Project Proposal for Real-Time Object Detection with Semantic Segmentation
Info: 5677 words (23 pages) Example Dissertation Proposal
Published: 10th Nov 2021
Contents
1 Introduction................................................................................................................ 4
2 Problem Statement.................................................................................................... 4
3 Background and Motivation........................................................................................ 6
4 Proposed Solution...................................................................................................... 9
5 Required Tools, Packages and Dependencies......................................................... 15
6 Testing...................................................................................................................... 16
7 Conclusion................................................................................................................ 16
8 Future Work.............................................................................................................. 16
9 Project Planning and Timeline................................................................................ 16
Appendix A: Modeling Theory of CNN, R-CNN Family, and Mask R-CNN................. 17
Appendix B: Bibliography............................................................................................ 24
1 Introduction
This proposal puts forward the development of an Android based mobile application, designed to detect, identify, and classify objects in the live stream from the mobile camera.
The goal of this application is to implement deep learning algorithm on mobile devices.
The application will have the means to detect patterns within the data at pixel level resolution considering its continuous feed from the mobile camera. And, based on the analysis, the objects in the image frame will be identified and classified into the predefined categories.
The categories will be based on the ImageNet database on which the deep learning (machine learning) model will be trained.
2 Problem Statement
The aim of this project is to develop an android application that has features of object detection and identification on live camera using machine learning algorithm and pre-defined object classes.
For example, as shown in the Figure 1, when camera is turned on in the mobile, the application will detect the object using trained deep learning (machine learning) model. The more live camera feed, the more clarity will be there to identify the objects.

Figure 1 Image showing real-time object detection and segmentation
(Image source: https://www.alamy.com/stock-photo-machine-learning-object-detection-and-artificialintelligence-concept-140769075.html)
The machine learning model for this application will be a quantized learning model taking the live stream from the device camera as input for predicting the output.
A quantized learning model with respect to this project, implies, that the model will go through the post-training quantization process. This process will reduce the model size using a general technique, while providing lower latency with little degradation in model accuracy. It will quantize the weights from floating point to 8-bits of precision.
For this project, the model will be trained on the ImageNet dataset and will then be quantized using TensorFlow Lite framework to be converted into a FlatBuffer file format to be used within the Android Neural Network API.
The Figure 2 below shows the proposed input and output process that will be used by this Android Application.
device camera Deep learning model Real-time classified
-Feature Extraction and objects in the live classification scene using bounding box with labels

Figure 2 Input and Output of the Android Application
The figure below shows an example of the high-level simplified input-output model applicable to this application.

Figure 3 High-level simplified Input-Output for the application
3 Background and Motivation
This section includes the background and motivation for this project.
3.1 Convolutional Neural Networks (CNN)
Convolutional neural networks (CNN, or ConvNet) is a type of deep artificial neural networks which is primarily applied to analyze visual data by classification, clustering, and object recognition within scenes.
The figure below shows a simplifies CNN workflow, in which images are passed to the CNN, which automatically learns the features and classifies the objects.

Figure 4 Deep learning simplified workflow using CNN
(Source: https://www.mathworks.com/solutions/deep-learning/convolutional-neuralnetwork.html)
For more details about CNN, R-CNN family, and Mask R-CNN, refer to the section Appendix A, Modeling Theory of CNN, R-CNN Family and Mask R-CNN.
3.2 Object Detection and Semantic Segmentation
3.1.1 Object Detection
Object detection is a computer vision and image-processing based procedure of finding the instances of objects such as people, car, and buildings in the images and videos. This process uses feature extraction and learning algorithms to recognize the instances of an object category. It is used in various applications like, image retrieval, security surveillance, and advanced driver assistance systems (ADAS).
3.1.2 Semantic Segmentation
Semantic segmentation involves the process to partition an image into multiple segments of pixel sets (or, super-pixels). This segmentation is then used to identify the objects location and boundaries in the images.
The segmentation simplifies the representation of an image to become more meaningful and easier to analyze. To summarize, semantic segmentation is the process of assigning a label, such as "dog", "person", "sofa", "floor" to every pixel in an image such that pixels with the same label share certain characteristics.
3.3 Machine Learning in Android Applications
A trained CNN model can be implemented in the Android based mobile devices using the Android Neural Networks API (NNAPI).
NNAPI enables the machine learning operations to run on the mobile devices. It provides a base layer of functionality to build and train neural networks for the higher-level machine learning frameworks such as TensorFlow, Caffe2, or others.
3.3.1 Android Neural Networks API (NNAPI)
NNAPI allows the trained machine learning models to perform inferencing by applying data from Android based devices. Some examples of inferencing include, image classification, user behavior prediction, and appropriate responses selection for a search query and so on.
The figure below shows the high-level architecture of NNAPI.
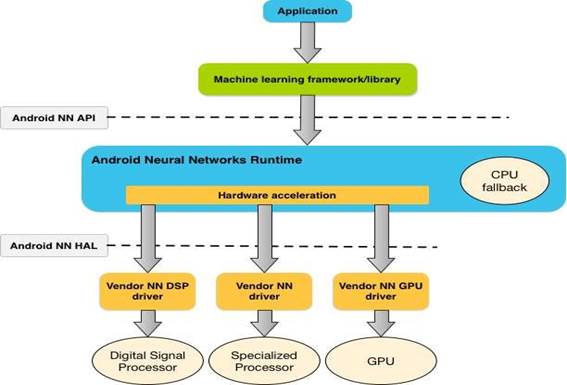
Figure 5 Android NNAPI architecture
(Source: https://developer.android.com/ndk/guides/neuralnetworks/)
3.4 Existing Deep Learning Frameworks for Mobile and embedded devices
With the widespread use of the Android operating system, several popular deep learning frameworks are available for the programmers to use, some of them are listed below:
OpenCV (Open Source Computer Vision Library) is a collection of programming functions for real-time computer vision and machine learning algorithms.
Deeplearning4j is an open-source framework released under Apache License 2.0.
TensorFlow Lite and Mobile is an open source Machine Learning framework developed by Google.
Caffe & Caffe2 are lightweight, modular, scalable deep learning frameworks developed by Facebook. Caffe2 is the successor of Caffe.
MXNet: Open-source deep learning software by Apache to train and deploy deep neural networks.
NNabla: Open source software by Sony containing Neural Network Libraries to make research, development and implementation of neural network more efficient.
3.5 Benefits of On-device Interfacing of Machine Learning Algorithms
The multi-core processors, dedicated GPUs, and gigabytes of RAM has enabled the smartphones capabilities to run complex computational programs and machine learning algorithms.
Some of the benefits of GPU acceleration for deploying AI algorithms are as follows:
Optimal Speed: With the design to have high throughput for parallelizable workloads, GPUs based devices are well-suited for deep neural nets. Comprising of many operators, each working on the input tensor(s) can easily be divided into smaller workloads to be carried out in parallel. This parallelism typically leads to a lower latency. In the best usecase, the inference on the GPU can run fast enough to perform real-time applications that were not possible earlier.
Significant Accuracy: The GPUs perform their computation using 16-bit or 32-bit floating point numbers and unlike CPUs, do not require quantization for optimal performance.
Energy Efficiency: A GPU consumes less power and generates less heat as compared to a CPU, resulting in a very efficient and optimized way of computations.
Some of the key benefits of on-device interfacing for Machine Learning:
Low Latency: Eliminates the need to send a request over a network connection and wait for a response. This can be critical for video applications processing successive frames coming from a camera.
Accessibility: Allows the application to run even when device is outside of network coverage.
Faster Speed: The hardware acceleration using GPUs provides significantly faster computation as compared to the CPUs alone.
Data Privacy: The security for the data as it no need to transfer it outside the device.
Low Cost: Eliminates infrastructure cost, as no server farm is needed when all the computations are performed on the device.
3.6 Trade-offs for Deep Learning on Smartphones
Some of the significant trade-offs for on-device interfacing of Machine learning algorithms on mobiles are as follows:
System utilization: Neural networks involve a large amount of computations, which may result in high battery power consumption.
Application size: If not carefully processed or quantized, the models may take up multiple megabytes of space. Bundling large models in the APK may result in the excessively impact to the end users.
4 Proposed Solution
This section explains the approach/methodology which will be followed during the project.
4.1 Solution Overview
This project will aim to develop a prototype Android application which will implement real-time object detection with semantic segmentation using a trained and quantized custom deep learning algorithm on the live streaming image frames receiving from the device camera.
The application will identify objects based on the model trained on a suitable database (such as, ImageNet) using supervised learning. It will identify the objects in frames and perform semantic segmentation in real-time to apply the approach for complete scene understanding, in short:
Perform object detection to draw bounding boxes around each instance of a class
Perform semantic segmentation on each of the bounding boxes and identify the object class
The solution can be broadly categorized in two stages:
a) Building and training the model using TensorFlow via Docker on Microsoft Azure using pipeline.
The figure below shows the machine learning pipeline on Microsoft Azure:

Figure 6 Machine learning pipeline on Microsoft Azure
(Source: https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-mlpipelines)
b) Developing an Android application integrating Android Neural Networks API (NNAPI) to deploy the machine learning model on the device.
The figure below proposed basic programming flow for the application.
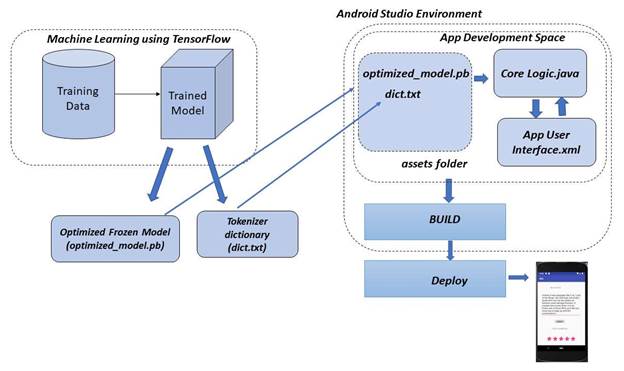
Figure 7 Proposed Basic programming flow for the Application
(Source: https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781788996921/7/c h07lvl1sec84/building-an-android-mobile-app-using-tensorflow-mobile)
4.2 Project Architecture and Detailed Work Flow
The following figure shows the proposed project architecture and stages involved:

Figure 8 Overview of project architecture and stages involved
The following steps lists the proposed workflow details for this project:
1. Import and prepare Data
a. Data Ingestion - Source an appropriate data set to be used for training, validation, and generalization testing.
b. Data preparation - Identify appropriate pre-processing techniques and apply to the data set.
2. Build and Train Model
a. Model – Build and train the deep learning model (or, use an existing model and re-train it on new dataset)
b. Feature extraction - Identify appropriate descriptors and generate a feature vector input for the classifier.
c. Image classification - Implement classifier for object class.
3. Evaluation - Evaluate the classification performance.
4. Processing the Model for Android Neural Network API integration
a. Convert the trained model into a compressed flat buffer with an appropriate converter
b. Quantize the model by converting 32-bit floats to more efficient 8-bit integers or run on GPU
5. Build the mobile application source code using Android NDK and SDK
NOTE: For a detailed proposed model for the development Android application, please refer to the section, 4.3.2 Deploying the Model on Android Application.
6. Integrate the processed model in the application using NNAPI
7. Deploy and test the model on device
8. Build and Test the application for optimization
9. Bug fixes and final bundling in the APK
4.3 Methodology for Solution
4.3.1 Creating and Training the Model
ImageNet is a massive database of images with training set of about one million images. It contains around 1000 images for around 1000 categories. The training set also includes the category names or labels for these images to allow the network to know what these training image embodies.
Using these over a million images to train the neural network delivers learned parameters to the model describing what the neural network has learned. But training the model may take lot of time, for example, VGGNet apparently took 2-3 weeks to train on a computer with four NVIDIA Titan Black GPUs. However, once a neural network is trained we can simply take these learned parameters or trained models and use them in our own applications.
The following figure shows the proposed workflow for building and training the deep learning model using TensorFlow for this project:
Classifier
- Download the classifier
- Run it on a single image
- Decode the predictions
- Run it on a batch of images
Simple transfer learning
- Download the headless model
- Attach a classification head
- Train the model
- Check the predictions



Figure 9 Proposed workflow for building and training the deep learning model using TensorFlow
4.3.2 Deploying the Model on Android Application
The following figure shows the proposed workflow for developing an Android app for this project:

Figure 10 Proposed workflow for developing the Android app
5 Required Tools, Packages and Dependencies
Python 3.5.x or Python 3.6.x 64-bit release for Windows
Microsoft Azure
Docker
Jupyter Notebook
TensorFlow
Pipeline
Bazel - build tool to compile TensorFlow
MSYS2 - bin tools needed to build TensorFlow
Android Studio
6 Testing
6.1 Unit testing
The application development with use unit testing, in which each method in the application will be tested using Junit. Testing will be carried out using a test-driven development (TDD) approach by writing the failing tests before implementation of the source code thus testing the code on an ongoing basis.
7 Conclusion
This project will develop a prototype Android Application using Android NDK and SDK on desktop platform. This application will perform real-time object detection and semantic segmentation using mobile camera. It will use a trained machine learning model for predictions. The learning model will be built and trained using TensorFlow on Docker using Jupyter notebook on Microsoft Azure cloud.
8 Future Work
The proposed Android application can be further worked upon in future to have more improved trained and stable models and additional features for end user application. It can be work be worked upon to create real-world end user applications. The machine learning model can also be re-trained for new datasets for further application.
9 Project Planning and Timeline
The table and chart below show the proposed project planning stages with their timelines.
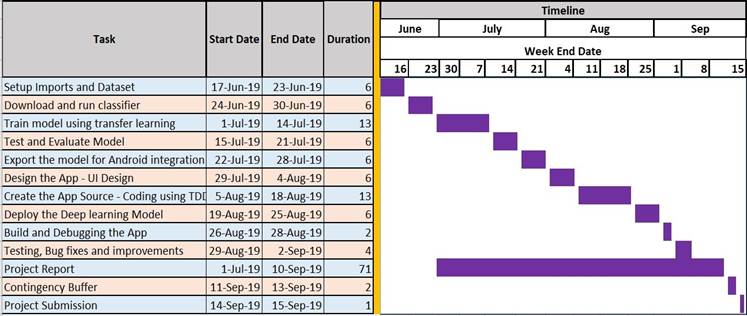
Figure 11 Project plan and timeline
Appendix A: Modeling Theory of CNN, R-CNN Family, and Mask R-CNN
A.1 Convolutional Neural Network (CNN)
A.1.1 CNN architecture
A CNN can consist of multiple layers, each of that learn to detect different features of an image. Then filters or kernels are applied to each training image at different resolutions, and then the output of each convolved image becomes the input to the next layer for processing. The kernels generally start as simple features, like brightness, then increase in complexity to features that uniquely define the object.
A CNN or ConvNet contains multiple layers that includes an input layer, an output layer, and many hidden layers in between.

Figure 12 CNN with multiple layers
(Source: https://www.mathworks.com/solutions/deep-learning/convolutional-neuralnetwork.html)
In general, a CNN contains the following layers:
Convolutional Layer – This layer takes the input images and put them through a set of convolutional filters. Each of these filters, or kernels activates certain features from the images.
Rectified linear unit (ReLU) – This layer by mapping negative values to zero and maintaining positive values, enables faster and more effective training. Sometimes, also referred as activation, since only activated features can be carried forward to the next layer.
Pooling Layer – This layer simplifies the output by reducing the number of parameters using nonlinear down-sampling.
Fully Connected (FC) Layer – Also known as FC layer, this is next-to-last layer that provides an output vector of k dimensions, where k represents the number of classes that the network will be able to predict. It contains the probabilities for each class of any image being classified.
Classification –The classification layer such as, softmax, is used by the final layer of the CNN architecture to provide the classification output.
A.1.2 CNN Workflow
The steps involved in the general workflow for CNN:

A.1.3 Limitations
The problem with using CNN approach is that the objects in the image can have different aspect ratios and spatial locations. For example, in some cases the object can cover most of the image, while in others it may only be covering a small portion of the image. The shapes of the objects can also vary, which happens often in real-life use cases.
Because of these factors, this model requires a very large number of regions resulting in a huge amount of computational time.
A.2 Region based Convolutional Neural Networks (R-CNN)
To overcome the limitation of CNN, region-based CNN is used, which selects the regions using a proposal method. This approach instead of working on a massive number of regions, proposes a bunch of boxes in the image and checks if any of these boxes contain any object. R-CNN uses a selective search to extract these boxes, called 'regions' from an image.
This approach uses three different model for making predictions, as listed below:
1. CNN – to extract feature
2. Linear SVM classifier – to identify objects
3. Regression model – to tighten the bounding boxes
The R-CNN takes an image as input and identify where the main objects are using a bounding box in the image.
The following figure shows the input-output for R-CNN model:
|
|
|
|
|

Input
Output
The figure below shows R-CNN workflow.
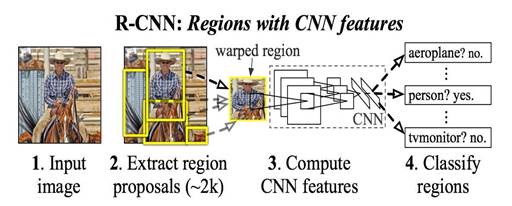
Figure 13 Region with CNN features workflow
(Source: https://arxiv.org/abs/1311.2524)
A.2.1 Limitations
R-CNN extracts around 2000 regions from each image, this results in high computation time as each region is passed to the CNN separately. In addition, it also uses three different model for making predictions resulting in more time to compute the output.
A.3 Fast R-CNN
To reduce the computation time of R-CNN algorithm, Ross Girshick, the author of R-CNN, came up with this idea of running the CNN just once per image and use that computation across the 2,000 regions. In Fast R-CNN, convolutional feature maps are generated by provided input images to CNN. These maps are the used to extract the regions of proposals. Then a regions of interest (RoI) pooling layer is used to reshape all proposed regions to a fixed size, enabling it to be able to feed into a fully connected network.
Listed below are the input and output to for this model:
|
|
|
|
|

Input
Output
The figure below shows Fast R-CNN joint training framework.

Figure 14 Fast R-CNN Framework
(Source: https://www.slideshare.net/simplyinsimple/detection-52781995)
A.3.1 Limitations
Fast R-CNN uses selective search, which is a slow and time-consuming process, as a proposal method to find the regions of interest. Considering large real-life datasets, even Fast R-CNN takes lots of computational time.
A.4 Faster R-CNN
The faster R-CNN is the enhanced version of Fast R-CNN. As compared to Fast R-CNN which uses selective search for generating Regions of Interest, Faster R-CNN uses Region Proposal Network (RPN) by adding a fully convolutional network on top of the features of the CNN.
An RPN generates a set of object proposals each with an objectness score as output by taking image feature maps as the input.
The following figure shows are the input and output for Faster R-CNN model:
|
|
|
|
|

Input
Output
A.5 Mask R-CNN
The Mask R-CNN is based on the Faster R-CNN model which uses an extract image features using CNN feature extractor. Then it creates region of interests (RoI) pooling using a CNN region proposal network, which warp them into fixed dimension to be used by the fully connected layers to make classification and boundary box prediction, as shown in the figure below.

Figure 15 A single CNN for region proposals, and classifications in Faster R-CNN.
(Source: https://arxiv.org/abs/1506.01497)
Two more convolution layers are then added by the Mask R-CNN, building a mask to this RoI pooling generating a mask, or segmentation output, as shown in the figure below.

Figure 16 Mask R-CNN with two additional layers
(Source: https://arxiv.org/abs/1703.06870)
A branch is added to Faster R-CNN that provides a binary mask output, specifying whether a given pixel is part of an object or not. This new branch is a Fully Convolutional Network (FCN) on top of a CNN based feature map.
It then takes the CNN feature maps as input to generate a binary mask as output. This binary mask is a matrix with 1s on all locations where the pixel belongs to the object and 0s elsewhere. But to make this pipeline work as expected, RoIPool needs to be adjusted to get aligned more precisely. To do this method known as RoIAlign is used.
For example, to select 15 pixels from the original image of size 128x128 and a feature map of size 25x25, knowing each pixel in the original image corresponds to ~ 25/128 pixels in the feature map, we just select 15 * 25/128 ~= 2.93 pixels.
In RoIPool, this would be round down and select 2 pixels causing a slight misalignment. However, in RoIAlign, such rounding is avoided. Instead, a bilinear interpolation is used to get a precise idea of what would be at pixel 2.93. With this, the misalignments caused by RoIPool can be avoided. The figure below shows the RoIPool realigning.

Figure 17 RoIPool realigning for more accuracy (RoiAlign)
(Source: https://arxiv.org/abs/1703.06870)
The following figure shows are the input and output for Mask R-CNN model:
|
|
|
|
|

Input
Output

Figure 18 Mask R-CNN with sematic segmentation and object classification
(Source: https://arxiv.org/abs/1703.06870)
Appendix B
Bibliography
1. Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., et al.: Tensorflow: a system for large-scale machine learning. In: OSDI. Volume 16. (2016) 265–283
2. Zhao, H., Qi, X., Shen, X., Shi, J., Jia, J.: Icnet for real-time semantic segmentation on high-resolution images. arXiv preprint arXiv:1704.08545 (2017)
3. Sheng, T., Feng, C., Zhuo, S., Zhang, X., Shen, L., Aleksic, M.: A quantization-friendly separable convolution for mobilenets. arXiv preprint arXiv:1803.08607 (2018)
4. Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: AAAI. Volume 4. (2017) 12
5. Ignatov, A., Kobyshev, N., Timofte, R., Vanhoey, K., Van Gool, L.: Dslr-quality photos on mobile devices with deep convolutional networks. In: the IEEE Int. Conf. on Computer Vision (ICCV). (2017)
6. Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks (2016) 1646–1654
7. Ignatov, A., Timofte, R., et al.: Pirm challenge on perceptual image enhancement on smartphones: Report. In: European Conference on Computer Vision Workshops. (2018)
8. Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A.P., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR. Volume 2. (2017)
9. Li, H., Lin, Z., Shen, X., Brandt, J., Hua, G.: A convolutional neural network cascade for face detection. (2015)
10. Hu, B., Lu, Z., Li, H., Chen, Q.: Convolutional neural network architectures for matching natural language sentences. In: Advances in neural information processing systems. (2014) 2042–2050
11. Severyn, A., Moschitti, A.: Twitter sentiment analysis with deep convolutional neural networks (2015)
12. Serban, I.V., Sankar, C., Germain, M., Zhang, S., Lin, Z., Subramanian, S., Kim, T., Pieper, M., Chandar, S., Ke, N.R., et al.: A deep reinforcement learning chatbot. arXiv preprint arXiv:1709.02349 (2017)
13. Ignatov, A.: Real-time human activity recognition from accelerometer data using convolutional neural networks. Applied Soft Computing 62 (2018) 915–922
14. Ordóñez, F.J., Roggen, D.: Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 16(1) (2016) 115
15. Lane, N.D., Georgiev, P.: Can deep learning revolutionize mobile sensing? In: Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, ACM (2015) 117–122
16. Codrescu, L., Anderson, W., Venkumanhanti, S., Zeng, M., Plondke, E., Koob, C., Ingle, A., Tabony, C., Maule, R.: Hexagon dsp: An architecture optimized for mobile multimedia and communications. IEEE Micro (2) (2014) 34–43
17. Latifi Oskouei, S.S., Golestani, H., Hashemi, M., Ghiasi, S.: Cnndroid: Gpu-accelerated execution of trained deep convolutional neural networks on android
18. Guihot, H.: Renderscript. In: Pro Android Apps Performance Optimization. Springer (2012) 231–263
19. TensorFlow-Mobile: https://www.tensorflow.org/mobile/mobile_intro.
20. Reddy, V.G.: Neon technology introduction. ARM Corporation (2008)
21. Alzantot, M., Wang, Y., Ren, Z., Srivastava, M.B.: Rstensorflow: Gpu enabled tensorflow for deep learning on commodity android devices. In: Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications, ACM (2017) 7–12
22. SNPE: https://developer.qualcomm.com/docs/snpe/overview.html.
23. HiAI: https://developer.huawei.com/consumer/en/devservice/doc/2020315.
24. Lee, Y.L., Tsung, P.K., Wu, M.: Techology trend of edge ai. In: VLSI Design, Automation and Test (VLSI-DAT), 2018 International Symposium on, IEEE (2018) 1–2
25. NNAPI: https://developer.android.com/ndk/guides/neuralnetworks/
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Information Systems"
Information Systems relates to systems that allow people and businesses to handle and use data in a multitude of ways. Information Systems can assist you in processing and filtering data, and can be used in many different environments.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation proposal and no longer wish to have your work published on the UKDiss.com website then please: