Development of AI Vision for Autonomous Vehicles Using FPGA
Info: 3026 words (12 pages) Example Dissertation Proposal
Published: 12th Oct 2021
Contents
1.1 YOLO USING DARKNET FRAMEWORK....................................................... 3
1.2 SEMANTIC SEGMENTATION......................................................................... 4
The primary given objective of the project is as follows:......................................... 5
1. Introduction
With the growing technological invention towards smarter lifestyle, AI plays a major role in changing mankind. The concept of AI was first coined in 1943 and is inspired by biological neurons, found in human brain, which are interconnected nodes that can perceive and correlate raw data, cluster and classify them over time and continuously learn to improve. They play a major role in technologies that works on massive data to give an almost perfectly accurate prediction.
Over time, this artificial neural networks (ANN) found their applications in almost every nooks and corners of todays technologies like computer vision, robotics, Speech recognition, video games, data mining etc.,
As the level of computer data and hardware systems developed, people developed several Machine learning models and deep learning techniques to train the algorithm from scratch and make its own predictions from scratch instead of running an algorithm with pre-defined equations. Therefore, the data given basically programs and tunes the algorithm to get a better result. Over the period of time, due to the advancement of hardware architecture and massive parallel operations, the Deep Neural Network (DNN) techniques has made a significant improvement training real-time data and providing errorless predictions. In particular, Convolutional Neural Network (CNN) have proved itself to be the most efficient technique primarily used in Image and object detection application. This definitely sounds like a lot of CPU power and memory bandwidth is needed. Computers are generally powered by the CPU with specialized hardware accelerators like DSP, GPU, sound and video cards. However, these ASICs tend to be expensive and highly complicated process to be developed as DL frameworks keep evolving, the hardware architecture had to be changed.
To support this, people started to prefer reconfigurable FPGAs.
FPGA based AI accelerators have been recently adopted to implement DNN like CNN algorithms efficiently due to their ability of parallelism, less weight and power consumptions, and has an ideal solution for robotics systems in terms of perceiving in the 3d space environment.
In our project, we are going to make use of the new UltraScale+ architecture from Xilinx.Inc. Xilinx claims that this architecture delivers unprecedented levels of integration and capabilities with ASIC, system level performance for huge data driven application which require massive I/O, memory bandwidth, data flow, advance DSP and packet-processing performance.
Convolution Neural Networks are a multi-layered feed forward ANN with pipeline-like architecture. Each layer carries a computation on the outputs of previous layer to generate the inputs for next layer. The data to be trained are sent into the CNN as feature maps. It can be images, videos or audio files.
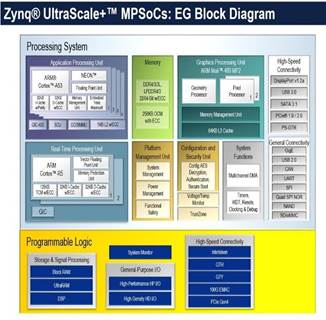
FIG 1: BLOCK DIAGRAM OF XILINX ZYNQ ULTRASCALE+ MPSOC [10]
These data get trained by the network and forms weights. In our case, CNN are trained off-line using backpropagation process to create weight file. Which is then used to perform recognition tasks using feed-forward process.
1.1 YOLO USING DARKNET FRAMEWORK
There are many CNN based object detection algorithms developed over the past decade. Among them, Yolo, programmed using darknet framework, is found to be the most efficient and fastest object detection algorithm[9]. Darknet is a framework written using C and CUDA which enables easy implementation on various CPU and GPU. There are different versions of YOLO, but for our project we are going to use the latest YOLO version 3.
Yolo is the state-of-the-art object detection algorithm:
- Bounding box prediction
- Class prediction
- Prediction across scales
- Feature extraction
- Output Result

FIG 2: OUTLINE ARCHITECTURE OF YOLO [11]
Yolo initially divides the image into a grid of 13 by 13 cells. And each cells can now predict upto 5 bounding boxes with confident scores. Once the bounding boxes are framed with certain threshold, the image is then applied to the pretrained images at multiple locations and the highest scoring regions are considered for the output.
1.2 SEMANTIC SEGMENTATION
Semantic segmentation is the task of classifying each and very pixel in an image into a class as shown in the image below. The sample output below shows that all persons are red, the road is purple, the vehicles are blue, street signs are yellow etc.

FIG 3 : SEMANTIC SEGMENTATION SAMPLE OUTPUT [12]
A typical semantic segmentation architecture has 2 phases. An encoder and a decoder:
- The encoder is a pre-trained classifier
- The task of the decoder is to semantically project the discriminative features (lower resolution) learnt by the encoder onto the pixel space (higher resolution) to get a dense classification. [12]
Semantic segmentation basically classifies each and every pixel with their individual color. It performs a very important role in the field of autonomous robots.
1.3 ROAD LANE DETECTION
The lane detection technique is one the important system in self driving vehicles. We can perform a simple lane detection using existing code libraries. The road lane detection is performed by the following sequence:
- Cropping the region of interest and Bird's View
- Grayscale conversion and Canny's Edge detection with threshold
- Generating lines from each pixel
- Creating the annotated output

FIG 4: ROAD LANE DETECTION SAMPLE OUTPUT USING OPENCV [13]
2. AIM
The project is about to develop an embedded computer vision system using Darknet Framework with FPGA board simulation. The Deep learning algorithm will be implemented to FPGA using trained weights for execution. We are going to use Xilinx ZCU102 ZYNQ UltraScale+ Architecture and Xilinx AI SDK for our project. The primary motivation of our project is to simulate AI Vision models easily on FPGA and providing an easy and portable implementation for future applications.
3. OBJECTIVES
The primary given objective of the project is as follows:
1. To build a simulation platform to execute a deep learning algorithm
2. To implement the YOLO object detection algorithm into FPGA board for vision application
Extended Objectives:
To simulate Semantic Segmentation and road lane detection in the fpga. And to combine all the three applications using Xilinx AI SDK APIs and run a fully functionable AI Vision for self driving vehicles.
To perform the simulations using weights of different pre-trained datasets available and to make a best choice based on its accuracy.
A case study will be conducted to compare the existing architects of FPGA dedicated to running AI Vision algorithms and a broad explanation of our selected architecture
A real-time simulation may be conducted at the end by fitting a camera module onto a working drone and viewing our result through a monitor wirelessly or using recorded version.
4. DELIVERABLES
The main deliverables of our project includes:
Simulation of YOLO Object detection AI Algorithm on embedded system (FPGA)
To conduct a real-time simulation of our model using FPGA
Performance study on accuracy and efficiency of running the algorithm on our FPGA at real-time
Case study on popular FPGA architects for running AI algorithms. And a detail study on process pipelining, parallelism and performance
5. PROJECT TIMELINE

|
Type |
Title |
Start date |
End date |
Duration (in days) |
|
Task |
Setting up FPGA |
11/02/2019 |
11/10/2019 |
9 |
|
Concurrent Task |
Study how our algorithm works on FPGA |
12/10/2019 |
03/01/2020 |
83 |
|
Task |
Run YOLO on FPGA |
11/11/2019 |
11/25/2019 |
15 |
|
Concurrent Task |
Study the existing FPGA architectures |
11/02/2019 |
12/15/2019 |
44 |
|
Milestone |
Simulate YOLO |
11/25/2019 |
11/25/2019 |
- |
|
Milestone |
Simulate Semantic Segmentation |
12/02/2019 |
12/02/2019 |
- |
|
Milestone |
Simulate Road Lane Detection |
12/10/2019 |
12/10/2019 |
- |
|
Task |
Run fully functionable AI vision |
02/03/2020 |
02/29/2020 |
27 |
|
Concurrent Task |
Study existing FPGA architectures dedicated for AI |
11/18/2019 |
12/01/2019 |
14 |
|
Task |
Further implementations |
02/01/2020 |
05/17/2020 |
107 |
|
Task |
Thesis writing |
02/03/2020 |
05/03/2020 |
91 |
|
Milestone |
Thesis Draft |
04/05/2020 |
04/05/2020 |
- |
|
Task |
Feedback on thesis |
04/06/2020 |
04/27/2020 |
22 |
|
Task |
Final Works |
05/01/2020 |
05/19/2020 |
19 |
5. REFERENCES
[1] Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla, " SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation". Computer Vision and Pattern Recognition (2016)
[2] Ming-Tzong Lin ; Hong-Tzong Yau ; Hao-Wei Nien ; Meng-Shiun Tsai, "FPGA-based motion controller with real-time look-ahead function". 2008 IEEE/ASME International Conference on Advanced Intelligent Mechatronics. July 2008
[3] Mrs. Rana D. Abdu-Aljabar, "Design and Implementation of Neural Network in FPGA". In Journal of Engineering and Development, Vol. 16, No.3, Sep. 2012 ISSN 1813- 7822
[4] H. Nakahara, H. Yonekawa, T. Fujii and Shimpei Sato, "A Lightweight YOLOv2: A Binarized CNN with A Parallel Support Vector Regression for an FPGA," FPGA, 2018, pp.31-40
[5] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014
[6] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012
[7] AHMAD SHAWAHNA, SADIQ M. SAIT and AIMAN EL-MALEH1, "FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review" in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition 2018, vol 4.
[8] D. F. Wolf, R. A. Romero, and E. Marques, "Using embedded processors in hardware models of artificial neural networks," in V Simposio Brasileiro de automação inteligente, Brasil, 2001. 9
[9] Redmon, Joseph and Farhadi, Ali, "YOLOv3: An Incremental Improvement". In arXiv 2018.
[10] Ovtcharov, Kalin and Ruwase, Olatunji and Kim, Joo-Young and Fowers, Jeremy and Strauss, Karin and Chung, Eric. "Accelerating Deep Convolutional Neural Networks Using Specialized Hardware". In Microsoft Research-Project Catapult. Feb 2015
[11] Figure obtained from https://www.slideshare.net/el10namaste/zynq-ultrascale
[12] Figure obtained from https://miro.medium.com/max/1152/1*m8p5lhWdFDdapEFa2zUtIA.jpeg
[13] Figure and data obtained from https://nanonets.com/blog/how-to-do-semantic-segmentation-using-deep-learning/
[14] Figure obtained from https://medium.com/@mrhwick/simple-lane-detection-with-opencv-bfeb6ae54ec0
6. ABSTRACT
A typical Convolution neural network for classification is given below with very brief explanation of each layers responsibility:

FIG OBTAINED FROM HTTPS://WWW.JAVATPOINT.COM/PYTORCH-CONVOLUTIONAL-NEURAL-NETWORK
The Convolution layers are the first layer of a CNN. It is responsible for taking the input as an pixel matrix and adding filter to it.
Pooling layer reduces the pixel of an image but retaining important pixels at the same time
The fully connected layer is responsible for predicting the accurate classes of the given input by performing a mathematical activation functions like softmax or sigmoid functions to classify the classes.
The Yolov3 and lane detection (Segmentation technique) has been successfully demonstrated on CPU (Laptop) and the output is given below:

Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Artificial Intelligence"
Artificial Intelligence (AI) is the ability of a machine or computer system to adapt and improvise in new situations, usually demonstrating the ability to solve new problems. The term is also applied to machines that can perform tasks usually requiring human intelligence and thought.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation proposal and no longer wish to have your work published on the UKDiss.com website then please: