Capstone Project to Create a Question Generation System
Info: 9113 words (36 pages) Dissertation
Published: 30th Jul 2021
Tagged: Computer Science
Abstract
Good readers ask themselves questions while reading or preparing for competitive exams. Today, automatic generation of questions is a considerable problem by many researchers. The Automatic question generation can be classified into two broad spectrums: Interactive question answering system and educational assessment. In this project the testing was done from the educational assessment point of view. The report describes the process of generating multiple choice questions, true and false questions as well as Wh- questions, by selecting topically important sentences at a time and using various techniques and pattern matching to construct a question. The goal of this project is to ease the process of the manually generating questions for online quiz as well as on other hand students can use it to prepare for competitive exams. The question generation system is built with an objective to semi automate /automate the process to generate questions for exams and quizzes. Most of the system will be based on information retrieval and classic NLP algorithm approaches. In the following sections will be discussing the design of the modules, the technical stack of the project and the management of the system.
Keywords: Question generation, distractors, Natural language processing, machine learning, automatic question generation
I. Introduction
How could someone tell whether you have read this text? In order to know that, they might ask you to summarize it or describe how it relates to your own work. They could ask you to compare the pro and cons with another paper. They could start by asking you simple questions like which features or ranking model did you use for your paper or on what data was your model tested. This would be done to make sure if you have understood the basic facts. If you answer that then they might ask on more challenging and tricky questions.
Now if a person is good reader then he might not worry as he would be aware of all the answers but this is not the case with everyone. Ever since old days, quizzing has been one of the primary manner to examine the learner’s learning effect. Going back to school days, a teacher needs to ask basic questions to the students to ensure that they have understood the concept thoroughly. At times, generating manual questions is very time consuming and takes a lot of effort. In this report, my idea to automate the process as much possible. The focus of this project is to create a question generation system which will generate Multiple choice questions, Fill in the blanks questions, True and false questions as well as Wh- questions (i.e Who, where, which, how).
Many researchers have proposed some strategies for automatic question generation, most of them focused on vocabulary assessment only. However, if a reader understands a reading, the learner will have the skill to comprehend the meaning of each vocabulary based on its context in the reading. Thus, this project also tries to propose the system to evaluate learner’s comprehension skill.
Research of pursuing information have demonstrated that retention of material is enhance if the understudy is intermittently required to answer questions regarding what he has perused (Anderson & Biddle, 1975; Anderson et al., 1974; A!essi et al., 1974).The approach proposed by Weizenbaum’s Eliza program in 1966 made use of pattern matching to certain words in the patient’s conversation without any understanding of the content. Lets take an example, if the patient said, “I am depressed these days,” the computer would see the words “I am” and generate “How long have you,” followed by the remainder of the patient’s statement so as to produce the question, “How long have you been depressed these days?”. For my project in generation of Wh questions, pattern matching is used to a certain extent and rank the questions to improve the question semantics.
II. Motivation
I, like many students, read a lot of online texts to supplement the material that is taught in the lecture rooms provided by my teachers. Most of the times the online texts do not come with review questions or practice assessments. Also crafting these questions is a time consuming process. Here I felt the need for automatic generation of questions from text could come to rescue.
Another motivation for the project was myCourses platform provided by Rochester Institute of Technology. The online quiz section available in the myCourses need manual intervention of the creating questions, and options. Being a grader and teaching assistant for a couple of courses during my Master’s program here, I realized that process of manually creating questions is again time consuming, and often Teaching Assistant’s along with faculty need to spend a lot of time creating questions. My proposed system tries to automate the question generation process to great extent and very little manual intervention is needed to ensure the semantic correctness of the questions generated.
III. Related work
We can broadly classify the automatic question generation from text into two main categories a) dialogue and interactive Q/A system b) Education assessment. The research work in this domain has been interesting. For the first application researchers have used techniques of generating questions and dialogues from expository texts [11, 12]. In the related domain, the question generation system can be useful if the system is able to predict what kind of questions the user wishes to ask. Harabagiu et al. [13] described a similar approach where the system first tries to identify the domain topic and context and then tries to generate questions with patterns.
The second application context of generating questions for education assessment, has been investigated for many years [5]. Infact, creating an exam paper is very time consuming task and if the questions are generated by the automated system then it reduces the workload of the instructors. Various researches have seen that educational assessment applications rely on question generation methods for creating Multi choice questions for text comprehension [4, 5].
In couple of papers the overall process for generation automatic question for the English language is described as follows: (i) perform a morph syntactic, semantic and/or discourse analysis of the source sentence, (ii) identify topically important keywords from the sentances for question formulation, (iii) replace the topically important keyword with a blank or a adequate Wh question (iv) post-process the question and ensure it is grammatically correct [4,5]. Interesting examples of these steps have also been discussed in Yao and Zhang [6] which made use of Minimal Recursive Semantics. Olney et al. [7] used concept maps to generate questions from text. These approaches focus more on semantics and grammer of the question been created. Curto et al. [8] comes up with a novel approach of using lexical syntactic patterns to form question answer pairs where as on other hand Lindberg et al. [9] uses semantic labels for identifying the patterns in text in order to formulate the questions. There already exists a large body of work in automatic generation of questions for educational purposes dating back to the Autoquest system [5], which makes use of syntactic approach to generate Wh-Questions from individual sentences. In addition to Autoquest, there are other systems for Wh-question generation using approaches like transformation rules [14] and generating questions based on a given templates [10, 8]. There is also work done in gap filling questions which is mainly used for vocabulary learning. Previous works in gap filling questions have generally worked with vocabulary-testing and language learning [15, 16].
IV. Proposed System Framework
The main goal of the framework is evaluate the performance of the students , generate questions as well as try to rank the questions based on semantic correctness and difficulty level. This framework is a rule based approach which has been trained on data as well with help of OpenNLP. There are two main aspects to the framework, first is the training phase and other is question generation phase.
Steps in the training phase are as follows:
a) Load the text
b) Detect topically important sentances
c) Mark places,locations,time,dates which can be potential gap candidates
d) Detect and recognize different part of speech
e) Construct the tree
f) Eliminate unwanted phrases and punctation marks
g) Store the template questions and preview them
During the training phase, the user can also rank the questions which will help in improving the model to generate more meaningful questions. New verbs if they do not exist then can be added into the dictionary as well in order to help in creating distractors discussed later in the report.
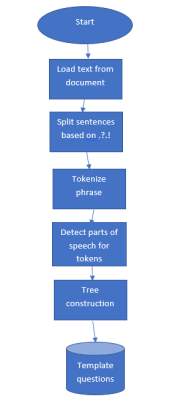
Figure 1:Training process of question generation
- Creation of Tree object
The sentence once inserted is split into various noun , pronoun, adverb category based on which it decides the selection of the gap for the sentence.
For instance, if the sentence is: “Firewall isolates organization’s internal net from larger internet, allowing some traffic to pass, blocking others.” Then the tree object generated is as shown in the figure [2].

Figure 2: Constituent Tree object for the sentence
Based on this classification of Verb, noun etc the gap is selected as well as based on various feature rules as discussed in later.
| Purpose | Expression |
|
ROOT |
|
ROOT=root |
Table 1: An example of expression used
The table [1] shows a glimpse of various expressions which are used in order to identify the main verb or the main clause in the sentence which helps in identification of the gap.
- Feature rules for Wh- questions
In deciding whether a question should be classified as a “Who” or “Why” etc, NER parser was used.
| Common Tag | NER Tag | SST Tag | Wh- question |
| Person | Person | Noun.person | Who |
| Organization | Organization | Noun.group | What |
| Time or date | ∅ | Noun.time | When |
| Location | Location | Noun.location | Where |
| Other | Other | All except above | what |
Table 2: Wh- question rules
Super-sense tagging (SST) is a NLP task where each entity like noun verb etc are annotated within the taxonomy defined by the WordNet.
Based on feature rules as seen in the Table [2], various kinds of Wh questions are generated from the sentences.
- Training data set
The system is trained on previous quiz questions as well as wikipedia documents and manually constructed questions.
| Called_VP | What did NP do ? |
| girl_ADJP | Who is the NP ? |
| Alice_NP_PERSON | Who is NP ? |
| said_VP | What did NP said to N1 ? |
| run_VP | Where did NP run to ? |
Table 3: LSTM Training snapshot
Long short term memory (LSTM) approach was used to train the model in order to predict which type of question it can get classified into. Table [3] gives a brief idea about the Wh questions which can be asked based on classification of the sentences.
Based on these training module, which consisted of around ~80 such questions the model was trained in order to detect various forms of questions which can be created when a given sentence is inputted by the user.
Training of data was also done after rating of the questions was given. Once the questions were rated by the domain experts, it was fed into the system so that the model can be improvised. All questions which had rating between 4-7 were manually modified and those questions were added to the training set for better performance of the model.
V. Data Processing
The data for this project was mainly tested for the course CSCI-735 Intelligent Security System, which mainly deals with machine learning algorithm in order to detect a threat or virus in the system.
I had access to all the slides prepared by Dr. Reznik for the course as well as the National Institute of Standard and Technology guides based on this topic along with the textbook Computer Network Security by J.M Kizza.
The questions generated and tested on students were solely based on these text data.
For training purpose, I had made use of Wiki articles as well in order to help my system to formulate better multiple choice questions and Wh- clause questions as discussed later in the sections.
The data present in the slides as well books had many pronouns like “It”, which made the generation of questions difficult for the system as the system was unable to form a link between multiple “It” and original reference, this is described later in the challenges as well. So for my model, I had to manually change those pronouns like “It” to the given original reference so that my system is able to generate appropriate questions.
VI. Fine tuning of Data
The data which I used for testing the system had many inconsistencies as well. Lets discuss them in detail.
A. Extracting data from Images
The data that I was using had power point slides and flow charts and images with textual information.
In order to generate questions from the flowchart and images having textual information, I had to write a python script to extract the textual information from the images. Along with the algorithm, I made use of pdf reader package of python to enhance the extraction process from images.
B. Incomplete sentences in slides
The slides many times had data presented in tabular format as well as incomplete sentences giving references to books and papers. In order to fetch the data correctly, following steps were used:
- Extract the data from slides and tables
- Store the incomplete sentences in a file
- Search for that given sentence in the reference paper
- Extract the complete sentences along with previous and next sentences from the paper
- Replace incomplete sentence with the result obtained in (iv)
C. Manual editing of the sentences
Many sentences had references to keywords using terms like “His”, “Her”, “It” but it is difficult for the system to create relevance for all such terms so I manually edited various sentences by replacing those pronouns with actual keywords.
VII. Question Generation Algorithms
In the system, there are various questions that I have tried to create and test with, right from fill in the blank to Wh- and true false questions. Each of them have been discussed in detail for better understanding
A. Fill in the Blank Question
Fill in the blank questions is one of the most common type of questions that a student encounters during the quiz or exams.
For Fill in the blank type of questions, the key point was to be able to identify the correct gap for which the blank needs to be created.
The algorithm followed for creating gap is as follows:
a) Train the model with predefined questions and gap
b) Use Natural language processing to identify the verbs, pronoun, noun.
c) Eliminate the stop words from being used as gaps
d) Give priority to Numbers/Places for gap creation
Using the above approach, I was able to create the gap filling questions as seen in Figure [2].

Figure 2: The fill in the blank question generation
The original text from which the question in Figure [1] was generated is “Insider is someone with access right to the system”.
Having a first glance at it, it looks like the code did a pretty good job, but I wanted to try to create all possible type of questions from a given sentence and then rank them based on good, bad and ok type of questions.
The algorithm for implementing the above-mentioned scenario is as follows:
- Train the model on set of questions, gaps and ranks associated with it
- Take the text as input and process each sentence at a time.
- Identify important keywords in the sentences and try to create gaps for the same.
- Display all possible sentences.
Gap Selection from the sentence is another important aspect. To identify the gap, employ Stanford parser to extract NP (noun phrase) and ADJP from important sentences as candidate gaps. Step wise approach is as follows:
a) Extract nouns, np, adjp from tree object
b) Using the topically important sentence extract the key gaps
c) Use lambda function and training data set to identify potential gaps
For ranking the questions into good, bad and ok category of questions, I took various other features also into consideration. Features like how many words does the blank have, how many stop words does it contain, frequency of occurring words and punctuation marks. Based on these features I tried to automatically also rank the questions which are created as seen in Figure [2].
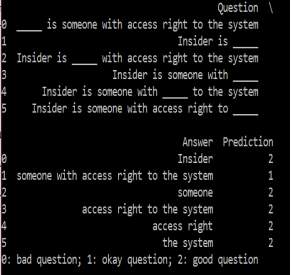
Figure 3: Showing all possible Fill in the blank question
As we can see from Figure [3] that for the input sentence “Insider is someone with access right to the system”, the system tried to generate all possible type of gap questions as well tried to automatically rank the questions.
There were various issues which I encountered with this process. As seen from the Figure[3], if we analyze second question generated, then it seems that a lot of words are in the blank and ranking should be ideally 0 but it as rank as 1.So the ranking model did not work as per the expectations,
Another major issue was the ambiguity in the answers. For instance,
“________ is someone with access rights to the system.”
This question can have various answers and not restricted to “Insider” itself. Many students might argue stating another similar word could also be correct.
In order to tackle this issue, I had to restrict the user answer choices by giving them multiple choices to select from so that there is no ambiguity in the question. I read various papers and got inspired by work done by Smith et al. presented TedClogg and approaches presented by Agarwal and Mannem [4,15] ; in these papers they generate fill-in-the-blank questions and distractor answers from the text with the help of using heuristic scoring measures. They made use of Thesaurus for getting distractors as well.
As mentioned earlier I was making use of CSCI-735 course for creating questions. This course mainly deals with Intelligent Security system terminology. The idea that I wanted to use for generating distractors is as shown in Figure[3].
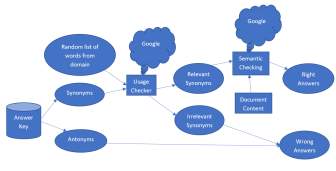
Figure 4: Approach for generating distractors
As we see in Figure [4], the selected keyword which is identified as the answer key is taken into consideration. With help of NLTK dictionary and wordNet, I try to generate all possible antonyms and synonyms for the given word. The antonyms generated are directly classified as the potential distractors. For the synonyms which are generated it is a tricky part. The synonyms generated are passed through the usage checker module which internally calls Google api and classifies the synonyms are relevant and irrelevant. Again the irrelevant synonyms are potential distractors and incorrect answers. The relevant synonyms are passed through semantic checking where we also put the original sentence into the module to check if semantically the sentence makes sense. Based on it we have a list of correct answers and wrong answers.
One of the issue is that, if the text is too technical in nature then generating synonyms and antonyms is difficult. For instance, if the candidate gap is “Firewall” then generating antonyms and synonyms is difficult. To overcome this difficulty, I had created a list of random words related to the domain, i.e when creating questions for CSCI-735 course, most of the jargons which are commonly used in that course were present in that random list. Hence the words picked from random list was also a part of distractors and incorrect answers.
B. True and False Question Generation
Identify applicable sponsor/s here. If no sponsors, delete this text box (sponsors).
True and False type of questions are another classic example of questions which are usually asked during exams or quizzes. The generation of True/False questions is mainly based on facts and figures.
There are multiple ways to generate a True/False question. One way is to move the modal verb to the front of the sentence and add a question mark at the end. This can be achieved via transducer template solutions.
Approach :
1) Make every statement in the list of statements False, except one.
2) If terms in the sentences have negative words like “could not / does not” convert to “could / does” and vice versa. If the sentence has no negative terms then try and add “not” in the sentence.
3) If there are numbers present in the question, try and manipulate the digits.
The system generates three categories of True/False questions.
a) Classic True and False: In this scenario a statement is given and the user needs to identify whether the statement is true or false. In order to make it tricky, I used negations like can converted to cannot , as well as if numbers were present then try to manipulate with it in the range. An example of this question generation can be seen in the Figure[5].

Figure 5: Classic True and False question
b) Multiple choice single answer True/False: In this scenario, four topically important sentances are taken into consideration, out of which 3 of them are negated or manipultaed with number is present, and only of the sentence is left in original form which is the right answer. An example of this scenario is seen in Figure [6].

Figure 6:An example of multi choice single answer True/False
As seen in the Figure [6], option (a), option (b) and option (d) have been negated from their original forms while option (c) is intact which is the correct answer.
c) Multiple choice Multi Answer True/False:This apporach is an extension of Multiple choice single answer method. The idea to create this approach was that the former approach could be easy at times for the user to detect the pattern of three negations in the sentence. So in this scenario, each time there will be a random number from 1-4 which will be true statement and the remaining statements will be false. The user needs to identify and mark all the true statements in order to get full credit. Figure[7] potrays how would this question look like.

Figure 7: Multiple choice Multi answer True/False
In Figure[7], option(a) and option (d) have been negated where as option (b) and option (c) have been kept intact. So the user needs to identify all the correct options and mark them to get full credits.
C. Wh- Type Question Generation
This is the interesting and challenging part of the project.
In this module, the system was trying to generate Wh- type of questions i.e. Who, What, Why, How scenario based questions.
In order to access the ability of knowledge grasped by the user, these kind of questions help in gauging it to a certain extent. The algorithm used to generate this type of questions is as described below:
i) Select the topically important sentences
ii) Identify the gaps using the logic described in A
iii) Based on various patterns associated Who, Where, What and How clauses
iv) Terminate the sentence with “?”
In order to try to detect whether a sentence should be associated with Who v/s How a list of patterns was developed by generalizing from the sentence features which I found myself using when I generated questions from text. Each pattern was associated with given set of rules and the question was formulated based on matching pattern. For instance if the target keyword selected is classified as Person entity then the clause to be used more aptly is “Who” rather then “When” or “How”. But at the same time the process of generating this Wh clause questions does not seem to be easy as domain knowledge is vast and a lot of training is needed, we can see that in the Figure [8].

Figure 8: All possible Wh- questions generated
As we can see from the Figure [8] that for a given sentence there are many questions which are generated from the Wh clauses as it matches with one of more pattern rules. Out of these questions there would be some questions which would make no sense at all.
In order to help the model, generate better questions as well as to automate the system, I devised a ranking module user interface which would ask the user to rank these generated questions on a rank scale of 0-10.
Based on the ranking, it would be saved in the file which will be used for training the model as well. For instance all questions which would be ranked above 7 would be good to be kept in a quiz, whereas questions having rank between 4-7 would need manual intervention for grammatical and domain knowledge help and questions having rank less than 4 would be irrelevant and can be ignored.
In this way the model would be automated to a certain extent as well it get training for future generation of questions.
The table [4] gives an overall picture of all the methods and techniques used to generate various kinds of questions which are implemented in this system.
| Sr. No | Type of Question Generated | Methodology | Algorithm/Packages used | Evaluation and Results |
| 1. | Fill in the blank question creation | Select topically important sentences using Noun, pronoun, verb, adverb into consideration. | Mainly used NLTK package of python | 1)Gaps created were good for majority of questions
2) Open interpretation was possible. |
| 2. | Fill in the blank with Multiple choice options | Sentence selection, key selection and distractor selection is domain specific and NER feature is used for key selection. | Used natural language processing toolkit with NER package in python | Manually Evaluation is done
1) Evaluation on the sentence selected 2) Evaluation of targeted answer keyword 3) Evaluation of selected distractor. |
| 3. | Fill in the blank with MCQ semi automated system | Extension of 2. With automatic ranking of questions in good, bad and ok category. | In order to rank the questions in Good, bad and Ok category made use of Support vector machine model to train the system and used various features to rank them. | 1) Bad question misclassified as Ok.
2) Manual intervention was needed but reduced compared to earlier approach. |
| 4. | True and False question | Using logic of negation converting can to cannot and playing with numbers. | Made use of regex patterns to identify terms and numbers to manipulate the facts. | 1) The questions generated were straight forward
easy to interpret the negative parts. 2) At times negation in sentences lost the meaning 3) Manual semantic correction was needed. |
| 5. | True False Multiple choice | An extension of 4. but having one correct answer and 3 negated options. | Made use of regex patterns to identify terms and numbers to manipulate the facts. | 1) Easy to figure out the pattern as only one of them was correct so the students could solve it easily. |
| 6. | True False Multiple choice Multiple Answer | An extension of 5. with more than one answer correct. So the user had to mark all options | Ensured a random number of options negated using regex and negation techniques. | 1) It enhanced the performance compared to earlier approach. |
| 7. | Wh- Type of question generation | Input sentence, Feature Extraction through NER, Test Sentence pattern and Test the Question type pattern. It generated all possible questions from a given sentence. | Used python packages feature rules and training data to identify whether a question is “Who” or “Why” | 1) 200 sentences are extracted and mapped into 100 patterns using NER. The 100 patterns are used in training and testing.
2) Precision, Recall and F-measurement is used for classification of question type. |
| 8. | Wh- Type of question with automated ranking | Extension of 7, with ranking module in order to get better accuracy. | A gui is created using python TkInter which takes the ranking of the questions and stores in text file to train the model to perform better. | 1) Automation to certain extent
2) Questions having rank of 7-10 could be used with manual reading, 4-7 needs manual intervention and less than 4 can be ignored. 3) Accuracy is 78% in correctly classified generated question which is promising |
Table 4: A comparative study of various algorithms and modules used in the system.
VIII. Overall System Flow
The overall process flow is as shown in Figure [9]:
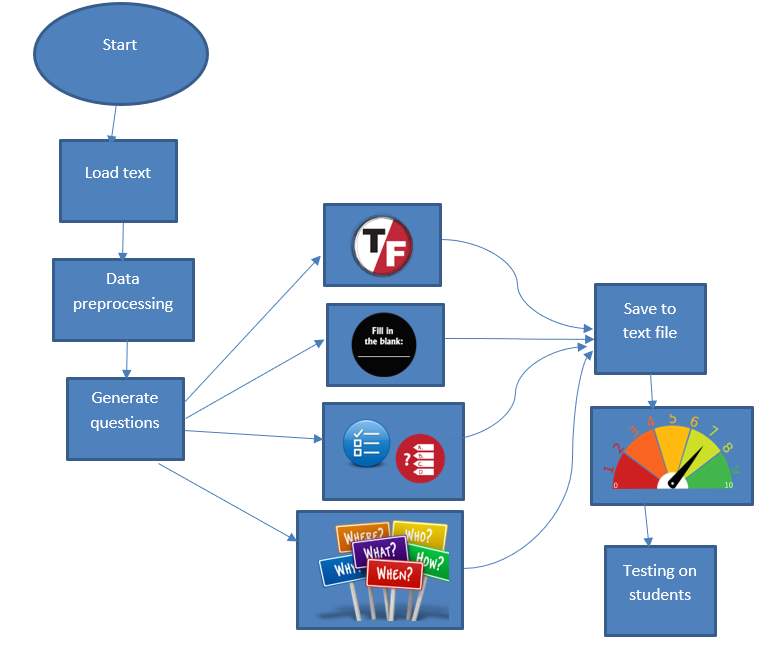
Figure 9: An overview of the entire system
The figure gives an idea about the overall system working where we load the data from the slides, books and pdf do some preprocessing of the data and generate the questions. Based on various of types on questions which are generated, it is saved to the file and an automatic as well as manual evaluation is conducted with the help of domain experts. Once based on the rating of the questions, changes are made and questions are ready for the students to be tested on quiz.
IX. Technical Stack and User Guide
In this project the programming language used is Python. There were various packages like NLTK and other natural language packages which were used along with my algorithms.
The process to execute the system is similar to as described in Figure [9]. There is no website or web hosting for the system currently, so everything runs on the local machine, since there are dependencies on wordNet API, CoreNLP so local machine servers should be running and calling those API in order for the system to work correctly.
There are graphical user interfaces which are again created in Python, with help of TkInter. The GUI take responses for ratings of the questions and displays the generated questions to the user.
The generated questions based on rating are stored in the files and can be used for testing on students on quiz or used by students for preparing in competitive exams and as study guide. In detail step by step instruction for running the code is provided in readMe file along with the code.
X. Challenges
During the project there were many computational and linguistic challenges that I encountered during the generation of questions.
We can broadly classify the challenges into three categories lexical challenges, discourse related challenges and syntactical challenges.
A. Lexical Challenges
Lexical challenges that were encountered during the project were mainly related to questions being generated from short phrases and sentences.
The semantics of the answer to a question plays an important role in determining the question that will be formed. For the fill in the blank and True/False scenario it was not an issue but for the generation of Wh type of question, it matters a lot because the answer will determine whether the question will be classified as a who question, what question etc.
Taking example in Figure [10] , we can clearly see that it tries to generate all possible questions from the sentence but out of which “Q.3” seems relevant and “Q.1” and “Q.2” seem irrelevant. In “Q.1” it tries to assume Application Firewall as a person entity which is incorrect and in “Q.2” it seems to phrase illogical question.

Figure 10:Wh- Question scenario 1
An extension of it was seen when it misclassifies a person entity while phrasing the question. This is shown in the Figure [11], where Chetan Bhagat is an author who wrote the book called Two states, so the first question which is formulated is acceptable but on other hand the second question generated does not seem to be acceptable.

Figure 11: Wh- question scenario 2
B. Paraphrasing
Paraphrasing is another challenge in automatic generation of questions, which should have slight variation from the original text.
For instance taking Figure [11] example, the system should also generate questions like “Who authored the book Two States?”, “Who was the book Two States written by?”, “Who wrote the book Two States?”. All these variations are also acceptable and valid questions.
One of the approaches to tackle this issue was discussed in the paper having existing paraphrase generation techniques (Callison-Burch, 2007; Kok and Brockett, 2010).
C. Generation of Distractors
The generation of distractors is also challenging if the topic on which questions are generated is too technical. For instance the data that I had was on Intelligent Security System course which mainly dealt with security, virus, firewall etc. So getting distractors with help of synonyms and antonyms is difficult as these terminologies may not have synonyms and antonyms at times.
One of the way that I came up to solve this issue to certain extent was to have a separate list created which extracts all such keywords from the text and stores them in a dictionary. All such words can be used as distractors for other questions for which these words are not an answer.
D. Relevance of pronouns
This is one of the biggest challenges on which a lot of research is still going on and work is in progress.
When the system tries to read the text, then it needs to figure out the link between the sentences as well which currently my system fails to do it and I need to manually correct the sentences.
An classic example that I encountered during my project is seen in Figure[12].

Figure 12: Relevance of keyword “it” for question generation
As we can see in Figure [12], the first sentence has the main term Firewall and the following sentences are referring to Firewall by using the keyword “it”. Unfortunately, the code fails to create the connection between sentences and simply creates questions taking sentences as independent entities.
This issue is currently in research and can also be witnessed in search engines. For instance if the first query is “Who is Bill gates?” and the second query is “What is his net worth?”. If we run these two queries one after another in Google Chrome then for second query in chrome we will get irrelevant result giving net worth of random “his” entity, where as in Microsoft Bing browser for the second query we will get net worth of Bill Gates.
So the idea is to use Long short term memory (LSTM) graph storage in order to form connections between sentences but for a given piece of passage it will very difficult to form that link of tree object in order to create questions. I did read various research papers on LSTM as well but there are various limitations for this approach as to the depth till which it can go in order to save the references, which eventually means that its not the ideal approach as well.
XI. Manual and Automatic Evalution
For identifying whether the system has generated the questions corrected or not, I had taken help of manual evaluation as well as automatic evaluation to a certain extent.
1) Manual Evalution
In Manual evaluation, the questions generated by the system were rated by the instructor for the course, teaching assistant for the course as well as a PhD student researching in that area. A small snapshot of their rating is shown in the Table[2].
| Sr. No | Type of Questions | Number of questions | Rating
(Out of 10) |
| 1. | Fill in the blank | 20
50 40 |
>7
4-7 0-3 |
| 2. | Fill in the blank with MCQ | 40
50 10 |
>7
4-7 0-3 |
| 3. | True and False | 30
15 |
>7
0-3 |
| 4. | True and False Multiple choice | 40
30 10 |
>7
4-7 0-3 |
| 5. | True and False Multiple Answer | 50
20 5 |
>7
4-7 0-3 |
| 6. | Wh- Questions | 40
65 30 |
>7
4-7 0-3 |
Table 5: Manual evaluation snapshot on small set of data
Based on Table [5], all the questions which had a ranking of 7 and above were good enough which could be put in quiz without any manual intervention. All questions which had a ranking between 4-7 needed a manual review with terms of grammar of the sentence as well as the jargons and structure of the sentence if it made sense. Where as remaining questions having ranking 0-3 were irrelevant and not making sense. For instance in 3. True/False scenario, 0-3 ranked questions where ones which had meaning of the sentence when negation was added to it, so all such questions having rating less than 3 could be ignored.
2) Automatic Evalution
In automatic evaluation process the steps used were as follows:
a) Number of gaps present in the sentence
b) Number of negations used in the sentence
c)Classification of person category question with “How” instead of “Who”
d) Using above mentioned rules and various other rules, ranked the generated questions into Good, bad and ok category where Good meant >7, Ok was 4-7 and Bad was 0-3 ranking in terms of manual ranking of questions.
The automatic evaluation was not that accurate compared to manual evaluation so an extension of it was that once automatic ranking was done, a GUI with ranking module was created and domain expert was asked to enter the rating, once that is entered it would compare both the rating and a common pool of questions would be taken out which satisfies both ratings within a threshold for evaluation and visualization purpose.
XII. Testing and Survey
Experimenting the questions generated on candidate’s real time is something really interesting and helpful in order to improve the system.
As mentioned earlier, Dr. Reznik who was instructor for the course CSCI-735 gave me an opportunity to test the students with the questions generated by my system for their online quiz evaluation.
One of the main goal of this project was to ensure that my system is as good as a human being in generating the questions and in order to ensure that this opportunity was really helpful.
The results were interesting as well as fascinating, as it appeared that the students were not able to identify that the questions were automatically generated or manually created.
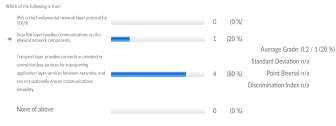
Figure 13: Multiple choice True/False result analysis
As we can see from Figure [13] that the result is quite interesting. The answer to the question was option (b) but majority of the students marked option (c). There could be various interpretations for this, either the students did not read the options carefully (as option c has negation added in the sentence) or the students were not clear with the concepts.
Another interesting question analysis is seen in Figure [14], in this question we can see that since the students had to select True or False, 57% of the students were able to guess it correctly but 43% of the students gave incorrect answers.
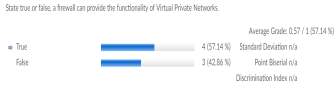
Figure 14: Classic True/False question analysis
Also there were other fill in the blank and multiple choice questions where majority of the users were able to answer them correctly and was easy to detect the answers as well.
Another interesting opportunity that I got was to have Survey results from the students, after the quiz. In the survey there were 3 questions that were asked the responses for that also were interesting.
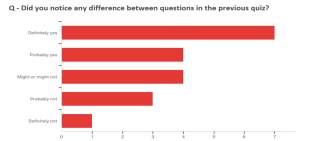
Figure 15: Survey question 1 analysis
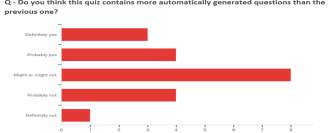
Figure 16: Survey question 2 analysis
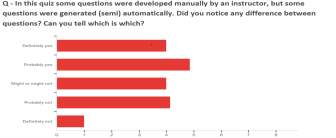
Figure 17: Survey question 3 analysis
Based on Figure [15], Figure [16] and Figure [17] it is easy to gauge that the majority students seem to have found a difference between the automate question generated quiz and manual question generation, but they would have difficulty in being able to detect which question is generated by the system and which is manually constructed.
The votes for Definitely Yes compared to votes for remaining category are evenly distributed which implies to a certain extent that the system was able to perform well on evaluating the student’s performance on the knowledge of the topic.
This survey helped me to understand that probably more fine tuning of the question generation needs to be done but at the same time the questions created by the system are good enough to trick the user as well as gauge the concepts.
XIII. Learning Outcomes
Working for this project gave me an immense knowledge for various algorithms present in the Machine learning domain to implement for my project. As mentioned in the challenges, generation of questions is not an easy task and there is lot of research going on. For instance, I realized that my system works for generating questions from the sentence provided the sentence has proper keywords and does not have pronouns like “It” which makes it difficult for the system to create connection between various words.
I got an exposure to various machine learning modules like Stanford parser, natural language processing toolkits as well as various algorithms to do semantic analysis and identify keywords from the sentences.
XIV. Conclusion and Future Work
In summary, the system to generate questions from text was data driven machine learning methods. The question generation process is a difficult activity in educational domain and is one of the research problems in modern days. The proposed system is flexible, ease to use and applicable in different levels of education environments. It is large scale ready with ability to learn more and more about different styles of topics and fields.
There are a number of avenues for future work. Although our question generation strategy is domain independent but as described for random list in Section V, some question patterns such as the ones focusing on the Intrusion detection and security might not be useful in other domains.
In another direction, our system can be explored to generate MCQ questions based on semantic parsers rather than on human domain knowledge.
As for distractor generation, the current system mainly used the idea of synonyms, antonyms, and random list of domain words but one can look at more advance ways of generating distractor items using causal relations and the knowledge of prior and subsequent events.
The system can be integrated with myCourses platform or can be leveraged and used with online learning portals like Moodle. Also, many online educational portals like Coursera and Udacity have video lectures, so in order to test the knowledge or self-learning, using IBM speech to text API the text can be generated from the video lectures and based on the text, the current system can generate the questions.
Currently, a prototype system has been implemented purely on python platform. However, this domain is open-ended as the knowledge base required is tremendously large and cannot be completed with limited sources and time. In future work, I would love to seek help of volunteers from the Internet for building the knowledge base.
Another interesting possibility is to feed the questions to the robot for conversations. Since the system tries to generate all possible questions from the sentence, it can train the robot to ask questions to the user to know more about the topic as well.
The system can be extended in future to be able to recognize new statements with auto suggestion without needs to user intervention.
Acknowledgment
I would like to thank Dr. Leon Reznik for guiding me through my capstone project and always being available to help, also giving me an opportunity to test my system on students of his CSCI-735 course online quizzes. Last but not the least, I would like to thank the faculty members at Rochester Institute of Technology, family and friends for helping me through during the project as well as in completing my Master’s Degree successfully.
References
John H. Wolfe. 1976. Automatic question generation from text – an aid to independent study. In Proceedings of the ACM SIGCSE-SIGCUE technical symposium on Computer science and education (SIGCSE ’76), Ron Colman and Paul Lorton, Jr. (Eds.). ACM, New York, NY, USA, 104-112. DOI=http://dx.doi.org/10.1145/800107.803459
Alessi, S. H., Anderson, R. C., Anderson T. H., Biddle, W. B., Dalgaard, B. R., Paden, D. W., Smock, H. R., Surber, J. R., & Wietecha, E. J. Development and implementation of the computerassisted instruction study management system (CAISMS). San Diego, California: Navy Personnel Research and Development Center, Technical Report TR 74-29, February 1974.
Anderson, T. H., Anderson, R. C., Alessi, S. M., Dalgaard, B. R., Paden, D. W., Biddle, W. B., Surber, J. R., & Smock, H. R. A multifaceted computer-based course management system. San Diego, California: Navy Personnel Research and Development Center, Technical Report TR 75-30, April 1975.
M. Heilman and N. A. Smith. “Question Generation via Overgenerating Transformation and Ranking” Online : http://www.cs.cmu.edu/ mheilman/papers/heilmansmith-qg-tech-report.pdf, Last visit on 2017.
J. H. Wolfe, “Automatic Question Generation from Text – an Aid to Independent Study SIGCUE Outlook”, In proceedings of the SIGCSE-SIGCUE technical symposium on Computer science education, 1976, pp.104–112.
X. Yao, and Y. Zhang, “Question Generation with Minimal Recursion Semantics”, In Proceedings of QG2010: The Third Workshop on Question Generation, 2010, pp. 68-75.
A. Olney, A. Graesser, and N. Person, “Question Generation from Concept Maps”, Dialogue and Discourse, Vol. 3, No. 2, 2012, pp. 75-99. R. Nicole, “Title of paper with only first word capitalized,” J. Name Stand. Abbrev., in press.
S. Curto, A. Mendes, and L. Coheur, “Question Generation Based on Lexico-Syntactic Patterns Learned from the Web” Dialogue & Discourse, Vol. 3, No. 2, 2012, pp. 147-175.
D. Lindberg, F. Popowich, J. Nesbit, and P. Winne, “Generating Natural Language Questions to Support Learning on-line”, In Proceedings of the 14th European Workshop on Natural Language Generation, 2013, pp. 105- 114.M. Young, The Technical Writer’s Handbook. Mill Valley, CA: University Science, 1989.
[10] W. Chen ,G. Aist, and J. Mostow, “Generating Questions Automatically from Informational Text”, In Proceedings of AIED Workshop on Question Generation, 2009, pp. 17–24.
[11] H. Prendinger, P. Piwek, and M. Ishizuka, “Automatic Generation of Multi-Modal Dialogue from Text Based on Discourse Structure Analysis”, In Proceedings 1st IEEE International Conference on Semantic Computing (ICSC- 07), 2007, pp. 27–36.
[12] P. Piwek and S. Stoyanchev, “Generating Expository Dialogue from Monologue: Motivation, Corpus and Preliminary Rules”, In Proceedings of the 11th Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2010, pp. 333– 336.
[13] S. Harabagiu, A. Hickl, J. Lehmann, and D. Moldovan. “Experiments with Interactive Question-Answering”, In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics, 2005, pp. 205–214.
[14] K. Nikiforos, L. Ha, and M. Ruslan, “Generating MultipleChoice Test Items from Medical Text: A Pilot Study”, In Proceedings of the Fourth International Natural Language Generation Conference, 2006, pp.111–113.
[15] M. Agarwal, R. Shah, and P. Mannem, “Automatic Question Generation using Discourse Cues”, In Proceedings of the 6th Workshop on Innovative Use of NLP for Building Educational Applications, Association for Computational Linguistics, 2011, pp. 1-9.
[16] R. Agerri, J. Bermudez, and G. Rigau, “IXA Pipeline: Efficient and Ready to Use Multilingual NLP tools”, in: Proceedings of the 9th Language Resources and Evaluation Conference (LREC2014), 2014, pp. 26-31
[17] Sheetal Rakangor*, Dr. Y. R. Ghodasara, “ Literature Review of Automatic Question Generation Systems” , International Journal of Scientific and Research Publications, Volume 5, Issue 1, January 2015 1 ISSN2250-3153
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Computer Science"
Computer science is the study of computer systems, computing technologies, data, data structures and algorithms. Computer science provides essential skills and knowledge for a wide range of computing and computer-related professions.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: