1 ePrivacy Directive
Chapter 4
4.1 Fingerprinting technologies and techniques
4.1.1 Canvas Fingerprinting
4.1.2 Browser specific fingerprinting
4.1.3 JavaScript Engine and JavaScript fingerprinting
4.1.4 Cross-browser Fingerprinting
4.2 Evasive methods and Circumventing Fingerprinting
4.2.1 Fingerprinting paradox and establishing a baseline
4.2.2 Tor
4.2.3 Browser Add-ons and Extensions
4.2.4 Countering JavaScript Fingerprinting
4.2.5 Countering Canvas Fingerprinting
4.2.6 Other methods
4.3 Mobile Fingerprinting
4.3.1 Sensory Fingerprinting
4.4 The evolution of web technologies and browser fingerprinting
4.4.1 End of Flash
4.4.2 The end of browser plugins
4.4.3 Standardized HTTP headers
4.4.4 Reduce the surface of HTML APIs
4.4.5 Increase common defaults
Chapter 5 :Analysis of browser add- ons/extensions on multiple browsers
5.1 introduction
5.1.2 Testing websites.
5.1.3 Configuration of system, Browsers and Add-ons
5.1.4 Test Cases
5.1.6 Procedure
5.2 Test case Results
5.3 Discussion
5.3.1 The Results
5.3.2 Analysing the effectiveness of add-ons
5.4 Related work
5.5 Fingerprinting of Add-ons/Extension
5.6 Limitations
Chapter 6
6.1 Conclusion
6.2 Limitations
6.3 Implications of the research
Bibliography
Appendices
List of figures & tables
Chapter 1
Figure 1: storage of cookies
Chapter 2
Table 2-1:Browser measurements include in the Panopticclick fingerprint
Table 2-2: Properties that are static or dynamic
Table 2-3- Returning browser comparison tests
Table 2-4: list of attributes used in amIunique fingerprinting
Table 2-5: entropy values for six values collected by Panopticclick and AmIUnique
Chapter 4
Table 4-1: fingerprinting methods and attribute associated with them
Table 4-2: HTTP Headers
Table 4-3: Attributes within JavaScript that can be used for fingerprinting purposes
Table 4-4: List of feature that can be used to obtain a fingerprint
Table 4-5:Values modified by the Modheader
Table 4-6: information leakage for each attribute
Figure 4-1: mobile user agent
Figure 4-2: NPAPI support over different browser versions
Chapter 5
Figure 5-1: Current market share
Table 5-1: Versions and figures as of July 2017
Table 5-2: add-ons used
Table 5-3: Chrome browser – 18.94 bits of identifiable information
Table 5-4: Firefox Browser – 18.93 bits of identifiable information
Table 5-5: Tor browser 12.17 bits of identifiable information
List of abbreviations & acronyms
Browse A term used to describe a user’s movement across the web, navigating from page to page, using a browser
Browser A software program used to access webpages
Cookie Small data files written to computer and used by websites to remember information that can be used by a returning visitor
HTTP The protocol used by webservers to format pages that are displayed by web browsers
JavaScript A scripting language originally developed by Netscape, that runs from within the browser on the users computer
Website A collection of related web pages
Chapter 1: Introduction
1.1 Introduction
In July 1993, The New Yorker published a cartoon by Peter Steiner that depicted a Labrador retriever sitting on a chair in front of a computer, paw on the keyboard, as he turns to his beagle companion and says, “On the Internet, nobody knows you’re a dog.” Two decades later, interested parties not only know you’re a dog, they also have a pretty good idea of the color of your fur, how often you visit the vet, and what your favorite doggy treat is [1].
Tracking user activity as they browse through websites as been a part of the web surfing experience for decades. Companies have colluded with each other to collect vast amounts of data based on our web browsing patterns. The idea is to utilise this data to customise your experience and essentially build user profile tailored to you[2]. This user profile can be quite telling, it may contain information on your location, income, interests, activities and various other information that you may not wish to divulge [3]. This is a serious threat to privacy as shown by recent studies [4], [5]. Maintaining a high level of privacy becomes harder when you have an unwanted big brother peering over your shoulder.
The main and earliest approach to tracking online activity was cookies, which was implemented in the Netscape navigator in the early 90s. Since their inception, cookies have been at the forefront for every web browser for storing user data and linking user’ page visits across time[4], [6]. Some users may find this as a benefit as it can eliminate the need for a user to repeat multiple steps when visiting the same page repeatedly. The problem arises when websites and third parties have used cookies to stealthily track a user and their browsing habits to their own gain.
Cookies have been the go tool used to collect data. As technology improves, users become more privacy conscious, vendors aid this by designing and implementing browsers that are more resistant to tracking. In response to this companies have developed techniques which will circumvent these secure measures placed by vendors and users [7]. Enter Web browser fingerprinting. The technologies and tracking mechanisms used within area make it a formidable foe for users. It’s hard to detect, leaves little to no trace of existence and some of the most prominent tracking techniques developed have been proven to be very resilient to blocking or deletion [8], [9].
Fingerprinting can be used to uniquely identify specific user’s computer by using a combination of attributes. These fingerprints can be so specific that it can lead to the identification of a user, whether cookies are present or not, regardless of who the user pretends to be [9]. Fingerprinting can be used constructively, and to a user’s benefit within such areas as fraud detection [4], [10]. This is accomplished by detecting that a user attempting to login, is likely an attacker using stolen credentials or cookies. The downside is that the data can be used to track a user across multiple websites without their knowledge and without a way to opt out. At the extreme end data can be collected and sold to various entities [7].
There are many reasons why users may want to conceal their identity online these can range from concerns about personal safety, discrimination from the content that has been viewed online and surveillance. When the data collected from a fingerprint is correlated with some personal identifiable information an attacker, application or service provider will be able to unveil an otherwise anonymous user. With the rise of online activities and social interactions the amount and the type of information that users’ inject into cyberspace, across the worlds multiple networks is vast and varied. This would raise concerns when it comes to users protecting their privacy and their anonymity when browsing. Vendors have recognised the need for better security and so have users, as can be seen by the increasing popularity of browser plugins/extensions such as Ghostery, adblock and many others [6], [4]. Features such as ‘private mode’ available in various web browsers also help user to avoid jeopardizing their privacy by effectively stopping cookies for tracking activities. Various entities have recognised this, using web browser fingerprinting techniques to circumvent blockades put in place by vendors and users.
1.2 Aims of research
The aim of this research is to investigate the affect web browser fingerprinting has on user privacy and whether there are methods that will reduce the effectiveness of fingerprinting, provide more transparency with regards to web tracking and tracking techniques. Furthermore I aim to investigate ways to completely circumvent fingerprinting to protect user privacy.
To meet this aim I will have to achieve the following sub objectives:
1) Define what web browser fingerprinting is and establish the level of difficulty required to build a unique fingerprint to track a user.
2) Determine and analyse the current security culture centered around browser security and privacy.
3) Identify technology, techniques and tools used for fingerprinting and tracking. Identify what information contributes to a unique fingerprinting. Then evaluate the usefulness of the information gathered.
4) Discuss real world applications of web browser fingerprinting and discuss the role of privacy with these realms.
5) Analyse what the law states with regards to web tracking and delve into the polices set out to protect users.
6) Explore and recommend countermeasure and evasive techniques that can be utilised to combat web browser fingerprinting.
Chapter 2
2.1 Web Browser Fingerprinting
So you are a security conscious user and you’ve read about the potential privacy concerns expressed about allowing your browser to track you. You have the knowhow and ability to protect yourself by deleting cookies eliminating future tracking from them. But a detectable tracking method is lying in wait ready to invade your system unknown as browser fingerprinting.
Browser Fingerprinting is a method of tracking web browsers with the aim of building a unique profile which identifies a specific system/user. Instead of using traditional tracking methods like cookies and IP addresses, fingerprinting is able to use the configuration and settings information which is made visible to websites[5], [11]. The moment you visit a website, everything will appear normal on the surface but in the background your browser will automatically broadcast information about itself to the website it is visiting. This website may contain a third-party tracker such as advertisers embedded in the site or a script buried in the source code. Now you’re on the site, analysis of your browser is able to be executed using JavaScript, Flash or various other methods [8]. Predetermined attributes will be looked up, these may include screen resolution, font installed, plugins/extensions you have associated with the browser you are using, language you’ve set and many other attributes [3], [6]. All this information is compiled together to create a profile of you which is tied to characteristics presented by the browser used, rather than tied to specific cookie which can be erased at any time by the user. While a user may remain pseudonymous, a collection of all this information can allow a tracker to build a personal dossier of websites you visit as well as a behavioral profile.
This following sections discuss the main types of fingerprinting. It provides an overview of the separate groups related to fingerprinting and how these impact the tracking of a user. It details the role cookies play in tracking and the current measures employed by web browser vendors to protect users.
2.1.1 Passive fingerprinting
This method of fingerprinting involves tracking users without executing code on the client side or altering their browser. An attacker or interested party can eavesdrop on a user, observing the information their browser contains in its protocol headers (HTTP, TCP IP) when sending requests to a website.
Passive fingerprinting typical involves cookies sent in HTTP requests. Tucked within these headers will be information that identifies the browser, version and operating system. This is contained within the User Agent string. Having a user’s IP address and user agent string will go a long way to uniquely identifying a user.
2.1.2 Active fingerprinting
Active Fingerprinting involves executing code on the client side to learn about additional characteristics not obtained from passive methods. The key difference between the two is that active fingerprinting may have a chance at being detected on the client side. Active fingerprinting techniques can vary and can be executed to perform an array of tasks including enumerating font or plugins, evaluating performance characteristics, or rendering graphical patterns. Some of these are discuss in later chapters.
2.1.3 Cookies for Everyone
The cookie can be a useful resource for both user and websites. This small text file can store passwords, remember website preferences but ultimately is used as a way of identification amongst millions of internet users.
As awareness has risen about tracking in the online community, users have begun to delete, block or somehow control cookie behavior. Most modern day browsers have in-built feature allowing management of cookies. Once cookies started being manipulated companies started looking for other methods of uniquely identifying individuals to collect data or push content. One way has been with supercookies. Which is an umbrella term for any enhanced cookie which is difficult to delete or require specialised tool for removal.
The EU Cookie law states that consent has to be given explicitly by the user for cookies to be placed on their machine [12]. Often users will accept as some websites won’t allow you to utilise the site fully without first accepting.
With the ability for user to delete HTTP cookies quite easily new methods have been developed to continue tracking. Mika A. Ayenson introduced the zombie cookie [6], [13]. Zombie cookies do not operate like normal cookies and store information locally but instead use different locations on a machine to storage itself in the form of Flash cookies and HTML5 storage. When a user deletes cookies from local storage, zombie cookies can be used to resurrect them once the user revisits a site the cookie belongs to. This allows tracking to continue unaffected. The cycle with only end if the zombie is also deleted from machine.
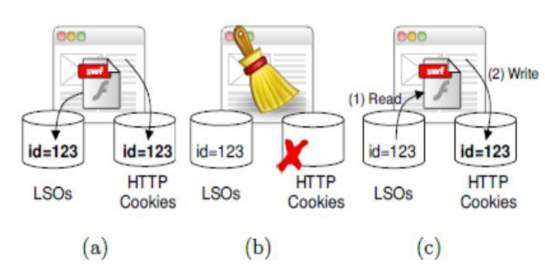
Figure 1: storage of cookies
- Both types of cookies are store by webserver
- User erases HTTP cookie
- HTTP cookie recreated from flash cookie
Browser fingerprinting bypasses the weakness of cookies by collecting information and leaving little to no trace of its existence. It is able to accurately identify a user via a range of browser attributes and system configuration settings [2], [6], [9], [11]. With the methods and technology available, browser fingerprint is the future of tracking.
2.1.4 Private mode and Do not track
With tracking and identification becoming more advanced over the years, vendors had to find a way to provide some protection for the users of their browsers. Almost all modern browsers support privacy mode also known as incognito mode in Chrome browsers. The main purpose of these modes is to hide the activity of a user by not recording information like history. This proved effective for the first generation of tracking methods i.e. cookies but with the birth of fingerprinting, private mode has shown to be completely ineffective.
Every time a computer requests information over the Web, the request begins with some short pieces of information called headers. These headers include information about the browser and its environment. Do not track (DNT) is simply a HTTP header which is available in most modern-day browsers. DNT is a combination of technology and policy aimed at allowing a user to choose whether to be tracked or chose to opt out. Because the DNT signal is a header, and not a cookie, it’s possible to delete cookies without affecting the do not track flag. The aim of DNT was to reduce the level of tracking present in the online community but to date not every website has to acknowledge the DNT header and its generally ignore.
2.2 Identifying browser fingerprints
Millions and millions of users are online each day using the most popular web browsers of today chrome, Firefox, internet explorer, safari. It’s easy to assume that you’re just another faceless person in the crowd when everyone is using the same browser as you.
2009 was the first time a discussion on the topic of using browser attributes combined with other information to develop a fingerprint was brought to the public’s attention[14]. Mayers view was that users have the ability to customise the systems, these actions had the potential to make a browser quite unique and using JavaScript as a tool to access that information, a fingerprint could be created. Mayer et al also showed additional ways to deanonymize browsers, including the obtaining of lists of pre-installed objects[14].
Mayer’s research [14] was further cemented when Peter Eckersley conducted a study in 2010 [11] which it showed it was indeed possible to track a user using JavaScript to obtain a list of various browser attributes, which include the browser user string agent, installed plugins, and screen resolution. These are exposed by the browser to JavaScript via the browser object model, specifically the navigator object. Eckersley was able to take advantage of the fact that HTTP headers give out information when sending requests to sites shown in table 4-1. This would reveal more information about user’s browser such as media type supported and the user agent, which reveals the browser type, version and platform. At the top of the list of most identifiable attributes is fonts installed as they tend to be machine specific. In the study, Flash and java was used to obtain a list of fonts. Eckersley was able to identify a majority of the 470,000+ users at the point his Panopticlick (open source web fingerprinting tool) project was made public[15]. 84% of the tested browsers produced unique fingerprints (94% if you count those that supported Flash or Java)
According to the EFF’s research [11], your browser fingerprint is likely to be very distinct indeed
“In this sample of privacy-conscious users, 83.6% of the browsers seen had an instantaneously unique fingerprint……..if we pick a browser at random, at best we expect that only one in 286,777 other browsers will share its fingerprint. Among browsers that support Flash or Java, the situation is worse … 94.2% of browsers with Flash or Java were unique in our sample” [11].
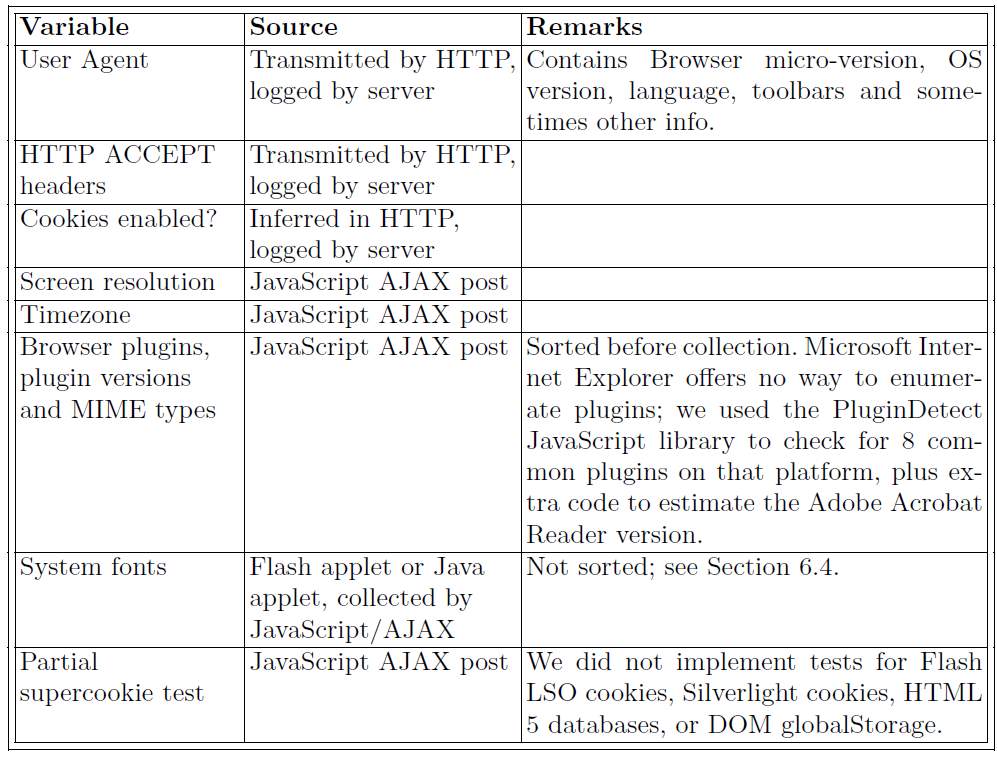
Table 2-1:Browser measurements include in the Panopticclick fingerprint [11]
Nikiforakis [1] expanded on the original 2010 study and looked into the code of three fingerprinting providers. According to [1] “The results were rather chilling. The tactics these companies use go far beyond Eckersley’s probing’s. For instance, we found that one company uses a clever, indirect method of identifying the installed fonts on a user machine, without relying on the machine to volunteer this information, as Eckersley’s software did.
We also discovered fingerprinting code that exploits Adobe Flash as a way of telling whether people are trying to conceal their IP addresses by communicating via intermediary computers known as proxies. In addition, we exposed Trojan horse–like fingerprinting plug-ins, which run surreptitiously after a user downloads and installs software unrelated to fingerprinting, such as an online gambling application” [1].
The results show that several websites use fingerprinting methods and even when the user selects Do Not Track (which explicitly tells a site that they prefer not to be tracked) users still get fingerprinted.
Another study conducted in 2011 [16] noticed a drawback in the Panopticlick project [11], its reliance on browser instances and either Flash or Java must be enabled to get the list on installed fonts. The solution was simple; omit browser specific details and use a combination of JavaScript and some basic system font to identify a certain amount of attributes. These would include details of the OS, screen resolution, fonts that are browser independent and the first octets of an IP address. Out of the 989 participants this study was able to identify 28% using multiple browsers on the same system. They were able to create unique fingerprints of the browsers as well as having the ability to track users across browsers. Using the technique Boda et al was able to increase the entropy of the whole fingerprint from 18.1 (obtained from Eckersley 2010 study) to 20.29 [6], [11].
Research continued in 2012 [9] where a site was created which attracted 1124 visitors, Letmetrackyou.org aided Broeninks research into detecting returning browsers. Broeninks highlighted that within the browser environment there would be things that were static and some which were dynamic shown in table 2-2. This lead to an algorithm being introduced to look for such attributes, these would include for example, the browser name and OS which wouldn’t change but the fonts install could increase and the available plugins could change. The algorithm was able to detect 86% of returning users over time. The data suggested that the screen size attribute was a wildcard and the types of screens being used varied from laptops to monitors to overhead projectors. It was still shown that the inclusion of this attribute helped improve the results [9].
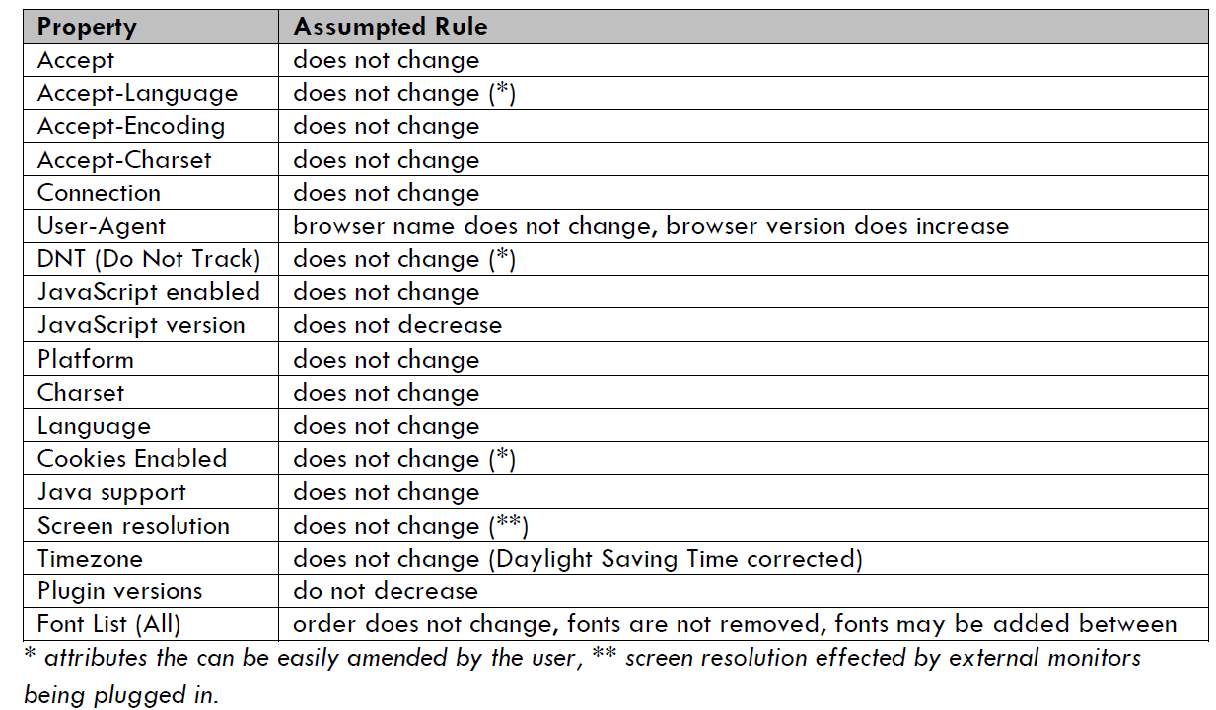
Table 2-2: Properties that are static or dynamic
A more granular approach was used in 2012 [17] to detect returning browsers. In this study attribute were assigned a weighting dependent on their level of contribution to the effectiveness of the fingerprint. To find the most likely match, attributes were collected from the visiting browser and for each of the fingerprints on file, a comparison score is computed to identify how likely a match is to exist. Tests are conducted to determine which fingerprint will be selected and this will be the one with the highest score. Test shown in table 2-3.

Table 2-3- Returning browser comparison tests [17]
In 2014 another study was conducted [2] with a sample size of 118,394 fingerprints and compared with the earlier study from 2010. AmIunique.org was launched in 2014 to collect browser fingerprints with the aim of performing an in-depth analysis of their diversity. A fingerprinting script was used to exploit some of the advanced techniques [13], [18] as well as some of the new browser APIs. In table 2-4 we see a list of attributes collected, include the source of the attribute and uniqueness of each attributes and the last column displays a complete list of a browser fingerprint.
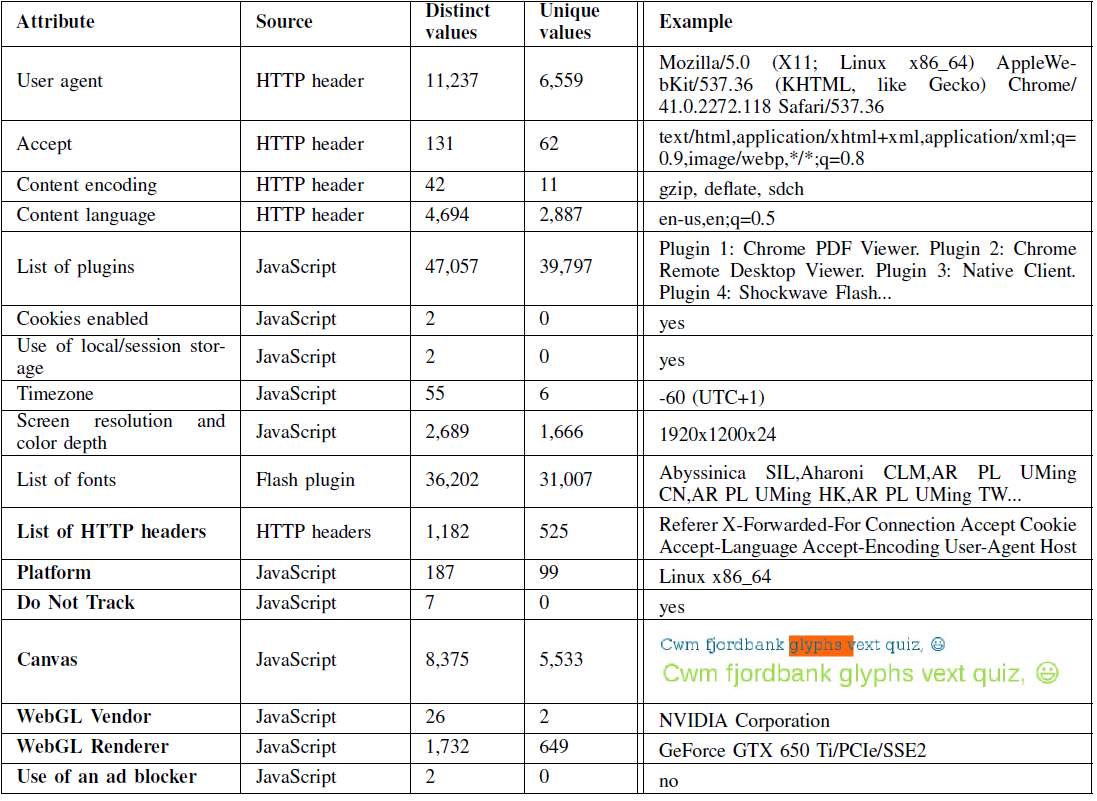
Table 2-4: list of attributes used in amIunique fingerprinting
Both studies used the same attributes to help develop a fingerprint. Additional attributes seen in the table increased the uniqueness of the fingerprint. The results were separated into three main categories JavaScript and Flash activated, Flash activated and JavaScript activated.
When compared the studies both show the ease of fingerprinting in today’s ecosystem [13]. The amIunique study had a bias toward more security conscious user and were still able to determine distinct fingerprints when users voluntarily interacted with the site. Table 4-5 from the study shows the level of entropy “which provides a mechanism for calculating a unique a specific value is , based on the information it contains , calculated the number of values that need to observed on average, before duplication occurred” [17] the higher the entropy the greater it’s contributions to producing and effective fingerprint.
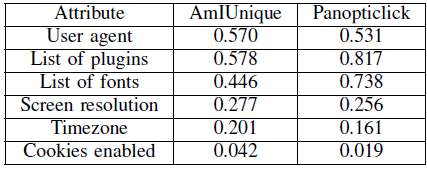
Table 2-5: entropy values for six values collected by Panopticclick [11] and AmIUnique [2]
Nikiforakis [4] analysed the techniques and adoption of three fingerprinting companies, two of which had been identified by Mayer and Mitchell[19]. These three companies were singled out as there was a lack of investigation into other fingerprinting companies and their methods. Acar [5] took this a step further and produced a paper that looked at device fingerprinting practices through three main contributions. The first is the design and implementation of FPDetective, which is framework for identifying and analysing web based fingerprinting without relying on a list of well-known fingerprinters. The second was to use FPDetective to conduct a study across the top million sites. Lastly, the study would look into fingerprint resistan browsers Tor and Firegloves. The study showed that fingerprint was even more prevalent than previous studies estimated. Acar [5] Showed undiscovered fingerprint scripts being executed in the top 500 websites. New fingerprinting practices were also discovered which include fingerprinting through third party widgets and automatic deletion of scripts once a user has been fingerprinted.
A sizeable amount of studies clearly demonstrate that browser fingerprinting is out there in the wild and that by collecting attributes and analysing browser environments, computers could be identified [5], [7], [11],[2]. Boda [16] was able to build a site which could identify a system without the aid of browser specific attributes. The studies and results [2], [11] highlight that fingerprinting is an important and hard to solve issue that needs researchers and policymakers’ attention to ensure that users’ privacy is at the forefront of all minds. Acar [5] helped fill the gaps in the research and further cemented the fact that fingerprinting will continue to grow and more transparency, awareness is needed as well as more effective countermeasures to combat new practices. The effectiveness of an attribute and its contribution to the fingerprint is represented by the level of entropy it produces. This suggests that the quantity of information contained in an attribute is directly related to its usefulness for tracking. This can be seen in Eckersley’s study [11].
2.3 Real world use of Fingerprinting
It’s been established that tracking has been around for a long time [19] and browser fingerprinting is present in today’s society [11], [7]. Undoubtedly it does raise security concerns and given that web advertising is the Web’s No. 1 industry and that tracking is a crucial component of it, user profiling in general and fingerprinting in particular are here to stay. Amongst many this could be considered a positive and some a negative. Nikiforakis [7] Presents numerous ways in which fingerprinting can be valuable to society.
Nikiforakis [4] determined that there are two methods in which fingerprinting is implemented into today’s web environment. The first being through a third party advertising element located on host website. In this case the website may not even be involved and is unaware that its users are getting fingerprinted. In this instance the fingerprint is sent back to the third party. The second method involves fingerprinting script, which is contained within the site visited. Once a user accesses the site, their fingerprint is captured and submitted to the host site via a hidden input element, when the user submits credentials. The fingerprint is encrypted and can be only be decrypted by the fingerprinting service provider. This helps fingerprinting companies conceal implementation details from their clients [4].
2.3.1 Protection against fraud
Fingerprinting be a way to differentiate between a valuable customer and a possible attacker. Nikiforakis [4] shows that a significant percentage of the websites checked for fingerprinting were pornography and dating sites. These sites utilised fingerprinting to help detect the user of shared or stolen credentials or duplication of user profiles for malicious purposes [7]. Essentially many websites will use fingerprinting to make sure the user is who they say they are. Companies, especially in fraud cases express that fingerprinting is more about providing a quality, safe experience and is more concerned with tracking and identifying ‘bots’ rather than user devices and users. So essentially these companies are saying that they are just using (security) script for collection of data through invisible, sometimes undetectable interactions that are irrelevant to user privacy. This then makes it harder to demand a response to privacy issues raised relating to fingerprinting. Over time fingerprinting practices will boom and device fingerprints will come represent users in databases instead of the standard personal identifiable information.
2.3.2 Paywalls
Used by many publications to limit the amount of publication a user can read. There would be a predetermined amount then the user will be required to pay or subscribe. Cookies could be used for this but they could be easily deleted by the user. The publication could also use a user IP address to track their activity but with the availability of IP spoofing this is easily thwarted. Fingerprinting can focus on the browser attributes, plugins and font installed to identify users and keep them for reading more.
2.3.3 Advertising, analytics and behavioural tracking
Third party network over time build up a database of profiles which contains information on a user web activity, hobbies and interests and other factors which help determine who they are as a person [20]. These third parties will then serve these users with advertisements targeted to them and collect analytical data which will aid content creators. These content creators will receive money from third party network to place advertisements. This raises serious privacy issues, users have no control over what data is taken and who it maybe be sold or distributed to. Furthermore users cannot request for their profile to be deleted and it will be rebuilt if it is deleted. Content creators will use multiple third parties to serve advertisements and collect analytics, this means the same tracker will be present on multiple sites effectively following users around the web which is behaviour tracking [20]. Behavioural tracking relies on JavaScript to implement their functionality and is achieved via the use of third party tracking networks [19].
2.3.4 Protection of HTTP sessions
Fingerprinting is not always used in tracking users an alternative use comes in the form of webservers using fingerprinting to protect against session hijacking. Attackers with the objective of hijacking a session will seek to clone all information including HTTP headers and cookies. JavaScript engine fingerprinting will be able to detect the modified user agent at the server side and by comparing the information in the HTTP header to the values the server has. Fingerprinting can be added as an additional layer of security to secure HTTP sessions [21].
Chapter 3: Security, Privacy and EU Policy
Over the course of the rise of the internet there has been a continued persistence and motivation to secure everything done online to protect ourselves and others. Software, techniques, tools and even legislation have been produced and continually updated to aid in the quest to protect us. As is commonly stated in security circles “humans are the weakest in a secure system” while this maybe subjective, it does hold some truth. What good does all the techniques, tools and plugins do if no one utilises them? Nowadays a lot of the leg work is done for us, various software companies will produce browsers with security already built in. Some features already enabled straight out the box and others left to the users’ discretion. Tor is a good secure browser used by security savvy user as it uses bland user agent strings and aggressive JavaScript blocking (as well as other features discussed in chapter 11 to resist fingerprinting.
The studies performed by Nikifirakis [4] highlighting the wide spread adoption of browser fingerprinting. This only goes to show the level of seriousness the threat on privacy has become. Big companies have adopted some use of fingerprinting to identify their customers. Google is a big player in the game as it is prevalent in many corners of the internet including google search, Gmail and YouTube. Google analytics can use the information sourced from these areas to analyse patterns and create a behavioural profile of sorts. This can be a pretty good profile but if we take this a step further and combine it with your Facebook userID, email address and phone number now companies can target you or at a minimum the demographic you fit into for their own purposes. As seen in google privacy policy June 2015 onwards indicates that they use “ technology to identify your browser of device “ [22] it can be interpreted that some form of fingerprinting is used in this process.
3.1 Current culture on Privacy
As the popularity of the internet increases the awareness of the threat to privacy has increased also [11]. This has lead to web users learning how to block, limit or delete HTTP cookies. To the non-security conscious user the knowledge of cookies may end here [22], the amount of people could describe what a supercookie is or how to thwart them is much lower.
It is stated that if a user wants to avoid being tracked then three tests have to be performed [11]. First you must find a site that uses cookies for necessary user interface feature but block other less welcome types of tracking. Your next task will be considerably more challenging, you will have to learn about the various type of supercookie and how to disable them all. If you managed to pass those two tests, which very limited amount of people will be capable of doing, you will be confronted with the third challenge: fingerprinting. The technique that is hard to detect by even the most seasoned investigators as it leaves no trace behind on the users’ system.
With browser fingerprinting there is a lack of user control and transparency. Fingerprinting is mostly executed stealthily, the user has no clear indication that such data collection is happening. Even when they’re made aware that they’re being tracked, say, as a fraud-protection measure, they are, in essence, asked to simply trust that the information collected won’t be used for other purposes. For web users to fully understand some of the actions taking place in the background, we need transparency. Transparency will not only aid users but researchers, law makers and others to document or regulate privacy-sensitive activity.
Privacy becomes that much more important when you’re a target. Browser fingerprinting can be quite destructive to a user if an entity has malicious intentions against them. Fingerprinting helps identify a certain browser configuration and the information gathered here can be utilised in the production of customized malware to attack that specific user. It can also passively gather data on a host to be later be used to match against known execution environments to launch exploits against that precise host. This is evident in [23] where a malicious fingerprinting script is examined to determine whether it can be successful at delivering an exploit to a targeted browser using a fingerprint. The results show a presence of several plugins. The next step taken was to combine the constructed fingerprint with the browser language. At this point a request is issued to fetch the malware that corresponds to the fingerprint.
3.2 Detection and Prevention
There are several methods mentioned by Upathilake [8] that help protect against browser fingerprinting.Having blocking tools which are maintained by doing regular web-crawls to detect tracking and incorporate blocking mechanisms into the tools [13]; the introduction of a universal font list that a browser is limited to choose from for rendering; reporting unified and uncommunicative attributes; blocking or disabling JavaScript; reducing the verbosity of the User-Agent string and the plug-in versions; having Flash provide less system information and reports only a standard set of fonts.
These are by no means the only methods which can be used more will be discussed in greater detail in later chapters. But it has been noted in many papers that privacy enhancing methods will 1) will only increase your uniqueness [9]. On the client side you will have the illusion of being protected but now you instead of being just a face in the crowd, you are now the face with a mask on in the crowd, making your more distinguishable. It’s the fingerprinting paradox: the more you hide the more visible you become[11]. 2) Not protecting you from much, as the more advanced fingerprinting method circumvent measures put in place by vendors and users [1].
Is hiding in plain sight the solution? This is what I believe some of the methods mentioned earlier are pointing to. If we all have the same profile then it becomes harder to identify an individual. This is evident in the mobile device world. While it is still possible to fingerprint a user via their mobile devices compared to their desktop [2] (because the hardware/software is very similar across millions of users and the modification/customisation that can be made is limited) it becomes a bigger task to uniquely identify someone [9]. Mobile Fingerprinting discussed in chapter 10. Web browsing through a cloud service could possibly be a method to help users appear similar. This service would treat a user’s desktop as a terminal and trackers will be only able to detect the clouds fingerprint. Another method discussed in other sections is to create a fake profile to offer fingerprinters [24]. This profile for all intense purposes is a legitimate but offers details different from the genuine profile. The idea is to trick the servers into classifying the browser in the wrong category. Discussed in chapter 5.
3.3 Laws and Policy protection privacy
The biggest collection of data today is happening in an online space. Every action from mouse click to keystrokes can be captured in a stream of data which can be stored, analysed and monetized by companies all over the world. The data helps build a profile used to personalise a user experience on the internet or it could be used to target an attack at that user’s specific configuration. At this point an endless feedback loop is created where user is fed data and then their reaction to this data is analysed and measured. Third party tracking gives rise to various privacy concerns and certain polices are in place to protect users [19] and some EU policy makers view online privacy as a “fundamental human right”
What should users have control of? Many Policymakers believe users should have control of data collected whereas advertisers believe that control should only extend to specific uses of data [19]. What should the default be? According to article 29 of the data protection act it is a belief that tracking shouldn’t be by default. Advertising groups reject this comment and believe it should be default [19].
3.3.1 ePrivacy Directive
“The 2002 ePrivacy Directive, 2002/58/EC, mandated that websites must provide information about their data collection practices and must enable users to opt out of having information stored in their browser, except as ‘strictly necessary’ to provide service ‘explicitly requested’ by the user. In practice the directive has had little force; Member States have not taken any measures to enforce compliance, and in many cases they have treated browser cookie settings as adequate implementation [25]. A 2009 amendment to the ePrivacy Directive, 2009/136/EC, replaces the opt-out rule with an opt-in consent rule [25]. Member State implementations initially split. Some states have suggested existing browser settings would remain adequate, through the legal fiction that they convey ‘implicit consent’. The majority view and the consensus is that the directive requires explicit consent from each third party”[19].
As of 2012 further changes were implemented in the European Union data protection law. These revisions would clarify that consent must be explicit.A proposal which could further protect users is in draft stage currently but when finalised it is set to replace the outdated EU ePrivacy directive[26]. The aim of this proposal is to impose stricter rules regarding consent for cookies and any kind of online tracking techniques. Failure to comply could result in a fine up to 4% of revenue. The new regulation is designed to work in harmony with the existing GDPR. Businesses will not have much time to react once the law has passed as there will only be a 6 month lead in period. This legislation will be aimed more directly at the secret, underhanded monitoring of online behaviour.
This will shine a light on third party cookies and the invisible companies hiding behind websites, stealthily building profiles of web user’s activities. A benefit to website owners performing analytics is that this will be exempt from the requirement for user to consent. More involvement will be required from browsers to play a more active role in mediating consent. This would mean that browsers would have to change the way they work and take on more responsibility, it would be down to the software developer to do this but the question is will they? Do Not Track (an option in web browsers to opt out of tracking ) will step into the light and will be expected to play a more significant role in preventing tracking. As this is not the final document a lot can be subject to change and of course there will be lengthy negotiations and lobbying from the online advertising industry. Nonetheless the inclusion of bigger fines will make companies think twice about non-compliance. Businesses will also have to look at their current cookie, tracking methods and practices and align then will the new set of rules.
Chapter 4
4.1 Fingerprinting technologies and techniques
The previous chapters have been effective at covering some of the objectives, leaving the following research to cover the remaining objectives. The third objective is to identify and investigate the current most utilised techniques and methods used in today’s society to establish a unique web browser fingerprint. The research will delve into how these techniques achieve their goal without affecting the operation of the browser and how they manipulate the environment to avoid detection.
Fingerprinting techniques can be divided up into five main categories. While there are more obscure techniques available these are the most documented and used throughout the internet:
- Browser specific:ndetails produced by the browser environment that contribute to the development of a fingerprint.
- Canvas fingerprinting: this element is associated with HTML5 and used in conjunction with WebGL to render images, reading the data pixel data to construct a fingerprint.
- JavaScript engine fingerprinting: the fingerprint is derived by utilising JavaScript conformance tests.
- Cross browser fingerprinting: most fingerprinting has been implemented on a single browser, but with users using multiple browsers nowadays a technique has been developed where fingerprinting is not constrained to one browser environment and instead can track users across Firefox, chrome and edge browsers for example.
- Sensory fingerprinting: performed on mobile devices, discussed in section 4.2
Table 4-1 Shows the attributes associated with different methods of fingerprinting
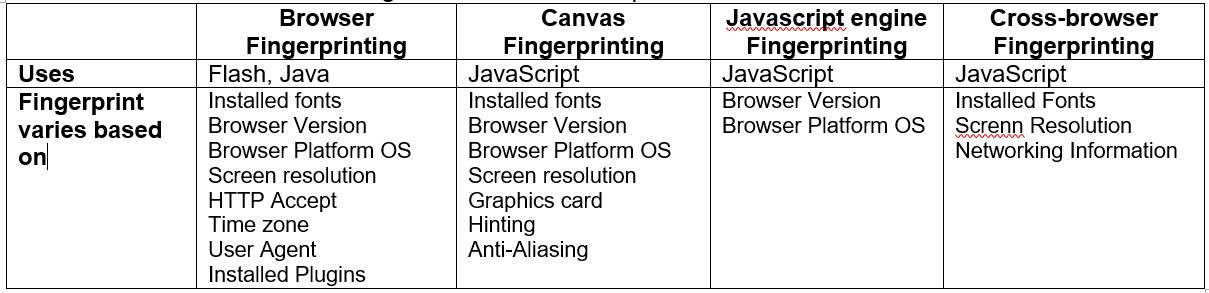
Table 4-1: fingerprinting methods and attribute associated with them
4.1.1 Canvas Fingerprinting
Canvas fingerprinting is a technique gaining popularity and was first presented by Mowery [18] in 2012. The canvas element which is part of the HTML5 set of attribute allows the scriptable rendering of 2d shapes and images, providing a rich, interactive web experience for the user. Given the right instructions an image can be rendered to help identify a system with pixel precision. Canvas fingerprinting is quite an attractive fingerprinting method as it provides information based on layers of the system. This may include the browsers, operating system used, graphics drivers and other hardware which is part of the machine.
In combination with WebGL rendering texts and scenes onto a section of the screen via the HTML
Canvas fingerprinting incorporates hashing into its operations as time and time again it will produce the same result if the input doesn’t change. So if you take the word “security” and run it through a hashing function it will produce a different result to the same word with a space added “security “. To the naked eye these examples appear the same but run through a has function and they may still produce different results due to the small unnoticeable differences. This is important in canvas fingerprinting.
Websites utilise JavaScript to perform the task of drawing an image. The image rendered will contain an array of elements such as various colours and backgrounds, different lines and shapes plus additional information like geometrical figures. The image may appear the same once again but different machines will draw the image in slightly different ways. Same image (small minuscule differences) different result like the hash functions. When images are requested to be drawn this is a result of a script being executed that follows a mathematical formula. An easy task if the image is of a simple nature like a circle but becomes extremely complicated when more complex images are involved.
With the evolution of technology and the emergence of high resolution screens, hardware development has been pushed to produce filters that improve the crispness, sharpness and overall appearance of an image. The two most notable filters are anti-aliasing and hints. The former provides a smoothing out effect on the jagged edges of an images and fonts (eliminating the staircase effect). The latter are instructions that are executed when glyphs are drawn on the screen.
The uniqueness of a fingerprint stems on how a machine will render these two filters. Individual computers will perform this process slightly different from another given the same input, and this provides the data needed for fingerprinting to be effective. These image discrepancies are noticed by websites.
Canvas fingerprinting has some appealing properties which play a part in its increased popularity [13]. It provides a stable and consistent fingerprint, the same process should produce the same result every time. It has a high entropy and is transparent to the user. If a website running JavaScript on a user’s browser then it is able to generate a fingerprint by observing the rendering behaviour. This requires no access to system resources. The method of fingerprint tends to suffer the same pitfall as other techniques discussed in this section, being that canvas fingerprinting cannot distinguish between users who have the exact same setup in regards to software and hardware [18]. Mitigation mechanisms for canvas fingerprinting can help block this technique but will only be effective given certain conditions. Circumventing canvas fingerprinting will be discussed in chapter 11.
To understand the impact this fingerprinting technique has made on the world wide web a study was conducted to search for the method in the wild [24]. Canvas fingerprinting was discovered in over 14,000 sites these were linked to scripted from 400 different domains. Analysis of this research indicated three possible trends. The first being that large trackers had ceased their use of this method, it was suspected that this was due to backlash by the public of a previous study. Secondly, the number of domains using it had increased substantially, indicating that more and more trackers had gained knowledge of this method. Thirdly, behavioral tracking was no longer the number one use for the method and that it had be succeeded by fraud detection. This is in line with the ad industry’s self-regulatory norm regarding acceptable uses of fingerprinting.
4.1.2 Browser specific fingerprinting
Browser specific fingerprinting is one of the earliest methods of fingerprinting. This section can be divided in three main areas expanding and analysing the role of HTTP headers, browser plugins, font lists and font enumeration.

Table 4-2: HTTP Headers
When a browser sends a request to a web server, it is required to send additional information. At a minimum, it will send the protocol version, requested path and requested host. The HTTP header will also send extra Information which again, maybe required for technical purposes but this additional information will aid in the development of a fingerprint of the system. The most popular header is the user agent string used for legitimate purpose likes solving debugging issues and identifying the capabilities of a browser. But it can also be used to identify the name, version and platform of a browser [6], [11]. Combining the user agent with the IP address will mostly increase the precision of user tracking [5]. The User Agent reveals a lot information about the browser and the underlying system architecture, both hardware and software. It has been shown that the highest entropy has been achieved from a combination of the User agent, installed plugins and font lists [9], [11]. Attribute sent by almost every browser aiding in use of tracking. Table 4-2 shows attributes found in the HTTP header.
With older version of HTML the need for plugins was needed to enrich the user experience, providing multimedia content. The main contenders in the plugin world was adobe Flash and Java. The adoption of third-party plugins gives fingerprinters the ability to extract numerous features. Eckersley was able to source a list of installed fonts [11] which he was able to do because font enumeration can be done via the Flash and java plugins. The use of plugins also provide advantages to commercial companies utilising fingerprinting technology. Flash was used to circumvent HTTP proxies set up by the user allowing to gather more information about a device. This included OS kernel and the use of several monitors (multi monitor setup). As mentioned previously Java can be used for collection system information but as it requires explicit consent in some situations from the user, it’s not ideal for fingerprinters. Flash can operate without the consent of a user.
Browser extensions like Adblockers are used to provide additional functionality to a browser. The list of extensions can be used to obtain information about the browser. The problem with extensions is that they can often be used to block attempts at fingerprinting a system but this creates a trade-off between privacy enhancing extensions and fingerprinting, as the more extensions install on a system the more a browser will stand out and thus become unique for fingerprinting.
The list of fonts can serve as a unique identifier[11]. This is not accessed directly via the browser but can be acquired via browser plugins or using a side-channel that unintentionally discloses the presence or absence of any font. Traditionally Flash APIs would be used to obtain the font list but with flash phasing out, new methods have to replace it. Nikiforakis [4] discussed a method similar is CSS history stealing technique, where a font list could be obtained.
HTTP header with its wealth of attributes and information has shown to produce some of the highest entropy making is a common option for fingerprinting [11],[5], [9]. All major browsers utilise these headers as well as JavaScript making them susceptible targets for fingerpinters. There are a number of issues that arises from this type of fingerprinting; the major being that the fingerprint is unstable, meaning that changes in the browser such as an upgrade of the plugins or hardware modification like adding and external monitor, can alter the fingerprint. Eskerley [11] demonstrated that the use of a heuristic can aid in predicting when a browser will make a change. The method of fingerprint tends to suffer the same pitfall as other techniques discussed in this section, being that canvas fingerprinting cannot distinguish between user who have the exact same setup in regards to software and hardware.
4.1.3 JavaScript Engine and JavaScript fingerprinting
This browser fingerprinting technique uses the underlying JavaScript engine to help identify the browser and a version number. The Use of JavaScript is popular choice as its well established, is used across a multitude of platforms including desktops and mobile devices and is supported and enabled by all major browsers [27]. It is also used by a large percentage of websites. This technique can be also used to detect modified user agent string. While the user string can be manipulated and set to a random set of values, the JavaScript fingerprint cannot. For each browser, the JavaScript fingerprint is authentic and cannot be ported to other browsers. Mowery [28] implemented and evaluated browser identification using JavaScript fingerprinting based on two areas timing and performance patterns. They found using JavaScript benchmarks like sunSpider a normalized fingerprint could be generated from runtime patterns [26]. This technique can be employed to detect modified User-Agent strings, it’s still utilised in mobile devices and can be used to reliably identify the browser of Tor Browser Bundle user.
While JavaScript conformance tests like Sputnik or EMCA’s test262 [29] consist of thousands of independent test cases, not all of them are necessary for browser identification. The first stage is to take the failed tests and compare them to cases that are known to fail in each version of a browser. With this method, a browser and major version number can be identified. The use of a one or two test cases may prove to be enough to successfully identify a browser but this can only happen under specific conditions. For example, assuming only two browsers are within a group of browsers and one fails a test case and the other doesn’t, this already provides some information to distinguish them apart.
JavaScript has been present in society since its invention in 1995 and remains a driving force in web technologies today. A study done back in 2013 showed that only 1% of visitors had the JavaScript disabled in their browsers [6]. The purpose of JavaScript can be divided you in to three tasks. The first being to dynamically alter the document object model (DOM) of a webpage. The second is enhancing the user experience via asynchronous requests and responses and thirdly to reduce the strain on the server by delegating some no critical tasks to the client side. As JavaScript is so heavily present in browsers nowadays, it makes it an effective fingerprinting tool [5].
The Navigator object and the screen object are the two most probed resources. Between the two objects a wealth of information is identified including browser, language set, time zone and plugins installed. Information on the machine operating system and architecture can also be obtained via the platform attribute. Table 4-3 shows the attribute obtained via JavaScript.

Table 4-3: Attributes within JavaScript that can be used for fingerprinting purposes
An experiment conducted in 2009 by Mayer [14] resulted in uniquely identifying 96% of 1328 browsers by combining four main attribute navigator, screen, navigator.plugins and navigator.mimeTypes. This was taken a step further a year via the Panopticlcik project [11] where a substantial number (early half a million) of browsers were fingerprinted by extending the set of fingerprinted features with fonts, time zones and a browser’s ACCEPT headers. This lead to 94.2% of visitor browsers being identified.
4.1.4 Cross-browser Fingerprinting
At the dawn of web tracking the first generation utilsed stateful identifiers such as cookies. Has times moved on the second generation emerged, moving from stateful to stateless identifiers i.e. user agent string. Stateless encompasses most of the browser fingerprinting methods found in cyberspace. The main constraint with both generation is that they can only operate within a single browser. With the use of multiple browsers nowadays tracking method methods had to evolved to adapt to the change in times. This has led to the third generation of tracking, cross-browser tracking [16], [30].
This third-generation technique can be used for a range of tasks that can benefit a user. Firstly, it can be used in the authentication process providing stronger multi-factor authentication and it can also aid in the improvement of existing privacy preserving work[30].
Cross-browser fingerprinting makes use of the feature that are used to fingerprint a single browser as these have already laid the groundwork. As an array of feature are unique to the browser specifically, the cross-browser stable attributes do not present as uniqueness enough even when combined for fingerprinting. That is why the only cross-browser fingerprinting works, Boda [16], uses IP address as a standout feature
In previous works such as the Pantopticlick study test [15] and many other related works [2], [5], [18], [4] the IP address is excluded as a fingerprintable feature this is because if dynamically allocated IP address can change depending on the network a system is connected or in some case may be completely anonymous
Cross-browser fingerprinting will take data that needs to be processed and make the browser carry out the required operation to execute a request utilising the underlying hardware components. For example applying an imaging to one side of a 3d box in WebGL will elicit an action for the machine GPU. The request could have come for different browsers but the response in hardware parameters will remain similar. This is because the operation is carried by the GPU and not browser.
Identification of users has been able to take place regardless of the browser used in addition to being able to identify different hardware setups associated with a specific user [16], [30]. This is based on the information gathered from response to these types of operations. Utilising the features in the operating system and surrounding hardware to fingerprint a machine may be effective as they are more stable across browsers and no matter the browser used they all operate on top of the same OS and hardware.
Let s examine WebGL, a 3D element used in the browser canvas object. It has been demonstrated that canvas element especially the 2D part can be used to fingerprint a single browser [8], [18] but according to Laperdrix [2] WebGL is considered “brittle and unreliable” for single browser fingerprinting. Cao [30] has indicted this because the AmIUnique study [2] “selects a random WebGL task and does not restrict many variables, such as canvas size and anti-aliasing, which affect the fingerprinting results” [30].Coa [30] has shown that by selecting specific graphic parameters and extracting the information from the output produced from these rendering tasks, that WebGL can be not only be used for single browser fingerprinting but for cross-browser fingerprinting purposes also.
Cao [30] proposed building a fingerprint based off operating system and hardware features this includes the graphics card and CPU. The idea was to take advantage of the fact the many hardware and Operating system features are exposed to JavaScript APIs via browsers and extract information when asking these APIs to perform requested tasks. Both single and cross-browser fingerprinting can benefit from the extraction of these features. The approach lead by Cao was successfully able to fingerprint “99.24% of users as opposed to 90.84% for AmIUnique[2]” [30]. Moreover, the approach achieved 83.24% uniqueness with 91.44% cross-browser stability, while Boda [16] excluding IP address only have 68.98% uniqueness with 84.64% cross-browser stability” [30].
The line between protecting user privacy and leveraging data for profit can sometimes get blurred amongst some of the bigger tech companies. Vendor like Microsoft and google have the ability to help reduce the chance of fingerprinting but with ad revenue at an all-time high doing this will affect their button line and it’s a big part of their business models. The use of techniques such as cross-browser fingerprinting will likely allow more tailored adverts to appear more often as the pool of specific user data increases.
Table 4-4 shows List of feature that can be used to obtain a fingerprint
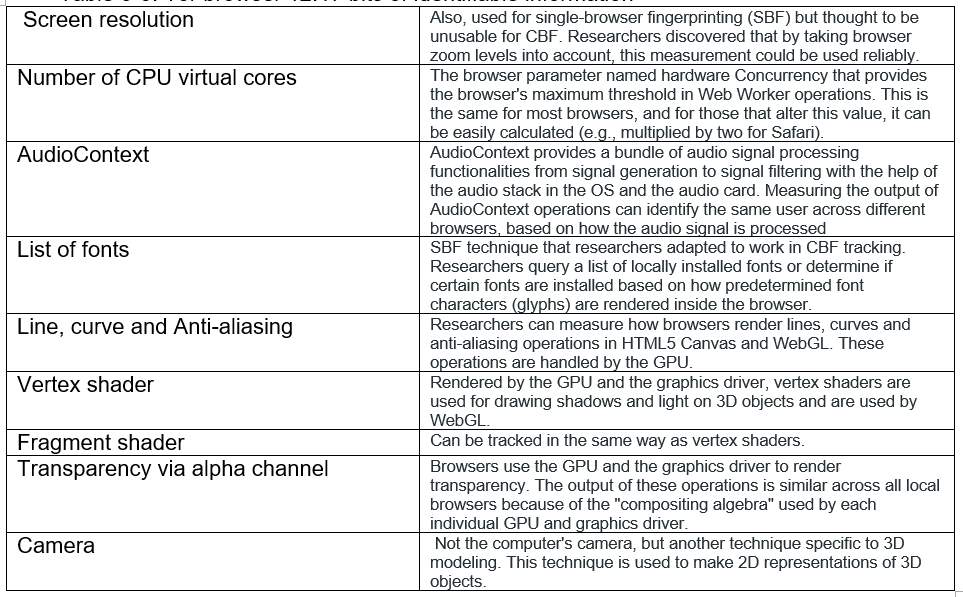
Table 4-4: List of feature that can be used to obtain a fingerprint [31]
4.2 Evasive methods and Circumventing Fingerprinting
4.2.1 Fingerprinting paradox and establishing a baseline
The main principle behind the design of some security technologies is to protect the privacy and anonymity of a user. But sometimes these technologies end up doing the opposite. The paradox, essentially, is that the measurements taken by a user to make a device harder to fingerprint are themselves distinctive. The more people also incorporating these same measures the less distinctive a device with be. These distinctive features of a browser aids in making fingerprinting easier.
To win the battle against fingerprint we must first establish the general ways in which we can attack it. The evasive techniques discussed in this section will incorporate one or several of these areas as a basis for protecting against fingerprinting.
- Decreasing fingerprinting surface: there we look at either removing the source that is causing high entropy or decreasing the ease of access to attributes used for successful fingerprinting.
- Increasing the level of anonymity: this can be accomplished by incorporating standardization, convention or common implementation by the majority or vendors and users. This will create a commonality amongst the mass decreasing uniqueness and thereby reduce the likelihood of fingerprinting.
- Detectable fingerprinting: The idea here is to make browser fingerprinting observable to the user agent, so that the user agent might block it or a crawler can determine that it’s happening.
4.2.2 Tor
The ability to be able to maintain anonymity while surfacing the internet is very important to users concerned about their privacy. The TOR network does provide a good level of protection making it nearly impossible to discover real IP address of users. This alone is not enough to protect users on the web.
Tor Browser is built upon the already existing architecture of Firefox. It has been preconfigured and modified with the purpose of protecting user privacy and identify while browsing the web. The history and cache are not persistent and is supplied with fixed settings, there is almost no other properties that can be exploited for identifying distinguishing features. The Tor browser will decrease your uniqueness on the web but as Tor has a limited user base compared to say Chrome, it will cause the browser to standout, indicating a privacy conscious Tor user. But this will be one generic Tor user in a sea of Tor users. Tor’s design provides anonymity and prevents linkability of browsing sessions. This circumvents the need for a user to change the browsers user agent string so frequently, to hide the browser information. This is a method of hiding via obscurity, which is not considered the best form of security in other realms of computer security and may cause a browser or system to stand out.
The default installation the Tor browser provides improved security [15]. Still, many people manipulate and customize their installations of Tor, so it can enhance the user’s experience. These tweaks can be a detriment to Tor weakening its defenses against fingerprinting techniques.
Fonts and font enumeration has proven to be a good attribute when it comes to distinguishing and recognizing users. To limit the power of this fingerprinting attribute Tor browsers, limit the number of fonts a page can request and load.
The price that Tor pays for increased security features is a lack in performance. Tor suffers from a reduction in internet speed making streaming music and movies an arduous task. The solution is to combine the Tor browser with a good Virtual private network resulting in increased performance and privacy.
Tor may be more resistant to fingerprinting than browsers such as chrome and Firefox but it doesn’t guarantee 100% protection. A Proof of concept JavaScript code has been created that can be inserted into the source code of websites to obtain information about their users, their hardware configuration, computing power and numerous other data [32]. The codes allow the researcher to extract information leaked by the mouse control events in the Tor browser; measure the time taken to execute scripts alongside other information. Access to this information was possible because the researcher was able bypass the protection of the Date.getTime() method, which by default will stop the measuring of events happening under 100ms. Notre [36] states “If a website is able to generate a unique fingerprint that identifies each user that enters the page, then it is possible to track the activity of this user in time, for example, correlate visits of the user during an entire year, knowing that its the same user” [36].
Tor remains a strong opponent in the war against fingerprint and privacy but this new method of fingerprinting can throw some doubt on that. The Tor network is not immune to threats. To remain effective customisation must be very limited or non-existent to not increase uniqueness, replaced by the Tor browser’s mono-configuration. This type of setup can be quite brittle, since a simple change, stands out. With the small number of Tor users, fingerprinters will be able to identify a system immediately.
4.2.3 Browser Add-ons and Extensions
The use of extensions for browsers is a popular countermeasure amongst users. Unlike plugins, extensions aren’t enumerable through JavaScript and so extension may be detected via the side effects produced or the absence of something in a normal configured browser. Firefox and Chrome both have numerous add-ons available to download and install.
There are several blocking extensions such as Privacy badger, Ghostery, Adblocker, and noScript which can be utilised in blocking fingerprinting scripts. One of the main functions of privacy badger and ghostery is to stop the downloading of script from known trackers. No script takes a different approach and implements the use of whitelists, configured by the user. This presents an issue as whitelists and database will requires to be kept up-to-date and maintained. This means that extensions cannot fully guarantee protection against fingerprinting. As with a lot of countermeasures this falls under the fingerprinting paradox, privacy-enhancing extensions can be counterproductive if detected and it increases the amount of information that can help identify a browser.
An alternative method to blocking would be spoof the user agent. The idea of spoofing is to increase anonymity by providing false information to fingerprinters. Numerous agent user spoofing extension can be found in both Firefox and Chrome respective markets. In a study conducted by Nikiforaskis [4] it was demonstrated that some of the extensions produce inconsistent headers and that the extension do not completely obscure a user’s identity. It was also noted that because only a small number of the online population install these extensions, that it increases the distinguishability of a user.
The inconsistencies can be seen in an test performed by Kaur [6]. In which the ModHeader extension was installed and all prominent attribute of HTTP headers were altered. The information shown in table 4-5 shows that the values modified by Modheader were correctly fetched by a website using JavaScript. Fetching a browser attribute can be accomplished in many ways in this case the navigator.appVersion was used instead of the HTTP header user agent. The mismatching of user agent can help websites identify a user is trying to mask their browser thereby reducing trackability.

Table 4-5:Values modified by the Modheader
This technique acts on disguising the user agent header but not the entire fingerprint, allowing other techniques such as cross-browser fingerprinting to work [16], [30]. The main weakness in the approach is that it doesn’t truly hide identity of browser and this can be demonstrated with the use of JavaScript. This is the case because of the following reasons:
Impossible configuration: None of the browser spoofing extensions can alter the value of screen object of the JavaScript language. Users configuration altered (spoofed) to that which doesn’t occur in real life. For a example a workstation has the attributes of a mobile display or iOS mobile platform with flash enabled. These would be considered impossible configuration and reveal the presence of privacy tools.
Mismatch of user agents: The extensions can only change browser’s HTTP headers and leave the matching JavaScript attributes unaltered this generates inconsistencies amongst the extension’s and JavaScript’s divulged values. This inconsistency can lead to the discovery of specific extensions which can once again increase the uniqueness of the browser.
The use of blocking extension may prove useful to some degree but will still make fingerprinting easier. Further study is conducted in chapter 5.
4.2.4 Countering JavaScript Fingerprinting
A simple method for defending against fingerprinting is to disable JavaScript, this may reduce the functionality of a website and dull the user experience of some websites, making this technique too restrictive for the majority of users. All scripts must be disabled as fingerprinting code could be buried in the code of the webpage. As shown in Panotpiclick, amIUnique websites [15], [33] JavaScript is included in most tests (especially the more powerful tests) to identify a browser, hence disabling JavaScript will thwart some of the tests conducted. The use of extensions will allow more control over the execution of script by utilsing whitelist accepting approved websites and denying everything else.
Disabling doesn’t defend against all tests and some other fingerprinting method can gather enough information from other attributes to identify a browser and user [11]. Using a combination of fonts, part of and IP address, screen size and time zone a study was able to still identify most users [13]. This was conducted on a small sample size of 989 fingerprints. Excluding the time zone attribute everything else could be attained without the aid of JavaScript. Further evidence supports this, in 2012 Microsoft found from analysing datasets from search client Bing and email client Hotmail that 60%-70% of client could be uniquely identified via the user agent string and if you concatenated that with the IP prefix the percentage increased to 80% [34]. Furthermore in 2016 there was a study that found that only 29% of fingerprints were unique when JavaScript was disabled [2]. But the Browserprint website has stated that they “found that out of 2104 submitted fingerprints where JavaScript was disabled 1372 were unique, that means 65.2% of fingerprints with JavaScript disabled were still unique” [35].
With regard to the Javascript engine the ideal situation would be if the JavaScript engine used across various browsers conformed uniformly with standards but having multiple vendors involved in the development of JavaScript engine and the implementation variety of engines used in major browser will prove difficult. The complexity of the JavaScript engine alone also make this a challenging task. According to Nikiforakis “To unify the behaviour of JavaScript under different browsers, all vendors would need to agree not only on a single set of API calls to expose to the web applications, but also to internal implementation specifics. For example, hash table implementations may affect the order of objects in the exposed data structures of JavaScript, something that can be used to fingerprint the engine’s type and version. Such a consensus is difficult to achieve among all browser vendors diversions in the exposed APIs of JavaScript even in the names of functions that offer the same functionality, e.g., execScript and eval” [4]. The competition over the performance of different engine may also present a problem for vendor to fall in line and accept a set standard that everyone follows.
The solution here is to focus on prevention and detection of fingerprinting client side. This can be done via the client browser itself, uitlising extensions to watch for fingerprinting as well as using a proxy server to detect and block fingerprinting patterns.
4.2.5 Countering Canvas Fingerprinting
Canvas fingerprinting has been known to be a difficult fingerprinting technique to detect and prevent without false positives [13]. One of a few solutions to combat this technique is to utilise crowd sourcing, to gain feedback in aid of developing a better tool that can block pixel data extraction attempts [15]. Other suggestion involves adding random pixel noise whenever canvas fingerprint attempts are made. Another option is to have the browser render scenes in a generic software render [18]. Both options are considered good ideas but they pay a cost in terms of performance which makes them unacceptable for general use [18]. The easiest method to implement involves giving power to the user and allowing them to approve a script request for pixel data [18]. Modern browsers have incorporated this approach, for example with the HTML5 geolocation API [16].
Another method defence against pixel information leakage, is for every system to produce identical, generic results. For this to occur browser vendors will need to agree on a list of “
Blockers will stop canvas fingerprinting but preventing the canvas image from loading is an identifier. Although the canvas fingerprint will not be sent, the fact that you did not load the canvas image will be this, itself a unique Identifier. This only becomes effective if a large percentage of the online community is actively participating in blocking too.
A good strategy is to hide in plain sight and use a browser extension like canvas Defender [36] a add-on which combines these 3 main functions:
- Tracking will still take place but will be under the control of user Make the canvas fingerprinting function available on the websites you visit. (So it’s not clear you’re not trying to mask yourself).
- Use a canvas identity with consistency (So it’s not clear you are trying to avoid detection)
- Switch up the identity when necessary to erase your tracks.
Different hash values mean different fingerprints, which means the tracking attempts fail (which is good for users who are concerned about being tracked). It would seem that a useful countermeasure would be to change browser canvas code, particularly the canvas toDataURL() function so that it introduces a few changes every time it is invoked. These changes could be ones that don’t really bother the human eye – for example altering a color by a couple of RGB values – or making changes to an alpha channel, perhaps in corners or along edges. The use of such advanced tool as Multiloginapp will allow spoofing of the canvas hash which provides false information for fingerprinters and protects the user. In theory switching up the fingerprint submitted at regular interval seems like a viable approach to avoiding fingerprinting, the problem is the browser will stand out enough to categorize it in an irregular group.
4.2.6 Other methods
Building a fake profile
A more elaborate way of countering fingerprinting is to build a fake profile. To the regular user this may seem impractical but it is a viable option nonetheless.
The aim is to produce a profile where the information contained mimics a real user profile. It should be good enough to trick a server into placing a user into the wrong category based on that profile. So instead of trying to block or spoof information, a better approach would be to supply what is required filling the field with false information, the user is protected and the server is satisfied. Multiloginapp has been developed for this purpose[37].
This can prove a challenging task as the artificial information selected for the profile cannot be freely chosen. There certain coherence constraints that must be adhered to. Some browsers have features disabled by a large amount of their users. These features may provide important information to fingerprinters, this must be recognized in building the profile. It is important to keep in mind that when constructing a believable profile that limitation and restrictions must be taken into consideration. Profiles should be collected from real world computers and browsers[24].
It was proposed that in a case study on google chrome that protection against fingerprinting is possible using a fake profile can be done in principle “by modifying the browser source code, via specialised HTTP proxy or with browser extension” [21]. While adapting and modifying the source seems like the best option to make this idea feasible it would also be the most complicated and require constant maintenance. The HTTP proxy would provide the ability to interpret, adjust and screen data used for fingerprinting.
The use of browser extension provides a unique advantage, in that it will allow the design to by separated in to two sections. One dealing with general concepts and techniques the other deals with feature specific to the browsers. This approach will allow this technique to be adapted by other browsers by keeping the same basic ideas and modifying only the relevant portions needed.
The main idea of this is to provide craft a profile which make identification, fingerprinting and tracking an impossible task.
Belonging to an anonymity set – Firegloves
Current browser fingerprinting countermeasures, such as FireGloves (Firefox plugin to impede fingerprinting-based tracking while maintaining browsing experience) [38], aim to change the web identity of a user in such a way that he belongs to a large anonymity set. An anonymity set is in this case a set of users all having the same web identity and therefore not being distinguishable within this set. FireGloves achieves this by changing the user’s browser characteristics to a very common one. Nevertheless, this approach has some downsides:
1. It requires many users to work.
2. A user is required to frequently change his browser characteristics to keep being part of most the users on the web.
3. A user is still unique through his IP-address.
The use of blockers and extensions would work better if there were many browsers using them. In this case a browser may still stand out but would be harder to identify as so many others have similar configurations. This is the technique utilized by Tor where everyone has the same fingerprint [6], [5].
PriVaricator
PriVaricator [39]is a solution designed specifically to break fingerprint stability.
Privaricator uses randomization to break linkability and randomization policies so the browser has an option about whether to conceal the truth about fingerprintable system characteristics such as font size. PriVaricator has been shown to be able to deceive well-known fingerprinters while keeping the level of site breakage to a minimum[39]. Firegloves [38] is a proof of concept plugin that follows a similar approach and has shown to be successful in protecting against fingerprinting in a study by Luangmaneerote [40]. The disadvantage of this randomization is its noisiness “If a feature is randomized on every access, sophisticated fingerprinting techniques could repeatedly perform measurements to determine the randomness and finally obtain the unrandomized features. Also, randomizing the lists of fonts and plugins cannot mitigate fingerprinting mobiles” [41].
Prevaricator is said to only address explicit fingerprinting this means it will only handle direct attempts to collect attributes made visible by the browser and will not address fingerprinting performed by plugins like Flash that give access to the complete list of fonts [42].
4.3 Mobile Fingerprinting
It has been demonstrated and proven that browser fingerprinting can be accomplished through highly customised environments such as desktops and laptops [2], [6], [11], [17]. In this section we explore the effectiveness of fingerprinting on standardised devices such as mobiles and tablets. For fingerprinting to work it must be able to identify a system/user from millions of similar systems. Customizable features such as installed fonts and device configuration (screen resolution, colour depth) provide the characteristics needed to help identify a device. Mobile device provides minimal or no customisation needed to track accurately. This remains an open problem in practice for entities tasked with tracking users. As the use of mobile device has increased over the years for day-to-day online browsing, so has the need to been able to track users on this platform.
Hupperich [41] studied whether using common fingerprinting method would work on mobile devices and if so to what degree? The data collected was split into two subsets (desktop and mobile) with over 2100 device represented. The experiment “measured the information leakage of feature in each set with respect to the classes instrumenting the Kullback-Leibler divergence (way to measure the difference between two probability distributions) to obtain an information score for every feature” [41].
Table 4-6: information leakage for each attribute
A high score means high entropy, resulting in more information leaked. Table 10-1 demonstrates that mobile device provides less information and may not be as precise for fingerprinting when compared to desktop. As mentioned in chapter 9, plugins play a part in forming a unique fingerprint. Consequently, mobiles do not allow the installation and customisation of plugins and minetypes as these features are standardised in mobile devices and cannot be altered by a user. However, the HTTP header (user agent) was still able to provide valuable information for both desktop and mobile devices, even though mobiles had a lower score.
The high standardization of mobile devices means that features such as fonts, screen size will have little to no variation across the same device. Most mobile device use standard browsers within built native functionality instead of third party plugins.In addition Laperdrix [2] studied the percentage at which mobile can be fingerprinted compared to desktops. The analysis was based on over 1,300 mobile fingerprints. Overall, the analysis concluded show that it was possible to fingerprint mobiles with only a 9% drop in the ability to uniquely identify a device going from 90% desktop to 81% mobile.
As with the previous study by Hupperich [41] mention on mobile device [41] plugins play a small part in producing a unique fingerprint on desktops. Taking full advantage of HTML 5 and ultimately scraping plugins has caused the level of uniqueness in mobile to fall. This has decreased information leaks and helped mobiles gain some privacy. The level of entropy from plugins will be closer to zero with newer installations of Android and IOS compared with legacy installations on older devices, making the former more resistant to fingerprinting.
When aiming to fingerprint mobiles, the main target will be the user agents, which provides rich information about the device and the discriminating emoji’s. According to Laperdrix [2] the user agent on mobile devices are five times more likely to be unique when compared to that of a desktop. When analysing their dataset it was discovered that 25% of smartphones can be identified via the user agent alone. This is due to the fact the manufacturers include information such as the device model number and current firmware version within the user agent. Shown figure 4-1.

Figure 4-1: mobile user agent
Browsers on smartphones is still the main application for accessing the internet. But the rise of the mobile applications has begun to slowly replace the use of browsers. Mobile applications, when installed are granted permissions explicitly by the user. This provides access a plethora of information, unbeknown to the user. It was found that the user agents collected for the study conducted by Laperdix [2] came from mobile apps rather than the default browsers.
The use of emoji’s play a part in producing an entropy point in mobile devices. Mobiles have distinctive hardware effecting the rendering of images and emoji’s, these can be can be every discriminating between two devices. Some manufactures have their own tailor made emoji’s and even across the multiple versions of android these group of emoji’s may differ, making them distinguishable.
Although different attributes are used compared to desktop fingerprinting, the result remains the same, mobile fingerprinting is equally unique to desktop fingerprinting in the eyes of browser fingerprinting.
4.3.1 Sensory Fingerprinting
As technology advances, the use of other methods to fingerprint mobile device have come into play namely sensory fingerprinting. This method uses a multitude of sensors on a smartphone to construct a reliable hardware fingerprint of the phone [45]. Such a fingerprint can be used to de-anonymize mobile devices as they connect to web sites. These robust fingerprints are built to be independent of software state and will survive a factory reset. Bojinov [45] showed that the speaker/microphone system and the accelerometer can be used in construction of a fingerprint.
When using the accelerometer this allows a fingerprinting script to avoid using traditional hardware identifiers such as the IMEI. The stealth of this technique has been show by Bonjinov [45] as the accelerometer when accessed via JavaScript didn’t notify the user in either iOS or Android. The process used by Bojinov involved frequently querying the accelerometer and then approximating the calibration errors in each of the three dimensions to produce a distinguishable fingerprint. In speakerphone-microphone system setup the speaker first emits a sound of various frequencies and the microphone records it. A fingerprint is computed based of the analysis of the multitude and frequency distortion of the recorded signals.
Sensory fingerprinting can be classified under the cross-browser banner as the fingerprint generated does vary across browsers. The sneakiest, but most useful property of this technique is it doesn’t require user interaction or permission [34]. The limiting factor of the technique lies in the collection of correct readings. To gather these readings the device must be left in a distinct position, either facing up or down [34], [35].
This research delves more into device hardware fingerprint and is beyond the scope of this research.
4.4 The evolution of web technologies and browser fingerprinting
The evolution of web technologies will play a big part in how effective web browser fingerprinting will be in limiting user identification. The rise of smartphones (primary medium for accessing the internet) has somewhat contributed to the limiting of unique identification by not incorporating the use of Flash [41]. On the flipside, some technologies will make it easier to single out users such as WebGL which provides information about the graphics processor unit. The aim of this section is to explore possible scenarios in the web technology realm, which may influence browser fingerprinting in the future. These will cover current trends as well as looking at more hypothetical situations.
4.4.1 End of Flash
Adobe Flash has been around since rise of the commercial internet. It has been adopted by millions of users and remains a great means of identification in conjunction with other attributes. Currently the use of Flash has been deprecated across many of the mobile device used today. This includes smartphone and tablets which can be used to access and browse the web. The same cannot be said for laptops and desktops environments, where a user can be exploited more easily. The security vulnerabilities that plague Flash are not its only issue, it also has many privacy implications. Flash provides a rich dataset of information to web servers which can be used to build a fingerprint allowing tracking across sites. As a result web applications are beginning to phase out Flash and adopt JavaScript as well as HTML5. According to the study conducted [2]in which over 118,000 fingerprints where collected, Flash is still present in 80% of the fingerprints acquired from desktops, 71 % had it activated and only 2% had it blocked.
A future without a Flash enabled browser does affect the number of unique fingerprints obtained but by no significant means does it stop it. Laperdrix [2] shows that only a reduction of 7% in the identifying browsers with Flash and those without. The combination of other attributes shared by the browser will still provide information to develop a unique fingerprint in the absence of Flash.
4.4.2 The end of browser plugins
A browser is a dynamic piece of software which can be customised to the users requirements. This may include the implementation of third party plugins and add-ons. The former poses a threat to user privacy and unlike add-ons are executed outside the browser environment in a different process. The user has control in which plugins are installed and which access rights are granted to the plugin. Most systems, especially in homes are operating under the administrator profile, allowing plugins operate more freely, collecting data without issue.
The most common plugins include Flash, Quicktime, Google Earth Silverlight, Java Applet, Adobe acrobat NPAPI and Wacom Tablet plugins. This is not by any means an exhaustive list but each one can play a part in providing unique information about the browser and the machine the browser is running on. The use of plugins unwittingly build up profile of a user. Not every user will have the exact same configuration when it comes to the number of plugins installed, the type or even the versions used. Though plugin enumeration websites can accurately identify your browser via your unique set up.
4.4.2.1 NPAPI
For many years, NPAPI plugins helped browsers add functionality But as time went on became part of the problem and not the solution.
In September 2015 Google chrome version 45 has removed support for NPAPI [43] and have chosen to make use of the embedded technology in modern browsers and utilise the native functionality that HTML5 and JavaScript provide. In 2016 Firefox followed in the footsteps of Chrome [44]. Developers have had to adapt to these changes by either withdrawing support or migrating to an alternative solution. The impact of this will cause the reduction of entropy produced from the list of plugins.
Mobile evolution has completely eradicated the use of plugins and lead the way to a future where the browsers used on desktops/laptops will employ an architecture that doesn’t support the use of plugins. This will be an on gong challenge as plugins still provide a diverse range of features.
Laperdrix [2] estimated the impact of this scenario, measuring the entropy of google chrome before the removal of NPAPI support and after. Firefox was also added has a comparison. As seen in figure 4-2 the entropy has improvement significantly and the complete removal of NPAPI will cause a big impact on desktop fingerprinting and influence web browser fingerprinting.
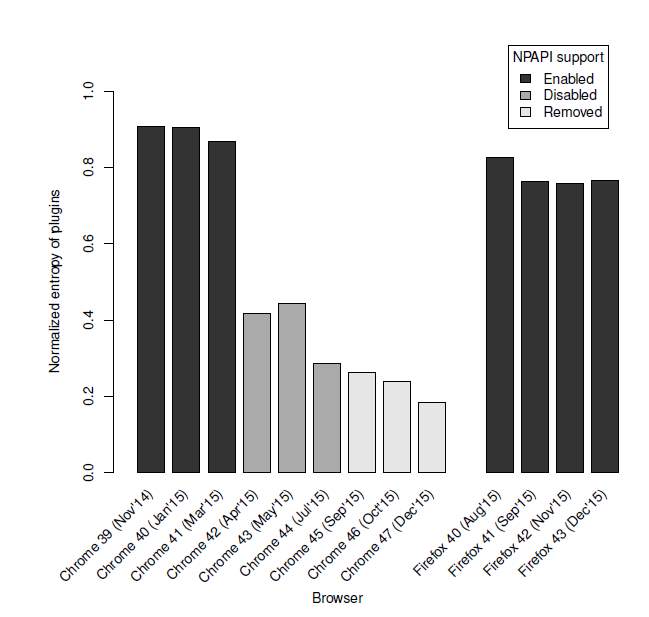
Figure 4-2: NPAPI support over different browser versions
4.4.3 Standardized HTTP headers
A large amount of information for developing a browser fingerprint is sourced from the HTTP headers, which include the user agent, connection header, Accept header, language header plus a few more. What can make HTTP headers valuable targets is the fact that application and web developers sometimes add arbitrary code to these headers and in some instance, create new ones thereby increasing the uniqueness of a browser. The Internet Engineering Task Force (IETF) which develops and promotes voluntary Internet standards has standardised a list of fields for HTTP headers. As technology continually progresses this scenario explores the idea of everyone converging and following a set standard of HTTP header fields.
The impact of such a scenario has been estimated on a dataset [2] and it was determined that although the effect on browser fingerprinting was affected, it only resulted in a moderate decrease in the uniqueness of a fingerprint falling by 8%. The largest impact was on mobile devices where there was a drop in 21%. This shows that being a little more generic especially when talking about the user agent header is of the utmost importance when privacy is concerned.
4.4.4 Reduce the surface of HTML APIs
For the internet experience to continue to thrive if one technology has become problematic then it must be removed and replaced with something equal or better. For Flash and plugins to fade, suitable replacements must be in place providing rich HTML and JavaScript rich features to fill the void. Consequently, HTML APIs keep growing, providing access to an increased number of information about the browser and its environment. The Canvas element is an example of this as well as numerous other APIs which leak information.
The battle between enhancing the user experience by providing rich features and taking privacy into account when setting up APIs is a difficult choice as there is always a trade-off between the two. Yet, it is possible to foresee that future API developments, combined with informed studies about privacy will lead to reduced APIs that still provide rich features.
4.4.5 Increase common defaults
The idea here is to increase the amount of default elements to help reduce the uniqueness of the browser. This task will fall at the feet of developers to achieve this goal. For example, developers, can use whitelists containing a list of default fonts which can be disclosed by the browser. The aim of implementing such measures is to decrease the amount of information provided to web servers but still allow user to customize their experience by having the power to add additional fonts without affecting privacy.
Chapter 5: Analysis of browser add- ons/extensions on multiple browsers
5.1 introduction
The aim of this experiment is to investigate and analyse the effectiveness of browser add-ons in mitigating and protecting user from fingerprinting and tracking. With the objective of reducing the uniqueness score on Panopticlick website, hence maintaining anonymity, of a user. The investigation will discuss the toughness and completeness of add-ons/extension that try to obscure the true nature of a web browser from a website.
The investigation will consider how a single add-on or a combination of different add-ons can provide security and peace of mind for a user. The results will be compared with the standard installation of the browser, standard installation with privacy features enabled, and each of the add-ons tested. As Tor browser is thought to be best browser for evading fingerprinting techniques [5], a comparison will be made with the other browsers chosen.
A browser is able to leak information about itself via but not limited to such attributes as the user agent (which is available both as a HTTP header and as a property of the JavaScript- accessible navigator object), JavaScript, canvas element, IP address and font enumeration. The add-ons/extensions chosen will focus on blocking, spoofing or provide a combination of services. I want to stress that these add-ons/extensions are not malicious in nature. They are legitimately-written software all available to the public via the vendors store.
The following areas will contribute to the experiment:
- Choosing existing add-ons in browsers to mitigate and protect user
- Analyse add-ons to minimize the leakage of information in web browsers
- Evaluate the effectiveness of add-on to reduce the uniqueness score
5.1.2 Testing websites
With the objective of studying fingerprint and its effective researchers have set up websites with purpose of allowing user to test their browser to reveal what information could be gathered about them. There are several of these websites but in the experiment I will focus on the following one:
1. EFF Panopticlick website
The techniques used by this website to fingerprint will provide a good assessment of how an add-on is performing as it covers a diverse range of cases, from pure analysis of the header to an assessment of uniqueness of an aggregate of information made available by the browser to an assortment of tests aimed at specific applications, plugins or components.
5.1.3 Configuration of system, Browsers and Add-ons
With the time constraint and limited resources the experiment will be conducted on a single operating system and windows 10 was selected, which at the time has a largest number of users only surpassed by Windows 7. This also gave me an option of choosing from multiple browser including Internet Explorer not available of other popular operating systems.
Google Chrome and Mozilla Firefox are statistically the most popular browsers so the study will be conducted via these browsers. Table 5-1 Shows the browser, version number and the percentage of total users. All browsers will use default settings. Figure 5-1 shows the current market share of the selected browser.
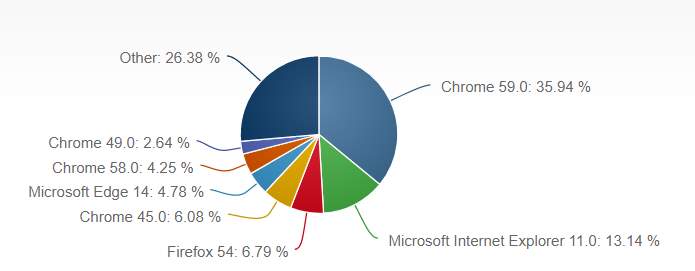
Figure 5-1: Current market share [46]
Given the popularity of add-ons/extensions the idea is to select ones with the highest rating and most installations shown in table 5-2. Dome wild cards have been added, which don’t have a large number of installations, but based on recommendations from research papers and also to target specific areas such as the canvas hash. The higher rated add-ons have been selected this way because of two main reason. Firstly, higher ratings show a good level of satisfaction from users, meaning the add-on did its intended job and performed well. Secondly the high rate usually correlates to higher installation, which means a large of users with similar configurations, a step in the right direction when trying to decrease uniqueness. An advantage of using add-on/extensions is that they are not enumerable through JavaScript and can only be detected through their side effect.
Some websites are able to detect the absence of specific attributes leading to the conclusion that privacy measures have been put in place. The add-ons selected will be the latest available version and will be configured to be as secure as possible by either increasing security settings to the maximum or deleting any preconfigured settings. All other settings are set to their defaults, and all settings are reset to defaults after each experiment. Add-ons or there equivalent are available on one, or both all browsers tested.
5.1.4 Test Cases
The experiment will be separated in to different cases with the aim to improve evasiveness and reduce uniqueness of the browser with each successive case. The cases will be organised as follows:
Case 1: Default installation of browser
Case 2: Browser with Privacy Badger add-on
Case 3: Browser with Random agent spoofer/random user agent add-on
Case 4: Browser with NOScript/ScriptSafe add-on
Case 5: Browser with HTTPs Everywejre add-on
Case 6: Browser with no script/scriptsafe, privacy badger, random agent spoofer add-ons
Case 7: Browser with noscript/scriptsafe, HTTPS EVERYWHERE and canvas defender add-ons
Case 8: Browser with Ghostery, add-ons
Case 9 : Tor Browser default
5.1.6 Procedure
Each case will follow the same procedure:
- Reset browser to default settings
- Activate add-on(s) being investigated, if any
- Open the website(s) and run test
- Record test results
| Browser | Version | % market share |
| Chrome | 59.0.3071 | 59.49% |
| Firefox | 54.0.1 | 12.2% |
Table 5-1: Versions and figures as of July 2017
| Add-on | Installations | Version | Description | |
| chrome | Firefox | |||
| Noscript | – | 1,759,996 | 5.0.6 | Take control of what is running in your browser by blocking unwanted scripts |
| Privacy badger | 6333,358 | 135,800 | 2017.6.13.1 | Block spying ads and invisible trackers! A project by the EFF (Electronic Frontier Foundation). |
| Random agent spoofer | – | 259,826 | 0.9.5.6 | Rotates complete browser profiles ( from real browsers / devices ) at a user defined time interval. |
| Random user agent | 23,510 | – | 2.1.5 | Automatically change the user agent after specified period of time to a randomly selected one, thus hiding your real user agent |
| disconnect | 851,496 | 207,859 | 5.18.23 | Stop tracking by third-party sites and visualize who is tracking you! |
| ghostery | 2,579,750 | 1,016,272 | 7.2.2 | Protect your privacy by blocking trackers on the Web and by learning who is watching you |
| HTTPs everywhere | 1,698,053 | 358,497 | 210.7.18 | Encrypt the web! Enable HTTPS automatically on websites that are known to support it |
| canvasefender | 40,448 | 3.240 | 1.1.1 | Instead of blocking JS-API, Canvas Defender creates a unique and persistent noise that hides your real canvas fingerprint |
| Scriptsafe | 267,442 | – | 1.0.9.1 | |
Table 5-2: add-ons used
With the millions of internet users and only a small number having knowledge of privacy threats beside security measures like disabling cookies, the percentage making use of browser extensions is small in comparison. For these extensions to be effective the number of users has to be large making it a less discriminatory feature. A large majority of user will have an extension to block ads seen on YouTube and Facebook but this will be the extent of their tracking protection. The most popular extension is Adblocker which has 40 million plus installation, 16x more than most used extension in the experiment.
5.2 Test case Results
Case 1: Default installation no extensions
With default settings, the results from this test case shows that there is no protection against fingerprinting and tracking, hence no real privacy in place. This was the same conclusion across both chrome and Firefox. In the tables 12-3 and 12-4 the level of information obtained from both browsers was at its highest making them unique amongst the pool of fingerprints collected. By analysing the data obtained for the Panopticlick tables I can see that in most cases the level of uniqueness amongst the different attributes is quite low for example ‘are cookies enabled?’ returned a value of 1.14, meaning that nearly every browser tested had cookies enabled. Whereas the user agent attribute returned 1 in 502,600 value making the browsers quite unique.
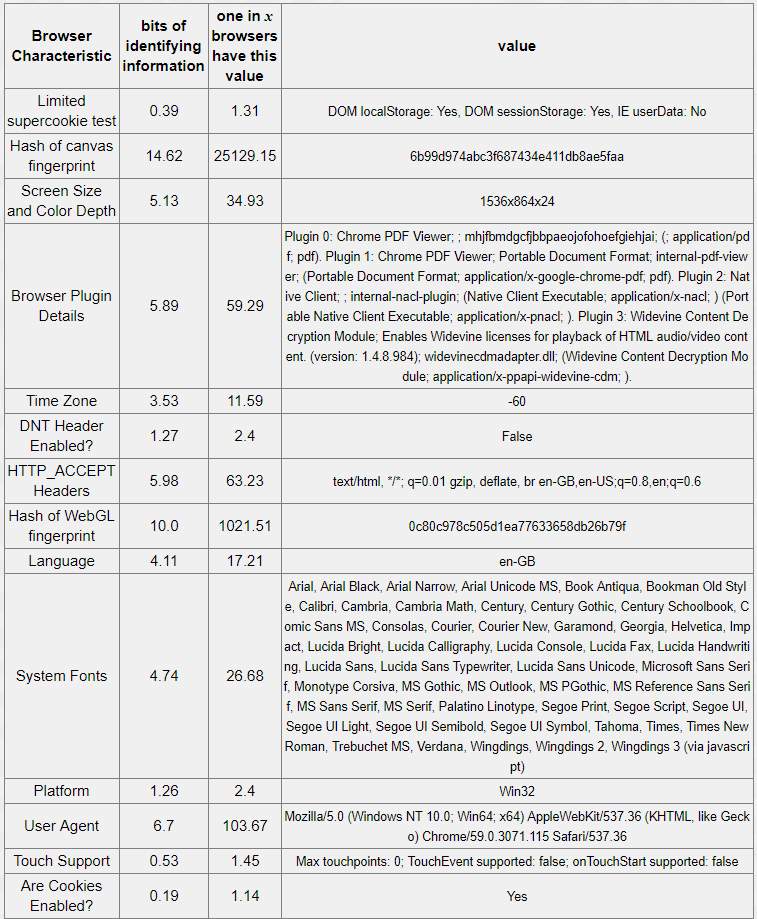
Table 5-3: Chrome browser – 18.94 bits of identifiable information
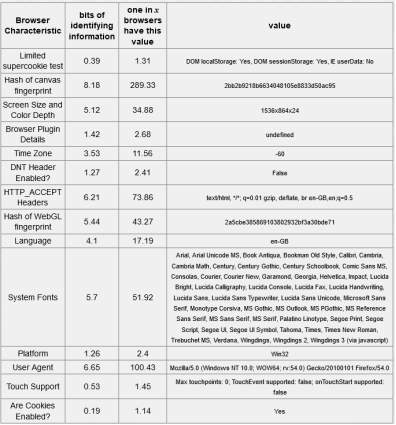
Table 5-4: Firefox Browser – 18.93 bits of identifiable information
Case 2: Browser + privacy badger extension
Privacy Badger an extension recommended by the inventors of Pantopticlick. It does protect against ads but provide very little help in the war against fingerprinting. It does however reduce some of the values compared to the default browser test. Between Firefox and chrome the amount of information captured was still quite vast despite the added security of the browser extension. Firefox did however leak slightly less information the list of plugins were not divulged as well as the hash canvas attribute being less unique (1 in 288) compared to chrome ( 1 in 22848).
Case 3: Browser + agent spoofer
The inclusion on a user agent spoofer did not halt the gathering of information but it can help protect a user by supplying false information. This would be an integral part to building a fake profile if that was the route chosen. From the both Firefox and Chrome tests it can be seen that the user agent was able to be spoofed, still supplying trackers with information. On its own it is a weak defense but in conjunction with other security extensions it may proof to be very useful.
Case 4: Browser +noscript
Noscript is an extension that allows the blocking of scripts or the complete disabling of JavaScript. It is popular in the Firefox domain but unavailable in the chrome ecosystem. Chrome however does allow you to turn off JavaScript which provides a similar effect. The manipulation of the use of JavaScript has the biggest impact to browser fingerprinting amount all the browser extensions. But there is a trade-off between security/privacy and performance. A substantial number of websites require the use JavaScript as part of its functionality, it provides a richer user experience and without some sites won’t even load. As mentioned in various studies the use of JavaScript to gather information is not uncommon [11], [27], [28], [34]The lack of JavaScript impacted FireFox and Chrome in the same manner, it brought the uniqueness down in most categories to 1 in 7 or lower. There was a reduction in the overall fingerprint value going from 1 in 500,000+ to 1 in 23,000. Ultimately this is the goal, making the browser a little more generic so it’s harder to identify, but a balance is needed to allow the internet to function properly.
Case 5: browser + HTTPs everywhere
HTTPs everywhere simply enforces secure HTTP communication where possible and will drop bad HTTP connections. HTTPS everywhere was one of the only add-on tested that produced a discrepancy between the Firefox and chrome browsers. While enabling it in Chrome caused the uniqueness value to decrease from 1 in 500,00 to 1 in 169,000 it has no major effect on Firefox and produced values similar to the default installation. It does allow a profile to be built of a system as there still enough identifiable information. This add-on does provide some protection from trackers but would be more powerful combined with other add-ons.
Case 6: Ghostery add-on
The inclusion of Ghostery produced no noticeable impact with regards to increasing protection against browser. This was the same across both Chrome and Firefox. Both browsers produced 18.9 of identifiable information, the same result has the default browser.
Case 7: NoScript/Scriptafe, privacy badger, random agent spoofer add-ons
To strengthen the protection, I combined these three add-ons to do a number of things. Too limit information leakage, provide false information if leaked and protect from trackers all over the internet. The spoofer is quite a useful plugin it changes settings to common values so that your browser’s fingerprint is less unique. Within the Firefox environment this proved somewhat successful only providing 14.44 bits of information the lowest of all the test cases and uniqueness to 1 in 31,402. Within Chrome the same could not be said. While the test shows that the combination of add-ons does provide strong protection against web tracking, but against fingerprinting, it is weak. This can be seen from seen from high amounts of data leakage (18.96 bits) witnessed from the test results.
This case is slightly skewed as identical add-ons were utilised in both browsers due to the unavailability in Chrome. In this case, they were substituted for the closest match in the store. The use of the scriptsafe add-on found in the chrome store caused the Panopticlick test to become inoperable and was subsequently replaced by simply disabling JavaScript.
Case 8: NoScript/Scriptsafe, HTTPs everywhere and canvas defender
Being the JavaScript has the biggest impact of building a fingerprint profile I kept in this test case. HTTPS everywhere will provide defense against trackers and insecure sites and canvas defender will attack the canvas attribute, spoofing the canvas hash. As suspected this case performed very similar to case 6 which meant it also had the disadvantage of case 6. The information leakage was slightly high at 14.55 bits but as JavaScript was disabled most categories just provided acknowledgement of this and did not necessary providing specific information. The use of canvas defender become void because it was unable to be detected (disabling of JavaScript). This combination dropped the uniqueness value to 1 in 23926. When installed on chrome the test did yield some good results, overall it was similar to Firefox but not as dramatic, more information was provided by the browser (16.96 bits) and is generated a moderate level of uniqueness, 1 in 127195.
Special Case 9: Tor default settings
Tor is currently touted as a good evasive solution to browser fingerprinting [6], [40] as it has been preconfigured for the purpose of maintaining anonymity by spoofing parameter that identify a user. Built of the back of Firefox, Tor aims to make a fingerprint as generic as possible by making a fingerprint identical to every other Tor browser. Tor is further discussed in chapter 11. Tor as standard have nosciprt and HTTPS everywhere activated upon installation. Tor, when test was able to produce the lowest uniqueness score (1 in 4599) compared to all the previous test cases and limits the information leakage to 12.17 bits of identifiable information shown table 5-5 of this 12 bits not all was specific but whatever is provided can still help a fingerprinter build a better profile, it could simply be the absence of information which helps distinguish a browser.
Trying to simulate the same affect in Chrome and Firefox does help somewhat to provide better defense against privacy but ultimately the addition of more extensions and settings manipulation adds granularity to a previously smooth surface causing a browser to stand out further. Tor functionality for avoiding fingerprinting is very brittle as minor changes in screen size or enabling JavaScript could have a significant impact of the ability to defend against fingerprinting. Tor browsers mono-configuration is its most valuable weapon in the war on fingerprinting.
The entropy produced by Tor when tested could be further reduced if more of the population used it, generating more of the same fingerprint.
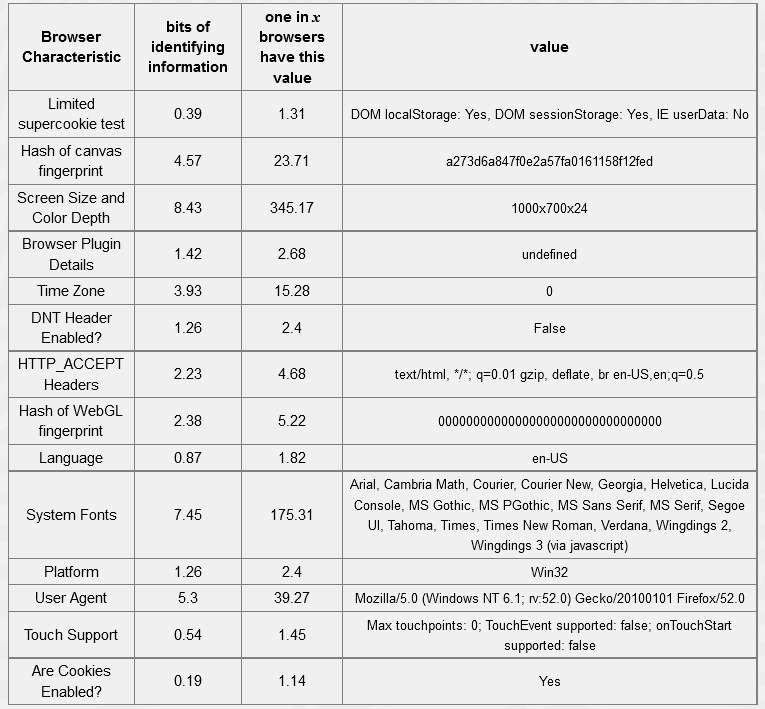
Table 5-5: Tor browser 12.17 bits of identifiable information
All results in appendix.
5.3 Discussion
In this experiment, it has been demonstrated that using add-ons in the Firefox and Chrome web browsers that we can protect users from information leakage to websites as well as limit tracking of user behavior. This happens to varying degrees but in the majority of cases some change was observed. Numerous add-ons are evaluated using the Panopticlick website to observe the effectiveness of them in terms defense against fingerprinting. There was a total of eight Cases, where 3 of them were using different combinations of add-ons. In this section, we discuss some of the findings in the experiments, as well as the limitations of the experiment.
5.3.1 The Results
The results confirmed my hypothesis on the effect add-ons would have on web browsing fingerprinting and tracking. I expected that a good level of protection could be established, this would very dependent of the add-ons utilised but ultimately it would be more a case of managing them. The results shows varying levels of entropy and browser uniqueness amongst the test cases. The experiment shows that disabling JavaScript has the biggest impact on mitigating fingerprinting. Having utilised add-ons to defend browser characteristics like the user agent string I can say that it is possible to supply fingerprinters with false information, which can be changed at regular intervals. This still means entropy will be high but the user can disguise themselves in an effort to avoid identification. This method of spoofing can be spotted in the hash of the canvas attribute also.
The overall results show that add-on can be effective either by obscuring information or providing a more generic profile. This doesn’t guarantee defense from fingerprinting but does provide insight into what works and may aid in development of more advanced methods or add-on that aim to thwart fingerprinting. Furthermore being that the add-ons chosen are quite popular, websites can be configured to check for them further reducing their effectiveness. Generally, the results from the experiment were in line with what was expected but test case 6 did produce slightly unexpected results. The same add-ons were implemented in both the chrome and Firefox browsers but these provided a thinner wall of protection in comparison to Firefox, meaning that the overall entropy was higher and the browser was said to be quite unique. I suspect that the spoofed agent used in chrome contributed highly to this anomaly. Looking at table…….it shows when tested that Chrome to be unique with a score of 1 in approximately 500,000. Being that the agent spoofer add–on does produce random user agent information, I suspect sometimes the information doesn’t match up. For example, it may state the browser is running on an iPhone with Flash plugins which wouldn’t be the case as iPhone doesn’t incorporate Flash. when retested the same result was given.
The results show that further testing is required as the add-ons available across both the Google Chrome and Firefox store is quite vast and the samples used was quite small. This would provide a more in depth and accurate view of the effectiveness of add-on as well as provide some insight in to more powerful security combinations.
5.3.2 Analysing the effectiveness of add-ons
The quality of a fingerprint is determined by the number of “bits” of identifying information. The higher the bits of information, he higher the entropy of the that attribute leading to a more distinguishable browser or device. By placing a browser situations, it can be tested to discover how it behaves and a total score can be derived based of the total number of bits. For example, whether cookies are enabled provides one bit of information (either they are enabled, or they are not enabled).
If we assume that the testable behaiours are evenly distributed, then any configuration with n bits of information occurs with probability 1/2n. However, the actual math surrounding this becomes somewhat more complicated due to certain settings being more popular. For example, most users have cookies enabled because that is the default in their browser; therefore, having cookies enabled does little to distinguish you from other users. But, if you are the rare person with cookies disabled, you will be more identifiable. It is impossible to not provide any fingerprinting information because the information is collected as a Boolean value: either your browser supports a feature or it does not. However, it is possible to reduce the uniqueness of that information by trying to match other users.
From analysing the results obtained from the experiment undertaken I believe the approach of using multiple add-ons and trying to shoehorn yourself into the middle of the bell curve is ultimately destined to fail. That is not to stay that add-ons are not effective because they are to some degree, this has been demonstrated in some of the test cases. The trade-off is the more protection via add-ons is increased the higher the level of uniqueness. This is an example of the fingerprint paradox.
Part of the problem is that there are many ways to build a fingerprint that trying to block every exit becomes an enormous task. Add-ons are generally developed to defend against information being extracted from a singular or multiple browser characteristic(s). But to cover all bases, they have to be used in conjunction with each other providing a synergistic affect with the aim of sitting in the middle of the bell curve (becoming just another generic user)of for all browsers. While fingerprinting techniques like Canvas, AudioContext and other features might leak information about the setup of a browser or system. These can be assessed and action can be taken to either disable or patch these areas, but to Panopticlick this may decrease the uniqueness of a browser but ultimately harms anonymity by causing the browser to stand out.
Majority of these add-on do allow you to customise security with the use of whitelists. So, it is possible to disable JavaScript across the board, only allowing a list of preselected sites to use JavaScript. This would be one method of getting around the non-functioning website issues but requires some work from the user. Other add-ons also provide some form of fine tuning but even at the highest setting there was little sense of increased protection. For example, most add-ons that are targeted towards blocking trackers such as privacy badger also allow whitelists to be setup. By default, everything can be blocked the aid of whitelist provides a better user experience allowing sites that are trusted to bypass checks. The problem here is that it’s not easy to maintain up-to-date whitelists.
One of the main driving forces building someone’s loyalty to a browser or website is the user experience. The add-ons were initially selected to be able to provide a service without hampering the user experience. In the majority of cases this was accomplished but with the JavaScript so in embedded in the online environment nowadays, disabling it only dulls the user experience. Some websites can function on a bare bones setup but most cannot. The activation of JavaScript is essential for certain websites to run properly. For the privacy savvy user a balance can be stuck utilising some of the features built in. But for an average user who doesn’t understand the implication being unprotected has on security, they may opt for performance over privacy.
5.4 Related work
This is not the first experiment to focus on web browser fingerprint [11], [16], [18], [34] some focus on proving the ability to fingerprint, other discuss the effects of fingerprint on privacy and some study to what extend fingerprint can track a user. The purpose of fingerprinting is to build up a unique identifiable profile which will be used for usually one of the following: a advertising, analytics or behavioral tracking.
So it is firmly established that it is indeed possible to fingerprint and track many devices. What I wanted to focus on here is a simple evasion technique that a standard user could implement using the resources available. The effective of add-ons with regards to tracking has been studied and document [3] but my experiment encompasses avoiding tracking but also avoiding browser fingerprinting.
In 2011 Repriv [47] was a tool developed with goal to try and solve privacy issues. To achieve this, they had to define rules based of the feelings of users with regards to web based tracking. The task of this tool was to perform data mining operations and then send relevant approved information about a user to first party websites to be used. This empowers a user by allowing them to control what personal information is shared across the networks, and websites. The disadvantage of this tool was the lack of understanding of the Repriv protocol and the difficulty at implementing across all websites without standardization [3].
Further down the timeline another tool was developed called MindYourPrivacy [3] a tool for controlling traffic coming in. It uses proxies to filter traffic and advertisements, analytics and tracker scripts were removed from the HTML source code directly. Users could observe tracking information on an interface provided. A main privacy concern related to use of this tool was with the use of proxies itself, since all user traffic flows through it.
Fourthparty was one of the more recent tool development [19] this add-on implements detailed logging of tracking mechanisms found on the web, all logged information can be extracted. The main purpose of this tool is to establish a relationship between first party websites and trackers.
You can see that using tool and add-ons for analysing or protection against tracking and profiling has been around for a while. It may not directly address fingerprinting but it does give an idea of where to start.
The key novelties of my work compared to Ruffell[3] are as follows: The experiment conducted has been done so recently, whereas Ruffell[3]study was run in 2015. With the constant evolution of web technologies, this gives this experiment access to improved, updated add-ons, a bigger source of add-ons to choose from, a large population uiltising add-on as well as the internet and more privacy focused browsers, with a bigger user base.
Some research has been done into the use of browser extension for protection[3], [4], [48]. Whereas Ruffel [3]focused on first and third party tracking and not necessary browser fingerprinting, the results obtained from that study did reflect the result from this study. It was concluded that browser add-ons were effective for general tracking. The use of user agent spoofing was the entire subject of another study [4]. To protect user privacy several spoofers were tested and the result show that can play a role in protecting privacy. The browser extension spoofers were utilised in both chrome and Firefox as a means of disguising the user agent in this experiment. The extension spoofers used did show that it was possible to provide fake information similar to what would have been leaked. While it may not have reduced the score on paper, but it is clear to see that deploying a fake profile for means of fingerprint protection may prove to be successful. Nikiforakis [4] suggest that using agent spoofers is not advisable as a single means of protection. My findings show that this is true but in conjunction with other add-ons it could be used successfully. Without testing more combinations of add-on it’s hard to state this conclusively.
5.5 Fingerprinting of Add-ons/Extension
My analysis shows that a user will be tracked using one method or another. The main objective here is just trying to minimize exposure, this is the service that browser add-ons have been developed to will provide. In related a study it has been shown that it is possible using the add-ons installed, to help build a fingerprint profile[48]. As shown in chapter 9 fingerprint usually takes advantage of the plugins, font list, user agent, JavaScript DOM to construct a profile. Xhound [48] scrutinized the top 10,000 Chrome Store extensions, and showed that “at least 9.2% of extensions introduce detectable changes on any arbitrary URL, and more than 16.6% introduce detectable changes on popular domains. The numbers increase to more than 13.2% and 23% respectively, when only the top 1,000 extensions were considered. Moreover, it was found that popular extensions remain fingerprintable over time, despite updates and rank changes” [48].
As stated in a previous sections the use of extensions for browsers is a popular countermeasure amongst users. Unlike plugins, extensions aren’t enumerable through JavaScript and so extension may be detected via the side effects produced or the absence of something in a normal configured browser. If Xhound gains some traction it may be possible to alter the affect add-ons have on protecting browsers, users and systems from fingerprinting. Moreover, it will provide another attribute to be measure increasing the overall level of entropy.
5.6 Limitations
With hundreds, possibly thousands of add-ons and countless combinations it’s hard to evaluate them all and choose the right combination that will not only provide protection but keep the level of uniqueness low. All tests were conducted via the Panopticlick website which compares my browser to the dataset they have on record. Since the rise of fingerprinting in the last decade, the number of testing sites also increased, containing their own dataset of fingerprints. Using these other sites such as amIunique [33] could provide different results as the comparison data will be different. I do believe that just using Panopticlick does give an overview of how effective the add-ons are.
With such a restricted dataset, it’s hard to gain an accurate view of what measures are really effective and what causes an increase level of uniqueness. We must keep in mind that the people who visit Panopticlick may not be considered a typical user but a more privacy conscious user, a smaller section of the internet population, who values their privacy. Panopticlick samples are therefore slightly skewed in this case as the data wouldn’t be collected from a random set of overall internet users but rather this small privacy aware group. The test results compare the system tested to systems of other privacy conscious users.
If we look at a typical user and the use of JavaScript within browser. You’ll find that the clear majority of users wouldn’t or even know how to disable JavaScript in Chrome or Firefox. Most don’t even understand the function of JavaScript or how it can be used to invade privacy, fingerprinting and tracking a user. Disabling JavaScript set you apart from the Crowd providing identifiable characteristic. Generally, as with many things there is a trade-off. Disabling JavaScript increases uniqueness but it also hides information from potential fingerprinters and trackers.
If a browser is tested on the Panotpiclick site was shown to only reveal 8.08 bits of information this wouldn’t be considered normal as most typical users wouldn’t go to the extreme of hiding this much information.
Chapter 6: Conclusion
6.1 Conclusion
Web browser fingerprinting has evolved rapidly since it was brought to the attention of the privacy conscious public courtesy of the Panopticlick study [11], [15].The aim of this dissertation was to dissect the role of browser fingerprinting into various sections and then analyse and discuss how each part either contributed to the development of a fingerprint or effected the privacy of user. The initial chapters provide key insights of how browser fingerprinting is integrated into the online society. Research was done into attributes associated with building a viable fingerprint and their effectiveness in helping to track users and successfully Identify a system. It was observed that these attributes can change depending on the methods used and the precautions the user took to protect themselves. To address the problem of privacy, in this dissertation the current technology, methods and fingerprinting techniques were investigated to determine the popularity of one technique over another but also to determines strength of each, the weakness of each and ease of companies incorporating each method.
From the research, I argued and demonstrated that it was almost impossible for a user or system to completely be 100% anonymous and that attempting to continually obfuscate your presence would only increase uniqueness. This makes the system an easy target for fingerprinting, thereby proving the theory of the fingerprint paradox. I argued that in most case some form of information leakage would occurs but the level entropy could be manipulated by the user or in some cases the vendor of the browser. It was shown in this paper that the impact on privacy was substantial, and if a user opted to be part the online community that privacy may fall a distant second to the needs or goals of a company. This in most cases would translate to more profits. The discussion of the real world uses of browser fingerprinting shone light on how it can be used to benefit and protect a user in such instances as fraud and impersonation.
An experiment was conducted to understand whether it was possible to reduce the effectiveness of browser fingerprinting. The results further supported the statement that it was impossible to completely hide oneself but did show that with the right combination of add-ons and settings, some protection against fingerprinting could be obtained. The findings indicated that the HTTP header attributes were less prone to causing an impact on the browser but provided the most information. It was discovered that manipulation of JavaScript affected user experience the most but also stopped fingerprinting scripts from being executed. The results obtained were expected to some degree but with a limited sample size it was be difficult to determine the level of protection that could of been obtained, that would strike a balance between keeping a user safe and providing a great user experience.
The findings support the conjecture that altering the fingerprint attributes in a way that was legitimate but unexpected, is likely to reduce the effectiveness of a fingerprinting site. However it was determined that (apart form the issue of the fingerprinting paradox) the measures a user may have to go to protect themselves would be beyond the scope of a general non security conscious user and in some cases would be too complex to manage as attributes or settings may need to be altered frequently. The onus lies at the feet of the user with regards to implementing protection for the system, without their interaction only a certain level of protection can be achieved by vendors.
The aim of the research was ultimately to determine the impact browser fingerprinting had on privacy and to investigate possible ways to thwart attempts. The research provided a detailed breakdown of the intricacies of browser fingerprinting consulting previous studies done on the subject, conducting primary research and analysing the information gathered and presented. This has provided evidence and allowed for further discussion on the subject area of browser fingerprinting, which I feel is needed as we move further in to the digital age.
6.2 Limitations
Having now completed my dissertation upon reflection would say that there was two limitations that did not necessary affect the overall quality or result of the dissertation but could have strengthened it.
Lack of knowledge; having more background knowledge of web technologies would have allowed me to better understand areas of the research material that were more technical. This may have contributed to produce a slightly more technical paper. Moving forward a simple recommendation for the future would be to spend a period of time understanding the surrounding areas of the chosen topic.
Sample size; As mentioned in chapter 5 the sample size of the experiment was quite limited. It did provide a good overview of the general trend of how effective add-ons are. However data is always better to draw conclusions. With the time constraints and limited resources, it was not possible to expand the experiment. This can be remedied with better planning and organization.
6.3 Implications of the research
Prior to this research most papers have focused on a specific element of browser fingerprinting this included at studying attributes associated with browser fingerprinting, examining the technique or countermeasures available to combat browser fingerprinting or proving the ability to construct a fingerprint to track and profile a browser.
This research has focused on investigating brining all those different elements together to provide a comprehensive report detailing the attributes used in fingerprinting, the impact on privacy, the affect across various devices and evasive techniques available for fingerprinting protection.
Bibliography
[1] B. N. Nikiforakis, “Browser Fingerprinting and the Online-Tracking Arms Race,” IEEE Spectrum. pp. 1–7, 2014.
[2] P. Laperdrix, W. Rudametkin, and B. Baudry, “Beauty and the Beast: Diverting Modern Web Browsers to Build Unique Browser Fingerprints,” Proc. – 2016 IEEE Symp. Secur. Privacy, SP 2016, pp. 878–894, 2016.
[3] M. Ruffell, J. B. Hong, and D. S. Kim, “Analyzing the Effectiveness of Privacy Related Add-Ons Employed to Thwart Web Based Tracking,” Proc. – 2015 IEEE 21st Pacific Rim Int. Symp. Dependable Comput. PRDC 2015, pp. 264–272, 2016.
[4] N. Nikiforakis, A. Kapravelos, W. Joosen, C. Kruegel, F. Piessens, and G. Vigna, “Cookieless monster: Exploring the ecosystem of web-based device fingerprinting,” Proc. – IEEE Symp. Secur. Priv., pp. 541–555, 2013.
[5] G. Acar, M. Juarez, and N. Nikiforakis, “FPDetective: Dusting the web for fingerprinters,” Proc. 2013 ACM SIGSAC Conf. Comput. Commun. Secur., pp. 1129–1140, 2013.
[6] N. Kaur, S. Azam, K. Kannoorpatti, K. C. Yeo, and B. Shanmugam, “Browser Fingerprinting as user tracking technology,” in Proceedings of 2017 11th International Conference on Intelligent Systems and Control, ISCO 2017, 2017, pp. 103–111.
[7] N. Nikiforakis, A. Kapravelos, W. Joosen, C. Kruegel, F. Piessens, and G. Vigna, “On the workings and current practices of web-based device fingerprinting,” IEEE Secur. Priv., vol. 12, no. 3, pp. 28–36, 2014.
[8] R. Upathilake, Y. Li, and A. Matrawy, “A classification of web browser fingerprinting techniques,” 2015 7th Int. Conf. New Technol. Mobil. Secur. – Proc. NTMS 2015 Conf. Work., 2015.
[9] R. Broenink, “Using browser properties for fingerprinting purposes,” pp. 169–176, 2012.
[10] ThreatMetrix, “Device Fingerprinting and Fraud Protection Whitepaper,” pp. 1–6, 2015.
[11] P. Eckersley, “How unique is your web browser?,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 6205 LNCS, pp. 1–18, 2010.
[12] “Cookies – European commission.” [Online]. Available: http://ec.europa.eu/ipg/basics/legal/cookies/index_en.htm. [Accessed: 09-Aug-2017].
[13] G. Acar, C. Eubank, S. Englehardt, M. Juarez, A. Narayanan, and C. Diaz, “The Web Never Forgets: Persistent Tracking Mechanisms in the Wild,” Proc. 2014 ACM SIGSAC Conf. Comput. Commun. Secur. – CCS ’14, pp. 674–689, 2014.
[14] J. R. Mayer, “Internet Anonymity in the Age of Web 2.0,” A Sr. Thesis Present. to Fac. Woodrow Wilson Sch. Public Int. A airs Partial ful llment Requir. degree Bachelor Arts., p. 103, 2009.
[15] EFF, “Panopticlick.” [Online]. Available: https://panopticlick.eff.org/. [Accessed: 01-Aug-2017].
[16] K. Boda, A. M. Foeldes, G. G. Gulyas, and S. Imre, “User Tracking on the Web via Cross-Browser Fingerprinting,” Inf. Secur. Technol. Appl., vol. 7161, pp. 31–46, 2012.
[17] M. Vaites, “The effectiveness of a browser fingerprint as a tool for tracking,” no. February, 2013.
[18] K. Mowery and H. Shacham, “Pixel Perfect : Fingerprinting Canvas in HTML5,” Web 2.0 Secur. Priv. 20, pp. 1–12, 2012.
[19] J. R. Mayer and J. C. Mitchell, “Third-party web tracking: Policy and technology,” Proc. – IEEE Symp. Secur. Priv., pp. 413–427, 2012.
[20] F. Roesner, T. Kohno, and D. Wetherall, “Detecting and defending against third-party tracking on the web,” Proc. USENIX Conf. Networked Syst. Des. Implement., no. Nsdi, p. 12, 2012.
[21] Mind IT, “Using browser fingerprints for session encryption – Mind IT.” [Online]. Available: https://www.mind-it.info/2012/08/01/using-browser-fingerprints-for-session-encryption/. [Accessed: 09-Aug-2017].
[22] Google Inc, “Privacy Policy – Privacy & Terms – Google.” [Online]. Available: https://www.google.com/policies/privacy/archive/20150501-20150605/. [Accessed: 18-Feb-2017].
[23] C. Kolbitsch, B. Livshits, B. Zorn, and C. Seifert, “Rozzle: De-cloaking Internet malware,” Proc. – IEEE Symp. Secur. Priv., pp. 443–457, 2012.
[24] U. Fiore, A. Castiglione, A. De Santis, and F. Palmieri, “Countering browser fingerprinting techniques: Constructing a fake profile with google chrome,” Proc. – 2014 Int. Conf. Network-Based Inf. Syst. NBiS 2014, pp. 355–360, 2014.
[25] C. Castelluccia and A. Narayanan, “Privacy considerations of online behavioural tracking,” pp. 1–33, 2012.
[26] “e-privacy-directive-review-draft-december.pdf.” .
[27] M. Mulazzani, P. Reschl, and M. Huber, “Fast and Reliable Browser Identification with JavaScript Engine Fingerprinting,” Proc. W2SP, 2013.
[28] K. Mowery, D. Bogenreif, S. Yilek, and H. Shacham, “Fingerprinting Information in JavaScript Implementations,” Web 2.0 Secur. Priv., pp. 1–11, 2011.
[29] C. P. Hansen, “Launching Sputnik into Orbit,” Chromium Blog, Jun. 2009.
[30] Y. Cao, “( Cross- ) Browser Fingerprinting via OS and Hardware Level Features,” no. March, 2017.
[31] “Cross Browser Tracking Techniques – Deep Dot Web.” [Online]. Available: https://www.deepdotweb.com/2017/03/06/cross-browser-tracking-techniques/. [Accessed: 01-Aug-2017].
[32] J. Notre, “Advanced Tor Browser Fingerprinting.” [Online]. Available: http://jcarlosnorte.com/security/2016/03/06/advanced-tor-browser-fingerprinting.html. [Accessed: 05-Aug-2017].
[33] “Am I unique?” [Online]. Available: https://amiunique.org/. [Accessed: 01-Aug-2017].
[34] T.-F. Yen, Y. Xie, F. Yu, R. P. Yu, and M. Abadi, “Host Fingerprinting and Tracking on the Web: Privacy and Security Implications,” Netw. Distrib. Syst. Secur. Symp., pp. 1–16, 2012.
[35] browserprint, “Browserprint.” [Online]. Available: https://browserprint.info/. [Accessed: 02-Aug-2017].
[36] multiloginapp, “How Canvas Fingerprint Blockers Make You Easily Trackable | Multiloginapp.” [Online]. Available: https://multiloginapp.com/how-canvas-fingerprint-blockers-make-you-easily-trackable/. [Accessed: 05-Aug-2017].
[37] multiloginapp, “How to create a unique online identity with Multiloginapp? | Multiloginapp.” [Online]. Available: https://multiloginapp.com/how-to-create-a-unique-online-identity-with-multiloginapp/. [Accessed: 07-Aug-2017].
[38] firegloves, “Cross-browser fingerprinting test 2.0.” [Online]. Available: https://fingerprint.pet-portal.eu/?menu=6. [Accessed: 05-Aug-2017].
[39] N. Nikiforakis, W. Joosen, and B. Livshits, “PriVaricator: Deceiving Fingerprinters with Little White Lies,” Research.Microsoft.Com, pp. 820–830, 2014.
[40] S. Luangmaneerote, E. Zaluska, and L. Carr, “Survey of existing fingerprint countermeasures,” Int. Conf. Inf. Soc. i-Society 2016, pp. 137–141, 2017.
[41] T. Hupperich, D. Maiorca, M. Kührer, T. Holz, and G. Giacinto, “On the Robustness of Mobile Device Fingerprinting,” Proc. 31st Annu. Comput. Secur. Appl. Conf., pp. 191–200, 2015.
[42] P. Laperdrix, W. Rudametkin, and B. Baudry, “Mitigating Browser Fingerprint Tracking: Multi-level Reconfiguration and Diversification,” Proc. – 10th Int. Symp. Softw. Eng. Adapt. Self-Managing Syst. SEAMS 2015, pp. 98–108, 2015.
[43] Google, “NPAPI deprecation: developer guide – The Chromium Projects.” [Online]. Available: https://www.chromium.org/developers/npapi-deprecation. [Accessed: 01-Aug-2017].
[44] Mozilla, “NPAPI Plugins in Firefox | Future Releases.” [Online]. Available: https://blog.mozilla.org/futurereleases/2015/10/08/npapi-plugins-in-firefox/. [Accessed: 01-Aug-2017].
[45] H. Bojinov and Y. Michalevsky, “Mobile Device Identification via Sensor Fingerprinting,” arXiv Prepr. arXiv …, pp. 353–354, 2014.
[46] netmarketshare.com, “Browser market share.” [Online]. Available: https://www.netmarketshare.com/browser-market-share.aspx?qprid=2&qpcustomd=0. [Accessed: 02-Aug-2017].
[47] M. Fredrikson and B. Livshits, “R E P RIV : Re-Envisioning In-Browser Privacy,” Organization, 2010.
[48] A. Submission, “XHOUND : Quantifying the Fingerprintability of Browser Extensions,” Oakland, pp. 1–19, 2017.
Appendices
Appendix A experiment results
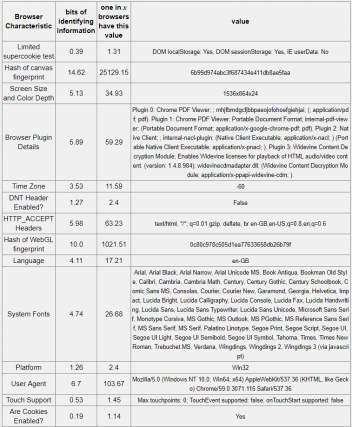
Default settings
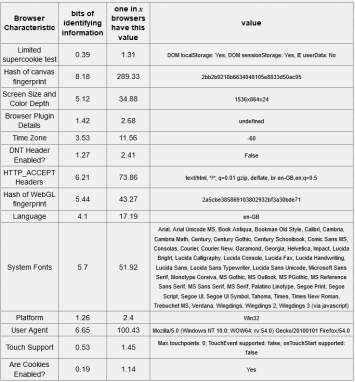
Chrome: unique among the 502,58318.94 bits of identifying information.
FireFox: unique among the 502,407; 18.93 bits of identifying information.
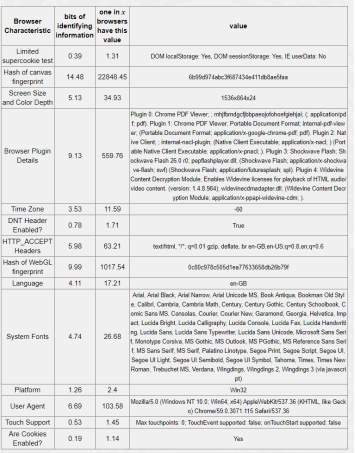
Case 2: Privacy badger
Chrome: appears to be unique among the 502,666; at least 18.94 bits of identifying information.
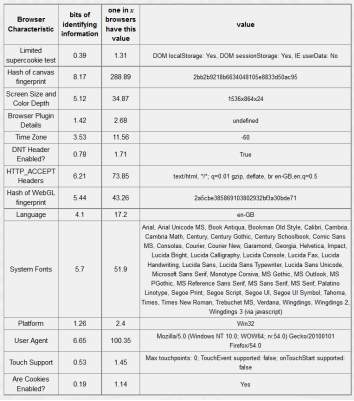
Firefox: appears to be unique among the 502,666; at least 18.3 bits of identifying information
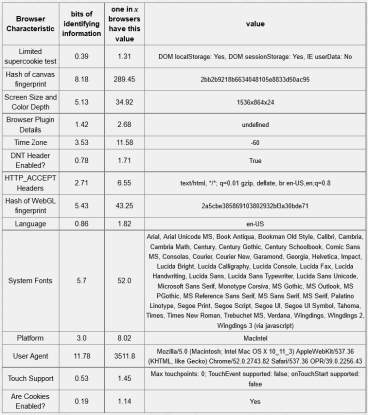
Case 3: Random agent spoofer (firefox), random user agent (chrome)
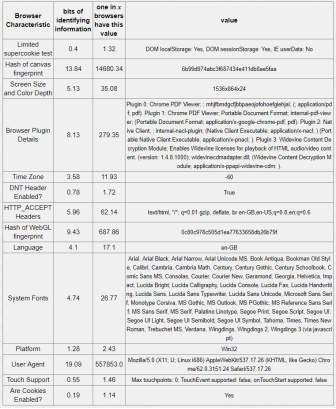
Firefox : 1 in 502,420 uniqeness; 18.94 bits of identifiable information
Chrome: 1 in 502,420; 18.94 bits of identifiable information
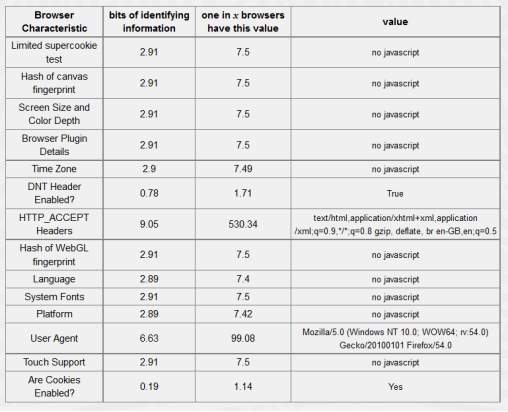
Case 4: no script (firefox) / scriptsafe (chrome)
FireFox: 1 in 23924.38 browser uniqueness; 14.55 bits of identifiable information

Case 5: HTTPS Eeverywhere
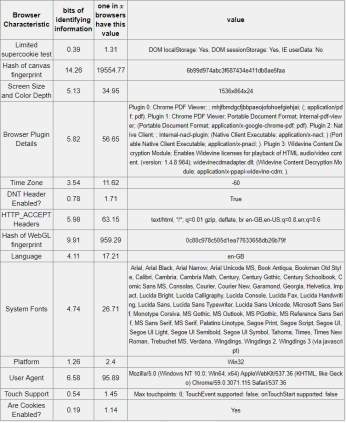
CHROME: one in 169474.67 browsers uniqueness; 17.37 bits of identifying information.
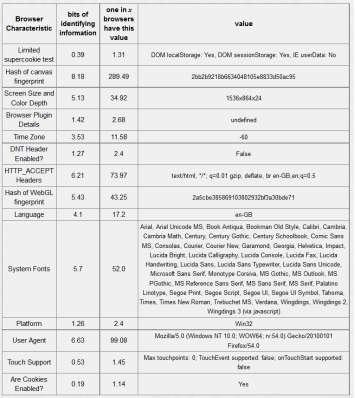
FireFox: unique among the 502,407; 18.94 bits of identifying information.
Case 6: Ghostery
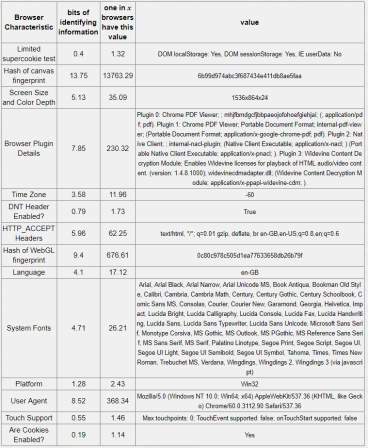
Chrome and Firefox : 1 in 502, 407 uniqueness; 18.9 bits of identifiable information
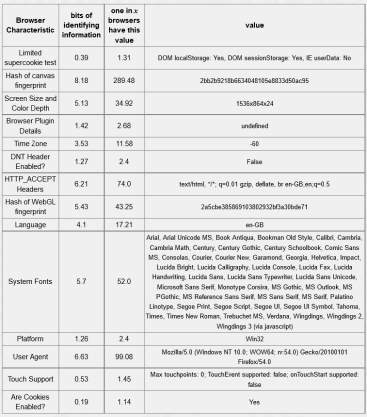
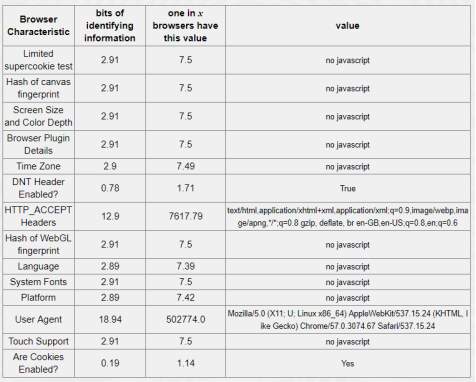
Case 7: noscript(firefox) scriptsafe(chrome), privacy badger, random agent spoofer
Chrome: unique among the 502,407; 18.94 bits of identifying information.
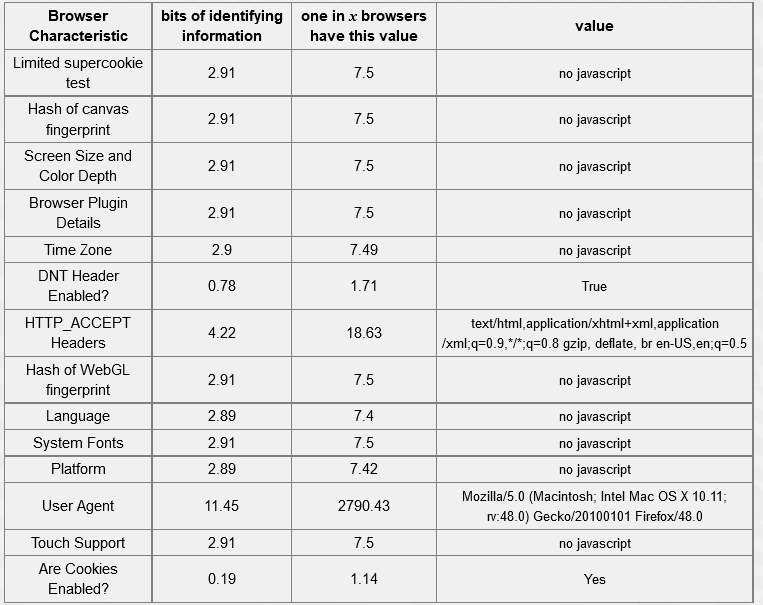
Firefox one in 31402.13 browsers uniqueness; at least 14.44 bits of identifiable information
Case 8: noscript(forefox) scriptsafe(chrome), HTTPS EVERYWHERE and canvas defender
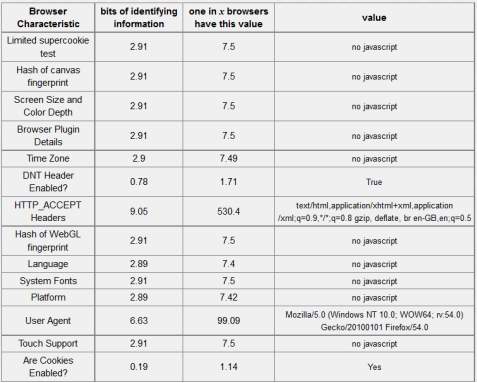
FireFox: one in 23926.1 browsers uniqueness; at least 14.455 bits of identifiable information
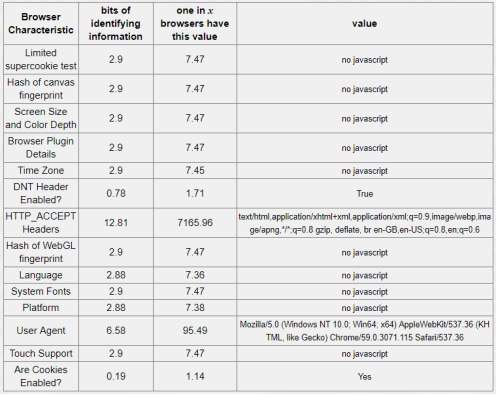
Chrome: one in 127195.75browsers uniqueness; at least 16.96 bits of identifiable information
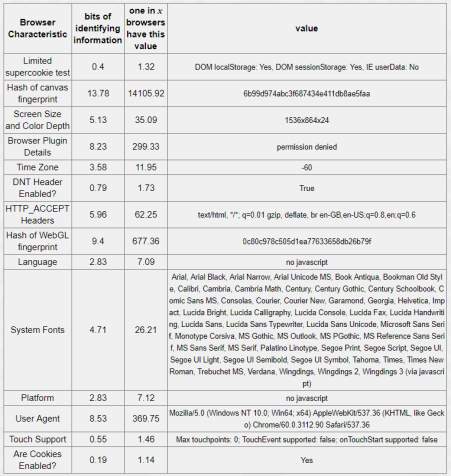
Case 8 (chrome only) + ghostery
1 in 282120 uniqueness; 18.11 bits of identifiable information
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Cyber Security"
Cyber security refers to technologies and practices undertaken to protect electronics systems and devices including computers, networks, smartphones, and the data they hold, from malicious damage, theft or exploitation.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: